LLMs之RLVR:《Absolute Zero: Reinforced Self-play Reasoning with Zero Data》翻译与解读
LLMs之RLVR:《Absolute Zero: Reinforced Self-play Reasoning with Zero Data》翻译与解读
导读:Absolute Zero范式通过让模型在没有外部数据的情况下,自主提出和解决任务,实现了推理能力的显著提升。Absolute Zero Reasoner (AZR) 作为该范式的一个具体实现,在代码和数学推理任务上取得了优异的成绩,展示了通过自我博弈和环境交互实现模型自我进化的巨大潜力。该研究为未来的AI推理模型发展提供了一个全新的方向,即摆脱对人工标注数据的依赖,探索更广阔的自我学习空间。
>> 背景痛点:
● 人工监督的局限性:
●● 人工标注成本高昂: 随着推理模型能力的提升,构建大规模高质量数据集所需的成本变得越来越难以承受。
●● 人类智能的限制: 当AI系统超越人类智能时,依赖人类设计的任务可能会限制其自主学习和增长的能力。
● 现有RLVR方法的不足:依赖专家知识。现有的可验证奖励强化学习(RLVR)方法仍然依赖于人工策划的推理问题-答案对,这限制了其长期可扩展性。
>> 具体的解决方案:
● Absolute Zero范式:
●● 自博弈学习: 模型同时学习定义最大化自身学习进度的任务,并通过解决这些任务来提高推理能力,无需任何外部数据。
●● 环境反馈: 依赖于来自环境的可验证反馈作为奖励来源,促进开放式但有实际依据的学习。
● Absolute Zero Reasoner (AZR):
●● 统一模型: 使用单一LLM作为任务的提出者和解决者。
●● 三种推理模式: 通过三种不同类型的编码任务进行学习,分别对应于归纳、演绎和溯因三种基本的推理模式。
●● 代码执行器: 将代码执行器用作开放式但有实际依据的环境,以验证任务的完整性并提供可验证的反馈。
●● 多任务学习: 采用专门为多任务学习设计的新型强化学习优势估计器进行模型更新。
>> 核心思路步骤:
● 任务提出: 模型(πpropose)根据变量z提出任务τ。
● 任务验证: 环境(e)验证任务τ,构建有效的推理任务(x, y⋆),并给出可学习性奖励rpropose。
● 任务解决: 模型(πsolve)解决任务x,得到答案y,并从环境获得奖励rsolve。
● 联合训练: 联合训练πpropose和πsolve,通过最大化目标函数J(θ)来优化模型参数θ。
● 循环迭代: 不断重复上述过程,实现模型的自我进化和能力提升。
>> 优势:
● 无需外部数据: 模型完全通过自我博弈和与环境的交互进行学习,无需任何人工标注或外部数据集。
● 卓越的性能: 在编码和数学推理任务上实现了最先进的性能,超越了依赖于大量人工标注数据的现有模型。
● 跨领域泛化: 在代码环境中训练的模型在数学任务上表现出更强的泛化能力。
● 可扩展性: 性能随着模型规模的增加而提升。
● 涌现行为: 模型在训练过程中自然涌现出中间计划(如ReAct提示框架)和认知行为(如逐步推理、枚举和试错)。
>> 结论和观点:
● 代码先验知识的重要性: 具有更强编码能力的模型在经过AZR训练后,整体推理能力提升更为显著。
● 探索学习任务空间: AI推理智能体可以从动态定义和改进自己的学习任务中受益,这为未来的研究开辟了一个有希望的新方向。
● 安全性问题: 在使用Llama-3.1-8B模型进行AZR训练时,观察到了一些令人担忧的思维链,这突出了未来工作中对安全意识训练的需求。
● 环境多样性: 建议探索更多样化的环境,例如万维网、形式化数学语言、世界模拟器,甚至是现实世界,以提供可验证的反馈。
● 多模态推理: 未来的研究可以探索多模态推理模型,并设计探索/多样性奖励来进一步提升模型性能。
目录
《Absolute Zero: Reinforced Self-play Reasoning with Zero Data》翻译与解读
Abstract
Figure 1:Absolute Zero Reasoner (AZR) achieves state-of-the-art performance with ZERO DATA. Without relying on any gold labels or human-defined queries, Absolute Zero Reasoner trained using our proposed self-play approach demonstrates impressive general reasoning capabilities improvements in both math and coding, despite operating entirely out-of-distribution. Remarkably, AZR surpasses models trained on tens of thousands of expert-labeled in-domain examples in the combined average score across both domains.图 1:绝对零度推理器(AZR)在零数据的情况下达到了最先进的性能。无需依赖任何人工标注的黄金标签或人为定义的查询,通过我们提出的自对弈方法训练的绝对零度推理器在数学和编程领域均展现出令人瞩目的通用推理能力提升,尽管其完全是在分布外进行操作。值得注意的是,AZR 在两个领域的综合平均得分上超过了那些基于数万个专家标注的领域内示例训练出来的模型。
