2025年MathorCup数学建模D题短途运输货量预测及车辆调度问题解题文档与程序
2025年第十四届MathorCup高校数学建模挑战赛
D题 短途运输货量预测及车辆调度问题
原题再现:
短途运输存在于物流网络的最后环节,是在同城或同省的末端场地之间进行,即将货物从末分拣点发往营业部。此环节有着运输距离短、资源可复用、时效重点保障的特点。由于处于网络末端环节,短途运输对每个包裹的履约时效及客户体验有着十分重要的作用;同时,该环节也占有着大量的运力资源,对运输活动的合理优化也可以显著提升运输效率,降低运输成本。
短途运输的线路由起始场地、目的场地、发运节点组成。一般来说,起始场地是物流网络的末分拣中心,目的场地是营业部,直接面向客户履约。线路的发运节点指的是这一波次的货物必须在此节点前发出,即为该线路的最晚发运时间,必须在此时间保证全部货物完成运输。每天有两个发运节点,一般为6点和14点。
短途线路的货量预测是资源优化及决策的基础,决策者需要提前预知短途线路的货量,从而更加合理地安排运力资源。预测的基本单元是每条线路的包裹量。在进行预测的时间点,已经有一定量的包裹进入了物流网络,这些包裹计划流经这条线路的时间是可以预知的,即在预测的时间点可以得到计划流经各条线路的包裹量,我们称之为“预知”数据。然而该预知数据存在三个问题:1)计划线路可能与实际不符,即发运异常;2)未涵盖部分未下单的货量;3)已下单的货量可能会取消。在得到一条线路的总货量后,需要将其拆分至10分钟的颗粒度,从而更好地辅助后续优化决策步骤。
货量预测的结果可以转化为运输需求,运输需求指的是各线路需要调度的车次(车的数量)及发运时间。短途运输场景每车次可装载的包裹量是相对固定的,因此车次可以直接由货量转化得到。当10分钟颗粒度的累计货量达到车辆满载量,即可发运。运输需求包含另一个场景:对部分临近的线路,若包裹量较少,或整车发运后剩余不足一车的货量,将多个线路的货量合并为一车发运,这种场景称为“串点”,一般从同一起始场地出发运送到不同的目的站点。串点涉及的线路一般不允许超过3个。
短途调度的核心是运输车辆的调度。一个短途车队会负责部分线路,并拥有一些自有车辆。对于上述生成的运输需求,短途车队需要最高效地利用自有车辆,形成多次周转,从而让有限的自有车辆运输更多的运输需求及包裹。自有车辆周转的前提是前后的运输需求可衔接,具体标准是:前一个需求的发运时间+装车时间+在途时间*2+卸车时间<后一个需求的发运时间。对于剩余自有车辆无法承运的运输需求,由外部承运商进行运输,但成本会较高。
以上逻辑的示意图如图1所示,根据货量该线路存在3个运输需求,假设该线路的最晚发车时间为5:00,则最后一个需求的发运时间为5:00,其余需求的发运时间为1:00和3:00,均根据货量折算得到。假设需求1使用自有车1;对于需求2,自有车1完成需求1后返回到分拣中心的时间为4:30,无法继续发运需求2,若此时无剩余的自有车,则需求2需使用外部车进行发运;对于需求3,由于自有车1返回后时间早于需求3的发运时间,则可以继续使用自有车1发运需求3。

短途调度的结果在车效、成本两个方面进行评价。车效反应了车辆的利用率,是否最高效地使用了已有自有资源,存在自有车周转率、车辆均包裹两个指标;成本指标包括自有成本和外部承运商成本,其中自有成本包括了固定成本和变动成本;以上指标需要在“天”的维度进行评价。上述指标定义如下:
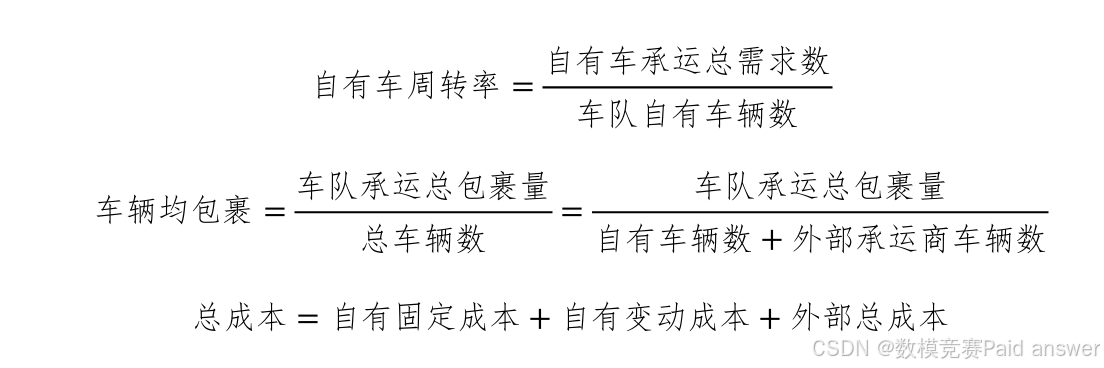
当前存在5个自有车队,每个车队负责的线路及相关信息如附件1所示,其中在途时长为单程分拣中心到营业部的时长,单位为小时;变动成本是发运一次该线路需求的成本,若为串点任务,则自有及外部成本均为串点的各线路中成本最大值。附件2是各线路历史15天的实际包裹量,注意6点和14点发运节点对应的最早货量分别为前一天21点和当天的11点,因此每天6-11点和14-21点可假设为不生产包裹量。要求每天21点开始进行预测和调度,附件3是各线路近15天的每天预知货量及未来1天在21点时的预知货量,附件4是可串点的站点集合(默认可串点站点对应的线路均可串点),附件5是各车队的自有车数量。假设所有车队只有一种车型,该车型的日固定成本为100,单次可装载1000个包裹,装车及卸车时长均为45分钟,其它成本见附件1。
