[测试_10] Selenium IDE | cssSelector | XPath | 操作测试
目录
1、Selenium IDE
2、Selenium 原理
3、WebDriver
(1)Webdriver 的工作原理
4、Selenium Grid
一、WebDriver API
1、元素的定位
(1)cssSelector(常用)
A. id 定位
(2)name 定位
(3)tag name 定位和 class name 定位
(4)XPath 定位(重点)(常用)
A. 什么是 XPath
B. XPath 基础教程
既然可以手动复制 selector/xpath 的方式,为什么还有了解语法?
css 选择器和 xpath 选择器哪个更好?
(5)link text 定位
(6)Partial link text 定位
二、操作测试对象
1、click 点击 / 提交对象
2、sendKeys 模拟按键输入
3、clear 清除文本内容
4、submit 提交表单
5、text 获取元素文本
如何判断获取到的元素对应的文本是否符合预期呢?
6、title 获取当前页面标题 & current_url 获取当前页面 URL
1、Selenium IDE
Selenium IDE 一个用于 Selenium 测试的完成集成开发环境,可以直接录制在浏览器的用户操作,并且能回放,编辑和调试测试脚本。
- 调试过程中可以逐步进行或调整执行的速度,并且可以在底部浏览日志出错信息。
- 录制的测试脚本可以以多种语言导出,比如 Java、Python、C#、JavaScript、Ruby 等(丰富的 API),方便掌握不同语言的测试人员操作。
2、Selenium 原理
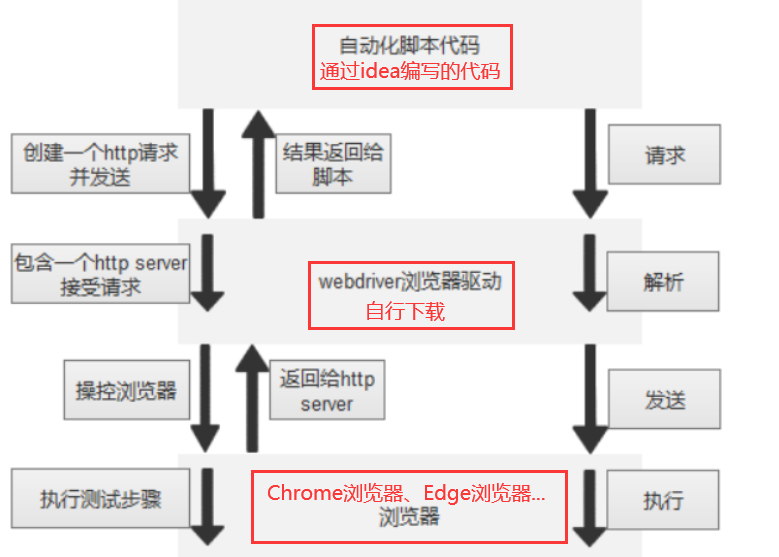
- 通过 selenium 编写的自动化脚本代码中在 ChromeDriverService 中创建⼀个服务。
- 通过创建好的服务打开 webdriver,安装在本地的驱动服务 IP 为 localhost,PORT 为 ChromeDriverService 中创建的端口号,该服务地址为 selenium 向 webdriver 发送请求的服务地址。
- 向浏览器驱动程序发送 HTTP 请求,浏览器驱动程序解析请求,打开浏览器,并获得 sessionid,如果再次对浏览器操作需携带此 id。
- 打开浏览器后,所有的 selenium 的操作(访问地址,查找元素等)均通过创建好的服务链接到 webdriver,然后使用 execute 发送请求
- 驱动收到请求并对请求进行解析,转成浏览器能够解析的脚本并发送给浏览器,浏览器通过请求的内容执行对应动作。
- 浏览器再把执行的动作结果通过浏览器驱动程序返回给测试脚本。
驱动需要接收、解析请求,发送请求给浏览器,那么驱动到底是什么样的角色呢?
