【证书】2025公益课,人工智能训练师-高级,知识点与题库(橙点同学)
【证书】2025公益课,人工智能训练师-高级,知识点与题库(橙点同学)
文章目录
- 1、课程与考试介绍
- 2、知识点总结
- 2.1 知识点大纲
- 2.2 重点知识内容解析
- 2.3 课程例图
- 3、题库
- 3.1 单选题
- 3.2 判断题
- 3.3 多选题
1、课程与考试介绍
认证信息
对文本生成算法有简单的了解,通过学习可以知道算法是如何生成文本生成内容的。学习语音识别,ASR模型的特点及如何调优模型;TTS的特点,语音合成中常见的问题及如何调优,掌握意图识别和分类算法的应用场景,如何对模型效果进行评测。
考试条件:本认证的教学课程均学完 100% 的小节
- 智能语音分享-语音合成TTS
总计 1 节,你已学完 1 节,达到考试条件需要学完 1 节 - 智能语音分享-语音识别ASR
总计 1 节,你已学完 1 节,达到考试条件需要学完 1 节 - 文本生成的原理与应用
总计 1 节,你已学完 1 节,达到考试条件需要学完 1 节 - 意图识别和分类算法
总计 1 节,你已学完 1 节,达到考试条件需要学完 1 节

2、知识点总结
2.1 知识点大纲
一、知识点大纲
1. 数据质量与标注
- 数据质量的关键要素
- 正负样本平衡的重要性
- 标签构建原则(业务相关性、正负样本均衡)
- 噪音数据对模型的影响
2. 语音处理技术(ASR/TTS)
- ASR(语音识别)的错误类型(替换/删除/插入错误)
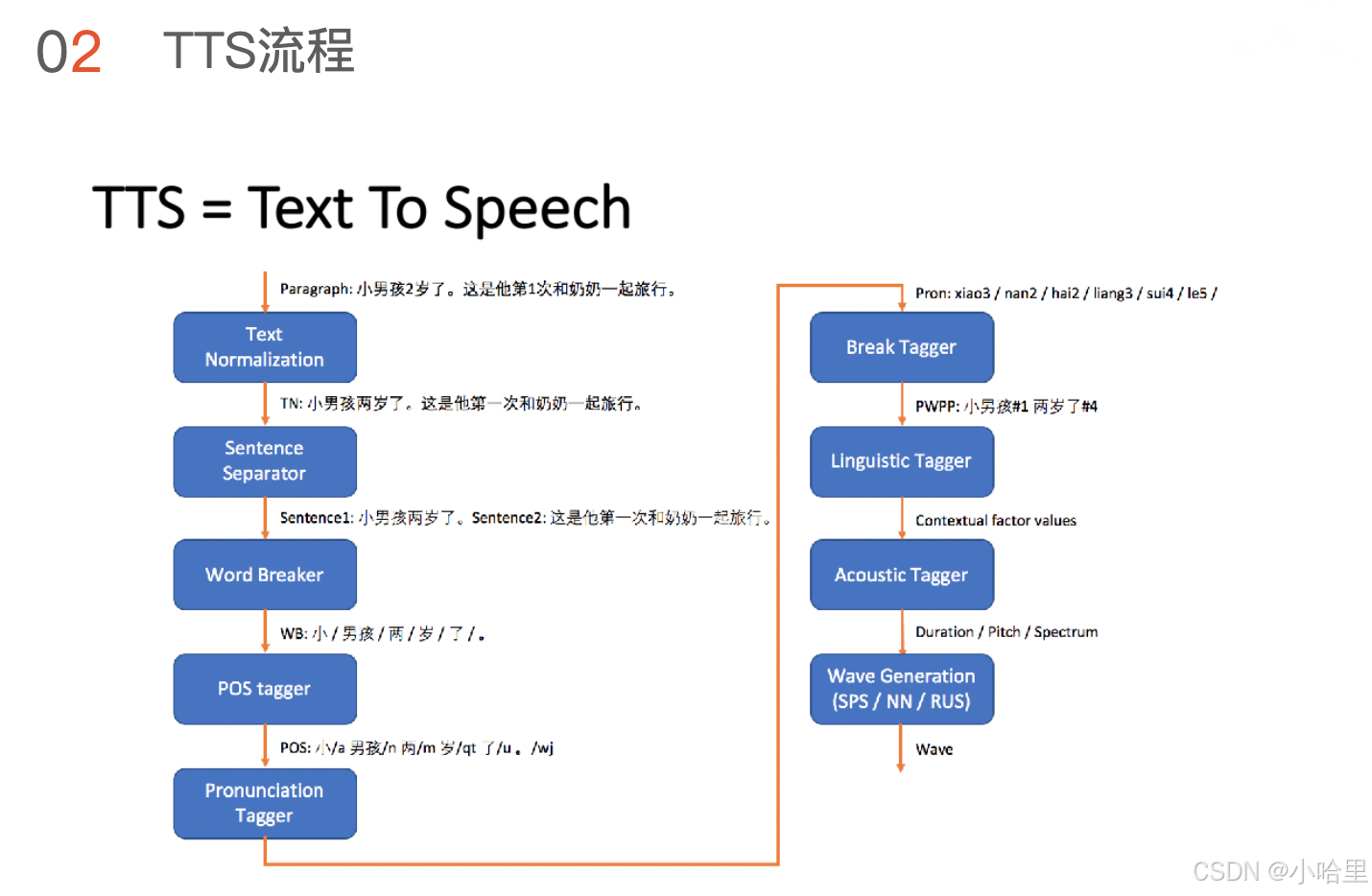
- TTS(文本转语音)的核心模块(文本归整、获取读音、停顿模型)
- TTS常见错误(读音错误、停顿错误)
- SSML(语音合成标记语言)的作用与标准
3. 模型评估指标
- 准确率(Accuracy)与精准率(Precision)的计算
- 召回率(Recall)的公式与应用场景
- 字符错误率(CER)的计算方法
