【Hugging Face】实践笔记:Pipeline任务、BERT嵌入层、Train任务、WandB解析
一、Pipeline学习
如何查找哪些task可以用
选择tasks,左侧的就是task的关键字,选定一个关键字之后,比如zero-shot image classification,右侧是可以选择的模型
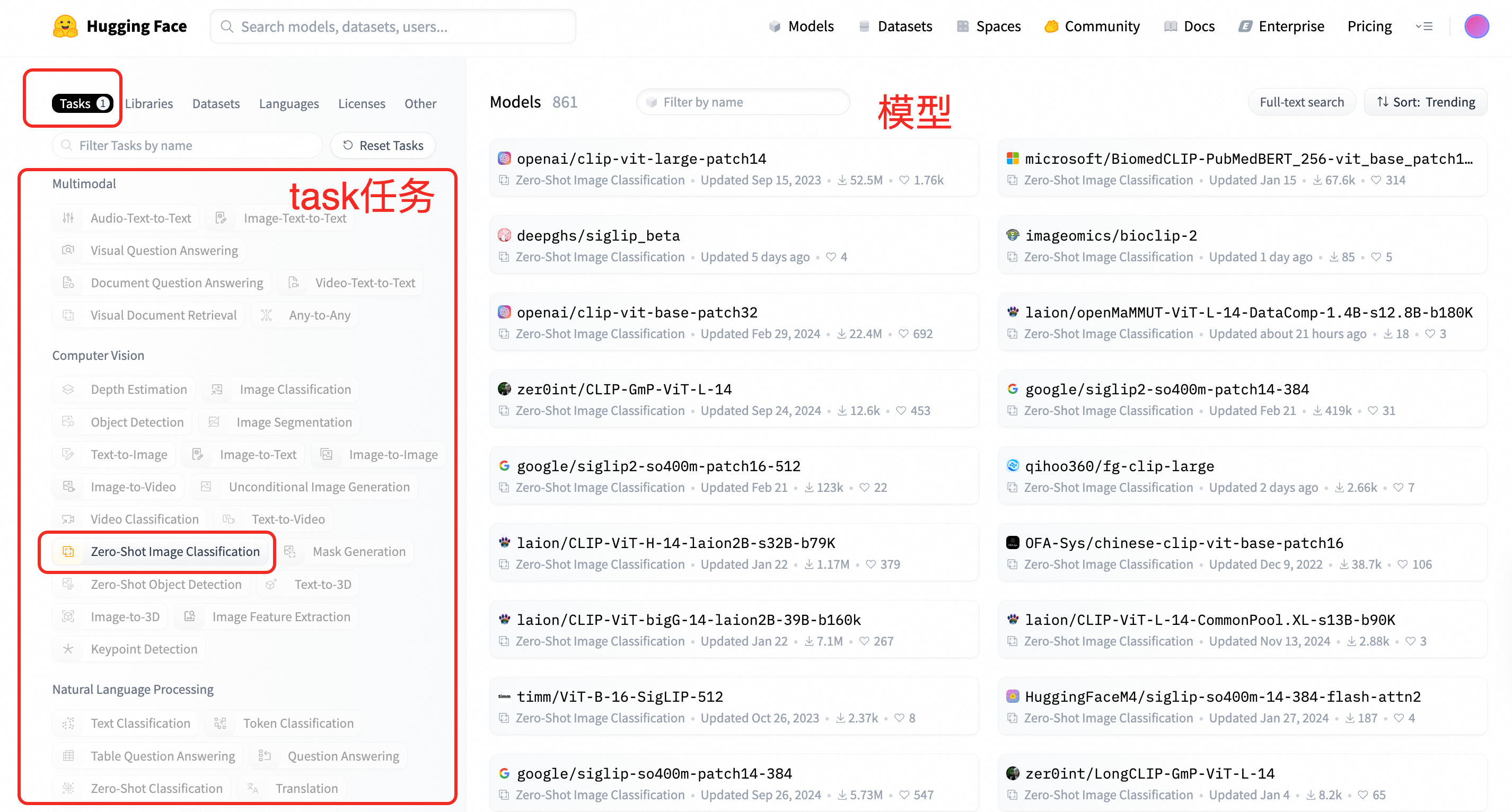
任务对比:image-classification vs zero-shot-image-classification
| 特性 |
|
|
| 类别固定性 | 是(模型训练时已定义) | 否(自定义候选标签) |
| 模型代表 | ViT、ResNet | CLIP、ALIGN |
| 输入格式 | 仅图像 | 图像 + 候选标签列表 |
| 典型用途 | 标准分类(如ImageNet) | 定制化分类(品牌识别、新类别) |
一句话总结: 需固定类别用image-classification,需灵活自定义标签选zero-shot-image-classification
如果要更改类别,对于image-classification模型需要重新训练
二、Tokenizer vs Processor:NLP与多模态预处理
| 对比项 | Tokenizer | Processor |
| 适用任务 | 纯文本(BERT、GPT等) | 多模态(CLIP、BLIP等) |
| 输入类型 | 字符串文本 | 图像+文本 / 音频+文本 |
| 核心功能 | 分词、生成token ID | 组合文本与图像预处理 |
| 加载方式 |
|
|
一句话总结: 处理纯文本用Tokenizer,多模态任务直接调用Processor
三、BERT嵌入层解析:为什么不同维度的Embedding能相加?

