Impromptu VLA:用于驾驶视觉-语言-动作模型的开放权重和开放数据
25年5月来自清华和博世的论文“Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models”。
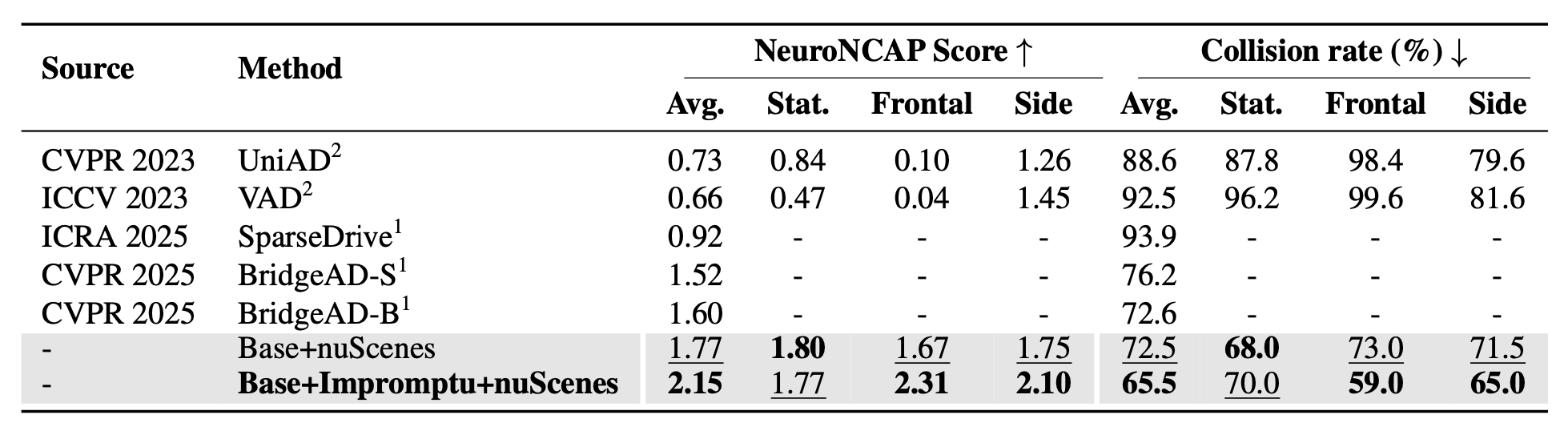
用于自动驾驶的“视觉-语言-动作” (VLA) 模型前景光明,但在非结构化极端场景下却表现不佳,这主要是由于缺乏有针对性的基准测试。为了解决这个问题, Impromptu VLA。其核心贡献是 Impromptu VLA 数据集:超过 8 万个精心挑选的视频片段,是从 8 个开源大型数据集的超过 200 万个源片段中提炼出来的。该数据集基于四大非结构化类别分类法构建,并具有丰富的、面向规划的问答标注和动作轨迹。至关重要的是,实验表明,使用数据集训练的 VLA 在既定基准上实现显著的性能提升——提高闭环 NeuroNCAP 得分和碰撞率,并在开环 nuScenes 轨迹预测中达到接近最先进的 L2 精度。此外,问答套件可作为有效的诊断工具,揭示 VLM 在感知、预测和规划方面的显著改进。
自动驾驶已经取得了显著进展,在城市中心和高速公路等结构化环境中,清晰的车道线和可预测的交通流量是常态,其导航能力日益提升 [23, 29, 58]。然而,实现无处不在的自动驾驶的终极目标,迫使大家将目光投向这些人迹罕至的道路之外,转向错综复杂且往往难以预测的非结构化道路领域。这些非结构化场景——涵盖从乡村小路、动态施工区域到标识模糊的区域或自然灾害后恢复的区域——代表着下一个重要的前沿领域。目前的自动驾驶系统往往面临着最严峻的考验,而突破对于充分发挥无所不能的自动驾驶能力的潜力至关重要 [74]。