验证方式:执行 selenium 编写的自动化脚本代码中,可以在终端看到创建的驱动服务地址。
3、WebDriver
- Selenium RC 在浏览器中运行 JavaScript 应用,会存在环境沙箱问题,而 WebDriver 可以跳出 JavaScript 的沙箱,针对不同的浏览器创建更健壮的,分布式的,跨平台的自动化测试脚本。
- 基于特定语言(Java,C#,Python,Ruby,Perl,JavaScript 等)绑定来驱动浏览器对Web元素进行操作和验证。
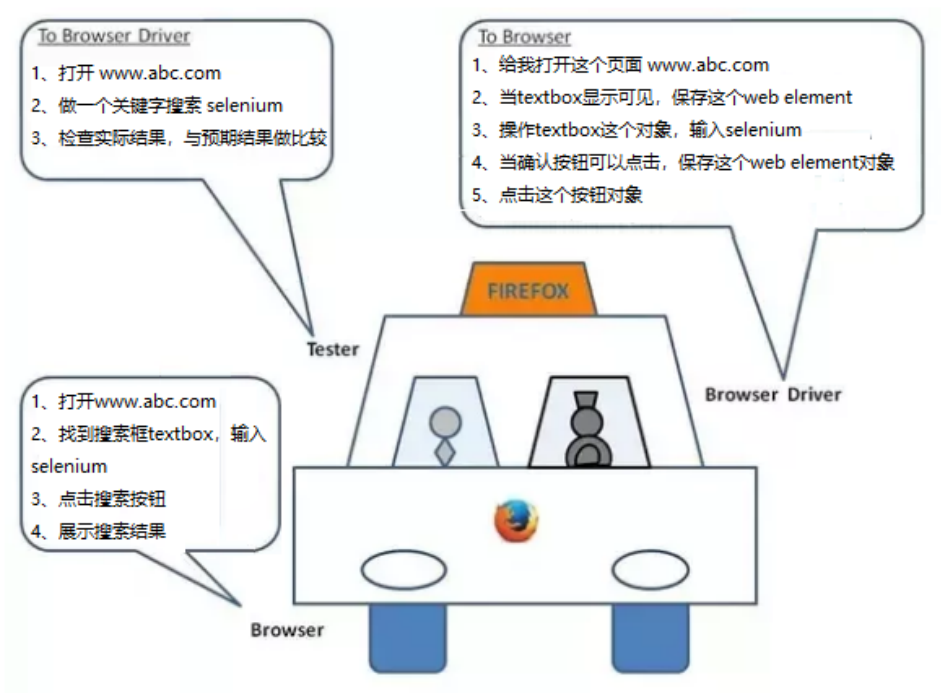
(1)Webdriver 的工作原理
启动浏览器后,Selenium-webdriver 会将目标浏览器绑定到特定的端口,启动后的浏览器则作为 webdriver 的 remote server。
- 客户端(也就是测试脚本),借助 ComandExecutor 发送 HTTP 请求给 Sever 端(通信协议:The WebDriver Wire Protocol,在 HTTP request 的 body 中,会以 WebDriver Wire 协议规定的 JSON 格式的字符串来告诉 Selenium,我们希望浏览器接下来做什么事情)。
- Sever 端需要依赖原生的浏览器组件,转化 Web Service 的命令为浏览器 native 的调用来完成操作。
4、Selenium Grid
- Selenium Grid 是一个服务器,提供对浏览器实例访问的服务器列表,管理各个节点的注册和状态信息。可以实现在同一时刻不同服务器上执行不同的测试脚本。
一、WebDriver API
一个简单自动化脚本的构成:
脚本解析
# coding = utf-8
from selenium import webdriver
import time
browser = webdriver.Firefox()
time.sleep(3)
browser.get("http://www.baidu.com")
time.sleep(3)
browser.find_element_by_id("kw").send_keys("selenium")
time.sleep(3)
browser.find_element_by_id("su").click()
browser.quit()防止乱码,在编辑器里面可以不用加,因为编辑器默认的就是 UTF-8 模式。
- coding = utf-8
导入 webdriver 工具包,这样就可以使用里面的 API
- from selenium import webdriver
获得被控制浏览器的驱动,这里是获得 Firefox 的,当然还可以获得 Chrome 浏览器,不过要想使这一段代码有效,必须安装相应的浏览器驱动。
- browser = webdriver.Firefox()
通过元素的 ID 定位想要操作的元素,并且向元素输入相应的文本内容 。
- browser.find_element_by_id("kw").send_keys("selenium")
通过元素的 ID 定位到元素,并进行点击操作。
- browser.find_element_by_id("su").click()
退出并关闭窗口。
- browser.quit()
