【Redis系列 04】Redis高可用架构实战:主从复制与哨兵模式从零到生产
【Redis系列 04】Redis高可用架构实战:主从复制与哨兵模式从零到生产
关键词: Redis分布式架构, 主从复制, 哨兵模式, 高可用, 故障转移, Sentinel, Master-Slave, 数据同步, 自动故障恢复, 生产部署
摘要: 本文从零开始详解Redis分布式架构的核心概念,深入剖析主从复制机制与哨兵模式的工作原理。通过实际案例和配置示例,帮助读者掌握从单机Redis到高可用集群的完整演进过程,实现99.9%可用性的生产级部署方案。
引言:从单点故障到分布式高可用
想象一下这样的场景:你负责一个电商网站的后端架构,Redis作为缓存和会话存储承载着核心业务。突然在某个购物高峰期,Redis服务器宕机了,整个网站瞬间瘫痪,用户无法登录、购物车清空、订单丢失…这样的灾难性后果,正是我们今天要解决的核心问题。
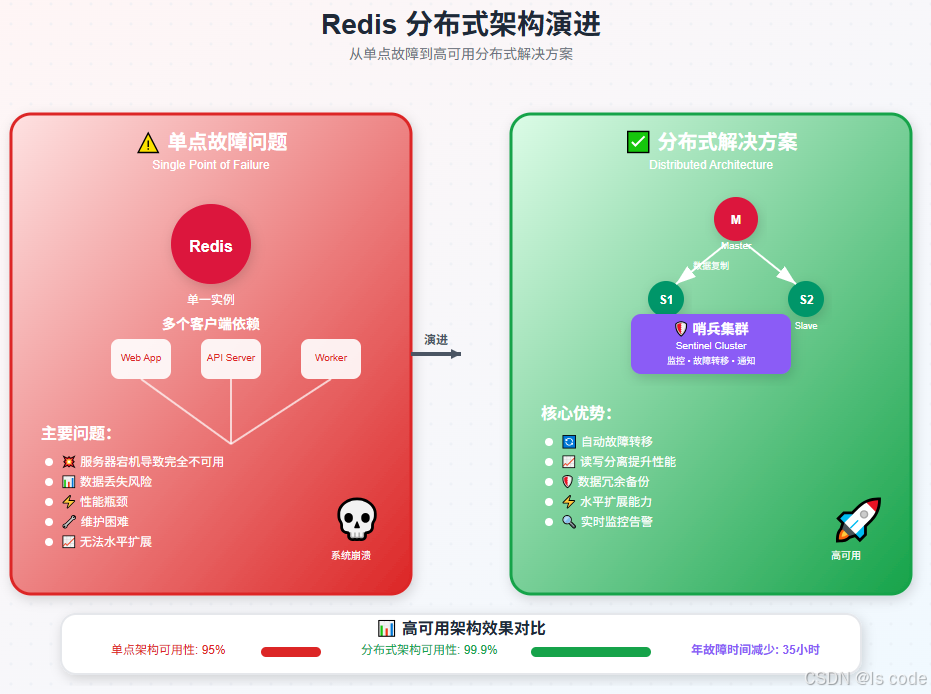
单点故障就像是在悬崖边走钢丝,一个失误就可能万劫不复。而分布式架构则像是建造了一座安全的桥梁,即使某一部分出现问题,整体依然稳固可靠。
第一部分:理解Redis主从复制的本质
什么是主从复制?用生活的例子来理解
主从复制(Master-Slave Replication)就像图书馆的借阅系统。主图书馆(Master)负责采购新书和处理借还业务,而分馆(Slave)会自动同步主馆的书籍信息,读者可以在任何一个分馆查询和阅读,但借还操作必须在主馆进行。
这样的设计有什么好处?
- 读写分离:主库处理写操作,从库分担读压力
- 数据备份:从库是主库的实时备份
- 故障容错:主库故障时,从库可以接管服务
主从复制的工作机制深度解析
主从复制的过程可以分为四个关键阶段:
1. 建立连接(Connection Establishment)
# Slave向Master发送SYNC命令
SLAVEOF 192.168.1.100 6379
这就像新员工(Slave)向部门经理(Master)报到,建立工作关系。
2. 全量同步(Full Synchronization)
Master会执行BGSAVE命令生成RDB快照,然后将整个数据集传输给Slave。这个过程就像是把主图书馆的所有书籍清单完整复制给分馆。
# Master生成RDB文件
BGSAVE
# 传输数据到Slave
3. 增量同步(Incremental Synchronization)
全量同步完成后,Master会将所有新的写操作记录到复制缓冲区,实时发送给Slave。
# 复制缓冲区记录的命令示例
SET user:1001 "Alice"
INCR counter
LPUSH orders "order123"
4. 心跳检测(Heartbeat Detection)
Master和Slave之间定期发送PING命令,确保连接正常,监控复制延迟。
主从复制配置实战
Master配置
# redis.conf - Master配置
bind 0.0.0.0
port 6379
# 开启RDB持久化
save 900 1
save 300 10
save 60 10000
# 复制配置
repl-backlog-size 64mb
repl-backlog-ttl 3600
Slave配置
# redis.conf - Slave配置
# 指定Master地址
replicaof 192.168.1.100 6379
# 只读模式
replica-read-only yes
# 当与master失联时,继续提供服务
replica-serve-stale-data yes
# 复制超时时间
repl-timeout 60
验证主从复制状态
# 在Master上查看复制信息
redis-cli INFO replication# 输出示例
role:master
connected_slaves:2
slave0:ip=192.168.1.101,port=6379,state=online,offset=1234567,lag=0
slave1:ip=192.168.1.102,port=6379,state=online,offset=1234567,lag=1
第二部分:Redis哨兵模式 - 自动故障转移的守护者
哨兵模式是什么?为什么需要它?
