分词算法总结:不同分词算法的优点和缺点
一、Tokenizer的作用
- 将文本序列转化为数字序列(token编号),作为transformer的输入
- 是训练、微调、推理的LLM的一部分
简单的输入文本:“Some, words are input?”
分割结果:["Some", "," "words ", "are ", "input", "?"]
转成token_id:[121, 694, ..., ...]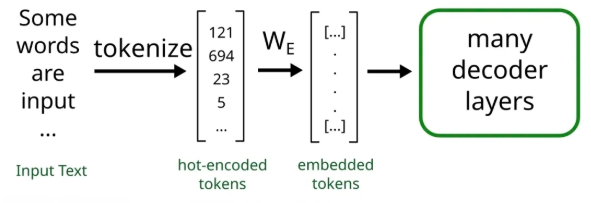
具体的详细实践可以看我前面的两篇博客:分词算法BBPE详解和Qwen的应用_bbpe 训练-CSDN博客
分词算法BPE详解和CLIP的应用-CSDN博客
二、word-based Tokenizers
简单描述:将文本划分为一个一个的词(包括标点)

优点:
- 符合人的自然语言和直觉,词粒度能保留更多的语义信息
- 序列划分后词元数量更短,处理起来更高效;;
缺点:
-
按词为粒度进行划分,会导致词典庞大;
-
词汇是不断扩张的,对于新产生的不在词典里的词,会带来OOV问题(未知的词用特殊的token表示,丢失了关键信息,直接对模型性能造成影响);
-
稀疏词、低频词无法在训练时有充分的语料进行训练;
-
难以学习到同一个词的不同形态,比如英文中的look和looks,按词划分的话需要对这两个分别进行训练,但显然没这个必要;
三、Character-based Tokenizers
简单描述:将文本划分为一个一个的字符

优点:
- 可以表示任意(英文)文本,不会出现word-based中的unknow情况
- 词表很小,比如英文只需要不到256个字符
缺点:
- 相对word-based来说信息量非常低,导致模型性能很差
- 相对于word-based来说,会产生很长的token_id序列
- 中文也需要一个很大的词表
四、Subword-based Tokenizer
具体见我上面两篇博客:BPE和BBPE算法,还包括WordPiece Tokenization和Unigram Tokenization(本文就不详细介绍分词算法细节)
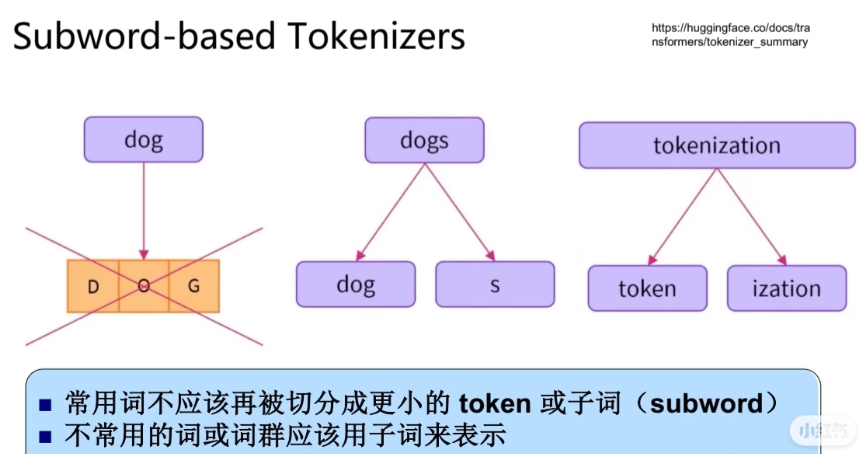
简单描述:
- 常用词不应该切分成更小的token或者subword
- 不常用词或者词群应该用字词来表示
优点:
- 使用subword划分英文词群,既能够保留充分的语义,也能够做到相对的高效和词表小
- 也能够尽量避免OOV问题(BPE依旧存在,BBPE解决了OOV问题)
怎么训练的?
- 初始化:将语料库中的单词分解为字符序列,末尾加上特殊符号表示词的计数
- 统计相邻符号的频率
- 合并频率最高的符号对
- 重复1-3步骤,直至满足达到预设的词汇表的大小
五、结论
基本上现在的GPT、LLama、Qwen、InternVL应该都采用了sub-word的算法(从开源的paper或者代码中找到,但是闭源的就不太清楚了),还有一些基于sentence的库的sub-word算法实现,此处就不详细介绍了
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.dtcms.com/a/238696.html
如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!