browser.close() 也可以关闭窗口。
两者的区别是:
- close 方法关闭当前的浏览器窗口
- quit 方法不仅关闭窗口,还会彻底的退出 WebDriver,释放与 driver server 之间的连接。
所以简单来说 quit 是更加彻底的 close,quit 会更好的释放资源。
1、元素的定位
对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。
- 一个对象就是一个人一样,他会有各种的特征(属性),比如我们可以通过一个人的身份证号,姓名,或者他住在哪个街道、楼层、门牌找到这个人。
- 那么一个对象也有类似的属性,我们可以通过这些属性找到这对象。
注意:不管用那种方式,必须保证页面上该属性的唯一性。
web 自动化测试的操作核心是能够找到页面对应的元素,然后才能对元素进行具体的操作。
WebDriver 提供了一系列的对象定位方法,常用的有以下几种:
- id
- name
- class name
- link text
- partial link text
- tag name
- xpath
- css selector
我们可以看到,一个百度的输入框,可以用这么多种方式去定位。
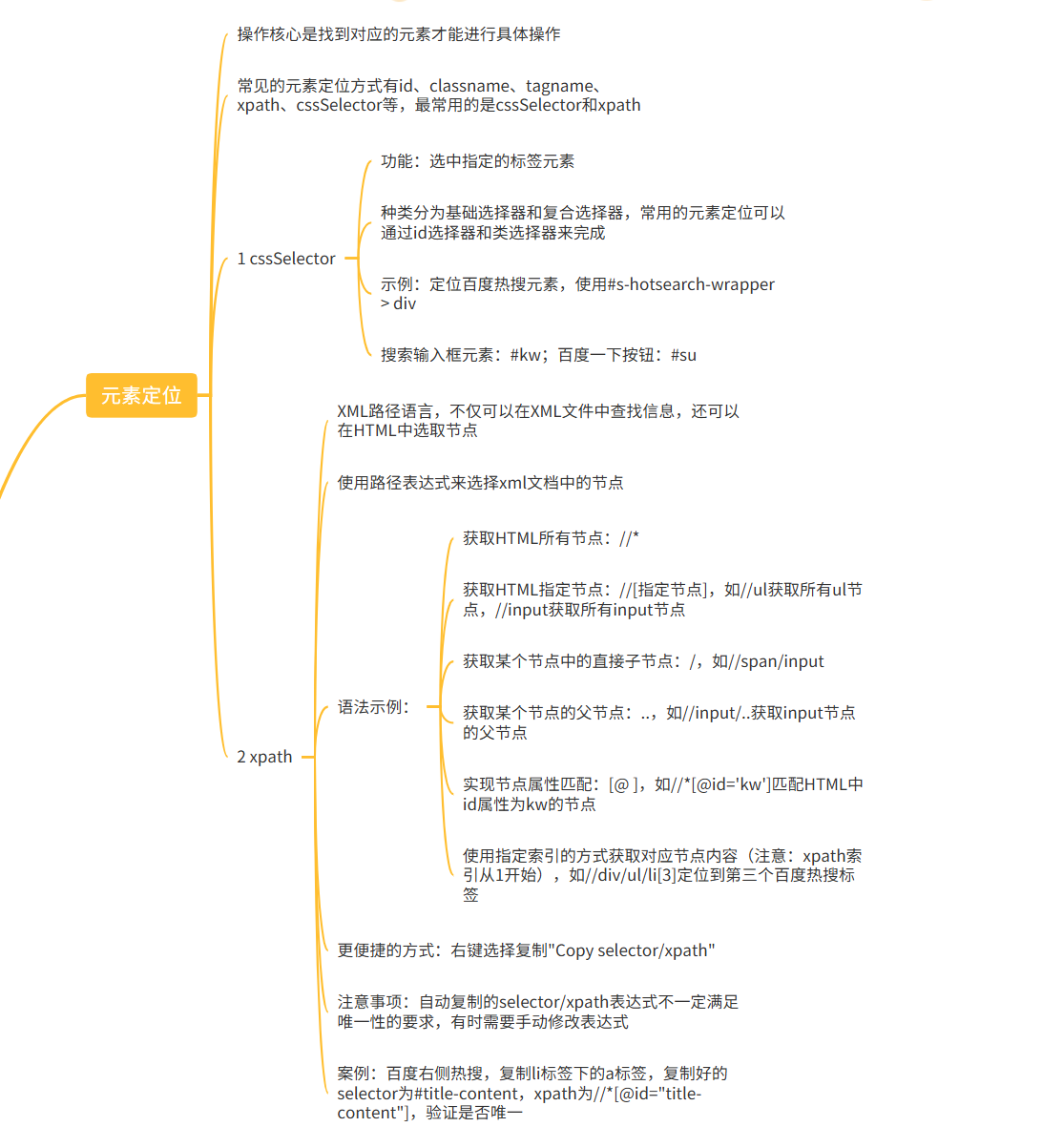
(1)cssSelector(常用)
CSS(Cascading Style Sheets)是一种语言,它被用来描述 HTML 和 XML 文档的表现。
- CSS 使用选择器来为页面元素绑定属性。这些选择器可以被 Selenium 用作另外的定位策略。
- CSS 的比较灵活可以选择控件的任意属性,上面的例子中,find_element_by_css_selector("#kw") 通过 find_element_by_css_selector( ) 函数,选择取百度输入框的 id 属性来定义。
- CSS 的获取可以用 Chrome 的 F12 开发者模式中 Element-右键-copy-copy selector 来获取。
css 选择语法:
- id 选择器:#id
- 类选择:class
- 标签选择:标签名
- 后代选择器:父级选择器、子级选择器
选择器的功能:选中页面中指定的标签元素。
选择器的种类分为基础选择器和复合选择器,常见的元素定位方式可以通过 id 选择器和子类选择器来进行定位。
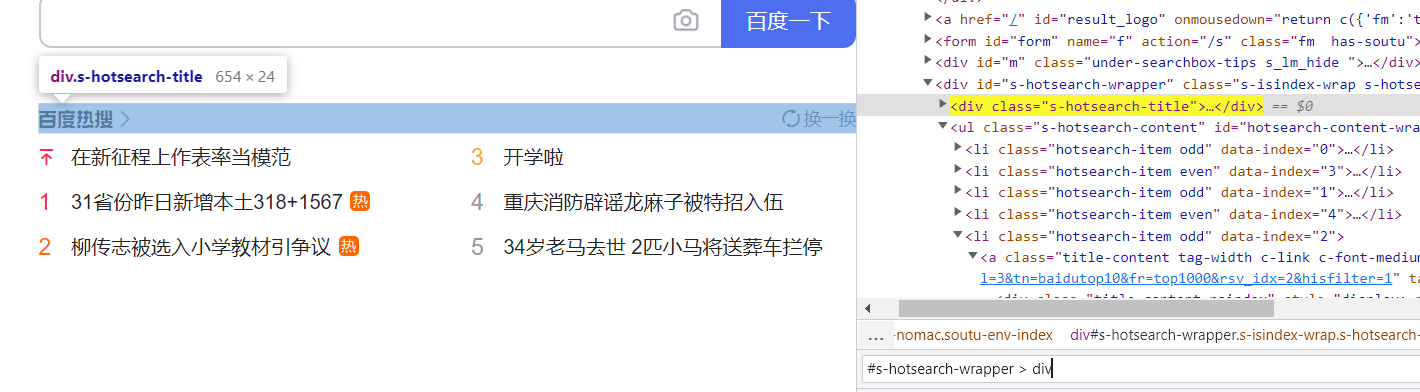
定位百度首页的 “百度热搜” 元素,可以使用通过 id 选择器和子类选择器进行定位:#s-hotsearch-wrapper > div
“搜索输入框元素”:#kw
“百度一下按钮”:#su
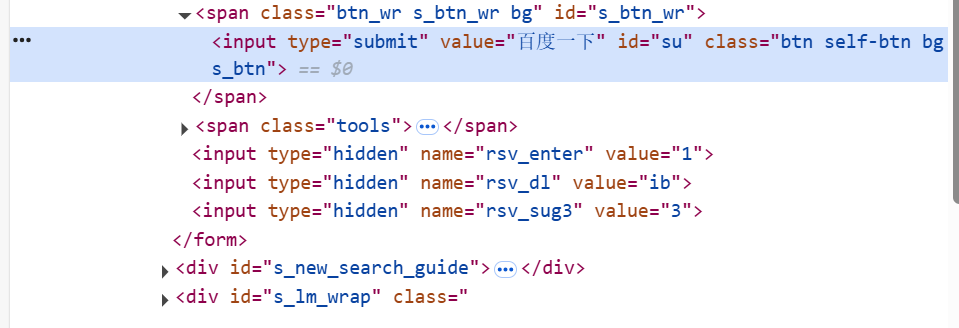

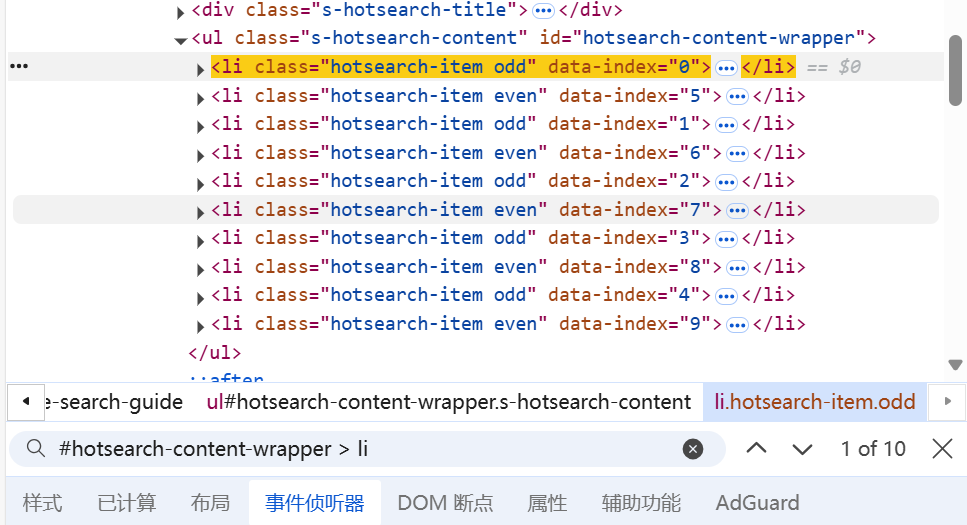
若要获取页面多个元素时,可以使用 find_elements:

获取成功:

注意:
因为自动化打开的页面是未登录状态
而我们手动打开的百度网页可能是有登录态的,二者页面可能不同,可能造成无法正确打印信息。
A. id 定位
id 是页面元素的属性,我们最常用元素定位方式,但是不是所有的元素都有 id 的。
