从零开始学Flink:揭开实时计算的神秘面纱
一、为什么需要Flink?
当你在电商平台秒杀商品时,1毫秒的延迟可能导致交易失败;当自动驾驶汽车遇到障碍物时,10毫秒的计算延迟可能酿成事故。这些场景揭示了一个残酷事实:数据的价值随时间呈指数级衰减。
传统批处理(如Hadoop)像老式火车,必须等所有乘客(数据)到齐才能发车;而流处理(如Flink)如同磁悬浮列车,每个乘客(数据)上车即刻出发。Flink的诞生,让数据从"考古材料"变为"新鲜血液"。
二、初识Flink
1. 定义
Apache Flink是由德国柏林工业大学于2009年启动的研究项目,2014年进入Apache孵化器,现已成为实时计算领域的事实标准。其核心能力可用一句话概括:对无界和有界数据流进行有状态计算。
2. 核心特性
流处理优先:批处理是流处理的特例(有界数据流)
事件时间语义:按数据真实发生时间处理(而非系统接收时间)
精确一次语义:确保计算结果100%准确
亚秒级延迟:处理延迟可控制在毫秒级
3. 技术架构
Flink运行时架构包含三个关键角色:
- JobManager:大脑中枢,负责任务调度与检查点管理
- TaskManager:肌肉组织,执行具体计算任务
- Dispatcher:网关系统,提供REST接口提交作业
三、环境搭建
环境要求
1. Windows 10 2004 或更高版本(建议使用 Windows 11)
2. 已启用 WSL 2
3. 存储空间:至少 1GB 可用空间
详细安装步骤
步骤 1:启用 WSL
在 PowerShell 中以管理员身份运行以下命令:
# 启用 WSL 功能dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart# 启用虚拟机平台dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart# 设置 WSL 2 为默认版本wsl --set-default-version 2# 重启电脑(必须步骤)步骤 2:安装 Ubuntu
1. 打开 Microsoft Store
2. 搜索安装 Ubuntu 22.04 LTS
3. 启动 Ubuntu 并创建用户名和密码
步骤 3:安装 Java 17
在 Ubuntu 终端执行:
# 更新软件包列表sudo apt update# 安装 Java 17sudo apt install -y openjdk-17-jdk# 设置环境变量echo 'export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64' >> /etc/profileecho 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profilesource /etc/profile# 验证安装java -version# 应显示类似:OpenJDK Runtime Environment (build 17.0.14+...)步骤 4:下载并安装 Flink 1.20.1
# 下载 Flinkwget https://archive.apache.org/dist/flink/flink-1.20.1/flink-1.20.1-bin-scala_2.12.tgz# 解压安装包tar xzf flink-1.20.1-bin-scala_2.12.tgz# 移动到安装目录sudo mv flink-1.20.1 /opt/flink# 设置环境变量echo 'export FLINK_HOME=/opt/flink' >> /etc/profileecho 'export PATH=$PATH:$FLINK_HOME/bin' >> /etc/profilesource /etc/profile步骤 5:修改内存配置
编辑配置文件:
vi /opt/flink/conf/conf.yaml
修改以下关键参数:
jobmanager:bind-host: 0.0.0.0rpc:address: localhostport: 6123memory:process:size: 1600mexecution:failover-strategy: regiontaskmanager:bind-host: 0.0.0.0host: localhostnumberOfTaskSlots: 2memory:process:size: 2048mparallelism:default: 2rest:address: localhostbind-address: 0.0.0.0port: 8081步骤 6:启动 Flink 集群
# 启动集群(JobManager + TaskManager)
$FLINK_HOME/bin/start-cluster.sh# 检查运行状态
jps步骤 7:访问 Web UI
在 Windows 浏览器中访问:
http://localhost:8081
四、实战第一个Flink程序:BatchWordCount
下面将详细介绍如何在Flink环境中创建并运行第一个WordCount程序。这个经典示例将带你从项目创建到代码执行,全面体验Flink开发流程。
项目结构设计
采用多模块Gradle项目,结构清晰:
flink-learning/├── build.gradle # 根项目构建配置├── settings.gradle # 多模块配置├── libraries.gradle # 依赖统一管理├── data/ # 数据文件夹│ ├── input.txt # 输入文件│ └── output.txt # 输出文件└── wordcount/ # WordCount模块├── build.gradle # 模块构建配置└── src/main/java # 源代码目录└── cn/com/daimajiangxin/flink/wordcount└── BatchWordCount.java # 主程序
核心文件配置
详细配置参考代码仓库:https://gitee.com/daimajiangxin/flink-learning.git
WordCount代码实现
package cn.com.daimajiangxin.flink.wordcount;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.nio.charset.StandardCharsets;
import java.time.Duration;
import java.util.Arrays;public class BatchWordCount {public static void main(String[] args) throws Exception {// 转换Windows路径格式args = convertWindowsPaths(args);// 参数校验if (args.length < 2) {System.err.println("Usage: BatchWordCount <input> <output> [--parallelism=N]");System.err.println("Example: BatchWordCount input.txt output.txt --parallelism=4");System.exit(1);}final String inputPath = args[0];final String outputPath = args[1];int parallelism = 1; // 默认并行度// 1. 创建流批一体执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 明确指定批处理模式env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 设置并行度和作业名称env.setParallelism(parallelism);env.getConfig().enableObjectReuse();// 2. 使用最新的FileSource API读取输入数据DataStream<String> text = createFileSource(env, inputPath, parallelism);// 3. 定义处理逻辑SingleOutputStreamOperator<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).name("Tokenizer").setParallelism(parallelism).keyBy(value -> value.f0).reduce(new SumReducer()).name("SumReducer").setParallelism(parallelism).returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));// 4. 输出结果到文件counts.writeAsText(outputPath).name("FileSink").setParallelism(1);// 5. 执行作业try {System.out.println("Starting Flink WordCount job...");System.out.println("Input path: " + inputPath);System.out.println("Output path: " + outputPath);System.out.println("Parallelism: " + parallelism);env.execute("Flink Batch WordCount Example");System.out.println("Job completed successfully!");} catch (Exception e) {System.err.println("Job execution failed: " + e.getMessage());e.printStackTrace();}}// Windows路径转换private static String[] convertWindowsPaths(String[] args) {if (args.length >= 1) {args[0] = "file:///" + args[0].replace("\\", "/").replace(" ", "%20");}if (args.length >= 2) {args[1] = "file:///" + args[1].replace("\\", "/").replace(" ", "%20");}return args;}// 创建文件源private static DataStream<String> createFileSource(StreamExecutionEnvironment env, String path, int parallelism) {// 使用file://前缀Path filePath = new Path(path);System.out.println("Loading file from: " + filePath);TextLineFormat format = new TextLineFormat(StandardCharsets.UTF_8);FileSource<String> fileSource = FileSource.forRecordStreamFormat(format, filePath).build();WatermarkStrategy<String> watermarkStrategy = WatermarkStrategy.