第46节:多模态分类(图像+文本)
一、多模态分类概述
多模态分类是指利用来自不同模态(如图像、文本、音频等)的数据进行联合分析和分类的任务。
在当今大数据时代,信息往往以多种形式存在,例如社交媒体上的图片配文字、视频附带字幕、医疗检查中的影像与报告等。单一模态的数据往往只能提供有限的信息,而多模态数据则能通过不同渠道提供互补信息,从而提高分类的准确性和鲁棒性。
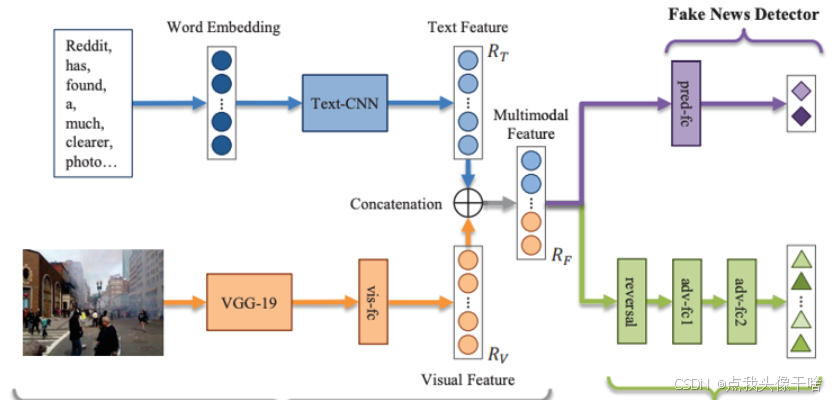
图像和文本作为两种最常见的数据模态,它们的结合分类具有重要的研究价值和广泛的应用前景。
图像数据能够提供丰富的视觉信息,而文本数据则包含明确的语义内容。
将二者有效结合,可以克服单一模态的局限性,例如图像分类中遇到的语义模糊问题,或文本分类中遇到的情感表达不充分问题。
多模态分类的核心挑战在于如何有效地融合不同模态的信息。由于图像和文本数据在特征空间中的分布差异巨大(图像通常表示为像素矩阵或卷积神经网络提取的特征向量,而文本则表示为词向量或序列编码),直接合并往往效果不佳。因此,研究者们开发了各种跨模态表示学习和融合策略来解决这一问题。