- 如果一个元素有 id 属性,那么一般在整个页面是唯一的。
- 所以我们一般可以用 id 来唯一的定位到这个元素。
- 通过前端工具,例如 Edge 浏览器的 F12,找到了百度输入框的属性信息,如下:
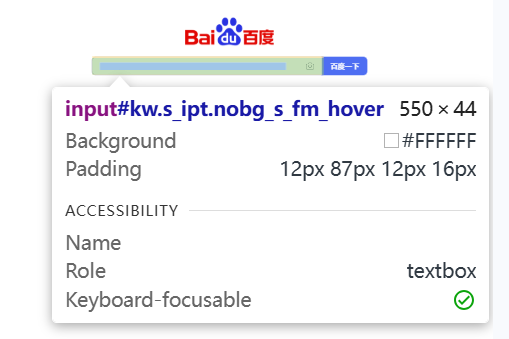
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">属性 id=”kw” 通过 find_element_by_id("kw") 函数就可以定位到百度输入框。
(2)name 定位
- 如果这个元素有 name,并且元素的 name 命名在整个页面是唯一的,那么我们可以用 name 来定位这个元素。
- 用上面百度输入框的例子,其中元素的属性 name=”wd” 通过 find_element_by_name("wd") 函数同样也可以定位到百度输入框。
(3)tag name 定位和 class name 定位
从上面的百度输入框的属性信息中,我们看到,不单单只有 id 和 name 两个属性, 比如 class 和 tag name(标签名)。
- input 就是一个标签的名字,可以通过 find_element_by_tag_name("input") 函数来定位
- class="s_ipt" 通过 find_element_by_class_name("s_ipt") 函数定位百度输入框。
注意 :不是所有的元素用 tag name 或者 class name 来定位元素,首先要保证该元素的这两种属性在页面上是唯一的,才能够准确的定位。
(4)XPath 定位(重点)(常用)
A. 什么是 XPath
Cover page | xpath | W3C standards and drafts | W3C
XML 路径语言,不仅可以在 XML 文件中查找信息,还可以在 HTML 中选取节点。
xpath 使用路径表达式来选择 xml 文档中的节点。

关于 xpath 可以结合 官网文档 来进行学习
B. XPath 基础教程
W3Schools Online Web Tutorials
相对路径:/html/head/title(不常用)
绝对路径:
- 相对路径+索引://form/span[1]/input
- 相对路径+属性值://input[@class="s_ipt"]
- 相对路径+通配符://*[@*="su"]
- 相对路径+文本匹配://a[text()="新闻"]
XPath 是一种在 XML 文档中定位元素的语言。因为 HTML 可以看做 XML 的一种实现,所以 Selenium 用户可是使用这种强大语言在 Web 应用中定位元素。
- XPath 扩展了上面 id 和 name 定位方式,提供了很多种可能性。
- XPATH 的获取可以用 Chrome 的 F12 开发者模式中 Element-右键-copy-copy xp。
//*[@id="kw"]
- 获取 HTML 页面所有的节点://*

获取 HTML 页面指定的节点://[指定节点]
- //ul:获取 HTML 页面所有的 ul 节点
- //input:获取 HTML 页面所有的 input 节点
获取⼀个节点中的直接子节点:/
- //span/input
获取⼀个节点的父节点:..