<String>forMonotonousTimestamps().withIdleness(Duration.ofSeconds(10));return env.fromSource(fileSource,watermarkStrategy,"FileSource").name("FileSource").setParallelism(1);}// 分词器public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {// 过滤空行if (value == null || value.trim().isEmpty()) return;// 转换为小写并分割单词String[] words = value.toLowerCase().split("\\W+");for (String word : words) {if (!word.isEmpty()) {out.collect(Tuple2.of(word, 1));}}}}// 累加器public static final class SumReducer implements ReduceFunction<Tuple2<String, Integer>> {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> v1, Tuple2<String, Integer> v2) {return Tuple2.of(v1.f0, v1.f1 + v2.f1);}}
}输入文件示例 (input.txt)
input.txt参考代码仓库:https://gitee.com/daimajiangxin/flink-learning.git
运行Flink作业
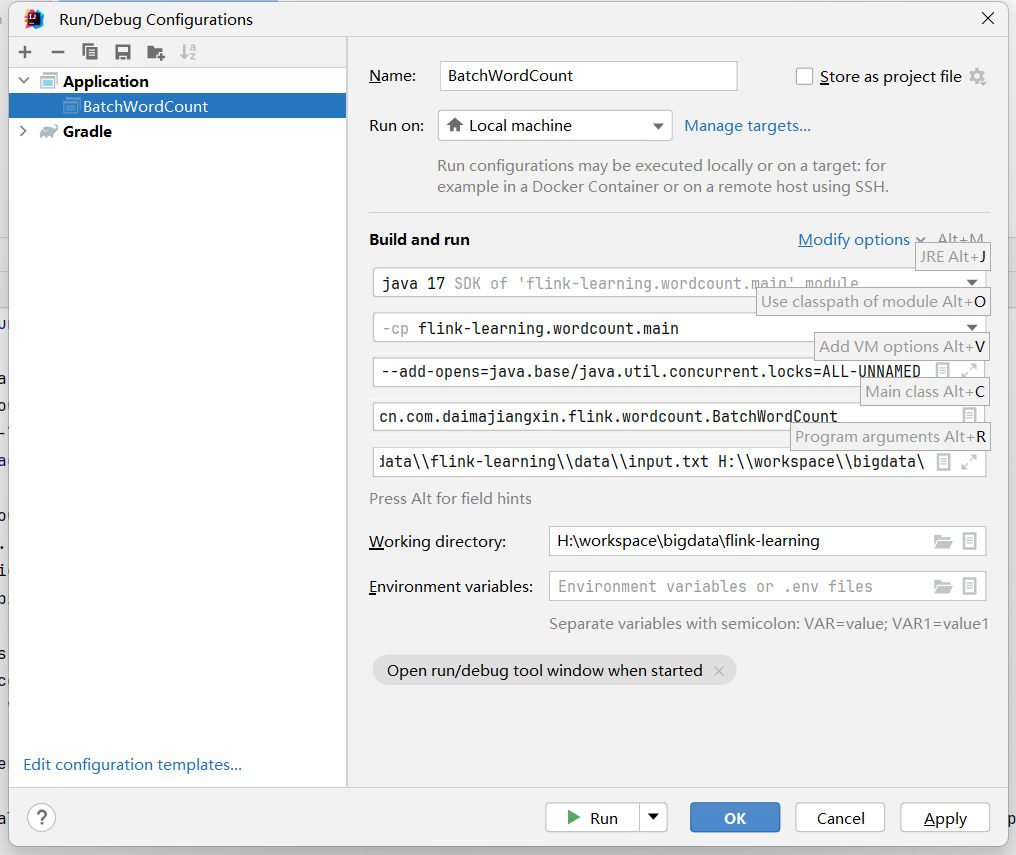
这里讲述在IDEA中运行刚刚写的BatchWordCount 任务,配置IDEA的APPlication。
VM选项配置
--add-exports=java.base/sun.net.util=ALL-UNNAMED--add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED--add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED--add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED--add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED--add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED--add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED--add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED--add-opens=java.base/java.lang=ALL-UNNAMED--add-opens=java.base/java.net=ALL-UNNAMED--add-opens=java.base/java.io=ALL-UNNAMED--add-opens=java.base/java.nio=ALL-UNNAMED--add-opens=java.base/sun.nio.ch=ALL-UNNAMED--add-opens=java.base/java.lang.reflect=ALL-UNNAMED--add-opens=java.base/java.text=ALL-UNNAMED--add-opens=java.base/java.time=ALL-UNNAMED--add-opens=java.base/java.util=ALL-UNNAMED--add-opens=java.base/java.util.concurrent=ALL-UNNAMED--add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED--add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMED
程序参数
代码放置路径\\flink-learning\\data\\input.txt代码放置路径\bigdata\\flink-learning\\data\\output.txt
运行BatchWordCount类
Run 或者Debug BatchWordCount的 APPlication.
