【学习笔记】Circuit Tracing: Revealing Computational Graphs in Language Models
Circuit Tracing: Revealing Computational Graphs in Language Models
![![[Pasted image 20250602202000.png]]](https://i-blog.csdnimg.cn/direct/be04273c158b481a96d85de8d4d217bb.png)
替代模型(Replacement Model):用更多的可解释的特征来替代transformer模型的神经元。
归因图(Attribution Graph):展示特征之间的相互影响,能够追踪模型生成输出时所采用的中间步骤。
Abstract
本文提出了一种方法,用于揭示语言模型行为背后的机制。该方法通过在一个“替代模型”中追踪每一步计算,生成模型在特定提示上的计算过程图。这个替代模型用一个更易解释的组件(此处为“cross-layer transcoder”)来替代底层模型的一部分(此处为MLP),并通过训练使其能够近似原模型的功能。还开发了一套可视化与验证工具,用于分析这些支持18层语言模型简单行为的“归因图”,并为后续论文奠定基础,该论文将把这些方法应用于前沿模型 Claude 3.5 Haiku 的研究中。
1 Introduction
深度学习模型通过一系列分布在众多计算单元(人工“神经元”)上的变换来生成输出。机制可解释性(mechanistic interpretability)这一研究领域旨在用人类可理解的语言描述这些变换过程。到目前为止,采用的是一个“两步法”:第一步,识别出模型在计算中使用的可解释构建块,即“特征”;第二步,描述这些特征之间如何交互形成模型输出的过程,也就是“路径”(circuit)。
模型神经元往往具有多义性(polysemantic),即一个神经元同时代表多个毫不相关的概念。导致这种多义性的重要原因之一被认为是“叠加现象”(superposition),即模型必须表示的概念数量超过了神经元的数量,因此不得不在多个神经元上“摊开”一个概念的表示。这种模型基本计算单元(神经元)与人类可理解概念之间的不匹配,严重阻碍了机制可解释性研究的进展,尤其是在语言模型方面。
近年来,稀疏编码模型(如稀疏自编码器 sparse autoencoders,SAEs)、转码器(transcoders)和跨编码器(crosscoders)等方法将模型的激活分解为稀疏激活的组成部分(即“特征”),这些特征在很多情况下与人类可理解的概念相对应。
尽管目前的稀疏编码方法在特征识别方面还不够完美,但它们所生成的结果已经足够可解释,因此我们有动力研究由这些特征组成的路径。
本文介绍了目前采用的方法,该方法涉及多个关键的技术决策:
- 转码器(Transcoders):使用Transcoders的一种变体来提取特征,而不是使用SAEs。这能够构建一个可解释的“替代模型”,用来作为原始模型的代理进行研究,同时允许分析特征与特征之间的直接交互。
- 跨层结构(Cross-Layer):本文分析基于Cross-Layer Transcoder,其中每个特征从某一层的残差流中读取输入,并对原始模型中所有后续的 MLP 层产生影响,这大大简化了最终得到的路径结构。值得注意的是,将学习到的 CLT 特征替代模型的 MLP 部分,并在约 50% 的数据下得到与原始模型相匹配的输出。
- 归因图(Attribution Graphs):重点研究“归因图”,该图描述了模型在特定提示词下,为一个目标 token 生成输出所经过的计算步骤。归因图中的节点代表活跃特征、提示词中的 token 嵌入、重建误差以及输出 logits。图中的边代表节点之间的线性影响,因此每个特征的激活等于其输入边的总和(直到其激活阈值为止)。
- 特征之间的线性归因:在特定输入下,特征之间的直接交互为线性关系。这使得归因操作有清晰且有理论依据的定义。关键在于冻结了注意力模式和归一化分母,并使用transcoders来实现线性。特征之间也存在由其他特征介导的间接交互,对应于多步路径。
