添加训练噪声以改进检测——去噪机制

早期视觉Transformer
DETR — DEtection TRANSformer(Carion、Massa 等人,2020)是首批用于目标检测的 Transformer 架构之一,它使用学习到的解码器查询从图像 token 中提取检测信息。这些查询是随机初始化的,并且该架构没有施加任何约束来强制这些查询学习类似于锚点的内容。虽然它取得了与 Faster-RCNN 相当的结果,但它的缺点是收敛速度慢——需要 500 个 epoch 来训练它(DN-DETR,Li 等人,2024)。近期基于 DETR 的架构使用了可变形聚合,使查询能够仅关注图像中的某些区域(Zhu 等人,《可变形 DETR:用于端到端对象检测的可变形 Transformers》,2020 年),而其他一些架构(Liu 等人,《DAB-DETR:动态锚框是 DETR 的更佳查询》,2022 年)则使用了空间锚点(使用 K 均值生成,方式类似于基于锚点的 CNN),这些锚点被编码到初始查询中。跳过连接迫使 Transformer 的解码器模块将框作为来自锚点的回归值进行学习。可变形注意层使用预编码锚点从图像中采样空间特征,并使用它们构建需要注意的标记。在训练过程中,模型会学习要使用的最佳锚点。这种方法教会模型在查询中明确使用框大小等特征。
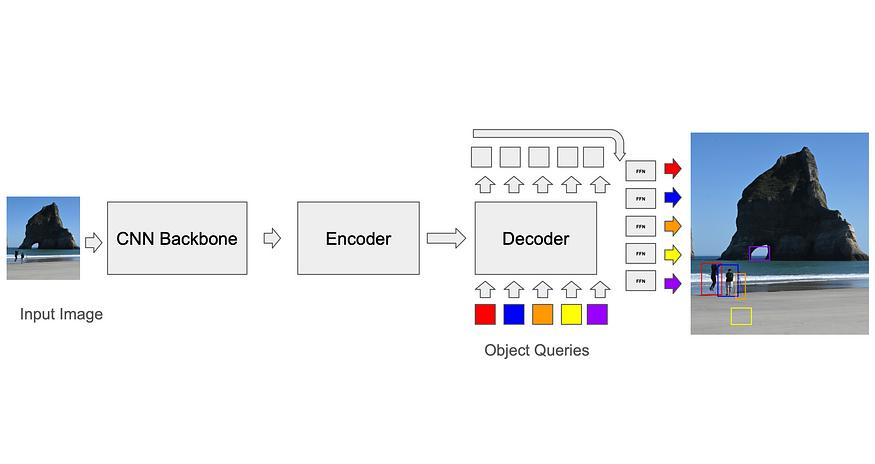
预测与真实值匹配
为了计算损失,训练器首先需要将模型的预测与地面实况 (GT) 框进行匹配。虽然基于锚点的 CNN 可以相对轻松地解决这个问题(例如,每个锚点在训练期间只能与其体素中的 GT 框匹配,并且在推理过程中使用非最大抑制来消除重叠检测),但由 DETR 设定的 Transformer 标准是使用一种称为匈牙利算法的二分匹配算法。在每次迭代中,该算法都会找到与 GT 匹配的最佳预测(该匹配会优化某些成本函数,例如框角之间的均方距离,并将其对所有框求和)。然后,在预测-GT 框对之间计算损失,并可以进行反向传播。过多的预测(没有匹配 GT 的预测)会产生单独的损失,从而导致它们降低置信度得分。
问题
匈牙利算法的时间复杂度为 o(n³)。有趣的是,这不一定是训练质量的瓶颈:已有研究表明(《稳定婚姻问题:从物理学家视角的跨学科评论》(Fenoaltea 等人,2021 年),该算法是不稳定的,因为其目标函数的微小变化可能会导致匹配结果发生剧烈变化,从而导致查询训练目标不一致。Transformer 训练的实际影响在于,对象查询可能会在不同对象之间跳跃,并且需要很长时间才能学习到最佳收敛特征。
