neo4j 5.19.0两种基于向量进行相似度查询的方式
介绍
主要讲的是两种相似度查询
- 一种是创建向量索引,然后直接从索引的所有数据中进行相似度搜索,这种不支持基于自己查询的结果中进行相似度匹配
- 另一种是自己调用向量方法生产相似度进行相似度搜索,这种可以基于自己的查询结果中进行相似度搜索
相关地址
向量索引的创建、查询、删除等
在线向量字段生成(也有包含离线生成的相关模型的链接)
相似度算法 Function
测试数据集
基于向量索引进行相似度查询
创建向量字段
创建字段代码
此处主要讲离线的创建方式,在线的需要大模型的key ,需要联网,我没试过,但是开头有提供官网链接,需要的可以自己看。
本质都是查出需要建向量字段的所有数据,然后看需要用哪些字段生成向量字段,将这些字段拼接起来后调用模型生成向量后给对应的节点插入一个 embedding 字段
下面是用 bert 的模型生成的 768 维的 embedding
from neo4j import GraphDatabase
from transformers import BertTokenizer, BertModel
# from transformers import AutoTokenizer, AutoModelForMaskedLMclass Neo:def __init__(self, uri, user, password):self.driver = GraphDatabase.driver(uri, auth=(user, password))def close(self):self.driver.close()def listMovies(self):result = self.driver.execute_query('match (n:Movie) return elementId(n) as id,n.description as description,n.name as name')return result.recordsdef writeMovieEmbedding(self,id,embedding):#插入embedding 字段result = self.driver.execute_query('match (n:Movie) where elementId(n) = $id set n.embedding=$embedding',id=id,embedding=embedding)return result.recordsclass Embedding:def __init__(self):self.tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')self.model = BertModel.from_pretrained('bert-base-chinese')# self.tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')# self.model = AutoModelForMaskedLM.from_pretrained('bert-base-chinese')def gen(self,text):#根据文本生成embeddinginputs = self.tokenizer(text, return_tensors='pt')outputs = self.model(**inputs)pooler_output = outputs.pooler_output# pooler_output = outputs.logitsreturn pooler_output.detach().numpy()if __name__ == "__main__":em = Embedding()neo = Neo("bolt://192.168.91.128:7687", "neo4j", "12345678")movies = neo.listMovies()for record in movies:data = record.data()# 需要进行相似度查询的文本,可以从neo4j查出的结果字段拼接,也可以拼接其他自己想拼接的东西embeddingText = data.get('name')+","+data.get('description')embedding = em.gen(embeddingText)neo.writeMovieEmbedding(data.get("id"),embedding.tolist()[0])neo.close()模型我是放在和代码同目录的地方,如下图所示
效果如下图所示,多了个 embedding 字段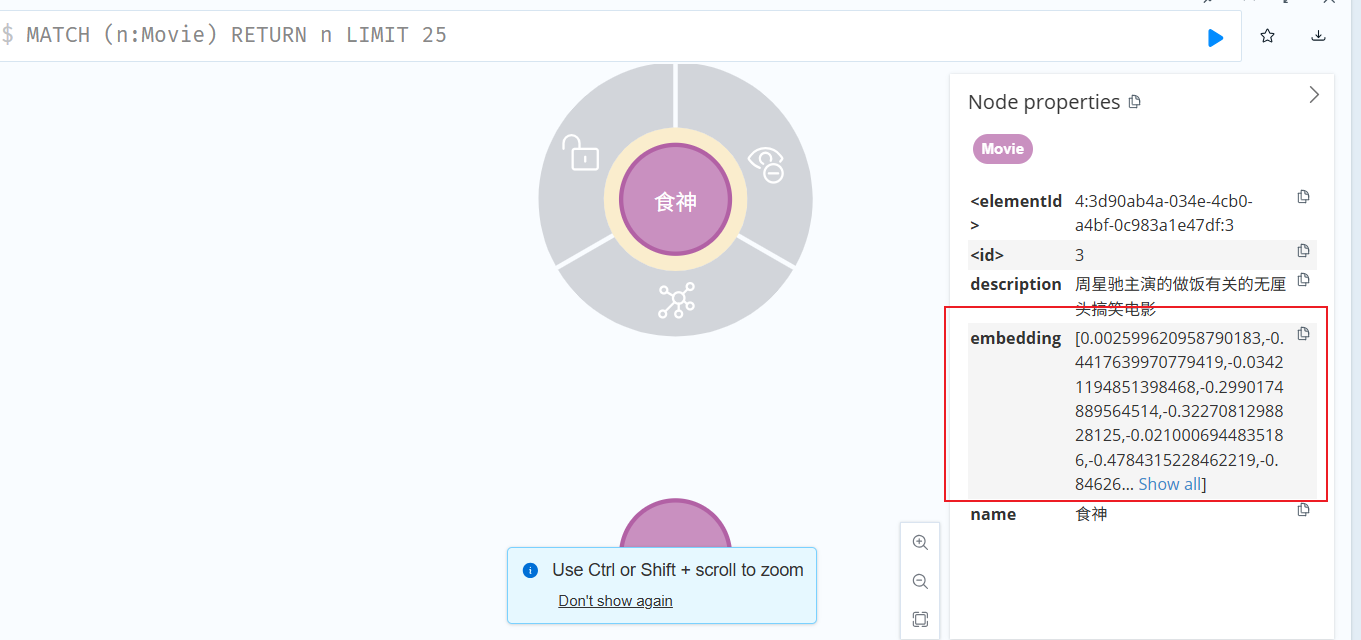
