越狱蒸馏-可再生安全基准测试
大家读完觉得有帮助记得关注!!!
摘要
大型语言模型(LLMs)正迅速部署在关键应用中,这引发了对稳健安全基准测试的迫切需求。我们提出了越狱提炼(JBDISTILL),这是一种新颖的基准构建框架,可以将越狱攻击“提炼”成高质量且易于更新的安全基准。JBDISTILL利用一小组开发模型和现有的越狱攻击算法来创建一个候选提示池,然后采用提示选择算法来识别有效的提示子集作为安全基准。JBDISTILL解决了现有安全评估中的挑战:在不同模型中使用一致的评估提示,确保了公平的比较和可重复性。它只需要极少的人工干预即可重新运行JBDISTILL流程并生成更新的基准,从而缓解了对饱和和污染的担忧。广泛的实验表明,我们的基准能够稳健地推广到13个不同的评估模型,这些模型在基准构建中被排除在外,包括专有模型、专用模型和新一代LLM,在有效性方面显著优于现有的安全基准,同时保持了高度的可分离性和多样性。因此,我们的框架为简化安全评估提供了一种有效、可持续和适应性强的解决方案。
1 引言
随着大型语言模型(LLM)的快速发展并被部署到关键应用中,迫切需要可靠的安全评估方法,这些方法能够跟上新模型和对抗性攻击的步伐,并在造成危害之前发现失效模式。一种常见的范例是动态安全评估,例如,基于LLM的红队方法,其生成对抗性攻击以发现安全漏洞(Ganguli et al., 2022; Perez et al., 2022; Shen et al., 2023; Andriushchenko et al., 2025)。或者,研究人员手动策划提示并将它们聚合为静态安全基准(Chao et al., 2024a; Souly et al., 2024; Zhang et al., 2024)。然而,先前的研究已经注意到,当前LLM安全评估,包括动态评估和静态基准,都不够稳健(Beyer et al., 2025; Eiras et al., 2025),面临着可比性、可重复性和饱和度方面的问题。因此,迫切需要新的安全评估范例。
我们首先提出一个根本性的问题:什么构成了一个好的安全基准?为了回答这个问题,我们概述了安全基准的关键要求——有效性、可分离性和多样性——并提出了相应的指标来评估基准质量(§2)。为了解决现有评估范式的缺点,我们提出了Jailbreak Distillation (JBDISTILL)2,这是一个两全其美的框架,它解决了基于LLM的动态红队算法的可比性和可重复性挑战,以及静态安全基准的饱和和污染挑战(§3)。
JBDISTILL 引入了一种新颖的基准构建流程,该流程将越狱攻击“提炼”成高质量且易于更新的安全基准。它首先通过在一小组“开发模型”上运行现成的越狱攻击算法来创建一个候选提示池,从而将种子有害查询转换为多样化的对抗性提示。接下来,基于开发模型的有效性可以作为保留评估模型有效性的代理(在第 5 节中经过实证验证)的直觉,我们提出了几种提示选择算法,这些算法允许 JBDISTILL 从候选提示池中选择有效的提示子集作为安全基准。
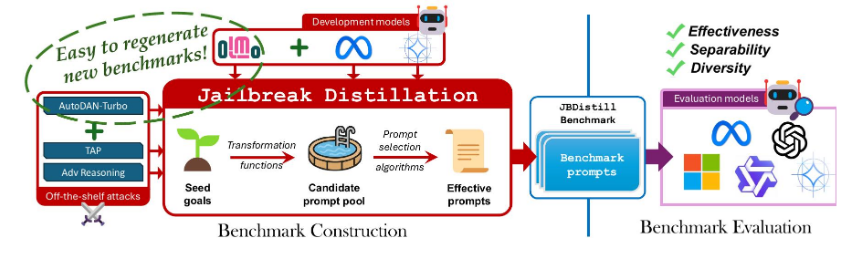
图 1:JBDISTILL 构建高质量且易于更新的安全基准。给定一组种子目标,我们使用现成的攻击作为转换函数来创建一个候选提示池,然后使用开发模型来选择有效的提示作为基准,从而在留出的评估模型上实现高有效性、可分离性和多样性。通过添加新的开发模型、攻击或使用不同的随机化重新运行管道,可以轻松地重新生成新的基准。
相较于为每个模型朴素地运行动态安全评估,JBDISTILL 具有多项优势。由于在测试时对所有模型使用相同的评估提示集,JBDISTILL 确保了公平的比较,并且比朴素地运行基于 LLM 的红队测试更具可重复性。后者在不一致的计算预算下为不同的模型开发不同的攻击提示,并且其攻击设置中的微小变化(例如,超参数、聊天模板)可能导致攻击成功率的巨大差异(Beyer et al., 2025)。由于昂贵的攻击仅在基准构建期间运行,因此 JBDISTILL 在评估时也显着提高了效率。直观地说,JBDISTILL 将为每个评估模型生成越狱攻击的测试时间成本分摊到基准构建时间中。
相较于精心策划不安全提示的静态安全基准测试(Chao et al., 2024a; Souly et al., 2024; Zhang et al., 2024),JBDISTILL只需最少的人工即可创建包含新模型和攻击的更新版本基准,只需重新运行基准创建流程即可。JBDISTILL易于更新的特性缓解了对基准饱和和污染的担忧(Li et al., 2024; Chen et al., 2025)。
实验结果表明,仅使用四个 8B 规模的开源开发模型,JBDISTILL 产生的基准测试即可达到高达 81.8% 的有效性,并推广到 13 个不同的评估模型,包括更新、更大、专有、专门和推理模型。我们还发现了有效性和可分离性之间的权衡,这可以通过提示选择算法来控制。消融研究表明,JBDISTILL 的每个组件对于高有效性至关重要,并且新的模型和攻击可以轻松集成到基准构建过程中。
我们的主要贡献是:(1)我们概述了安全基准的期望和评估标准。(2)我们提出了JBDISTILL,这是一个高级框架,可以实现可再生的安全基准测试。(3)我们在两种设置中实例化JBDISTILL——单轮和多轮评估,并提出了有效的提示选择算法,并通过我们的实验进行了实证验证。(4)我们进行了分析,没有发现JBDISTILL产生的基准中存在显著偏差的证据。
2 安全基准的期望
虽然许多基准测试旨在评估模型的安全性,但我们应该如何评估这些基准测试本身的质量?我们定义了评估设置和关键期望属性,然后将其具体化为评估基准测试的指标。
2.1 预备知识