Figure 2:Absolute Zero Paradigm. Supervised learning relies on human-curated reasoning traces for behavior cloning. Reinforcement learning from verified rewards, enables agents to self-learn reasoning, but still depends on expert-defined learning distribution and a respective set of curated QA pairs, demanding domain expertise and manual effort. In contrast, we introduce a new paradigm, Absolute Zero, for training reasoning models without any human-curated data. We envision that the agent should autonomously propose tasks optimized for learnability and learn how to solve them using an unified model. The agent learns by interacting with an environment that provides verifiable feedback, enabling reliable and continuous self-improvement entirely without human intervention.图 2:绝对零度范式。监督学习依赖于人工整理的推理轨迹来进行行为克隆。强化学习从经过验证的奖励中学习,使智能体能够自主学习推理,但仍依赖于专家定义的学习分布以及相应的一组人工整理的问答对,这需要领域专业知识和人工努力。相比之下,我们引入了一种新的范式——绝对零度,用于在没有任何人工整理数据的情况下训练推理模型。我们设想智能体应自主提出针对可学习性进行优化的任务,并学习使用统一模型解决这些任务。智能体通过与提供可验证反馈的环境进行交互来学习,从而在完全无需人工干预的情况下实现可靠且持续的自我改进。
1、Introduction
6、Conclusion and Discussion
《Absolute Zero: Reinforced Self-play Reasoning with Zero Data》翻译与解读
| 地址 | 论文地址:[2505.03335] Absolute Zero: Reinforced Self-play Reasoning with Zero Data |
| 时间 | 2025年5月6日 |
| 作者 | 清华大学,北京通用人工智能研究院,宾夕法尼亚州立大学 |
Abstract
| Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes. | 具有可验证奖励的强化学习(RLVR)通过直接从基于结果的奖励中学习,已展现出增强大型语言模型推理能力的潜力。近期在零样本设置下运行的 RLVR 工作避免了对推理过程进行标注的监督,但仍依赖于人工整理的问题和答案集合进行训练。高质量的人工生成示例稀缺,这引发了对长期依赖人工监督的可扩展性的担忧,这一挑战在语言模型预训练领域已显而易见。此外,在假设未来人工智能超越人类智能的情况下,由人类提供的任务可能对超级智能系统的学习潜力有限。为解决这些担忧,我们提出了一种新的 RLVR 范式,称为绝对零,其中单个模型学会提出能最大化自身学习进度的任务,并通过解决这些任务来改进推理,而无需依赖任何外部数据。在此范式下,我们引入了绝对零度推理器(AZR),这是一个通过使用代码执行器来验证所提出的代码推理任务和答案,从而自我进化其训练课程和推理能力的系统,作为可验证奖励的统一来源,以引导开放但有根据的学习。尽管完全不依赖外部数据进行训练,AZR 在编码和数学推理任务上的整体性能达到了最先进的水平,超过了依赖数万个领域内人工策划示例的现有零样本设置模型。此外,我们证明了 AZR 可以有效地应用于不同规模的模型,并且与各种模型类别兼容。 |
Figure 1:Absolute Zero Reasoner (AZR) achieves state-of-the-art performance with ZERO DATA. Without relying on any gold labels or human-defined queries, Absolute Zero Reasoner trained using our proposed self-play approach demonstrates impressive general reasoning capabilities improvements in both math and coding, despite operating entirely out-of-distribution. Remarkably, AZR surpasses models trained on tens of thousands of expert-labeled in-domain examples in the combined average score across both domains.图 1:绝对零度推理器(AZR)在零数据的情况下达到了最先进的性能。无需依赖任何人工标注的黄金标签或人为定义的查询,通过我们提出的自对弈方法训练的绝对零度推理器在数学和编程领域均展现出令人瞩目的通用推理能力提升,尽管其完全是在分布外进行操作。值得注意的是,AZR 在两个领域的综合平均得分上超过了那些基于数万个专家标注的领域内示例训练出来的模型。
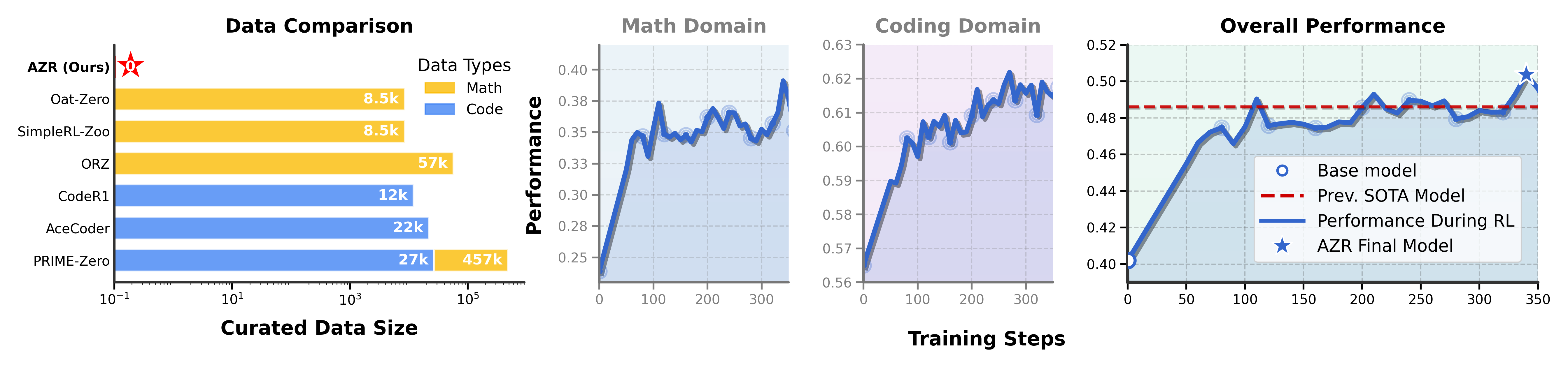