专业数据的严重匮乏严重阻碍成功探索这一领域。虽然众多驾驶数据集为当前的研究进展奠定基础,但它们主要捕捉的是常见的结构化交通状况 [7, 8, 21, 42, 43, 55, 59, 68]。这留下一个显著的盲点,即非结构化环境所带来的多样性和独特挑战,例如道路边界不清晰、出现非常规动态障碍物、遵守临时交通规则或应对危险的路面。如果没有能够具体反映这些复杂条件的大规模、精细标注的数据集 [70, 47],训练稳健的人工智能驾驶员并严格评估其在此类场景下的适应性的能力仍然受到严重制约。
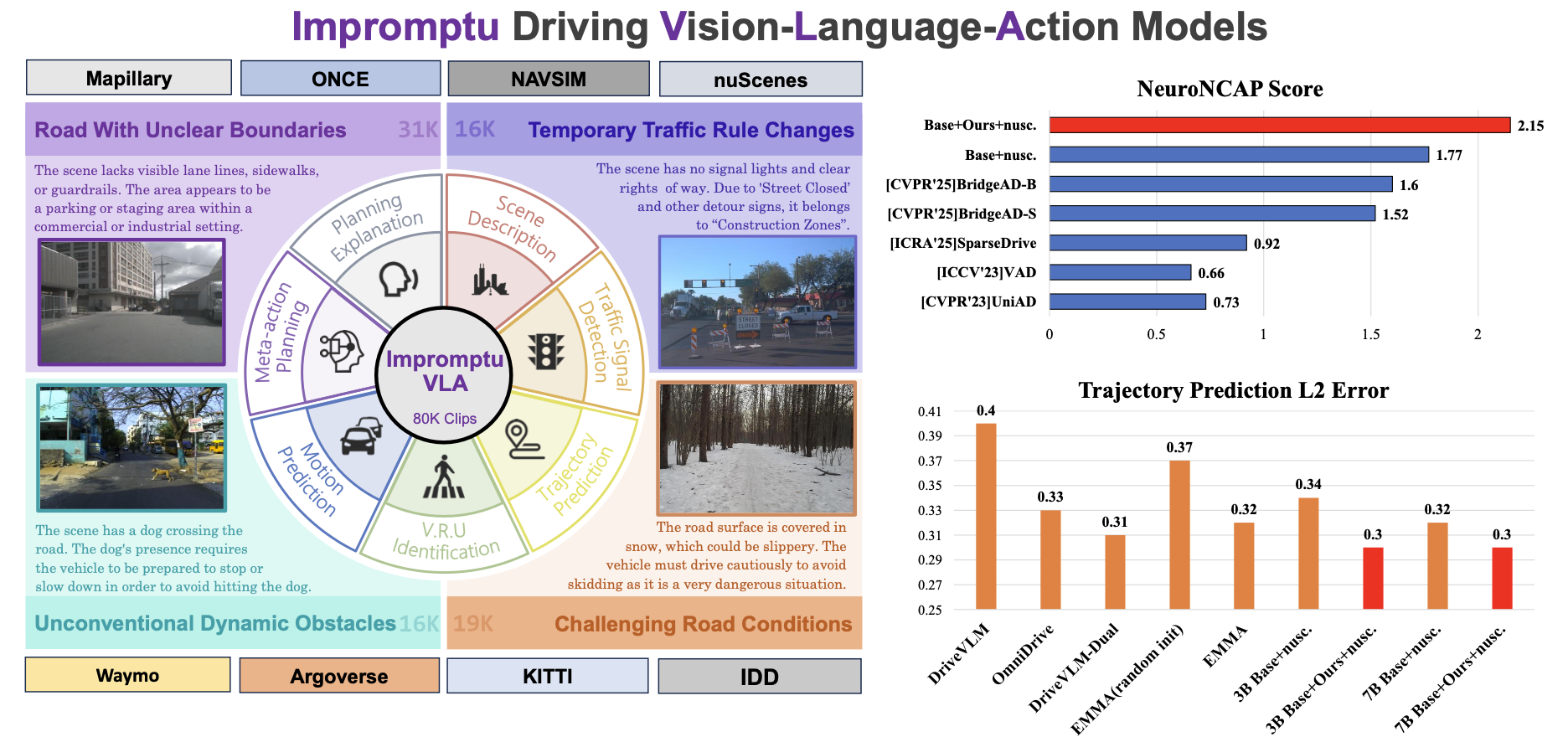
为了弥补这一数据空白,本文推出 Impromptu VLA 数据集。这是一个大规模基准数据集,专门用于推动非结构化道路上自动驾驶的研究,如图所示。Impromptu VLA 数据集从八个不同的公共来源 [7, 8, 21, 42, 43, 55, 59, 68] 的 200 多万个初始素材库中提炼而出,包含约 8 万个经过精心挑选和验证的素材。这些素材被分为四类具有挑战性的非结构化场景——边界不清晰的道路、临时交通规则变化、非常规动态障碍物和挑战性路况——并包含大量的多任务注释和规划轨迹。该数据集采用先进的流程构建,利用视觉语言模型 (VLM) 和思维链推理 [39, 2, 12] 进行细致理解,然后进行全面的人工验证,以确保高质量、可靠的标签。
概述
目前,研究界缺乏足够多的大规模、多样化且标注精细的非结构化场景数据集。为了弥补这一关键缺口,Impromptu VLA 数据集,旨在促进非结构化道路自动驾驶的发展。Impromptu VLA 数据集最初汇集来自八个著名公共数据集 [7, 8, 21, 42, 43, 55, 59, 68] 的超过 200 万个片段(占用超过 10T 的存储空间),经过筛选机制提炼,最终精简为一个高度集中的约 80,000 个片段的集合,如图所示。最终的数据集能够精准捕捉各种具有挑战性的场景,包括边界不清晰的道路、存在非常规动态障碍物以及存在临时或非标准交通规则的路段(详细统计数据见下表)。