4. 分类任务类型
- 二分类、多分类、多标签分类的区别
- 多标签分类的典型场景(用户画像、文本标签)
5. 分词与文本处理
- 正确分词规则(如地名拆分)
- 文本正则化(数字转汉字、符号处理)
6. 模型训练与优化
- 数据量与质量的权衡(高质量数据优先)
- 声学模型在口音优化中的作用
- 方言模型构建的底层逻辑(词典建设)
2.2 重点知识内容解析
二、重点知识内容解析
1. 数据质量与标注
- 核心要点:
- 高质量数据需具备准确性、全面性、代表性,避免噪音和错误标签。
- 样本平衡:同一模型中训练数据的样本需均衡,否则易导致过拟合或欠拟合。
- 标签构建:需结合业务知识,正负样本均需充足,标签范围不宜过小(易过拟合)或过大(缺乏针对性)。
- 典型例题:
- 提升数据质量的方法包括无噪音数据、样本平衡、负向样本丰富(答案:D.以上都是)。
- 构建数据标签时需考虑业务属性(答案:C)。
2. 语音处理技术(ASR/TTS)
- ASR错误类型:
- 替换错误:识别结果中字错误(如“排球”→“拍球”)。
- 删除错误:识别结果缺失实际语音内容(如漏读“天”字)。
- 插入错误:识别结果多出无关内容(如额外添加“哦”)。
- TTS核心模块:
- 文本归整模块:负责数字转汉字(如“2岁”→“两岁”)、符号处理。
- 获取读音模块:直接影响发音准确性,是TTS读音错误的主要来源。
- SSML:通过格式化标记控制语音合成的语速、语调、音量等,属于W3C语音接口框架。
- 典型例题:
- TTS中数字转汉字属于文本归整模块(答案:A)。
- ASR中“实际语音有、识别结果无”属于删除错误(答案:A.正确)。
3. 模型评估指标
- 计算公式:
- 准确率(Accuracy) = 预测正确数 / 总数据量 × 100%
- 精准率(Precision) = 预测正确数 / 预测有结果数 × 100%
- 召回率(Recall) = TP / (TP+FN) (TP:真正例,FN:假反例)
