mitmproxy 爬虫,下载自己的博客图片
1. 起因, 目的:
- 打算把 mitmproxy 作为爬虫的主力工具,简单,强大,简直就是一辆会飞的坦克,还要啥自行车。
- 打算先写10个爬虫,即 ,10 小例子 ,找找手感,后面再搭建大一点的系统。
2. 先看效果
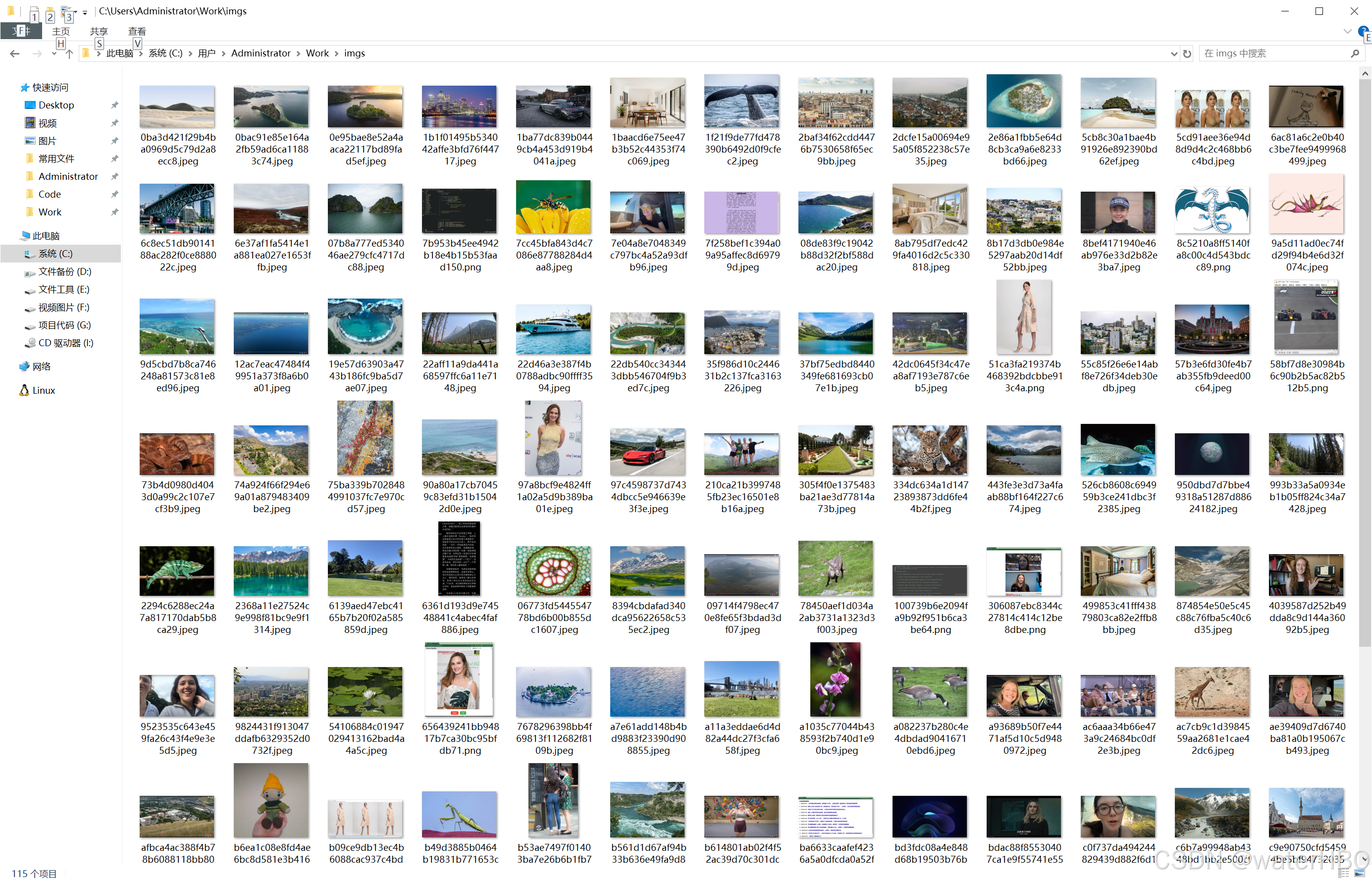
3. 过程:
分2步走
1. 开启 mitmweb
import os
import requests
from mitmproxy import http"""
# 帮我写个脚本把图片下载下来
mitmweb -s get_imgs.py
# 当我运行这个命令的时候,
# 可以把图片下载到当前目录下 , imgs/ 目录下
"""def response(flow: http.HTTPFlow) -> None:# 检查 imgs 文件夹是否存在,如果不存在则创建它if not os.path.exists("imgs"):os.makedirs("imgs")# 判断响应的内容类型是否为图片if flow.response.headers.get("Content-Type", "").startswith("image/"):# 获取图片的文件名filename = flow.request.url.split("/")[-1]# 确保文件名不为空,防止异常if filename:path = os.path.join("imgs", filename)with open(path, "wb") as f:f.write(flow.response.content)mitmweb -s get_imgs.py
2. 第二部分,点击自动滚动按钮。
- 使用我自己写的一个浏览器插件,我前面的博客中提到过,读者可以找找看。
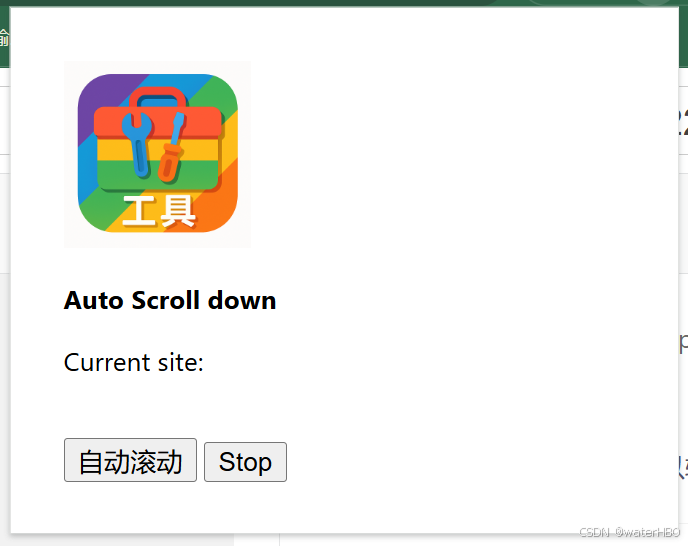
剩下的就是,坐等图片飞到本地文件夹。
3. 删掉一些小图片,这个很简单
import osdef delete_images(folder, kb_limit=200):total = os.listdir(folder)print(f"删除之前,图片数量是: {len(total)}")for img in os.listdir(folder):img_file = os.path.join(folder, img)# print(img_file)bytes_size = os.path.getsize(img_file)kb_size = int(bytes_size / 1024)if kb_size < kb_limit:os.remove(img_file)after = os.listdir(folder)print(f"删除之后,图片数量是: {len(after)}")if __name__ == '__main__':# 在这里传入文件夹的名称folder_name = r" C:\Users\Administrator\Work\mitm\imgs ".strip()delete_images(folder_name, kb_limit=200)
4. 结论 + todo
- 对于这个 浏览器插件, 我需要增加几个按钮,即,调整页面滚动的速度,1倍,2倍,5倍。
希望对大家有帮助。