NLP学习路线图(三十一): 迁移学习在NLP中的应用
迁移学习(Transfer Learning) 的引入,犹如为NLP领域注入了一剂强心针。其核心思想是将从一个任务(源任务)中学到的知识(如对语言结构、词汇含义的理解)迁移到另一个相关但数据可能稀缺的新任务(目标任务)上,从而显著提升新任务的性能和学习效率。而在NLP领域,预训练语言模型(Pre-trained Language Models, PLMs) 已成为实现大规模、高效迁移学习的最强大载体。
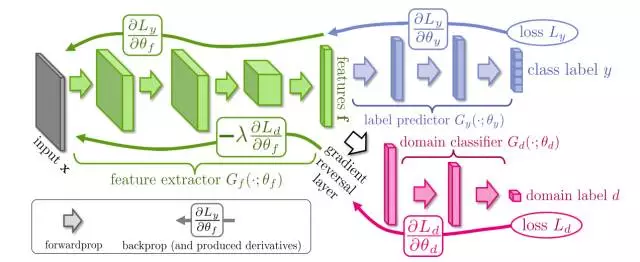
一、预训练语言模型:迁移学习的超级引擎
预训练语言模型的核心范式是 “预训练 + 微调” (Pre-training + Fine-tuning):
-
预训练 (Pre-training):
-
目标: 在大规模、无标注的通用文本语料库(如整个维基百科、海量网页文本、书籍)上训练一个模型。
-
任务: 模型被设计来学习语言本身的内在规律和通用知识。常见的自监督预训练任务包括:
-
掩码语言建模 (Masked Language Modeling, MLM): 随机遮盖输入句子中的部分单词(如15%),让模型预测被遮盖的单词是什么(BERT的核心任务)。这迫使模型深刻理解单词的上下文含义。
-
下一句预测 (Next Sentence Prediction, NSP): 判断两个句子是否在原文中连续出现(BERT)。这帮助模型学习句子间的关系和连贯性。
-
自回归语言建模 (Autoregressive Language Modeling): 给定前面的单词序列,预测下一个最可能出现的单词(GPT系列模型的核心任务)。这侧重于学习文本生成的模式和单向上下文依赖。
-
去噪自编码 (Denoising Autoencoding): 对输入文本加入噪声(如随机遮盖、打乱顺序、删除部分词),让模型恢复原始文本(如BART, T5)。
-
-
-
微调 (Fine-tuning):
-
目标: 将预训练好的模型适配到特定的下游NLP任务上。
-
过程:
-
在预训练模型(通常保留其核心结构,如Transformer层)的基础上,根据任务需求添加一个小的任务特定层(如一个用于分类的全连接层、一个用于序列标注的CRF层、或用于问答的指针网络)。
-
使用相对较小规模的下游任务标注数据集(可能是几百或几千条,远小于预训练数据)。
-
在下游任务数据上对整个模型(包括预训练参数和新添加的任务层)进行进一步的训练。
-
-
二、预训练语言模型的演化之路
-
词嵌入时代 (Word Embedding Era - 基石):
-
代表:Word2Vec (Skip-gram, CBOW), GloVe, FastText。
-
贡献:将离散的单词映射到连续的、稠密的低维向量空间(词向量),能捕捉基本的语义相似性(“国王” - “男人” + “女人” ≈ “王后”)。
-
局限:静态表征 - 每个单词只有一个固定向量,无法解决一词多义问题(“苹果”在水果和公司语境下含义不同)。缺乏对上下文和句子级结构的建模。
-
-
上下文词嵌入时代 (Contextual Word Embedding Era - 重要突破):
-
代表:ELMo (Embeddings from Language Models)。
-
贡献:使用双向LSTM,根据单词的完整上下文生成动态词向量。同一个单词在不同句子中会有不同的向量表示,初步解决了一词多义问题。
-
局限:基于RNN,训练相对较慢,难以捕捉非常长距离的依赖。
-
-
预训练Transformer时代 (Pre-trained Transformer Era - 爆发与统治):
-
