DataStreamAPI实践原理——快速上手(实操详细版)
引入
上一篇DataStreamAPI实践原理——快速上手的实操内容不够详细,对很多基础薄弱的小伙伴来说上手有一定难度,所以本文重点针对实操环节进行详细讲解。
Flink开发环境准备
学习一门新的编程语言时,往往会从"hello world"程序开始,而接触一套新的大数据计算框架时,则一般会从WordCount案例入手,所以我们以大数据中最经典入门案例WordCount为例,来快速上手,编写Flink代码。
Flink底层源码是基于Java代码进行开发,在Flink编程中我们除了可以使用Java语言来进行编写Flink程序外,还可以使用Scala、Python语言来进行编写Flink程序,在后续章节中我们将会主要使用Java和Scala来编写Flink程序。下面来准备下Flink开发环境。
Flink版本
本专栏的实践部分,主要采用Flink1.16.0版本,深入源码的时候会从1.9到最新的2.0都会去看看。
Flink1.16.0版本官方文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.16/
JDK环境
Flink核心模块均采用Java开发,所以运行环境需要依赖JDK,Flink可以基于类UNIX 环境中运行,例如:Linux、Max OS、Windows等,在这些系统上运行Flink时都需要配置JDK环境,Flink 1.16.0版本需要JDK版本为JDK11,不过也支持使用JDK8。
考虑到Flink后期与一些大数据框架进行整合,这些大数据框架对JDK11的支持并不完善,例如:Hive3.1.3版本还不支持JDK11,所以这里还是采用JDK8来开发Flink。对JDK8安装及配置就不再详述。
开发工具
我们可以选择IntelliJ IDEA或者Eclipse作为Flink应用的开发IDE,Flink开发官方建议使用IntelliJ IDEA,因为它默认集成了Scala和Maven环境,使用更加方便,我们也使用IntelliJ IDEA开发工具,具体安装步骤就不再详述。
Maven环境
通过IntelliJ IDEA进行开发Flink Application时,可以使用Maven来作为项目jar包管理工具,需要在本地安装Maven及配置Maven的环境变量,需要注意的是,Maven版本需要使用3.0.4及以上,否则编译或开发过程中会有问题。这里使用Maven 3.5.4版本。
Scala环境
Flink开发语言可以选择Java、Scala、Python,如果用户选择使用Scala作为Flink应用开发语言,则需要安装Scala执行环境。
在Flink1.15之前版本,如果只是使用Flink的Java api ,对于一些没有Scala模块的包和表相关模块的包需要在Maven引入对应的包中加入scala后缀,例如:flink-table-planner_2.11,后缀2.11代表的就是Scala版本。在Flink1.15.0版本后,Flink添加对 opting-out(排除) Scala的支持,如果你只使用Flink的Java api,导入包也不必包含scala后缀,你可以使用任何Scala版本。如果使用Flink的Scala api,需要选择匹配的Scala版本。
从Flink1.7版本往后支持Scala 2.11和2.12版本,从Flink1.15.0版本后只支持Scala 2.12,不再支持Scala 2.11。Scala环境可以通过本地安装Scala执行环境,也可以通过Maven依赖Scala-lib引入,如果本地安装了Scala某个版本,建议在Maven中添加Scala-lib依赖。Scala2.12.8之后的版本与之前的2.12.x版本不兼容,建议使用Scala2.12.8之后版本。
Hadoop环境
Flink可以操作HDFS中的数据及基于Yarn进行资源调度,所以需要对应的Hadoop环境,Flink1.16.0版本支持的Hadoop最低版本为2.8.5。
Flink入门案例
需求:读取本地数据文件,统计文件中每个单词出现的次数。
IDEA Project创建及配置