DN-DETR
Li 等人提出了一种解决不稳定匹配问题的优雅解决方案,后来被许多其他作品采用,包括 DINO、Mask DINO、Group DETR 等。
DN-DETR 的主要思想是通过创建虚拟的、易于回归的锚点来加速训练,从而跳过匹配过程。这是在训练期间通过向 GT 框添加少量噪声并将这些噪声框作为锚点提供给解码器查询来实现的。DN 查询与有机查询之间会被屏蔽,反之亦然,以避免交叉注意力机制干扰训练。这些查询生成的检测结果已经与其源 GT 框匹配,不需要二分匹配。DN-DETR 的作者已经证明,在 epoch 结束的验证阶段(关闭去噪),与 DETR 和 DAB-DETR 相比,这提高了模型的稳定性,因为在连续的 epoch 中,更多查询与 GT 对象的匹配保持一致。(见图 2)。
作者表明,使用 DN 既可以加速收敛,又能获得更佳的检测结果。(见图 3)他们的消融研究表明,在使用 ResNet-50 作为骨干网络时,COCO 检测数据集上的 AP 提升了 1.9%,而之前的 SOTA(DAB-DETR,AP 为 42.2%)则有所提升。
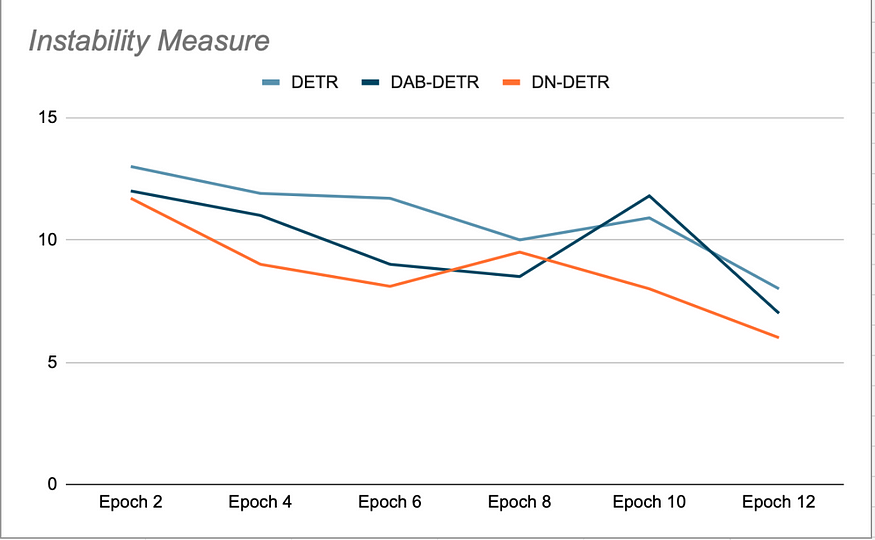
训练期间不稳定性图示,以验证期间的测量结果为准。基于 DN-DETR(Li 等人,2022 年)提供的数据。
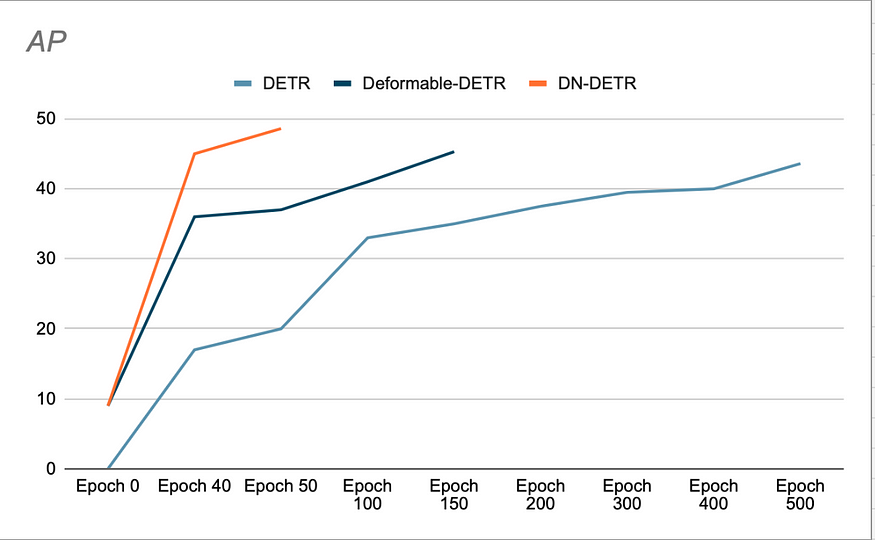
DN-DETR 的性能在 1/10 的训练周期内迅速超越了 DETR 的最高性能。基于 DN-DETR 中的数据(Li 等人,2022 年)。
DINO 和对比去噪
DINO 进一步发展了这一理念,并在去噪机制中加入了对比学习:除了正例之外,DINO 还为每个 GT 创建另一个加噪版本,该版本在数学上被构造为与正例相比与 GT 的距离更远(见图 4)。该版本用作训练的反例:模型学会接受更接近真实值的检测结果,并拒绝距离更远的检测结果(通过学习预测“无物体”类别)。
此外,DINO 支持多个对比去噪 (CDN) 组(每个 GT 对象有多个加噪锚点),从而从每次训练迭代中获得更多收益。
DINO 的作者报告称,使用 CDN 时 AP 为 49%(在 COCO val2017 上)。
