软件测试python学习
文章目录
- 一、可变参数
- 参数的正确顺序
- 正确的顺序
- 示例
- 调用示例
- 错误的顺序示例
- 示例 1:默认参数在普通位置参数之前
- 示例 2:可变位置参数在默认参数之后
- 示例 3:可变关键字参数不在最后
- 实参的顺序规则
- 正确的调用顺序
- 示例
- 正确的调用方式
- 错误的调用方式
- 示例 1:关键字参数在位置参数之前
- 示例 2:跳过某些普通位置参数
- 示例 3:位置参数和关键字参数冲突
- 总结
- 二、面向对象
- 1.创建类
- 2.类属性和类方法
- ==总结==
- 3.封装
- 4.继承与多级继承
- 5.多继承
- 6.方法重写
- 7.多态
- 三、模块及导包
- 1.导包
- 步骤 2:修正 `__init__.py`
- 步骤 3:确保 `all.py` 中的函数定义正确
- 步骤 4:外部调用方式
- 关键原理说明
- 常见问题排查
- 最终代码结构
- 四、PyMysql数据库的连接
- 五、文件处理
- 1.excel的操作
- 2.编写函数(处理excel表格)
- 3.异常处理
- 4.文件的读取
- 5.Json处理
- 六、系统库获取路径
- 七、Pytest使用
- 1.pytest的命名规则
- 2.配置文件
- 3.条件跳过与无条件跳过
- 4.测试用例的执行顺序
- 5.断言
- 6.参数化
- 7.夹具
- 1>unittest的夹具
- 2>Pytest自己的夹具
- tset_fixtrue.py文件
- conftest.py文件
- 八、allure
- 1. mian.py
- 2. allure 注解使用
- 没有发现测试解决办法
- UI自动化
- 1.什么项目适合做ui自动化测试?
- 2.selenium工作原理
- 3.浏览器驱动安装
- 面试题
- 1.Python基本数据类型有哪些?
- 2.数据类型之间怎么转换的?
- 3.变量的命名规则
- 4.Python的关键字有哪些?
- 5.列表的插入和删除方式有哪些?
- 6.字典的插入和删除方式有哪些?
- 集合的增加和删除方式有哪些?
- 7.列表的去重有哪些方式?
- 8.break与continue的区别?(怎么跳出循环?怎么终止循环的?)
- 9.冒泡排序的原理?(有没有写过排序算法?)
- 10.python是怎么生成随机数的?
- 11.列表与元组的区别?
- 12.列表与集合的区别?
- 13.元组跟集合的区别?
- 14.python中不可变的数据类型
- 15.python中可变类型有哪些
- 16.常用函数有哪些
- 17.列表跟字典的区别?
- 18.截取字符串怎么使用?
- 19.全局变量与局部变量区别?
- 20.形参跟实参的区别?
- 21.怎么把局部变量变成全局变量?
- 22.我们有哪些装饰器?
- 23.python中is与==的区别?
- 24.面向对象的三大特点(特性)?
- 25.什么是继承?
- 26.什么是重写?重写的前提是啥?
- 27.pyton自带的库有哪些(你常用的库有哪些?)
- 28.python用的版本是哪个版本?
- 29.你用Python做过哪些工具?
- 30.python如何操作数据库?
- 32.json与python字典怎么相互转换?
- 33.python的深拷贝与浅拷贝的区别?
- 34.对pytest了解吗?
- 35.pytest的命令规则?
- 36.使用过pytest哪些装饰器?
- 37.有对pytest的夹具了解过吗,使用过吗,请说一下
- 38.自动化中怎么做断言的?
- 39.python你觉得你学的怎么样?
- 40.python什么时候接触的?
- 41.对python了解吗?从哪里了解的?你都学了哪些东西?
- 42.为什么要用函数?
- 43.什么是匿名函数
- 44.静态方法和类方法的区别
- 45.python怎么读取表格
- UI自动化面试题
- 1.UI(web)自动化测试是怎么做的?
- 2.元素的定位有哪些? 你常用哪些进行定位
- 3.而对于动态 id 你是怎么解决的?
- 4.元素的状态都有哪些?怎么判断元素状态?
- 5.怎么对测试报告进行分析
- 6.元素等待有哪几种方式?怎么使用的?
- 6.显式等待和隐式等待的区别
- 7.对于frame你是怎么处理的?
- 8.怎么处理弹出框的?
- 9.UI(web)自动化测试过程中遇到的异常有哪些?
- 10.对于不可见的元素,你如何定位,如何处理?
- 11.定位不到元素,你碰到过那些,怎么解决?
- 12.如何处理下拉菜单?
- 13.在自动化中,如何处理验证码
- 14.对于生成的自动化测试报告如何分析?
- 15.怎么提高自动化测试的稳定性(自动化稳定性)
- 16.什么是po模式
一、可变参数
1.普通参数(没有默认值的形参):必须在有默认参数的前面。默认值形参后不能跟非默认值参数
2.默认值参数
1>在可变参数之后,我们调用时,需要使用关键子参数
2>在可变参数之前,我们调用时,使用位置参数即可
3.可变参数 (接收的结果是元组类型)
1>一般不会放在第一位,原因:如果放到第一位,普通参数将拿不到值
2>可变参数放在默认参数之前,调用时需要在可变参数后,使用关键字传参
3>可以放在默认参数后,在调用时使用位置传参
4>可变参数是由位置实参转变过来的
5>默认值传参,如果要传值只能使用关键字实参(必须在位置实参之后)
4.字典参数 (接收的结果是字典类型)
只能放在最后面,调用时,使用关键字传参,自动变为字典
字典参数是由关键字实参传递过来的
字典参数在定义时在形参的后面
# 个数可变的关键字参数
def fun2(a,b=12,*args,**kwpara):print(kwpara)print(a)print(b)print(args)print(*args) # 解包# 调用
fun2(12,23,234,234,234,234,name='娟子姐',age=18,height=170) # 关键字参数
参数的正确顺序
在定义函数时,参数的顺序必须遵循以下规则:
-
普通位置参数(必选参数)
- 这些参数是函数调用时必须提供的参数。
- 它们不能有默认值。
-
默认参数(可选参数)
- 这些参数可以有默认值,调用函数时可以省略这些参数。
- 默认参数必须放在普通位置参数之后。
-
可变位置参数(
*args)- 用于接收任意数量的位置参数,存储为元组。
- 它必须放在默认参数之后。
-
可变关键字参数(
**kwargs)- 用于接收任意数量的关键字参数,存储为字典。
- 它必须放在所有其他参数类型之后。
正确的顺序
函数定义中参数的顺序应该是:
普通位置参数 -> 默认参数 -> 可变位置参数 -> 可变关键字参数
示例
以下是一个符合规则的函数定义:
def my_function(a, b=10, *args, **kwargs):print(f"a: {a}, b: {b}")print("位置参数:", args)print("关键字参数:", kwargs)
调用示例
my_function(1) # 调用时只提供普通位置参数
my_function(1, 20) # 提供普通位置参数和默认参数
my_function(1, 20, 3, 4, 5) # 提供普通位置参数、默认参数和可变位置参数
my_function(1, 20, 3, 4, 5, x=6, y=7) # 提供所有类型的参数
错误的顺序示例
以下是一些不符合规则的函数定义示例,会导致语法错误:
示例 1:默认参数在普通位置参数之前
def my_function(b=10, a): # 错误:默认参数不能在普通位置参数之前pass
这会导致语法错误:
SyntaxError: non-default argument follows default argument
示例 2:可变位置参数在默认参数之后
def my_function(a, *args, b=10): # 错误:可变位置参数不能在默认参数之后pass
这会导致语法错误:
SyntaxError: non-default argument follows default argument
示例 3:可变关键字参数不在最后
def my_function(a, **kwargs, *args): # 错误:可变关键字参数不能在可变位置参数之前pass
这会导致语法错误:
SyntaxError: invalid syntax
实参的顺序规则
-
位置参数(Positional Arguments)
- 位置参数是按照函数定义中形参的顺序传递的。
- 位置参数必须按照形参的顺序传递,且数量必须匹配。
- 位置参数不能跳过某些形参,必须连续传递。
-
关键字参数(Keyword Arguments)
- 关键字参数是通过参数名来传递的,因此它们的顺序可以与形参的顺序不同。
- 关键字参数必须在位置参数之后传递。
- 关键字参数可以跳过某些形参,只要这些形参有默认值。
-
可变位置参数(
*args)- 如果函数定义中包含
*args,则在调用函数时,所有多余的未命名的位置参数会被收集到一个元组中。 *args必须在所有普通位置参数之后传递。
- 如果函数定义中包含
-
可变关键字参数(
**kwargs)- 如果函数定义中包含
**kwargs,则在调用函数时,所有多余的未命名的关键字参数会被收集到一个字典中。 **kwargs必须在所有关键字参数之后传递。
- 如果函数定义中包含
正确的调用顺序
调用函数时,实参的顺序应该是:
普通位置参数 -> 关键字参数 -> 可变位置参数(`*args`)-> 可变关键字参数(`**kwargs`)
示例
假设我们有以下函数定义:
def my_function(a, b=10, *args, **kwargs):print(f"a: {a}, b: {b}")print("位置参数:", args)print("关键字参数:", kwargs)
正确的调用方式
# 只传递普通位置参数
my_function(1)# 传递普通位置参数和默认参数
my_function(1, 20)# 传递普通位置参数、默认参数和可变位置参数
my_function(1, 20, 3, 4, 5)# 传递普通位置参数、默认参数和可变关键字参数
my_function(1, 20, x=6, y=7)# 传递普通位置参数、默认参数、可变位置参数和可变关键字参数
my_function(1, 20, 3, 4, 5, x=6, y=7)
错误的调用方式
