SOC-ESP32S3部分:33-声学前端模型ESP-SR
飞书文档![]() https://x509p6c8to.feishu.cn/wiki/YnbmwtqI5iBwE3kHA7AcZ3yTnLf
https://x509p6c8to.feishu.cn/wiki/YnbmwtqI5iBwE3kHA7AcZ3yTnLf
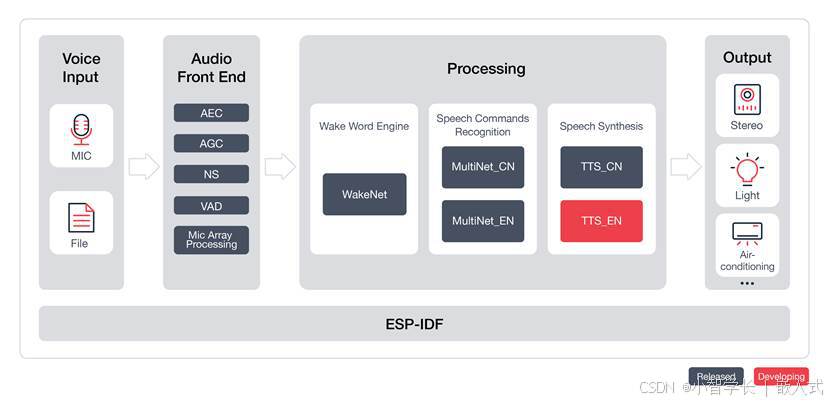
ESP-SR 是乐鑫官方开发的一个音频组件,支持以下模块:
- 声学前端算法 AFE
- 唤醒词检测 WakeNet
- 命令词识别 MultiNet
- 语音合成(目前只支持中文)
组件地址:https://components.espressif.com/components/espressif/esp-sr/versions/2.0.2
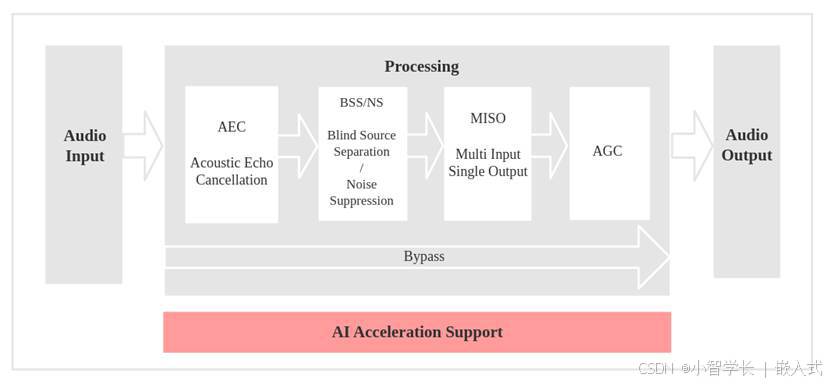
声学前端 (Audio Front-End, AFE) 算法
由于语音交互类设备需要保证能够采集干净的音频,所以在读取麦克风的音频后,需要进行一系列的算法处理,例如AEC、NS、BSS、MISO、VAD、AGC等
| 名称 | 简介 |
| AEC (Acoustic Echo Cancellation) | 回声消除算法,最多支持双麦处理,能够有效的去除 mic 输入信号中的自身播放声音,从而可以在自身播放音乐的情况下很好的完成语音识别。 |
| NS (Noise Suppression) | 噪声抑制算法,支持单通道处理,能够对单通道音频中的非人声噪声进行抑制,尤其针对稳态噪声,具有很好的抑制效果。 |
| BSS (Blind Source Separation) | 盲信号分离算法,支持双通道处理,能够很好的将目标声源和其余干扰音进行盲源分离,从而提取出有用音频信号,保证了后级语音的质量。 |
| MISO (Multi Input Single Output) | 多输入单输出算法,支持双通道输入,单通道输出。用于在双麦场景,没有唤醒使能的情况下,选择信噪比高的一路音频输出。 |
| VAD (Voice Activity Detection) | 语音活动检测算法,支持实时输出当前帧的语音活动状态。 |
| AGC (Automatic Gain Control) | 自动增益控制算法,可以动态调整输出音频的幅值,当弱信号输入时,放大输出幅度;当输入信号达到一定强度时,压缩输出幅度。 |
例如语音通过使用的算法
WakeNet 唤醒词检测
WakeNet 是一个基于神经网络,为低功耗嵌入式 MCU 设计的唤醒词模型,目前支持 5 个以内的唤醒词识别,对于需要支持唤醒词功能的应用,我们可以把经过AFE算法处理的音频输入给WakeNet模型,得到唤醒状态,模型支持的音频格式如下:输入的音频文件采样率为 16 KHz,单声道,编码方式为 signed 16-bit。。
例如语音识别使用的算法:
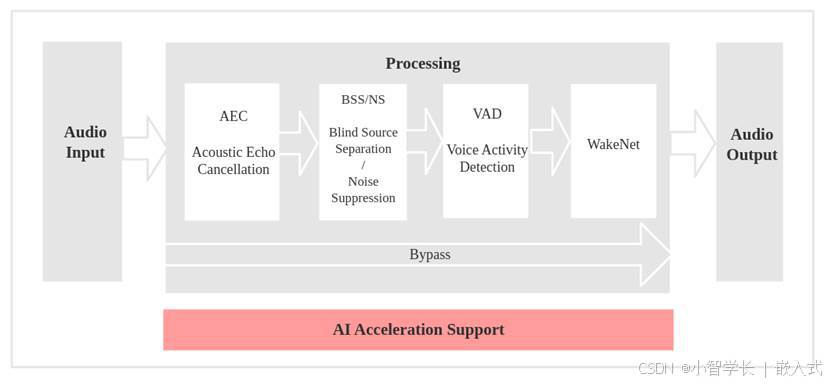
MultiNet 是为了在 ESP32-S3 系列上离线实现多命令词识别而设计的轻量化模型,目前支持 200 个以内的自定义命令词识别。
- 支持中文和英文命令词识别
- 支持用户自定义命令词
- 支持运行过程中 增加/删除/修改 命令词语
- 最多支持 200 个命令词
- 支持单次识别和连续识别两种模式
- 轻量化,低资源消耗
- 低延时,延时 500 ms内
- 支持在线中英文模型切换
- 模型单独分区,支持用户应用 OTA
乐鑫 TTS 语音合成模型是一个为嵌入式系统设计的轻量化语音合成系统,具有如下主要特性:
- 目前 仅支持中文
- 输入文本采用 UTF-8 编码
- 输出格式采用流输出,可减少延时
- 多音词发音自动识别
- 可调节合成语速
- 数字播报优化
- 自定义声音集(敬请期待)
如何使用esp-sr组件的相关功能呢?官方也给我们提供了示例工程ESP-Skainet。
ESP-Skainet 是乐鑫推出的智能语音助手应用,内置了很多例程,例如唤醒词识别、命令词识别、中文文字转语音,USBmic等,详见:https://github.com/espressif/esp-skainet/blob/master/README_cn.md
唤醒功能实现
参考
https://github.com/espressif/esp-skainet/tree/master/examples/wake_word_detection
新建工程,添加sr组件
idf.py add-dependency "espressif/esp-sr^2.0.2"
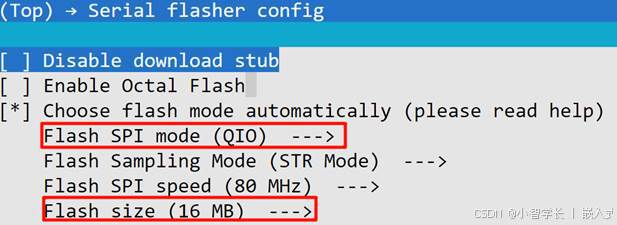
idf.py add-dependency "espressif/es8311^1.0.0"修改工程配置Flash大小
因为加入sr声学模型后,需要更大的存储空间
添加自定义分区表
