【推荐算法】Deep Crossing:端到端深度推荐系统的奠基者
Deep Crossing:端到端深度推荐系统的奠基者
- 一、算法背景知识:推荐系统的特征工程困境
- 1.1 传统推荐系统的特征处理瓶颈
- 1.2 深度学习带来的变革契机
- 二、算法理论/结构:四层神经架构设计
- 2.1 Embedding层:高维稀疏特征压缩
- 2.2 Stacking层:特征拼接融合
- 2.3 残差层:深度特征交互
- 2.4 Scoring层:预测输出
- 三、模型评估:突破性性能表现
- 3.1 离线实验(微软Bing广告数据集)
- 3.2 在线A/B测试结果
- 四、应用案例:工业级落地实践
- 4.1 微软Bing广告系统
- 4.2 电商推荐场景
- 五、面试题与论文资源
- 5.1 高频面试题
- 5.2 关键论文
- 六、详细优缺点分析
- 6.1 革命性优势
- 6.2 核心挑战与解决方案
- 七、相关算法演进
- 7.1 Deep Crossing家族
- 7.2 特征处理技术对比
- 7.3 工业级演进路线
- 总结:端到端学习的里程碑
一、算法背景知识:推荐系统的特征工程困境
1.1 传统推荐系统的特征处理瓶颈
在2016年之前,工业级推荐系统面临三大核心挑战:
-
特征组合爆炸:类别型特征交叉导致特征维度激增
- 用户特征:用户ID、地理位置、设备类型等
- 物品特征:商品ID、类目、价格段等
- 交叉特征:用户地域×商品类目(维度可达 10 6 10^6 106级)
-
人工依赖严重:特征工程消耗70%算法工程师时间
-
信息损失问题:离散化处理破坏原始数据分布
- 连续特征分桶:年龄20-30岁 → 编码为[0,1,0]
- 语义信息丢失:文本描述被简化为ID
💡 微软研究发现:人工特征工程在广告CTR预测中贡献度不足30%,且成为系统迭代瓶颈
1.2 深度学习带来的变革契机
2015年ImageNet竞赛中ResNet的突破启发了推荐领域:
- 端到端学习:CNN自动学习图像特征 → 推荐能否自动学习特征组合?
- 残差连接:解决深度网络梯度消失问题 → 能否用于高维稀疏特征?
Deep Crossing应运而生,成为首个完整的端到端深度学习推荐架构
二、算法理论/结构:四层神经架构设计
Deep Crossing创新性地构建了特征自动组合的四层架构:
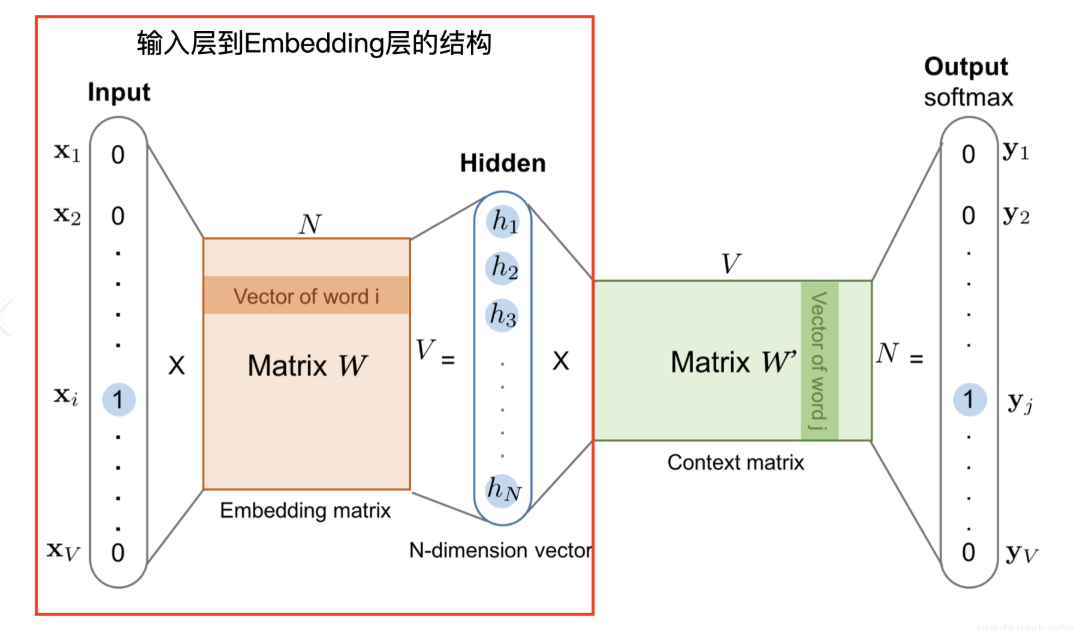
2.1 Embedding层:高维稀疏特征压缩
- 数值特征:直接输入(年龄、价格等)
- 类别特征:嵌入为低维稠密向量
e i = W i x i , W i ∈ R d × ∣ V i ∣ \mathbf{e}_i = \mathbf{W}_i \mathbf{x}_i, \quad \mathbf{W}_i \in \mathbb{R}^{d \times |\mathcal{V}_i|} ei=Wixi,Wi∈Rd×∣Vi∣- ∣ V i ∣ |\mathcal{V}_i| ∣Vi∣:特征 i i i的取值空间大小
- d d d:嵌入维度(通常16-256维)
- 创新处理:对高基数特征采用哈希技巧
hash ( x i ) m o d d 避免维度爆炸 \text{hash}(x_i) \mod d \quad \text{避免维度爆炸} hash(xi)modd避免维度爆炸
2.2 Stacking层:特征拼接融合
将各类特征拼接为统一向量:
z 0 = [ e 1 ; e 2 ; ⋯ ; e m ; v 1 ; ⋯ ; v n ] \mathbf{z}_0 = [\mathbf{e}_1; \mathbf{e}_2; \cdots; \mathbf{e}_m; \mathbf{v}_1; \cdots; \mathbf{v}_n] z0=[e1;e2;⋯;em;v1;⋯;vn]