由于我们编写Flink代码选择语言为Java和Scala,所以这里我们通过IntelliJ IDEA创建一个目录,其中包括Java项目模块和Scala项目模块,将Flink Java api和Flink Scala api分别在不同项目模块中实现。步骤如下:
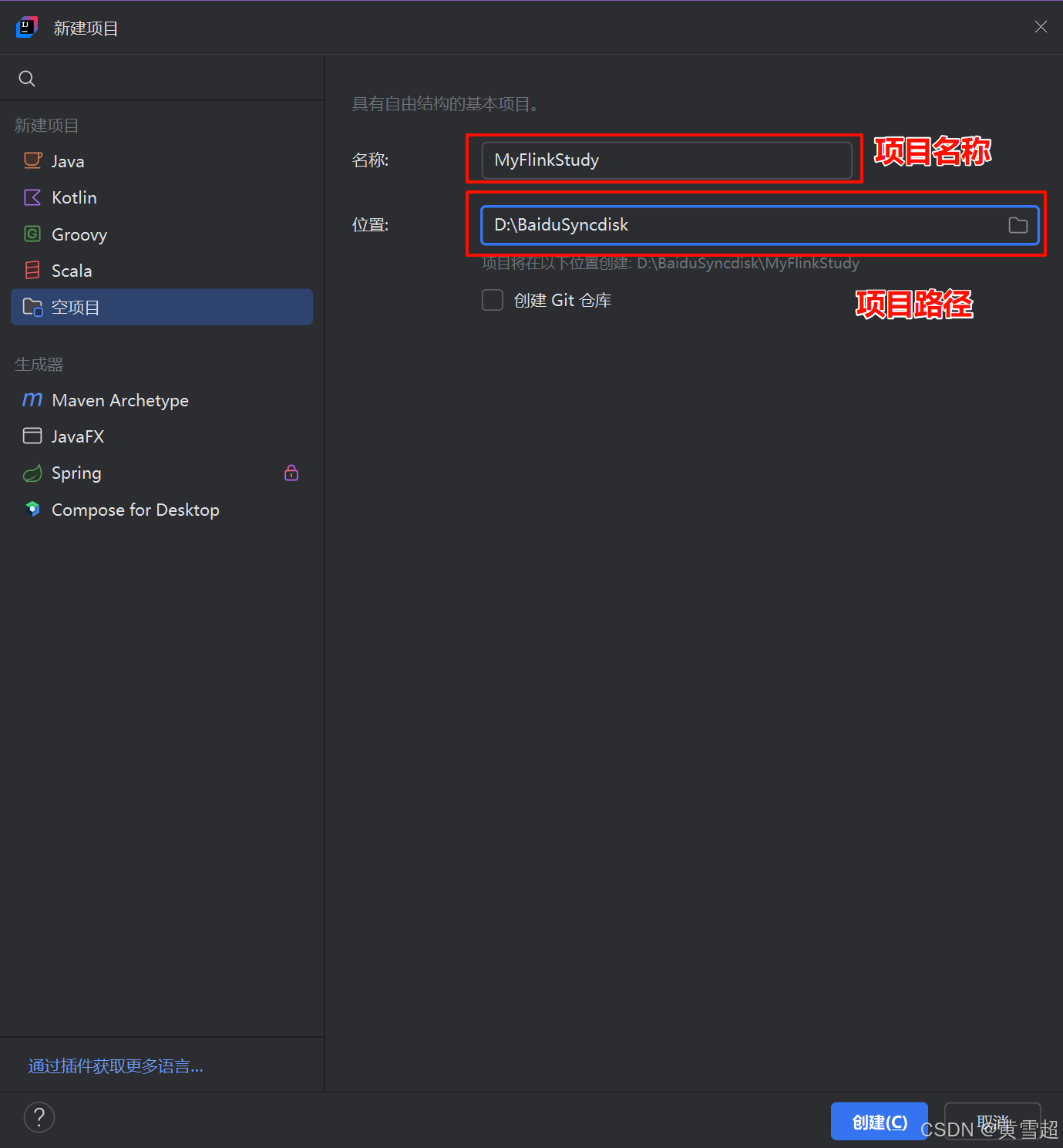
1.打开IDEA,创建空项目
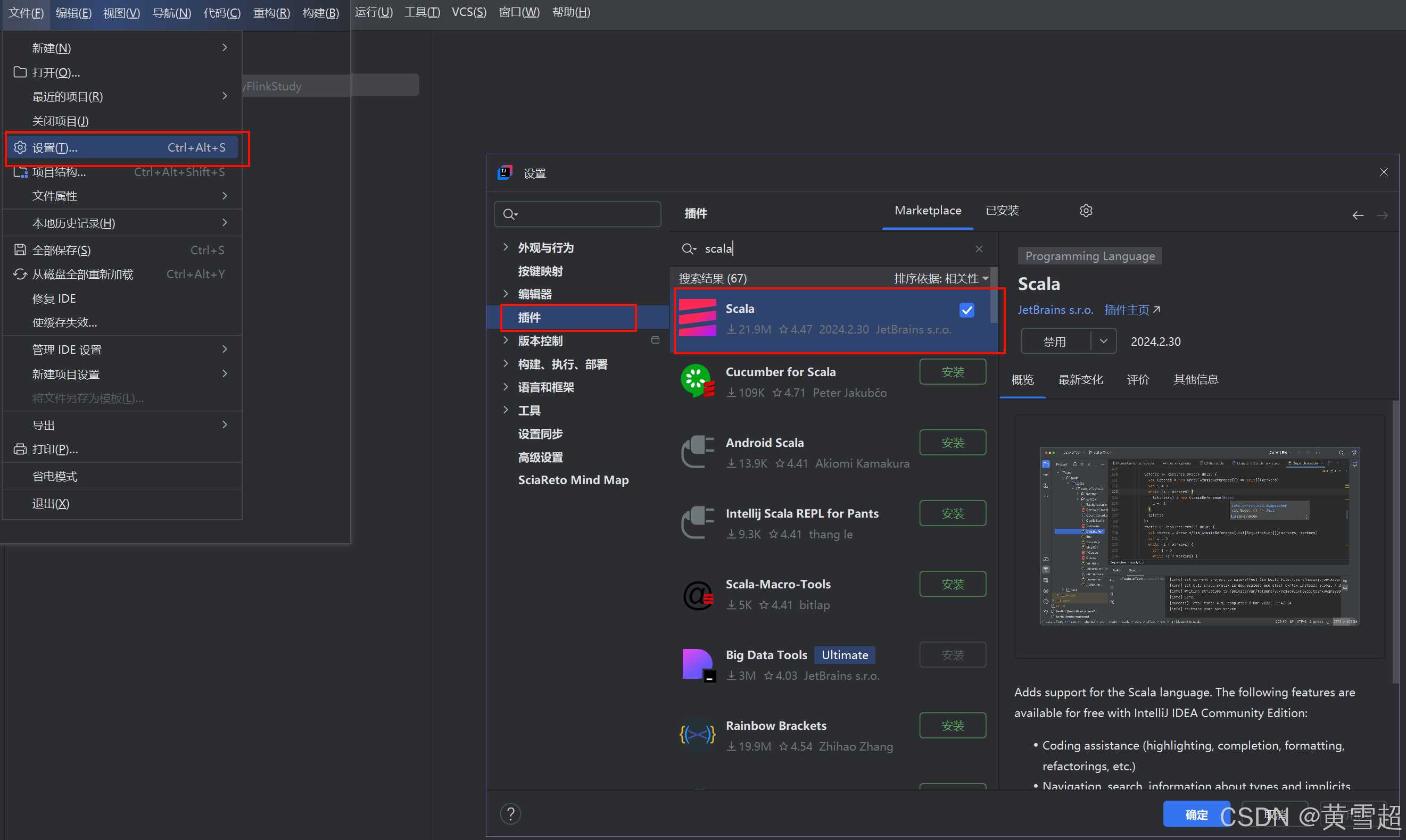
2. 在IntelliJ IDEA 中安装Scala插件
使用IntelliJ IDEA开发Flink,如果使用Scala api 那么还需在IntelliJ IDEA中安装Scala的插件,如果已经安装可以忽略此步骤,下图为以安装Scala插件。
3. 打开文档结构(Structure),创建项目新模块
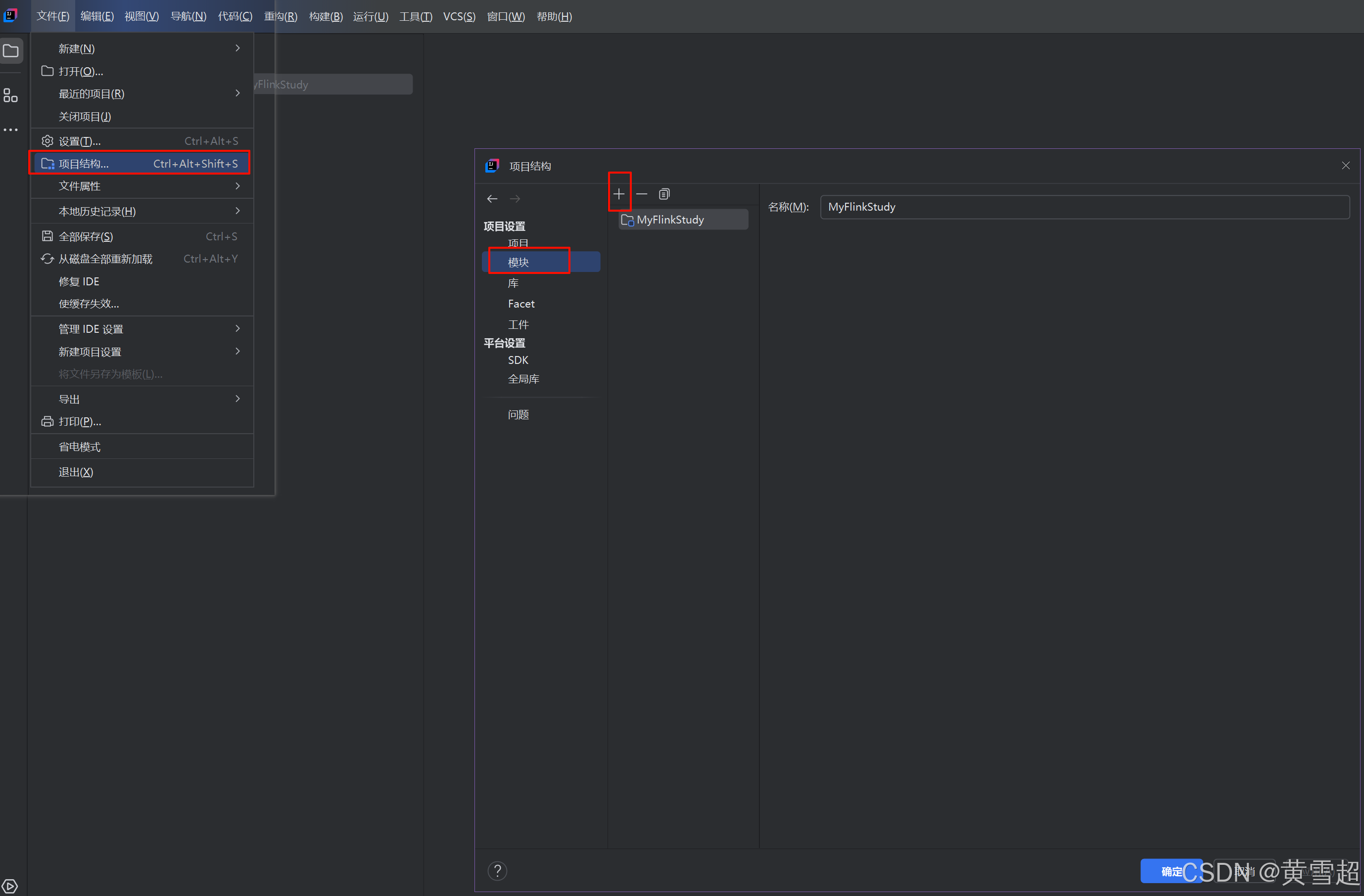
创建Java模块:
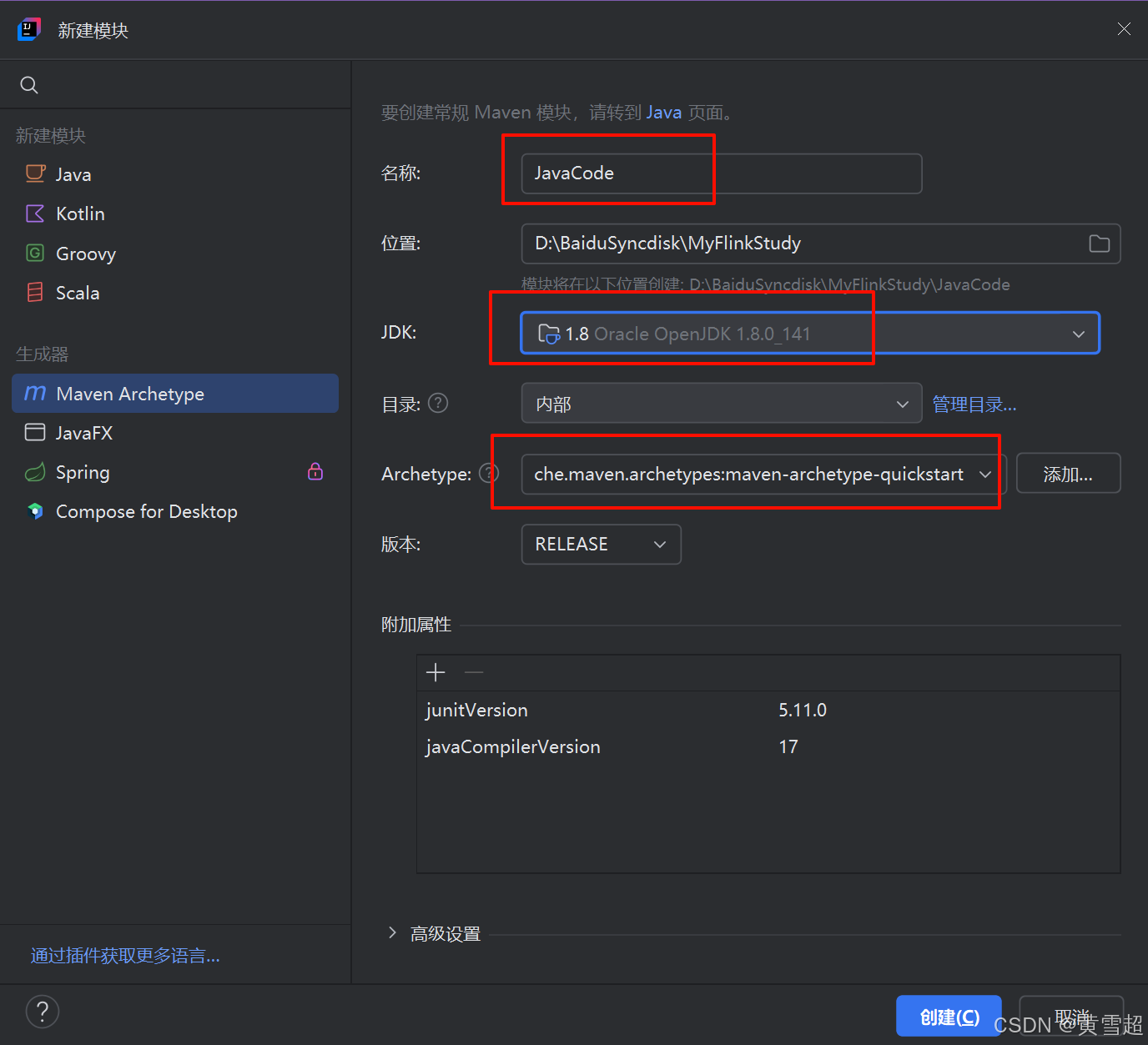
继续点击"+",创建Scala模块:
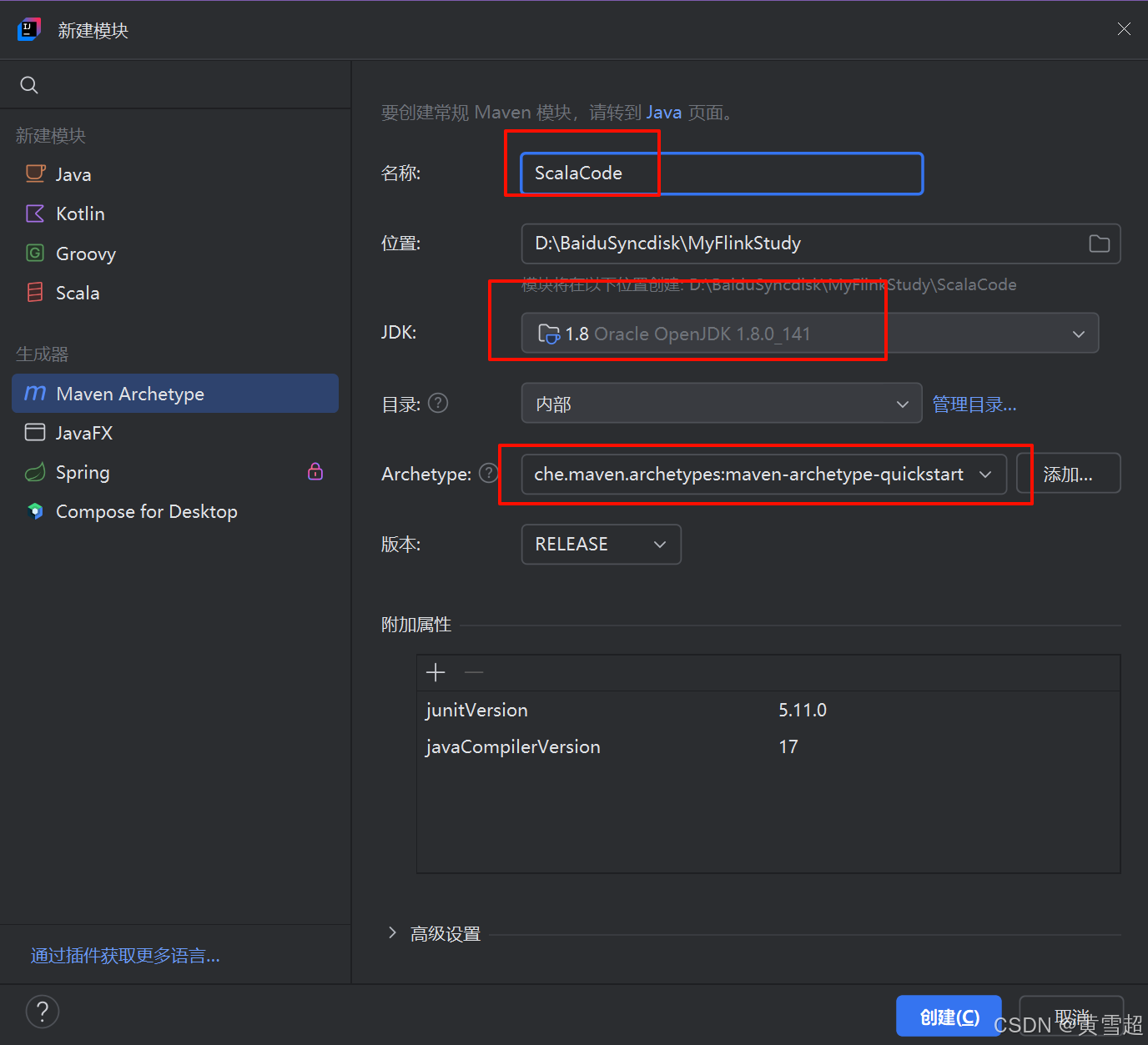
创建好 ScalaCode 模块后,在全局库添加Scala的SDK:
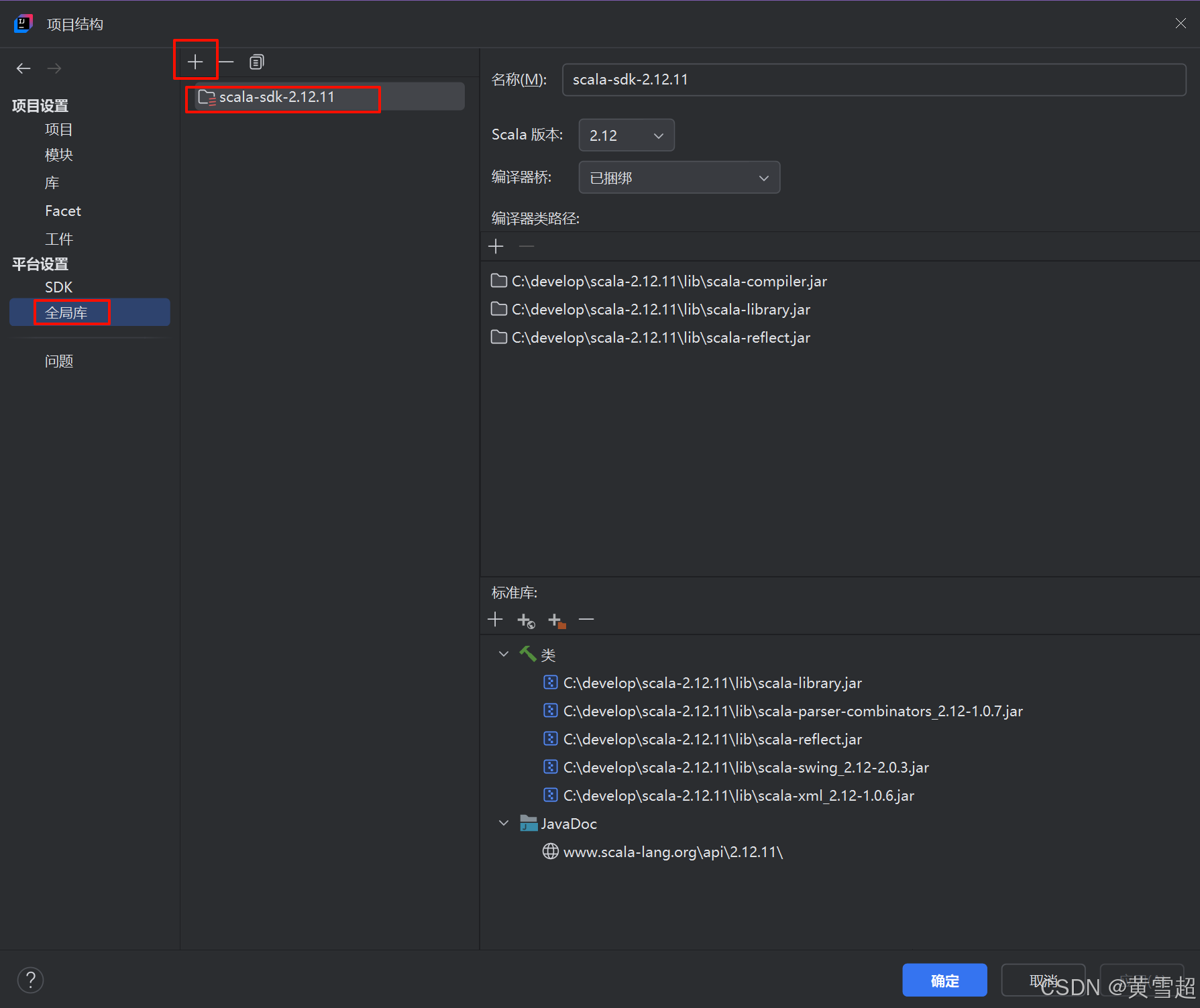
然后对ScalaCode添加Scala框架支持:

在 ScalaCode 模块Maven pom.xml中引入Scala依赖包,这里使用的Scala版本为2.12.11:
<properties><scala.version>2.12.11</scala.version><scala.binary.version>2.12</scala.binary.version>
</properties><dependencies><!-- Scala包 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>${scala.version}</version></dependency><!-- slf4j&log4j 日志相关包 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>${log4j.version}</version></dependency>
</dependencies>4. Log4j日志配置
为了方便查看项目运行过程中的日志,需要在两个项目模块中配置log4j.properties配置文件,并放在各自项目src/main/resources资源目录下,没有resources资源目录需要手动创建并设置成资源目录。
log4j.properties配置文件内容如下:
log4j.rootLogger=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{HH:mm:ss} %p %c{2}: %m%n并在两个项目中的Maven pom.xml中添加对应的log4j需要的依赖包,使代码运行时能正常打印结果:
<properties><slf4j.version>1.7.31</slf4j.version><log4j.version>2.17.1</log4j.version>
</properties>
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.36</version>
</dependency>
<dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.17.2</version>
</dependency>5. 分别在两个项目模块中导入Flink Maven依赖
JavaCode 模块导入Flink Maven依赖如下:
<properties><flink.version>1.16.0</flink.version>
</properties><dependencies><!-- Flink批和流开发依赖包 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency>