- 剪枝(Pruning):尽管特征稀疏,在一个给定prompt下,仍然会有过多的活跃特征,导致归因图难以解释。为了控制这一复杂度,通过识别在特定 token 位置上对模型输出贡献最大的节点和边,对图进行剪枝,生成稀疏、可解释的模型计算图。
- 验证(Validation):研究路径的方式是间接的——替代模型可能与原始模型使用了不同的机制。因此,验证在归因图中发现的机制就显得尤为重要。使用扰动实验进行验证,具体而言,测量在某一特征方向上施加扰动是否会引起其他特征激活(及模型输出)中的变化,并检查这些变化是否与归因图中的预测一致。
- 全局权重(Global Weights):尽管本文主要聚焦于研究单个提示词的归因图,但我们的方法同样可以直接研究替代模型中的权重(即“全局权重”),从而揭示适用于多个提示词的机制。
2 Building an Interpretable Replacement Model
2.1 Architecture
![![[Pasted image 20250602222848.png]]](https://i-blog.csdnimg.cn/direct/6eac5f1c27b94a3983389991190ce53f.png)
图1:CLT构成了替代模型的核心架构。
CLT由若干神经元(“特征”)构成,这些特征被划分为与原始模型相同数量的 L L L层。该模型的目标是利用稀疏激活的特征来重建原始模型中 MLP 的输出。每个特征从其所在层的残差流(residual stream)中接收输入,但其“跨层”特性在于它可以向所有后续层提供输出。具体而言:
- 第 ℓ \ell ℓ层中的每个特征通过一个线性编码器加上非线性激活,从该层的残差流中“读取”输入。
- 第 ℓ \ell ℓ层的一个特征会参与重建第 ℓ , ℓ + 1 , … , L \ell, \ell+1, \dots, L ℓ,ℓ+1,…,L层的 MLP 输出,对每一个输出层使用一组独立的线性解码器权重。
- 所有层中的所有特征是联合训练的。因此,某一层 ℓ ′ \ell' ℓ′的 MLP 输出是由所有前层的特征共同重建的。
运行一个跨层转码器时,令 x ℓ x^\ell xℓ表示原始模型在第 ℓ \ell ℓ层的残差流激活值,第 ℓ \ell ℓ层的 CLT 特征激活值 a ℓ a^\ell aℓ通过如下方式计算:
a ℓ = JumpReLU ( W enc ℓ x ℓ ) a^\ell=\text{JumpReLU}(W_\text{enc}^\ell x^\ell) aℓ=JumpReLU(Wencℓxℓ)
其中, W enc ℓ W_\text{enc}^\ell Wencℓ是CLT在第 ℓ \ell ℓ层的编码矩阵。
令 y ℓ y^\ell yℓ表示原始模型在第 ℓ \ell ℓ层的 MLP 输出,CLT 对其的重建结果记作 y ^ ℓ \hat{y}^\ell y^ℓ,使用 JumpReLU 激活函数进行计算:
y ^ ℓ = ∑ ℓ ′ = 1 ℓ W dec ℓ ′ → ℓ a ℓ ′ \hat{y}^\ell=\sum_{\ell'=1}^\ell W_\text{dec}^{\ell'\rightarrow \ell} a^{\ell'} y^ℓ=ℓ′=1∑ℓWdecℓ′→ℓaℓ′
其中 W dec ℓ ′ → ℓ W_\text{dec}^{\ell'\rightarrow \ell} Wdecℓ′→ℓ是从第 ℓ ′ \ell' ℓ′层的特征输出到第 ℓ \ell ℓ层的CLT解码器矩阵。
为了训练CLT,最小化两个损失的和。第一个是重建误差损失(reconstruction error loss),在各层上求和:
L MSE = ∑ ℓ = 1 L ∥ y ^ ℓ − y ℓ ∥ 2 L_\text{MSE}=\sum_{\ell=1}^L\|\hat{y}_\ell-y_\ell\|^2 LMSE=ℓ=1∑L∥y^ℓ−yℓ∥2
第二个是稀疏性惩罚项(整体系数为超参数 λ \lambda λ,另一个超参数为 c c c)。在所有层上求和:
L sparsity = λ ∑ ℓ = 1 L ∑ i = 1 N tanh ( c ⋅ ∥ W ℓ dec , i ∥ ⋅ a ℓ i ) L_\text{sparsity}=\lambda\sum_{\ell=1}^L\sum_{i=1}^N\tanh(c\cdot\|W_\ell^{\text{dec},i}\|\cdot a_\ell^i) Lsparsity=λℓ=1∑Li=1∑Ntanh(c⋅∥Wℓdec,i∥⋅aℓi)