- 字符错误率(CER) = 错误字符数 / 总字符数 × 100%,插入错误可能导致CER超过100%。
- 典型例题:
- 总数据10条,预测正确5条,准确率50%;预测有结果6条,精准率83.3%(答案:A)。
- 标注文本10字,错误4字,CER=40%,字准确率=60%(答案:A)。
4. 分类任务类型
- 区别对比:
分类类型 定义 示例 二分类 样本分为两类(非此即彼) 垃圾邮件判别(是/否) 多分类 样本分为多个互斥类别(仅属其一) 情绪识别(愤怒/高兴/平静) 多标签分类 样本可同时属于多个类别 新闻标签(体育、C罗、欧冠) - 典型例题:
- 书箱分类(同时有“出版社、语言、内容类型”标签)属于多标签分类(答案:C)。
- 用户画像包含多个维度标签(如年龄、性别、兴趣),属于多标签分类(答案:A.正确)。
5. 分词与文本处理
- 规则要点:
- 地名分词需保持完整性(如“南京市长江大桥”→“南京市/长江大桥”,答案:B)。
- 文本正则化需避免读音错误(如“二岁”→“两岁”,答案:A)。
6. 模型训练与优化
- 核心原则:
- 数据质量优先于数量:低质量数据量增加可能引入更多噪音(答案:B)。
- 口音与方言处理:
- 重口音可通过加强声学模型训练改善。
- 方言模型需从底层词典建设开始,涉及词汇、语法多层面,仅优化声学模型不足(答案:D)。
2.3 课程例图
1、智能语音分享-语音合成TTS—玉环
- 人机对话
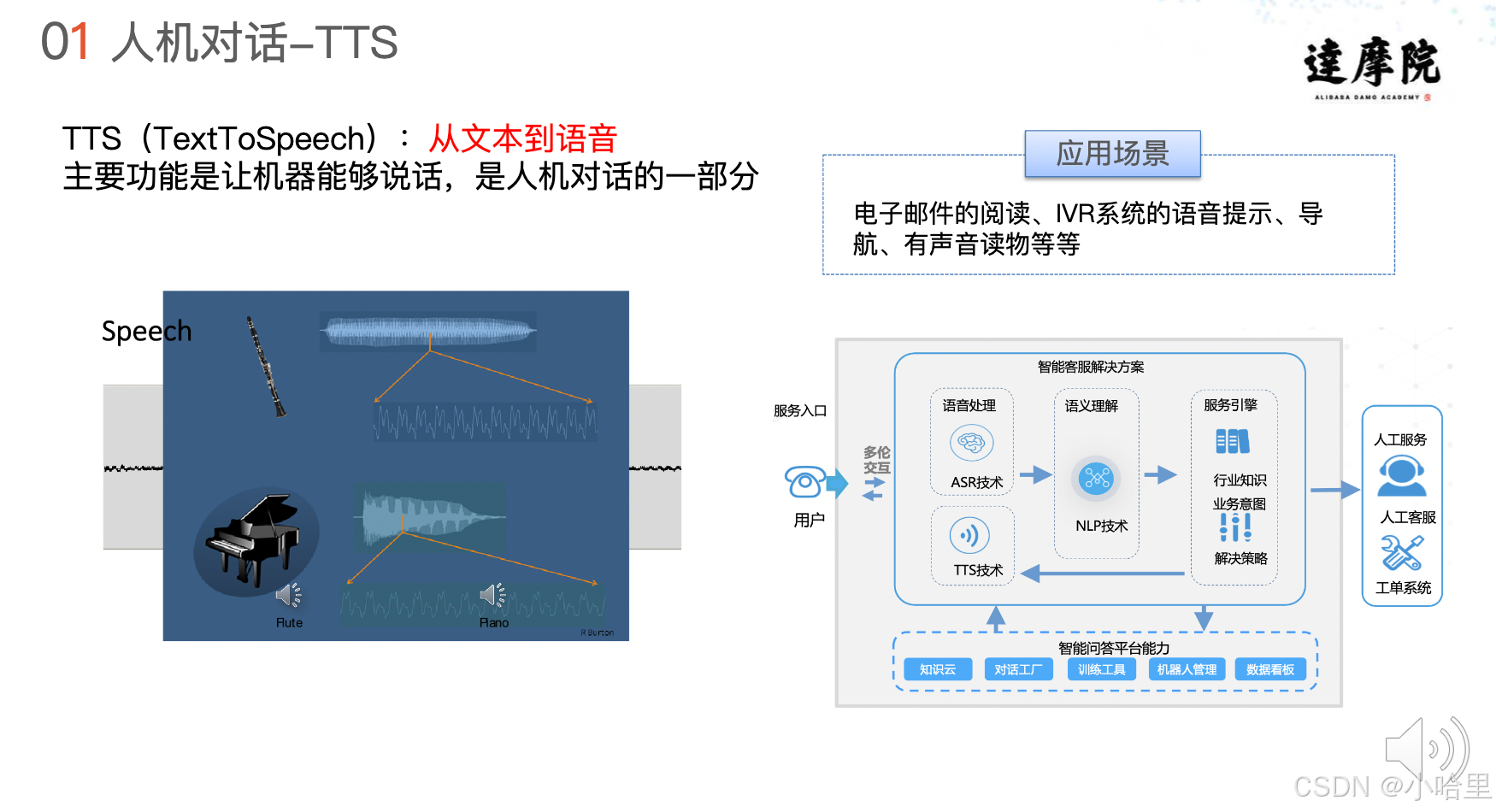
- TTS流程
- TTS vs ASR:
TTS跟ASR正好是反向的,ASR输入的是语音,输出的是文字,而TTS的话他输入的是文字,输出的是语音
除了这个是相反的之外还有另外一个也是相反的,我们还是来看一下这个NR系统,之前讲ASR的时候也有讲到过,策略后面会有一个TTS的分支、现在TTS较我的应用场景会在一些IWR系统的语音提示、导航,有声朗读这些场景。