相关依赖
下面是我使用的依赖和版本
python:3.8
torch:2.4.0
neo4j:5.28.1
transformers:4.46.3
向量模型下载
下面是我使用模型的下载地址,可以从网址中找到其他模型。你们也可以选择其他模型
官网,需要翻墙的地址
镜像地址,不需要翻墙,但不知道啥时候失效
创建向量索引
执行如下语句创建索引
CREATE VECTOR INDEX $indexName IF NOT EXISTS
FOR (m:Movie)
ON m.embedding
OPTIONS { indexConfig: {`vector.dimensions`: 768,`vector.similarity_function`: 'cosine'
}}$indexName 是自己指定的索引名称,不要创建重复的名称。
FOR 后面的 (m:Movie) 用于配置查询条件指定给哪些数据创建索引
ON 后面的 m.embedding 用于指定用哪个字段创建索引,我创建的向量字段是 embedding
vector.dimensions 配置向量的维度,主要我们生成向量的模型用的什维度,此处就是什么维度,我上面用的模型生成的维度是768,所以没得就是768
vector.similarity_function:配置相似度的计算算法,consine 余弦相似度,euclidean 欧氏距离
向量相似度查询
这种查询方式我目前知道的只能基于索引内的全量数据进行相似度查询,而无法基于自己MATCH 之后的数据集进行相似度查询
基本语法
CALL db.index.vector.queryNodes($indexName, $topK, $embedding)
YIELD node AS movie, score$indexName 要查询的索引名称
$topK 设置要返回最相似的前面多少条
$embedding 查询和这个向量字段相似的数据,double 数组
score 相似度分数,值越大表示越相似
直接从索引查询
这种查询会查询索引下所有数据匹配相似度,然后返回前5条
CALL db.index.vector.queryNodes('movie_idx', 5, $embedding)
YIELD node AS movie, score
RETURN movie.name AS name, movie.description AS description , score$embedding 需要自己将自己要查询的字符串生成向量数组后放进去查询,比如如果需要查询和“食物”相关的电影,将 “食物” 通过上面的模型生产向量,如生成向量的为 [1.8,2.7,3.5] ,则查询写法为
CALL db.index.vector.queryNodes('movie_idx', 5, [1.8,2.7,3.5] )
YIELD node AS movie, score
RETURN movie.name AS name, movie.description AS description, score注意,此处生成的向量 $embedding 维度需要和索引的维度一致,假设量纲不匹配,如上面的[1.8,2.7,3.5] 才三个量纲,于是出现如下错误
Failed to invoke procedure `db.index.vector.queryNodes`: Caused by: java.lang.IllegalArgumentException: Index query vector has 3 dimensions, but indexed vectors have 768.