以下是一些不符合规则的调用示例,会导致错误或不符合预期的行为:
示例 1:关键字参数在位置参数之前
my_function(b=20, 1) # 错误:关键字参数不能在位置参数之前
这会导致语法错误:
SyntaxError: positional argument follows keyword argument
示例 2:跳过某些普通位置参数
my_function(1, 3, 4, 5) # 错误:跳过了默认参数 b
这会导致错误:
TypeError: my_function() missing 1 required positional argument: 'b'
示例 3:位置参数和关键字参数冲突
my_function(1, b=20, 3, 4, 5) # 错误:位置参数和关键字参数冲突
这会导致错误:
SyntaxError: positional argument follows keyword argument
总结
在调用函数时,实参的顺序必须遵循以下规则:
- 普通位置参数(必须按照形参的顺序传递)
- 关键字参数(可以不按顺序传递,但必须在位置参数之后)
- 可变位置参数(
*args,必须在所有普通位置参数和关键字参数之后) - 可变关键字参数(
**kwargs,必须在所有其他参数之后)
遵循这些规则可以确保函数调用的行为符合预期。
二、面向对象
三大特征:封装、继承、多态
1.创建类
"""
万物皆对象创建类
语法:
class 类名: #类名首字母大写类中的方法类中的属性
所有的类都有一个父类 object类中的属性 名词
类中的方法 动词
如果类中的方法第一个参数是self,它就是成员方法;
成员方法的调用:对象名.成员方法名(实参),其中实参不包含self成员变量语法:
我们的成员变量写在def __init__(self)方法内
def __init__(self,成员变量名):self.成员变量名 = 成员变量名/值独有属性/独有变量/私有变量
在创建对象后进行定义
语法:对象名.变量名 = 值成员变量与私有变量的区别
成员变量在__init__方法中声明,每个对象都具有该变量
私有变量在创建对象后声明,只有当前对象具有此变量
定义对象的私有变量时,如果私有变量名与成员变量名相同,视为修改成员变量的值;
如果有私有变量名与成员变量名不相同,视为定义新的私有属性
None含义是为空,表示没有具体的数据取值:对象名.变量名
赋值:对象名.变量名 = 值成员方法调用成员方法:
语法:
def 成员方法名():self.成员方法名(需要调用的)#对象消亡方法
def __del__(self):# 执行后会释放对象占用的内存空间如果对象是局部的,那么函数执行完毕,自动调用对象的de方法
如果对象是全局的,那么程序执行完毕,自动调用对象的Del方法把对象字符串化,如果不写打印的时对象的内存地址 print(t2) <__main__.Teacher object at 0x000002B117B73A30>
如果写这个方法,打印的是返回的信息
def __str__(self):return '指定内容'
print(t2) 指定内容"""class Cat:# def eat(self,a):# print(f'吃{a}')## def sleep(self):# print('睡')## def pao(self):# print('跑')def __init__(self): # 只要为这个类创建对象,默认就会执行这个方法# 所有的成员变量都要写在这个方法内self.name = '波斯猫'self.age = 2print('sadfasdf')# 创建对象 也叫 对象实例化 对象名 = 类名()
# c1 = Cat()
# c1.eat('老鼠') # 成员方法的调用
# print(c1) # <__main__.cat object at 0x00000236D1DEB6D0>
# c2 = Cat()
# c2.eat('猫粮')# c3 = Cat()
# print(c3)
# print(c3.name)# 练习定义一个学生类
class student:def __init__(self, name, age, weight):# 每次创建对象后都会加载self.name = nameself.age = ageself.weight = weight# 成员方法调用成员变量def pri(self):print(f'姓名:{self.name},年龄:{self.age},体重:{self.weight}')# print(s.cloth)# 成员方法调用成员方法def test(self):# 语法:self.成员方法名self.pri()s = student('高凯', 25, 200)
# s.cloth = '栏' # 私有变量(独有属性/独有变量);只属于s,这一个对象
# print(s.cloth)
# s.pri()
# s2 = student('赵辰云', 25, 180)
# s2.pri()
# s.test()# 汽车car
# 属性# 方法class car:def __init__(self,luntai = '橡胶',yanse = '绿色',chuanghu = '防弹',xinghao = '帕拉梅拉'):self.luntai = luntaiself.yanse = yanseself.chuanghu = chuanghuself.xinghao = xinghaodef guadang(self):print('挂挡选择固伦方式')def qianjin(self):self.guadang()print(f'{self.xinghao}的{self.luntai}向前鼓轮')def houtui(self):self.guadang()print(f'{self.luntai}向后鼓轮)')def wurenjiashi(self):print(f'{self.yanse}无人驾驶)')def shache(self):print('shache(刹车)')print('jiayou(加油)')# car1 = car()
# car1.qianjin()class Teacher:def __init__(self,name:str,age:int,height:float,hobby:str):self.name = nameself.age = ageself.height = heightself.hobby = hobbydef eat(self,food:str):print(f'{self.name}喜欢吃{food}')def hit(self):print(f'{self.name}打豆豆'*10)def show(self):print(f'我叫{self.name},爱好是{self.hobby}')# def __del__(self):# print('对象消亡了')def __str__(self):return '指定内容'def myfunc():# 局部对象t3 = Teacher('王老师', 20, 175, '看电影')
#
# t1 = Teacher('王老师', 20, 175, '看电影')
# t1.eat('牛肉')
# t1.hit()
# t1.show()
# t2 = Teacher('张老师', 30, 185, '玩游戏')
# t2.eat('鸡蛋灌饼')
# t2.hit()
# t2.show()
# print(t2)
# print(t2)class Teacher1:def name1(self,name:str = '张三',age:int = 18):self.name = nameself.age = agedef pri(self):print(f'{self.name}打豆豆'*10)te = Teacher1()
# 没有初始化成员变量
# 如果直接调用pri方法会报错,因为找不到self.name,
# 但是如果先调用name1方法,self.name已经被赋值,再调用pri方法,self.name会与name1中的self.name指向同一内存地址
te.name1()
te.pri()
2.类属性和类方法
"""
类属性:
定义:定义在类里面,在方法外部,不使用self进行定义,直接是变量名 = 值
调用:在类中调用:1.成员方法中调用self.类属性2.在类外部调用对象名.类属性类名.类属性 推荐在类方法中调用:cls.类属性类方法:首字母为 @ 符号,就是装饰器定义有 @classmethod 装饰器所修饰第一个参数是cls类方法调用:类属性,类方法,既可以使用对象调用,也可以使用类名调用成员变量,成员方法,只能使用对象调用类中:成员方法可以调用类方法,类属性 通过self来进行调用类外:1、对象名.类方法 -----> 必须先创建对象 c1=Teacher()2、类名.类方法 推荐成员方法内可以调用类方法和类属性,但是类方法内不能调用成员方法和成员变量静态方法:内部不能调用任何内容(方法,类属性,变量),可以通过类名.静态方法在内部实现间接调用成员方法和类方法都可以调用静态方法静态方法和类方法调用的方法相同"""class Teacher:# 类属性student1 = 18def __init__(self, name = '关羽'):self.name = namedef test(self):# 在成员方法中调用类属性print(self.student1)# 类方法@classmethoddef eat(cls):print("这个是类方法")# 类方法调用类属性cls.student1 = 23print(f'类属性{cls.student1}')# 类方法调用静态方法cls.he()# cls.pao() # 类方法不能调用成员方法# cls.name # 类方法不能调用成员变量# 静态方法@staticmethoddef he():print('这是静态方法')# 成员方法def pao(self):print('成员方法调用类方法')# 调用类方法self.eat()print('成员方法调用静态方法')# 调用静态方法self.he()t1 = Teacher()