2.2 评估安全基准
为了评估安全基准,我们在一组多样化的evaluation models Meval上运行它,并收集汇总统计数据,因为我们认为使用广泛的模型(其负责任的部署至关重要)可以为基准的实际效用提供可靠的代理。3 我们为安全基准提出了三个期望的特性:有效性、可分离性和多样性。

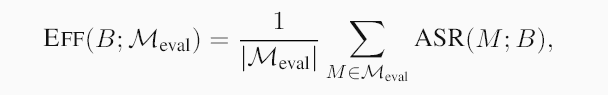

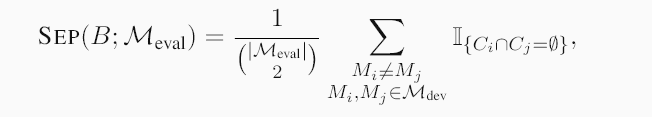

![]()

我们用另一个多样性指标——覆盖率来补充通用性,即基准测试所覆盖的种子目标的比例。覆盖率很重要,因为它表明基准测试在多大程度上代表了原始的种子目标集。
我们认为这三个期望都至关重要:一个有效性低的基准测试揭示的安全漏洞有限,因此不可靠。如果没有高可分离性,它就无法区分不同模型的安全性,从而使基准测试结果不确定。低多样性意味着狭隘的关注点(低覆盖率)或仅对一小部分种子目标有效(低通用性),从而导致有偏差的评估结果。
3 JBDISTILL框架
现在,我们介绍 JBDISTILL 框架,该框架将越狱攻击提炼成有效的安全基准(图 1)。我们首先描述其关键组成部分,然后提出一个统一的算法,最后给出 JBDISTILL 为何能实现强大有效性的直觉。
关键组成部分。为了实现生成广泛有效的安全基准的最终目标,我们建议在基准构建过程中使用一小组开发模型Mdev。我们假设使用多个Mdev的信息来生成和选择评估提示可以产生更有效的基准(在§5.4中验证)。JBDISTILL 从种子目标G = {g1, . . . , gn}开始,这些目标可以很容易地从现有基准中获得,或者经过精心策划以针对特定的有害领域。