基于查询的结果进行相似度查询
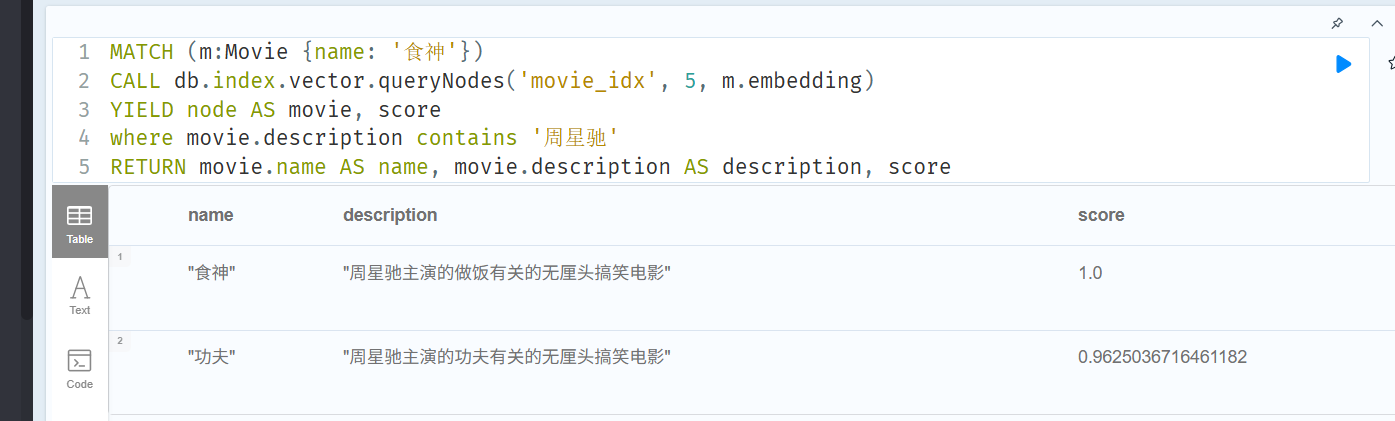
MATCH (m:Movie {name: '食神'})
CALL db.index.vector.queryNodes('movie_idx', 5, m.embedding)
YIELD node AS movie, score
where movie.description contains '周星驰'
RETURN movie.name AS name, movie.description AS description, score1. MATCH 查出一条名称为 "食神" 的节点
2.CALL 里的 m.embedding 表示用这条"食神" 的节点的 embedding 向量字段进行相似度匹配,找出和食神这部电影相似度最高的前五部电影。
注意:
1.前面的 MATCH 是可以返回多条数据的,假设前面的 MATCH 返回两个节点 "食神" ,"功夫",则循环每个节点调用一次后面的 CALL ,结果为和"食神" 相似度最高的五部电影加上和 功夫" 相似度最高的五部电影,总共十部电影。同理,如果返回的是十条数据,那就是得到五十部电影
2. CALL 里的 m.embedding 必须是MATCH的向量属性,不能自己输入向量数组,我一开始是自己输入向量数组,以为 CALL 是基于前面 MATCH 之后的结果集里进行相似度查询。结果返回的数据变成 5 的倍数,然后数据每 5 条重复一次。
3.where 是可以基于匹配结果进行过滤的
查询效果如下图所示
基于Function进行相似度查询
这种方式是自己调用相似度算法生成相似度 Score 后排序获取最相似的数据,所以支持基于 Match 后的数据集进行相似度查询。这种方式不需要建索引。
MATCH (m:Movie)
WITH m, vector.similarity.cosine($embedding, m.vector) AS score
RETURN node, score
ORDER BY score DESCENDING
LIMIT 2;1.MATCH 就是查询出自己需要的数据集
2.WITH 里调用 vector.similarity.cosine 生成余弦相似度作为 score,socre越高表示越相似
3.odder by + limit 就可以查出最相似的前几条数据了
4. $embedding 是向量数组,也是基于要查询的文本生产向量数组后放上去,同 直接从索引查询 的 $embedding 是一样的