# print(t1.student1)
# print(Teacher.student1)
# t1.test()
# Teacher.eat()
# t1.eat()
# t1.pao()# 补充
# l1 = [1,2,3]
# l2 = [1,2,3]
# print(id(l1))
# print(id(l2))
# print(l1 is l2)
# print(l1 == l2)class iphone:dianliang = 0@classmethoddef play(cls):if cls.dianliang > 10:cls.dianliang -= 10else:print('电量不足请充电')@classmethoddef yinyue(cls):if cls.dianliang > 5:cls.dianliang -= 5else:print('电量不足请充电')@classmethoddef call(cls):if cls.dianliang > 4:cls.dianliang -= 4else:print('电量不足请充电')@classmethoddef call2(cls):if cls.dianliang > 3:cls.dianliang -= 3else:print('电量不足请充电')@classmethoddef chongdian(cls,a):cls.dianliang += aif cls.dianliang >= 100:cls.dianliang = 100# iphone.dianliang = 100
iphone.dianliang = eval(input('请输入当前手机电量:'))
if iphone.dianliang > 100:print('输入错误')print('请输入你要进行的操作,操作之间用空格隔开')
lst = input('1.打游戏 2.听歌 3.打电话 4.接电话 5.充电').split()# 用于标记是否同时接打电话
biaoji = 0
# 遍历操作
for i in lst:if i == '1':iphone.play()elif i == '2':iphone.yinyue()elif i == '3':if '3' in lst:if '4' in lst:biaoji = 1else:iphone.call()elif i == '4':if '4' in lst:if '3' in lst:biaoji = 1else:iphone.call2()elif i == '5':n = eval(input('请输入要冲入的电量:'))iphone.chongdian(n)else:print('输入错误')# 打印结果
if biaoji == 1:print('不能同时接打电话')
else:print(f"当前电量剩余:{iphone.dianliang}")
总结
"""
总结:
定义:
类属性:定义在类中,方法之外
类方法:定义在类中,使用@classmethod装饰器修饰,第一个参数是cls
成员属性/成员方法:定义在类中,第一个参数是self
静态方法:定义在类中,使用@staticmethod装饰器来修饰
调用:
类中:
成员方法:可以调用所有的方法和属性,通过self调用
类方法:可以调用类属性,静态方法,通过cls调用
静态方法:不能调用任何的方法和属性。可以间接调用,通过类名.方法名/属性名。通常用作工具
类外:
成员方法/成员属性:通过对象进行调用,对象名.成员方法/成员属性
类属性/类方法/静态方法:通过类名调用,类名.类属性/类方法/静态方法;也可以通过对象记性调用,对象名.类属性/类方法/静态方法
"""class Dog:# 类属性age = 20# 成员变量也叫成员属性def __init__(self,name):self.name = name# 静态方法@staticmethoddef drink():print('这是一个静态方法')# 成员方法def eat(self):print('这是一个成员方法')# 类方法@classmethoddef sleep(cls):print('这是一个类方法')d1 = Dog('小黑')
d1.sleep()
d1.drink()
3.封装
"""
封装:
类的私有属性、方法语法:self.__变量名 = 值def __方法名():...类的私有属性、方法语法:只能在类的内部使用目的: 为了数据的安全性,但是python的封装,只是为了有这个特点,可封可不封
不让类的外部随便使用或者看到类的属性
我们需要创建公有的方法来修改私有的属性"""class people:def __init__(self,name = '张三'):self.__name = namedef func1(self):# 在类中调用私有变量print(self.__name)def __func2(self):print('这是私有方法')# 给私有变量设置值的公有方法def set_name(self,name):# 通过set_name方法设置私有变量self.__name的值self.__name = name# 去值的公有方法def get_name(self):# 通过get_name方法取出私有变量self.__name的值return self.__namep1 = people('第三方')
p1.func1()
print(p1.get_name())
p1.set_name('使用更改的方法')
print(p1.get_name())
# p1.__name # 报错,私有属性无法调用
# p1.__func2() # 报错,私有方法无法调用
4.继承与多级继承
"""
继承:
语法:
class 子类(父类):...注意:子类只能继承父类的非私有的属性和方法多级继承类C继承了类A,类D继承了类C类D间接继承了类A"""class A():def __init__(self):self.name = '关羽'self.__name1 = '张飞'# 共有方法def fun1(self):print('这是A父类共有的方法')# 私有方法def __fun2(self):print('这是A父类私有的方法')class B(A):def __init__(self):super().__init__()self.sex = '男'def eat(self):print('这是B子类自己的方法')class C(A):def __init__(self):super().__init__()self.sex1 = '女'def eat1(self):print('这是C子类自己的方法')# 多级继承
class D(C):def __init__(self):super().__init__()self.sex1 = '女'def eat2(self):print('这是D子类自己的方法')b1 = B()
print(b1.name)
b1.fun1()
b1.eat()
print(b1.sex)c1 = C()
c1.eat1()d1 = D()
d1.fun1()
d1.eat1()
d1.eat2()
5.多继承
"""
多继承
class 子类(父类1,父类2,父类3 ...)多继承关系中,当多个父类具有同名的成员,子类调时该成员时先调用继承关系中的第一个声明的类的成员"""class Father:def eat(self):print('吃肉')def hejiu(self):print('喝酒')class Mother:def eat(self):print('吃蔬菜')def sleep(self):print('睡觉')class Son(Mother,Father):passs1 = Son()
# 采用的是就近原则
s1.eat() # 吃蔬菜
6.方法重写
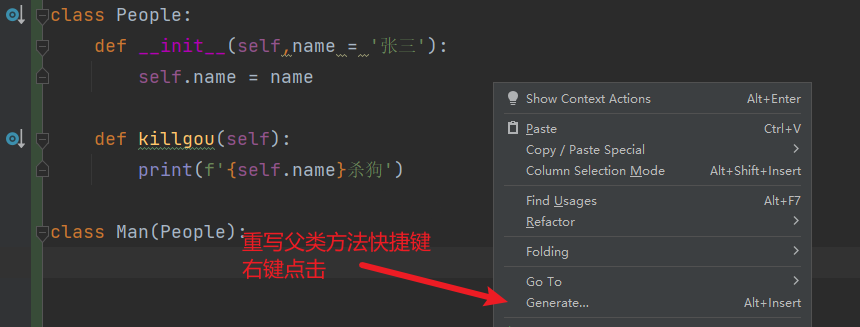
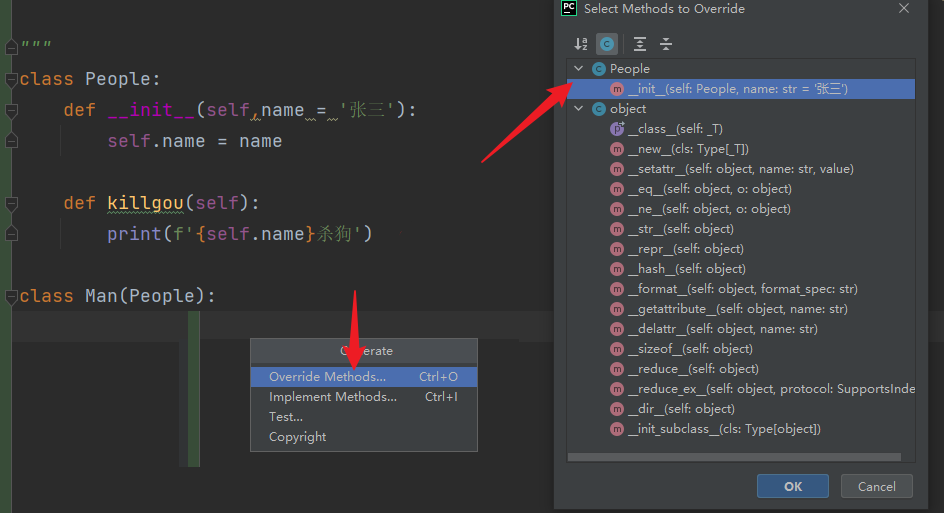
"""
重写:子类重写父类的方法(有两种方式)
重写的快捷键:右键--->生成--->重写方法
重写的前提:必须要先继承
注意点:子类的方法名、形参的个数,要与父类一致
第一种:覆盖写
子类的方法名和形参的个数,要和父类的一致
第二种:扩展写/追加写
面试题: super:指向父类 子类通过super调用父类的同名方法
如果存在子类跟父类同名的方法,我们在调用的时候指向子类的方法
如果不存在子类跟父类同名的方法,我们在调用的时候指向父类的方法"""
class People:def __init__(self,name,age):self.name = namedef eat(self):print('吃饭')def killgou(self):print(f'{self.name}杀狗')class Man(People):def __init__(self,name = '张三',age=18):super().__init__(name,age)self.name = name # 会将传递的参数内容覆盖,因为顺序执行(可调试查看)self.age = age # 添加子类自己的成员属性# 覆盖写,也就是使用的就近原则# def eat(self):# print('吃肉')def eat(self):super().eat()print('吃蔬菜')print(f"{self.name}今年{self.age}岁了")def killgou(self):# 扩展写需要加super().killgou()super().killgou()print('著狗肉')m1 = Man('bbbb',18)
m1.killgou()
m1.eat()
# m2 = Man()
# m2.killgou()
7.多态
"""
多态:继承,重写多个子类调用相同父类的同名方法,得到的结果不同多态的前提:
1.必须存在继承
2.必须存在重写(覆盖写/追加写)
两个条件缺一不可
"""
class Dongwu:def eat(self):print('吃东西')class Dog(Dongwu):def eat(self):print('狗吃骨头')class People(Dongwu):def eat(self):print('人吃肉')def fun(obj):obj.eat()d1 = Dog()
d1.eat()
p1 = People()
p1.eat()fun(d1)
fun(p1)
三、模块及导包
1.导包
"""
一般会将需要导入的包都放在__init__.py中
"""
导包的快捷键:光标放至要导入的方法上,按 Alt + 回车键,选择导入
步骤 1:确认包结构