</dependencies>注意: 在后续实现WordCount需求时,Flink Java Api只需要在Maven中导入"flink-clients"依赖包即可,而Flink Scala Api 需要导入以下三个依赖包:
<properties><flink.version>1.16.0</flink.version>
</properties>
<dependencies><!-- Flink批和流开发依赖包 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency>
</dependencies>主要是因为在Flink1.15版本后,Flink添加对opting-out(排除)Scala的支持,如果你只使用Flink的Java api,导入包不必包含scala后缀,如果使用Flink的Scala api,需要选择匹配的Scala版本。
案例数据准备
在项目 MyFlinkStudy 中创建 data 目录,在目录中创建 words.txt 文件,向文件中写入以下内容,方便后续使用Flink编写WordCount实现代码。
Flink案例实现
数据源分为有界和无界之分,有界数据源可以编写批处理程序,无界数据源可以编写流式程序。DataSet API用于批处理,DataStream API用于流式处理。
批处理使用ExecutionEnvironment和DataSet,流式处理使用StreamingExecutionEnvironment和DataStream。DataSet和DataStream是Flink中表示数据的特殊类,DataSet处理的数据是有界的,DataStream处理的数据是无界的,这两个类都是不可变的,一旦创建出来就无法添加或者删除数据元。
Flink 批数据处理案例
Java版本WordCount
使用Flink Java Dataset api实现WordCount具体代码如下:
/*** WordCountTest 类用于演示 Apache Flink 的批处理功能,实现单词计数。* 该程序从指定文件中读取文本,将文本拆分为单词,统计每个单词的出现次数并打印结果。*/
public class WordCountTest {/*** 程序的入口点,执行单词计数的主要逻辑。* * @param args 命令行参数,在本程序中未使用。* @throws Exception 若执行过程中出现异常,将抛出该异常。*/public static void main(String[] args) throws Exception {// 获取 Flink 的批处理执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 1. 读取文件// 从指定路径读取文本文件,将每行文本作为一个字符串元素存储在 DataSource 中DataSource<String> linesDS = env.readTextFile("./data/words.txt");// 2. 切分单词// 使用 flatMap 操作将每行文本拆分为多个单词,并将每个单词收集到新的数据集里FlatMapOperator<String, String> wordsDS =linesDS.flatMap((String lines, Collector<String> collector) -> {// 将每行文本按空格分割成字符串数组String[] arr = lines.split(" ");// 遍历数组,将每个单词收集到 Collector 中for (String word : arr) {collector.collect(word);}}).returns(Types.STRING);// 3. 将单词转换成 Tuple2 KV 类型// 使用 map 操作将每个单词转换为 Tuple2 类型,其中第一个元素为单词,第二个元素为初始计数 1LMapOperator<String, Tuple2<String, Long>> kvWordsDS =wordsDS.map(word -> new Tuple2<>(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 按照 key 进行分组处理得到最后结果并打印// 按照 Tuple2 的第一个元素(单词)进行分组,对每组的第二个元素(计数)进行求和操作// 最后打印统计结果kvWordsDS.groupBy(0).sum(1).print();}