其中 N N N是每层的特征数量, W ℓ dec , i W_\ell^{\text{dec},i} Wℓdec,i表示第 i i i个特征的所有解码向量的拼接。
我们在一个小型的18层 Transformer 模型(称为 “18L”)和 Claude 3.5 Haiku 模型上训练了不同规模的 CLT。18L 的特征总数在 30 万到 1000 万之间,Haiku 的特征总数则在 30 万到 3000 万之间。
2.2 From Cross-Layer Transcoder to Replacement Model
在拥有一个已训练好的CLT之后,可以定义一个“替代模型”,用CLT的特征来替代原始模型中的 MLP 神经元。这个替代模型的前向传播过程与原始模型基本相同,只有两个修改之处:
- 当执行到第 ℓ \ell ℓ层的 MLP 输入时,我们计算编码器位于第 ℓ \ell ℓ层的跨层转码器特征的激活;
- 当执行到第 ℓ \ell ℓ层的 MLP 输出时,我们用来自当前层及之前各层的跨层转码器特征的解码输出总和,覆盖掉原始的 MLP 输出。
注意力层(Attention layers)依旧按照原样执行,未做任何冻结或修改。尽管CLT 仅使用原始模型的输入激活进行训练,但在运行替代模型时,CLT 实际上是在处理来自替代模型自身的中间激活,也就是“分布外”(off-distribution)的输入激活。
![![[Pasted image 20250603002241.png]]](https://i-blog.csdnimg.cn/direct/25d1db0ce9c04accbaebfc7328f60158.png)
图2:替代模型是通过将原始模型的神经元替换为CLT中稀疏激活的特征而得到的。
我们衡量替代模型输出的最可能 token 是否与原始模型一致的完成比例。该比例随着模型规模的增加而提高,并且CLT的表现优于逐层transcoder的baseline(即每一层都有一个独立训练的标准单层转码器;所示的特征数量表示的是所有层的总特征数)。
还与一个baseline进行了对比:对神经元设置阈值,将低于该阈值的神经元置零(经验上我们发现,激活值越高的神经元越容易解释)。
最大的 18 层 CLT 在一个多样化的预训练风格提示词数据集中(见 §R 附加评估细节)对下一个 token 的预测,与原始模型一致的比例达到了 50%。
![![[Pasted image 20250603002621.png]]](https://i-blog.csdnimg.cn/direct/af8c72cda2ca44248a03f63e102da714.png)
图3:CLT、逐层transcoder和设定阈值的神经元在作为替代模型基础时的top-1准确率和KL散度对比。可解释性阈值通过排序与对比评估确定(见评估部分)。
2.3 The Local Replacement Model
替代模型与原始模型存在显著差距,且重建误差可能在各层之间累积。
最终目标是理解原始模型,因此希望尽可能准确地对其进行近似。为此,在研究一个固定的prompt p p p时,我们构建一个局部替代模型(local replacement model),该模型:
- 替换 MLP 层为 CLT(与替代模型相同);
- 使用原始模型在提示词 p p p上前向传播所得到的注意力模式和归一化分母;
- 在每个(token位置,层)对上对CLT输出加入一个误差调整项,该误差等于 CLT 对 p p p 的输出与真实 MLP 输出之间的差值。
进行误差调整并冻结注意力与归一化非线性之后,等效地用不同的基本单元“重写”原始模型在提示词 p p p上的计算;经过误差修正的替代模型的所有激活值和 logit 输出与原始模型完全一致。
然而,这不意味着局部替代模型和原始模型使用了相同的机制,可以通过比较模型对扰动的响应差异来衡量其机制差异;
将扰动行为的一致程度称为“机制忠实度”(mechanistic faithfulness)。