参考分区表章节22-分区表
# Name, Type, SubType, Offset, Size, Flags
# Note: if you have increased the bootloader size, make sure to update the offsets to avoid overlap
nvs, data, nvs, , 0x6000,
phy_init, data, phy, , 0x1000,
factory, app, factory, , 1M,
model, data, spiffs, , 5168K,开启PSRAM

选择模型
ESP-SR允许您通过 menuconfig 界面选择所需的模型。要配置模型:
运行
idf.py set-target esp32s3
idf.py menuconfig
导航到 ESP Speech Recognition
可支持配置以下选项:
- NS噪声抑制模型
- VAD语音活动检测模型
- WakeNet唤醒词识别模型
- MultiNet命令词识别模型模型存储位置
(Top) → ESP Speech Recognition → model data path
(X) Read model data from flash
( ) Read model data from SD CardAFE回声消除模型
→ ESP Speech Recognition → Select voice activity detection
(X) voice activity detection (WebRTC)
( ) voice activity detection (vadnet1 medium) NS噪声抑制模型
→ ESP Speech Recognition → Select noise suppression model
(X) noise suppression (WebRTC)
( ) Deep noise suppression v2 (nsnet2)VAD语音活动检测模型
-> ESP Speech Recognition ->Select voice activity detection
(X) voice activity detection (WebRTC)
( ) voice activity detection (vadnet1 medium)唤醒词配置:
→ ESP Speech Recognition → Load Multiple Wake Words
[ ] Hi,乐鑫 (wn9_hilexin)
[ ] 小爱同学 (wn9_xiaoaitongxue)
[*] 你好小智 (wn9_nihaoxiaozhi_tts)
可选择单个,最多可选择两个中文命令词识别模型
→ ESP Speech Recognition → Chinese Speech Commands Model
(X) None
( ) chinese recognition (mn5q8_cn)
( ) general chinese recognition (mn6_cn)
( ) chinese recognition for air conditioner controller (mn6_cn_ac)
( ) general chinese recognition (mn7_cn)
( ) chinese recognition for air conditioner controller (mn7_cn_ac)英文命令词识别模型
→ ESP Speech Recognition → English Speech Commands Model
(X) None
( ) english recognition (mn5q8_en)
( ) general english recognition (mn6_en)
( ) general english recognition (mn7_en)为了使得前端模型运行效果更佳,建议参考例程进行配置,ESP32S3其它配置如下
CONFIG_IDF_TARGET="esp32s3"
CONFIG_ESPTOOLPY_FLASHMODE_QIO=y 4线spi
CONFIG_ESPTOOLPY_FLASHSIZE_16MB=y 16M flash
CONFIG_PARTITION_TABLE_CUSTOM=y 自定义分区表
CONFIG_SR_VADN_VADNET1_MEDIUM=y vad检测模型
CONFIG_SPIRAM=y 开启spiram
CONFIG_SPIRAM_MODE_OCT=y 8线sprram
CONFIG_SPIRAM_SPEED_80M=y 80M速率
CONFIG_ESP_DEFAULT_CPU_FREQ_MHZ_240=y 240M CPU主频
CONFIG_ESP32S3_INSTRUCTION_CACHE_32KB=y 缓存配置
CONFIG_ESP32S3_DATA_CACHE_64KB=y
