M3T联邦基础模型用于具身智能:边缘集成的潜力与挑战
作者: Kasra Borazjani, Student Member, IEEE, Payam Abdisarabshali, Student Member, IEEE, Fardis Nadimi, Student Member, IEEE, Naji Khosravan, Member, IEEE, Minghui Liwang, Senior Member, IEEE, Xianbin Wang, Fellow, IEEE, Yiguang Hong, Fellow, IEEE, Seyyedali Hosseinalipour, Member, IEEE
摘要——随着具身智能系统日益变得多模态、个性化和交互式,它们必须能够从多样化的感官输入中有效学习,持续适应用户偏好,并在资源和隐私约束下安全运行。这些挑战凸显了对能够在模型泛化与个性化之间取得平衡的同时实现快速、情境感知自适应能力的机器学习模型的迫切需求。在此背景下,两种方法脱颖而出,各自提供了部分所需能力:FMs为跨任务和跨模态的泛化提供了一条路径,FL)则为分布式、隐私保护的模型更新和用户级模型个性化提供了基础设施。然而,单独使用时,这两种方法都无法满足现实世界中具身环境复杂且多样化的能力要求。在这篇展望性论文中,我们提出了面向具身智能的FFMs,这是一种新的范式,将M3T FMs的泛化能力与FL的隐私保护分布式特性相结合,使能无线边缘的智能系统。我们在一个统一框架“EMBODY”下,收集了FFMs在具身AI生态系统中的关键部署维度:Embodiment heterogeneity、Modality richness and imbalance、Bandwidth and compute constraints、On-device continual learning、Distributed control and autonomy、以及Yielding safety、privacy和personalization。针对每一个维度,我们识别出具体挑战并提出可行的研究方向。此外,我们还提出了一个评估框架,用于在具身智能系统中部署FFMs,并分析其相关权衡。
I. 引言
具身智能是指物理上嵌入于现实世界的智能系统——通常指机器人或能够通过与环境互动来感知、行动和学习的智能体。在此基础上,具身智能不仅重新定义了智能系统的角色,更重塑了其本质。与传统的AI系统(如大语言模型LLMs或静态视觉分类器)相比,下一代具身智能体的根本区别在于它们对交互式、基于物理世界的情境智能的需求 [1]。特别是,具身智能体必须通过多种传感器模态(例如视觉、触觉、音频)持续感知世界,与动态环境进行互动,并适应各种任务,从物体操作、社交互动到在非结构化地形中搜救,以及协助医院外科手术等。这些要求无法通过在这些AI智能体上部署狭窄训练的单一任务模型来满足。相反,它们自然地契合新兴的M3T基础模型的能力。这类大规模架构通常在涵盖语言、视觉场景和人类指令的多样化数据集上进行预训练 [2]。M3T FMs 可以为具身智能体提供统一的语义主干,使其能够解释指令、理解环境并规划行动。例如,厨房机器人可以利用单一的 M3T FM 来识别食材、遵循语音命令、操控厨具,即使在它从未见过的环境中也能完成(例如通过少量/零样本学习)。
然而,将FMs应用于具身智能引入了新的挑战,这需要从传统集中式训练/微调模式迁移出来。本质上,每个机器人/智能体通过其自身具身形式体验世界:不同的传感器、执行器、任务和用户交互方式。此外,这些机器人/智能体运行在去中心化的物理环境中(如家庭、医院和工厂),在其具身过程中积累了丰富的、具有上下文特征的、涉及隐私的数据(如机密工业流程),这些数据难以集中存储和处理。因此,为了真正发挥M3T FMs在这些场景下的潜力,我们需要转向跨具身学习,即让作为数据采集者的具身智能体,尽管配置各异,也能通过去中心化的协作共享、优化和适配M3T FMs。此时,FL为这种协作提供了一个有吸引力的机制,使得分布式智能体可以在不传输原始数据的前提下共享模型更新,从而保护隐私 [3], [4]。
在本文中,我们提出了适用于具身智能的FFMs,这是应对上述挑战与动机的一种自然但尚未充分探索的解决方案。FFMs在该领域的整合创造了一个新范式,将FMs强大的泛化表达能力与FL的隐私保护、去中心化自适应/学习能力结合起来。为了使我们的讨论围绕一个统一的主题展开,我们将影响网络边缘上FFMs实现的最具相关性的具身智能要素归纳为“EMBODY”维度:具身异构性(硬件、传感器、执行器)、模态丰富性与不平衡性、带宽与计算限制、设备端持续学习、分布式控制与自主性、以及安全性、隐私性和个性化。本文旨在作为一篇展望性论文,既阐明将FFMs整合进具身智能的变革潜力,也揭示由此带来的关键挑战。我们的主要贡献总结如下:
-
我们提出了一种适合具身智能的FFMs架构,包含模块化传感器编码器、MoE层和任务头。
-