}执行结果如下:
(hadoop,1)
(scala,1)
(zookeeper,2)
(flink,1)
(world,1)
(hello,13)
(java,1)
(kafka,3)
(python,1)
(spark,1)
(chaos,1)
Scala版本WordCount
使用Flink Scala Dataset api实现WordCount具体代码如下:
// 导入Flink的Scala API执行环境类
import org.apache.flink.api.scala.ExecutionEnvironment/*** WordCountTest 是一个使用 Apache Flink 进行单词计数的示例程序。* 该程序从文件中读取文本数据,对文本中的单词进行计数,并将结果打印输出。*/
object WordCountTest {/*** 程序的入口点。* @param args 命令行参数,在本程序中未使用。*/def main(args: Array[String]): Unit = {// 1. 准备环境,注意是Scala中对应的Flink环境// 获取Flink的批处理执行环境,后续的所有操作都将在这个环境中执行val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment// 2. Scala 批处理导入隐式转换,使用Scala API 时需要隐式转换来推断函数操作后的类型// 导入Flink Scala API的隐式转换,使得后续操作可以正常使用Scala的语法特性import org.apache.flink.api.scala._// 3. 读取数据文件// 从指定路径的文本文件中读取数据,每一行作为DataSet中的一个元素val linesDS: DataSet[String] = env.readTextFile("./data/words.txt")// 4. 进行 WordCount 统计并打印linesDS// 将每一行文本按空格分割成多个单词,每个单词作为一个新的元素.flatMap(line => {line.split(" ")})// 将每个单词映射为 (单词, 1) 的元组,1 表示该单词出现一次.map((_, 1))// 根据元组的第一个元素(即单词)进行分组.groupBy(0)// 对每个分组内元组的第二个元素(即出现次数)进行求和.sum(1)// 将最终的统计结果打印输出.print()}
}执行结果如下:
(hadoop,1)
(scala,1)
(zookeeper,2)
(flink,1)
(world,1)
(hello,13)
(java,1)
(kafka,3)
(python,1)
(spark,1)
(chaos,1)
Flink流式数据处理案例
Java版本WordCount
使用Flink Java DataStream api实现WordCount具体代码如下:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** WordCountStreamTest 类用于实现 Flink 流式处理的单词计数功能。* 该程序从文件中读取文本数据,对文本中的单词进行计数,并输出每个单词的出现次数。*/
public class WordCountStreamTest {/*** 程序的入口点,执行 Flink 流式单词计数任务。* * @param args 命令行参数,在本程序中未使用。* @throws Exception 执行环境可能抛出的异常。*/public static void main(String[] args) throws Exception {// 1. 创建流式处理环境// 获取一个默认的流式执行环境,用于配置和执行 Flink 流式作业StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文件数据// 从指定路径的文本文件中读取数据,将每行文本作为一个字符串元素添加到数据流中// 注意:readTextFile 方法已弃用,建议使用新的文件读取 APIDataStreamSource<String> lines = env.readTextFile("./data/words.txt");// 3. 