CONFIG_ESP32S3_DATA_CACHE_LINE_64B=y修改demo/main/CMakeLists.txt
idf_component_register(SRCS "main.c""driver_es8311.c"INCLUDE_DIRS ".")添加es8311驱动
demo/main/driver_es8311.h
#ifndef _DERIVER_ES8311_H_
#define _DERIVER_ES8311_H_int es8311_get_feed_channel();esp_err_t es8311_get_feed_data(bool is_get_raw_channel, int16_t *buffer, int buffer_len);void init_driver_es8311();#endifdemo/main/driver_es8311.c
#include <stdio.h>
#include <string.h>
#include "sdkconfig.h"
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "driver/i2s_std.h"
#include "esp_system.h"
#include "esp_check.h"
#include "es8311.h"/* Example configurations */
#define EXAMPLE_SAMPLE_RATE (16000) // 音频采样率,采样率被设置为16000 Hz,即每秒采样16000次。
#define EXAMPLE_DATA_BIT_WIDTH I2S_DATA_BIT_WIDTH_16BIT // 音频采样位宽 16bit
#define EXAMPLE_SLOT_MODE_MONO I2S_SLOT_MODE_STEREO // 音频采样声道 双声道#define EXAMPLE_MCLK_MULTIPLE (384) // 主时钟频率是采样率的倍数,用于驱动I2S接口。MCLK的倍数被设置为384。这意味着主时钟频率将是采样率的384倍。如果数据宽度不是24位,256倍数可能已经足够。
#define EXAMPLE_MCLK_FREQ_HZ (EXAMPLE_SAMPLE_RATE * EXAMPLE_MCLK_MULTIPLE) // 主时钟的频率
#define EXAMPLE_VOICE_VOLUME 90 // 音量,控制输出音量的大小。
#define EXAMPLE_MIC_GAIN ES8311_MIC_GAIN_0DB // 麦克风增益
#define EXAMPLE_RECV_BUF_SIZE (2400) // MIC接收缓冲区大小/* I2C port and GPIOs */
#define I2C_NUM (0)
#define I2C_SCL_IO (GPIO_NUM_5)
#define I2C_SDA_IO (GPIO_NUM_7)
/* I2S port and GPIOs */
#define I2S_NUM (0)
#define I2S_MCK_IO (GPIO_NUM_6)
#define I2S_BCK_IO (GPIO_NUM_14)
#define I2S_WS_IO (GPIO_NUM_12)
#define I2S_DO_IO (GPIO_NUM_11)
#define I2S_DI_IO (GPIO_NUM_13)
#define SPKER_CTRL_PIN GPIO_NUM_10
#define SPKER_CTRL_PIN_SEL (1ULL<<SPKER_CTRL_PIN)static const char *TAG = "i2s_es8311";
static i2s_chan_handle_t tx_handle = NULL;
static i2s_chan_handle_t rx_handle = NULL;static esp_err_t i2s_driver_init(void)
{// 指定I2S编号和主模式i2s_chan_config_t chan_cfg = I2S_CHANNEL_DEFAULT_CONFIG(I2S_NUM, I2S_ROLE_MASTER);// 启用自动清除DMA缓冲区中的遗留数据chan_cfg.auto_clear = true;// 创建一个新的I2S通道,并将返回的发送和接收通道句柄分别存储在tx_handle和rx_handle中ESP_ERROR_CHECK(i2s_new_channel(&chan_cfg, &tx_handle, &rx_handle));// 配置标准I2S模式i2s_std_config_t std_cfg = {// 设置时钟配置,使用默认的标准I2S时钟配置,并根据EXAMPLE_SAMPLE_RATE配置采样率.clk_cfg = I2S_STD_CLK_DEFAULT_CONFIG(EXAMPLE_SAMPLE_RATE),// 设置槽位配置,使用默认的Philips标准槽位配置,16位数据宽度和立体声模式.slot_cfg = I2S_STD_PHILIPS_SLOT_DEFAULT_CONFIG(EXAMPLE_DATA_BIT_WIDTH, EXAMPLE_SLOT_MODE_MONO),// 设置GPIO配置,指定各个I2S信号的GPIO引脚,并配置信号不反转.gpio_cfg = {.mclk = I2S_MCK_IO, // 主时钟引脚.bclk = I2S_BCK_IO, // 位时钟引脚.ws = I2S_WS_IO, // 左右声道选择引脚.dout = I2S_DO_IO, // 数据输出引脚.din = I2S_DI_IO, // 数据输入引脚.invert_flags = {.mclk_inv = false, // 主时钟不反转.bclk_inv = false, // 位时钟不反转.ws_inv = false, // 左右声道选择信号不反转},},};// 设置主时钟的倍数std_cfg.clk_cfg.mclk_multiple = EXAMPLE_MCLK_MULTIPLE;// 初始化发送通道为标准I2S模式ESP_ERROR_CHECK(i2s_channel_init_std_mode(tx_handle, &std_cfg));// 初始化接收通道为标准I2S模式ESP_ERROR_CHECK(i2s_channel_init_std_mode(rx_handle, &std_cfg));// 启用发送通道ESP_ERROR_CHECK(i2s_channel_enable(tx_handle));// 启用接收通道ESP_ERROR_CHECK(i2s_channel_enable(rx_handle));return ESP_OK;
}static esp_err_t es8311_codec_init(void)
{/* 初始化I2C外设 */const i2c_config_t es_i2c_cfg = {.sda_io_num = I2C_SDA_IO, // SDA引脚编号.scl_io_num = I2C_SCL_IO, // SCL引脚编号.mode = I2C_MODE_MASTER, // I2C模式为主模式.sda_pullup_en = GPIO_PULLUP_ENABLE, // 启用SDA引脚的上拉电阻.scl_pullup_en = GPIO_PULLUP_ENABLE, // 启用SCL引脚的上拉电阻.master.clk_speed = 100000, // I2C主时钟速度为100 kHz};// 配置I2C参数ESP_RETURN_ON_ERROR(i2c_param_config(I2C_NUM, &es_i2c_cfg), TAG, "config i2c failed");// 安装I2C驱动ESP_RETURN_ON_ERROR(i2c_driver_install(I2C_NUM, I2C_MODE_MASTER, 0, 0, 0), TAG, "install i2c driver failed");// 初始化ES8311编解码器 创建ES8311句柄,使用I2C_NUM和ES8311的地址es8311_handle_t es_handle = es8311_create(I2C_NUM, ES8311_ADDRRES_0);ESP_RETURN_ON_FALSE(es_handle, ESP_FAIL, TAG, "es8311 create failed");// 配置ES8311的时钟const es8311_clock_config_t es_clk = {.mclk_inverted = false, // 主时钟不反转.sclk_inverted = false, // 位时钟不反转.mclk_from_mclk_pin = true, // 主时钟从MCLK引脚获取.mclk_frequency = EXAMPLE_MCLK_FREQ_HZ, // 主时钟频率.sample_frequency = EXAMPLE_SAMPLE_RATE // 采样频率};// 初始化ES8311编解码器ESP_ERROR_CHECK(es8311_init(es_handle, &es_clk, ES8311_RESOLUTION_16, ES8311_RESOLUTION_16));// 配置ES8311的采样频率ESP_RETURN_ON_ERROR(es8311_sample_frequency_config(es_handle, EXAMPLE_SAMPLE_RATE * EXAMPLE_MCLK_MULTIPLE, EXAMPLE_SAMPLE_RATE), TAG, "set es8311 sample frequency