定义非结构化驾驶场景的分类法
创建 Impromptu VLA 数据集的主要目标是突破对非结构化单一且模糊的理解,并更细致地理解这些环境所带来的具体挑战。为了实现这一目标,并将数据集聚焦于真正考验当前自动驾驶系统极限的场景,初步尝试采用数据驱动的流程,定义一个简洁而全面的非结构化道路场景分类法。
定义这些类别的方法始于对收集的数据进行广泛、客观的探索。首先,从聚合且标准化的多源数据集中定期抽取约 10% 的片段,创建一个具有代表性的子集。然后,利用强大的视觉语言模型 Qwen2.5-VL 72B [3] 对该子集进行开放式描述性分析。没有查询模型以按照预定义的标签协议回答问题,而是利用 VLM 的高级图像理解功能,促使其为每个场景生成详细的文本描述。
后续阶段涉及一个多阶段、高度自动化的过程,将这些描述提炼为有意义的非结构化挑战类别。首先,为了以编程方式识别并过滤掉常规驾驶场景,采用另一个基于 VLM 的分类步骤。使用精心设计的提示对 Qwen2.5-VL 生成的每个初始、丰富的场景描述进行评估,该提示指示 VLM 充当场景分类器,判断标题是否属于非常规情况。为了确保此基于 VLM 的过滤提示的可靠性和有效性,对提示进行迭代细化过程。该过程在约 1000 个场景描述的验证子集上进行测试,这些场景描述也由两位人工注释者手动且独立地标记为“常规”或“非常规”。将 VLM 的分类结果与人类共识进行比较,并不断迭代调整提示,直至达到高度一致。
对于从全集中筛选出的非常规场景,进行语义级分析,以识别重复出现的模式,并将语义相似的非结构化场景分组。这种聚类方法自下而上地催生出潜在的子类别,例如“道路边缘不清晰”、“临时道路施工”、“道路上的动物”或“因雪导致能见度低”。通过迭代改进、合并这些机器生成的聚类,以及基于在这些组中识别出的驾驶复杂性主要来源进行抽象,最终归纳出以下四个突出的高级类别:
- 边界不清晰的道路:可通行路径模糊或未定义的场景,例如乡村土路、越野小径或标线褪色/缺失的道路。这些场景对车道检测和可行驶区域分割等感知任务提出严峻挑战。
- 临时交通规则变更:标准交通规则因施工区域、人工交通管制员或临时标识而临时改变的动态情况,要求自动驾驶汽车适应异常指令和道路布局。
- 非常规动态障碍物:指在典型的城市驾驶中不常见的动态行为体或障碍物,需要专门的交互策略。例如,大型或不规则移动的车辆、意外位置的弱势道路使用者或与动物的碰撞,所有这些都构成突发危险。
- 复杂路况:指恶劣路面(例如,坑洼、泥泞、积雪、冰面)或环境条件(例如,雾、暴雨、弱光、眩光)严重影响能见度或影响车辆动态,使危险感知和安全导航变得复杂化的场景。
数据处理与注释
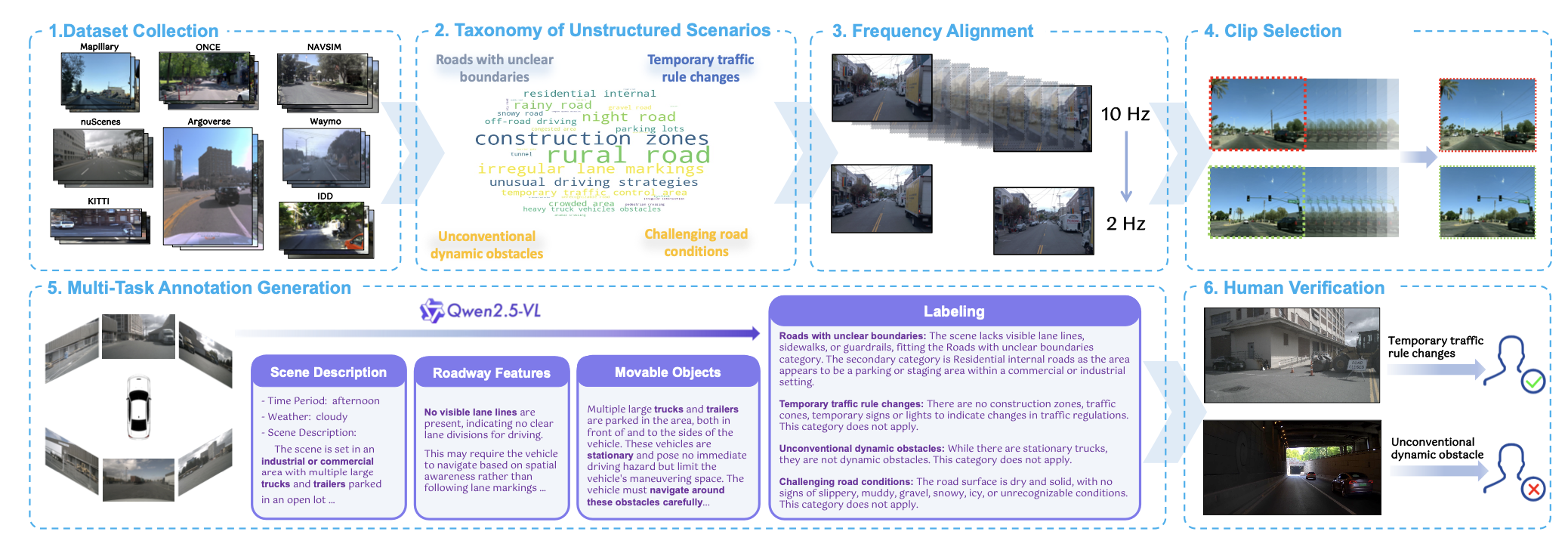
根据非结构化场景分类法的定义,整理后的数据经过多个处理和注释阶段,如上图所示。
关键片段选择和稳定性过滤。所有收集到的序列首先被标准化为 2 Hz 的统一时间频率,以解决来自不同来源的不一致问题。将片段配置与 NAVSIM [14] 进行对齐,保留过去 1.5 秒和未来 5 秒的片段,并从每个包中选择中心关键片段进行注释。为了最大限度地减少瞬态关键片段级别预测的误报,采用时间稳定性打包机制。具体而言,相邻片段被打包成(如果可能的话)15 秒的“局部过滤包”。片段的场景特征(在关键片段级别初步识别)只有当其在该包中持续存在最少数量的片段(例如,出现多次)时,才被认为是稳定的,并传播到后续注释阶段。需要注意的是,这些“局部过滤包”仅用于稳定性检查和选择过程;最终数据集主要由单独注释的关键片段组成。