假设你的项目结构如下(注意 all.py 和 __init__.py 的位置):
Day09/package/__init__.py # 包的初始化文件all.py # 包含 sum1, sum2, sum3, sum4 函数的模块
步骤 2:修正 __init__.py
在 package/__init__.py 中需要做两件事:
- 定义
__all__列表,声明允许通过from package import *导出的函数名。 - 显式导入
all.py中的函数到包顶层,使外部可以直接调用。
正确代码:
# Day09/package/__init__.py# 定义允许导出的函数名(字符串列表)
__all__ = ['sum1', 'sum2', 'sum3', 'sum4']# 从 all.py 中导入函数到包顶层命名空间
from .all import sum1, sum2, sum3, sum4
步骤 3:确保 all.py 中的函数定义正确
你的 all.py 内容没有问题,但建议规范函数参数命名(保持一致性):
# Day09/package/all.pydef sum1(a, b):print(a + b)return a + bdef sum2(c, d):print(c + d)def sum3(a, b):print(a + b)def sum4(a, b):print(a + b)
步骤 4:外部调用方式
现在可以通过以下方式使用包中的函数:
# 示例 1:导入所有允许导出的函数
from Day09.package import *sum1(1, 2) # 输出 3
sum2(3, 4) # 输出 7# 示例 2:按需导入特定函数
from Day09.package import sum3, sum4
sum3(5, 6) # 输出 11
关键原理说明
-
__all__的作用- 它是一个字符串列表,指定当用户执行
from package import *时,允许导出的函数/变量名。 - 若未定义
__all__,import *会默认导出所有不以下划线开头的名称。
- 它是一个字符串列表,指定当用户执行
-
显式导入的必要性
- 即使
__all__中声明了函数名,仍需通过from .all import ...将函数实际导入包的顶层命名空间。 - 这样用户可以直接通过
package.sum1()调用,而无需写package.all.sum1()。
- 即使
常见问题排查
-
报错
ModuleNotFoundError: No module named 'Day09'-
确保项目根目录(包含
Day09的目录)在 Python 的搜索路径中。 -
可通过以下方式临时添加路径:
import sys sys.path.append('/绝对路径/到/Day09的父目录')
-
-
函数未正确导出
- 检查
__init__.py中的导入语句是否正确(例如拼写错误)。 - 确保
all.py文件名和路径与包结构一致。
- 检查
-
循环导入问题
- 避免在
__init__.py或all.py中导入其他模块时形成循环依赖。
- 避免在
最终代码结构
Day09/package/__init__.py # 包含 __all__ 和导入语句all.py # 包含 sum1, sum2, sum3, sum4 函数
四、PyMysql数据库的连接
游标提供了一种灵活的方式,允许你对查询结果进行逐行访问和操作,而不是一次性将所有结果加载到内存中。这在处理大量数据时尤其有用,因为它可以显著减少内存的使用。
import pymysql
db = pymysql.connect(user ='root',password='cheng..,,224',host='localhost',port=3306,database='girls',autocommit=True, # 自动提交charset='utf8'
)
# 创建游标
cur = db.cursor()
# 由游标对象执行sql语句
cur.execute('select * from boys')# 游标结果只能获取一次,获取完结之后,游标对象就失效了
# 获取结果 游标中fetch 是推进的意思
# all会获取所有结果
# print(cur.fetchall())
result = cur.fetchall()
for i in result:print(i)
# 获取单个结果
print(cur.fetchone())# 获取多个结果
print(cur.fetchmany(2))# 先关游标再关闭数据库
# 关闭游标
cur.close()
# 关闭数据库
db.close()# 可以使用try ...finnally 语句
try:db = pymysql.connect(user='root',password='cheng..,,224',host='localhost',port=3306,database='girls',autocommit=False,charset='utf8')# 创建游标cur = db.cursor()cur.execute('update boys set usercp = 8337 where id = 4')# 注意:在查询语句中的,需要使用引号的地方,在这里也需要使用引号# 注意如果外层使用的单引号,那么内层需要使用双引号name = '张'cur.execute(f'select * from boys where boyname like"{name}%"')print(cur.fetchall())
finally:cur.close()db.close()
五、文件处理
1.excel的操作
# 面试题:怎么获取表格中的数据?
# 1.xlrd库
import xlrd# 打开excel表格,创建一个文件对象
DW = xlrd.open_workbook("./data.xls")# 通过文件对象创建表格对象
# book = DW.sheet_by_index(0)
# sheet_by_index = DW.sheet_by_index(0) # 索引可以为正数,也可以为负数,负数表示倒数第几个sheet
# sheet_by_name = DW.sheet_by_name("Sheet1") # 不能忽略字母大小写
# 获取所有sheet名称
print(DW.sheet_names())sheet = DW.sheet_by_name("login_data")
# 根据表格对象获取行数和列数,单元格
# 行
print(sheet.nrows)
# 列
print(sheet.ncols)
# 单元格
print(sheet.cell(0, 0))# 读取一行数据
# row_values默认从0开始,底层是列表切片,看一下源码
print(sheet.row_values(0)) # 读取第0行数据,默认返回的是列表
print(sheet.row_values(1,0,2)) # 读取第1行,第0列到第2列的数据# 读取一列数据
print(sheet.col_values(0)) # 读取第0列数据
print(sheet.col_values(0,0,2)) # 读取第0列,第0行到第2行数据# 读取所有数据
for i in range(sheet.nrows):row_data = sheet.row_values(i)print(tuple(row_data)) # 将结果转为元组
2.编写函数(处理excel表格)
# 编写读取excel数据并放到新的列表的函数
import xlrd
import os# 读取excel数据并放到新的列表中
def read_excel(file_name:str, book_name:str,index = 0):# 通过路径拼接的方式,可以解决找不到文件问题,只需要传入文件名file_name = os.path.dirname(os.path.dirname(__file__)) + "/Data/" + file_nameprint(file_name)workbook = xlrd.open_workbook(file_name) # 打开excel文件sheet = workbook.sheet_by_name(book_name) # 获取表单new_list = []for i in range(index, sheet.nrows):# 列表套元组,这是参数化的类型new_list.append(tuple(sheet.row_values(i)))return new_listprint(read_excel('data.xls','login_data',1))
3.异常处理
"""
else和finally很鸡肋,一般只会使用try和except
把你觉得有问题的代码放到try里面
except: 出现异常现象的处理代码
在try内的变量都是局部变量
# 快捷键:alt + ctrl +T
"""try:print(a)# pass
except NameError:print("a未定义")
except:print("未知异常执行这块代码")
else:# 没有异常的时候执行print("没有异常,else执行")
finally:# 不管有没有代码都会执行print('finnally不管有没有异常都会执行')
4.文件的读取

"""
语法:采用的是with语法
优点:with会自动帮我们关闭文件
with open(文件名,模式,字符集) as 变量名:读取/写入
"""
with open("123.txt","r",encoding="utf-8") as file:print(file.read())"""
读文件
r 的作用:就是把转义字符不转义 就是把带有转义字符变成字符串,相当于'\'进行转义字符
file = open(r"D:\Desktop\test.txt",encoding='utf-8')
"""# 打开文件
file = open("123.txt","r",encoding="utf-8")# 读取文件内容 与游标相同,只能读取一次,读取完全后,游标会移动到文件末尾
# print(file.read())# 读取n个字母 5表示读取5个字母
print(file.read(5))
# 括号内不填任何内容,表示读取一行 15表示读取第一行的15个字母
print(file.readline(15))# 读取所有行 结果是一个列表,以换行符为分隔符