ASR的模型识别的是所有说普通话的语音,他不对人做区别,而TTS是反过来的,TTS是一个千人千面的东西,每一个人的声音就跟我们的指纹一样,它都是有自己特点的,什么决定了一个TS最基础的东西,就像人的基因一样,如果你选择了一个声优,你选择了一个他的录音方式,比如说你把自己当成客服把这些话念一遍,或者你把自己当成小学语文老师在教学生,把这个课本念一遍,当这些东西确定了之后,我们采集的录音生成的TTS模型他就不再具有可变性了。
2、 智能语音分享-语音识别ASR—玉环
- ASR
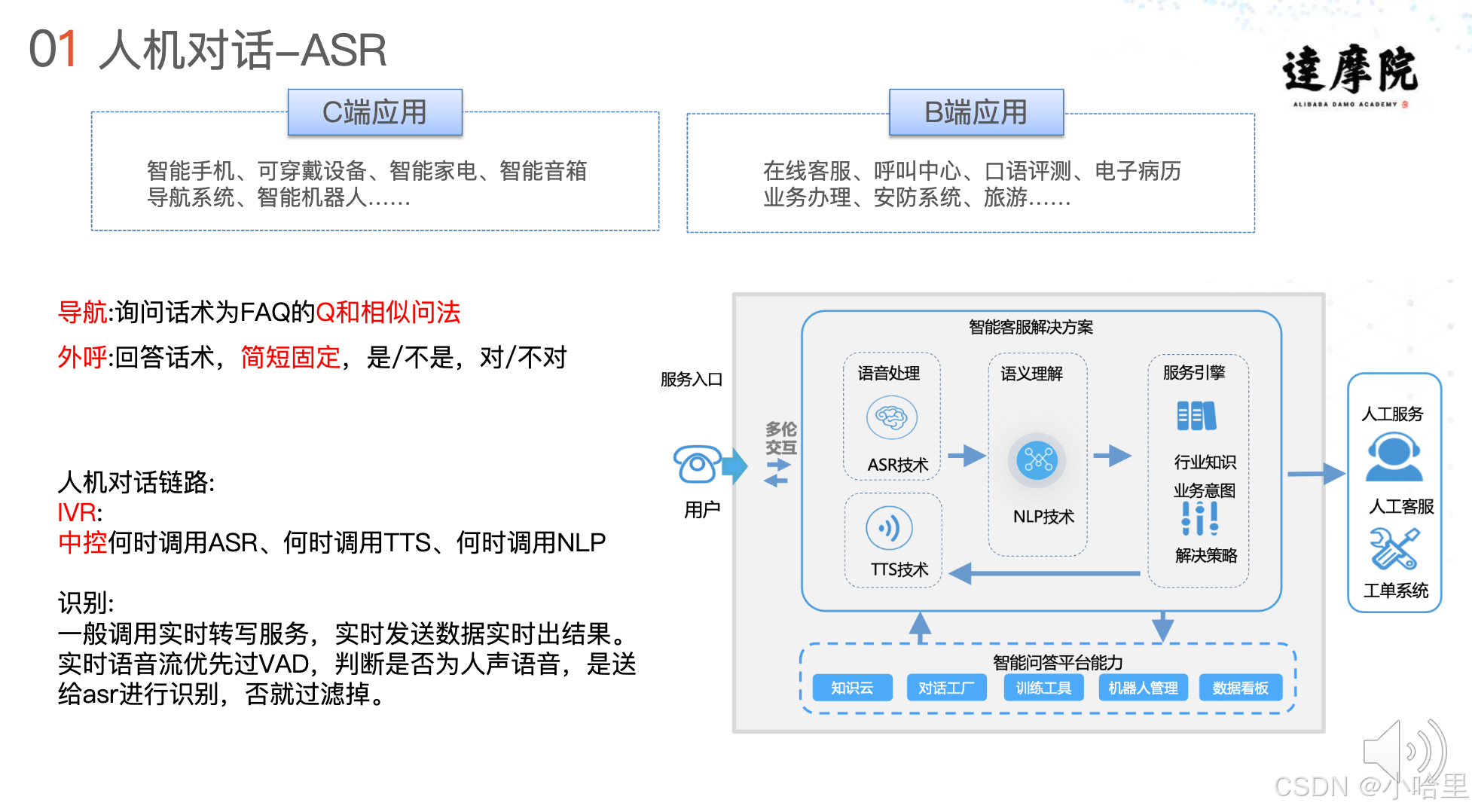
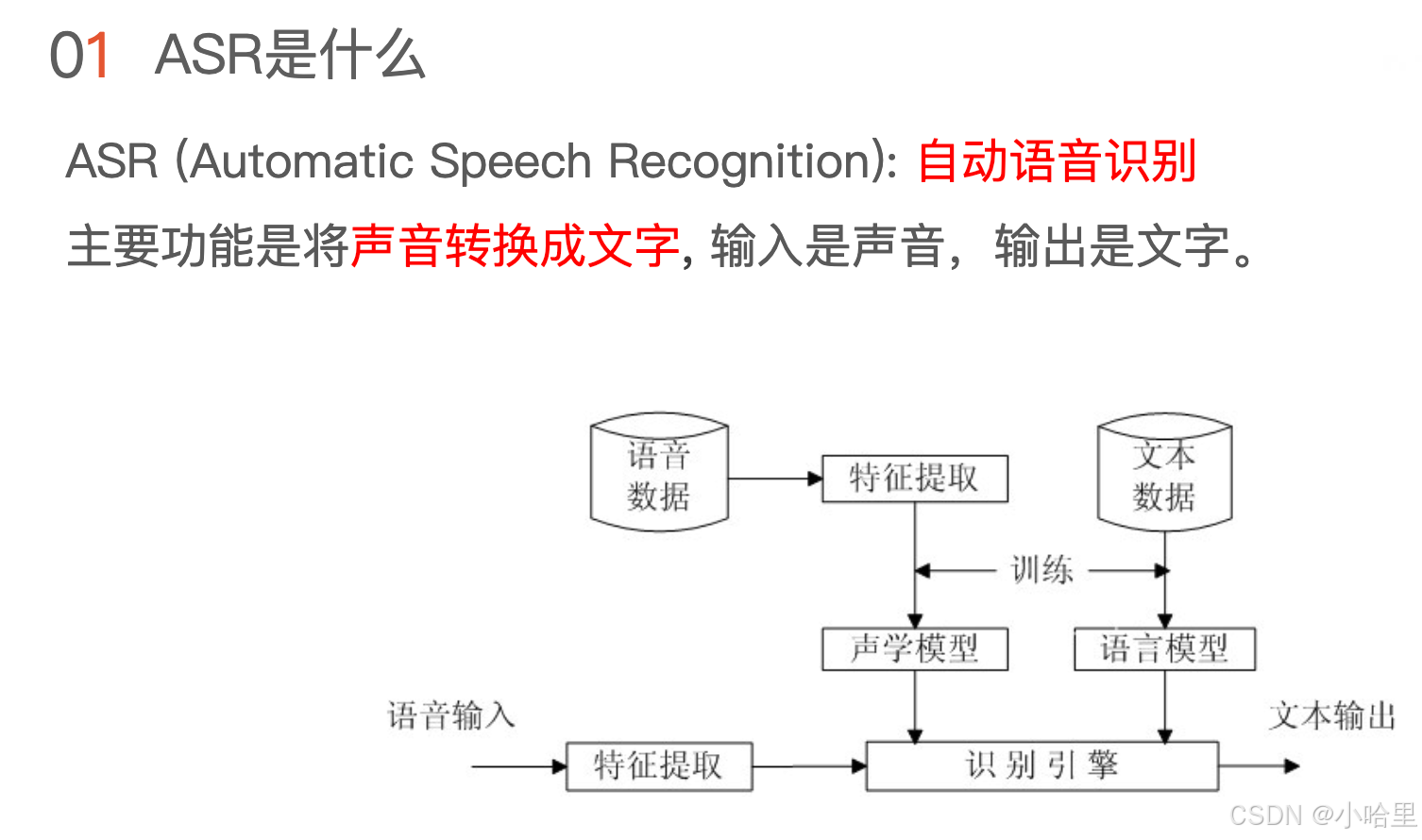
- ASR模型系统有两部分
声学模型(acoustics model,简称am)和语言模型(language model,简称lm)
这两部分从字面上也可以理解:
1)声学模型:的声学指的是我们听到的声音,发的是什么样的音,例如是"ni"的音还是"wo"的音等等
例如(以拼音表示为例):wo shi yi ge xiao xue sheng(“我是一个小学生”的声音)
2)语言模型:的语言可以理解为一个句子(上下文)的通顺度,语义是否完整或者是否能够理解
例如:我试一个晓雪升/我是一个小学生
3、文本生成的原理与应用—时生
-
文本生成,一般是怎么做的
概率统计–基于统计的语言生成
无脑黑盒·–基于神经网络的语言生成
有迹可循–依据规划的语言生成
理解常识–融合知识的语言生成 -
有哪些常见的任务
机器翻译
文本摘要
故事生成
对话生成
多模态生成 -
怎么衡量生成的好坏–自动化
BLEU: 精准率,生成的ngrams有多少是对的
ROUGE: 召回率,生成的ngrams有多少是参考答案想要的
METEOR: 精准率&召回率
Distinct: 语言多样性,生成的不同ngrams占所有ngrams的比例
Self-BLEU: 语言多样性,生成句之间BLEU相似度