局部替代模型可以被看作一个非常大的全连接神经网络,跨越多个 token,可以在其上进行经典的路径分析:
- 输入是prompt中每个 token 的 one-hot 向量拼接而成;
- 神经元是所有 token 位置上激活的 CLT 特征的集合;
- 权重是从一个特征到另一个特征之间所有线性路径的加和,包括通过残差流和注意力路径,但不包括 MLP 或 CLT 层。由于注意力模式和归一化分母被冻结,从源特征的激活对目标特征的预激活的影响是线性的。有时称这些为“虚拟权重”,因为它们并未在原始模型中显式存在;
- 此外,该模型还包含类似偏置的节点,对应误差项,并从每个偏置连接到模型中每个下游神经元;
- 局部替代模型中唯一的非线性操作是作用于特征预激活的函数。
局部替代模型是我们归因图(attribution graphs)的基础,在这些图中研究 CLT 特征之间在特定提示词下的相互作用。这些图是本文的主要研究对象。
![![[Pasted image 20250603010304.png]]](https://i-blog.csdnimg.cn/direct/0ed0c6a939384b7ea4317edf43391a94.png)
图4:局部替代模型是在替代模型的基础上,加入误差项和固定的注意力模式,从而在特定提示词上精确复现原始模型行为而得到的。
3 Attribution Graphs
本届将在一个案例研究中介绍构建归因图的方法,该案例探讨模型为任意标题生成缩略词的能力。在研究的示例中,模型成功生成了一个虚构的缩略词。
具体来说,给模型的提示是:The National Digital Analytics Group (N,并采样其补全为:DAG。
模型使用的分词器包含一个特殊的“大写锁定”符号,因此该提示和补全被分词为:The National Digital Analytics Group ( ⇪ n dag。
通过构建归因图来解释模型如何计算并输出 “DAG” 这个 token,归因图展示了信息如何从提示词流向中间特征,最终到达输出结果。
下图展示了完整归因图的简化示意图。图中底部是提示词,顶部是模型生成的补全。方框代表一组相似的特征,悬停可以查看每个特征的可视化表示。
箭头表示某组特征或 token 对其他特征及输出 logit 的直接影响。
![![[Pasted image 20250603012023.png]]](https://i-blog.csdnimg.cn/direct/7635460defa747258e414fa6abe429ce.png)
图5:18层模型生成虚构缩略词的归因图简化示意图。
3.1 Constructing an Attribution Graph for a Prompt
为了理解局部替代模型所执行的计算过程,构建一个因果图,描述它在特定提示词上执行的一系列计算步骤。图包含四类节点:
- 输出节点:对应候选输出词元。我们仅为那些累计概率质量达到 95% 的词元构建输出节点,最多保留 10 个。
- 中间节点:对应在每个提示词位置处被激活的CLT特征。
- 主输入节点:对应提示词词元的嵌入向量。
- 附加输入节点(“误差节点”):对应底层模型中每个 MLP 输出中未被 CLT 解释的部分。
图中的边表示局部替代模型中的直接线性归因。边从特征节点、嵌入节点或误差节点出发,终止于特征节点或输出节点。
给定一个源特征节点 s s s和一个目标特征节点 t t t,它们之间的边权定义为:
A s → t = a s w s → t A_{s\rightarrow t}=a_sw_{s\rightarrow t} As→t=asws→t
其中 w s → t w_{s\rightarrow t} ws→t是虚拟权重, a s a_s as是源特征的激活值。
在底层模型中, w s → t w_{s \rightarrow t} ws→t是连接源特征的解码向量到目标特征的编码向量之间的所有线性路径(例如通过注意力头的输出向量和残差连接)的总和。
现在说明如何在实践中使用反向 Jacobian 高效地计算这些边权重。