切分单词,设置 KV 格式数据// 使用 flatMap 操作将每行文本切分为多个单词,并将每个单词转换为 (word, 1) 的元组形式// returns 方法用于显式指定返回类型信息,帮助 Flink 正确推断数据类型SingleOutputStreamOperator<Tuple2<String, Long>> kvWordsDS =lines.flatMap((String line, Collector<Tuple2<String, Long>> collector) -> {// 将每行文本按空格分割成单词数组String[] words = line.split(" ");// 遍历单词数组,将每个单词封装为 (word, 1) 的元组并收集到结果流中for (String word : words) {collector.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 分组统计获取 WordCount 结果// 使用 keyBy 方法按照元组的第一个字段(单词)进行分组// 使用 sum 方法对每个分组内的元组的第二个字段(计数)进行求和操作// 最后使用 print 方法将结果打印到控制台kvWordsDS.keyBy(tp -> tp.f0).sum(1).print();// 5. 流式计算中需要最后执行 execute 方法// 触发 Flink 作业的执行,程序会一直运行直到作业完成或被手动终止env.execute();}
}执行结果如下:
5> (hello,1)
15> (hadoop,1)
13> (zookeeper,1)
1> (spark,1)
4> (chaos,1)
3> (java,1)
1> (scala,1)
13> (flink,1)
1> (kafka,1)
5> (hello,2)
1> (kafka,2)
9> (world,1)
1> (kafka,3)
5> (hello,3)
5> (hello,4)
5> (hello,5)
5> (hello,6)
5> (hello,7)
5> (hello,8)
5> (hello,9)
5> (hello,10)
5> (hello,11)
5> (hello,12)
5> (hello,13)
5> (python,1)
13> (zookeeper,2)
Scala版本WordCount
使用Flink Scala DataStream api实现WordCount具体代码如下:
// 导入 Flink 流式执行环境相关类,用于创建和管理流式处理环境
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment/*** WordCountStreamTest 对象用于实现 Flink 流式处理的单词计数功能。* 该程序从文件中读取文本数据,统计每个单词出现的次数,并将结果打印输出。*/
object WordCountStreamTest {/*** 程序的入口点,执行 Flink 流式单词计数任务。** @param args 命令行参数,在本程序中未使用。*/def main(args: Array[String]): Unit = {// 1. 创建环境// 获取一个默认的流式执行环境,用于配置和执行 Flink 流式作业val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment// 2. 导入隐式转换,使用 Scala API 时需要隐式转换来推断函数操作后的类型// 这些隐式转换能帮助 Flink 正确处理 Scala 集合和函数,使代码更简洁import org.apache.flink.streaming.api.scala._// 3. 读取文件// 从指定路径的文本文件中读取数据,将每行文本作为一个字符串元素添加到数据流中val ds: DataStream[String] = env.readTextFile("./data/words.txt")// 4. 