- //input/..:获取 input 节点的父节点
实现节点属性的匹配:[@...]

使用指定索引的方式获取对应的节点内容
注意:xpath 的索引是从 1 开始的。
- 百度首页通过://div/ul/li[3] 定位到第三个百度热搜标签
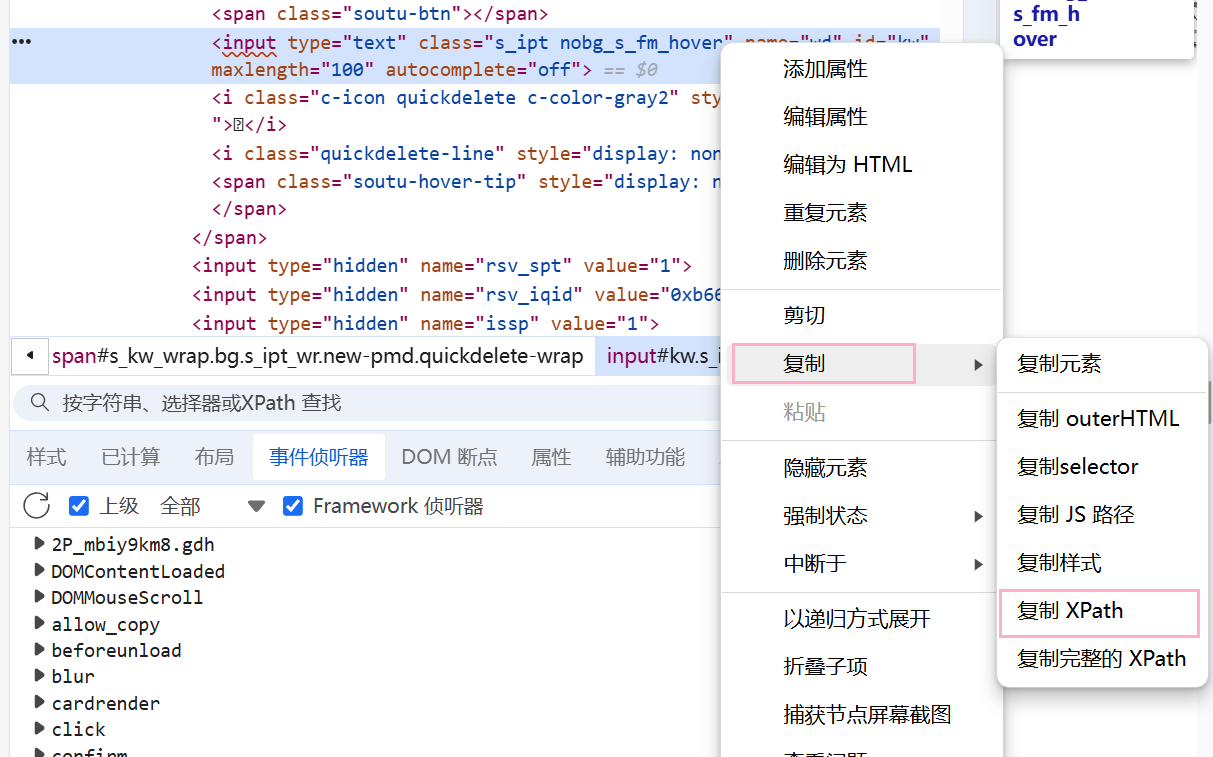
- 更便捷的生成 selector/xpath 的方式:右键选择复制 "Copy selector/xpath"
- 注意 :元素的定位方法必须唯⼀。
既然可以手动复制 selector/xpath 的方式,为什么还有了解语法?
- 手动复制的 selector / xpath 表达式并不一定可以满足上面的唯一性的要求
- 有时候也需要手动的进行修改表达式。
css 选择器和 xpath 选择器哪个更好?