4 JBDISTILL的实例化

4.1 变换函数

我们直接采用了上述8种现成的攻击方法,因为它们是最近提出的、被广泛使用,并且能够生成可解释的(语义上有意义的)提示,这对于从基准测试过程中获得见解至关重要。使用这些现成的攻击方法作为转换函数已经非常有效,正如我们在第5节中展示的那样,它显著优于所有基线。为JBDISTILL开发有针对性的转换可能会带来进一步的改进,为未来的工作留下潜力。
4.2 提示选择的问题构建


4.3 提示选择算法
我们提出了几种提示选择算法,这些算法与单轮和多轮JBDISTILL兼容。有趣的是,我们发现在实践中,简单的贪婪算法已经实现了很高的有效性和可分离性(§5.2)。我们使用随机选择作为基线,并提出了三种算法:RBS、BPG和CS。





5. JBDISTILL框架实验
5.1 实验装置
种子目标 我们从 HarmBench (Mazeika et al., 2024) 基准测试中获取种子目标,使用包含 200 个种子目标的标准行为集。我们使用 HarmBench 是因为它被广泛使用,并且它包含具有 7 个语义类别的多样化目标集,从而方便了我们的分析(§6)。



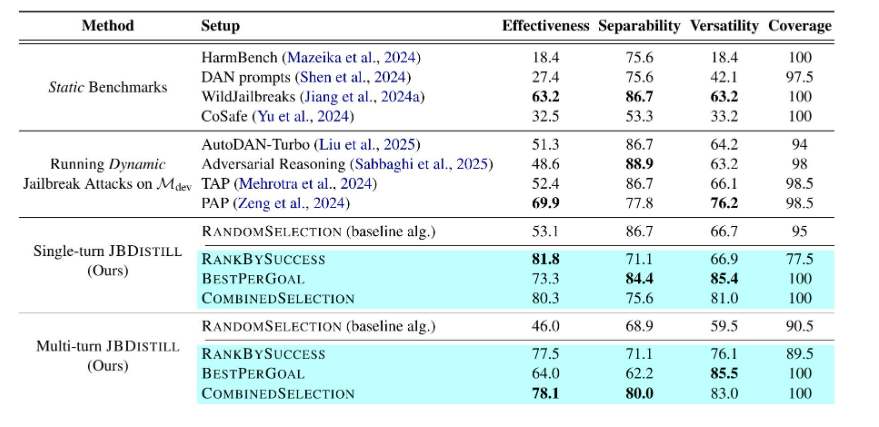
表1:不同基准测试方法在
Meval
上的性能表现(%)。JBDISTILL使用HarmBench作为种子目标。非基线的JBDISTILL基准测试已高亮显示。每种基准测试方法的最佳结果已加粗显示。我们提出的框架在有效性和通用性方面显著优于静态基准和动态攻击,同时保持了可分离性和覆盖率。提示选择算法对于产生有效的基准至关重要。
5.2 主要结果
JBDISTILL 优于现有的静态基准和动态越狱攻击(表 1)。无论是在单轮还是多轮测试中,JBDISTILL 在有效性和通用性方面均显著优于静态基准和动态攻击,分别实现了 81.8% 和 78.1% 的最佳有效性。JBDISTILL 还在基线之上保持了可分离性。这验证了我们将越狱攻击提炼成安全基准的动机,并证实 JBDISTILL 产生了高质量的基准。
提示选择算法对于实现高有效性至关重要。表1显示,RBS算法的性能明显优于基线RS算法,有效性分别为81.8%和53.1%,多轮设置也呈现类似趋势。这表明,使用多个开发模型可以选择有效的提示子集,从而验证了我们的核心假设。虽然之前的工作主要集中在生成更具迁移性的攻击提示(Zou et al., 2023; Sabbaghi et al., 2025; Lin et al., 2025a; Yang et al., 2025),但我们表明,使用现成的方法过度生成攻击提示,然后选择一个高效的提示子集,是一种简单、有效且被忽视的增强攻击迁移性的方法。我们在§7中提供了进一步的讨论。
我们还观察到有效性和可分离性之间存在权衡:当提示非常有效以至于大多数提示可以破解大多数模型时,模型之间的性能差异会更小。然而,这种权衡可以通过提示选择算法的选择来实现:BPG实现了最佳的可分离性,但牺牲了一些有效性,实现了73.3%的有效性,而RBS的有效性为81.8%。在实践中,基准开发者可以选择最适合其需求的算法,以平衡不同的需求。
5.3 推广到评估模型