进行 wordCount 统计// flatMap 操作将每行文本按空格分割成多个单词,将嵌套的集合“扁平化”为单个元素流// map 操作将每个单词映射为 (word, 1) 的元组形式,表示该单词出现一次// keyBy 操作按照元组的第一个元素(单词)进行分组// sum 操作对每个分组内元组的第二个元素(计数)进行求和// print 操作将最终的统计结果打印到控制台ds.flatMap(line => line.split(" ")).map((_, 1)).keyBy(_._1).sum(1).print()// 5. 最后使用 execute 方法触发执行// 启动 Flink 作业,程序会持续运行直到作业完成或被手动终止env.execute()}
}执行结果如下:
4> (chaos,1)
13> (flink,1)
1> (kafka,1)
1> (spark,1)
5> (hello,1)
1> (scala,1)
3> (java,1)
9> (world,1)
15> (hadoop,1)
13> (zookeeper,1)
5> (hello,2)
5> (hello,3)
13> (zookeeper,2)
5> (hello,4)
5> (hello,5)
5> (hello,6)
1> (kafka,2)
1> (kafka,3)
5> (hello,7)
5> (hello,8)
5> (hello,9)
5> (hello,10)
5> (hello,11)
5> (python,1)
5> (hello,12)
5> (hello,13)
流式数据处理的输出结果开头展示的是处理当前数据的线程,一个Flink应用程序执行时默认的线程数与当前节点cpu的总线程数有关。
Flink批和流案例总结
关于以上Flink 批数据处理和流式数据处理案例有以下几个点需要注意:
Flink程序编写流程总结
编写Flink代码要符合一定的流程,Flink代码编写流程如下:
- 获取flink的执行环境,批和流不同,Execution Environment。
- 加载数据数据-- soure。
- 对加载的数据进行转换-- transformation。
- 对结果进行保存或者打印-- sink。
- 触发flink程序的执行 --env.execute()
在Flink批处理过程中不需要执行execute触发执行,在流式处理过程中需要执行env.execute触发程序执行。
关于Flink的批处理和流处理上下文环境
创建Flink批和流上下文环境有以下三种方式,批处理上下文创建环境如下:
// 设置Flink运行环境,根据当前的运行上下文自动选择合适的环境。
// 如果在本地启动,会创建本地环境;如果是在集群中启动,则创建集群环境。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 指定并行度为10,手动创建一个本地Flink执行环境。
// 该环境会在本地以指定的并行度运行Flink作业,常用于本地开发和测试。
LocalEnvironment localEnv = ExecutionEnvironment.createLocalEnvironment(10);// 指定远程JobManager的IP地址、RPC端口号、并行度以及运行程序所在的Jar包及其依赖包,
// 创建一个用于连接到远程Flink集群的执行环境。
// 此环境可将作业提交到指定的远程集群上运行。
ExecutionEnvironment remoteEnv = ExecutionEnvironment.createRemoteEnvironment("JobManagerHost", 6021, 5, "application.jar");流处理上下文创建环境如下:
// 设置Flink运行环境,该方法会根据程序的运行上下文自动选择合适的执行环境。
// 如果程序在本地运行,会返回本地执行环境;如果在集群中运行,会返回集群执行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 指定并行度创建本地环境,这里将本地环境的并行度设置为5。