设 s s s是处于第 ℓ s \ell_s ℓs层、上下文位置为 c s c_s cs的源特征,令 t t t为处于 ℓ t \ell_t ℓt层、上下文位置为 c t c_t ct的目标特征。记 J c s , ℓ s → c t , ℓ t ▼ J_{c_s,\ell_s\rightarrow c_t,\ell_t}^\blacktriangledown Jcs,ℓs→ct,ℓt▼为底层模型的Jacobian,在对目标提示进行反向传播时,对所有非线性部分(MLP 输出、注意力模式、归一化分母)施加 stop-gradient 操作,从 ℓ t \ell_t ℓt层的 c t c_t ct位置的残差流回传至 ℓ s \ell_s ℓs层的 c s c_s cs位置的残差流。
从 s s s到 t t t的边权为:
A s → t = a s w s → t = a s ∑ ℓ s ≤ ℓ < ℓ t ( W dec , s ℓ s → ℓ ) ⊤ J c s , ℓ s → c t , ℓ t ▼ W enc , t ℓ t A_{s\rightarrow t}=a_sw_{s\rightarrow t}=a_s\sum_{\ell_s\leq\ell<\ell_t}(W_{\text{dec},s}^{\ell_s\rightarrow\ell})^\top J_{c_s,\ell_s\rightarrow c_t,\ell_t}^\blacktriangledown W_{\text{enc},t}^{\ell_t} As→t=asws→t=asℓs≤ℓ<ℓt∑(Wdec,sℓs→ℓ)⊤Jcs,ℓs→ct,ℓt▼Wenc,tℓt
其中:
- W dec , s ℓ s → ℓ W_{\text{dec},s}^{\ell_s\rightarrow\ell} Wdec,sℓs→ℓ是特征 s s s在写入第 ℓ \ell ℓ层时的decoder向量;
- W enc , t ℓ t W_{\text{enc},t}^{\ell_t} Wenc,tℓt是特征 t t t在第 ℓ t \ell_t ℓt层的encoder向量。
对于其他类型的边,计算公式类似。如嵌入-特征的边权为 w s → t = Emb s ⊤ J c s , ℓ s → c t , ℓ t ▼ W enc , t ℓ t w_{s\rightarrow t}=\text{Emb}_s^\top J_{c_s,\ell_s\rightarrow c_t,\ell_t}^\blacktriangledown W_{\text{enc},t}^{\ell_t} ws→t=Embs⊤Jcs,ℓs→ct,ℓt▼Wenc,tℓt。注意:误差节点没有入边。
由于上述计算中对所有非线性模块都施加了stop-gradient,任意特征节点 t t t的预激活值 h t h_t ht可以通过其所有入边直接线性求和得到: h t = ∑ S t w w → t h_t=\sum_{\mathcal{S}_t} w_{w\rightarrow t} ht=∑Stww→t,其中 S t \mathcal{S}_t St是所有出现在更早层或更早上下文位置的节点集合。因此,归因图的边构成了每个特征激活的线性分解。
请注意,这些图中不包含节点通过影响注意力模式对其他节点产生影响的信息,但包含通过冻结的注意力输出在节点之间传播的影响信息。换句话说,考虑了信息从一个 token 位置流向另一个位置的过程,但不考虑模型为何移动这些信息。
另请注意,跨层特征节点的出边会聚合它在所有写入层上对下游特征的解码影响。
虽然替代模型中的特征是稀疏激活的(每个 token 位置大约有一百个激活特征),但归因图仍然过于庞大,难以完整可视化,特别是在提示长度增加时 —— 即使是较短的提示,其边的数量也可能达到百万级。幸运的是,一个小的子图通常就能解释大部分从输入到输出的重要路径。
为了识别这样的子图,我们应用了一种剪枝算法,旨在保留那些直接或间接对 logit 节点产生显著影响的节点和边。
在默认参数下,通常能将节点数减少到原来的十分之一,同时仅减少约 20% 的可解释行为。
3.4 Grouping Features into Supernodes
归因图中常常包含一组特征,它们共享与提示词相关的某个方面。例如,在我们的提示词中,“Digital”一词上有三个活跃的特征,它们分别对“digital”这个词在不同大小写和上下文中作出响应。对于这个提示词而言,唯一重要的方面是这个词以字母 “D” 开头;这三个特征都对同一组下游节点有正向影响。因此,在分析这个提示词时,将这些特征归为一组并作为一个整体来看是有意义的。