请根据以上数据解决以下问题:
问题1:建立货量预测模型,未来1天各条线路的货量进行预测,并将每条线路的总货量拆解到10分钟颗粒度(结果的时间范围为12月15日14:00至12月16日14:00)。请将预测结果写入结果表1和表2中,并在论文中给出线路编码为“场地3-站点83–0600”和“场地3-站点83–1400”的预测结果。
问题2:根据问题1输出的结果,确定运输需求,包括每条线路的发运车辆数、预计发运时间及串点方案,其中每个需求的发运时间不能晚于线路的发运节点。基于以上结果,确定每个需求的承运车辆;要求自有车的周转率尽可能高,以及所有车辆均包裹尽可能高、总成本尽可能低。请将结果写入结果表3中,结果需包含:线路编码、预计发运时间、承运车辆。其中串点方案可将多条线路编码合并在“线路”一列展示,无法使用自有车满足时注明为“外部”,并在论文中给出线路编码为“场地3-站点83–0600”和“场地3-站点831400”的调度结果。
问题3:当前存在一种标准容器,使用该容器可以进一步提升自有车辆利用率,将装车及卸车时长显著缩短至10分钟;但缺点是会降低车辆的装载量,其装载包裹量下降至800个。假设这种容器数量是无限的。请根据问题1输出的结果,重新确定运输需求,优化目标与问题2相同。在问题2所需输出结果的基础上,需另外输出各运输需求是否使用该标准容器。请将结果写入结果表4中,并在论文中给出线路编码为“场地3-站点83–0600”和“场地3-站点83–1400”的调度结果。
问题4:当问题1的货量预测结果出现偏差时,基于问题3,评估对你们的调度模型优化结果的影响。
整体求解过程概述(摘要)
随着电子商务和同城配送业务的迅猛发展,短途运输在现代物流体系中的重要性日益凸显。相比长途运输,短途运输任务具有路线密集、频次高、时效性强的特点,对货量预测和车辆调度提出了更高的要求。准确预测未来货量并制定高效的运输策略,能够显著提升车辆利用率、降低运营成本,是提升物流系统运行效率的关键。本文针对短途运输货量预测及车辆调度问题,提出了系统的解决方案。通过对问题的深入分析,结合预测模型和优化算法,分别针对货量预测、运输需求制定以及引入标准容器后的多目标优化调度进行了详细研究。
针对问题一,本文首先建立了基于长短期记忆网络(LSTM)的货量预测模型,旨在对未来一天内各条线路的货量进行精准预测。通过对历史数据的分析和预处理,将数据转化为适合LSTM模型的输入格式,并设计了包含输入层、LSTM层和输出层的网络架构。模型训练过程中,采用均方误差(MSE)作为损失函数,并通过滚动预测方法对未来一天的货量进行预测。实验结果表明,该模型能够有效捕捉时间序列中的长期依赖关系,预测结果具有较高的准确性和稳定性。
针对问题二,基于问题一的预测结果,本文进一步制定了每条线路的运输策略,包括发运时间、承运车辆分配以及串点方案设计。通过线路聚合与发运需求确认,确定每条线路的最迟发运时间,并判断是否需要外包。在自有车可用性判断的基础上,设计了串点方案,优先将相近线路、发运节点接近、目的地接近的任务组合在一辆车上,以提高装载率、减少车辆数、降低总成本。最后,通过优先分配自有车辆,不足时采用外部承运商,并结合成本对比优化使用策略,生成了详细的运输需求表。该策略在满足装载量和成本最低的前提下,最大化了车辆利用率。
针对问题三,在问题二的基础上,本文引入了一种标准容器,该容器能够显著缩短装车和卸车时间,但会降低车辆的装载量。针对这一变化,本文重新评估了运输需求,并采用多目标优化方法,同时优化自有车周转率、车辆均包裹量和总成本。通过加权法将多个目标函数合并为一个单一的目标函数,并利用优化算法求解。实验结果表明,引入标准容器后,虽然装载量有所下降,但通过优化调度策略,仍然能够有效提高车辆利用率,降低总成本,并在多个目标之间达到较好的平衡。