// 并行度表示任务在本地执行时同时运行的任务实例数量。
LocalStreamEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment(5);// 指定远程JobManager的IP地址、RPC端口、并行度以及运行程序所在的Jar包及其依赖包,创建远程执行环境。
// 该环境用于将作业提交到指定的远程Flink集群上运行。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment.createRemoteEnvironment("JobManagerHost", 6021, 5, "application.jar");同样在Scala api 中批和流创建Flink 上下文环境也有以上三种方式。
-
在实际开发中建议批处理使用"ExecutionEnvironment.getExecutionEnvironment()"方式创建。
-
流处理使用"StreamExecutionEnvironment.getExecution-Environment()"方式创建。
Flink Scala api需要导入隐式转换
在Flink Scala api中批处理和流处理代码编写过程中需要导入对应的隐式转换来推断函数操作后的类型,在批和流中导入隐式转换不同,具体如下:
//Scala 批处理导入隐式转换,使用Scala API 时需要隐式转换来推断函数操作后的类型
import org.apache.flink.api.scala._
//Scala 流处理导入隐式转换,使用Scala API 时需要隐式转换来推断函数操作后的类型
import org.apache.flink.streaming.api.scala._
关于Flink Java api 中的 returns 方法
Flink Java api中可以使用Lambda表达式,当涉及到使用泛型Java会擦除泛型类型信息,需要最后调用returns方法指定类型,明确声明类型,告诉系统函数生成的数据集或者数据流的类型。
批和流对数据进行分组方法不同
批和流处理中都是通过readTextFile来读取数据文件,对数据进行转换处理后,Flink批处理过程中通过groupBy指定按照什么规则进行数据分组,groupBy中可以根据字段位置指定key(例如:groupBy(0)),如果数据是POJO自定义类型也可以根据字段名称指定key(例如:groupBy("name")),对于复杂的数据类型也可以通过定义key的选择器 KeySelector 来实现分组的key。
Flink流处理过程中通过keyBy指定按照什么规则进行数据分组,keyBy中也有以上三种方式指定分组key,建议使用通过KeySelector来选择key,其他方式已经过时。
关于DataSet Api (Legacy)软弃用
Flink架构可以处理批和流,Flink 批处理数据需要使用到Flink中的DataSet API,此API 主要是支持Flink针对批数据进行操作,本质上Flink处理批数据也是看成一种特殊的流处理(有界流),所以没有必要分成批和流两套API,从Flink1.12版本往后,Dataset API 已经标记为Legacy(已过时),已被官方软弃用,官方建议使用Table API 或者SQL 来处理批数据,我们也可以使用带有Batch执行模式的DataStream API来处理批数据。
DataStream BATCH模式
下面使用Java代码使用DataStream API 的Batch 模式来处理批WordCount代码,方式如下:
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** WordCountStreamBatchTest 类用于演示使用 Apache Flink 进行批处理模式下的单词计数操作。*/
