线性模型 - 二分类问题的损失函数
在二分类问题中,损失函数用于量化模型预测与真实标签之间的差异,以指导模型参数的调整。本文,我们来一起学习一下常见的损失函数及其直观解释。
一、核心二分类损失函数及通俗理解
1. 0-1损失(Zero-One Loss)
公式:
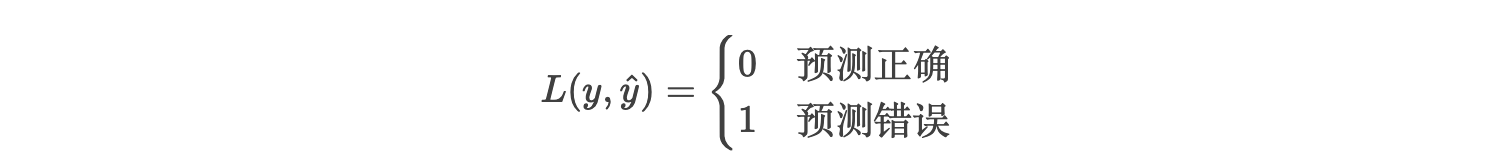
通俗理解:
-
类似“非黑即白”的评分:答对得0分,答错得1分。
示例: -
预测明天是否下雨(1=下雨,0=不下雨):
-
真实标签:下雨(1),预测结果:下雨(1) → 损失=0
-
真实标签:不下雨(0),预测结果:下雨(1) → 损失=1
-
缺点:
-
无法反映预测的“可信度”(例如预测概率0.51和0.99都算正确,但置信度不同)。
-
不可导,无法直接用于梯度下降优化。
2. 对数损失(Log Loss,交叉熵损失)
(1)公式:
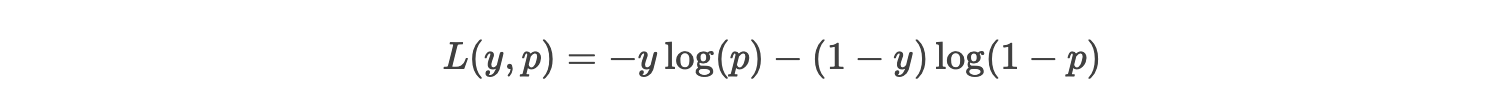
(2)通俗理解:
-
惩罚“预测概率与真实标签的偏离程度”:预测越错误,损失越大(指数级增长)。
-
例如:真实标签为1(正类),若预测概率p=0.9,损失较小;若p=0.1,损失极大。
(3)示例:
-
垃圾邮件分类(1=垃圾邮件,0=正常邮件):
-
真实标签:垃圾邮件(1),预测概率:0.8 → 损失= −log(0.8)≈0.223
-
真实标签:正常邮件(0),预测概率:0.3 → 损失= −log(1−0.3)≈0.357
-
(4)适用场景:
-
需要概率输出的模型(如逻辑回归、神经网络)。
(5)为了便于理解交叉熵损失,我们回顾一下对数函数:
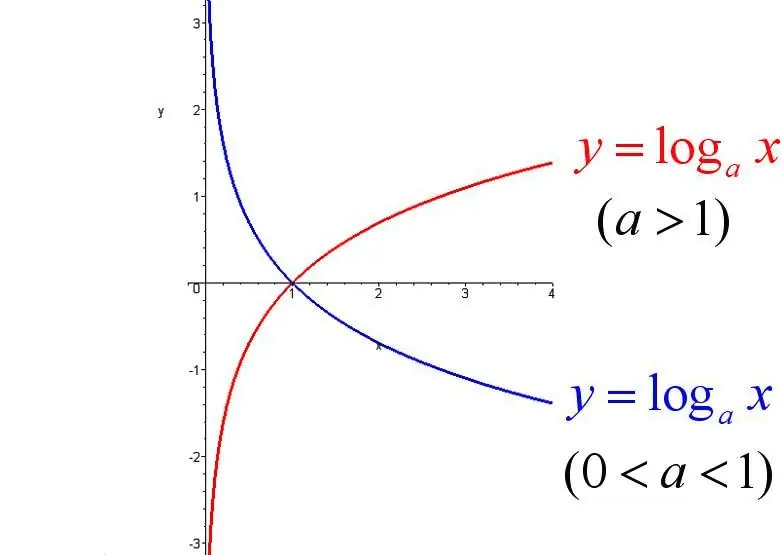
对于log(y^)来说,注意这里的底数指的是自然对数,底数为e,因此对应的是红色的曲线,前面有负号。关于x轴对称,因此最终对应的是蓝色的曲线。
 从曲线可以直观看出,当模型预测得y^越接近真实标签1,对应的损失就越小;相反,如果预测偏离真实标签很多,损失会急剧增加。(曲线更陡,指数级增加)
从曲线可以直观看出,当模型预测得y^越接近真实标签1,对应的损失就越小;相反,如果预测偏离真实标签很多,损失会急剧增加。(曲线更陡,指数级增加)
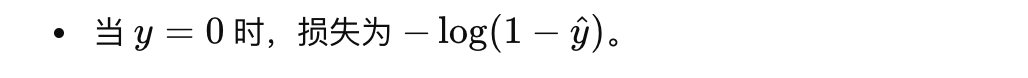
这时把(1-y^)看成整体,模型预测y^越接近0,对应的损失就越小;相反,如果预测偏离真实标签很多,损失会急剧增加。(曲线更陡,指数级增加)
(6)概率与信息论角度
