数据导入技术(文档加载)
1. 简单文本的读取
用LangChain读入txt文档
# 读取单个txt文件
import os
from langchain_community.document_loaders import TextLoader
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
file_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空/设定.txt')
loader = TextLoader(file_dir)
documents = loader.load()
print(documents)
langchain会将文档转换为Document对象
LangChain Document对象和其中的元数据

LangChain中的各种Loader
Providers | 🦜️🔗 LangChain
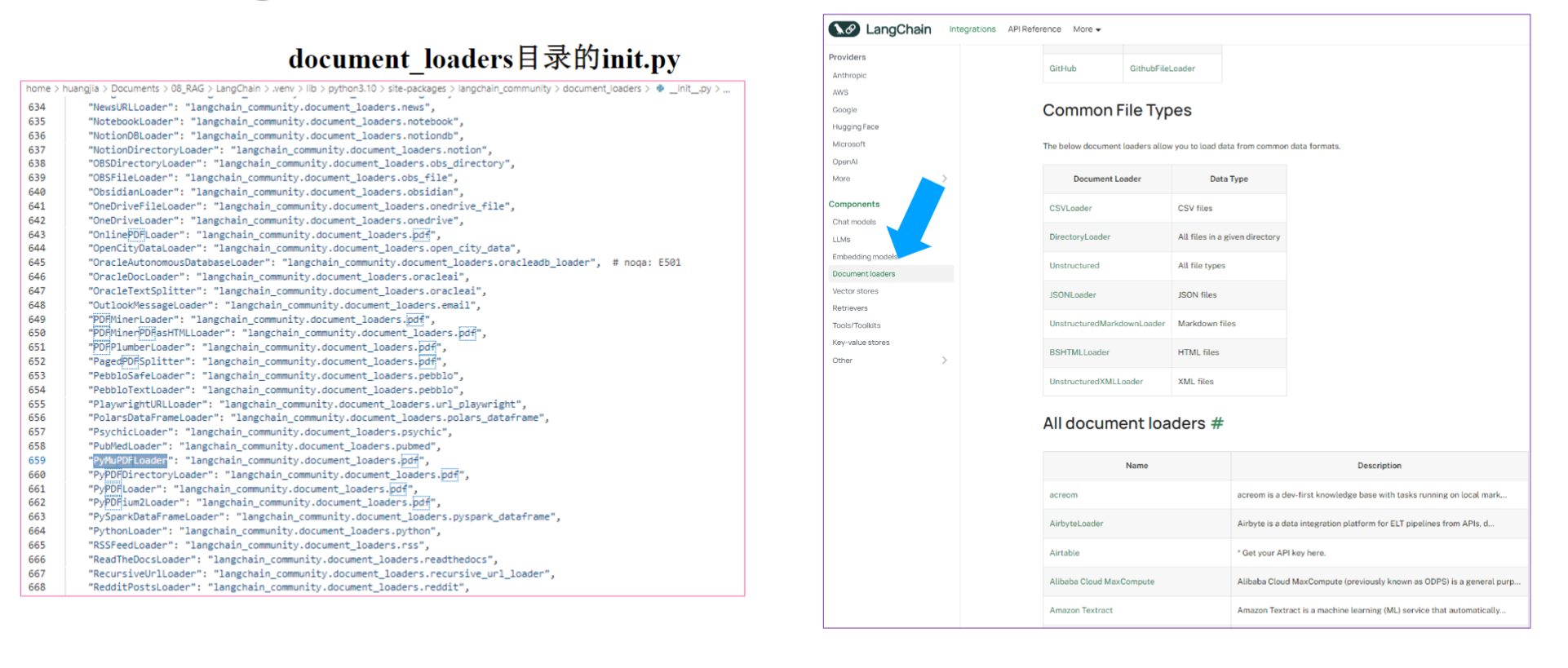
用LangChain读取目录中的所有格式类型文档

pip install unstructured
pip install "unstructured[image]"
pip install "unstructured[md]"
sudo apt-get install tesseract-ocr
pip install pytesseract
用LangChain不同的Loader解析结果不同
from langchain_community.document_loaders import DirectoryLoader, TextLoaderimport os
# 获取当前脚本文件所在的目录
script_dir = os.path.dirname(__file__)