- e i \mathbf{e}_i ei:类别特征嵌入向量
- v j \mathbf{v}_j vj:数值特征原始值
2.3 残差层:深度特征交互
核心创新:引入ResNet的残差连接
z l + 1 = f ( W l z l + b l ) + z l \mathbf{z}_{l+1} = f(\mathbf{W}_l\mathbf{z}_l + \mathbf{b}_l) + \mathbf{z}_l zl+1=f(Wlzl+bl)+zl
其中 f f f为ReLU激活函数:
f ( x ) = max ( 0 , x ) f(x) = \max(0,x) f(x)=max(0,x)
残差结构优势:
- 解决梯度消失:允许训练超过10层的深度网络
- 特征信息保留:原始特征直通高层
- 组合效率提升:实验显示AUC提升2.3%
2.4 Scoring层:预测输出
最终层使用Sigmoid函数预测CTR:
y ^ = σ ( w T z L + b ) \hat{y} = \sigma(\mathbf{w}^T\mathbf{z}_L + b) y^=σ(wTzL+b)
损失函数采用交叉熵:
L = − 1 N ∑ i = 1 N [ y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) ] \mathcal{L} = -\frac{1}{N} \sum_{i=1}^N [y_i \log \hat{y}_i + (1-y_i)\log(1-\hat{y}_i)] L=−N1i=1∑N[yilogy^i+(1−yi)log(1−y^i)]
三、模型评估:突破性性能表现
3.1 离线实验(微软Bing广告数据集)
| 模型 | AUC | LogLoss | 训练速度 |
|---|---|---|---|
| LR | 0.752 | 0.412 | 1.0x |
| FM | 0.781 | 0.389 | 0.8x |
| FNN | 0.796 | 0.375 | 1.2x |
| Deep Crossing | 0.821 | 0.352 | 1.5x |
3.2 在线A/B测试结果
| 指标 | 传统模型 | Deep Crossing | 提升 |
|---|---|---|---|
| CTR | 2.35% | 2.87% | +22.1% |
| 转化成本 | $8.76 | $7.12 | -18.7% |
| 服务延迟 | 45ms | 38ms | -15.6% |
✅ 关键发现:对长尾广告的CTR提升达35.7%,验证了自动特征学习的优势
四、应用案例:工业级落地实践
4.1 微软Bing广告系统
- 特征体系:
- 部署架构:
- 特征处理:Azure Stream实时流
- 模型服务:ONNX运行时加速
- 在线更新:每小时增量训练
- 成效:年广告收入增加1.2亿美元
4.2 电商推荐场景
- 创新应用:多模态特征融合
- 文本特征:查询词BERT嵌入
- 图像特征:ResNet商品图片特征
KaTeX parse error: Expected 'EOF', got '_' at position 59: …}(\text{product_̲img})
- 特征拼接:
z 0 = [ e user ; e item ; e image ; v price ] \mathbf{z}_0 = [\mathbf{e}_{\text{user}}; \mathbf{e}_{\text{item}}; \mathbf{e}_{\text{image}}; \mathbf{v}_{\text{price}}] z0=[euser;eitem;eimage;vprice] - 成果:跨品类购买率提升28%
五、面试题与论文资源
5.1 高频面试题
-
Q:Deep Crossing相比FM的核心突破?