问题:对于BertModel的embeddings层,word_embeddings(30522×768)和position_embeddings(512×768)维度不同,为何能相加?
答案:
-
维度真相:两者输出向量维度均为768,差异仅在词表大小(30522 vs 512位置),实际使用时按token索引取对应向量相加。
-
融合逻辑:
-
word_emb(词义)+position_emb(位置)+token_type_emb(句子角色)= 最终嵌入表示。
-
-
类比理解:三个独立特征盒子(词义、位置、角色)叠加,维度一致即可逐元素相加。
示例: 输入长度为5的句子,每个token从三个Embedding层各取1个768维向量相加。
🧩 示例场景
假设我们有这样一个输入句子:
[CLS] I love NLP [SEP]这个句子被分词成 5 个 token:
-
[CLS]→ token_id = 101 -
I→ token_id = 1234 -
love→ token_id = 5678 -
NLP→ token_id = 9101 -
[SEP]→ token_id = 102
所以 token_ids = [101, 1234, 5678, 9101, 102] 对应的 token 类型是:[0, 0, 0, 0, 0](全部属于第一个句子)
Embedding 层取值过程
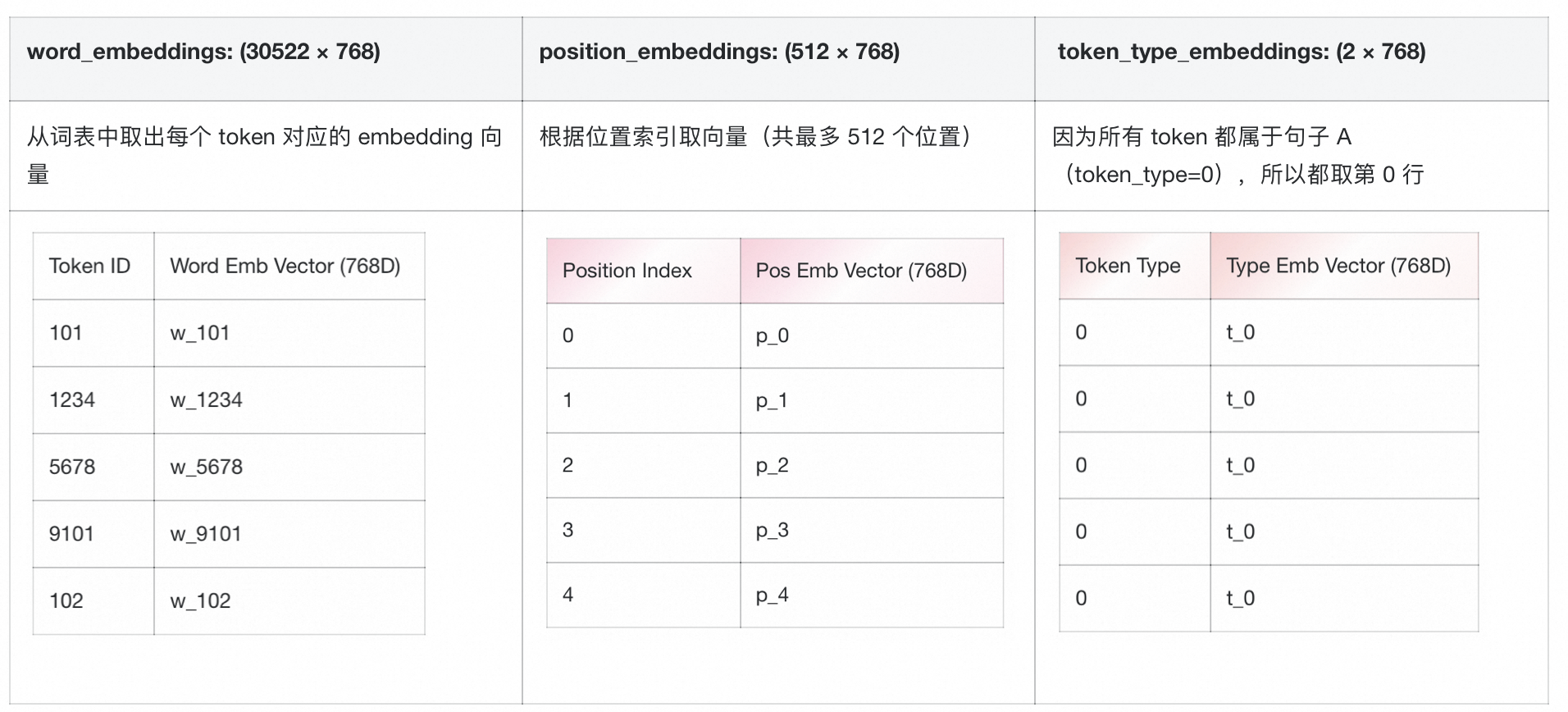
最终嵌入融合(逐元素相加)
对每个 token,将三部分向量按位置一一相加:
final_embedding_i = word_emb[i] + position_emb[i] + token_type_emb[i]结果如下:
| Token | Final Embedding (768D) |
| 101 | w_101 + p_0 + t_0 |
| 1234 | w_1234 + p_1 + t_0 |
| 5678 | w_5678 + p_2 + t_0 |
| 9101 | w_9101 + p_3 + t_0 |
| 102 | w_102 + p_4 + t_0 |
总结一句话
虽然 word_embeddings 和 position_embeddings 的行数不同(即词表大小不同),但它们输出的 向量维度都是 768,因此可以在每个 token 上进行逐元素相加,从而融合词义、位置和句子类型信息。
四、WandB
什么是 WandB?