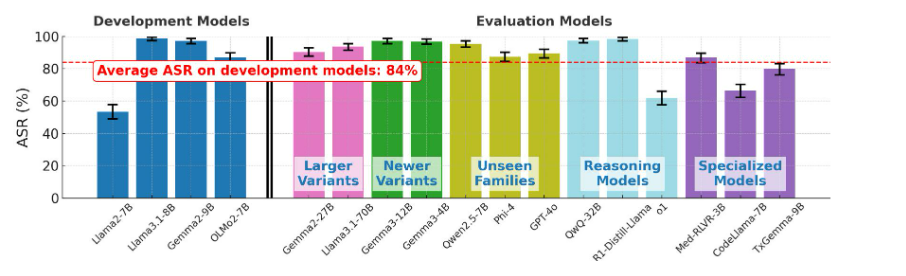
图2:JBDISTILL生成的基准(RBS)的ASR,其中误差条表示95%的置信区间(CI)。该基准在基准构建期间保留的不同评估模型组中有效,其中13个模型中有10个实现了比开发模型的平均ASR更高的ASR(水平虚线)。
5.4 消融实验:增加开发模型和变换函数
我们使用RBS选择算法改变JBDISTILL基准构建中使用的开发模型和转换函数的数量。图3表明,随着更多模型和转换函数的加入,基准的有效性增加,显著优于使用单一模型或单一转换函数的平均有效性。这进一步支持了JBDISTILL的可持续性:随着新模型和越狱攻击的发布,它们可以很容易地被纳入JBDISTILL,以构建一个更新的基准,该基准将保持或提高有效性。这与静态基准形成对比,静态基准通常需要大量的人力来更新和维护。这与静态基准形成对比,静态基准通常需要大量的人力来更新和维护。
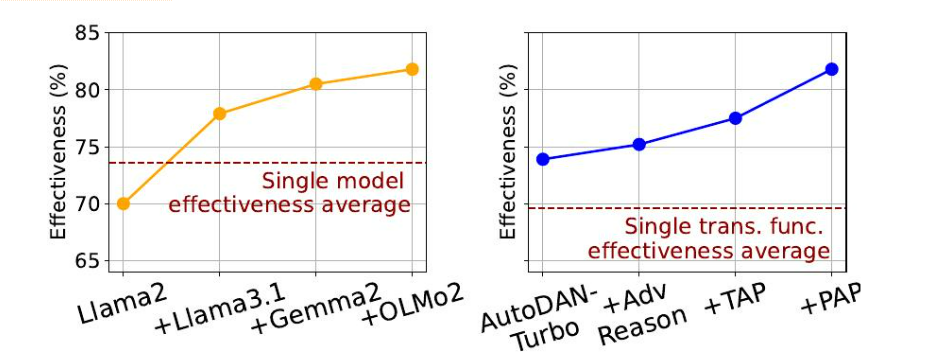
图3:随着更多开发模型和转换函数的加入,基准在预留评估模型上的有效性得到提高,优于使用单一开发模型或转换函数的平均有效性。
![]()
6 分析
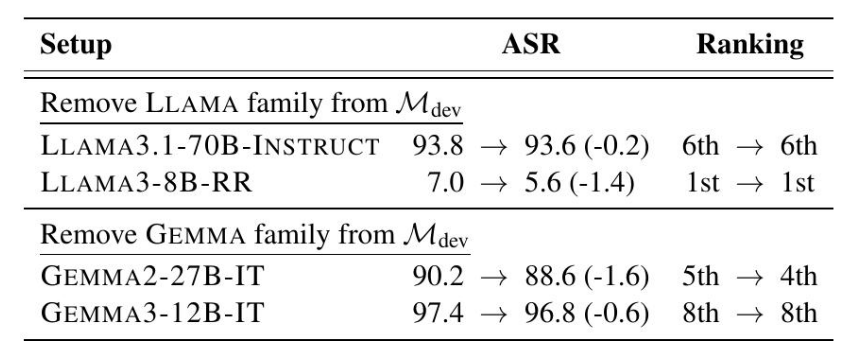
6.1 JBDISTILL基准测试是否偏向于开发模型家族?

