机器学习基础(三) 逻辑回归
目录
- 逻辑回归的概念
- 核心思想
- Sigmoid 函数
- 逻辑回归的原理和底层优化手段
- 伯努利分布
- 最大似然估计 Maximum Likelihood Estimation (MLE)
- 伯努利分布的似然函数
- 交叉熵损失函数(Cross-Entropy Loss),也称为 对数损失(Log Loss)
- 实操代码
- 逻辑回归解决多分类问题
- OVR
- 核心思想:
- 优点
- 缺点
- 一对一(One-vs-One)OvO
- 核心思想
- 优点
- 缺点
- 适用场景
逻辑回归的概念
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。
注意: 尽管名称中有"回归"二字,但它实际上是一种分类算法。
核心思想
逻辑回归通过将线性回归的输出映射到(0,1)区间,使用Sigmoid函数将连续值转换为概率值,然后根据概率值进行分类预测。
Sigmoid 函数
Sigmoid函数可以将任何实数映射到(0,1)区间内,可以解释为概率。
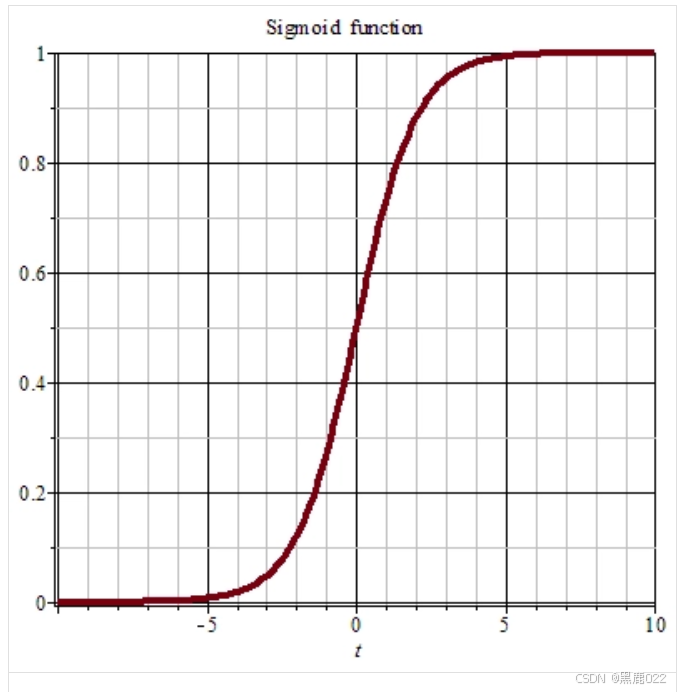 sigmoid 公式: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
sigmoid 公式: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
其中 z = ω T x + b z=\omega^Tx+b z=ωTx+b , ω \omega ω是权重向量(类似线性回归中的回归系数),x是特征向量,b是偏置。
逻辑回归的原理和底层优化手段
伯努利分布
伯努利分布也就是0,1分布:
P ( X = k ) = { p i f k = 1 1 − p i f k = 0 P(X=k)=\begin{cases} p & \quad if \; k=1 \\ 1-p & \quad if \; k=0 \end{cases} P(X=k)={p1−pifk=1ifk=0
或者简写为: P ( X = k ) = p k ( 1 − p ) 1 − k , k ∈ { 0 , 1 } P(X=k)=p^k(1-p)^{1-k},\qquad k\in \{0,1\} P(X=k)=pk(1−p)1−k,k∈{0,1}
逻辑回归的假设是:标签服从伯努利分布,因此我们可以套用伯努利分布的公式。
最大似然估计 Maximum Likelihood Estimation (MLE)
最大似然估计的核心思想是:“在已知观测数据的情况下,选择使得这些数据出现概率最大的参数值。” 我们可以通过最大化似然估计函数,来找到一个最优的参数。
伯努利分布的似然函数
由于样本标签是服从伯努利分布的,我们可以套用伯努利的最大似然函数公式:

交叉熵损失函数(Cross-Entropy Loss),也称为 对数损失(Log Loss)
直接最大化似然函数 L ( p ) L(p) L(p)在数学和计算上都不方便,所以我们对 L ( p ) L(p) L(p)取对数,将乘法变成加法,又因为优化算法(如梯度下降)通常被设计为最小化一个损失函数(成本函数),而不是最大化,因此,我们取对数似然函数 l o g ( L ( p ) ) log(L(p)) log(L(p)) 的负值,将其转化为一个最小化问题,这时的 − l o g ( L ( p ) ) -log(L(p)) −log(L(p))或者说 L o s s ( L ) Loss(L) Loss(L)就是二分类的交叉熵损失函数!