在可视化和分析过程中,发现将多个节点(即特征与上下文位置的组合)合并为一个“超级节点”更为方便。这些超级节点对应于我们上方展示的简化示意图中的方框,为方便起见,下方也再次展示了该图。
![![[Pasted image 20250603025145.png]]](https://i-blog.csdnimg.cn/direct/9e77b350c88b43f6b2e28f9cbcd14c8d.png)
图8:一个简化的归因图示例,展示了18层模型在补全一个虚构缩略词时的归因过程。
用于对节点进行分组的策略取决于具体的分析任务,以及特征在给定提示中的作用。根据我们对机制的解释重点不同,有时会将激活于相似上下文的特征、具有相似嵌入或logit影响的特征,或具有相似输入/输出边的特征归为一组。
通常希望超级节点中的各个节点彼此之间是促进关系,且它们对下游节点的影响具有相同的符号。虽然尝试过一些自动化策略,例如基于解码器向量或图的邻接矩阵进行聚类,但没有一种自动方法能够涵盖说明某些机制性结论所需的各种特征分组。因此采用人工方式构建这些分组。
3.5 Validating Attribution Graph Hypotheses with Interventions
在归因图中,节点表示哪些特征对模型输出具有重要作用,而边则表示这些特征是如何发挥作用的。可以通过对底层模型中的特征进行扰动,并检查其对下游特征或模型输出的影响是否与归因图中的预测一致,从而验证归因图中的结论。对特征的干预可以通过修改其计算得到的激活值,并用修改后的解码结果替代原始重构来实现。
CLT中的特征会写入多个输出层,因此需要决定在哪些层中执行干预。该如何选择这个层的范围?可以像处理单层transcoder那样,只在一个层上对特征的解码结果进行干预,但归因图中的边代表的是多个层的解码累积效果,因此只在单层干预只能覆盖某条边的一个子集。此外,通常希望同时干预多个特征,而超级节点中的不同特征会在不同的层中被解码。
为了在层范围内执行干预,我们会在给定范围内的每一层上修改目标特征的解码结果,然后从该范围的最后一层开始进行前向传播。由于不会根据范围中更早干预的结果重新计算某一层的MLP输出,因此模型MLP输出中唯一的变化就是我们的干预。
将这种方法称为“受限补丁(constrained patching)”,因为它不允许干预在补丁范围内产生二阶效应。
下图展示了“受限补丁”的一种乘法版本,其中我们在层范围 [ ℓ − 1 , ℓ ] [\ell-1,\ell] [ℓ−1,ℓ]中将目标特征的激活乘以 M M M。需要注意的是,更后续层的 MLP 输出不会被这个补丁直接影响。
![![[Pasted image 20250603030118.png]]](https://i-blog.csdnimg.cn/direct/5e826c184152479bb3f39460cad7a708.png)
图9:乘法补丁的示意图。
归因图是基于底层模型的注意力模式构建的,因此图中的边不考虑通过 QK 回路传递的影响。
同样地,在扰动实验中,将注意力模式固定为未经扰动的前向传播中观察到的值。这一方法选择意味着我们的结果不包括扰动可能对注意力模式本身造成的影响。
回到我们构造的首字母缩略词提示词上,我们展示了对超级节点进行补丁处理的结果,首先是抑制“Group”超级节点。下图中,将补丁效果叠加在超级节点示意图上,以提高清晰度,显示其对其他超级节点和 logit 分布的影响。请注意,在该图中,节点的位置除非特别标注,否则不代表对应的 token 位置。
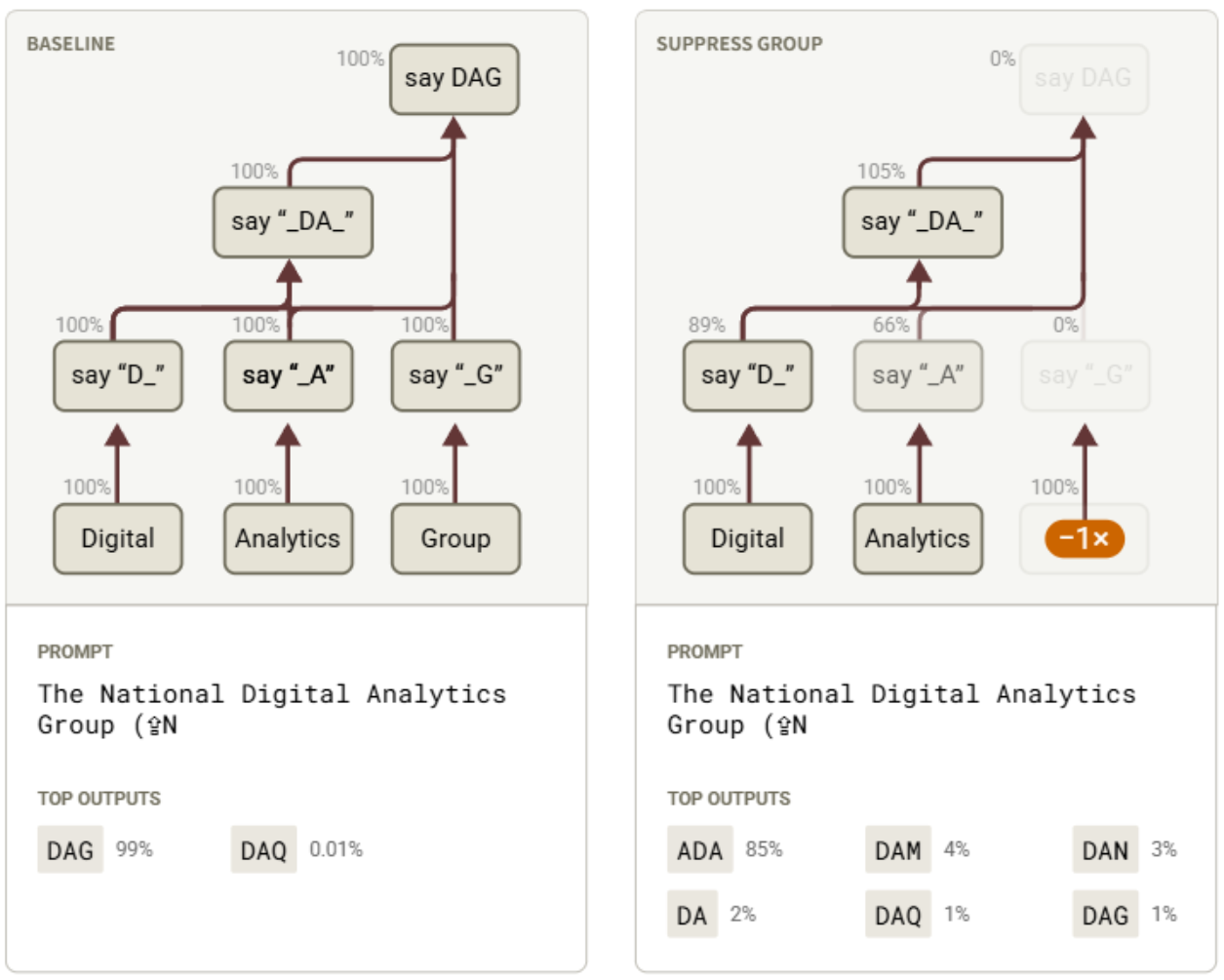
图10:抑制虚构组织名称中的单词 “Group” 会导致 18L 输出其他包含 “DA” 的缩略词。
3.6 Localizing Important Layers
归因图还能够识别出某一特征的解码在哪些层级上对最终 logit 的下游影响最大。例如,“Analytics”(分析)超级节点中的特征,主要是通过中间特征群组间接影响 “dag” 的 logit,这些中间特征群组包括 “say A”、“say DA” 和 “say DAG”,它们主要分布在第 13 层及之后的层级中。