Figure 2:Absolute Zero Paradigm. Supervised learning relies on human-curated reasoning traces for behavior cloning. Reinforcement learning from verified rewards, enables agents to self-learn reasoning, but still depends on expert-defined learning distribution and a respective set of curated QA pairs, demanding domain expertise and manual effort. In contrast, we introduce a new paradigm, Absolute Zero, for training reasoning models without any human-curated data. We envision that the agent should autonomously propose tasks optimized for learnability and learn how to solve them using an unified model. The agent learns by interacting with an environment that provides verifiable feedback, enabling reliable and continuous self-improvement entirely without human intervention.图 2:绝对零度范式。监督学习依赖于人工整理的推理轨迹来进行行为克隆。强化学习从经过验证的奖励中学习,使智能体能够自主学习推理,但仍依赖于专家定义的学习分布以及相应的一组人工整理的问答对,这需要领域专业知识和人工努力。相比之下,我们引入了一种新的范式——绝对零度,用于在没有任何人工整理数据的情况下训练推理模型。我们设想智能体应自主提出针对可学习性进行优化的任务,并学习使用统一模型解决这些任务。智能体通过与提供可验证反馈的环境进行交互来学习,从而在完全无需人工干预的情况下实现可靠且持续的自我改进。

1、Introduction
| Large language models (LLMs) have recently achieved remarkable improvements in reasoning capabilities by employing Reinforcement Learning with Verifiable Rewards (RLVR) (Lambert et al., 2024). Unlike methods that explicitly imitate intermediate reasoning steps, RLVR uses only outcome-based feedback, enabling large-scale reinforcement learning over vast task datasets (DeepSeek-AI et al., 2025; Team et al., 2025; Jaech et al., 2024; OpenAI, 2025b; a). A particularly compelling variant is the “zero” RLVR paradigm (DeepSeek-AI et al., 2025), which forgoes any cold-start distillation data, using neither human-generated nor AI-generated reasoning traces, and applies RLVR directly on the base model with task rewards. However, these methods still depend heavily on expertly curated distributions of reasoning question–answer pairs, which raises serious concerns about their long-term scalability (Villalobos et al., 2024). As reasoning models continue to advance, the effort required to construct large-scale, high-quality datasets may soon become unsustainable (Yue et al., 2025). A similar scalability bottleneck has already been identified in the domain of LLM pretraining (Sutskever et al., 2024). Furthermore, as AI systems continue to evolve and potentially exceed human intellect, an exclusive dependence on human-designed tasks risks imposing constraints on their capacity for autonomous learning and growth (Hughes et al., 2024). This underscores the need for a new paradigm that begins to explore possibilities beyond the constraints of human-designed tasks and prepares for a future in which AI systems may surpass human intelligence. | 大型语言模型(LLMs)最近通过采用可验证奖励的强化学习(RLVR)(Lambert 等人,2024 年)在推理能力方面取得了显著进步。与那些明确模仿中间推理步骤的方法不同,RLVR 仅使用基于结果的反馈,从而能够在大规模任务数据集上进行强化学习(DeepSeek-AI 等人,2025 年;Team 等人,2025 年;Jaech 等人,2024 年;OpenAI,2025 年 b;a)。其中一种特别有吸引力的变体是“零”RLVR 范式(DeepSeek-AI 等人,2025 年),它完全不依赖冷启动蒸馏数据,既不使用人类生成的也不使用 AI 生成的推理轨迹,而是直接在基础模型上应用 RLVR 并给予任务奖励。然而,这些方法仍然严重依赖专家精心策划的推理问答对分布,这引发了对其长期可扩展性的严重担忧(Villalobos 等人,2024 年)。随着推理模型的不断进步,构建大规模高质量数据集所需的努力可能很快就会变得不可持续(Yue 等人,2025 年)。在大型语言模型预训练领域(Sutskever 等人,2024 年),类似的可扩展性瓶颈问题已经显现。此外,随着人工智能系统的不断发展,甚至有可能超越人类智力,过度依赖人类设计的任务可能会限制其自主学习和成长的能力(Hughes 等人,2024 年)。这凸显了需要一种新的范式,开始探索超越人类设计任务限制的可能性,并为人工智能系统可能超越人类智能的未来做好准备。 |