PPL(困惑度): 语言有序性,与语言模型生成概率的熵成正相关,增困惑度增,越无序;熵减困惑度减,越有序
4、意图识别和分类算法—桂月
-
算法工程师
-
智能客服训练系统
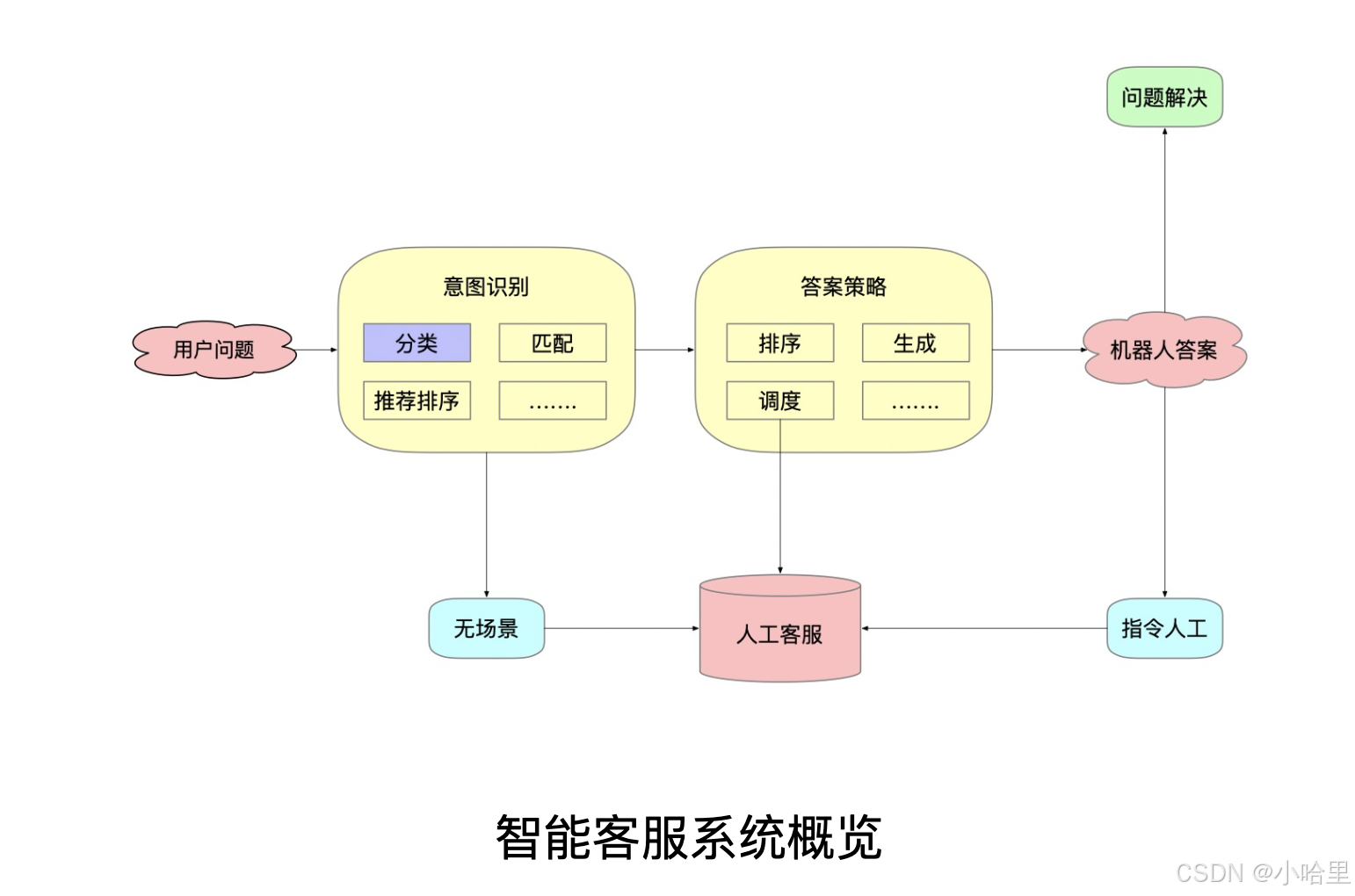
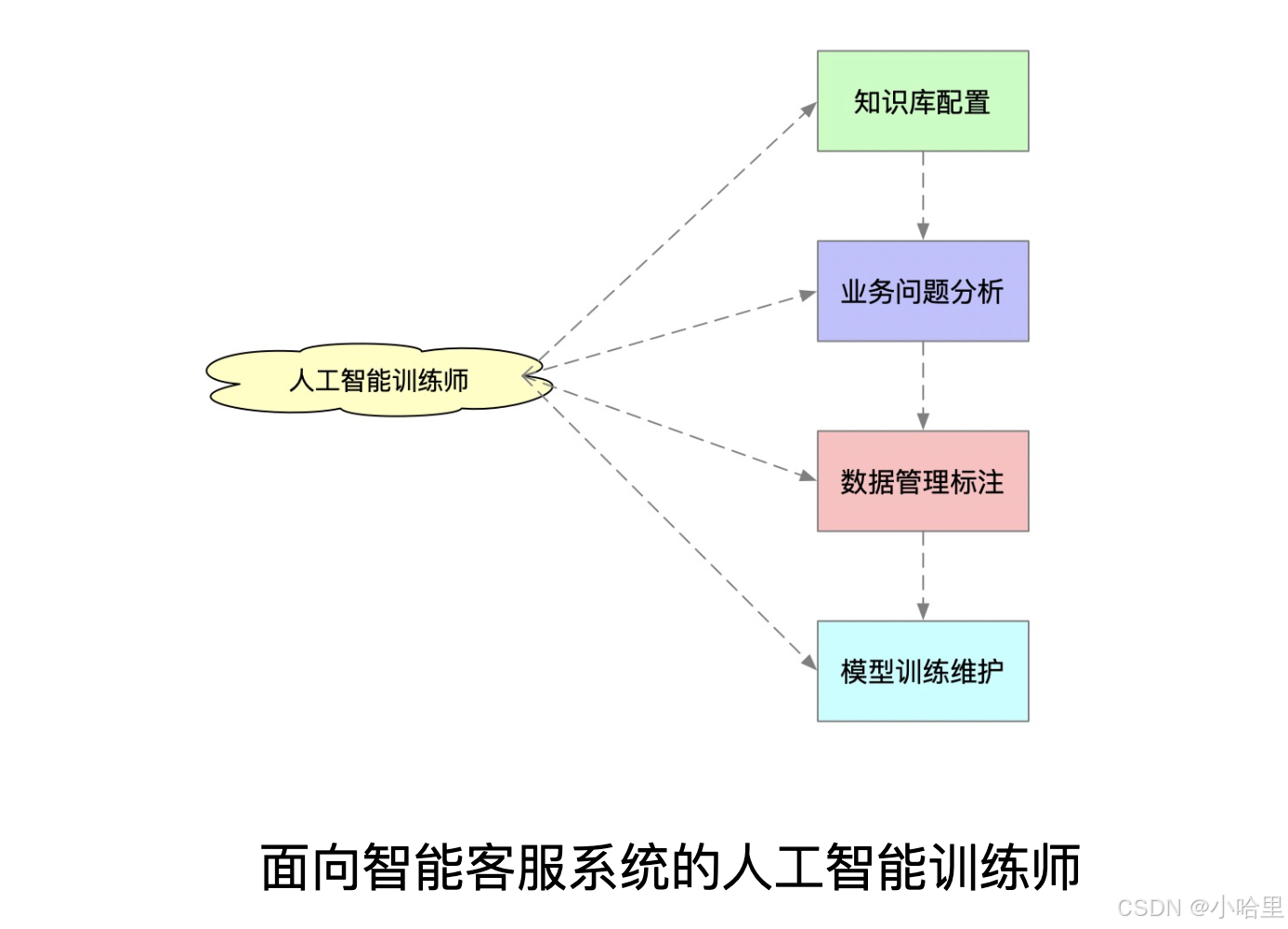
-
1、规则与算法模型适用场景
规则适合场景:逻辑清晰、边界明确的简单任务,如电商满减、银行年龄限制;需强解释性的场景,像医疗诊断标准;数据量少或对实时性要求高的场景,如设备实时报警。
算法模型适合场景:处理复杂、非线性关系问题,如金融诈骗检测;应对动态变化的业务,如推荐系统;在数据丰富且追求高精度的场景中,如自动驾驶、精准营销。 -
2、分类模型训练数据量影响因素
问题复杂度:类别越多、问题越复杂,所需数据量越大。
特征维度:特征数量增加,数据量需指数级增长以避免维度灾难。
模型复杂度:复杂模型参数多,需大量数据防止过拟合。
数据质量:低质量数据需更多样本降低噪音影响。
业务容错:容错成本低的业务可用较少数据,反之则需大量数据保障准确性。 -
3、意图识别模型需要负向样本的原因
负向样本用于明确意图边界,避免模型将无关问题误判为目标意图;平衡样本分布,防止模型偏向多数类;提升模型泛化能力,使其能区分相似但不同的问题。
若缺乏负向样本,模型会过度泛化,准确率降低,易将包含部分关键词的问题误判;难以识别新意图,遇到未见过的负向意图容易出错;还会加剧样本失衡问题,导致模型预测失去实际价值 。
3、题库
3.1 单选题
一、单选题(每题3分)
- 以下说法正确的是
- A. 质量更高的数据可以训练出更好的模型
- B. 同一模型中训练数据的样本需要有一定的平衡
- C. 训练样本中的数据标签的正确性会影响到模型的准确率
- D. 以上都对
答案:D
解析:A、B、C选项分别从数据质量、样本平衡、标签正确性角度说明其对模型的影响,均正确。
- 关于方言和重口音模型的构建,错误的是