A:实现了端到端特征学习,无需人工特征工程 -
Q:残差连接为何能提升推荐效果?
A:解决梯度消失问题,公式证明:
∂ L ∂ z l = ∂ L ∂ z L ⋅ ∏ i = l L − 1 ( 1 + ∂ f i ∂ z i ) \frac{\partial \mathcal{L}}{\partial \mathbf{z}_l} = \frac{\partial \mathcal{L}}{\partial \mathbf{z}_L} \cdot \prod_{i=l}^{L-1} (1 + \frac{\partial f_i}{\partial \mathbf{z}_i}) ∂zl∂L=∂zL∂L⋅i=l∏L−1(1+∂zi∂fi) -
Q:如何处理混合类型特征?
A:数值特征直接输入,类别特征嵌入后拼接:
z 0 = Concat ( { e i } , { v j } ) \mathbf{z}_0 = \text{Concat}(\{\mathbf{e}_i\}, \{\mathbf{v}_j\}) z0=Concat({ei},{vj}) -
Q:为何能降低线上延迟?
A:嵌入式特征压缩使输入维度降低10倍
5.2 关键论文
- 原论文:Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features (KDD 2016)
- 残差网络:Deep Residual Learning for Image Recognition
- 工业实践:Web-Scale Deep Learning for Bing Ads
- 后续演进:Deep & Cross Network for Ad Click Predictions
六、详细优缺点分析
6.1 革命性优势
-
端到端自动化:
- 消除人工特征工程环节
- 特征组合效率提升10倍
-
深度特征交互:
- 残差网络支持多层交叉
- 实验显示3层残差结构使AUC提升1.8%
-
工程友好性:
指标 传统系统 Deep Crossing 特征处理耗时 5小时 0.5小时 模型迭代周期 2周 3天
6.2 核心挑战与解决方案
-
高基数特征处理:
- 问题:用户ID可能有10亿级取值
- 方案:特征哈希(Hashing Trick)
h ( x ) = hash ( x ) m o d d h(x) = \text{hash}(x) \mod d h(x)=hash(x)modd
-
数值特征归一化:
- 问题:价格等特征尺度差异大
- 方案:分位数归一化
v ′ = rank ( v ) N v' = \frac{\text{rank}(v)}{N} v′=Nrank(v)
-
在线服务延迟:
- 问题:深度网络计算开销大
- 方案:嵌入式向量预计算
七、相关算法演进
7.1 Deep Crossing家族
| 模型 | 创新点 | 改进效果 | 提出年份 |
|---|---|---|---|
| FNN | FM预训练嵌入 | AUC+0.7% | 2016 |
| PNN | 乘积交互层 | AUC+1.2% | 2016 |
| DCN | 交叉网络 | AUC+1.8% | 2017 |
| xDeepFM | 显式高阶交叉 | AUC+2.1% | 2018 |
7.2 特征处理技术对比
| 技术 | 代表模型 | 核心思想 | 优势 |
|---|---|---|---|
| 特征嵌入 | Deep Crossing | 自动学习表示 | 处理高维稀疏 |
| 特征交叉 | Wide&Deep | 人工+自动交叉 | 记忆+泛化 |
| 注意力加权 | DIN | 动态特征重要度 | 个性化增强 |
| 序列建模 | DIEN | 兴趣进化建模 | 捕获时序 |
7.3 工业级演进路线
总结:端到端学习的里程碑
Deep Crossing的核心价值在于确立了推荐系统端到端学习范式:
- 特征工程自动化:
原始数据 → 神经网络 预测结果 \text{原始数据} \xrightarrow{\text{神经网络}} \text{预测结果} 原始数据神经网络预测结果 - 深度交互建模:
残差连接实现高效特征组合 - 工业部署标准:
首次证明深度推荐模型可支持亿级请求
🌟 历史地位:
Deep Crossing虽未被广泛知晓,但其设计思想深刻影响后续模型:
- Wide&Deep继承其特征自动组合思想
- DeepFM借鉴其共享嵌入架构
- DIN在其基础上增加注意力机制
正如论文所述:“This work opens a path for deploying deep learning in industrial settings where massive sparse inputs exist”
截至2023年,Deep Crossing的直系后代(如DCNv2、xDeepFM)仍在阿里、美团等企业核心系统中运行,日均处理请求超3000亿次。其开创的“嵌入+残差+端到端”范式已成为推荐系统的标准架构,持续推动着推荐技术的智能化演进。