这一现象表明,特征的影响并非仅由其直接解码位置决定,而是在网络深层通过特征联动与组合,在语义构建上形成更复杂的协同效应。这也是理解跨层特征行为和层级解码依赖关系的关键所在。
因此,预计对“Analytics”特征进行负向引导时,对“dag” logit 的影响将在第13层之前达到平台期,然后随着接近最后一层而减弱。
影响减弱的原因在于干预方式的约束性。如果补丁范围涵盖了所有“say an acronym”特征,由于约束性补丁不允许产生连锁反应,其激活状态将不会改变。
下图展示了对每个“Analytics”特征进行引导时的效果,起始层固定为1,补丁结束层逐层变化。
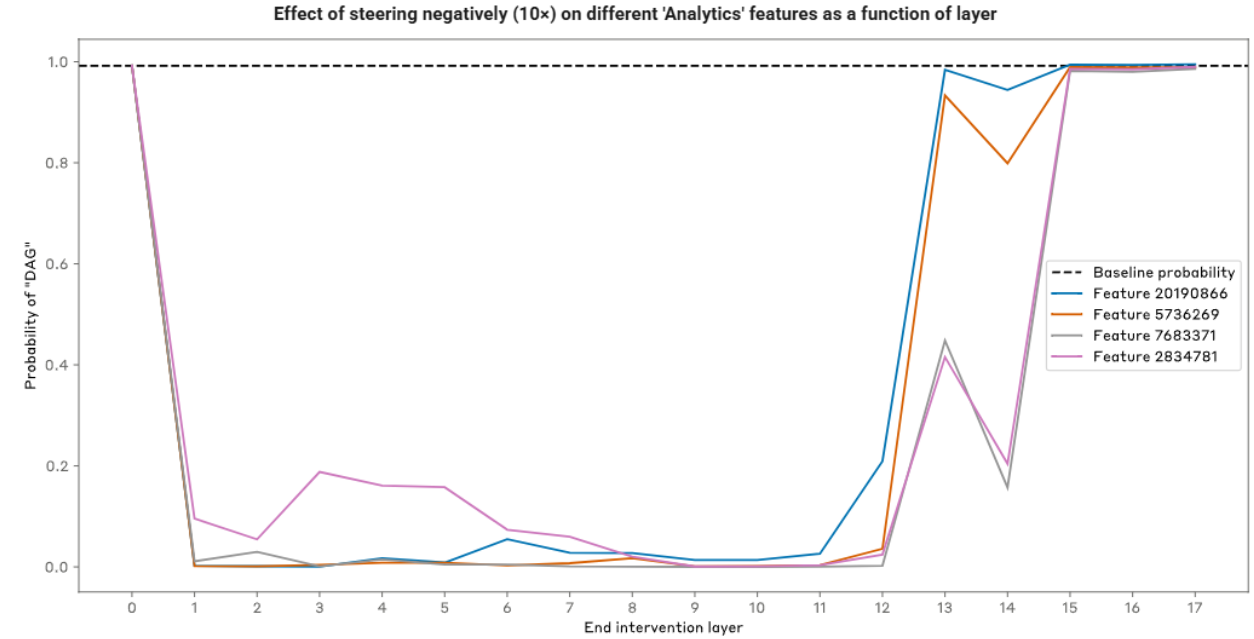
图12:干预在包含“say an acronym”特征的层之前进行时效果最佳。
4 Global Weights
构建的归因图展示了特征如何在特定提示下相互作用以产生模型的输出,但我们也对特征在所有上下文中如何相互作用的更全局图景感兴趣。
在经典的多层感知机中,全局交互由模型的权重提供:如果神经元位于连续层之间,一个神经元对另一个神经元的直接影响就是它们之间的权重;如果神经元相距较远,一个神经元对另一个神经元的影响则通过中间层传递。
在本文设置中,特征之间的交互既包含上下文无关的成分,也包含上下文相关的成分。理想情况下,希望同时捕捉这两者:希望获得一组上下文无关的全局权重,同时也能反映网络在所有可能上下文中的行为。
本节分析上下文无关的成分(一种“虚拟权重”)、它们存在的问题(存在无因果分布效应的大量“干扰”项),以及一种利用共激活统计来处理干扰的方法。
在一个特定的提示上,一个源 CLT 特征(记作 s)通过三种路径影响一个目标特征(记作 t):
- 残差-直接路径(residual-direct):
s的解码器将信息写入残差流,随后被t的编码器在后续层中读取。 - 注意力-直接路径(attention-direct):
s的解码器将信息写入残差流,这些信息通过若干注意力头的 OV 步传递,最终被t的编码器读取。 - 间接路径(indirect):
从s到t的路径由其他 CLT 特征进行中介。
注意到,残差-直接路径的影响可以简化为:该提示上第一个特征的激活值乘以一个在不同输入之间保持一致的虚拟权重。 这些虚拟权重因其一致性关系而构成了一种简单形式的全局权重。
对于 CLT 特征,两个特征之间的虚拟权重是下游特征的编码器与两者之间所有解码器之和的内积。
不过,虚拟权重存在一个主要问题:干扰(interference)。
由于很多的特征都通过残差流进行交互,它们之间都会有连接,哪怕某些特征在真实分布中从未同时激活,也可能存在(甚至很大的)虚拟权重。
当这种情况发生时,这些虚拟权重就不再适合作为全局权重,因为这些连接并不实际影响网络的行为。
通过下面的例子看到干扰的作用:
选取一个第18层中的 “Say a game name” 特征,并画出它与其他特征之间按虚拟权重绝对值排序的最大连接。
绿色条表示正向连接,紫色条表示负向连接。 其中许多连接最强的特征难以解释,或与该概念并无明显关系。
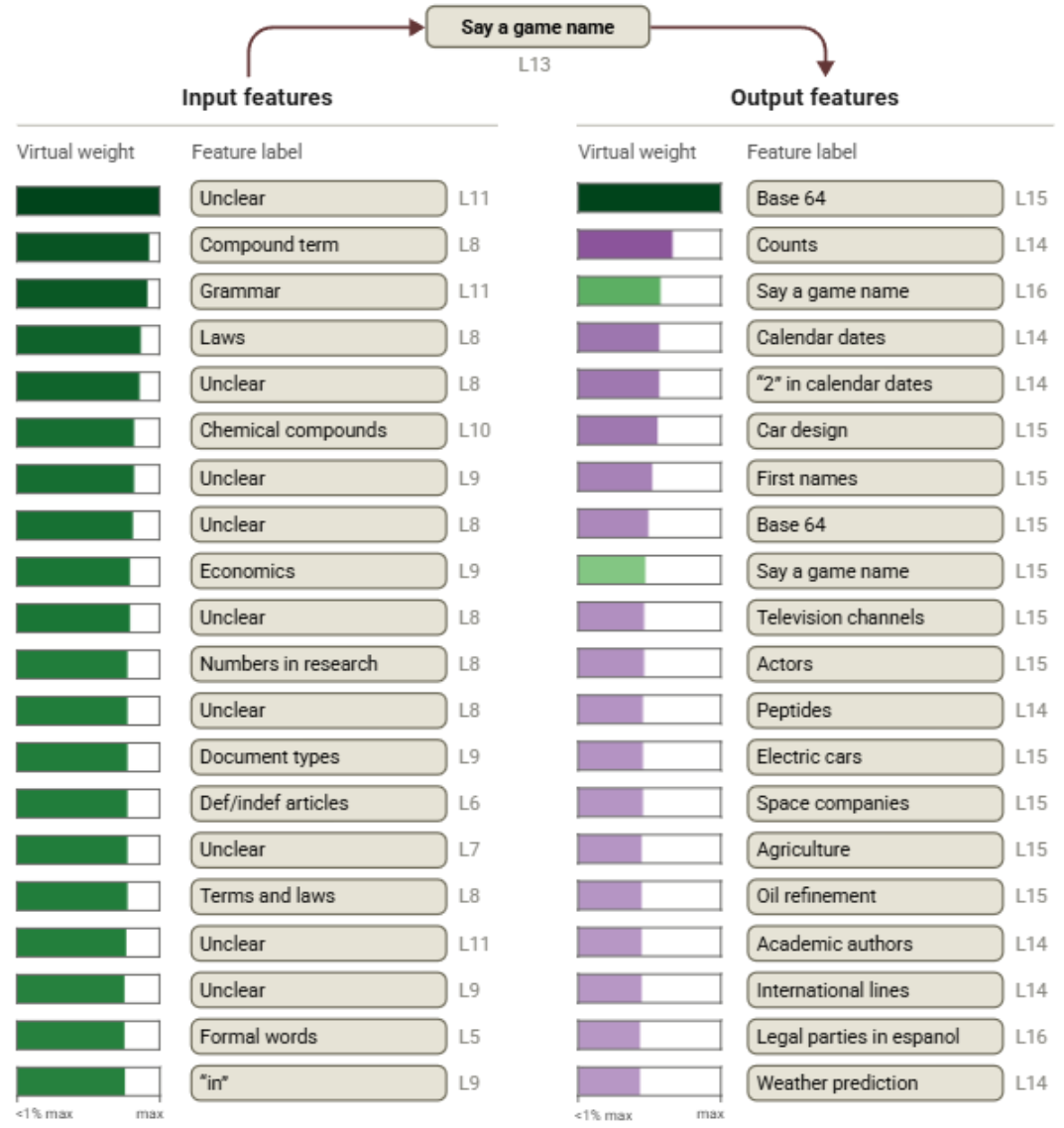
图20:一个第18层特征的虚拟权重按绝对值排序的最大值示意图。绿色条表示正向连接,紫色条表示负向连接。许多大的连接关系难以解释。
看上去CLT 没有捕捉到可解释连接的一个迹象。然而,通过尝试从这些权重中去除干扰,仍然可以发现许多具有可解释性的连接。
这个问题有两个基本的解决方案。一种是将研究的特征集限制在一个较小的领域内的活跃特征。另一种是引入关于特征之间在数据分布上共激活的信息。
例如,设 a i a_i ai是特征 i i i的激活值。可以通过如下方式将虚拟权重与激活值相乘,计算一个期望的残差归因值:
V i j ERA = E [ 1 ( a j > 0 ) V i j a i ] = E [ 1 ( a j > 0 ) a i ] V i j V_{ij}^\text{ERA}=\mathbb{E}[\mathbb{1}(a_j>0)V_{ij}a_i]=\mathbb{E}[\mathbb{1}(a_j>0)a_i]V_{ij} VijERA=E[1(aj>0)Vijai]=E[1(aj>0)ai]Vij