我们具体阐述了EMBODY各个维度,展示了FFMs在具身智能中的独特能力,并举例说明了本领域中FFMs的多个应用场景。
-
我们基于EMBODY维度勾勒出多个研究方向,突出了FFMs模块化特性为具身智能提供的独特机遇。这些方向有意被设定为捕捉“在这个未被充分探索的研究领域中我们可以做什么”的广泛主题,为未来分解为具体、可执行的研究课题提供灵活的概念基础。
-
我们设想了一个用于具身智能中FFMs的评估框架,包括不同的评估指标与权衡关系。
II. 背景与相关工作
A. Embodied AI
现代具身智能体的典型实例包括人形机器人(例如Figure AI的Figure 01)、移动式机器人平台(例如波士顿动力公司的Spot),以及通过沉浸式可穿戴设备运行的XR智能体,如Meta Quest或Apple Vision Pro [1], [5]。与大多局限于屏幕任务的传统AI系统不同,具身智能体与动态、不确定的物理和社会环境进行交互。
具身智能体从根本上依赖于多模态感知,以通过多种感官数据(如视觉(RGB、深度)、听觉、触觉、惯性、力反馈等)实时地理解其周围环境,且这些数据通常在质量各异的条件下获取。此外,为了实现目标导向的行为,这些智能体可能需要将感知与运动动作紧密耦合,包括行走、转向或导航(即移动性)、抓取或移动物体(即操作)、手势或信号(即表达性动作),以及操作工具或界面。这类运动动作通常必须在严格的延迟约束下执行,以响应环境或用户驱动的变化。
然而,利用这些智能体所采集的多模态感知数据来训练能够在严格延迟约束下引导运动动作的ML模型并非易事:这些智能体(如家用机器人或可穿戴XR系统)会收集高度个人化的数据(如家庭布局、手势、语音),由于隐私问题,这些数据无法传输至集中式的机器学习模型训练单元(如云服务器)。这推动了由FL实现的隐私保护型分布式机器学习在具身智能中的引入。
B. 联邦学习在机器人/具身智能中的应用
传统的联邦学习(见图1(a))通过一个三步循环过程运作直至模型收敛:
(i) 每个客户端/设备使用本地数据训练局部模型;
(ii) 模型更新(如参数或梯度)定期上传至服务器/聚合器;
(iii) 聚合器将这些更新(例如通过加权平均)融合为全局模型,并广播回各个设备,从而同步其本地模型并启动下一轮训练。
联邦学习已被应用于机器人和具身智能中的任务,如协同驾驶和协作制造,使机器人能够联合学习运动规划和安全关键控制。其变体,如去中心化/基于八卦通信的联邦学习、FRL和基于区块链的联邦学习也得到了探索。例如,基于八卦通信的联邦学习被用于cobot系统中,而联邦强化学习则用于多智能体策略学习。有关详细讨论,请参阅[3]、[4]。总体而言,这些进展突出了联邦学习在具身智能中实现可扩展智能的重要作用;然而,这些研究并未聚焦于FMs。
C. 面向具身智能的FMs
基础模型的发展迅速,最初是单模态的LLMs(如BERT、GPT-3、PaLM),展示了强大的文本生成和理解能力 [6]。随后出现了多模态基础模型,如CLIP、DALL-E和Imagen,实现了零样本分类和文本到图像生成 [7]。近年来,M3T基础模型(如Gato、Kosmos-2和GPT-4)逐渐兴起,旨在通过统一架构实现跨任务和跨模态的学习、推理和行动,打造通用人工智能 [8]。
尽管基础模型在具身智能领域尚属新兴,但已有先驱性研究:RT-1 使用13万个机器人轨迹训练了一个Transformer模型;RoboCat 探索了跨具身学习;SayCan 和 ChatGPT-for-Robotics 则将大语言模型用于任务规划和代码生成。这些研究表明基础模型在具身智能中的潜力,但它们均假设采用集中式训练,并忽略了现代M3T基础模型的模块化特性——这一方面将在本文中围绕FFMs展开探讨。
D. 面向分布式具身智能的FFMs
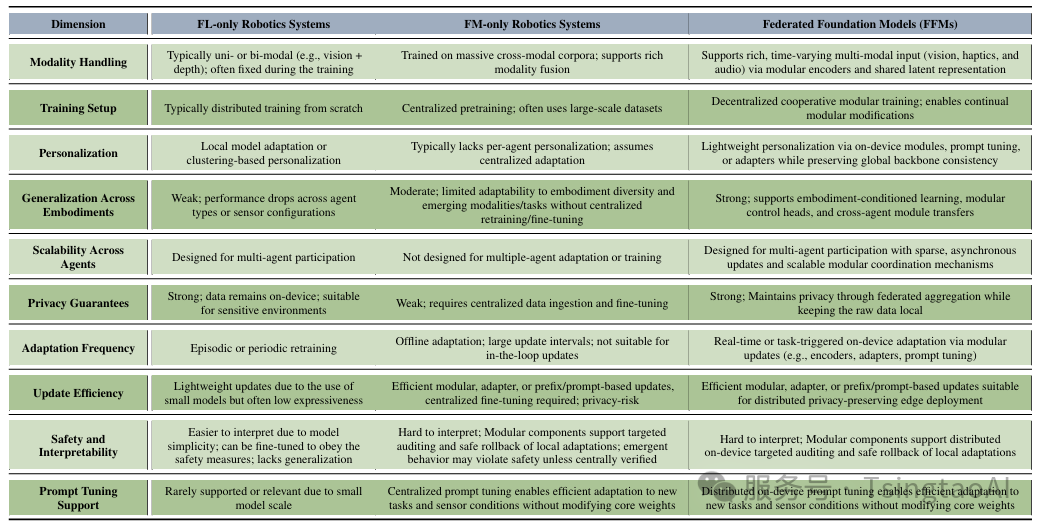
尤其是当考虑新兴的M3T联邦基础模型时,这是一个非常前沿的研究方向。因此,在具身智能领域中对FFMs的研究仍极为有限。不过,最近在其他领域中关于FFMs的研究已显示出巨大的潜力,对其聚合方法、计算/通信效率以及可信性的研究正在人工智能/机器学习和无线网络社区中引起广泛关注(参考[13]及其引用文献)。在本文中,我们旨在提供首批将M3T FFMs整合进具身智能领域的愿景之一。为了更结构化地理解,我们在表I中对具身智能中的三种主要范式进行了比较分析:仅使用联邦学习的系统、仅使用基础模型的系统,以及我们提出的FFMs。
E. M3T FFMs的模块化架构
目前尚无统一的M3T基础模型架构,因为该领域仍在快速发展,不同科技公司和学术文献中对其构想存在差异。在本文中,我们基于[14]中提出的架构进行构建,并将其分解为一种模块化架构,如图1(b)所示,其中各模块可以独立进行更新/训练。为进一步增强对M3T FFMs的理解,我们将其置于具身智能的背景中,如图1(c)所示,并对其组件解释如下:
-