| To this end, we propose “Absolute Zero”, a new paradigm for reasoning models in which the model simultaneously learns to define tasks that maximize learnability and to solve them effectively, enabling self-evolution through self-play without relying on external data. In contrast to prior self-play methods that are limited to narrow domains, fixed functionalities, or learned reward models that are prone to hacking (Silver et al., 2017; Chen et al., 2025; 2024), the Absolute Zero paradigm is designed to operate in open-ended settings while remaining grounded in a real environment. It relies on feedback from the environment as a verifiable source of reward, mirroring how humans learn and reason through interaction with the world, and helps prevent issues such as hacking with neural reward models (Hughes et al., 2024). Similar to AlphaZero (Silver et al., 2017), which improves through self-play, our proposed paradigm requires no human supervision and learns entirely through self-interaction. We believe the Absolute Zero paradigm represents a promising step toward enabling large language models to autonomously achieve superhuman reasoning capabilities. Building on this new reasoning paradigm, we introduce the Absolute Zero Reasoner (AZR), which proposes and solves coding tasks. We cast code executor as an open-ended yet grounded environment, sufficient to both validate task integrity and also provide verifiable feedback for stable training. We let AZR construct three types of coding tasks: infer and reason about one particular element in a program, input, output triplet, which corresponds to three complementary modes of reasoning: induction, abduction, and deduction. We train the entire system end-to-end with a newly proposed reinforcement learning advantage estimator tailored to the multitask nature of the proposed approach. | 为此,我们提出“绝对零度”这一新范式,用于推理模型,该模型能够同时学习定义最大化可学习性的任务,并有效解决这些任务,从而通过自我博弈实现自我进化,无需依赖外部数据。与先前仅限于狭窄领域、固定功能或易受黑客攻击的神经奖励模型的自博弈方法(Silver 等人,2017 年;Chen 等人,2025 年;2024 年)不同,“绝对零度”范式旨在开放环境中运行,同时扎根于真实环境。它依靠来自环境的反馈作为可验证的奖励来源,这与人类通过与世界互动学习和推理的方式相似,并有助于防止诸如神经奖励模型被黑客攻击等问题(Hughes 等人,2024 年)。与通过自我博弈不断改进的 AlphaZero(Silver 等人,2017 年)类似,我们提出的范式无需人类监督,完全通过自我交互进行学习。我们认为,“绝对零度”范式是使大型语言模型能够自主实现超人类推理能力的一个有前景的步骤。基于这一新的推理范式,我们引入了绝对零推理器(AZR),它能够提出并解决编码任务。我们将代码执行器视为一个开放但有依据的环境,足以验证任务的完整性,并提供可验证的反馈以实现稳定训练。我们让 AZR 构建三种类型的编码任务:推断和推理程序、输入、输出三元组中的一个特定元素,这对应于三种互补的推理模式:归纳、溯因和演绎。我们使用一种新提出的强化学习优势估计器对整个系统进行端到端训练,该估计器专为所提出方法的多任务性质而设计。 |