通过思维链 (CoT) 提示进行场景分类和结构化信息提取。使用 Qwen2.5-VL 72B [3] 和思维链 (CoT) 提示 [65] 对选定的关键片段进行分类,以提取除简单字幕之外的丰富结构化信息。此分层推理过程分析整体场景上下文(R1:描述)、静态道路特征(R2)、可移动目标(R3),并最终将结果合理地分配到四个非结构化场景类别之一。结构化 CoT 输出不仅提供场景类别,还为后续任务注释提供丰富的上下文信息。
多任务注释生成。利用场景类别和在 CoT 过程中提取的结构化信息,借鉴 Senna [28] 等综合注释框架,用一组多样化的任务特定注释进一步丰富每个关键片段。这种多任务注释是通过结合基于规则和基于 LLM 的方法实现的。具体来说,为每个选定的关键片段生成以下注释。
- 场景描述:通过对 VLM 的定向查询,生成涵盖整体环境背景、时间、天气和交通状况的综合描述。
- 交通信号检测:通过进一步的 VLM 查询,识别活动交通信号的存在状态和类型。
- 弱势道路使用者 (VRU) 识别:关于 VRU 的信息,包括它们的存在、类型(例如行人、骑自行车的人)以及与自车的距离,均来自真值数据。
- 运动意图预测:为了捕捉动态方面,VLM 生成了场景中关键参与者的预测运动意图。
- 元动作规划:通常通过基于场景上下文的 VLM 提示,制定自车的高级规划(例如,左加速、保持直行)。
- 规划解释:VLM 生成文本解释,用于合理化自车响应场景的潜在或实际操作。
- 端到端轨迹预测:通过构建车辆历史状态和地面实况中对应的未来目标轨迹,整理支持此任务的数据。
全面的人工验证。所有生成的注释——包括主要的非结构化场景类别和后续的多任务标签——都经过细致的人工验证。注释员审查每个关键片段及其相关标签,提供二元判断(接受/拒绝)或在必要时进行细微的校正编辑。这确保整个数据集的高保真度。在进行广泛的人工审核之前,为了定量评估 VLM 在定义的非结构化类别中场景分类性能,基于从 nuScenes 数据集中间隔采样的 200 幅图像子集对其进行评估。