print(f"获取当前脚本文件所在的目录:{script_dir}")
# 结合相对路径构建完整路径
data_dir = os.path.join(script_dir, '../../90-文档-Data/黑悟空')# 加载目录下所有 Markdown 文件
loader = DirectoryLoader(data_dir,glob="**/*.md",#loader_cls=TextLoader # 指定加载工具)
docs = loader.load()
print(docs[0].page_content[:100]) # 打印第一个文档内容的前100个字符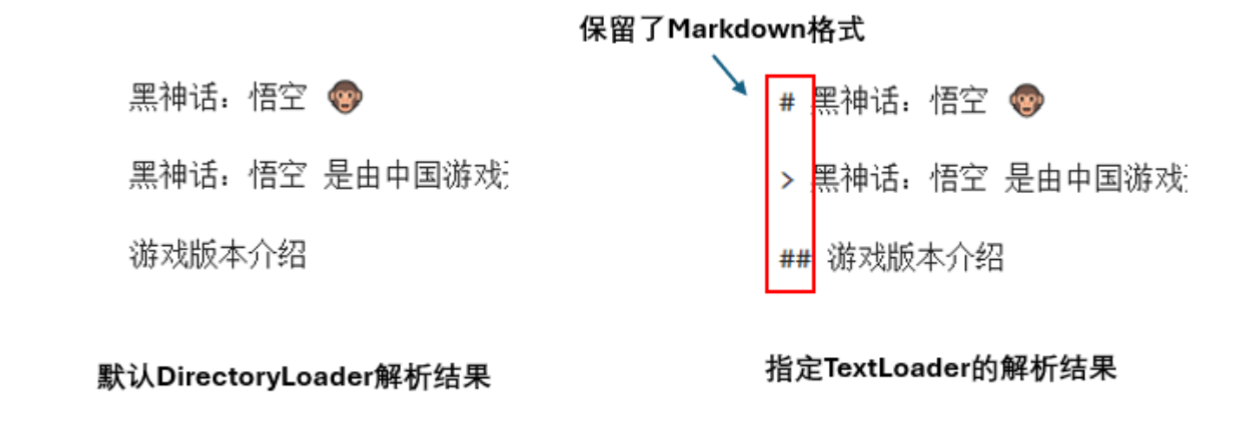
用LlamaIndex读取目录中的所有文档
from llama_index.core import SimpleDirectoryReader
# 使用 SimpleDirectoryReader 加载目录中的文件
dir_reader = SimpleDirectoryReader("90-文档-Data/黑悟空")
documents = dir_reader.load_data()
# 查看加载的文档数量和内容
print(f"文档数量: {len(documents)}")
print(documents[0].text[:100]) # 打印第一个文档的前100个字符# 仅加载某一个特定文件
dir_reader = SimpleDirectoryReader(input_files=["data/黑神话/黑神话悟空的设定.txt"])
documents = dir_reader.load_data()
print(f"文档数量: {len(documents)}")
print(documents[0].text[:100]) # 打印第一个文档的前100个字符用Unstructured工具读取各式类型的文档