6.2 不同施工设置下的稳定性



6.3 多轮回复传递分析

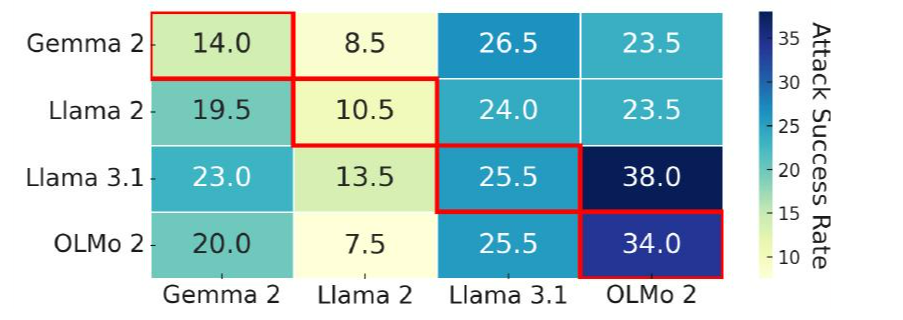

我们将基准分解的进一步分析推迟到§C。
7 相关工作




8 讨论与结论
在大型语言模型和风险环境快速变化的时代,我们提出了JBDISTILL,并展示了其在可再生安全评估方面的强大能力,解决了现有动态评估的可比性和可重复性挑战,以及静态基准测试的饱和和污染问题。我们强调,JBDISTILL不能取代红队测试(人工或自动),后者可以与基准测试方法产生互补的优势(Bullwinkel et al., 2025)。
我们的工作为对抗攻击的开发和安全基准测试之间的关系提供了一个新的视角。尽管我们的评估侧重于输入空间攻击,但由于评估是通过提示进行的,因此将攻击“提炼”成基准测试的相同高级原则可以应用于更广泛的攻击空间,例如模型调温攻击(Che et al., 2025),从而推动未来的工作,以全面地检查LLM安全的不同支柱。
局限性
我们的工作范围仅限于英语文本目标和可解释的越狱攻击算法,将其作为转换函数。未来的工作可以探索使用JBDISTILL构建多语言、多模态的基准,将转换函数集合扩展到更广泛的攻击集合,或者使用针对多个开发模型共同进行的攻击(Zou et al., 2023;Sabbaghi et al., 2025),并探索为JBDISTILL开发定制的转换函数。我们专注于开发对抗性提示的输入空间攻击,未来的工作可以将我们的框架扩展到扰乱模型潜变量和权重的模型篡改攻击(Che et al., 2025)。
我们的工作侧重于安全性评估,这本身就是一个至关重要的问题,因此我们不考虑安全性和有用性之间的平衡,即安全性和过度拒绝之间的平衡(Röttger et al., 2024;Cui et al., 2024)。未来的工作可以使用我们的JBDISTILL框架来包含针对过度拒绝的种子目标和相应的评判标准,并构建一个评估安全性和过度安全性的基准。
伦理考量
我们的 JBDISTILL 框架构建了由对抗性提示组成的基准,这些提示有效地揭示了安全漏洞。我们强调,这些对抗性攻击应仅用于安全评估,不得滥用于有害应用。由于我们仅从具有公开可用代码库的现成对抗性攻击中获取资源,因此我们认为引入和发布 JBDISTILL 的代码不会构成重大的伦理风险。