将 VLM 分类与专家手动标签进行比较,发现多个类别的 F1 得分较高:“临时交通规则变更”为 0.90,“非常规动态障碍物”为 0.81,“复杂路况”为 0.91。“边界不清晰的道路”类别在特定的 nuScenes 子集中过于稀少,无法进行有意义的 F1 得分计算。这些验证结果为基于 VLM 的注释流程阶段提供了信心。
数据集统计
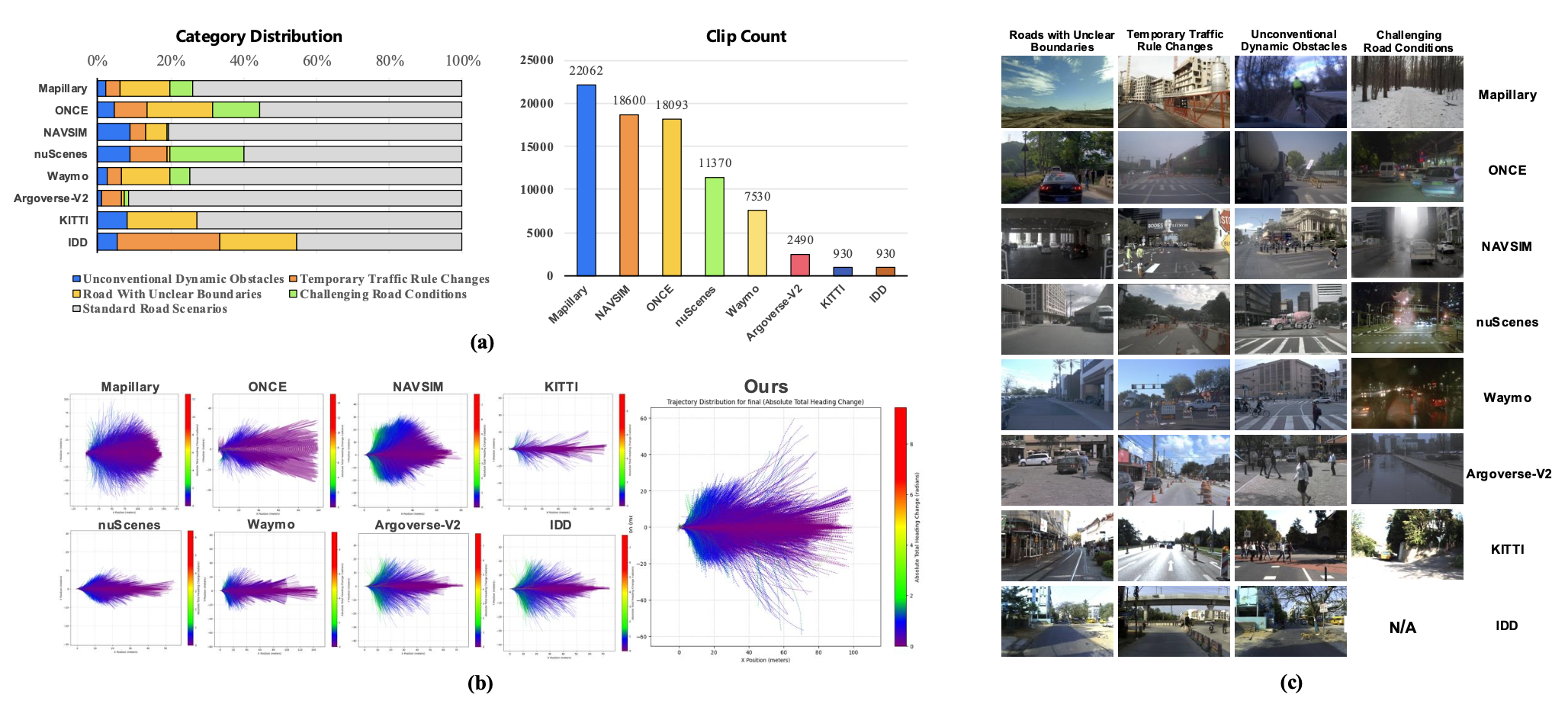
最终的 Impromptu VLA 数据集包含大量带注释的片段,这些片段专门针对其非结构化道路特征进行整理。如图展示了从每个源数据集派生出的片段总数,并展示这些片段在四个非结构化场景类别中的总体分布。图中还报告了轨迹分布的覆盖范围。
为了最大限度地利用该数据集训练和评估感知与规划模型,为每个片段生成的丰富的多任务注释被构建为面向规划的问答 (Q&A) 对。这种格式受到 DriveVLM [58] 或 EMMA [25] 等框架的启发,将视觉输入、文本输出和动作轨迹预测直接关联到 LLM 的序列空间中。为了进行标准化评估,将涵盖所有四个非结构化类别的整个精选片段数据集按 80:20 的比例划分为训练集和验证集。每个类别内都进行这种分层,以确保验证集保持所有定义的非结构化道路挑战的代表性分布。
基础模型是 Qwen2.5VL 3B [3]。第一个流程,在下表 NeuroNCAP 结果中,称之为“Base + Impromptu + nuScenes”,首先在 Impromptu VLA 数据集的训练样本上对基础 VLM 进行微调,然后在 nuScenes 训练集上进一步微调这个调整后的模型。第二个流程“Base + nuScenes”直接在 nuScenes 训练集上对基础 VLM 进行微调,无需使用 Impromptu VLA。然后,这两个模型都会在 NeuroNCAP 基准上进行评估。