- A. 方言模型需从底层词典建设开始
- B. 重口音问题可通过加强声学模型训练改善
- C. 方言和重口音的优化方式不同
- D. 方言问题仅通过优化声学模型即可解决
答案:D
解析:方言涉及词汇、语法等多层面,仅优化声学模型无法完全解决。
- 如何提升数据的质量
- A. 没有噪音数据
- B. 训练数据样本平衡
- C. 负向样本充足,种类丰富
- D. 以上都是
答案:D
- TTS中通常把数字变成汉字是发生在哪个模块
- A. 文本归整模块
- B. 停顿模型
- C. 获取读音
- D. 分句模块
答案:A
- 模型的召回率如何计算
- A. RECALL = TP TP+FN \text{RECALL} = \frac{\text{TP}}{\text{TP+FN}} RECALL=TP+FNTP
- B. RECALL = TP TP+FP \text{RECALL} = \frac{\text{TP}}{\text{TP+FP}} RECALL=TP+FPTP
- C. RECALL = TP+TN TP+FP \text{RECALL} = \frac{\text{TP+TN}}{\text{TP+FP}} RECALL=TP+FPTP+TN
- D. RECALL = TP+TN TP+FP+TN \text{RECALL} = \frac{\text{TP+TN}}{\text{TP+FP+TN}} RECALL=TP+FP+TNTP+TN
答案:A
- 通过SSML标记() 文本内容,可以控制() 语音生成的许多方面
- A. 标准,简单
- B. 标准,复杂
- C. 格式化,合成
- D. 通用性,合成
答案:C
- 以下哪些场景适用分类模型解决
- A. 开发票流程
- B. 反馈电话号码
- C. 反馈订单编号
- D. 发送宝贝链接
答案:A
- 计算字准确率:标注“我最喜欢的运动是排球”,识别“吾最喜爱的运动是拍球哦”
- A. 0.6
- B. 0.4
- C. 0.7
