【推荐算法】WideDeep推荐模型:融合记忆与泛化的智能推荐引擎
Wide&Deep推荐模型:融合记忆与泛化的智能推荐引擎
- 一、算法背景:推荐系统的核心矛盾
- 二、算法理论/结构:双路并行架构
- 1. Wide组件:记忆专家
- 2. Deep组件:泛化大师
- 3. 联合训练(Joint Training)
- 三、模型评估:线上线下的双重验证
- 四、应用案例:Google Play的成功实践
- 五、面试题与论文资源
- 常见面试题:
- 关键论文:
- 六、详细优缺点分析
- 七、相关算法演进:从Wide&Deep到下一代
- 总结:记忆与泛化的哲学统一
本文系统性地剖析Wide&Deep模型如何通过独特的双路架构实现“记忆性”(Memorization)与“泛化性”(Generalization)的完美融合,使其成为推荐系统领域的里程碑式工作。
一、算法背景:推荐系统的核心矛盾
记忆性(Memorization) 指模型直接学习历史数据中高频、共现的特征组合的能力(如“用户A购买过手机壳”与“用户A点击手机贴膜”的强关联)。
泛化性(Generalization) 指模型基于特征嵌入(Embedding)发现未见过的特征组合的潜在规律(如“喜欢科技产品的用户可能对智能手表感兴趣”)。
传统模型存在明显局限:
- 线性模型(如LR):依赖人工特征交叉(如
AND(user_type=VIP, item_category=luxury)),记忆性强但泛化弱。 - 深度模型(如DNN):通过嵌入自动学习特征交互,泛化性好但可能过度泛化,对长尾特征组合预测不准。
💡 核心问题:如何让模型既能精准捕捉历史规则,又能探索潜在的新模式?
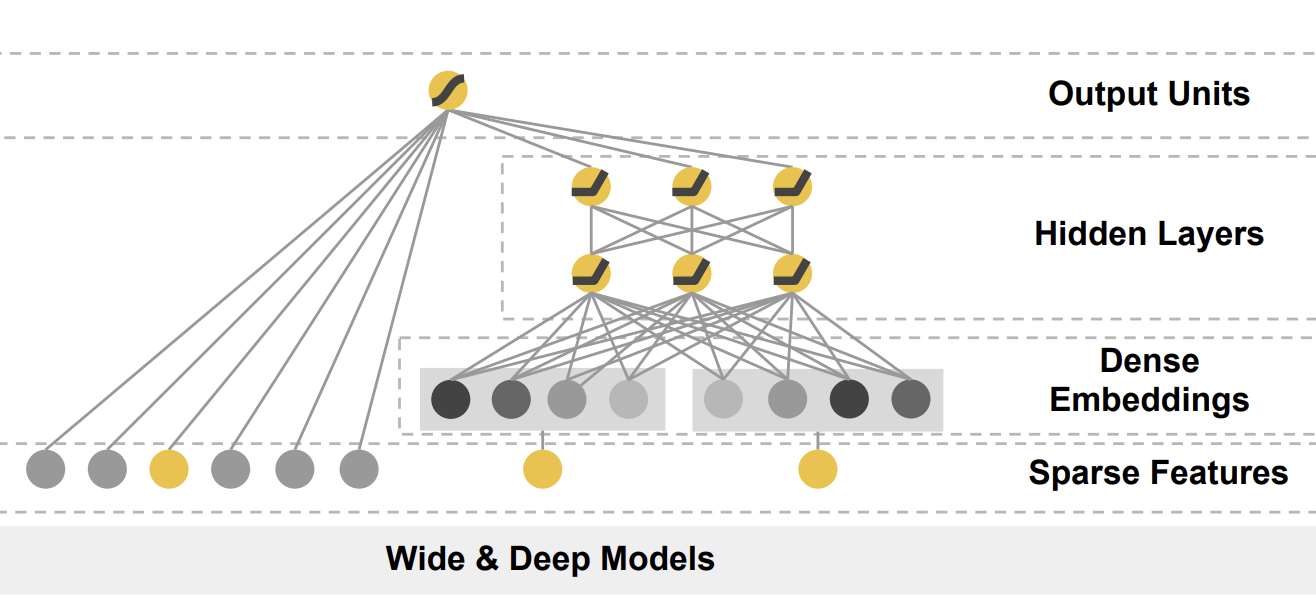
二、算法理论/结构:双路并行架构
Wide&Deep创新性地将线性模型(Wide)与深度神经网络(Deep)联合训练(Joint Training),公式化表示为:
y ^ = σ ( w wide T [ x , ϕ ( x ) ] + w deep T α ( l ) + b ) \hat{y} = \sigma \left( \mathbf{w}_{\text{wide}}^T [\mathbf{x}, \phi(\mathbf{x})] + \mathbf{w}_{\text{deep}}^T \alpha^{(l)} + b \right) y^=σ(wwideT[x,ϕ(x)]+wdeepTα(l)+b)
其中:
- y ^ \hat{y} y^:最终预测概率(如点击率)
- σ \sigma σ:Sigmoid激活函数
- [ x , ϕ ( x ) ] [\mathbf{x}, \phi(\mathbf{x})] [x,ϕ(x)]:原始特征 + 人工交叉特征(Wide侧输入)