failed");// 设置ES8311的音量ESP_RETURN_ON_ERROR(es8311_voice_volume_set(es_handle, EXAMPLE_VOICE_VOLUME, NULL), TAG, "set es8311 volume failed");// 配置ES8311的麦克风ESP_RETURN_ON_ERROR(es8311_microphone_config(es_handle, false), TAG, "set es8311 microphone failed");// 设置ES8311的麦克风增益ESP_RETURN_ON_ERROR(es8311_microphone_gain_set(es_handle, EXAMPLE_MIC_GAIN), TAG, "set es8311 microphone gain failed");return ESP_OK;
}int es8311_get_feed_channel(void)
{return EXAMPLE_SLOT_MODE_MONO;
}esp_err_t es8311_get_feed_data(bool is_get_raw_channel, int16_t *buffer, int buffer_len){size_t bytes_read = 0;esp_err_t ret = ESP_OK;ret = i2s_channel_read(rx_handle, buffer, buffer_len, &bytes_read, 1000);if (ret != ESP_OK) {ESP_LOGE(TAG, "[echo] i2s read failed");abort(); // 终止程序}return ret;
}esp_err_t es8311_play_data(const int16_t *buffer, int buffer_len)
{size_t bytes_written = 0;esp_err_t ret = i2s_channel_write(tx_handle, buffer, buffer_len, &bytes_written, 1000);if (ret != ESP_OK) {ESP_LOGE(TAG, "i2s write failed");return ret;}return ESP_OK;
}void init_driver_es8311(void)
{gpio_config_t io_conf = {};io_conf.intr_type = GPIO_INTR_DISABLE;io_conf.mode = GPIO_MODE_OUTPUT;io_conf.pin_bit_mask = SPKER_CTRL_PIN_SEL;io_conf.pull_down_en = 0;io_conf.pull_up_en = 0;gpio_config(&io_conf);gpio_set_level(SPKER_CTRL_PIN, 1);printf("i2s es8311 codec example start\n-----------------------------\n");/* 初始化I2S外设 */if (i2s_driver_init() != ESP_OK){ESP_LOGE(TAG, "i2s driver init failed");abort(); // 终止程序}else{ESP_LOGI(TAG, "i2s driver init success");}/* 初始化I2C外设并配置ES8311编解码器 */if (es8311_codec_init() != ESP_OK){ESP_LOGE(TAG, "es8311 codec init failed");abort(); // 终止程序}else{ESP_LOGI(TAG, "es8311 codec init success");}
}
main.c
#include <stdio.h>
#include <stdlib.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "esp_wn_iface.h"
#include "esp_wn_models.h"
#include "esp_afe_sr_models.h"
#include "esp_mn_iface.h"
#include "esp_mn_models.h"
#include "model_path.h"
#include "string.h"#include "driver_es8311.h"int detect_flag = 0; // 检测标志,初始为0
static esp_afe_sr_iface_t *afe_handle = NULL; // AFE 处理接口句柄
static volatile int task_flag = 0; // 任务标志,用于控制任务的运行// 任务:从麦克风获取音频数据并喂给 AFE 处理