模态编码器:每种感官输入(如RGB-D图像、音频、力/扭矩信号、惯性测量)都通过一个编码器处理,将原始信号转换为潜在表示。这种模块化的编码器集成方式支持针对特定模态的微调以及智能体之间的编码器互换,而不影响下方定义的共享主干网络。
-
共享主干网络:主干网络由一组MoEs组成,如下所述。
表 I
具身智能领域中FL-only、FM-only与FFM方法的对比分析。
(i)MoMEs:为了应对感知能力的异构性和工作负载的平衡,模态的潜在表示将通过一个MoME层进行处理。专家是神经网络或Transformer结构,根据输入特征有选择地激活,从而在不激活整个模型的情况下实现高效的专门化处理。
(ii)MoTEs:为了应对广泛的具身任务,例如导航、物体操作、手势跟随或环境交互,模型流程中集成了任务特定的MoEs。这些模块可以根据任务提示或上下文信号动态激活相关的专家路径。
上述MoEs可以是预先训练好的(例如,通过对公开网站爬取的数据进行训练),也可以与其他模块一起从头训练 [14]。主干网络通过这些专家模块融合来自不同模态和任务的信息,同时捕捉具身智能所需的组合结构、时空关系和上下文基础,并在部署过程中基本(但非完全)保持冻结状态。
-
Task Heads:每个具身任务都由输出头支持,这些输出头是将共享特征映射为具体预测(如控制指令、动作概率)的神经网络层。这种模块化的输出头集成方式支持任务特定的微调以及智能体之间的任务头互换。
-
Adapters and Prompts:小型/浅层的适配器模块和/或提示调优模块可以插入到主干网络中,或前置到输入中。这些模块支持针对特定智能体或具身形式的适应性调整(即适应某一特定具身智能体的物理/感知特性)。
-
Coordinator and Learning Process:一个中央协调器/服务器按照标准的联邦学习流程(即本地训练、聚合和广播)管理跨智能体的模型更新,而无需交换完整的模型参数。在此过程中,智能体仅更新本地FM的子组件/模块(如编码器、任务头、适配器权重、提示模块),这些模块的选择可以如我们在未来研究方向中讨论的那样进行优化。协调器对这些模块进行聚合后返回给各智能体以继续下一轮更新。
⋆ 此后,由于我们的关注点仅限于此类模型,我们使用“FFM”来指代“M3T FFM”。
III. 具身智能中FFMs的应用场景与EMBODY维度
鉴于FMs在具身智能领域已取得的显著成果,FFMs有望更进一步,在工业、家庭及沉浸式环境中广泛变革各类具身智能应用。以下我们将列举一些应用场景,并阐述其中自然存在的EMBODY维度。
具身智能中FFMs的应用场景:接下来我们提供三个FFMs在具身智能中的典型用例。
(1)FFMs可用于赋能智能制造工厂,在这类场景中,具有多样传感器、执行器和策略的协作机器人能够适应动态的工作流程和人类协作者。不同于可能需要集中再训练的传统基础模型,FFMs支持去中心化的训练与适应,保护专有数据并满足严格的隐私法规。
(2)在家庭环境中,FFMs使辅助机器人能够在不暴露敏感家庭数据的前提下,学习并个性化用户的日常习惯、偏好和生活空间,从而克服仅依赖基础模型方案的关键局限性。
(3)在沉浸式XR系统中,FFMs使分布式的头戴设备和可穿戴设备能够协同微调用于身体语言、注视和手势识别的模型,实现实时的设备端个性化。
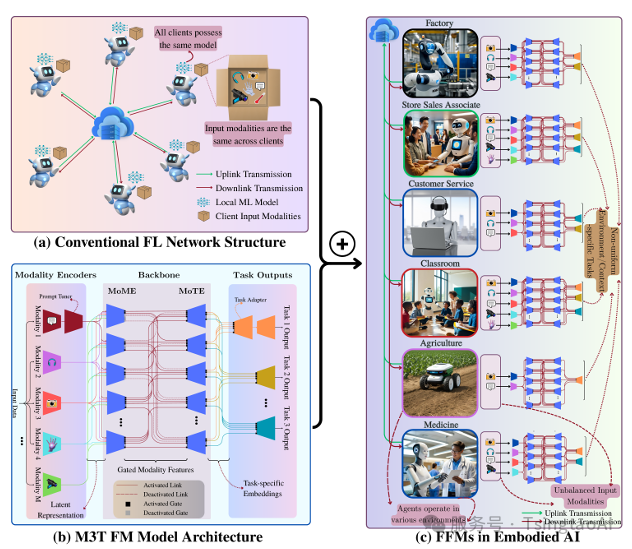
图1。(a)FL架构示意图,其中客户端/智能体参与协同模型训练。这种协同训练通过以下步骤循环进行:
(i) 智能体使用本地数据进行本地模型训练;
(ii) 将模型/梯度传输至服务器;
(iii) 服务器基于接收到的模型/梯度(例如通过加权平均)更新全局模型,并将全局模型广播回各智能体以启动下一轮本地模型训练。
(b)M3T基础模型的模块化架构,包括模态编码器、MoMEs、MoTEs和任务输出头。根据输入特征,一部分MoME模块在推理和训练过程中被触发/激活;进一步地,根据期望的输出任务,一部分MoTE模块也将被激活。
(c)具身智能中的FFMs架构,其中不同智能体具有不同的感知模态和感兴趣的任务。每个智能体拥有一个本地FM,训练其本地FM的不同模块(例如编码器、任务头、部分MoME或MoTE模块),并将这些模块发送至服务器进行聚合。服务器对收到的模块进行聚合后,再将聚合后的模块广播回各智能体。接收的聚合模块可在智能体端进一步进行本地微调。
与传统的FMs不同,后者在集中式预训练后通常被“冻结”,往往缺乏情境响应能力,而FFMs则能够在上述所有场景中实现持续的、保护隐私的适应性更新,以应对新用户、新任务和不同的硬件配置。
EMBODY维度的阐述:在上述各种应用场景中,EMBODY维度自然显现,突显了在具身智能中简单实施FFM所无法解决的关键挑战:
-
Embodiment heterogeneity贯穿于所有前述场景之中:在智能制造工厂中,机器人在形态结构、感知能力和执行器方面存在差异;在家庭环境中,辅助机器人必须适应用户的个性化布局和硬件配置;而在XR系统中,头戴设备和虚拟化身在追踪精度、接口延迟和传感器保真度方面各不相同。
-