最近的时间模型需要使用 CDN 逐帧跟踪对象,例如 Sparse4Dv3,并添加时间去噪组,其中一些成功的 DN 锚点(以及学习到的非 DN 锚点)存储起来,以便在后续帧中使用,从而增强模型在对象跟踪方面的性能。

去噪图解。训练过程快照。绿色框是当前锚点(从先前图像中学习或固定)。蓝色框是鸟类目标的地面实况 (GT) 框。黄色框是通过向 GT 框添加噪声(同时改变位置和尺寸)生成的正例。红色框是负例,保证其与 GT 的距离(在 x、y、w、h 空间中)比正例更远。
讨论
去噪(DN)似乎可以提高视觉变换器检测器的收敛速度和最终性能。但是,研究上述各种方法的演变,提出了以下问题:
- DN 改进了使用可学习锚点的模型。但可学习锚点真的那么重要吗?DN 是否也能改进使用不可学习锚点的模型?
- DN 对训练的主要贡献在于通过绕过二分匹配来增强梯度下降过程的稳定性。但二分匹配的存在似乎主要是因为 Transformer 的工作标准是避免查询的空间约束。因此,如果我们手动将查询限制在特定的图像位置,并放弃使用二分匹配(或者使用简化版的二分匹配,在每个图像块上分别运行),DN 还能提升结果吗?
我找不到能明确解答这些问题的著作。我的假设是,如果一个模型使用了不可学习的锚点(前提是锚点不太稀疏)和空间受限的查询,那么:1——不需要二分匹配算法;2——在训练过程中,DN 不会带来任何好处,因为锚点是已知的,学习从其他易逝锚点回归没有任何好处。
如果锚点是固定的但稀疏的,那么我可以看到使用更容易回归的瞬时锚点可以为训练过程提供热启动。
Anchor-DETR (Wand et al., 2021) 比较了可学习和不可学习的anchor的空间分布,以及各自模型的性能。在我看来,可学习性对模型性能的提升并不大。值得注意的是,这两种方法都使用了匈牙利算法,因此尚不清楚他们是否可以放弃二分匹配并保持性能。
一旦考虑,就会发现可能存在生产原因需要避免在推理中使用 NMS,这促进了在训练中使用匈牙利算法。
降噪在哪些方面真正重要?在我看来——在追踪中。在追踪中,模型会被输入视频流,不仅需要检测连续帧中的多个物体,还需要保留每个检测到的物体的唯一标识。时间变换模型(即利用视频流顺序特性的模型)不会独立处理各个帧。相反,它们会维护一个存储先前检测结果的库。在训练中,追踪模型被鼓励从物体的先前检测结果(或者更准确地说——与物体先前检测结果相关的锚点)进行回归,而不是简单地从最近的锚点进行回归。而且,由于先前的检测结果并不局限于某个固定的锚点网格,因此去噪带来的灵活性可能是有益的。我非常希望阅读未来关注这些问题的著作。