序列搜索策略
序列搜索策略
贪心搜索(greedy search)
-
在大语言模型中, 对于输出序列的每一时间步t′, 我们都将基于贪心搜索从Y中找到具有最高条件概率的词元,即:
y t ′ = argmax y ∈ Y P ( y ∣ y 1 , … , y t ′ − 1 , c ) y_{t^{\prime}}=\underset{y \in \mathcal{Y}}{\operatorname{argmax}} P\left(y \mid y_1, \ldots, y_{t^{\prime}-1}, \mathbf{c}\right) yt′=y∈YargmaxP(y∣y1,…,yt′−1,c)
一旦输出序列包含了“”或者达到其最大长度限制,则输出完成。即将当前时刻预测概率最大的词输出
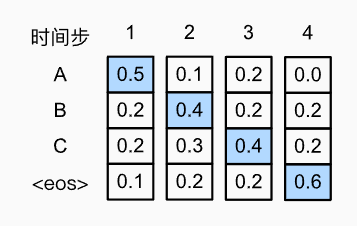
-
贪心搜索是效率最高的,但是贪心搜索很可能不是最优的,可以看下面的例子
在时间步2的时候,选择具有第二高条件概率的词元“C”(而非最高条件概率的词元)
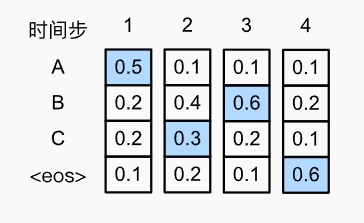
因为我们在第二步没有选择最优,导致后续的预测词元概率发生了变化,从而形成了更好的结果
穷举搜索(exhaustive search)
-
如果目标是获得最优序列, 我们可以考虑使用穷举搜索(exhaustive search): 穷举地列举所有可能的输出序列及其条件概率, 然后计算输出条件概率最高的一个。
-
最优的算法:对所有可能的序列,计算他的概率,然后选取最好的额那个
-
如果输出字典大小为n,序列最长为T那么我们需要考察 n T n^T nT个序列,假设
n = 10000 T = 100 则 n T = 10 50 n^T = 10^{50} nT=1050
计算上是不可行的
-
所以最好我们需要有个折中的方法
集束搜索(beam search)
-
束搜索(beam search)是贪心搜索的一个改进版本。 它有一个超参数,名为束宽(beam size)k。 在时间步1,我们选择具有最高条件概率的k个词元。 这k个词元将分别是k个候选输出序列的第一个词元。 在随后的每个时间步,基于上一时间步的k个候选输出序列, 我们将继续从k|Y|个可能的选择中 挑出具有最高条件概率的k个候选输出序列。下面是k=2,字典长度为5时候的示例
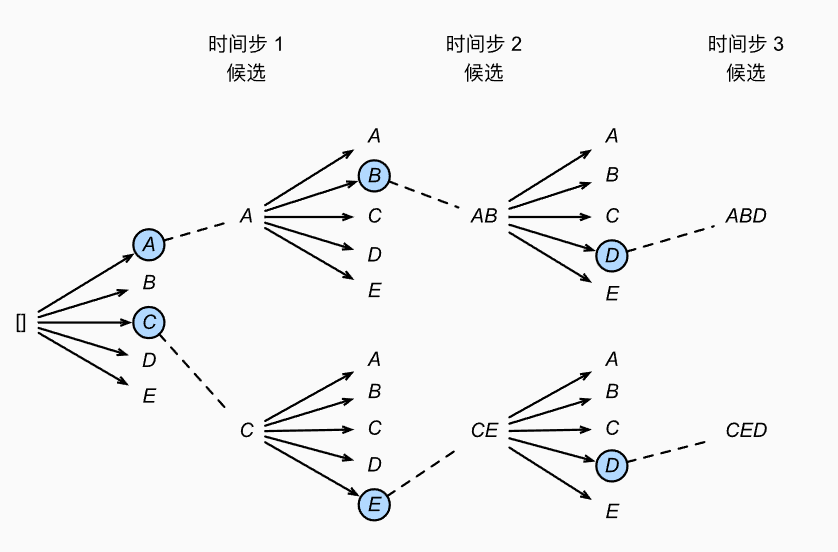
-
集束搜索时间复杂度
O ( k n T ) O(knT) O(knT) -
每个候选的最终分数为:
1 L α log P ( y 1 , … , y L ∣ c ) = 1 L α ∑ t ′ = 1 L log P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) \frac{1}{L^\alpha} \log P\left(y_1, \ldots, y_L \mid \mathbf{c}\right)=\frac{1}{L^\alpha} \sum_{t^{\prime}=1}^L \log P\left(y_{t^{\prime}} \mid y_1, \ldots, y_{t^{\prime}-1}, \mathbf{c}\right) Lα1logP(y1,…,yL∣c)=Lα1t′=1∑LlogP(yt′∣y1,…,yt′−1,c)
通常 α = 0.75 \alpha=0.75 α=0.75,其中L是最终候选序列的长度, α通常设置为0.75。 因为一个较长的序列在 的求和中会有更多的对数项, 因此分母中的Lα用于惩罚长序列。 -
总结:集束搜索在每次搜索时保存K个最好的候选。当k=1时时贪心搜索,当k=n时时穷举搜索