Modality richness and imbalance在各个场景中也至关重要:工业机器人需要处理视觉信息、力反馈数据以及机器状态信息;家用智能体需解析语音、触觉和注视等多模态线索;而XR系统可能依赖头部姿态、手势动作、眼动追踪和语音等多种模态的融合。
-
Bandwidth and compute constraints是多个场景中的共性问题:工厂机器人通常面临通信带宽受限的挑战;智能家居设备受限于本地计算能力;XR设备则需在低功耗和有限算力条件下运行复杂的AI模型。
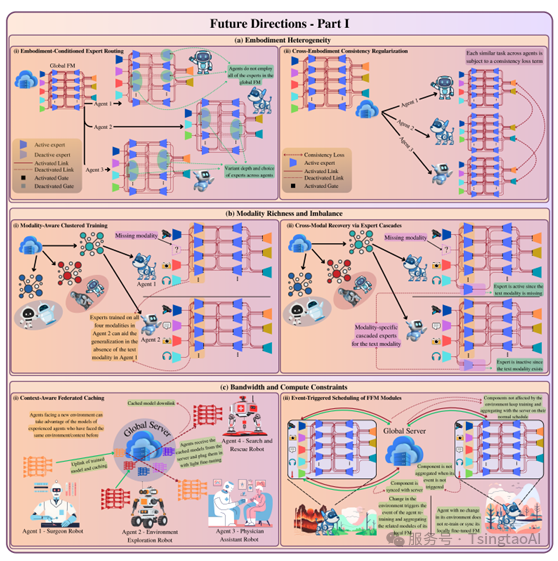
图2. 所设想的未来研究方向的可视化展示。
(a)具身异构性。
左图:Embodiment-Conditioned Expert Routing。
右图:Cross-Embodiment Consistency Regularization。
(b)模态丰富性与不平衡性。
左图:Modality-Aware Clustered Training。
右图:Cross-Modal Recovery via Expert Cascades。
(c)带宽与计算资源限制。
左图:Context-Aware Federated Caching。
右图:Context-Aware and Event-Triggered Scheduling of FFM Modules。
窗口限制和本地处理能力:工厂机器人依赖于车载处理器,无法支持大规模模型再训练;家用机器人通常是低功耗、成本敏感的设备,缺乏用于全模型微调的强大GPU;XR系统则要求超低延迟和高帧率,这在执行XR任务期间排除了重型模型更新或大规模通信的可能性。
• 设备端持续学习 普遍存在于各类场景中:工厂中的机械臂必须适应新任务或新工具,家庭助手需适应不断变化的用户习惯,而XR虚拟化身则需要根据行为信号的变化进行(近似)实时的本地模型/行为更新,且无需服务器干预。
• 分布式控制与自主性 是这些场景的固有特征:工厂机器人可能需要在不频繁依赖中心化指令的情况下协调动作,家庭机器人通常在不同房间或住宅之间半独立运行,而XR用户可在沉浸式环境中自由移动。
• 实现安全性、隐私保护与个性化 是所有场景共同的核心需求:工厂中的安全/合规性要求、家庭环境中的用户隐私、以及沉浸式系统中的个性化体验,都要求一种既能尊重隐私又能确保安全运行的个性化智能。
IV. 开放研究方向:面向EMBODY维度的FFM研究议程
接下来,我们重新审视上述 EMBODY 维度,旨在为解决这些问题定制一系列研究方向。每一部分介绍一个核心挑战,并基于模块化的FFM框架提出开放性的研究方向。这些方向有意设定在较高层次上,以允许多样化的解读,并鼓励在这个尚未充分探索的领域中进行创新。
A. Embodiment Heterogeneity
由智能体在不同物理环境中运行所导致的具身异构性,给构建能在多种具身形式间泛化的共享FFMs带来了挑战(例如,模型可以在一种或多种机器人上训练,但在部署到其他机器人时仍能有效运行)。为此,我们设想以下研究方向(见图2(a)):
(i) Embodiment-Conditioned Expert Routing:
模态专用的 MoME 层可以增强“具身编码令牌”,该令牌对硬件特性(如运动范围、执行器数量、传感器精度)进行编码。这些令牌随后可作为软键,用于选择合适的专家模块,使模型内部的信息路由决策能够反映推理过程中的物理上下文并实现模型个性化。
(ii) Cross-Embodiment Consistency Regularization:
在联邦训练过程中,具有不同具身形式的智能体往往会在表示空间中产生偏差(即硬件、感知或控制上的差异可能导致相似任务的内部编码不同)。为解决这一问题,我们设想通过嵌入相关任务之间的一致性损失,使得在不同具身配置下(如手臂长度、夹爪类型、传感器位置等变化)执行的相似任务之间建立更紧密的联系,从而提升模型的泛化能力。
B. Modality Richness and Imbalance
由于智能体感官输入存在(时间上的)变化,导致其模态丰富性和不平衡性,我们设想以下研究方向(见图2(b)):
(i) Modality-Aware Clustered Training:
我们设想采用智能体聚类技术,将具有相似任务的智能体分组,同时确保每组内的模态组合比单一智能体更全面。在每个聚类内,服务器可在选定的MoME专家模块上进行联邦聚合,使智能体不仅能从具有相似任务的同伴中学习,还能从它们所缺少的互补模态中学习。关键在于,在每个聚类中,一个智能体MoME层内的专家可通过拥有更丰富模态集的智能体来学习模态之间的隐藏结构和关系。
(ii) Cross-Modal Recovery via Expert Cascades:
为了提高模型对缺失模态的鲁棒性,我们设想在MoME层中引入“专家级联”——当某些类型的数据缺失或质量较低时才被激活的一系列专用模型。这些专家应通过联邦方式进行训练,即各智能体使用本地可用的传感器数据训练自己的专家模块,并仅上传专家模型更新至服务器。服务器随后对这些专家模块在跨智能体层面进行聚合,实现在不暴露原始数据的前提下知识共享。这样一来,智能体可以协同学习填补缺失的模态(例如通过视觉和运动传感器预测触觉输入),同时保持训练过程的去中心化和隐私保护。
C. Bandwidth and Compute Constraints
考虑到许多具身智能体运行在边缘处理器上,受到严格的能量/计算能力和带宽限制,我们设想以下研究方向(见图2(c)):
(i) Context-Aware Federated Caching:
我们设想一种针对FFMs的情境感知边缘缓存机制,其中边缘服务器根据其内存限制缓存来自智能体的模型模块。参与FFM训练的智能体首先根据当前任务和环境(例如“在走廊中跟随用户”)查询最近的服务器中是否已有所需模块,以避免重复的本地模型更新和传输。如果另一个智能体在之前的联邦轮次中已提交过类似模块,则请求方只需进行轻量微调即可下载并复用该模块。该机制可利用语义任务签名(例如,从近期观察-动作历史中提取的紧凑嵌入)来匹配缓存模块与当前智能体的上下文。
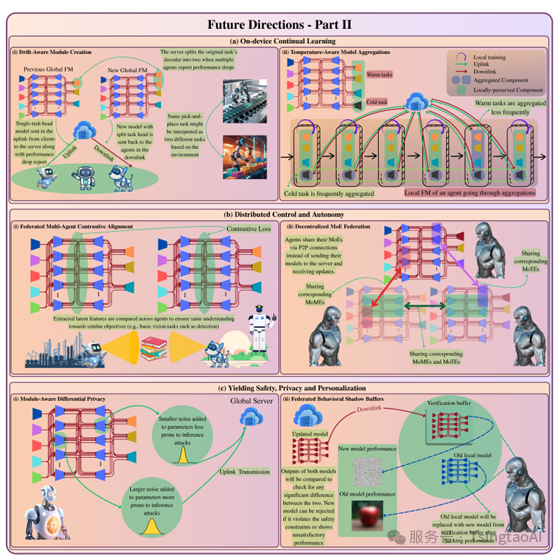
图3. 所设想的未来研究方向的可视化展示。
(a)设备端持续学习。
左图:Drift-Aware Module Aggregation。
右图:Temperature-Aware Model Aggregations。
(b)分布式控制与自主性。
左图:Federated Multi-Agent Contrastive Alignment。
右图:Decentralized MoE Federation。
(c)实现安全性、隐私保护与个性化。
左图:Module-Aware Differential Privacy。
右图:Federated Behavioral Shadowing Buffers。
(ii) Event-Triggered Scheduling of FFM Modules:
在FFMs中,我们设想通过事件触发机制减少不必要的计算与通信开销。具体而言,智能体不必定期向服务器发送模型更新,而是仅在检测到显著的上下文/环境变化、任务切换或性能下降时,动态触发特定FFM模块(如编码器、适配器或专家层)的训练。例如,移动机器人只有在进入新环境或遇到陌生障碍物时,才更新其导航任务头。
D. On-Device Continual Learning
由于面临不断演变的环境、用户偏好和任务定义(见图3(a)),具身智能体的设备端持续学习也带来挑战,我们设想以下研究方向:
(i) Drift-Aware Module Creation:
我们设想为FFMs引入任务漂移管理机制。在智能体层面,任务漂移可能意味着需要对局部任务头进行微调或拆分为两个头。例如,对于家用机器人的“清洁”任务,鉴于房间布局的多样性,可能分别设置“厨房清洁”和“卧室清洁”的专用任务头。关键挑战在于判断这种漂移是局部孤立现象还是全局系统性变化。若多个智能体中均检测到漂移模式(例如通过聚类级别的模型发散指标),服务器可创建一个新的全局任务头;否则,优先采取智能体层面的微调策略(如跨任务邻近项或添加适配器),以避免全局模型膨胀并维持其泛化能力。
(ii) Temperature-Aware Model Aggregations:
在数据和模态漂移普遍存在的动态FL环境中,不同的模型模块可能处于不同的成熟度阶段——有些已经训练充分、表现稳定(称为“热”模块),而有些则是新加入或仍在适应阶段(例如新增模态对应的编码器)(称为“冷”模块)。为应对这种差异,我们设想一种“温度感知”的聚合策略,服务器根据各模块的当前“温度”调整其聚合权重或频率。对于表现良好、稳定的模块,可减少聚合频率以避免边际收益递减;而对于新兴或不确定性高的模块,则增加聚合频次和强度,以加速其在多个智能体间的性能提升。
E. Distributed Control and Autonomy
为了使具身智能体能够在协调的同时以去中心化的方式适应本地任务和上下文环境——见图3(b)——我们设想以下研究方向:
(i) Federated Multi-Agent Contrastive Alignment:
具身智能体通常可以在不同环境中运行、使用不同的硬件或面对不同的用户偏好,但仍执行相似的任务。我们设想采用一种共享的对比学习目标,通过该机制引导智能体将相似任务的内部表示(潜在空间)拉近,并将非相似任务的表示推远。在我们的场景中,这将在不共享原始数据的前提下,使具有相似任务的智能体对任务的理解趋于一致。例如,一架空中无人机和一台地面机器人如果都在执行避障任务,即使它们的传感器和动作方式不同,也可以学习让其对该任务的内部表示趋于相似。
(ii) Decentralized MoE Federation:
智能体之间无需聚合整个模型,而是可以通过P2P通信共享特定任务的模块,如MoME/MoTE/编码器/任务头(即,不是将完整模型上传至中央服务器,而是智能体之间直接交换与特定任务相关的组件,例如导航或操作任务所需模块),从而实现去中心化的协作和局部知识迁移。
F. 实现Yielding Safety、Privacy和Personalization
为了使智能体能够满足安全、隐私和用户特定约束条件——见图3(c)——我们设想以下研究方向:
(i) Module-Aware Differential Privacy:
为防止数据泄露(例如通过对智能体向服务器发送的模型更新进行推理攻击),我们设想引入“模块感知”的差分隐私机制:这是一种在FFM中更细粒度的隐私保护方法,在智能体传输模块用于聚合之前,根据模块类型(如编码器、任务头、MoME/MoTE等)施加非均匀噪声。该方法中,噪声强度可以根据各模块的重要性及其使用模式进行调整。例如,一个捕捉通用特征的编码器,或是一个频繁被激活、用于敏感任务的专家模块,应受到更强的噪声扰动;而针对特定任务的头部或较少使用的专家模块则可以施加较弱噪声,因为它们带来的隐私风险较低。
(ii) Federated Behavioral Shadow Buffers:
为了确保从服务器传来的模型更新在被智能体实际应用前是安全的,我们设想先以“影子模式”部署这些更新,而不是立即启用。在这种模式下,更新后的模型会做出预测,但其动作不会被执行。智能体会将这些预测与旧模型的结果进行比较,寻找显著差异,同时关注用户的反应(例如纠正或反馈)。这样可以帮助智能体和系统判断新更新是否提升了性能,同时避免引发安全问题或产生不良行为。这种影子机制可以针对每个用户或任务进行个性化设置,并仅在敏感情境下启用,例如当机器人在有人的共享空间中行动时。另外,也可以选择在一个虚拟环境中测试新模型的行为,例如通过数字孪生技术,在无现实风险的情况下观察模型行为的后果。
V. FFMs的评估维度:面向EMBODY的视角
接下来,我们设想围绕EMBODY维度构建一个评估框架。
-
Embodiment Heterogeneity: 为了评估模型在不同机器人形态结构和传感器配置下的泛化能力,应在leave-one-embodiment-out设定下进行测试。即在N−1种具身形式上训练模型,并在第N种具身上进行零样本部署。关键评估指标包括任务成功率、在不同形态结构下的策略稳定性以及安全违规情况。基准测试环境应模拟可变运动学、传感器保真度和执行延迟。
-
Modality Richness and Imbalance: FFMs应对跨智能体的模态缺失或稀疏具有鲁棒性。因此,评估应测量在模态缺失、模态不平衡或晚融合时间错配(即由于传感器更新频率或处理延迟导致视觉、触觉或本体感觉等模态到达异步或融合时间戳不一致)情况下的性能下降。评估模型鲁棒性的指标包括:模态消融准确率(即有意移除/遮蔽一个或多个输入模态时模型的表现)、跨模态迁移能力(即某一模态学到的知识能在多大程度上用于推断或补偿另一模态,如用视觉信息推测音频或触觉信息)、依赖偏差(即模型过度依赖单一模态的程度)。
-
Bandwidth and Compute Constraints: 对于部署在资源受限设备上的FFMs,必须评估其通信效率和能耗效率,考虑不同的模块化训练/聚合策略(如参与专家数量的变化、传输编码器 vs 任务头 vs 专家模块等)。评估指标应包括模型更新大小、每任务完成所需的计算量、能效比、模型聚合延迟、处理深度相关指标(如模型更新和执行过程中被激活专家的比例)等。
-
On-Device Continual Learning: FFMs的持续学习能力应通过测量模型适应速度及在环境变化过程中的遗忘率来评估。评估指标包括正向迁移与负向迁移(即利用已有知识学习新任务的能力,以及学习新任务后保留旧知识的能力)、适应时间(即FFM在新任务/环境下提升性能的速度)、保留曲线(即模型随时间推移对先前学习任务保持效果的轨迹)等。
-
Distributed Control and Autonomy: FFMs应评估其协调有效性、全局/本地模型更新延迟、跨智能体泛化能力。评估指标可能包括智能体间行为差异(即在相同FFM下训练的不同智能体表现出不一致或冲突行为的程度)、涌现行为一致性(即训练后的智能体在与环境交互时能否收敛到协调或互补行为)、对异步更新的鲁棒性(即当智能体在不同时间接收并应用模型更新时,模型是否仍能保持稳定表现)。
表 II
具身智能中FFM设计的关键权衡关系(基于EMBODY维度) 。
最后一列中的字母“E”、“M”、“B”、“O”、“D”和“Y”分别代表EMBODY的各个维度。
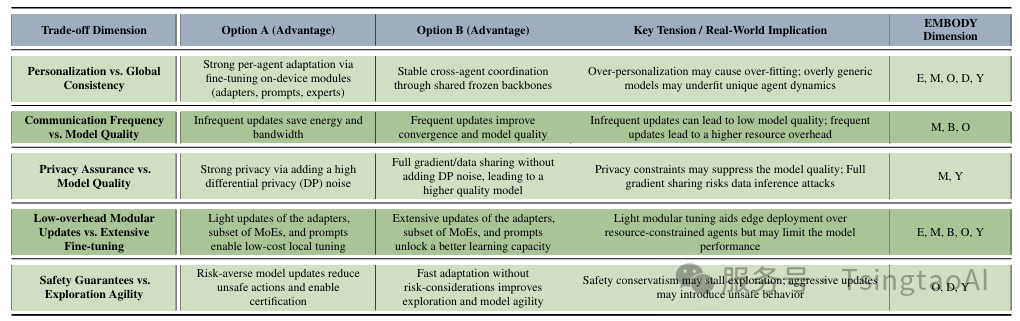
表 III
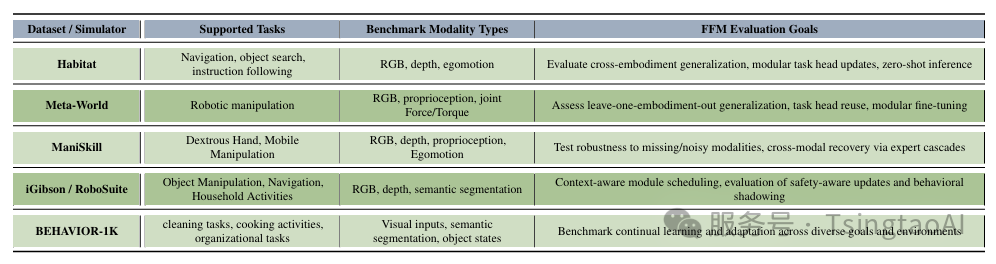
使用现有具身智能数据集对FFMs进行基准测试:数据集特性及其提供的模态与任务 [15] 。
-