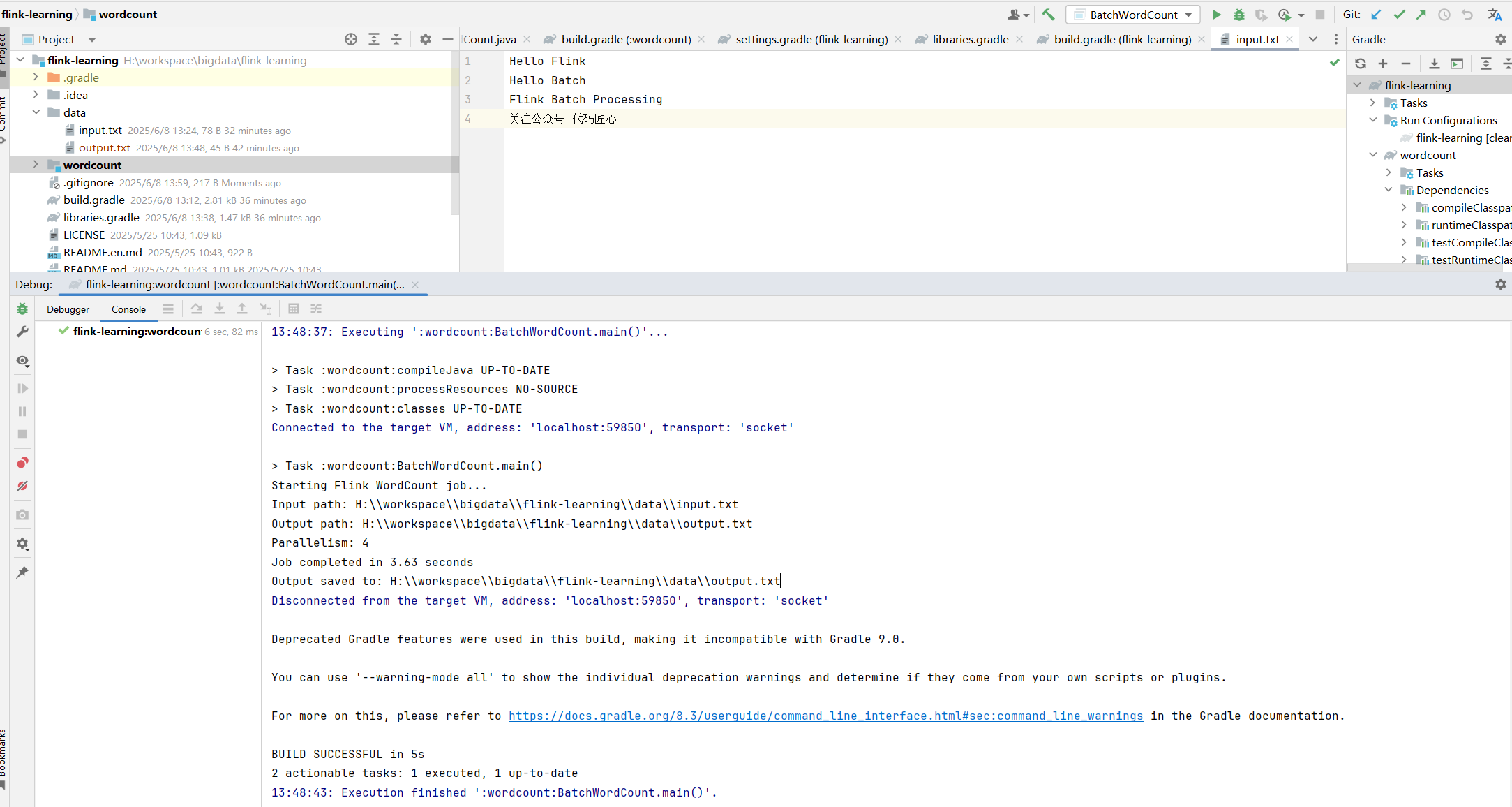
预期输出
运行成功data目录下会生成output的文件。
(processing,1)
(batch,2)
(flink,2)
(hello,2)
五、技术要点解析
- 流批一体API:Flink 1.20+使用StreamExecutionEnvironment统一处理批流
- 文件源:使用FileSource API
- 精确一次处理:批处理天然支持Exactly-Once语义
- 并行度控制:通过setParallelism控制任务并行度
- Windows路径适配:统一转换为file:///开头的URI格式
六、学习路线建议
完成WordCount后,可逐步探索:
- 实时流处理(SocketWordCount)
- 状态管理(StatefulProcessing)
- 事件时间处理(EventTimeProcessing)
- 窗口计算(TumblingWindow、SlidingWindow)
- CEP复杂事件处理
- Table API和SQL
通过这个完整的BatchWordCount实例,你已经掌握了Flink项目的搭建、编码和运行全流程。随着Flink在实时数据处理领域的广泛应用,这些技能将成为大数据开发的宝贵资产。