- α ( l ) \alpha^{(l)} α(l):Deep侧最后一层激活值
1. Wide组件:记忆专家
- 结构:广义线性模型 y = w T x + b y = \mathbf{w}^T\mathbf{x} + b y=wTx+b
- 输入:原始特征 + 人工设计的交叉特征(如
user_installed_app & impression_app) - 作用:精确记忆历史数据中的强特征规则,保证高置信度预测的准确性。
2. Deep组件:泛化大师
- 结构:多层全连接神经网络
α ( 0 ) = Embedding ( x ) \alpha^{(0)} = \text{Embedding}(\mathbf{x}) α(0)=Embedding(x)
α ( k ) = ReLU ( W ( k ) α ( k − 1 ) + b ( k ) ) \alpha^{(k)} = \text{ReLU}(\mathbf{W}^{(k)} \alpha^{(k-1)} + \mathbf{b}^{(k)}) α(k)=ReLU(W(k)α(k−1)+b(k)) - 输入:类别特征通过Embedding转为稠密向量,数值特征直接输入
- 作用:自动学习特征间的隐含关系,泛化到未见过的特征组合。
graph LRA[原始特征] --> B(Wide部分)A --> C(Embedding层)C --> D[Deep部分:多层DNN]B --> E[联合输出层]D --> EE --> F[预测概率]
3. 联合训练(Joint Training)
- Wide和Deep组件共享损失函数(交叉熵):
L = − 1 N ∑ i ( y i log y i ^ + ( 1 − y i ) log ( 1 − y i ^ ) ) L = -\frac{1}{N} \sum_{i} \left( y_i \log \hat{y_i} + (1-y_i) \log(1-\hat{y_i}) \right) L=−N1i∑(yilogyi^+(1−yi)log(1−yi^)) - 同步更新参数,避免集成学习中两阶段训练的误差累积。
三、模型评估:线上线下的双重验证
-
离线评估(AUC/LogLoss)
在Google Play的实验中:- Wide&Deep相比纯Wide(LR)AUC提升3.9%
- 相比纯Deep模型,在头部商品预测更稳定。
-
在线A/B测试
- 关键指标:App下载率(+3.9%),显著优于单一模型。
- 验证了模型在处理稀疏特征组合上的优势(如冷门App推荐)。
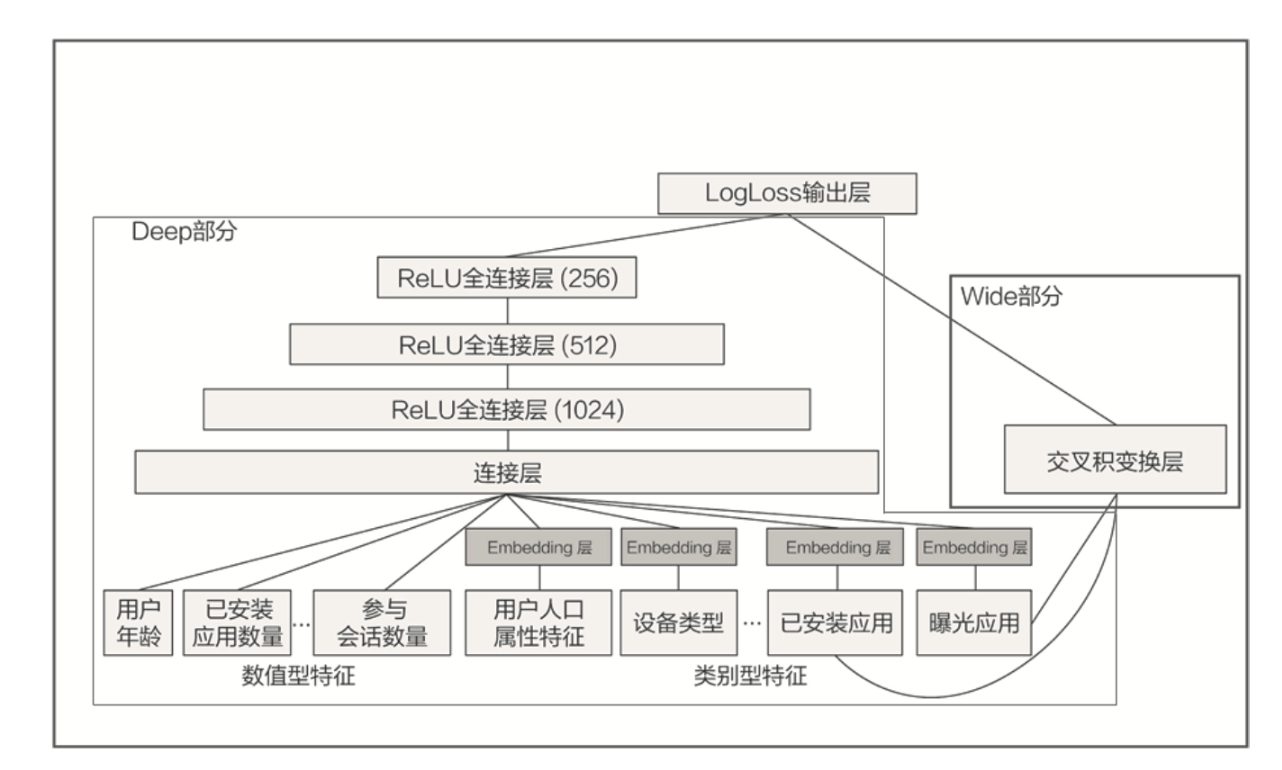
四、应用案例:Google Play的成功实践
- 场景:应用商店的App推荐。
- 特征工程:
- Wide侧输入:用户已安装应用 × 曝光应用的交叉特征。
- Deep侧输入:应用ID、用户画像的嵌入向量。