实现Yielding Safety、Privacy和Personalization: 对FFMs的评估必须明确捕捉其安全性违规情况,例如碰撞、危险区域误分类或违反监管规定等。此外,隐私保护效用应通过诸如差分隐私等技术在不同模型模块上的应用如何影响下游具身智能任务性能来衡量。进一步地,个性化效果应从每个用户/智能体的任务性能提升(即单个智能体在本地适应后任务表现的提升程度)以及潜在的“目标偏离风险”(即个性化更新可能偏离全局目标或引入非预期行为的可能性)两个方面进行评估。
Design Tradeoffs and Benchmarking:
为了在具身智能中有效部署FFMs,理解在模型个性化能力、跨智能体一致性、资源限制、安全性和互操作性之间出现的多维权衡关系至关重要。为便于理解,我们在表II中结构化呈现了这些权衡关系,并以EMBODY维度为框架进行分析。每一行突出显示了两种相互竞争的设计选择之间的张力,例如个性化 vs 全局泛化、模块化更新 vs 全量微调,并阐明了它们在现实世界中的影响。该表格可作为系统设计者根据目标环境的操作优先级和约束条件定制FFM架构和协议的指导工具。
此外,在表III中,我们结构化描述了可用于在多样化任务和模态下评估FFMs的关键具身智能基准数据集。
VI. 结论
本文中,我们设想通过将M3T FMs的强大泛化能力与FL的去中心化学习能力相结合,FFMs能够在具身智能生态系统中提供一种统一的学习方法。借助EMBODY框架,我们明确了FFMs在真实世界具身智能部署中所需应对的核心维度。针对每一个维度,我们识别了开放性的挑战,并提出了覆盖模型架构、训练机制和系统配置等多个层面的研究方向。同时,我们也讨论了面向具身智能系统的FFM部署评估协议与权衡分析方法。
参考文献
[1] J. Duan, S. Yu, H. L. Tan, H. Zhu 和 C. Tan,“具身智能综述:从仿真器到研究任务”(A survey of embodied AI: From simulators to research tasks),《IEEE计算智能新兴专题汇刊》(IEEE Transactions on Emerging Topics in Computational Intelligence),第6卷,第2期,第230–244页,2022年。
[2] D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang 等,“PaLM-E:一种具身多模态语言模型”(PaLM-E: An embodied multimodal language model),2023年。
[3] Y. Xianjia, J. P. Queralta, J. Heikkonen 和 T. Westerlund,“机器人与自主系统中的联邦学习”(Federated learning in robotic and autonomous systems),《计算机科学程序》(Procedia Computer Science),第191卷,第135–142页,2021年。
[4] S. Savazzi, M. Nicoli, M. Bennis, S. Kianoush 和 L. Barbieri,“在互联、协作与自动化工业系统中联邦学习的机遇”(Opportunities of federated learning in connected, cooperative, and automated industrial systems),《IEEE通信杂志》(IEEE Communications Magazine),第59卷,第2期,第16–21页,2021年。
[5] Figure AI 提供的 Figure 01,“Figure AI 官网”,https://www.figure.ai,访问于2025年5月14日。
[6] S. Loukili, A. Fennan 和 L. Elaachak,“使用大语言模型生成电子邮件主题:GPT-3.5、PaLM 2 和 BERT 的比较”(Email subjects generation with large language models: GPT-3.5, PaLM 2, and BERT),《国际电气与计算机工程期刊》(International Journal of Electrical & Computer Engineering (2088-8708)),第14卷,第4期,2024年。
[7] S. Jamal, H. Wimmer 和 C. M. Rebman Jr,“文本到图像生成AI模型的认知与评估:DALL-E、Google Imagen、GROK与Stable Diffusion的对比研究”(Perception and evaluation of text-to-image generative AI models: a comparative study of DALL-E, google Imagen, GROK, and stable diffusion),《信息系统问题》(Issues in Information Systems),第25卷,第2期,第277–292页,2024年。