这是分析的所有prompt中,一个残差直接路径的平均强度。这类似于在多个 token 的上下文位置中,对所有归因图求平均。
由于小的特征激活值通常具有多义性,改为使用目标激活值对归因值加权:
V i j TWERA = E [ a j a i ] E [ a j ] V i j V_{ij}^\text{TWERA}=\frac{\mathbb{E}[a_ja_i]}{\mathbb{E}[a_j]}V_{ij} VijTWERA=E[aj]E[ajai]Vij
将这种权重称为目标加权期望残差归因(TWERA)。如公式所示,这两种归因值都可以通过将原始虚拟权重乘以(在分布上的)激活统计量来计算。
这次按照 TWERA 对连接进行排序。同时绘制了每个连接的“原始”虚拟权重用于对比。
可以看出,许多连接变得更具可解释性,这表明虚拟权重中提取出了有用的信号,只是需要去除干扰才能看到它们。
之前虚拟权重图中最容易解释的特征(例如另一个“说一个游戏名称”特征和“极限飞盘”特征)仍然被保留,而许多不相关的概念被过滤掉了。
![![[Pasted image 20250603042015.png]]](https://i-blog.csdnimg.cn/direct/01a40a0eaf09401e9407a953a4243fc2.png)
图21:相同示例特征的最大 TWERA 值。
TWERA 并不是解决干扰问题的完美方案。将 TWERA 值与原始虚拟权重进行比较可以发现,许多极小的虚拟权重却具有很高的 TWERA 值。这表明 TWERA 严重依赖于共激活统计数据,并且在决定哪些连接重要时会发生显著变化,而不仅仅是去除较大的干扰权重。TWERA 也不擅长处理抑制效应(这在归因方法中是普遍问题)。
5 Evaluations
本节对转码器特征及由其派生出的归因图进行了定性和定量评估,重点关注可解释性和充分性。
我们的方法会生成模型在特定提示词下机制的因果图描述。如何量化这些描述在多大程度上真实反映了模型的运作?这个问题难以简化为一个单一指标,因为其中涉及多个因素:
可解释性。对单个特征“代表什么”的理解程度如何?
在下文中尝试通过几种方式对可解释性进行量化;实际中,仍然大量依赖主观评价。此外,将特征分组为“超级节点”的一致性同样值得评估。在本文中我们并未尝试量化这一点,而是留给读者自行判断我们的分组是否合理且可解释。
还指出,在归因图的语境中,图结构本身的可解释性与单个特征的可解释性同等重要。为此,我们量化了图简洁性的一个指标:平均路径长度。
充分性。(经过剪枝的)归因图在多大程度上足以解释模型的行为?
尝试通过几种方式来量化这一点。最直接的评估方式是我们在第 2.2 节“从CLT到替代模型”中讨论的:衡量替代模型的输出与原始模型的匹配程度。这是一种“严格”的评估方式,因为计算图中任一位置的错误都可能严重影响整体性能。
还在下文中引入了几种“宽松”的充分性指标,用于衡量归因图中错误节点的占比。需要注意的是,在许多情况下,展示的是经过剪枝的归因图的子图示意图,用于呈现我们认为最值得注意的部分。我们有意不对这些子图的充分性进行评估,因为它们往往故意省略了一些“无趣但必要”的部分(例如,在加法类提示中表示“这是一个数学问题”的特征)。。
机制忠实性。识别出的机制在多大程度上是模型实际使用的?
为此进行了干扰实验(例如抑制激活特征),并测量实验结果是否与本地替代模型(即归因图所描述的对象)预测的结果一致。
在下文中尝试对此进行定量分析,并在具体案例研究中验证忠实性,特别关注我们认为有趣或重要的机制的忠实性。
需要说明的是,机制忠实性与“路径组件是否是模型计算所必需的”这一概念密切相关。但“必需性”这一概念往往过于狭隘——即使某些机制不是模型输出的严格“必需部分”,它们仍可能值得识别,尤其是在多个机制并行协作共同完成某一计算的情况下。
本文所采用的许多具体评估方法在以往研究中并未出现。这部分是因为我们的方法较为独特,聚焦于单个提示词下的归因图,而不是识别支撑整个任务表现的路径结构。未来研究的重要方向是开发更好的自动化方法,来评估整个归因流程(特征、超级节点、图)的可解释性、充分性和忠实性。