print(file.readlines())
# for i in file.readlines():
# print(i,end="")
# 关闭文件
file.close()"""
写文件
w是覆盖写
写入过程,如果文件不存在,则创建文件,
但是中文会出现乱码,需要设置encoding="utf-8
默认是GBK编码
"""
# file = open("123.txt","w",encoding="utf-8")
# a是追加写
file = open("123.txt","a",encoding="utf-8")
# 在写入内容中添加换行符,会有换行写入效果
file.write("hello world\n")
# 按行写入效果
file.writelines('heasdadasd')
file.close()# 读取图片
file1 = open("we.jpg","rb")
data = file1.read()
print(data)
file1.close()
5.Json处理
"""
读取json文件json.load(文件) 把json转为字典
json.dump(字典,文件,编码) 把字典转为Json
"""
# json转字典
import json
with open("a.json","r",encoding="utf-8") as js:data = json.load(js)print(data)# 字典转json
dict = {"name":"张三","age":12,"sex":"男","hobby":["大球","玩游戏"]
}with open("b.json","w",encoding="utf-8") as js:# ensure_ascii=False 默认是把中文转为ascii码,变成false就是不转为ascii码json.dump(dict,js,ensure_ascii=False)print(dict)
六、系统库获取路径
- Windows 文件系统的灵活性:
- Windows 文件系统在解析路径时,会同时支持反斜杠
\和正斜杠/作为路径分隔符。 - 这种灵活性使得路径的表示更加灵活,减少了因路径分隔符不一致而导致的错误。
- Windows 文件系统在解析路径时,会同时支持反斜杠
"""
abspath和dirname的区别
abspath:获取当前文件所在的绝对路径
dirname:获取当前文件所在的目录
"""
# 获取当前路径
import os
# 获取当前文件路径
print(__file__)
# 获取当前文件路径
print(os.path.dirname(__file__))
print(os.path.abspath(__file__))
# 获取当前文件所在目录
print(os.path.dirname(os.path.abspath(__file__)))
print(os.path.dirname(os.path.dirname(__file__)))
七、Pytest使用
Pytest官方文档:https://pytest.cn/en/stable/reference/reference.html
菜鸟教程:https://www.cainiaoya.com/pytest/pytest-run-tests-in-parallel.html
基础:https://blog.csdn.net/qq_45609369/article/details/140007322
1.pytest的命名规则
- 模块名以test_开头
- 测试类型必须以Test开头
- 测试方法以小写test开头
- 可以在配置文件中修改
2.配置文件
文件名为:pytest.ini
[pytest]
#addopts:配置命令行参数,用空格进行分隔
;-v 详细的内容
;-s 打印信息
;-vs 详细的内容和打印信息
;--count 多次执行测试 --count=次数
;--reruns 失败用例重跑 --reruns=次数
;--reruns-delay 失败重跑的间隔是多少秒 --reruns-delay=秒
;-x 表示只要有一个用例报错,那么测试停止
;--maxfail 达到设置的用例失败的数量就停止 --maxfail=数量
;--html 生成测试报告 --html=report/report.html --capture=sys显示详细信息;addopts = -v -s --html=./report.html ;addopts = -v -s --count=3 --reruns=2;改变用例的查找路径规则 多个测试目录,用空格进行分隔,所有目录下的测试文件名不能相同
;testpaths = ./Day13_Pytest ./Pytest
testpaths = ./Day13_Pytest;模块名的规则,配置测试搜索的模块文件名称
python_files = test_*.py;类名的规则,配置测试搜索的测试类名
python_classes = Test*;方法名的规则,配置测试搜索的测试函数名
python_functions = test*;解决中文变成ascii码
disable_test_id_escaping_and_forfeit_all_rights_to_community_support = True
3.条件跳过与无条件跳过
# pytest 作用:就是大面积的跑测试用例
"""
面试题:
pytest的命名规则
模块名以test_开头
语法
测试类型必须以Test开头
测试方法以小写test开头
pytest会自动识别
"""
import pytest
class TestDemo:# 无条件跳过@pytest.mark.skipdef test_demo1(self):print("测试用例01")# 条件跳过,条件为真时跳过,条件为假时执行用例age = 10@pytest.mark.skipif(age>5,reason="跳过原因")def test_demo2(self):print("测试用例02")def test_demo3(self):print("测试用例03")
4.测试用例的执行顺序
"""
@pytest.mark.run(order=值)
调整执行测试用例的执行顺序:值的优先级越小越大(正数和负数都是)
负数最后执行
没有装饰器,默认是正数中的最后一个
"""
import pytest
class TestDemo:@pytest.mark.run(order=1)def test_demo1(self):print('执行测试用例1')@pytest.mark.run(order=0)def test_demo2(self):print('执行测试用例2')@pytest.mark.run(order=2)def test_demo3(self):print('执行测试用例3')@pytest.mark.run(order=-1)def test_demo4(self):print('执行测试用例4')
5.断言
"""
assert 断言,实际结果 = 预期结果
面试题:在python/自动化测试怎么做断言的
断言:assert
目的:判断实际结果与预期结果相同
"""import pytest
class TestAssert:def test_assert1(self):a = 10b = 20assert a == bprint("a == b")
6.参数化
"""
参数化:
装饰器: @pytest.mark.parametrize
第一个参数,多个值时只能有一个引号
参数值:列表里面套列表或元组
"""
import pytest
from utils.get_excel import read_excelclass TestParametrize:@pytest.mark.parametrize("num",[1,2,3,4])def test_parametrize1(self,num):assert 11*num == 11# 多参数,多数据@pytest.mark.parametrize("num, output",[(1,11),(2,22),(3,35),(4,44)])def test_parametrize(self,num, output):assert 11*num == output@pytest.mark.parametrize("title, url, username, password, verify_code, error_text",read_excel('data.xls','login_data',1))def test_parametrize2(self,title, url, username, password, verify_code, error_text):print(title, url, username, password, verify_code, error_text)@pytest.mark.parametrize("title, num1, num2, result",read_excel('data.xls','addNum',1))def test_parametrize3(self,title, num1, num2, result):# print(title, num1, num2, result)assert num1+num2 == result
7.夹具
1>unittest的夹具
"""
这种方法是unittest的
夹具:
类级夹具:在类中只执行一次
类中方法级夹具:类中有多少个测试方法执行多少遍
"""class Test_Setup:# 在类中所有的测试方法执行用例前执行def setup_class(self):print("类前夹具")# 在类中所有的测试方法执行用例后执行def teardown_class(self):print("类后夹具")def test1(self):print("测试用例1")def test2(self):print("测试用例2")class Test_Setup1:# 在类中每一个测试方法执行用例前执行def setup_method(self):print("方法前夹具")# 在类中每一个测试方法执行用例后执行def teardown_method(self):print("方法后夹具")def test1(self):print("测试用例1")def test2(self):print("测试用例2")
2>Pytest自己的夹具