二元交叉熵损失源自信息论中的交叉熵概念,用来衡量两个概率分布之间的距离。这里有两个分布:
- 真实分布:对于每个样本,真实的分布可以看作是一个“独热编码”(one-hot encoding),比如 y=1 时为 [1,0],y=0时为 [0,1]。
- 模型预测分布:模型输出的概率为 [y^, 1−y^]。
交叉熵度量的是用模型预测分布编码真实分布所需的信息量。如果模型预测与真实分布完全一致,交叉熵损失最小;如果有偏差,则需要更多的信息来“纠正”,损失增大。
3. Hinge损失(Hinge Loss,SVM专用)
公式:
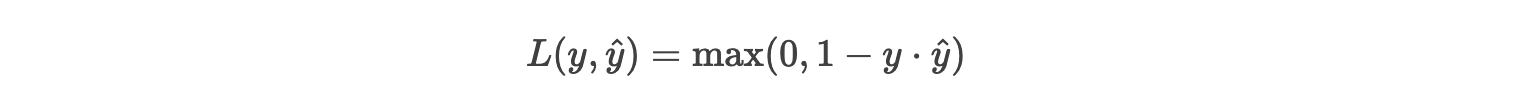
(其中y^为模型输出的未归一化分数,如SVM的决策函数值)
通俗理解:
-
要求预测分数与真实标签“方向一致且间隔足够大”:
-
若预测正确且置信度高(间隔≥1),损失为0;
-
若预测正确但置信度低(间隔<1),损失为1−yy^;
-
若预测错误,损失随错误程度线性增长。
-
示例:
-
电影评分预测(1=好评,-1=差评):
-
真实标签:好评(1),模型输出分数:2 → 损失= max(0,1−1⋅2)=0
-
真实标签:差评(-1),模型输出分数:0.5 → 损失= max(0,1−(−1)⋅0.5)=1.5
-
适用场景:
-
支持向量机(SVM),追求最大间隔的分类边界。
这里我们生活化的理解一下:
-
类似“考试及格线不仅要过,还要超过一定分数才算安全”。
-
例如:驾照考试要求得分≥90分(而非刚好60分),确保驾驶员技能足够可靠。
如何理解Hinge损失的公式?


4. 指数损失(Exponential Loss,AdaBoost专用)
公式:
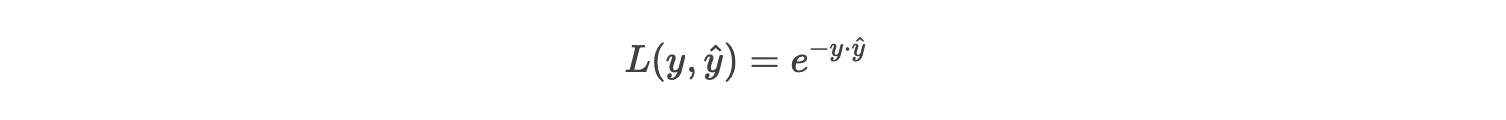
(y^为模型输出的未归一化分数)
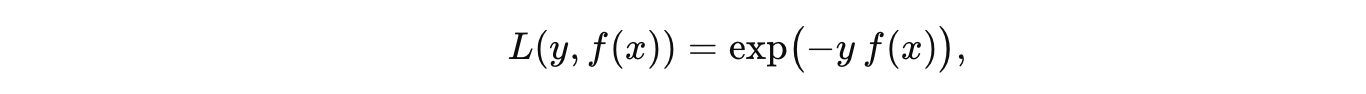
其中:
- y是真实标签,通常取值为 ±1(例如,正类为 +1,负类为 -1);
- f(x) 是模型对输入 x 给出的预测分数(或者称为决策函数值)。
通俗理解:
-
对错误预测的样本施加指数级惩罚,迫使模型重点关注难分样本。
示例:
-
疾病诊断(1=患病,-1=健康):

适用场景:
-
AdaBoost等集成学习算法。
同样,生活化的理解一下:
-
类似“老师反复讲解大多数学生做错的题”。
-
例如:班级第一次测验后,老师发现第5题错误率最高,于是后续课程中反复强化此题,直到学生掌握。
如何理解指数损失的公式?