针对问题四,在短途运输中,货量预测的准确性对车辆调度至关重要。本文量化了预测偏差,并评估了其对调度优化结果的影响,提出了优化预测模型、调整调度策略、建立实时监控系统和制定应急预案等综合应对措施,以提高物流运输的稳定性和经济性,降低预测偏差带来的风险。
模型假设:
1.假设标准容器数量是无限的。
2.假设车辆调度不存在延时情况。
3.假设每天6 - 11点和14 - 21点不生产包裹量。
4.假设不存在突发事件使包裹数量受外界因素干扰而变化。
5.假设车辆性能一致且在途时长不受外界因素干扰而改变。
问题分析:
问题一分析
针对问题一,为探究未来一天的货量,建立基于LSTM神经网络模型进行预测,首先,我们先对附件二数据进行预处理,构建时间序列数据集。然后将数据划分为训练集和测试集,用于训练模型和测试模型准确度。计算测试集上每个时间步的RMSE值,并以训练好的LSTM模型对未来一天各线路的货量进行预测。
问题二分析
针对问题二,需根据问题一的预测结果,确定运输需求。为了提高自有车辆的周转率、增大车辆均包裹,并确保总成本最低,需要优化车辆调度方案。因此我们利用贪心优化算法,首先,优先分配装载率高的线路给自有车,使得周转率和均包裹最大化。然后,筛选出剩余自有车无法运输的线路,交由外部承包商运输。在确保满足附件四可串点的基础上,将其中成本最高的三条线路进行串点,以实现成本最大化节省。
问题三分析
针对问题三,是在问题二的基础上,引入了标准容器这一新变量,导致车辆装卸时间缩短的同时使其装载能力下降。本题核心是对多目标优化问题的求解,在承载量和装卸时间的约束下,提高自有车辆的周转率、增大车辆均包裹,并确保总成本最低。我们采用遗传算法对多目标车辆调度问题进行建模与优化,通过多次迭代,最终输出车辆调度方案的最优解。
问题四分析
问题四是评估货量预测偏差对车辆运输调度的影响,问题一预测结果具有一定的误差,该误差会对运输车辆的调度产生影响,甚至产生运输资源不足或者空车,导致资源浪费,成本增加,误差还可能导致自有车周转率下降和车辆均包裹数减少,我们需要建立一个对预测偏差影响和调度策略鲁棒性分析的模型,评估其对调度结果的影响,便于提出应对策略,提高模型的鲁棒性。
模型的建立与求解整体论文缩略图

全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
# 参数设定
N_DAYS = 7 # 滑动窗口天数
ALPHA = 0.5 # 趋势项权重
PREDICT_DATE = '2024/12/16'
START_TIME = datetime.strptime('2024/12/15 14:00:00', '%Y/%m/%d %H:%M:%S')
END_TIME = datetime.strptime('2024/12/16 14:00:00', '%Y/%m/%d %H:%M:%S')
# 2. 数据预处理
daily_df['日期'] = pd.to_datetime(daily_df['日期'])
minute_df['日期'] = pd.to_datetime(minute_df['日期'])
minute_df['分钟起始'] = pd.to_timedelta(minute_df['分钟起始'].astype(str))
# 3. 定义函数:获取每条线路的时间分布向量(144个10分钟比例)
def get_time_distribution(line_code, df):df_line = df[df['线路编码'] == line_code]if df_line.empty:return Nonegrouped = df_line.groupby(['日期'])ratio_matrix = []for date, group in grouped:group_sorted = group.sort_values(by='分钟起始')total = group_sorted['包裹量'].sum()if total > 0:ratio = group_sorted['包裹量'].values / totalif len(ratio) == 144:ratio_matrix.append(ratio)if ratio_matrix:return np.mean(ratio_matrix, axis=0)else:return None# 4. 定义函数:根据最近N天进行滑动预测