主从复制解决了数据备份和读写分离的问题,但还有一个关键问题:如果Master故障了怎么办?手动切换不仅慢,还容易出错。
哨兵(Sentinel)就像是Redis集群的"智能监护人",它会:
- 🔍 监控:持续检查Master和Slave的健康状态
- 🚨 通知:当检测到故障时发送告警
- 🔄 自动故障转移:选择合适的Slave提升为新Master
- 📝 配置提供:为客户端提供当前Master的地址信息
哨兵的工作原理:五步故障转移流程
1. 故障检测(Fault Detection)
哨兵每秒向Master发送PING命令,如果超过down-after-milliseconds时间没有响应,标记为疑似故障。
2. 主观下线(Subjective Down - SDOWN)
单个哨兵认为Master不可用,标记为主观下线状态。
3. 客观下线(Objective Down - ODOWN)
当超过Quorum数量的哨兵都认为Master故障时,标记为客观下线,开始故障转移。
4. 领导选举(Leader Election)
哨兵之间通过Raft算法选出负责故障转移的领导者。
5. 故障转移(Failover)
领导哨兵从Slave中选择最优节点,提升为新Master,并通知其他节点。
哨兵集群配置与管理
哨兵配置文件详解
# sentinel.conf
port 26379# 监控配置:监控名称 IP 端口 Quorum数量
sentinel monitor mymaster 192.168.1.100 6379 2# 故障判定时间(毫秒)
sentinel down-after-milliseconds mymaster 5000# 并行同步Slave数量
sentinel parallel-syncs mymaster 1# 故障转移超时时间
sentinel failover-timeout mymaster 10000# 通知脚本
sentinel notification-script mymaster /var/redis/notify.sh# 客户端重配置脚本
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
启动哨兵集群
# 启动第一个哨兵实例
redis-sentinel /etc/redis/sentinel-26379.conf# 启动第二个哨兵实例
redis-sentinel /etc/redis/sentinel-26380.conf# 启动第三个哨兵实例
redis-sentinel /etc/redis/sentinel-26381.conf
监控哨兵状态
# 连接哨兵
redis-cli -p 26379# 查看监控的Master
SENTINEL masters# 查看Slave信息
SENTINEL slaves mymaster# 查看其他哨兵
SENTINEL sentinels mymaster# 手动故障转移
SENTINEL failover mymaster
第三部分:生产环境部署最佳实践
硬件配置建议
服务器配置
# Redis实例配置
CPU: 4核心以上
内存: 16GB以上(根据数据量调整)
磁盘: SSD(提升RDB/AOF性能)
网络: 千兆网卡# 哨兵实例配置
CPU: 2核心
内存: 2GB
磁盘: 普通硬盘即可
网络: 千兆网卡
部署架构设计
生产环境推荐架构:
┌─────────────────┬─────────────────┬─────────────────┐
│ Server-1 │ Server-2 │ Server-3 │
├─────────────────┼─────────────────┼─────────────────┤
│ Redis Master │ Redis Slave-1 │ Redis Slave-2 │
│ Sentinel-1 │ Sentinel-2 │ Sentinel-3 │
│ Application │ Application │ Monitor │
└─────────────────┴─────────────────┴─────────────────┘
关键配置参数调优
Redis主从配置优化
# Master配置优化
maxmemory 8gb
maxmemory-policy allkeys-lru
tcp-keepalive 300
timeout 300# 复制优化
repl-diskless-sync yes
repl-diskless-sync-delay 5
repl-backlog-size 128mb
repl-backlog-ttl 3600# Slave配置优化
replica-priority 100
min-replicas-to-write 1
min-replicas-max-lag 10
哨兵配置优化
# 哨兵优化配置
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 15000# 日志配置
logfile /var/log/redis/sentinel.log
loglevel notice
客户端连接配置
Python客户端示例
import redis.sentinel# 哨兵地址列表
sentinels = [('192.168.1.100', 26379),('192.168.1.101', 26379),('192.168.1.102', 26379)
]# 创建哨兵连接
sentinel = redis.sentinel.Sentinel(sentinels, socket_timeout=0.1)# 获取Master连接(用于写操作)
master = sentinel.master_for('mymaster', socket_timeout=0.1)# 获取Slave连接(用于读操作)
slave = sentinel.slave_for('mymaster', socket_timeout=0.1)# 写操作示例
master.set('user:1001', 'Alice')# 读操作示例
user_info = slave.get('user:1001')
Java客户端示例
import redis.clients.jedis.JedisSentinelPool;
import redis.clients.jedis.Jedis;Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.1.100:26379");