二、为了更好的理解上面提到的交叉熵损失,我们还需要弄清楚独热编码、真实分布和模型预测分布的概念:
1、独热编码:
独热编码(One-Hot Encoding)是一种将类别数据转换为数值向量的常用技术。它的主要思想是为每个可能的类别创建一个二进制向量,该向量中只有一个位置为1(表示当前类别),而其它位置都为0。
直观理解
-
类别的表示:
假设你有一个类别变量“水果”,其可能取值为“苹果”、“香蕉”和“橘子”。
独热编码会为这三种水果分别生成一个向量:- 苹果:1,0,01, 0, 0
- 香蕉:0,1,00, 1, 0
- 橘子:0,0,10, 0, 1
这样,每个类别都有一个唯一的编码,且这些编码之间互不重叠。
-
为何需要独热编码:
机器学习模型通常只能处理数值输入,不能直接处理文字或符号数据。独热编码将类别信息转换为数值向量,使得模型可以利用这些信息进行学习。另外,这种编码避免了将类别转换成单一数值(如 1、2、3)可能引入的排序关系,从而保证不同类别之间没有隐含的大小比较。
应用示例
例子:邮件分类中的标签编码
假设我们有一个邮件分类问题,标签为“垃圾邮件”和“正常邮件”。
- 我们可以用独热编码表示:
- 垃圾邮件:[1, 0]
- 正常邮件:[0, 1]
例子:颜色特征
如果我们有一个颜色属性,可能的取值为红、绿、蓝,独热编码表示为:
- 红色:[1, 0, 0]
- 绿色:[0, 1, 0]
- 蓝色:[0, 0, 1]
通过这种方式,独热编码帮助我们把非数值型的类别特征转换成适合机器学习模型处理的数值型向量,同时避免错误地引入类别之间的顺序或大小关系。
独热编码是一种简单而有效的方法,将类别变量转化为二进制向量表示,使得每个类别都能以一种无序、互斥的方式呈现,便于后续的机器学习模型进行处理和学习。
2、真实分布和模型预测分布:
在监督学习中,“真实分布”指的是数据中真实的概率分布,即每个样本的真实标签对应的理想分布。例如,在二分类问题中,通常采用独热编码来表示真实标签:
- 如果一个样本的真实标签为1,那么真实分布可以表示为 [1,0];
- 如果真实标签为0,则表示为 [0,1]。
而“模型预测分布”则是机器学习模型在给定输入后输出的概率分布。例如,对于逻辑回归模型,给定一个输入 x,模型计算得到的正类概率为 y(介于0和1之间),那么模型预测分布就是 [y^, 1−y^]。
两者的联系与作用:
-
比较与优化目标:
在训练过程中,我们希望模型预测分布能够尽可能接近真实分布。损失函数(如交叉熵损失)就是用来衡量这两个分布之间的差距,进而指导模型参数的更新。换句话说,最优的模型应该使得模型预测分布与真实分布之间的“距离”最小,从而提高预测准确性。 -
最大似然估计:
当我们最大化数据在模型下的似然时,实际上是在努力让模型预测分布尽可能贴近真实分布。交叉熵损失的最小化与最大化似然等价,这为我们提供了训练模型的理论依据。
直观例子:
以垃圾邮件分类为例:
- 假设某封邮件真实标签为垃圾邮件,对应真实分布为 [1,0];
- 逻辑回归模型预测这封邮件为垃圾邮件的概率为 0.9,则模型预测分布为 [0.9,0.1];
- 交叉熵损失会计算真实分布和预测分布之间的差异,当预测分布与真实分布越接近时,损失越小,说明模型在这封邮件上的预测越准确。
通过这种方式,真实分布和模型预测分布之间的比较构成了训练过程中优化的核心目标。
三、二分类问题的损失函数的对比总结:
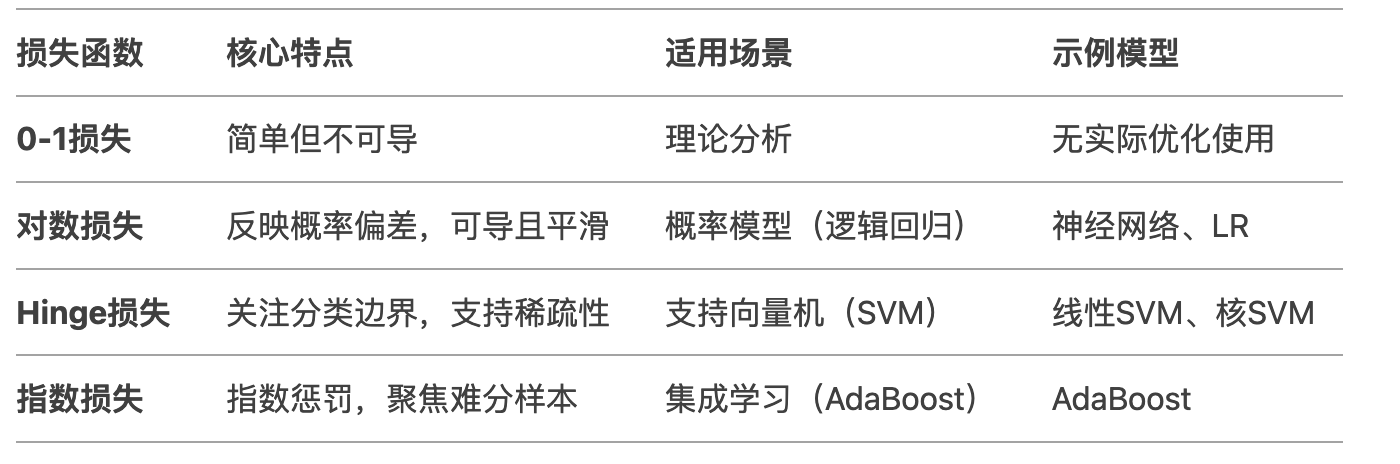
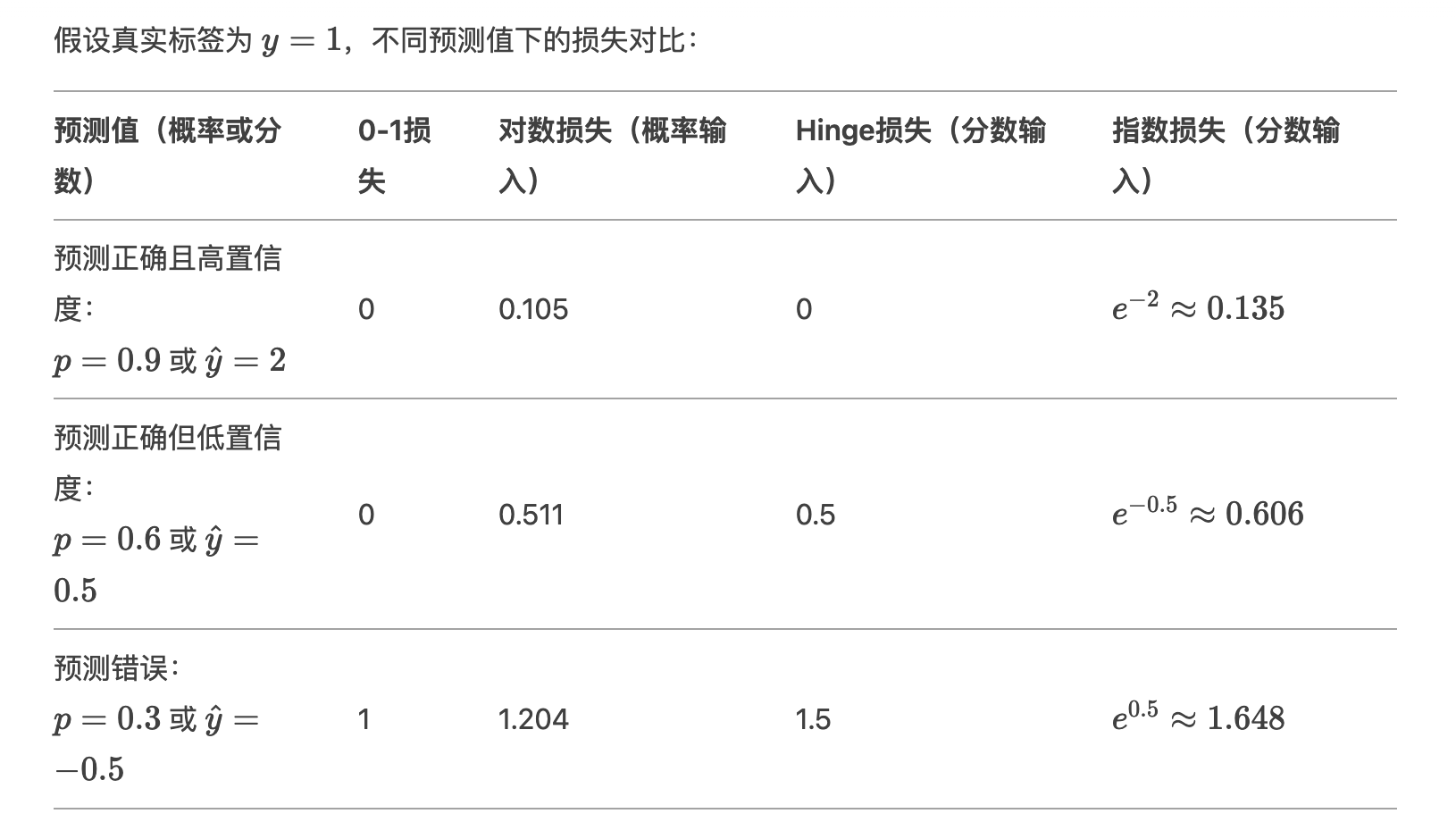
四、直观对比示例
五、如何选择二分类问题的损失函数?
-
是否需要概率输出 → 选对数损失(如逻辑回归)。
-