def predict_daily_quantity(line_code, df):df_line = df[df['线路编码'] == line_code].sort_values(by='日期')recent = df_line.tail(N_DAYS + 1)if len(recent) < N_DAYS + 1:return Nonevalues = recent['包裹量'].valuesmoving_avg = np.mean(values[-N_DAYS:])trend = values[-1] - values[0]return moving_avg + ALPHA * trend
# 5. 执行预测主逻辑
results_1 = []
results_2 = []for line_code in result_template_1['线路编码'].unique():predicted_qty = predict_daily_quantity(line_code, daily_df)if predicted_qty is None:continueresults_1.append({'线路编码': line_code,'日期': PREDICT_DATE,'货量': round(predicted_qty)})r_vector = get_time_distribution(line_code, minute_df)if r_vector is None:origin = line_code.split(' - ')[0]similar_lines = [lc for lc in minute_df['线路编码'].unique() if lc.startswith(origin)]avg_vectors = [get_time_distribution(lc, minute_df) for lc in similar_lines]avg_vectors = [v for v in avg_vectors if v is not None]if avg_vectors:r_vector = np.mean(avg_vectors, axis=0)else:r_vector = np.ones(144) / 144 # 均匀分布兜底# 分解预测总量到每10分钟quantities_10min = predicted_qty * r_vectorcurrent_time = START_TIMEfor q in quantities_10min:results_2.append({'线路编码': line_code,'日期': current_time.strftime('%Y/%m/%d'),'分钟起始': current_time.strftime('%H:%M:%S'),'包裹量': round(q)})current_time += timedelta(minutes=10)# 6. 保存结果表
result_df1 = pd.DataFrame(results_1)
result_df2 = pd.DataFrame(results_2)result_df1.to_excel('结果表1_预测结果.xlsx', index=False)
result_df2.to_excel('结果表2_分钟预测.xlsx', index=False)
print("已保存:结果表1_预测结果.xlsx 和 结果表2_分钟预测.xlsx")