MySQL 索引:聚集索引与二级索引
在数据库性能优化的征途中,索引无疑扮演着至关重要的角色。正确理解和使用索引,能够显著提升查询效率,为应用带来丝滑般的操作体验。今天,我们将深入 MySQL 的心脏,重点探讨 InnoDB 存储引擎中两种核心的索引类型:聚集索引 (Clustered Index) 和 二级索引 (Secondary Index)。它们是如何工作的?又有哪些本质区别?让我们一探究竟!
前言:为何要关心索引类型?
当我们谈论数据库查询速度时,索引是绕不开的话题。但并非所有索引都生而平等。MySQL 的 InnoDB 存储引擎对数据的组织方式与索引紧密相关,理解聚集索引和二级索引的机制,能帮助我们:
- 更精准地设计表结构和索引策略。
- 预测并优化特定查询的性能。
- 避免常见的索引误区,减少不必要的性能开销。
接下来,我们将从定义、底层原理、特点及差异等多个维度,为你揭开它们的神秘面纱。
什么是聚集索引 (Clustered Index)? 🔑
定义
聚集索引,简而言之,是一种数据的物理存储顺序与索引的键值逻辑顺序完全一致的索引。在 MySQL 的 InnoDB 存储引擎中,每张表都有且只有一个聚集索引,它通常就是表的主键。
为了更深入地理解这一点,我们可以这样想象:InnoDB 会依据表的主键(或按规则选定的键)来构建一个 B+ 树。这棵 B+ 树的特殊之处在于,其叶子节点的排列顺序,直接决定了对应数据行在磁盘上的物理存放次序。换句话说,数据表本身就是这棵 B+ 树的叶子节点层级——按键值顺序排列的叶子节点,直接承载着一行行的完整数据。因此,当数据按照聚集索引的键值插入时,它们会被安置到磁盘上“正确”的物理位置,以维护这种有序性。
底层原理
- 数据与索引一体化 (Table-as-Index):这是聚集索引最核心、最本质的特征。正是因为上述B+树叶子节点直接决定物理存储的机制,在 InnoDB 中,表数据本身就是以聚集索引的 B+ 树结构进行物理组织的。B+ 树的叶子节点直接包含了完整的行数据,而非像其他某些索引类型那样仅仅存储指向数据行的指针。
- B+ 树结构细节:InnoDB 使用 B+ 树作为聚集索引的数据结构。
- 非叶子节点:存储索引键值以及指向下一层数据页(子节点)的指针。
- 叶子节点:按照索引键(通常是主键)的逻辑顺序排列,并且每个叶子节点存储了对应键值的完整数据行(包含了表中的所有列)。这些叶子节点之间通过双向链表连接,以便于高效的范围扫描。
- 主键的中心地位(聚集索引键的选择):
- 如果表定义了主键 (PRIMARY KEY),那么主键列自动成为聚集索引的键。这是最常见且推荐的方式。
- 如果没有显式定义主键,InnoDB 会选择表中的第一个唯一非空索引 (UNIQUE NOT NULL) 作为聚集索引。
- 如果以上两者都没有,InnoDB 会在内部自动生成一个隐藏的、6字节长的自增列(通常称为
ROW_ID或GEN_CLUST_INDEX)作为聚集索引的键。
- 物理存储的唯一性:由于数据行的物理存储顺序是由聚集索引唯一决定的,因此一张表只能拥有一个聚集索引。数据的整体物理排列方式只有一种。
特点
- 查询效率高(尤其是主键查找):当通过聚集索引键(通常是主键)查找数据时,B+ 树会引导查询直达包含完整行数据的叶子节点。一旦定位到叶子节点,就意味着找到了所需数据,无需额外的磁盘 I/O 来读取数据行(这个过程在其他索引中可能需要,常被称为“回表”)。