- css 选择器定位元素效率更高。
(5)link text 定位
有时候不是一个输入框也不是一个按钮,而是一个文字链接,我们可以通过链接内容,也就是 link text 来定位。
注意:链接内容必须这个页面唯一,否则会报错。
(6)Partial link text 定位
通过部分链接定位,这个有时候也会用到,我还没有想到很好的用处。拿上面的例子,我可以只用链接的一部分文字进行匹配

二、操作测试对象
前面讲到了不少知识都是定位元素,定位只是第一步,定位之后需要对这个元素进行操作。是鼠标点击还是键盘输入,或者清除元素的内容,或者提交表单等。这个取决于定位元素需要进行的下一步操作。
Webdriver 中比较常用的操作对象的方法有下面几个:
- click 点击对象。
- send_keys 在对象上模拟按键输入。
- clear 清除对象输入的文本内容。
- submit 提交。
- text 用于获取元素的文本信息。
- get_attribute 获得属性值。
1、click 点击 / 提交对象
click() # 用于点击一个按钮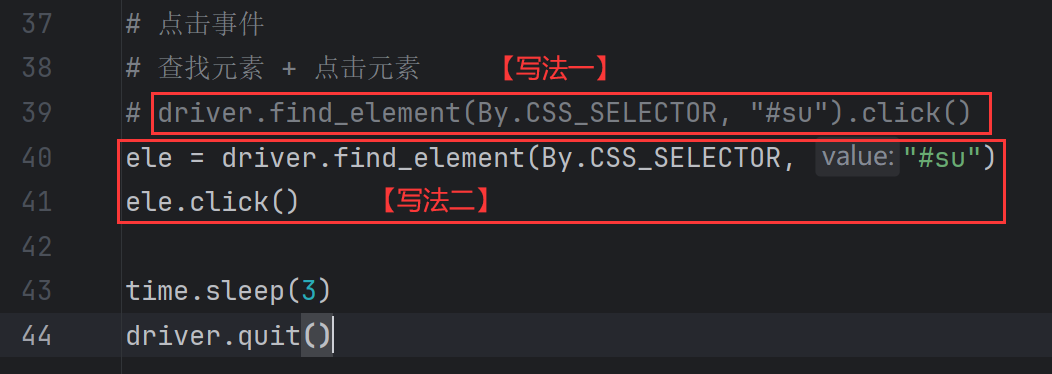
页面上任意元素都可以进行点击操作。

2、sendKeys 模拟按键输入
键盘上可以输入的内容都能填入。
sendKeys("")
# send_keys("xx") 用于在一个输入框里输入 xx 内容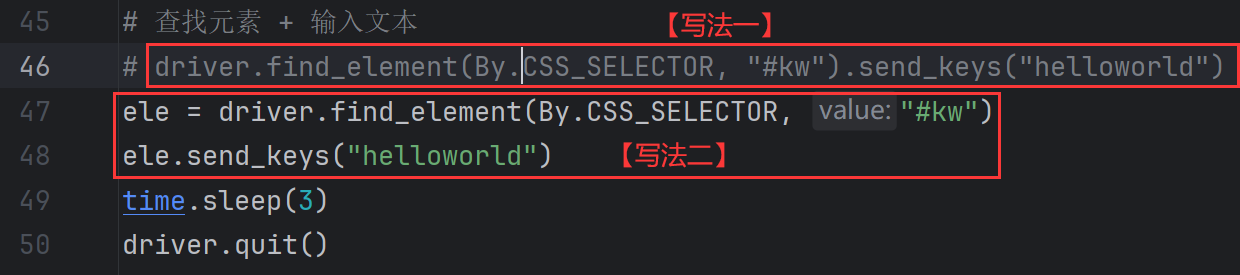
3、clear 清除文本内容
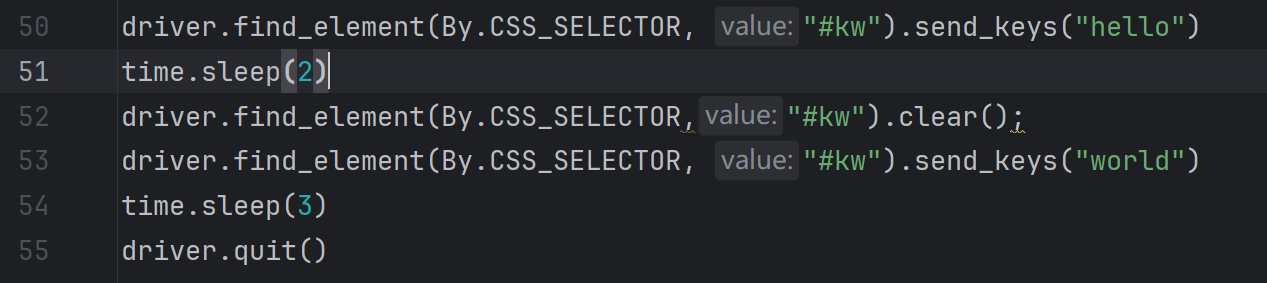
输入文本后又想换一个新的关键词,这里就需要用到 clear()。
- clear() 用于清除输入框的内容,比如百度输入框里默认有个 “请输入关键字” 的信息,再比如我们的登陆框一般默认会有 “账号”、“密码” 这样的默认信息。clear 可以帮助我们清除这些信息。
- 连续的 sendKeys 会将多次输入的内容拼接在一起,如果想要重新输入,需要使用清除方法:
4、submit 提交表单
打开百度搜索页面,按钮 “百度一下” 元素的类型 type=“submit”,所以把“百度一下”的操作从 click 换成 submit 可以达到相同的效果:
driver.find_element_by_id("su").submit()- 如果点击的元素放在 form 标签中,此时使用 submit 实现的效果和 click 是一样的。
- 如果点击的元素放在非 form 标签中,此时使用 submit 报错。
5、text 获取元素文本
如何判断获取到的元素对应的文本是否符合预期呢?