[8] N. Ferruz, M. Zitnik, P.-Y. Oudeyer, E. Hine, N. Sengupta, Y. Shi, D. Mincu, S. P. Mann, P. Das 和 F. Stella,“人工智能周年反思”(Anniversary AI reflections),《自然机器智能》(Nature Machine Intelligence),第6卷,第1期,第6–12页,2024年。
[9] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu 等,“RT-1:面向大规模现实世界控制的机器人Transformer模型”(RT-1: Robotics transformer for real-world control at scale),arXiv预印本,编号 arXiv:2212.06817,2022年。
[10] K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauz´a, T. Davchev, Y. Zhou, A. Gupta, A. Raju 等,“RoboCat:一个自我提升的通用机器人操作智能体”(Robocat: A self-improving generalist agent for robotic manipulation),arXiv预印本,编号 arXiv:2306.11706,2023年。
[11] M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman 等,“听其言不如观其行:将语言锚定在机器人可执行能力上”(Do as I can, not as I say: Grounding language in robotic affordances),arXiv预印本,编号 arXiv:2204.01691,2022年。
[12] S. H. Vemprala, R. Bonatti, A. Bucker 和 A. Kapoor,“ChatGPT 在机器人领域的应用:设计原则与模型能力”(ChatGPT for robotics: Design principles and model abilities),《IEEE Access》,2024年。
[13] C. Ren, H. Yu, H. Peng, X. Tang, B. Zhao, L. Yi, A. Z. Tan, Y. Gao, A. Li, X. Li 等,“联邦基础模型的进展与开放挑战”(Advances and open challenges in federated foundation models),《IEEE通信调查与教程汇刊》(IEEE Communications Surveys & Tutorials),2025年。
[14] J. Chen 和 A. Zhang,“关于模态-任务无关联邦学习中非对称知识迁移的解耦研究”(On disentanglement of asymmetrical knowledge transfer for modality-task agnostic federated learning),载于《AAAI人工智能大会论文集》(Proceedings of the AAAI Conference on Artificial Intelligence),第38卷,第10期,2024年,第11311–11319页。
[15] C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Martín-Martín, C. Wang, G. Levine, W. Ai, B. Martinez 等,“BEHAVIOR-1K:一个人类中心、包含1000种日常活动和真实仿真的具身智能基准数据集”(BEHAVIOR-1K: A human-centered, embodied AI benchmark with 1,000 everyday activities and realistic simulation),CoRR,2024年。
关于TsingtaoAI
TsingtaoAI拥有一支高水平的产学研一体的AI产品开发团队,核心团队主要来自清华大学、北京大学、首尔大学、中科院、北京邮电大学、复旦大学、中国农业大学、华中科技大学、美团、京东、百度、中国技术创业协会和三一重工等产研组织。 TsingtaoAI核心团队擅长面向教育领域的LLM和AIGC应用开发。公司拥有近10项LLM/AIGC相关的知识产权。TsingtaoAI自研基于LLM大模型的AIGC应用开发实训平台、基于AI大模型的具身智能实训解决方案、面向CS类的AI训练实训平台等产品方案,为高校提供实训解决方案、师资研修和实验实训课程开发服务。