- 范围查询高效:由于数据在物理上是按照聚集索引键的顺序连续存储在磁盘页上的(至少是逻辑上的连续,通过叶子节点的双向链表保证),对于范围查询(例如
WHERE id BETWEEN 100 AND 200),数据库可以高效地顺序读取相关数据页,减少了随机 I/O。 - 插入/更新成本可能较高:为了维护数据的物理有序性,当插入新数据或更新聚集索引键值时:
- 如果插入的数据不在当前数据页的“正确”位置,可能需要移动已有的数据来腾出空间。
- 如果当前数据页已满,则需要进行页分裂操作(将一部分数据移到新的数据页),这会带来额外的 I/O 和 B+ 树结构的调整。
- 对于非顺序插入(例如使用UUID作为主键),这种开销会更加明显。
什么是二级索引 (Secondary Index)? 🔗
定义
二级索引,也被称为非聚集索引 (Non-Clustered Index) 或辅助索引 (Auxiliary Index)。它是一种独立于聚集索引的索引结构。与聚集索引不同,二级索引的叶子节点并不存储完整的行数据。
底层原理
- 独立的 B+ 树:每个二级索引都有其自己独立的 B+ 树结构。
- 叶子节点存储内容:二级索引 B+ 树的叶子节点存储的是该索引列的值以及对应的主键值(即聚集索引的键值)。它不包含完整的行数据。
- 回表 (Book-Lookup/Covering Index Lookups):当使用二级索引进行查询时,MySQL 的标准流程是:
- 首先在二级索引的 B+ 树中查找,根据索引列的值定位到叶子节点,获取到对应行的主键值。
- 然后,再利用这个主键值去聚集索引的 B+ 树中查找,最终定位到完整的行数据。这个通过主键再次查找完整数据的过程,就称为“回表”。
- 覆盖索引 (Covering Index) 优化:存在一种优化情况。如果查询所需要的所有列恰好都包含在二级索引中(即索引列本身或加上主键列),那么 MySQL 就可以直接从二级索引的叶子节点获取所有需要的数据,无需再进行回表操作。这种情况称为覆盖索引,它能显著提高查询效率。
特点
- 灵活性高:一张表可以创建多个二级索引,以满足不同查询场景的需求,针对不同的列组合进行优化。
- 存在存储开销:每个二级索引都需要额外的磁盘空间来存储其 B+ 树结构。
- 查询效率(一般情况):相比直接通过聚集索引查询,通过二级索引查询通常需要两次 B+ 树查找(一次二级索引查找,一次回表到聚集索引查找),因此在需要回表的情况下,效率会略低于聚集索引。但如果能命中覆盖索引,则效率很高。
- 维护成本:当对表中的数据进行插入、更新或删除操作时,不仅聚集索引可能需要调整,所有相关的二级索引也必须同步更新,这会增加写操作的维护成本。
聚集索引 vs. 二级索引:核心区别一览 🆚
为了更直观地理解两者的差异,我们通过一个表格来进行对比:
| 特性 | 聚集索引 (Clustered Index) | 二级索引 (Secondary Index) |
| 定义 | 数据物理存储顺序与索引键一致 | 独立于数据物理存储,索引键与主键值关联 |
| 数据存储 | 叶子节点存储完整行数据 | 叶子节点存储索引列值 + 主键值 |
| 数量限制 | 一张表只能有一个 | 一张表可以有多个 |
| 查询过程 | 直接定位到数据,通常无需回表 | 先定位主键值,通常需要回表(除非是覆盖索引) |