获取元素对应的⽂本并打印⼀下。
getText()“百度一下” 在这里是作为元素属性值,而不是文本信息。
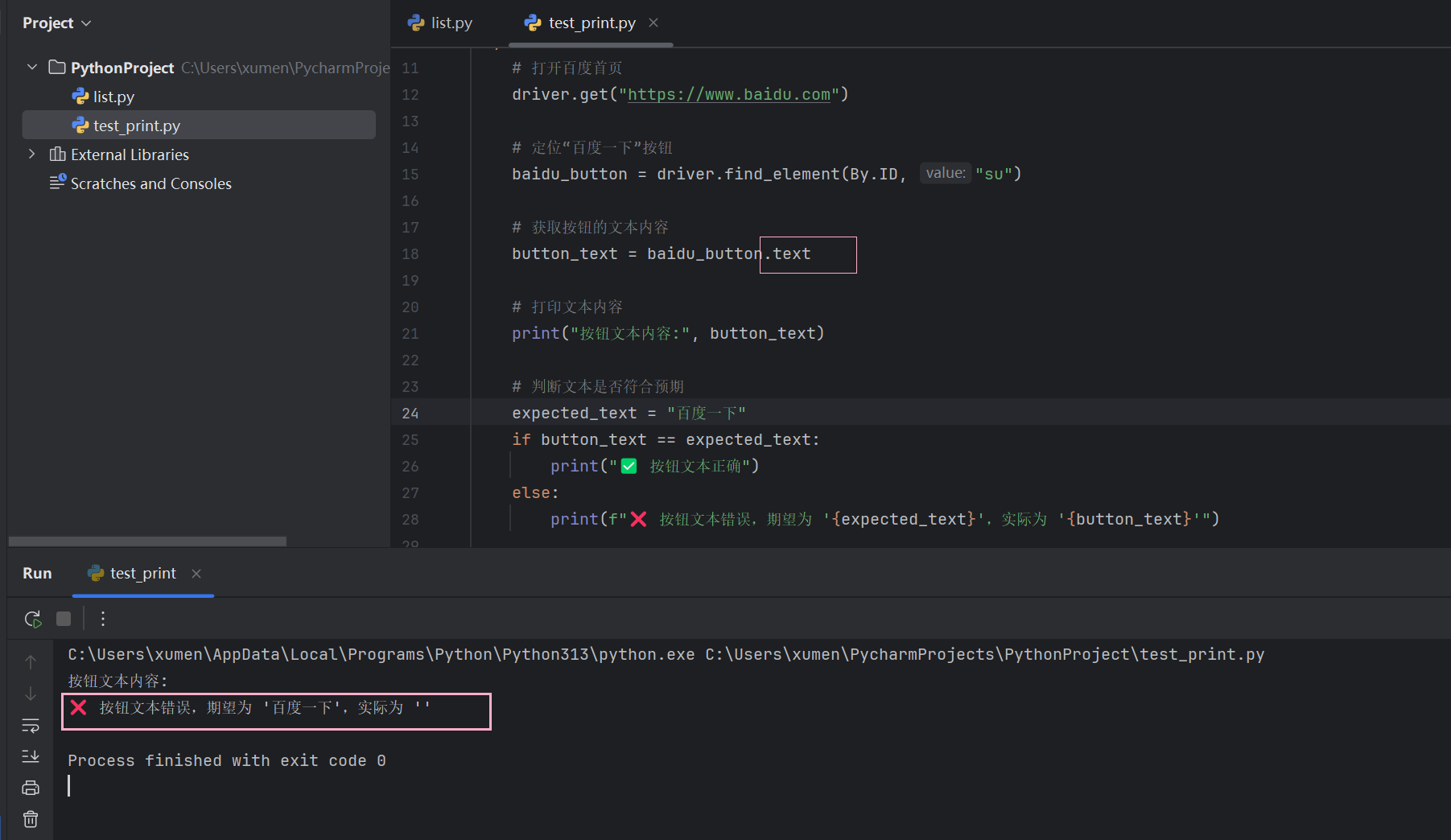
不应该是获取文本信息,而是获取属性值:
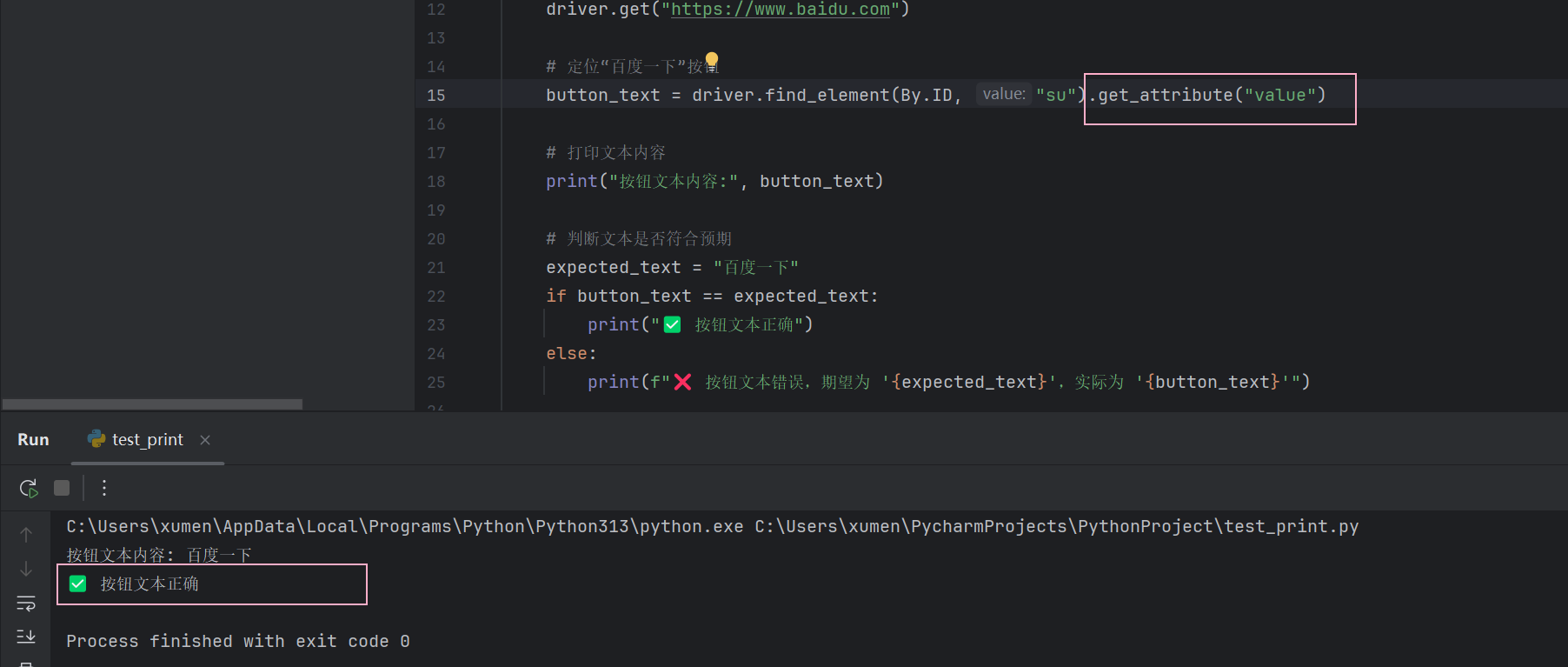