tset_fixtrue.py文件
"""
pytest自己的夹具
先执行yield前的代码,再执行yield的代码,最后执行yield的代码
装饰器:@pytest.fixture()默认是方法级function
conftest.py文件是存放夹具的文件
在使用夹具时,pytest会自动去找conftest.py,不需要导包
pytest扫描范围,根目录和与测试文件同级目录下的conftest.py
"""class TestFixture:def test_fixtrue1(self,my_fixtrue1):print(my_fixtrue1)print("用例1")def test_fixtrue2(self):print("用例2")def test_fixtrue3(self,my_fixtrue5):print(my_fixtrue5)print("用例3")
conftest.py文件
"""
存放自定义夹具
文件名必须是:conftest.py
使用pytest时才能扫描到自定义夹具
扫描范围,根目录和与测试文件同级目录下conftest.py
conftest放在根目录也能识别到
如果夹具重名,则采用就近原则
一个项目内,可以有多个conftest.py文件.scope 参数指定夹具的级别,默认是方法级function
name参数,给夹具起别名字,不写,默认是方法名
autouse参数,自动使用,默认是False,不自动使用夹具
ids参数,给params起别名
"""import pytest
@pytest.fixture()
def my_fixtrue1():print("方法级夹具前")yield '返回值'print("方法级夹具后")# scope 参数指定夹具的级别,默认是方法级function
@pytest.fixture(scope='class')
def my_fixtrue2():print("类级别夹具前")yield '返回值'print("类级别夹具后")# name参数,给夹具起别名字,不写,默认是方法名
@pytest.fixture(scope='class',name='my_fix3')
def my_fixtrue3():print("夹具前")yield '返回值'print("夹具后")# autouse参数,自动使用,默认是False,不自动使用夹具
@pytest.fixture(scope='function',name='my_fix3',autouse=True)
def my_fixtrue4():print("自动使用夹具前")yield '返回值'print("自动使用夹具后")# params参数,夹具中的参数,表示多个参数,参数值会依次传入夹具中
@pytest.fixture(scope='class',params=[1,2,3])
def my_fixtrue5(request):print("使用参数的类的夹具前")yield f'返回值{request.param}'print("使用参数的类的夹具后")
八、allure
1. mian.py
import pytest
import os
# main() pytest是用来执行测试用例的
# pytest.main()
# 运行pytest测试框架,执行指定测试文件并生成Allure测试结果数据
# 参数说明:
# "test_fixture5.py" - 指定要运行的测试文件
# "--alluredir" - 指定Allure结果数据的输出目录参数
# "result" - Allure结果数据的输出目录
pytest.main(["--alluredir=./allure_result", "--clean-alluredir"])# 调用系统命令,使用Allure命令行工具将测试结果转换为HTML报告
# 参数说明:
# "allure generate" - Allure生成报告的命令
# "result" - 源结果数据目录(与上面pytest指定的输出目录一致)
# "-o report" - 指定HTML报告的输出目录为"report"
# "--clean" - 生成前先清理报告目录,避免旧文件干扰
os.system("allure generate ./allure_result -o ./allure_report --clean")# 调用系统命令,使用Allure命令行工具打开HTML报告
os.system("allure open ./allure_report")
2. allure 注解使用
"""
@allure.epic() 相当于一级标题
@allure.feature() 二级标题
@allure.story() 三级标题
@allure.title(用例的标题) 四级标题
"""
import allure
import pytest@allure.epic("电商平台")
@allure.feature("用户模块")
class TestUser:@allure.story("登录功能")@allure.title("成功登录测试")def test_successful_login(self):"""验证用户使用正确凭证登录成功"""# 测试逻辑assert True@allure.story("注册功能")@allure.title("注册时邮箱格式验证")@pytest.mark.parametrize("email", ["invalid_email","user@.com","@domain.com"])def test_invalid_email_registration(self, email):"""验证使用无效邮箱格式注册时系统报错"""# 测试逻辑assert False@allure.epic("电商平台")
@allure.feature("商品模块")
class TestProduct:@allure.story("搜索功能")@allure.title("搜索结果验证")def test_search_results(self):"""验证搜索结果的准确性"""# 测试逻辑with allure.step("输入关键词进行搜索"):passwith allure.step("检查结果列表是否包含关键词"):passassert True

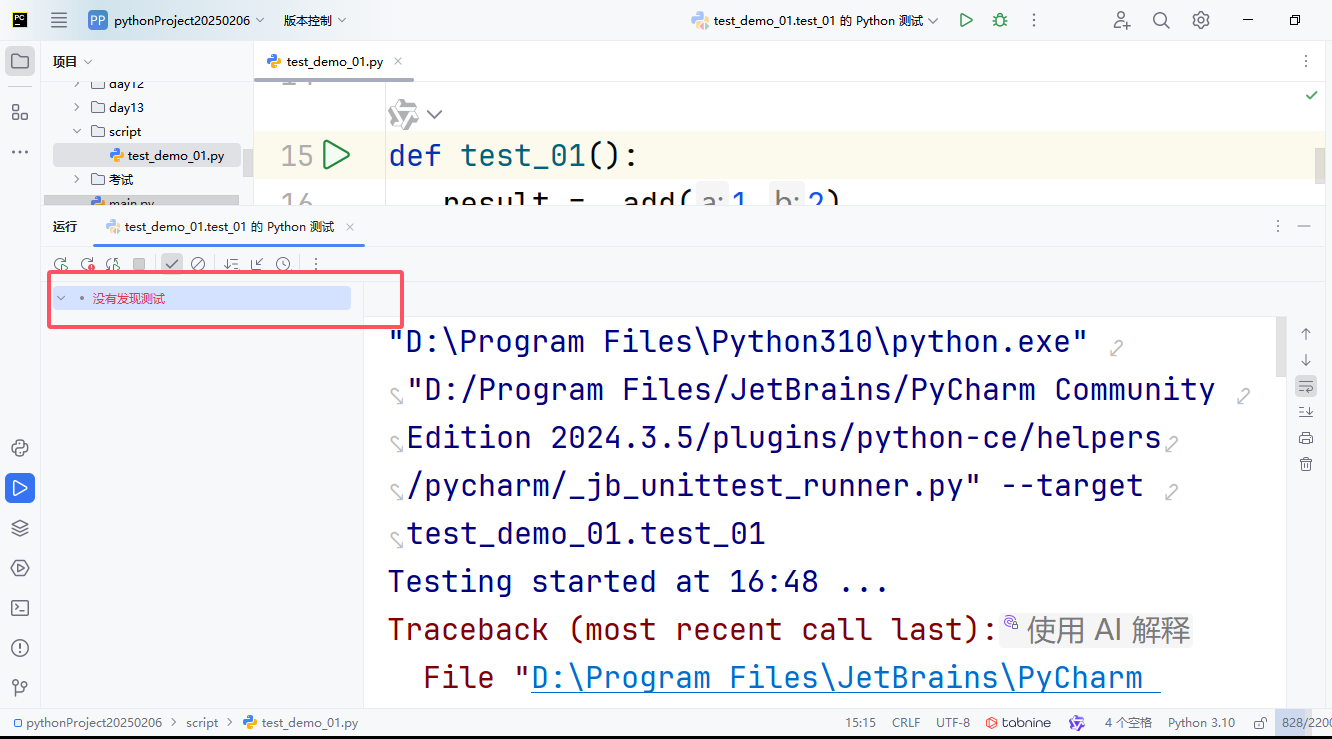
没有发现测试解决办法

UI自动化
1.什么项目适合做ui自动化测试?

2.selenium工作原理

3.浏览器驱动安装
- 安装浏览器驱动之前,一定要知道自己浏览器的版本。
- 通过 https://npm.taobao.org/mirrors/chromedriver/
- 获取对应的浏览器驱动 通过 https://googlechromelabs.github.io/chrome-for-testing/ 下载最新的谷歌浏览器驱动
- 解压浏览器驱动文件,并将驱动文件复制到 python 的根目录就行了。
- 查看 python 安装根目录:通过 python 命令
面试题
python面试题
1.Python基本数据类型有哪些?
数字型:整型:int 浮点型:float 布尔型:bool 假 true 真
非数字型:字符串、元组、列表、集合、字典
2.数据类型之间怎么转换的?
int() float() str
# 列表转元组
tuple()
# 元组转列表
list()
dict()
3.变量的命名规则
-
不能使用数字开头
-
不能使用关键子
-
只能以字母,下划线开头
-
区分大小写
4.Python的关键字有哪些?
#保留字区分大小写
import keyword
print(keyword.kwlist)#输出保留字
print(len(keyword.kwlist))#获取保留字的大小
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
5.列表的插入和删除方式有哪些?
# 插入
lst.insert(index,X) lst.append(X) lst.extend(lst2)
# 删除
pop(index) remove del
6.字典的插入和删除方式有哪些?
# 增加
d[key]=value # 如果key值存在则会修改,如果不存在,则会添加
# 删除
pop(key) d.clear()
集合的增加和删除方式有哪些?
# 增加
add(X) updata(另一个集合)
# 删除
pop() remove(X) discard(X) # 使用discard时,集合中没有X不会报错,而remove会
7.列表的去重有哪些方式?
-
将列表转为集合,使用set()去重,集合再转为列表
-
循环遍历列表,把里面的不重复的数据放到一个新的列表里
-
利用字典key值的唯一性来去重,先转换为字典,再转换为列表
-
dict.fromkeys()来实现列表去重
# 法1
list1 = [1,2,3,53,4,4,4,4,3,6,7]
dict3 = {}
for a in list1:if dict3.get(a) == None:dict3[a] = list1.count(a)
print(list(dict3.keys()))# 法2
# fromkeys 把容器中的值转为key,其中值可以不写,默认None
# dict.fromkeys() 是一个字典类方法,用于创建一个新字典,其中的键来自给定的可迭代对象,而所有键对应的值默认为 None。
# 由于字典的键是唯一的,因此通过这种方式可以自动去除重复的键。
# 从 Python 3.7 开始,字典会保持插入顺序,因此这种方法可以保留原始列表的顺序。my_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = list(dict.fromkeys(my_list))
print(unique_list) # 输出:[1, 2, 3, 4, 5]
8.break与continue的区别?(怎么跳出循环?怎么终止循环的?)
break终止循环,continue跳过本次循环
9.冒泡排序的原理?(有没有写过排序算法?)
冒泡排序是一种最基础的交换排序,是将列表中的相邻元素,从左到右依次进行比较,较大的往右移,比较完后列表中最后一个元素就是最大的,除去这个元素,从剩下的列表中再重复以上操作,直到所有元素排序完成。
10.python是怎么生成随机数的?