Partitioning - Unstructured
Unstructured工具会将文档转换为element格式
from unstructured.partition.text import partition_text
text = "data/黑神话/黑神话悟空的设定.txt"
elements = partition_text(text)
for element in elements:
print(element)
LangChain集成了各种Unstructured Loader
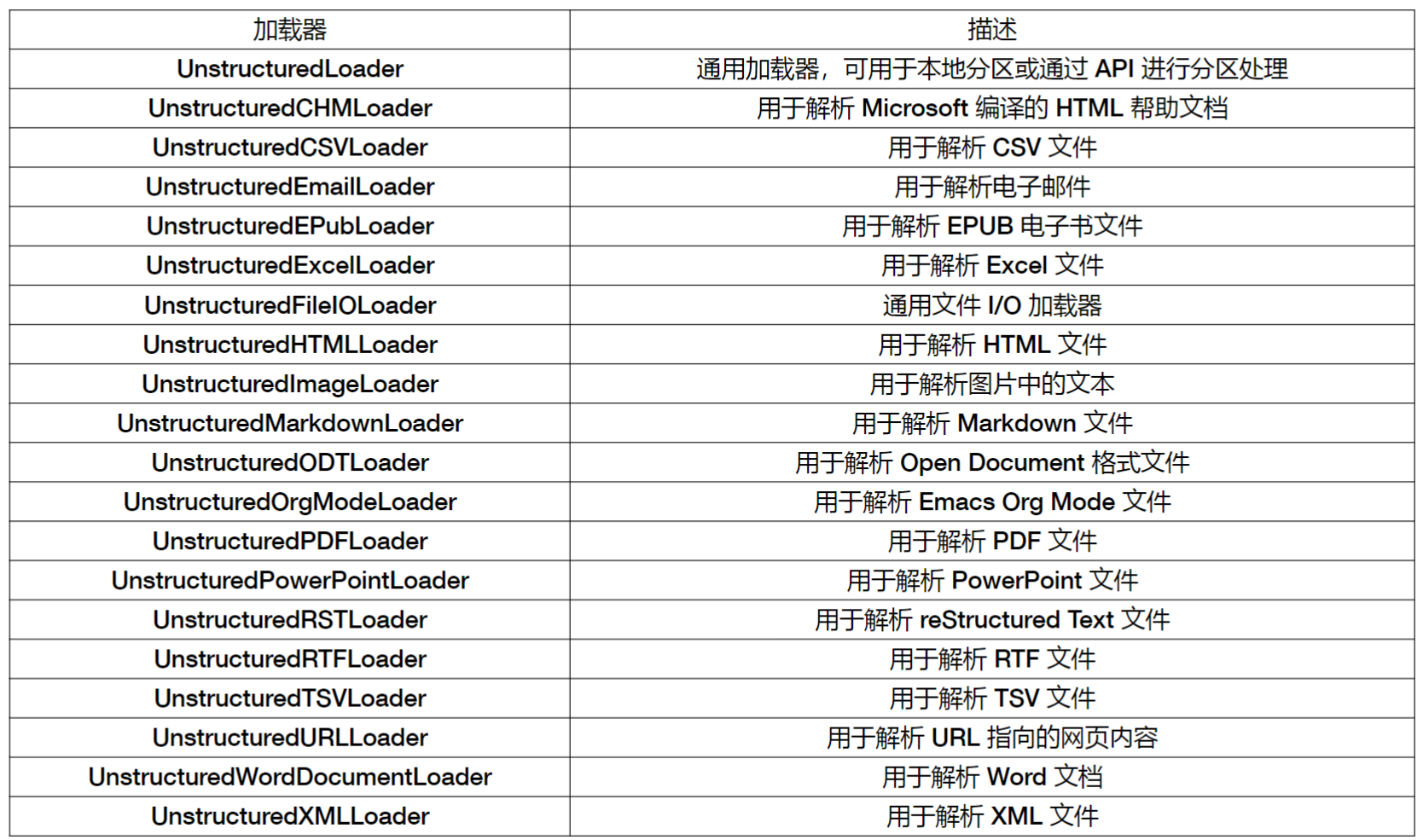
2. 结构化文本的读取(JSON\网页\Markdown)
使用LangChain的JSON Loader

- 当输入数据为 JSON 格式时,若需从嵌套复杂的 JSON 中提取特定字段或结构,可通过
jq_schema定义提取规则(类似 SQL 查询或 JSONPath 表达式)。
LangChain中的各种网页加载器
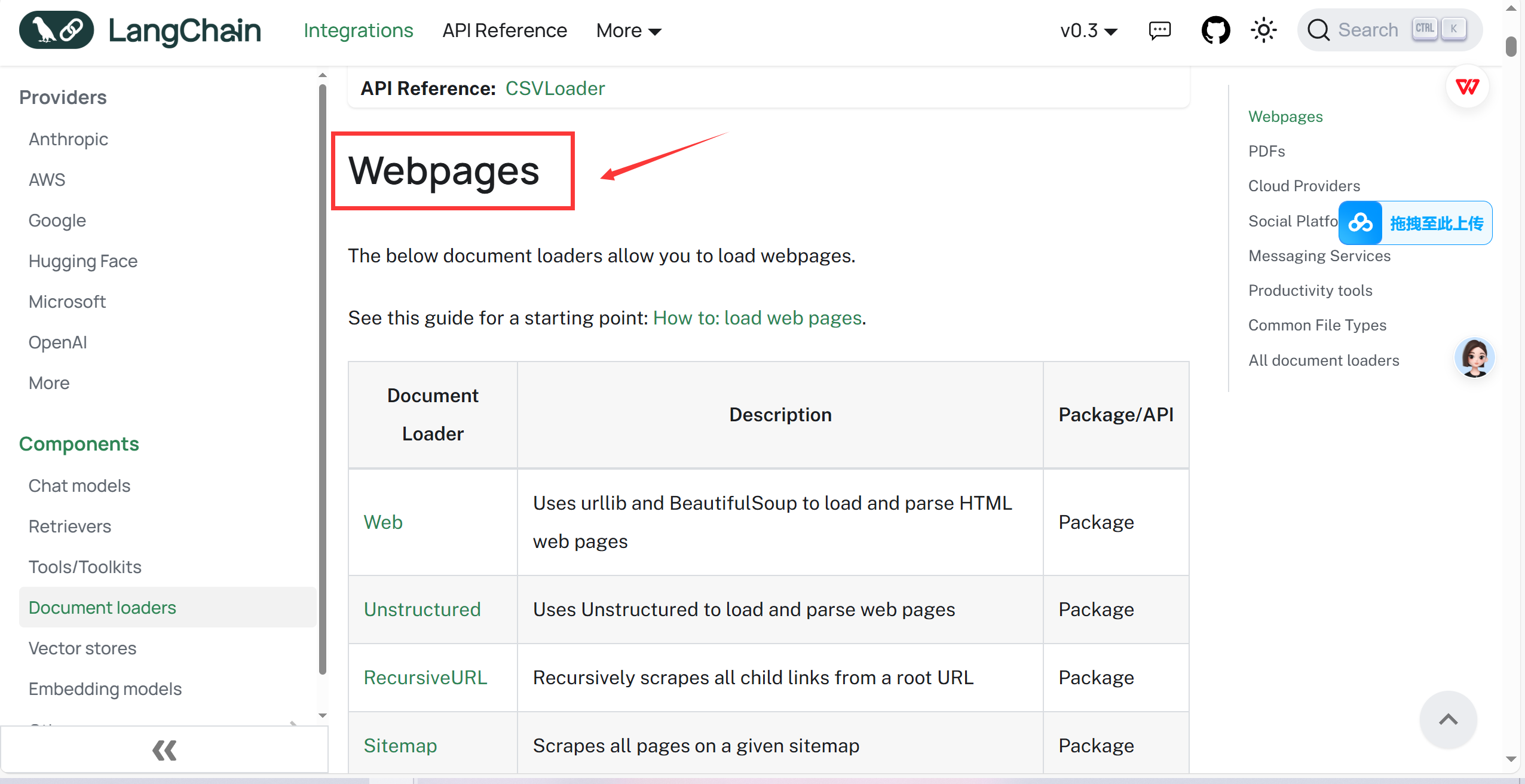
#WebBaseLoader
#UnstructuredLoader
UnstructuredLoader – 父子元素的链接
from langchain_unstructured import UnstructuredLoader
from typing import List
from langchain_core.documents import Document
page_url = "https://zh.wikipedia.org/wiki/黑神话:悟空"
def _get_setup_docs_from_url(url: str) -> List[Document]:
loader = UnstructuredLoader(web_url=url)
setup_docs = []
# parent_id = None # 初始化 parent_id
# current_parent = None # 用于存储当前父元素
for doc in loader.load():
# 检查是否是 Title 或 Table
if doc.metadata["category"] == "Title" or doc.metadata["category"] == "Table":
parent_id = doc.metadata["element_id"]
current_parent = doc # 更新当前父元素
setup_docs.append(doc)
elif doc.metadata.get("parent_id") == parent_id:
setup_docs.append((current_parent, doc)) # 将父元素和子元素一起存储
return setup_docs
docs = _get_setup_docs_from_url(page_url)
for item in docs:
if isinstance(item, tuple):
parent, child = item
print(f'父元素 - {parent.metadata["category"]}: {parent.page_content}')
print(f'子元素 - {child.metadata["category"]}: {child.page_content}')
else:
print(f'{item.metadata["category"]}: {item.page_content}')
print("-" * 80)