| 查询效率 | 基于主键的查询和范围查询极快 | 取决于是否回表;覆盖索引时快,否则相对慢 |
| 存储开销 | 索引本身就是数据,不额外占用太多(相对数据而言) | 需要额外存储空间来维护独立的 B+ 树 |
| 写操作成本 | 插入/更新可能导致页分裂/合并,成本可能较高 | 插入/更新/删除时,需要同步更新所有相关二级索引,有成本 |
| 主要作用 | 定义数据主要存储方式,主键查找 | 优化非主键列的查询,提供多种查询路径 |
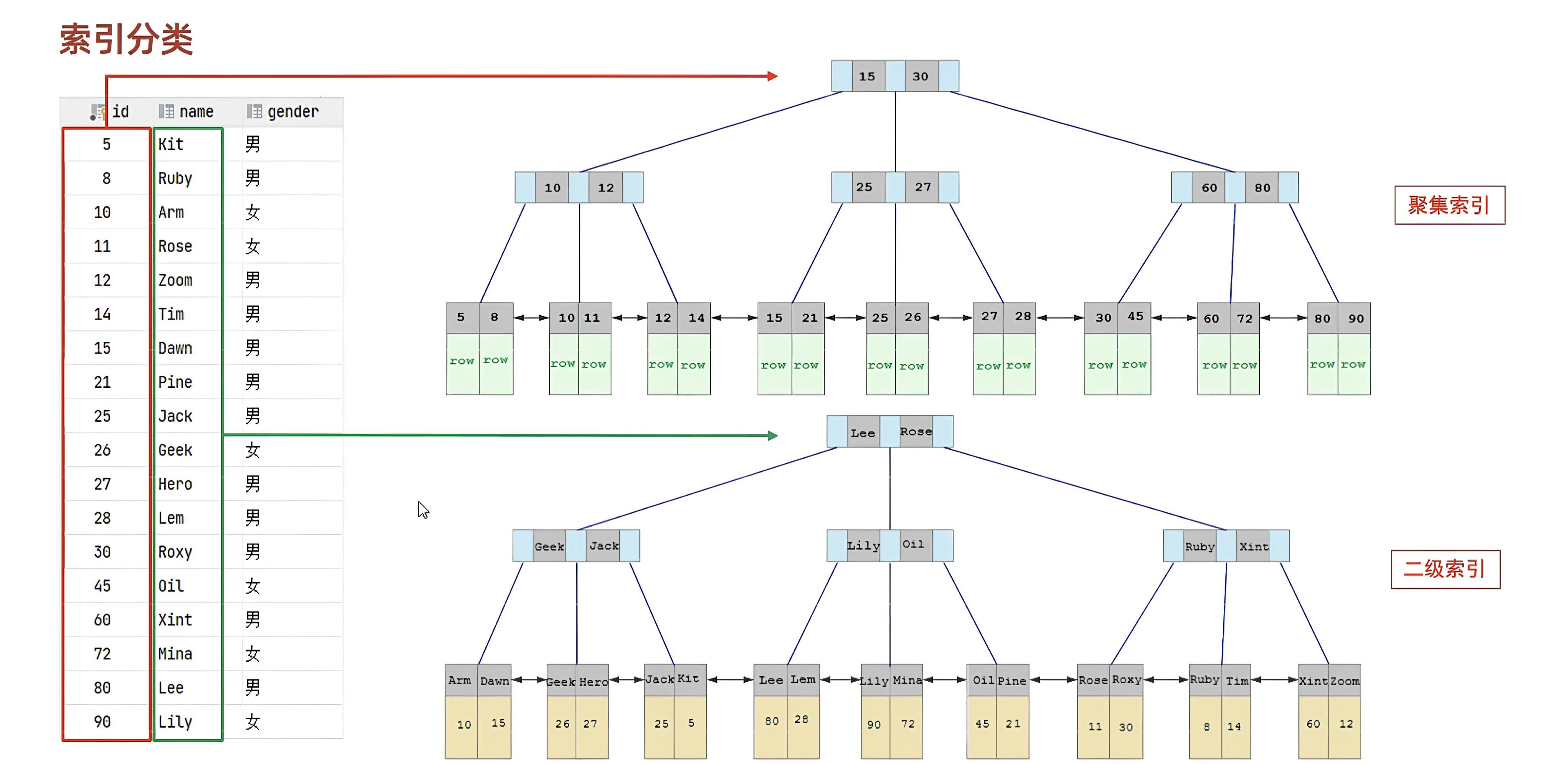
深入底层:B+ 树与索引的工作机制剖析 🌳
理解了定义和特点,我们再稍微深入一点,看看它们在 B+ 树中是如何具体实现的。
聚集索引的 B+ 树
- 结构:
- 非叶子节点:存储
<主键值, 指向下一层节点的指针>。 - 叶子节点:存储
<主键值, 完整的行数据 (所有列)>。叶子节点之间通过双向链表连接,便于范围查询。
- 非叶子节点:存储
- 查找过程 (例如
SELECT * FROM users WHERE id = 100;):- 从 B+ 树的根节点开始。
- 比较
id = 100与非叶子节点中的主键值,决定走向哪个子节点。 - 逐层向下,直到达到叶子节点。
- 叶子节点直接包含了
id = 100的那一行完整数据。
二级索引的 B+ 树
- 结构:
- 非叶子节点:存储
<索引列值, 指向下一层节点的指针>。 - 叶子节点:存储
<索引列值, 对应行的主键值>。叶子节点也按索引列值排序,并通过双向链表连接。
- 非叶子节点:存储
- 查找过程 (例如
SELECT * FROM users WHERE name = 'Alice';,假设id是主键,name上有二级索引):- 第一步:查找二级索引
idx_name- 从
idx_name的 B+ 树根节点开始。 - 比较
name = 'Alice'与非叶子节点中的name值,逐层向下。 - 到达叶子节点,找到
name = 'Alice'的条目,并从中获取对应的主键id值 (例如,假设id是 15)。
- 从
- 第二步:回表查找聚集索引
- 使用上一步获取到的主键
id = 15。 - 在聚集索引(主键索引)的 B+ 树中进行查找(同聚集索引查找过程)。
- 定位到
id = 15的叶子节点,获取完整的行数据。
- 使用上一步获取到的主键
- 第一步:查找二级索引
- 覆盖索引的情况 (例如
SELECT id, name FROM users WHERE name = 'Alice';):- 同样先查找二级索引
idx_name,获取到name = 'Alice'和对应的主键id。 - 由于查询所需的列 (
id,name) 都在idx_name的叶子节点中(name是索引列,id是叶子节点存储的主键值),MySQL 直接从二级索引返回数据,无需回表。
- 同样先查找二级索引
回表示例代码
假设我们有这样一个用户表:
CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY, -- id 是主键,因此是聚集索引name VARCHAR(50),age INT,email VARCHAR(100),INDEX idx_name (name) -- name 列上创建一个二级索引
);
- 查询 1:
SELECT * FROM users WHERE id = 10;- 直接在聚集索引(基于
id的 B+ 树)中查找,一步到位。
- 直接在聚集索引(基于
- 查询 2:
SELECT * FROM users WHERE name = 'Bob';- 在二级索引
idx_name中查找name = 'Bob',得到Bob对应行的id值(比如是 25)。 - 使用
id = 25,在聚集索引中查找,获取id=25的完整行数据。(发生回表)
- 在二级索引
- 查询 3:
SELECT id, name FROM users WHERE name = 'Charlie';- 在二级索引
idx_name中查找name = 'Charlie',得到Charlie对应行的id值。 - 由于查询的列
id和name都可以从idx_name的叶子节点直接获取(name是索引列,id是存储的主键),所以直接返回结果。(覆盖索引,无回表)
- 在二级索引
实践应用与优化建议 💡
了解了理论,我们来看看在实际工作中如何应用这些知识:
-
明智选择聚集索引(主键):
- 强烈推荐使用单调递增的列作为主键(如自增
INT或BIGINT)。这有助于减少数据插入时的页分裂,保持数据写入性能。 - 避免使用无序的、宽的(占用字节多,如长字符串 UUID)列作为主键,它们会导致频繁的页分裂、数据移动,增加 B+ 树维护成本,并使得二级索引也变得更大(因为二级索引叶子节点存储主键)。
- 强烈推荐使用单调递增的列作为主键(如自增
-
善用二级索引与覆盖索引:
- 为经常作为查询条件 (
WHERE子句)、排序条件 (ORDER BY子句) 或分组条件 (GROUP BY子句) 的列创建二级索引。 - 尽量设计覆盖索引来满足查询需求,以避免回表。这意味着 SELECT 列表中的列、WHERE 条件中的列,最好都包含在同一个二级索引中。
- 不要滥用索引:过多的二级索引会占用更多磁盘空间,并显著增加插入、更新、删除操作的维护成本。只创建真正需要的、能带来性能提升的索引。
- 为经常作为查询条件 (
-
理解写操作的代价:
- 对聚集索引的修改(尤其是键值的修改)通常比二级索引的修改代价更高,因为它涉及数据的物理移动。
- 任何写操作都可能需要更新聚集索引和相关的多个二级索引。
-
区分 InnoDB 和 MyISAM (虽然现在 InnoDB 是主流):
- 本文主要基于 InnoDB,它是 MySQL 默认且最常用的事务性存储引擎,强制要求并依赖聚集索引。
- 传统的 MyISAM 存储引擎则只支持非聚集索引。在 MyISAM 中,索引文件(
.MYI)和数据文件(.MYD)是分开的,其主键索引和二级索引在结构上类似,叶子节点都存储指向数据文件中实际数据行的指针(地址)。
总结:索引是双刃剑,善用方能致胜 ⚔️
总而言之:
- 聚集索引是 InnoDB 表数据的组织核心,它决定了数据行的物理存储顺序。叶子节点存储完整的行数据,因此基于主键的查找和范围扫描非常高效。每张表只有一个聚集索引。
- 二级索引是为优化特定查询而创建的辅助结构。它的叶子节点存储索引列值和对应行的主键值。通过二级索引查询数据通常需要“回表”到聚集索引,除非能命中“覆盖索引”。一张表可以有多个二级索引。
理解聚集索引和二级索引的底层机制及其差异,对于数据库设计和 SQL 性能优化至关重要。希望这篇博文能帮助你更清晰地认识它们,并在实践中做出更优的选择。