public class WordCountStreamBatchTest {/*** 程序的入口方法,负责初始化 Flink 执行环境,读取文件数据,进行单词计数并输出结果。* * @param args 命令行参数,在本程序中未使用。* @throws Exception 当执行 Flink 作业时可能抛出异常。*/public static void main(String[] args) throws Exception {// 获取 Flink 流执行环境实例StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式为批处理模式env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 从指定文件中读取文本数据,返回一个包含每行文本的数据流DataStreamSource<String> linesDS = env.readTextFile("./data/words.txt");// 使用 flatMap 操作将每行文本拆分为单词,并将每个单词映射为 (单词, 1) 的元组SingleOutputStreamOperator<Tuple2<String, Long>> wordsDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {/*** 对输入的每行文本进行处理,将其拆分为单词,并将每个单词封装为 (单词, 1) 的元组发送给收集器。* * @param lines 输入的一行文本。* @param out 用于收集处理结果的收集器。* @throws Exception 理论上可能抛出异常,但在本方法中未实际抛出。*/@Overridepublic void flatMap(String lines, Collector<Tuple2<String, Long>> out) throws Exception {// 将输入的行文本按空格拆分为单词数组String[] words = lines.split(" ");// 遍历单词数组,将每个单词封装为 (单词, 1) 的元组并发送给收集器for (String word : words) {out.collect(new Tuple2<>(word, 1L));}}});// 按照元组的第一个元素(单词)进行分组,然后对第二个元素(计数)进行求和操作wordsDS.keyBy(tp -> tp.f0).sum(1).print();// 执行 Flink 作业env.execute();}
}以上代码运行完成之后结果如下,可以看到结果与批处理结果类似,只是多了对应的处理线程号:
13> (flink,1)
5> (hello,13)
13> (zookeeper,2)
5> (python,1)
4> (chaos,1)
9> (world,1)
3> (java,1)
15> (hadoop,1)
1> (kafka,3)
1> (scala,1)
1> (spark,1)
此外,Stream API 中除了可以设置Batch批处理模式之外,还可以设置 AUTOMATIC、STREAMING模式,STREAMING 模式是流模式,AUTOMATIC模式会根据数据是有界流/无界流自动决定采用BATCH/STREAMING模式来读取数据,设置方式如下:
//BATCH 设置批处理模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//AUTOMATIC 会根据有界流/无界流自动决定采用BATCH/STREAMING模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//STREAMING 设置流处理模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);除了在代码中设置处理模式外,还可以在Flink配置文件(flink-conf.yaml)中设置execution.runtime-mode参数来指定对应的模式,也可以在集群中提交Flink任务时指定execution.runtime-mode来指定,Flink官方建议在提交Flink任务时指定执行模式,这样减少了代码配置给Flink Application提供了更大的灵活性,提交任务指定参数如下:
$FLINK_HOME/bin/flink run -Dexecution.runtime-mode=BATCH -c xxx xxx.jar