vue+elementUI+springboot实现文件合并前端展示文件类型
项目场景:
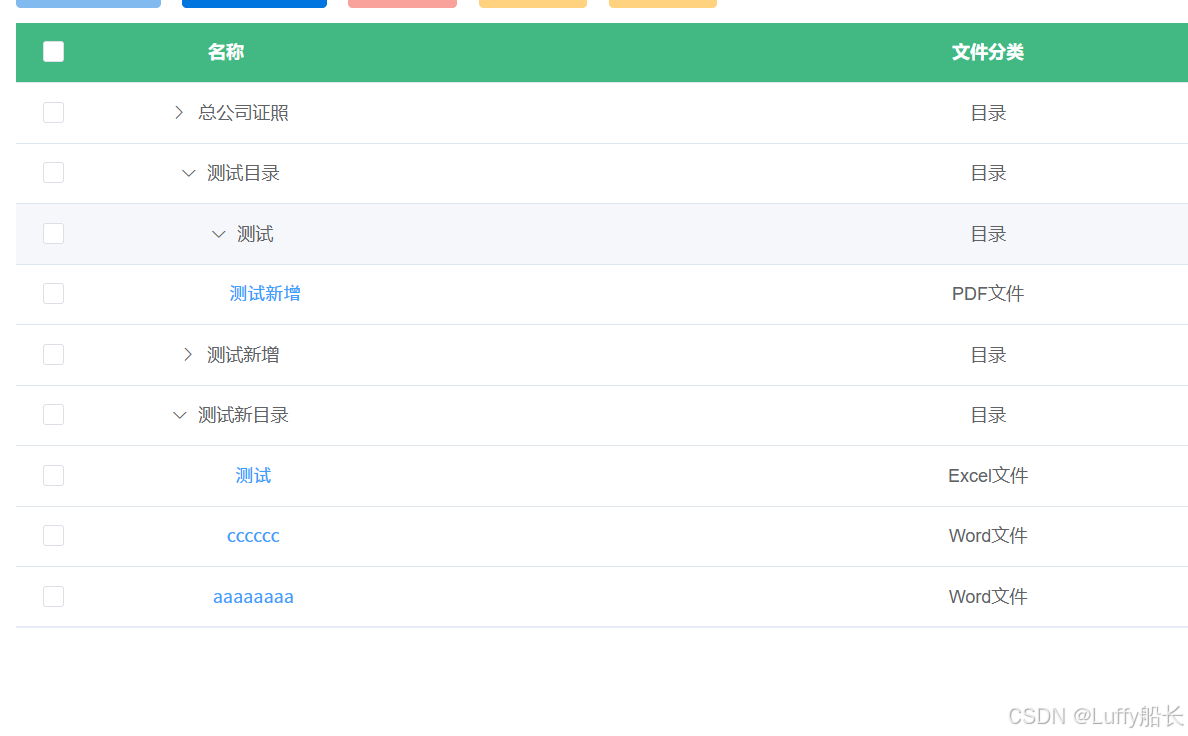
element的table上传文件并渲染出文件名称点击所属行可以查看文件,并且可以导出合并文件,此文章是记录合并文档前端展示的帖子
解决方案:
后端定义三个工具类
分别是pdf,doc和word的excle的目前我没整
word的工具类
package com.sc.modules.biddinvestment.utils;import org.apache.poi.xwpf.usermodel.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;public class WordMerger {private static final Logger logger = LoggerFactory.getLogger(WordMerger.class);public String mergeWordDocuments(List<String> filePaths) throws IOException {validateFiles(filePaths);XWPFDocument mergedDoc = new XWPFDocument();try {for (String filePath : filePaths) {addFileToDocument(mergedDoc, filePath);}return saveMergedDocument(mergedDoc);} finally {mergedDoc.close();}}private void addFileToDocument(XWPFDocument mergedDoc, String filePath) throws IOException {File file = new File(filePath);addSectionTitle(mergedDoc, file.getName());if (filePath.toLowerCase().endsWith(".txt")) {addTxtContent(mergedDoc, file);} else if (filePath.toLowerCase().endsWith(".docx")) {addDocxContent(mergedDoc, file);} else {throw new IllegalArgumentException("暂不支持的文件格式: " + filePath);}}private void addSectionTitle(XWPFDocument doc, String fileName) {XWPFParagraph titlePara = doc.createParagraph();titlePara.setAlignment(ParagraphAlignment.CENTER);XWPFRun titleRun = titlePara.createRun();
// titleRun.setText("===== 文件: " + fileName + " ====="); //添加上之后文档名称会出现在合并后的文档里titleRun.setFontSize(14);titleRun.setBold(true);titleRun.addBreak();}private void addTxtContent(XWPFDocument doc, File txtFile) throws IOException {List<String> lines = Files.readAllLines(txtFile.toPath());XWPFParagraph para = doc.createParagraph();XWPFRun run = para.createRun();for (String line : lines) {run.setText(line);run.addBreak();}run.addBreak(); // 段落间隔}private void addDocxContent(XWPFDocument mergedDoc, File docxFile) throws IOException {try (XWPFDocument sourceDoc = new XWPFDocument(new FileInputStream(docxFile))) {for (XWPFParagraph para : sourceDoc.getParagraphs()) {XWPFParagraph newPara = mergedDoc.createParagraph();newPara.getCTP().set(para.getCTP()); // 复制段落格式}for (XWPFTable table : sourceDoc.getTables()) {mergedDoc.createTable().getCTTbl().set(table.getCTTbl()); // 复制表格}}}private String saveMergedDocument(XWPFDocument doc) throws IOException {Path desktopPath = Paths.get(System.getProperty("user.home"), "Desktop");if (!Files.exists(desktopPath)) Files.createDirectories(desktopPath);String timestamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());Path outputPath = desktopPath.resolve("merged_word_" + timestamp + ".docx");try (FileOutputStream fos = new FileOutputStream(outputPath.toFile())) {doc.write(fos);}logger.info("Word合并完成,输出路径: {}", outputPath);return outputPath.toString();}private void validateFiles(List<String> filePaths) {for (String path : filePaths) {File file = new File(path);if (!file.exists() || !file.canRead()) {throw new IllegalArgumentException("文件无效或不可读: " + path);}}}