最后我们通过 L o s s ( L ) Loss(L) Loss(L)使用梯度下降方法求得最优的参数值。
实操代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, classification_report# 1. 加载并了解数据
data = pd.read_csv("癌症.csv")
print("数据头5行内容:")
print(data.head())
print("------------------------------------------"*3)
# 注意info()方法在内部就调用了print 不用手动print
print("数据详细描述信息:")
data.info()
print("------------------------------------------"*3)
print("数据列名称:")
print(data.columns)
print("------------------------------------------"*3)# 2. 处理数据
# 处理缺失值
data = data.replace('?', np.NaN)
data = data.dropna()
# 提取特征和标签
features = data.iloc[:, 1:-1]
label = data.iloc[:, -1]
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(features, label, test_size=0.2, random_state=666)# 3. 特征工程
# 数据标准化
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)# 使用逻辑回归模型
logit_model = LogisticRegression()
logit_model.fit(x_train, y_train)
y_predict = logit_model.predict(x_test)# 输出模型评估指标
print("模型混淆矩阵:\n", confusion_matrix(y_test, y_predict))
print("模型准确率:", accuracy_score(y_test, y_predict))
print("模型精准率(precision_score):", precision_score(y_test, y_predict, pos_label=2))
print("模型召回率(recall_score):", recall_score(y_test, y_predict, pos_label=2))
print("模型f1score:", f1_score(y_test, y_predict, pos_label=2))
print("模型分类报告:", classification_report(y_test, y_predict))"""
数据头5行内容:Sample code number Clump Thickness ... Mitoses Class
0 1000025 5 ... 1 2
1 1002945 5 ... 1 2
2 1015425 3 ... 1 2
3 1016277 6 ... 1 2
4 1017023 4 ... 1 2[5 rows x 11 columns]
------------------------------------------------------------------------------------------------------------------------------
数据详细描述信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 699 entries, 0 to 698
Data columns (total 11 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Sample code number 699 non-null int64 1 Clump Thickness 699 non-null int64 2 Uniformity of Cell Size 699 non-null int64 3 Uniformity of Cell Shape 699 non-null int64 4 Marginal Adhesion 699 non-null int64 5 Single Epithelial Cell Size 699 non-null int64 6 Bare Nuclei 699 non-null object7 Bland Chromatin 699 non-null int64 8 Normal Nucleoli 699 non-null int64 9 Mitoses 699 non-null int64 10 Class 699 non-null int64
dtypes: int64(10), object(1)
memory usage: 60.2+ KB
------------------------------------------------------------------------------------------------------------------------------
数据列名称:
Index(['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape', 'Marginal Adhesion','Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class'],dtype='object')
------------------------------------------------------------------------------------------------------------------------------
模型混淆矩阵:[[83 1][ 1 52]]
模型准确率: 0.9854014598540146
模型精准率(precision_score): 0.9880952380952381
模型召回率(recall_score): 0.9880952380952381
模型f1score: 0.9880952380952381
模型分类报告: precision recall f1-score support2 0.99 0.99 0.99 844 0.98 0.98 0.98 53accuracy 0.99 137macro avg 0.98 0.98 0.98 137
weighted avg 0.99 0.99 0.99 137"""逻辑回归解决多分类问题
OVR
一对其余(One-vs-Rest) OVR
核心思想:
对于 K 个类别的问题,训练 K 个独立的二分类器
第 i 个分类器负责将第 i 个类别(作为“正类”)与所有其他 K-1 个类别(合并作为“负类”)区分开来。
在预测时,将新样本输入到这 K 个分类器中。
每个分类器 i 会输出一个分数(通常是属于其“正类”的概率 p_i)。
选择输出概率 p_i 最高的那个分类器所对应的类别 i 作为样本的最终预测类别。
优点
概念简单直观,易于理解和实现。
训练复杂度相对较低(只需要训练 K 个模型)。
是 scikit-learn 中 LogisticRegression 类默认的多分类处理策略(当 multi_class=‘ovr’ 时)。
缺点
类别不平衡: 对于每个分类器,负类样本的数量通常远大于正类样本(尤其是当 K 较大时)。虽然逻辑回归本身对类别不平衡有一定鲁棒性(通过概率输出),但这仍可能影响模型的训练效果和决策边界。通常需要仔细调整样本权重(class_weight)
决策模糊: 如果多个分类器都给出较高的概率,或者所有概率都很低(样本可能不属于任何已知类别),决策可能会变得模糊或不可靠。
不一致性: 每个分类器都是在“该类 vs 所有其他类”的定义下训练的,而“所有其他类”本身是一个异构的集合。这可能导致学习到的决策边界不够精确。
一对一(One-vs-One)OvO
核心思想
对于 K 个类别的问题,训练 C(K, 2) = K(K-1)/2 个独立的二分类器。
每个分类器只负责区分一对特定的类别 (i, j) (i < j)。
在预测时,将新样本输入到所有 K(K-1)/2 个分类器中。
每个分类器对样本属于其两个类别中的哪一个进行投票。
统计所有分类器的投票结果,获得票数最多的类别作为样本的最终预测类别。
优点
训练数据更均衡: 每个分类器只使用涉及的两个类别的样本进行训练,避免了 OvR 中严重的类别不平衡问题。对于大规模数据集,这尤其有利。
可能更准确: 每个分类器只需学习区分两个类别之间的边界,任务通常比 OvR 中区分一个类别和所有其他类别的边界更简单、更清晰。
缺点
训练复杂度高: 需要训练 O(K²) 个分类器。当类别数量 K 很大时(例如成百上千),训练所需的时间和存储空间会显著增加。
预测复杂度高: 预测时需要运行 O(K²) 个分类器并进行投票统计,预测速度比 OvR 慢。
需要更多存储: 需要保存所有 O(K²) 个模型。
投票平局: 可能出现多个类别得票相同的情况,需要额外的策略处理平局。
适用场景
类别数量 K 适中时(不能太大);当训练集非常大,且类别不平衡在 OvR 中成为主要问题时;对预测速度要求不是极其苛刻时。scikit-learn 的 LogisticRegression 可以通过 multi_class=‘multinomial’ 使用(内部优化实现),但传统的 OvO 策略也常用于 SVM 等算法。