里程碑:BERT (Bidirectional Encoder Representations from Transformers):
-
革命性:首次大规模成功应用双向Transformer Encoder进行预训练。
-
核心任务:掩码语言建模(MLM)和下一句预测(NSP)。
-
影响:在众多NLP基准测试上取得突破性提升,确立了“预训练+微调”的标准范式。催生了一系列BERT变体(RoBERTa, DistilBERT, ALBERT等)。
-
-
生成式预训练:GPT (Generative Pre-trained Transformer):
-
路径:基于Transformer Decoder,使用自回归语言建模任务进行预训练(预测下一个词)。
-
特点:强大的文本生成能力。从GPT-1, GPT-2发展到震惊世界的GPT-3(1750亿参数),以及后续的ChatGPT (GPT-3.5/4),展示了大规模自回归模型的惊人涌现能力(Few-shot/Zero-shot Learning)。
-
-
统一文本到文本:T5 (Text-to-Text Transfer Transformer):
-
理念:将所有NLP任务(分类、翻译、摘要、问答等)都统一转化为文本到文本(Text-to-Text)的格式(输入文本,输出文本)。
-
优势:极大简化了模型接口和微调过程,一个模型架构适配几乎所有任务。
-
-
编码器-解码器架构:BART (Denoising Sequence-to-Sequence Pre-training), T5:
-
特点:同时使用Transformer Encoder和Decoder,擅长需要理解输入并生成输出的任务(如摘要、翻译、对话)。
-
-
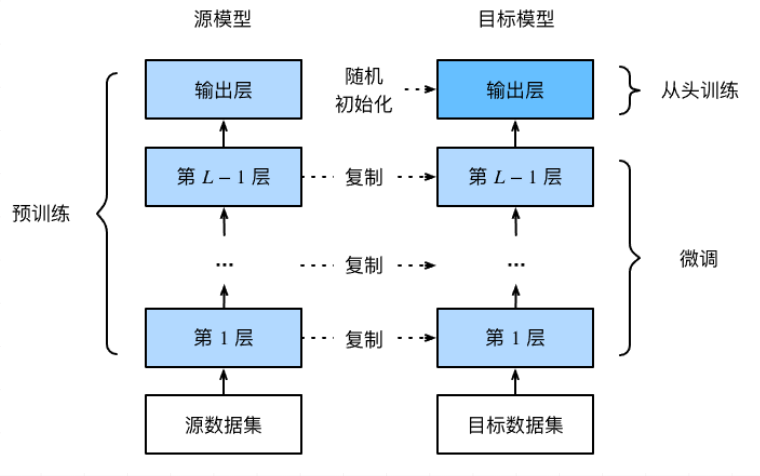
三、迁移学习的魔力:预训练模型如何赋能下游任务
通过微调,预训练语言模型能高效迁移其学到的通用知识,显著提升各种NLP任务的性能:
-
文本分类 (Text Classification):
-
任务:情感分析(正面/负面)、新闻主题分类、垃圾邮件检测等。
-
微调:在预训练模型(如BERT)后添加一个分类层(通常是一个池化层+全连接层),在特定分类数据集上微调。效果远优于传统机器学习方法(如SVM)和浅层神经网络。
-
-
自然语言推理 (Natural Language Inference / Textual Entailment):
-
任务:判断两个句子之间的关系(蕴含、矛盾、中立)。如“Premise: 一个人正在遛狗。 Hypothesis: 有人在户外活动。” 关系应为“蕴含”。
-
微调:将前提句和假设句拼接输入模型(如BERT),添加分类层判断关系。模型需要深入理解语义和逻辑关系。
-
-
命名实体识别 (Named Entity Recognition, NER):
-
任务:识别文本中的人名、地名、组织机构名、时间、金额等实体。
-
微调:模型(如BERT)为输入序列中的每个token预测其所属的实体类型标签(如B-PER, I-PER, O)。模型强大的上下文理解能力对识别歧义实体(如“苹果”是公司还是水果?)至关重要。
-
-
问答系统 (Question Answering, QA):
-
抽取式问答 (Extractive QA): 给定问题和一段上下文,从上下文中抽取出答案片段。
-
微调(如BERT):模型输出答案在上下文中的开始位置和结束位置。需要精确匹配问题和上下文信息。
-
-
生成式问答 (Generative QA): 根据问题和相关知识,生成自然语言形式的答案(不一定直接复制原文)。
-
微调(如T5, GPT):使用Seq2Seq架构,输入“问题:... 上下文:...”,模型生成答案文本。需要更强的理解和生成能力。