| Despite being trained entirely without any in-distribution data, AZR demonstrates remarkable capabilities across diverse reasoning tasks in math and coding. In mathematics, AZR achieves competitive performance compared to zero reasoner models explicitly fine-tuned with domain-specific supervision. In coding tasks, AZR establishes a new state-of-the-art performance, surpassing models specifically trained with code datasets using RLVR. Furthermore, AZR outperforms all previous models by an average of 1.8 absolute points compared to models trained in the “zero” setting using in-domain data. These surprising results highlight that general reasoning skills can emerge without human-curated domain targeted data, positioning Absolute Zero as an promising research direction and AZR as a first pivotal milestone. Besides the remarkable results AZR achieved with zero human data for reasoning, we also make very interesting findings summarized below: • Code priors amplify reasoning. The base Qwen-Coder-7b model started with math performance 3.6 points lower than Qwen-7b. But after AZR training for both models, the coder variant surpassed the base by 0.7 points, suggesting that strong coding capabilities may potentially amplify overall reasoning improvements after AZR training. • Cross domain transfer is more pronounced for AZR. After RLVR, expert code models raise math accuracy by only 0.65 points on average, whereas AZR-Base-7B and AZR-Coder-7B trained on self-proposed code reasoning tasks improve math average by 10.9 and 15.2, respectively, demonstrating much stronger generalized reasoning capability gains. • Bigger bases yield bigger gains. Performance improvements scale with model size: the 3B, 7B, and 14B coder models gain +5.7, +10.2, and +13.2 points respectively, suggesting continued scaling is advantageous for AZR. • Comments as intermediate plans emerge naturally. When solving code induction tasks, AZR often interleaves step-by-step plans as comments and code (Figure 19), resembling the ReAct prompting framework (Yao et al., 2023). Similar behavior has been observed in much larger formal-math models such as DeepSeek Prover v2 (671B) (Ren et al., 2025). We therefore believe that allowing the model to use intermediate scratch-pads when generating long-form answers may be beneficial in other domains as well. • Cognitive Behaviors and Token length depends on reasoning mode. Distinct cognitive behaviors—such as