void feed_Task(void *arg)
{esp_afe_sr_data_t *afe_data = arg; // 获取 AFE 数据结构int audio_chunksize = afe_handle->get_feed_chunksize(afe_data); // 获取每次喂给 AFE 的音频块大小int nch = afe_handle->get_feed_channel_num(afe_data); // 获取音频通道数int feed_channel = es8311_get_feed_channel(); // 获取实际的音频通道数assert(nch == feed_channel); // 确保通道数匹配// 分配内存以存储音频数据块int16_t *i2s_buff = malloc(audio_chunksize * sizeof(int16_t) * feed_channel);assert(i2s_buff);while (task_flag){ // 当任务标志为1时,持续运行// 从麦克风获取音频数据es8311_get_feed_data(true, i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel);// 将音频数据喂给 AFE 处理afe_handle->feed(afe_data, i2s_buff);}// 释放内存if (i2s_buff){free(i2s_buff);i2s_buff = NULL;}// 删除任务vTaskDelete(NULL);
}// 任务:检测唤醒词
void detect_Task(void *arg)
{esp_afe_sr_data_t *afe_data = arg; // 获取 AFE 数据结构int afe_chunksize = afe_handle->get_fetch_chunksize(afe_data); // 获取每次从 AFE 获取的音频块大小int16_t *buff = malloc(afe_chunksize * sizeof(int16_t)); // 分配内存以存储音频数据块assert(buff);printf("------------detect start------------\n");while (task_flag){ // 当任务标志为1时,持续运行// 从 AFE 获取处理结果afe_fetch_result_t *res = afe_handle->fetch(afe_data);if (!res || res->ret_value == ESP_FAIL){printf("fetch error!\n");break;}if (res->wakeup_state == WAKENET_DETECTED) {printf("wakeword detected\n");printf("model index:%d, word index:%d\n", res->wakenet_model_index, res->wake_word_index);printf("-----------LISTENING-----------\n");}// if (res->vad_state == VAD_SILENCE)// {// printf("VAD_SILENCE\n");// }// else if (res->vad_state == VAD_SPEECH)// {// printf("VAD_SPEECH\n");// }}// 释放内存if (buff){free(buff);buff = NULL;}// 删除任务vTaskDelete(NULL);
}void app_main()
{// 初始化音频板,设置采样率为16000 Hz,单声道,位深为16位init_driver_es8311();// 初始化声学前端(AFE)模型,存储到分区表的model分区srmodel_list_t *models = esp_srmodel_init("model");if (models){for (int i = 0; i < models->num; i++){if (strstr(models->model_name[i], ESP_WN_PREFIX) != NULL){printf("wakenet model in flash: %s\n", models->model_name[i]);}}}//"MR":声学前端模型名称,模型具体参考https://docs.espressif.com/projects/esp-sr/zh_CN/latest/esp32s3/benchmark/README.html// M:麦克风通道 R:播放参考通道 N:未使用或未知通道 MRNN代表一个麦克风通道、一个播放通道// models:声学前端和麦克风唤醒模型列表。