使用random函数
11.列表与元组的区别?
定义:列表是以中括号定义的,元组是小括号定义的
特点:列表可以修改,删除,增加,元组不能修改,删除,增加
传参:元组常常作为参数来传递(安全性高)
12.列表与集合的区别?
列表有序,集合无序(不能使用索引)
列表可以存重复值,集合不能有重复值
语法不同:列表是中括号,集合是大括号
13.元组跟集合的区别?
定义:元组是小括号定义的,集合是大括号定义的
元组可以存重复值,集合不能有重复值
特点:元组不能修改,增加,删除,集合可以增加、删除
元组是有序的可以通过索引访问,集合是无序的
14.python中不可变的数据类型
数字,字符串,元组,布尔
15.python中可变类型有哪些
列表,集合,字典
16.常用函数有哪些
max min sum len print input abs round pow
17.列表跟字典的区别?
- 列表是有序的,字典是无序的
- 列表通过索引访问数据,字典通过 key 访问数据,
- 字典比列表的插入和删除操作速度快,
- 列表用中括号表示,字典用大括号表示
18.截取字符串怎么使用?
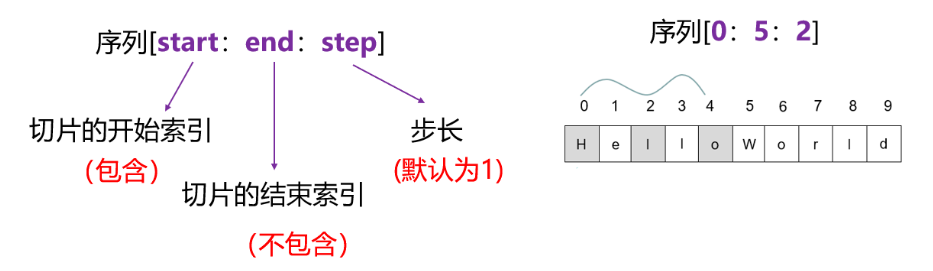
# 按分隔符截取(如split)
parts = s.split(", ") # 结果为 ["Hello", "World!"]
19.全局变量与局部变量区别?
在函数内部定义的变量是局部变量,只能在函数内部使用
在函数外部定义的变量是全局变量,整个文件都可以使用
20.形参跟实参的区别?
形参:定义函数时,括号里的参数,形参必须是变量
实参:调用函数时,括号里的参数,实参可以是值,变量,表达式
21.怎么把局部变量变成全局变量?
使用global,先声明,再赋值,必须分开写
22.我们有哪些装饰器?
@staticmethod
@classmethod
23.python中is与==的区别?
is 比较的是两个对象的内存地址是否相同
== 是比较两个对象的值是否相同
24.面向对象的三大特点(特性)?
封装、继承、多态
25.什么是继承?
子类继承父类的非私有的属性和方法
26.什么是重写?重写的前提是啥?
重写有两种方式:覆盖写和扩展写
super:指向父类 子类通过super调用父类的同名方法
重写的前提:先继承
27.pyton自带的库有哪些(你常用的库有哪些?)
a. random
b. math —数学库
c. os 操作系统库
d. sys 命令行参数库
e. datetime 日期和时间库
f. time 时间库
28.python用的版本是哪个版本?
3.10版本
29.你用Python做过哪些工具?
a. 连接数据库的工具类
b. 读取excel表格用的xlrd库
30.python如何操作数据库?
a.导入pymysql
b.创建数据库连接对象
c.根据连接对象创建游标对象
d.在通过游标对象执行sql语句的方法,进行数据库的增删改查,如果是增删改需要事务的提交
e.关闭游标对象,连接对象
32.json与python字典怎么相互转换?
"""
读取json文件
json.load(文件) 把json转为字典
json.dump(字典,文件,编码) 把字典转为Json # ensure_ascii=False 默认是把中文转为ascii码,变成false就是不转为ascii码
"""
33.python的深拷贝与浅拷贝的区别?
区别:浅拷贝只拷贝对象的第一层,而深拷贝会把所有对象包括子对象,全部拷贝
浅拷贝(copy):用的copy模块的copy方法,拷贝对象的第一层,但不会拷贝对象的内部的子对象(copy后的新的是指向原来的位置,也就是,两个内容是指向的同一块地址空间)
import copy
lst1 = [1,2,[3,4,5]]
lst2 = copy.copy(lst1)
lst1[2][1] = 100
print(lst1) # [1, 2, [3, 100, 5]]
print(lst2) # [1, 2, [3, 100, 5]]
# lst1与lst2中的元素指向同一块内存空间
深拷贝(deepcopy):用的是copy模块的deepcopy方法,完全拷贝了对象及其子对象(完全拷贝,互不影响)
import copy
lst1 = [1,2,[3,4,5]]
lst2 = copy.deepcopy(lst1)
lst1[2][1] = 100
print(lst1) # [1, 2, [3, 100, 5]]
print(lst2) # [1, 2, [3, 4, 5]]
# lst1与lst2指向不同的内存空间
34.对pytest了解吗?
pytest是基于unittest开发的测试框架,使用起来更简单、效率更高,还有很多强大的插件库,能实现更多的实用功能
常用的功能有:重复执行,失败重跑,生成测试报告
35.pytest的命令规则?
- 测试文件名必须以test_开头
- 测试类名必须以Test开头
- 测试方法名必须以test开头
- 这些规则可以通过pytest.ini文件进行配置
36.使用过pytest哪些装饰器?
@pytest.mark.run 调整测试用例顺序
@pytest.mark.skip 无条件跳过
@pytest.mark.skipif 有条件跳过
@pytest.mark.parametrize 参数化
37.有对pytest的夹具了解过吗,使用过吗,请说一下
1.类中方法级,有多少个测试方法,就运行多少次
2.类级,类中无论有多少个测试方法,只运行一次
fixture
setup
teardown
yield 前置和后置的划分,可以设置返回值
38.自动化中怎么做断言的?
assert
39.python你觉得你学的怎么样?
40.python什么时候接触的?
41.对python了解吗?从哪里了解的?你都学了哪些东西?
python是近几年比较热门的编程语言,它有着简单易学,免费开源,可移植性强,解释型,有丰富的第三方库可使用等优点。
我熟悉python基础语法格式,基础数据类型。
字符串str,整型int,浮点型float,布尔型bool,列表list,元组tuple,字典dict,集合set
熟悉顺序,分支和循环语句,分支 if,if else,if elif语句,循环语句while循环 和for循环,跳出循环break,跳过本次循环continue等操作,熟悉if嵌套语句,熟悉循环嵌套语句。
会字符串常用操作,比如,格式化字符串操作,+号连接字符串,split拆分字符串,还有字符串查找find,字符串替换replace等操作。
熟悉列表和字典的增加,删除,修改,查找等操作:
列表:
增加用 insert(索引,值) append(值) extend(列表),删除用 pop(索引) remove(值),修改用 list[索引] = 值,查找用 list[索引]
字典:
增加和修改都用dict[键] = 值,如果键存在,则是修改,键不存在则是新增,删除用pop(“键”) ,查找用 dict[键]
会定义和使用函数,定义类和生成对象,了解面向对象的思想,还会读取,写入txt格式的文件等。
我熟悉pycharm开发环境,会使用python标准库和一些常用的第三方库,会在pycharm环境下安装第三方库(包),也会通过pip install 库名 的方式进行安装,
比如:常用的第三方库有:xlrd库,pymysql库,selenium库,requests库,pytest库等。
xlrd库, 读取excel文件,并会做一些读取excel函数的简单的封装,方便在别的地方使用,
pymysql库,连接数据库,对数据库进行一些增加,删除,修改,查找等操作,
selenium库,做网页自动化操作,对网页进行元素定位,模拟鼠标点击,键盘输入等操作,
requests库,做接口自动化操作,调用get 或 post 方法发请求,对返回数据进行处理等,
pytest库,自动化框架库,可以自动执行测试用例方法,重复执行,生成测试报告等,
可以结合这些库来写一些自动化相关的代码,
比如:结合pytest+selenium写一些网页自动化测试代码,结合pytest+requests写一些接口自动化测试代码。
以上内容就是我对python的了解。
42.为什么要用函数?