step-by-step reasoning, enumeration, and trial-and-error all emerged through AZR training, but different behaviors are particularly evident across different types of tasks. Furthermore token counts grow over AZR training, but the magnitude of increase also differs by task types: abduction grows the most because the model performs trial-and-error until output matches, whereas deduction and induction grow modestly. • Safety alarms ringing. We observe AZR with Llama3.1-8b occasionally produces concerning chains of thought, we term the “uh-oh moment”, example shown in Figure 32, highlighting the need for future work on safety-aware training (Zhang et al., 2025a). | 尽管完全在无分布数据的情况下进行训练,AZR 在数学和编码的各种推理任务中都展现出了卓越的能力。在数学方面,AZR 达到了与专门针对特定领域进行微调的零推理器模型相当的性能。在编码任务中,AZR 创立了新的性能标杆,超越了使用 RLVR 专门在代码数据集上训练的模型。此外,与使用领域内数据在“零”设置下训练的所有先前模型相比,AZR 平均高出 1.8 个绝对点。这些令人惊讶的结果表明,通用推理技能可以在没有人工整理的领域定向数据的情况下出现,这将“绝对零度”定位为一个有前景的研究方向,而 AZR 则是这一方向上的首个关键里程碑。除了 AZR 在推理方面无需人类数据就能取得的显著成果外,我们还总结了以下非常有趣的发现: • 代码先验知识能增强推理能力。Qwen-Coder-7b 基础模型在数学性能上比 Qwen-7b 低 3.6 个点。但在 AZR 训练后,编码器变体比基础模型高出 0.7 个点,这表明强大的编码能力可能在 AZR 训练后潜在地放大整体推理能力的提升。 • AZR 的跨领域迁移能力更为显著。经过 RLVR 训练后,专家代码模型在数学准确率上平均仅提高 0.65 个点,而 AZR-Base-7B 和 AZR-Coder-7B 在自我提出的代码推理任务上训练后,数学平均准确率分别提高了 10.9 和 15.2 个点,这表明 AZR 具有更强的通用推理能力提升。• 更大的基础模型带来更大的收益。性能提升与模型规模成正比:30 亿、70 亿和 140 亿参数的编码器模型分别提升了 5.7、10.2 和 13.2 个点,这表明对于 AZR 而言,继续扩大规模是有利的。 • 中间计划以注释形式自然出现。在解决代码归纳任务时,AZR 经常将逐步计划以注释和代码的形式交错出现(图 19),这类似于 ReAct 提示框架(Yao 等人,2023)。在诸如 DeepSeek Prover v2(6710 亿参数)(Ren 等人,2025)这样规模大得多的正式数学模型中也观察到了类似的行为。因此,我们认为在生成长篇答案时允许模型使用中间草稿区可能在其他领域也有益处。 • 认知行为和标记长度取决于推理模式。不同的认知行为——如逐步推理、枚举和试错——都在 AZR 训练过程中自然出现,但不同行为在不同类型的任务中表现得尤为明显。此外,在 AZR 训练过程中,标记数量会增加,但增加的幅度因任务类型而异:演绎推理的标记数量增长最多,因为模型会反复尝试直至输出匹配,而归纳推理的标记数量则增长较少。 • 安全警报响起。我们观察到使用 Llama3.1-8b 的 AZR 有时会产生令人担忧的思维链,我们将其称为“哎呀时刻”,如图 32 所示,这凸显了未来需要开展安全意识训练方面的研究(Zhang 等人,2025a)。 |
6、Conclusion and Discussion
| In this work, we proposed the Absolute Zero paradigm, a novel setting that addresses the data limitations of existing RLVR frameworks. In this paradigm, reasoning agents are tasked with generating their own learning task distributions and improving their reasoning abilities with environmental guidance. We then presented our own instantiation, the Absolute Zero Reasoner (AZR), which is trained by having them propose and solve code-related reasoning tasks grounded by code executor. We evaluated our trained models on out-of-distribution benchmarks in both the code generation and mathematical reasoning domains. Remarkably, even though our models were not directly trained on these tasks and lacked human expert-curated datasets, our reasoning agents achieved exceptional