是否关注分类边界间隔 → 选Hinge损失(如SVM)。
-
是否需处理样本不平衡 → 调整损失函数权重(如加权交叉熵)。
-
是否使用集成方法 → 指数损失(如AdaBoost)。
通过理解损失函数如何量化“错误程度”,可以更直观地设计模型和调参。
六、与二分类问题相关的,这里附加理解一下伯努利分布
伯努利分布是一种非常基础的离散概率分布,用来描述一次只有两种可能结果的随机试验。直观上,你可以把它看作是“抛硬币”的概率模型,其中硬币只有正面和反面两种结果。
定义
- 支持:伯努利分布的随机变量 XX 只可能取两个值:0 和 1。
- 参数:一个参数 p(0≤p≤1),表示事件“成功”(或取值为1)的概率,而 1−p 则表示事件“失败”(或取值为0)的概率。
- 概率质量函数:
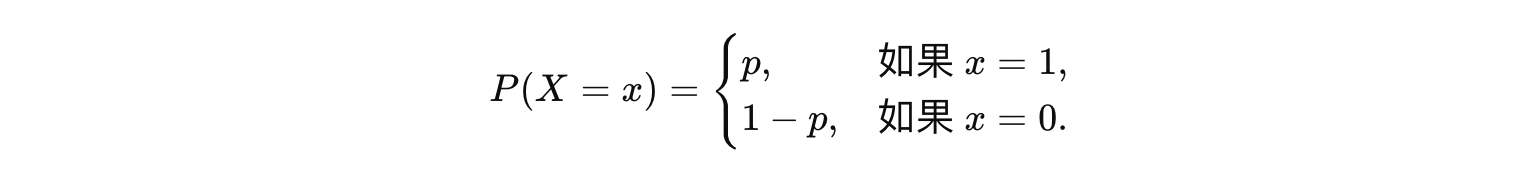
数学性质
- 期望: E[X]=p. 直观上讲,就是成功的概率。
- 方差: Var(X)=p(1−p). 表示结果的不确定性或波动性。
直观例子
-
抛硬币:
设一枚硬币正面朝上的概率为 p。如果我们将正面记为1,反面记为0,那么抛一次硬币的结果服从伯努利分布。如果硬币是公平的,则 p=0.5;如果硬币不公平,比如正面朝上的概率为70%,则 p=0.7。 -
简单实验:
假设你在进行一个简单实验,比如检测某种药物是否有效,我们可以将“有效”记为1,“无效”记为0。如果根据历史数据你认为药物有效的概率为80%,那么这个实验的结果可以用 p=0.8 的伯努利分布来描述。
伯努利分布简单地描述了只有两种可能结果的随机试验。它的核心在于一个参数 p——表示某一结果(通常称为“成功”或“正面”)的概率。这个分布在许多实际问题中都有广泛应用,比如二分类问题、决策过程、甚至在更复杂的分布(如二项分布、贝叶斯模型中)中,伯努利分布常常作为基本构件出现。