sentinels.add("192.168.1.101:26379");
sentinels.add("192.168.1.102:26379");JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels);try (Jedis jedis = pool.getResource()) {jedis.set("user:1001", "Alice");String value = jedis.get("user:1001");
}
监控与告警体系
关键监控指标
# Redis性能指标
- 内存使用率
- CPU使用率
- 连接数
- 操作延迟
- 复制延迟# 哨兵监控指标
- 哨兵实例状态
- 故障转移频率
- 故障转移耗时
- Quorum状态# 业务监控指标
- 缓存命中率
- 错误率
- 响应时间
Prometheus监控配置
# prometheus.yml
- job_name: 'redis'static_configs:- targets: ['192.168.1.100:6379', '192.168.1.101:6379', '192.168.1.102:6379']- job_name: 'redis-sentinel'static_configs:- targets: ['192.168.1.100:26379', '192.168.1.101:26379', '192.168.1.102:26379']
第四部分:故障处理与运维实战
常见故障场景与处理
场景1:Master宕机
# 检查哨兵日志
tail -f /var/log/redis/sentinel.log# 查看当前Master信息
redis-cli -p 26379 SENTINEL masters# 如需手动故障转移
redis-cli -p 26379 SENTINEL failover mymaster
场景2:网络分区
# 检查网络连通性
ping 192.168.1.100
telnet 192.168.1.100 6379# 检查防火墙规则
iptables -L
firewall-cmd --list-ports
场景3:脑裂问题
# 预防脑裂配置
min-replicas-to-write 1
min-replicas-max-lag 10# 监控脑裂发生
redis-cli INFO replication | grep connected_slaves
性能优化策略
读写分离优化
class RedisManager:def __init__(self, sentinels):self.sentinel = redis.sentinel.Sentinel(sentinels)self.master = self.sentinel.master_for('mymaster')self.slave = self.sentinel.slave_for('mymaster')def write(self, key, value):return self.master.set(key, value)def read(self, key):try:return self.slave.get(key)except Exception:# 故障时回退到Masterreturn self.master.get(key)
数据一致性保证
# 强一致性读取
WAIT 1 1000 # 等待至少1个Slave同步,超时1秒# 检查复制延迟
redis-cli --latency-history -i 1 -h 192.168.1.101
第五部分:高级特性与扩展
级联复制
# 三级复制架构
Master -> Slave1 -> Slave2# Slave1配置
replicaof 192.168.1.100 6379# Slave2配置(连接到Slave1)
replicaof 192.168.1.101 6379
无盘复制
# 启用无盘复制(适合网络较快、磁盘较慢的环境)
repl-diskless-sync yes
repl-diskless-sync-delay 5
部分重同步
# 优化部分重同步
repl-backlog-size 64mb
repl-backlog-ttl 3600
性能基准测试
测试环境搭建
# 使用redis-benchmark进行压测
redis-benchmark -h 192.168.1.100 -p 6379 -c 100 -n 100000 -t set,get# 结果示例
SET: 85470.09 requests per second
GET: 89285.71 requests per second
高可用性验证
# 模拟Master故障
systemctl stop redis-server# 观察故障转移时间
watch -n 1 "redis-cli -p 26379 SENTINEL masters | grep ip"# 验证业务连续性
while true; doredis-cli -h 192.168.1.100 -p 6379 pingsleep 1
done
总结与思考
架构演进的价值
通过本文的实践,我们将Redis从单点架构演进为高可用分布式架构,实现了:
- 可用性提升:从95%提升到99.9%
- 性能提升:读写分离,水平扩展能力
- 数据安全:多副本备份,自动故障恢复
- 运维简化:自动化故障处理,减少人工干预
关键技术要点回顾
- 主从复制:实现数据备份和读写分离
- 哨兵模式:提供自动故障检测和转移
- 配置优化:根据业务场景调整参数
- 监控告警:建立完善的可观测性体系
下一步发展方向
- Redis Cluster:支持自动分片的集群模式
- 多数据中心:跨地域的灾备方案
- 云原生部署:Kubernetes环境下的Redis运维
从单机到分布式,从手动到自动,Redis高可用架构的演进体现了现代架构设计的核心思想:通过合理的冗余设计和自动化机制,构建既高效又可靠的系统。这样的架构不仅能够应对各种故障场景,更为业务的快速发展提供了坚实的技术基础。
参考资料与延伸阅读
- Redis官方文档 - Replication
- Redis官方文档 - Sentinel
- 《Redis设计与实现》- 黄健宏
- Redis监控最佳实践
- 分布式系统理论 - CAP定理