performance, surpassing the state-of-the-art in combined general reasoning scores and in coding. This demonstrates the potential of the absolute zero paradigm to drive superior reasoning capabilities without the need for extensive domain-specific training data. Furthermore, we showed that AZR scales efficiently, offering strong performance across varying model sizes, and can enhance the capabilities of other model classes as well. To foster further exploration and advancement of this emerging paradigm, we are releasing the code, models, and logs as open-source, encouraging the research community to build upon our findings. | 在本研究中,我们提出了绝对零度范式,这是一种新颖的设置,旨在解决现有 RLVR 框架的数据限制问题。在该范式中,推理代理的任务是生成自己的学习任务分布,并在环境引导下提升其推理能力。随后,我们介绍了我们自己的实例化模型——绝对零度推理器(AZR),它通过让代理提出并解决由代码执行器支持的代码相关推理任务来进行训练。 我们在代码生成和数学推理领域的分布外基准上对训练好的模型进行了评估。令人瞩目的是,尽管我们的模型并未直接在这些任务上进行训练,也缺乏由人类专家整理的数据集,但我们的推理代理仍取得了卓越的性能,在综合推理得分和编码方面均超越了现有最佳水平。这表明绝对零度范式具有在无需大量特定领域训练数据的情况下推动更优推理能力的潜力。此外,我们还证明了 AZR 能够高效扩展,在不同规模的模型中均表现出色,并且还能增强其他模型类别的能力。为了促进这一新兴范式的进一步探索和进步,我们将代码、模型和日志作为开源资源发布,鼓励研究社区在我们的发现基础上继续发展。 |
| We believe there remains much to explore, such as altering the environment from which the reasoner receives verifiable feedback, including sources like the world wide web, formal math languages Sutton (2001); Ren et al. (2025), world simulators, or even the real world. Furthermore, AZ’s generality could possibly be extend to domains such as embodied AI (Zitkovich et al., 2023; Yue et al., 2024). Additionally, more complex agentic tasks or scientific experiments, present exciting opportunities to further advance the absolute zero setting to different application domains (Wu et al., 2024; 2023). Beyond that, future directions could include exploring multimodal reasoning models, modifying the distribution p(z) to incorporate privileged information, defining or even let the model dynamically learn how to define f (Equation 3), or designing exploration/diversity rewards for both the propose and solve roles. While underappreciated in current reasoning literature, the exploration component of RL has long been recognized as a critical driver for emergent behavior in traditional RL (Yue et al., 2025; Silver et al., 2016; Ladosz et al., 2022). Years of research have examined various forms of exploration, even in related subfields using LLMs such as red teaming Zhao et al. (2025a), yet its role in LLM reasoning models remains underexplored. Taking this a step further, our framework investigates an even more meta-level exploration problem: exploration within the learning task space—where the agent learns not just how to solve tasks, but what tasks to learn from and how to