注意 :文本和属性值不要混淆了,获取属性值需要使用方法: getAttribute(" 属性名称 ")。
6、title 获取当前页面标题 & current_url 获取当前页面 URL
getTitle()
getCurrentUrl()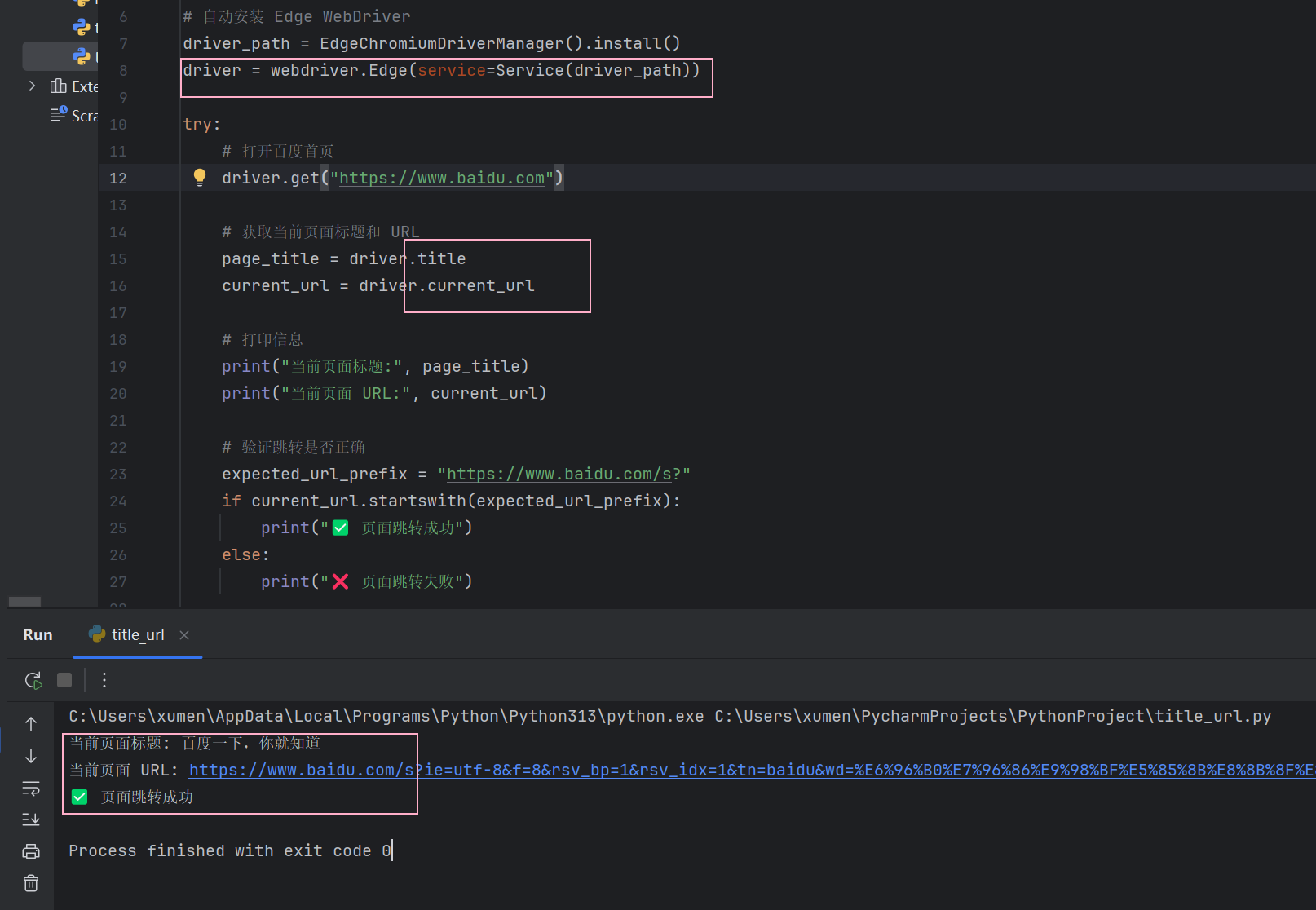
适用场景:页面元素可点击/跳转的情况下,用来检测跳转的结果是否为正确的。