// AFE_TYPE_VC :用于语音通话降噪 AFE_TYPE_SR:用于语音识别。// AFE_MODE_LOW_COST:AFE 模式,低功耗模式。afe_config_t *afe_config = afe_config_init("MR", models, AFE_TYPE_SR, AFE_MODE_LOW_COST);// print/modify wake word model.if (afe_config->wakenet_model_name){printf("wakeword model in AFE config: %s\n", afe_config->wakenet_model_name);}if (afe_config->wakenet_model_name_2){printf("wakeword model in AFE config: %s\n", afe_config->wakenet_model_name_2);}afe_handle = esp_afe_handle_from_config(afe_config);esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(afe_config);afe_config_free(afe_config); // 释放 AFE 配置内存task_flag = 1; // 设置任务标志为1,启动任务// 创建音频采集任务,运行在核心0xTaskCreatePinnedToCore(&feed_Task, "feed", 8 * 1024, (void *)afe_data, 5, NULL, 0);// 创建检测唤醒词任务,运行在核心1xTaskCreatePinnedToCore(&detect_Task, "detect", 4 * 1024, (void *)afe_data, 5, NULL, 1);
}音频减噪功能实现
新建工程,添加sr组件
idf.py add-dependency "espressif/esp-sr^2.0.2"
idf.py add-dependency "espressif/es8311^1.0.0"添加自定义分区表
# Espressif ESP32 Partition Table
# Name, Type, SubType, Offset, Size
factory, app, factory, 0x010000, 2500k
model, data, spiffs, , 5168K,最终main.c
#include <stdio.h>
#include <stdlib.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "esp_wn_iface.h"
#include "esp_wn_models.h"
#include "esp_afe_sr_models.h"
#include "esp_mn_iface.h"
#include "esp_mn_models.h"
#include "model_path.h"
#include "string.h"#include "driver_es8311.h"int detect_flag = 0; // 检测标志,初始为0
static esp_afe_sr_iface_t *afe_handle = NULL; // AFE 处理接口句柄
static volatile int task_flag = 0; // 任务标志,用于控制任务的运行// 任务:从麦克风获取音频数据并喂给 AFE 处理
void feed_Task(void *arg) {esp_afe_sr_data_t *afe_data = arg; // 获取 AFE 数据结构int audio_chunksize = afe_handle->get_feed_chunksize(afe_data); // 获取每次喂给 AFE 的音频块大小int nch = afe_handle->get_feed_channel_num(afe_data); // 获取音频通道数int feed_channel = es8311_get_feed_channel(); // 获取实际的音频通道数assert(nch == feed_channel); // 确保通道数匹配// 分配内存以存储音频数据块int16_t *i2s_buff = malloc(audio_chunksize * sizeof(int16_t) * feed_channel);assert(i2s_buff);while (task_flag) { // 当任务标志为1时,持续运行// 从麦克风获取音频数据es8311_get_feed_data(true, i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel);// 将音频数据喂给 AFE 处理afe_handle->feed(afe_data, i2s_buff);}// 释放内存if (i2s_buff) {free(i2s_buff);i2s_buff = NULL;}// 删除任务vTaskDelete(NULL);