find them. Rather than being confined to a fixed problem set, AI reasoner agents may benefit from dynamically defining and refining their own learning tasks. This shift opens a powerful new frontier—where agents explore not only solution spaces but also expand the boundaries of problem spaces. We believe this is a promising and important direction for future research. One limitation of our work is that we did not address how to safely manage a system composed of such self-improving components. To our surprise, we observed several instances of safety-concerning CoT from the Llama-3.1-8B model, which we term the “uh-oh moment”. These findings suggest that the proposed absolute zero paradigm, while reducing the need for human intervention for curating tasks, still necessitates oversight due to lingering safety concerns and is a critical direction for future research Wang et al. (2024; 2025a). As a final note, we explored reasoning models that possess experience—models that not only solve given tasks, but also define and evolve their own learning task distributions with the help of an environment. Our results with AZR show that this shift enables strong performance across diverse reasoning tasks, even with significantly fewer privileged resources, such as curated human data. We believe this could finally free reasoning models from the constraints of human-curated data (Morris, 2025) and marks the beginning of a new chapter for reasoning models: “welcome to the era of experience” Silver & Sutton (2025); Zhao et al. (2024). | 我们认为还有许多值得探索的地方,比如改变推理器接收可验证反馈的环境,包括像万维网、形式化数学语言(Sutton,2001;Ren 等人,2025)、世界模拟器甚至现实世界这样的来源。此外,AZ 的通用性或许还能拓展到诸如具身人工智能(Zitkovich 等人,2023;Yue 等人,2024)这样的领域。另外,更复杂的代理任务或科学实验,为将绝对零度设置进一步推进到不同的应用领域提供了令人兴奋的机会(Wu 等人,2024;2023)。除此之外,未来的研究方向可能包括探索多模态推理模型、修改分布 p(z) 以纳入特权信息、定义甚至让模型动态学习如何定义 f(公式 3),或者为提议和解决角色设计探索/多样性奖励。 尽管在当前的推理文献中未得到充分重视,但强化学习中的探索成分长期以来一直被认为是传统强化学习中出现新行为的关键驱动因素(Yue 等人,2025 年;Silver 等人,2016 年;Ladosz 等人,2022 年)。多年来,研究者们已经对各种形式的探索进行了研究,甚至在使用 LLM 的相关子领域中也是如此,例如红队对抗(Zhao 等人,2025a),但其在 LLM 推理模型中的作用仍未得到充分探索。更进一步,我们的框架研究了一个更高级别的探索问题:在学习任务空间内的探索——在这种情况下,智能体不仅学习如何解决任务,还学习从哪些任务中学习以及如何找到这些任务。与局限于固定的问题集不同,AI 推理智能体可能会从动态定义和细化自己的学习任务中受益。这种转变开辟了一个强大的新领域——智能体不仅探索解决方案空间,还拓展问题空间的边界。我们认为这是未来研究的一个有前景且重要的方向。 我们工作的一个局限性在于,我们没有解决如何安全地管理由这种自我改进组件组成的系统。令我们惊讶的是,我们从 Llama-3.1-8B 模型中观察到了几个令人担忧的 CoT 实例,我们将其称为“哎呀时刻”。这些发现表明,尽管绝对零范式减少了对人工干预来策划任务的需求,但由于仍存在安全问题,因此仍需要监督,这是未来研究的一个关键方向(Wang 等人,2024 年;2025a 年)。 最后,我们探索了具备经验模型的推理模型,这些模型不仅能解决给定的任务,还能在环境的帮助下定义和演化自己的学习任务分布。我们的 AZR 结果表明,这种转变即使在显著减少特权资源(如人工策划的数据)的情况下,也能在各种推理任务中实现强大的性能。我们认为这最终能够使推理模型摆脱人工整理数据的限制(莫里斯,2025 年),并标志着推理模型新篇章的开启:“欢迎来到经验时代”(西尔弗和萨顿,2025 年;赵等人,2024 年)。 |