提高的代码重复使用
43.什么是匿名函数
Lambda 函数(也称为匿名函数)是一种小型、一次性的匿名函数,通常用于简单的操作。
它们是用 lambda 关键字定义的,语法简洁,适用于需要快速定义函数的场景。
"""
面试题:
什么是匿名函数?他们是用lambda关键字定义的,语法简洁
适用于需要快速定义函数的场景
直接返回该函数
语法:lambda 参数:表达式
"""# 匿名函数
s=lambda a,b:a+b # s表示就是一个匿名函数
print(type(s)) # <class 'function'>
# 调用匿名函数
print(s(10,20))
print('-'*30)
# 列表的正常取值操作
lst=[10,20,30,40,50]
for i in range(len(lst)):print(lst[i])
print('-'*30)for i in range(len(lst)):result=lambda x:x[i] # 根据索引取值 ,result是的类型是function ,x是形式参数print(result(lst)) # lst是实际参数
44.静态方法和类方法的区别
- 静态方法(Static Method):
- 使用
@staticmethod装饰器。 - 成员方法和类方法都可以调用静态方法
- 静态方法只能通过类名打点调用类属性和类方法。其他的内容都不可以
- 通常用于工具类
- 使用
- 类方法(Class Method):
- 使用
@classmethod装饰器。 - 第一个参数是类本身,通常命名为
cls。 - 可以调用静态方法,以及类的属性和方法,但不能访问成员属性和成员方法。
- 使用
45.python怎么读取表格
-
导入第三方xlrd库
-
打开excel表格,创建一个文件对象
DW = xlrd.open_workbook("./data.xls") -
通过文件对象创建表格对象
book = DW.sheet_by_index(0) -
根据表格对象获取行数和列数,单元格
book.nrows book.ncols book.cell(0,0)
UI自动化面试题
1.UI(web)自动化测试是怎么做的?
UI自动化通常是python+pytest+selenium框架来编写自动化测试代码
- 搭建环境,安装库
- 准备测试数据
- 创建测试文件,编写测试类,测试方法 测试方法中包含:selenium元素定位和网页操作,加入assert断言
- 生成并分析测试报告selenium怎么用的,工作原理,怎么使用
是一个用于web端的自动化测试工具
工作原理:首先创建浏览器驱动对象,然后通过浏览器驱动对象打开页面,通过浏览器驱动对象对页面进行操作,然后关闭浏览器驱动对象。
使用方法:
- 先创建浏览器驱动对象
- 用这个驱动对象调用get函数,传入要打开的网址
- 再用这个驱动对象用find_element函数对要操作的元素进行定位,定位到了之后,得到元素对象,再调用对元素对象的相关的操作函数,比如按钮点击click,还有发送文本send_keys等函数,完成对浏览器的操作,中间步骤可以用time.sleep(时间),加入操作后等待时间
- 操作完成后,调用quit函数退出浏览器驱动
2.元素的定位有哪些? 你常用哪些进行定位
id 定位
name 定位
class_name 定位
tag_name 定位
link_text 定位
partail_link_text 定位
xpath 定位
css定位
3.而对于动态 id 你是怎么解决的?
- 可以根据元素的其他固定的属性来定位
- 可以根据父节点、子节点、兄弟节点定位
- 还可以用xpath的绝对路径来定位
- 还可以用xpath的部分属性值定位方法来定位
4.元素的状态都有哪些?怎么判断元素状态?
状态有:
是否可见、是否可用、是否被选中
判断状态:
判断元素是否可见 is_displayed()
判断元素是否可用 is_enabled()
判断复选框或者单选框是否被选中 is_selected()
5.怎么对测试报告进行分析
allure
pytest自带的测试报告
6.元素等待有哪几种方式?怎么使用的?
元素等待方式有三种: 显示等待 隐式等待 强制等待
使用:
显示等待 每次元素定位时都需要调用显示等待的函数 WebDriverWait(driver,时间,间隔)
隐式等待 隐式等待只需要调用一次隐式等待的函数,对所有的元素定位都有效 implicitly_wait(时间)
强制等待 需要时调用time.sleep(时间),可以让程序暂停一段时间后再执行
6.显式等待和隐式等待的区别
作用域:显示等待针对的单个元素,而隐式等待是页面中的所有元素
异常:显示等待抛出的超时异常,而隐式等待是元素找不到
效率:影视等待需要整个页面加载完才能进行查找,二显示等待不需要整个页面加载完,只需要查找的元素就可以进行查找,所以显示等待效率高,工作中常常还用显示等待
7.对于frame你是怎么处理的?
定位元素时,如果遇到在内嵌frame的元素,需要先用switch_to.frame函数跳转进内嵌frame,才能对里面的元素进行定位等操作
如果有多层内嵌,需要一层一层进入
退出内嵌frame是通过switch_to.default_content的函数退出,
如何在不同的网页窗口之间切换
先获取窗口对象: handles = driver.window_handles
通过switch_to.window函数,传入窗口对象进行窗口的跳转: driver.switch_to.window(handles[1])
8.怎么处理弹出框的?
先使用switch_to.alert方法跳转到alert弹出框,
然后通过accept方法点击确定按钮, 通过dismiss方法点击取消按钮,text方法获取弹出窗口的文本
如何操作滚动条
js=window.scollto(0,500范围)
drive.excute.script(js)
9.UI(web)自动化测试过程中遇到的异常有哪些?
没有找到元素异常 NoSunchEelementExpection:
相应超时异常 timeOutExpection:
元素不可见异常 EelementNoiVsibleExpection:
没有Frame异常 NoSunchFrameExpection:
没有该属性异常 NoSunchAttributeExpection:
10.对于不可见的元素,你如何定位,如何处理?
不可见的隐藏元素是可以正常定位的,只是不能操作。如果想对其进行操作,我们可以通过 js修改 display 的值,来实现修改元素的属性
先写出通过修改 display 值为‘block’的js语句
js = ‘document.getElementById(“user”).style.display=“block”;’
driver.execute_script(js)
然后把js语句放入selenium里的execute_script()语句进行执行
11.定位不到元素,你碰到过那些,怎么解决?
1、像页面加载延迟的问题,这个需要通过等待延迟的方式来处理。
2、不过有时候,页面加载完成,但是元素暂时还不可见,导致定位不成功,这个可以选择使用显示等待来处理,这里需要用到 WebDriverWait 类来实现
3、还有就是像内嵌网页的问题,需要使用 switch_to.frame这个函数来跳转到处理
4、还有要注意多窗口问题,动态 id 问题等的问题,对于多窗口处理,可以使用 switch_to.window的方式来进行处理,而对于动态 id 的问题,动态id就是每次打开页面,这个元素的id属性值是动态生成的。用id定位这些元素会出现定位不到的情况
1)可以根据元素的其他固定的属性来定位
2)可以根据父节点、子节点、兄弟节点定位
3)还可以用xpath的绝对路径来定位
4)还可以用xpath的部分属性值定位方法来定位
5、 有的页面元素需要下拉到显示区域才会显示,才能被定位到,这时需要操作 js 的方法:execute_script(),可以直接执行 js 的滚动语句,滚动到元素显示区域,进行操作
6、再这就是有时候会碰到某些元素的是不可见的,如果想对元素操作的话,则需要修改元素为可见,比如 display 属性为 none,这就需要通过js语句修改 display 的值
12.如何处理下拉菜单?
当下拉框元素是select标签,我们就用select对象来处理
首先定位下拉框生成元素对象,通过元素对象生成select对象
select = Select(element)
通过索引index或者文本text函数选中下拉框
select.select_by_index(index)
select.select_by_value(value)
select.select_by_visible_text(text)
当下拉框元素不是select标签,我们就可以通过ActionChains类,用鼠标点击或键盘操作
13.在自动化中,如何处理验证码
开发屏蔽验证码
万能验证码
通过cookie信息跳过登录
14.对于生成的自动化测试报告如何分析?
-
查看通过率,主看总共执行了多少用例,通过了多少,失败了多少,错误了多少
-
定位错误,对于错误的用例,基本都脚本问题,查看报告中的日志详细信息,看具体哪个位置出错了,针对性去进行调试,修改
-
确定错误,提交Bug,对于失败的用例,也是首先看报告中的日志,看具体哪个位置出错了,一般首先怀疑自己的脚本,先确定脚本是否有问题,如果脚本没有问题,那可以确定就是 Bug 了,提 Bug 即可
15.怎么提高自动化测试的稳定性(自动化稳定性)
1、使用唯一且稳定的元素定位策略。优先选择ID、CSS选择器或XPath,避免使用容易变化的定位方式
2、合理使用等待方式,比如脚本中使用显式等待来等待页面加载和元素可见性,
3、合理使用捕获异常和错误重试机制,比如try except块来处理异常,
使用数据驱动方法,将测试数据与测试脚本分离
16.什么是po模式
po全称为page object模式,是selenium中的一种测试设计模式,主要是将一个页面定位元素的功能,设计为一个页面类class,以后再进行元素定位,我们就可以通过页面类来获取元素定位,
好处是,当页面元素变化时,只需修改测试页class中的元素定位的代码,不需要在别的地方多处修改。
闭包
堆栈
hasattr() 函数用于判断对象是否包含对应的属性。
getattr() 函数获取属性。
setattr() 函数用于设置属性值,若该属性不存在则创建新属性。