-
-
-
文本摘要 (Text Summarization):
-
抽取式摘要 (Extractive): 从原文中抽取关键句子组成摘要。
-
微调:可建模为序列标注(选择哪些句子)或排序问题。
-
-
生成式摘要 (Abstractive): 理解原文核心意思,用新的、更简洁的语言重新表达生成摘要。
-
微调(如BART, T5, PEGASUS):典型的Seq2Seq任务。预训练模型的语言理解和生成能力在此大放异彩。
-
-
-
机器翻译 (Machine Translation, MT):
-
微调(如mT5, mBART, MarianMT):虽然传统MT模型(如基于Transformer的Seq2Seq)本身就需要大量双语语料训练,但在预训练好的多语言Seq2Seq模型(在大量多语言语料上预训练过)基础上进行微调,能显著提升低资源语对的翻译质量,加速模型收敛。大规模预训练模型(如GPT系列)在Few-shot翻译上也展现出潜力。
-
-
情感分析 & 舆情分析 (Sentiment Analysis & Opinion Mining):
-
微调:作为文本分类的特例,预训练模型能精准捕捉文本中细微的情感倾向和观点表达。
-
-
对话系统 (Chatbots & Dialog Systems):
-
微调:基于预训练模型(如DialoGPT, BlenderBot)微调,能生成更流畅、相关、信息丰富的对话回复。
-
四、优势与挑战:理性看待PLM驱动的迁移学习
核心优势
-
大幅提升性能: 在绝大多数NLP任务上,微调预训练模型都显著超越了之前的SOTA方法,有时甚至是飞跃性的提升。
-
降低数据依赖: 微调只需要目标任务的少量标注数据即可达到优异效果,极大缓解了标注数据瓶颈。使得在特定领域(如医疗、金融、法律)快速部署高质量NLP应用成为可能。
-
缩短开发周期: “预训练+微调”范式标准化了开发流程,开发者无需从零开始设计复杂模型,只需选择合适的PLM并进行高效微调。
-
强大的泛化能力: 预训练模型学习到的语言知识具有极强的通用性,使其能够较好地迁移到各种相关甚至未见过的任务和领域(尤其在Few-shot/Zero-shot设置下)。
-
解决一词多义: 动态上下文表征从根本上解决了一词多义问题。
面临的挑战
-
巨大的计算资源消耗: 预训练阶段(尤其是千亿参数级别的大模型)需要海量的计算资源(GPU/TPU集群)和电力,成本高昂,碳排放量大,限制了研究机构的参与。
-
模型规模与推理成本: 大型模型在部署和实时推理时对计算资源和延迟要求高,在资源受限场景(如移动端)应用困难。模型压缩(如蒸馏、量化、剪枝)成为重要研究方向。
-
“黑盒”特性与可解释性差: 大型神经网络内部的决策过程难以理解,模型可能学习到数据中的偏见或做出不可预测的错误判断,在关键领域(如司法、医疗)的应用存在可解释性和可信度挑战。
-
数据偏见放大: 预训练数据来源于互联网,不可避免地包含社会偏见(性别、种族、地域等)。PLM在预训练和微调过程中可能吸收甚至放大这些偏见,导致模型输出不公平或有歧视性结果。去偏见是重要研究课题。
-
知识更新与时效性: 预训练模型的知识“冻结”在预训练数据的时间点。世界在变化(新事件、新术语),模型需要持续更新知识(Continual Learning)或接入外部知识源(如检索增强)。
-
领域迁移的适应性: 虽然PLM通用性强,但在专业性极强的领域(如生物医学文献、法律条文),通用PLM的表现可能不够理想,仍需领域适配(Domain Adaptation)或领域预训练。
-
灾难性遗忘: 在微调模型适应新任务或新数据时,可能会损害其在之前任务上学到的性能。持续学习技术仍需发展。