- 结果:线上服务延迟仅31ms,支持每秒超1000万次推荐请求。
✅ 核心价值:既精准推荐用户常点类别(记忆性),又探索新兴趣方向(泛化性)。
五、面试题与论文资源
常见面试题:
- Wide部分为什么需要人工交叉特征?Deep部分能否替代?
答:Wide依赖交叉特征实现精准记忆;Deep通过嵌入泛化,但难以完全复现特定组合规则。 - 联合训练与集成学习(Ensemble)的区别?
答:联合训练共享损失函数,端到端优化;集成独立训练各模型后融合结果。 - 如何解决Wide部分特征维度爆炸?
答:使用FTRL(Follow-the-Regularized-Leader)优化器,支持大规模稀疏特征。
关键论文:
- 原论文:Wide & Deep Learning for Recommender Systems
- 扩展阅读:DeepFM:结合FM与Deep架构
六、详细优缺点分析
| 优势 | 挑战 |
|---|---|
| ✅ 记忆性:高置信度规则精准预测 | ❌ Wide依赖人工特征工程 |
| ✅ 泛化性:挖掘潜在特征关联 | ❌ 双路结构增加计算复杂度 |
| ✅ 联合训练:端到端优化参数 | ❌ Embedding维度需调参 |
| ✅ 线上服务高效(Google实际验证) | ❌ 特征重要性解释性弱于纯线性模型 |
七、相关算法演进:从Wide&Deep到下一代
-
DeepFM(2017)
用FM(Factorization Machines)替代Wide部分,自动学习特征交叉,解决人工设计瓶颈。
y ^ = σ ( y FM + y DNN ) \hat{y} = \sigma(y_{\text{FM}} + y_{\text{DNN}}) y^=σ(yFM+yDNN) -
xDeepFM(2018)
引入显式向量级特征交互(Compressed Interaction Network),增强高阶特征组合能力。 -
DCN(Deep & Cross Network)
设计交叉网络(Cross Network),显式构造高阶特征:
x l + 1 = x 0 x l T w l + x l + b l \mathbf{x}_{l+1} = \mathbf{x}_0 \mathbf{x}_l^T \mathbf{w}_l + \mathbf{x}_l + \mathbf{b}_l xl+1=x0xlTwl+xl+bl
总结:记忆与泛化的哲学统一
Wide&Deep的精髓在于用辩证思维解决推荐系统的根本矛盾:
- Wide如历史学家:忠实记录“已知规律”(记忆性)
- Deep如探险家:勇敢探索“未知关联”(泛化性)
🌟 技术启示:在AI模型设计中,融合简单模型的鲁棒性与复杂模型的表达能力,往往比追求单一结构的极致更有效。这一思想在后续的DeepFM、DCN等模型中持续演进,成为推荐系统的主流范式。