- D. 0.3
答案:A
解析:总字数10,错误数4(3处替换+1处插入),CER=40%,准确率=60%。
- 找出标签分类不一致的句子
- A. 我忘记蜜码了
- B. 输了好多次都提示密码错误
- C. 为什么总是提示密码错误
- D. 如何设置密码
答案:D
解析:D为“密码设置”,其他为“密码使用问题”。
- 书箱分类的标签属于哪种分类任务
- A. 二分类
- B. 多分类
- C. 多标签分类
- D. 多模态
答案:C
- 总数据量10,有结果6条(正确5条),准确率和精准率
- A. 准确率50%,精确率83.3%
- B. 准确率83.3%,精确率50%
- C. 准确率50%,精确率50%
- D. 准确率83.3%,精确率83.3%
答案:A
- 属于多标签分类的是
- A. 垃圾邮件判别(是/否)
- B. 情绪识别(愤怒/高兴/平静)
- C. 新闻主题标签(体育,C罗,欧冠)
- D. 以上都是
答案:C
- 构建数据标签正确的是
- A. 只保证正例正确
- B. 不需要负例样本
- C. 需考虑业务属性和行业知识
- D. 标签范围越小越好
答案:C
- “南京市长江大桥”正确分词
- A. 南京/市长/江大桥
- B. 南京市/长江大桥
- C. 南京/市/长江/大桥
- D. 南京/市/长江/大/桥
答案:B
- 文本正则归整结果:“小男孩2岁了, 第1次和奶奶一起旅行”
- A. 小男孩两岁了,第一次和奶奶一起旅行
- B. 小男孩二岁了,第一次和奶奶一起旅行
- C. 小男孩2岁了,第1次和奶奶1起旅行
- D. 小男孩两岁了,第1次和奶奶一起旅行
答案:A
- 数据优化正确的是
- A. 数据量越多越好
- B. 数据质量越高对模型效果越好
- C. 数据类型越丰富越好
- D. 正负样本量不影响模型效果
答案:B
- 实际语音有、识别结果有但字错误,属于
- A. 插入错误
- B. 删除错误
- C. 替换错误
- D. 识别错误
答案:C