}
doc的工具类
package com.sc.modules.biddinvestment.utils;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.BufferedWriter;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;public class DocMerger {private static final Logger logger = LoggerFactory.getLogger(DocMerger.class);// 保留原文本合并功能(可选)public String mergeTxtDocuments(List<String> filePaths) throws IOException {validateFiles(filePaths);Path desktopPath = Paths.get(System.getProperty("user.home"), "Desktop");if (!Files.exists(desktopPath)) Files.createDirectories(desktopPath);String timestamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());Path outputPath = desktopPath.resolve("merged_txt_" + timestamp + ".txt");try (BufferedWriter writer = Files.newBufferedWriter(outputPath, StandardCharsets.UTF_8)) {for (String path : filePaths) {File file = new File(path);writer.write("===== 文件: " + file.getName() + " =====\n");List<String> lines = Files.readAllLines(file.toPath(), StandardCharsets.UTF_8);for (String line : lines) {writer.write(line);writer.newLine();}writer.write("\n\n");}}logger.info("文本合并完成,输出路径: {}", outputPath);return outputPath.toString();}private void validateFiles(List<String> filePaths) {for (String path : filePaths) {File file = new File(path);if (!file.exists() || !file.canRead()) {throw new IllegalArgumentException("文件无效或不可读: " + path);}}}
}
pdf的
package com.sc.modules.biddinvestment.utils;
import org.apache.pdfbox.multipdf.PDFMergerUtility;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.stream.Collectors;public class PdfMerger {private static final Logger logger = LoggerFactory.getLogger(PdfMerger.class);private static final String DEFAULT_OUTPUT_NAME = "merged";private static final String PDF_EXTENSION = ".pdf";/*** 合并多个PDF文件** @param filePaths 要合并的PDF文件路径列表* @return 合并后的文件绝对路径* @throws IOException 如果合并过程中发生错误*/public String mergePdfs(List<String> filePaths) throws IOException {validateInputFiles(filePaths);File outputFile = prepareOutputFile();mergeFiles(filePaths, outputFile);logger.info("成功合并 {} 个PDF文件到: {}", filePaths.size(), outputFile.getAbsolutePath());return outputFile.getAbsolutePath();}/*** 验证输入文件*/private void validateInputFiles(List<String> filePaths) {if (filePaths == null || filePaths.isEmpty()) {throw new IllegalArgumentException("文件路径列表不能为空");}for (String path : filePaths) {if (path == null || path.trim().isEmpty()) {throw new IllegalArgumentException("文件路径不能为空");}File file = new File(path);if (!file.exists()) {throw new IllegalArgumentException("文件不存在: " + path);}if (!file.isFile()) {throw new IllegalArgumentException("路径不是文件: " + path);}if (!file.canRead()) {throw new IllegalArgumentException("文件不可读: " + path);}if (!path.toLowerCase().endsWith(".pdf")) {throw new IllegalArgumentException("仅支持PDF文件: " + path);}}}/*** 准备输出文件*/private File