}// 任务:音频处理结果
void detect_Task(void *arg) {esp_afe_sr_data_t *afe_data = arg; // 获取 AFE 数据结构int afe_chunksize = afe_handle->get_fetch_chunksize(afe_data); // 获取每次从 AFE 获取的音频块大小int16_t *buff = malloc(afe_chunksize * sizeof(int16_t)); // 分配内存以存储音频数据块assert(buff);printf("------------detect start------------\n");while (task_flag) { // 当任务标志为1时,持续运行// 从 AFE 获取处理结果afe_fetch_result_t* res = afe_handle->fetch(afe_data);if (res && res->ret_value != ESP_FAIL) {memcpy(buff, res->data, afe_chunksize * sizeof(int16_t));// 在这里使用算法处理后的音频,存储到本地或者上传云端//data = buff,len = afe_chunksize * sizeof(int16_t)}}// 释放内存if (buff) {free(buff);buff = NULL;}// 删除任务vTaskDelete(NULL);
}void app_main() {// 初始化音频板,设置采样率为16000 Hz,单声道,位深为16位init_driver_es8311();// 初始化声学前端(AFE)模型,存储到分区表的model分区srmodel_list_t *models = esp_srmodel_init("model");if (models) {for (int i=0; i<models->num; i++) {if (strstr(models->model_name[i], ESP_WN_PREFIX) != NULL) {printf("wakenet model in flash: %s\n", models->model_name[i]);}}}//"MR":声学前端模型名称,模型具体参考https://docs.espressif.com/projects/esp-sr/zh_CN/latest/esp32s3/benchmark/README.html。//models:声学前端和麦克风唤醒模型列表。//AFE_TYPE_VC :用于语音降噪。//AFE_MODE_LOW_COST:AFE 模式,低功耗模式。afe_config_t *afe_config = afe_config_init("MR", models, AFE_TYPE_VC, AFE_MODE_LOW_COST);afe_handle = esp_afe_handle_from_config(afe_config);esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(afe_config);afe_config_free(afe_config); // 释放 AFE 配置内存task_flag = 1; // 设置任务标志为1,启动任务// 创建音频采集任务,运行在核心0xTaskCreatePinnedToCore(&feed_Task, "feed", 8 * 1024, (void*)afe_data, 5, NULL, 0);// 创建检测唤醒词任务,运行在核心1xTaskCreatePinnedToCore(&detect_Task, "detect", 4 * 1024, (void*)afe_data, 5, NULL, 1);
}默认启用:
如果应用涉及 Wi-Fi 或网络通信,
建议默认开启 WIFI_IRAM_OPT 和 LWIP_IRAM_OPTIMIZATION。
按需启用 WIFI_RX_IRAM_OPT:仅在需要 极低延迟接收
或 Wi-Fi/BLE 并发 时启用WIFI_STATIC_RX_BUFFER_NUM 16 24 静态 Wi-Fi 接收缓冲区数量
WIFI_DYNAMIC_RX_BUFFER_NUM 32 64 动态 Wi-Fi 接收缓冲区数量
WIFI_STATIC_TX_BUFFER_NUM 16 24 静态 Wi-Fi 发送缓冲区数量
WIFI_RX_BA_WIN 16 32 Block Ack 窗口大小 影响吞吐量,不占内存
LWIP_UDP_RECVMBOX_SIZE 6 64 16