- TTS流程中易造成读音错误的模块
- A. 分词模型
- B. 停顿模型
- C. 获取读音
- D. 分句模块
答案:C
- CER字错误率超过100%的情况
- A. 删除错误较多
- B. 插入错误较多
- C. 替换错误较多
- D. 以上都对
答案:B
- 标签与文本最相关的是
- A. 账户登录不上了→账户被盗
- B. 怎么还不回复我→催促
- C. 怎么恢复聊天记录→恢复钉钉内容
- D. 怎么开发票呀→开票流程
答案:D
3.2 判断题
二、判断题(每题2分)
- 用户画像是多标签分类
- 答案:A. 正确
- 声音转文字未达100%说明模型不行
- 答案:B. 错误
- SSML是W3C语音接口框架的一部分
- 答案:A. 正确
- 文本生成的随机性风险可控
- 答案:B. 错误
- 调整speech_rate可改变TTS语速
- 答案:A. 正确
- 分类任务包括二分类、多分类、多标签分类
- 答案:A. 正确
- 数据标记只能添加一个标签
- 答案:B. 错误
- 删除错误是实际语音有、识别结果无
- 答案:A. 正确
- ASR不区分说话人,TTS可模拟不同声音
- 答案:A. 正确
- 召回率衡量检索系统的查全率
- 答案:A. 正确
3.3 多选题
三、多选题(每题5分)
- TTS常见错误
- A. 拼写错误
- B. 识别错误
- C. 读音错误
- D. 停顿错误
答案:CD
- 建立语音评测集的要求
- A. 1-2小时有效数据
- B. 反映业务真实数据
- C. 只需要语音内容
- D. 数据具随机性和代表性
答案:ABD
- 提升数据质量的方法
- A. 类间边界清晰
- B. 子项与父项共存
- C. 类别数据量悬殊
- D. 正负样本丰富
答案:AD
- 无噪音数据
- A. …(内容缺失)
- B. 好了哦
- C. 去火车站怎么走
- D. 今天天气怎么样
答案:CD
参考资料:1, 2, 3, 4, 5,6, 7 asr, 8 数字人