prepareOutputFile() throws IOException {Path desktopPath = Paths.get(System.getProperty("user.home"), "Desktop");// 确保桌面目录存在if (!Files.exists(desktopPath)) {logger.warn("桌面目录不存在,尝试创建: {}", desktopPath);try {Files.createDirectories(desktopPath);} catch (IOException e) {throw new IOException("无法创建桌面目录: " + desktopPath, e);}}// 生成唯一文件名String timestamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());String baseName = DEFAULT_OUTPUT_NAME + "_" + timestamp + PDF_EXTENSION;Path outputPath = desktopPath.resolve(baseName);// 处理文件名冲突int counter = 1;while (Files.exists(outputPath)) {baseName = DEFAULT_OUTPUT_NAME + "_" + timestamp + "_" + counter + PDF_EXTENSION;outputPath = desktopPath.resolve(baseName);counter++;}return outputPath.toFile();}/*** 执行PDF合并*/private void mergeFiles(List<String> inputFilePaths, File outputFile) throws IOException {PDFMergerUtility merger = new PDFMergerUtility();try {// 添加所有源文件for (String filePath : inputFilePaths) {merger.addSource(new File(filePath));}// 设置输出文件merger.setDestinationFileName(outputFile.getAbsolutePath());// 执行合并merger.mergeDocuments(null);} catch (IOException e) {// 合并失败时删除可能已创建的部分输出文件if (outputFile.exists() && !outputFile.delete()) {logger.error("无法删除部分合并的文件: {}", outputFile.getAbsolutePath());}throw new IOException("PDF合并失败: " + e.getMessage(), e);}}// 重载方法,支持可变参数public String mergePdfs(String... filePaths) throws IOException {return mergePdfs(Arrays.asList(filePaths));}}调用方法
@PostMapping("/mergeDocuments")
public String mergeFiles(@RequestBody Map<String, List<String>> request) {try {List<String> filePaths = request.get("filePaths");if (filePaths == null || filePaths.isEmpty()) {return "错误:文件路径列表为空!";}boolean allPdf = filePaths.stream().allMatch(path -> path.toLowerCase().endsWith(".pdf"));String mergedFilePath;if (allPdf) {PdfMerger merger = new PdfMerger();mergedFilePath = merger.mergePdfs(filePaths);} else {WordMerger wordMerger = new WordMerger();mergedFilePath = wordMerger.mergeWordDocuments(filePaths);}return "文件合并成功,保存路径: " + mergedFilePath;} catch (Exception e) {return "文件合并失败:" + e.getMessage();}
}前端:
getMenuData() {setTimeout(() => {url.getMenusTree().then(res => {// 定义文件类型映射const fileTypeMap = {pdf: 'PDF文件',doc: 'Word文件',docx: 'Word文件',xls: 'Excel文件',xlsx: 'Excel文件'};// 提取文件后缀的工具函数const getFileType = (filepatch, filecode) => {if (filepatch) {const ext = filepatch.split('.').pop().toLowerCase();return fileTypeMap[ext] || '目录';}// fallback 用 filecode 判断return filecode === 0 ? '目录' : '目录';};// 定义递归处理函数const processTree = (nodes) => {return nodes.map(item => ({...item,filetype: getFileType(item.filepatch, item.filecode),children: item.children ? processTree(item.children) : []}));};// 处理后的树结构赋值this.biddData = processTree(res.data);});}, 100); },
前端定义递归方法遍历每条数据的filepatch 然后利用
filepatch.split('.').pop().toLowerCase();
获取名称的拓展名判断是哪一类
之后调用fileTypeMap将对应的文件名称写进去
就可以展示了
我这里是树形结构所以调用了processTree