WandB 是一个用于机器学习实验跟踪、可视化和协作的平台。它可以帮助你记录训练过程中的超参数、指标、模型结构、数据集版本等,并提供交互式图表帮助你分析模型表现。
常见用途:
-
记录训练日志(loss, accuracy 等)
-
可视化训练过程
-
跟踪不同实验之间的差异
-
模型版本管理
-
分享结果与报告
使用方法简要步骤:
-
安装:
pip install wandb -
登录:
wandb login -
初始化:在训练脚本中加入
import wandb
wandb.init(project="your_project_name", config={"lr": 1e-4, "batch_size": 32})-
日志记录
wandb.log({"loss": loss.item(), "accuracy": acc}, step=epoch)五、DataCollatorWithPadding:动态 max_length
在 NLP 任务中,输入序列长度通常不一致。为了提高效率,Hugging Face 提供了 DataCollatorWithPadding 来自动处理 padding。
示例:
from transformers import DataCollatorWithPadding
from transformers import Trainerdata_collator = DataCollatorWithPadding(tokenizer=tokenizer, padding="longest")# 在DataLoader中使用
train_loader = DataLoader(encoded_dataset["train"],batch_size=16,shuffle=True,collate_fn=data_collator
)
# 在Trainer中使用
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,data_collator=data_collator,tokenizer=tokenizer
)参数说明:
-
padding: 可选"longest"(当前 batch 最长)、"max_length"(固定长度)、"do_not_pad" -
max_length: 若设为固定值,则所有样本 pad 到这个长度 -
pad_to_multiple_of: 有时需要对齐硬件优化块大小(如 TPU)
💡 动态 max_length 的好处是减少不必要的 padding,提升训练效率。
六、 Batch, Step, Epoch 的区别
| 名词 | 含义 | 示例 | 例子 |
| Batch | 一次前向+反向传播使用的样本数 | batch_size=32 表示每次用 32 个样本更新权重 | 一篮子有32个苹果 |
| Step | 一次参数更新(即一次 batch 处理) | 1 epoch = (总样本数 / batch_size) 个 steps | 一次吃一篮子 |
| Epoch | 整个训练集被完整遍历一次 | 10 epochs 表示整个数据集被训练了 10 次 | 总共遍历两车 |
training_args = TrainingArguments(output_dir='./results',eval_strategy="epoch", # 每个epoch评估一次准确率learning_rate=2e-5, # 学习率per_device_train_batch_size=5, # 一篮子5个🍎per_device_eval_batch_size=5, # 一篮子5个🍎num_train_epochs=2, # 训练两遍weight_decay=0.01,save_strategy="steps", # 保存策略:按照 篮子save_steps=10, # 每10篮子保存一次logging_dir='./logs', # 启用日志目录(用于 WandB 记录)logging_strategy="epoch", # 按照 epoch 算report_to=["wandb"], # 把训练信息报告给 WandBrun_name = '50-epochs2',
)七、Pipeline 与 Config:修改模型结构但仍使用原始参数
Hugging Face 的 transformers 提供了 AutoModel.from_pretrained(...) 接口加载预训练模型。有时候你想在不改变参数的前提下,自定义模型结构(比如加一层分类层、改输出维度等)。
方法一:继承并重写模型类
from transformers import BertPreTrainedModel, BertModel
import torch.nn as nnclass MyBertForSequenceClassification(BertPreTrainedModel):def __init__(self, config):super().__init__(config)self.bert = BertModel(config)self.classifier = nn.Linear(config.hidden_size, 2) # 修改输出类别数def forward(self, input_ids, attention_mask=None):outputs = self.bert(input_ids, attention_mask=attention_mask)cls_output = outputs.last_hidden_state[:, 0, :]logits = self.classifier(cls_output)return logits
方法二:加载预训练模型后替换部分层
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 替换最后一层
model.classifier = nn.Linear(768, 4) # 改成 4 类
方法三:使用 config 自定义模型结构
from transformers import BertConfig, BertModelconfig = BertConfig.from_pretrained("bert-base-uncased")
config.num_hidden_layers = 6 # 减少层数
config.vocab_size = 30000 # 修改词汇量
model = BertModel(config) # 构建新模型,不加载预训练参数