LLM模型量化从入门到精通:Shrink, Speed, Repeat
前言
神经网络把它们的知识都存成数字啦,主要是训练时学到的权重,还有运行时在每一层流动的激活值。这些数字必须保持在一个固定的数值格式里,而选的格式就决定了每个参数要占多少内存。要是用默认的32位浮点表示,一个有70亿参数的语言模型可就重达28 GB啦,这比普通笔记本/台式机的GPU能装下的内存多多了。
量化就能解决这个问题啦,它把同样的值重新编码成精度更低的格式:8位整数、4位块浮点数,还能更小呢,能让内存占用缩小4-8倍,还能加速推理,因为小张量在内存里跑得更快。
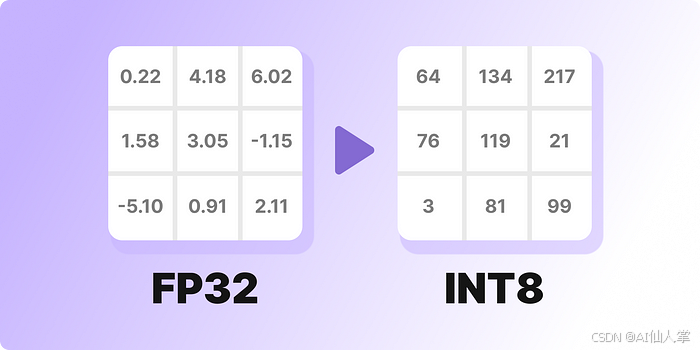
1. 模型为啥需要减肥
深度学习网络的体积可是爆炸式增长的,尤其是大型语言模型(LLM):GPT-2(2019年)有15亿参数,GPT-4的公开估计参数数量达到了几百亿,现在好多研究实验室都在训练万亿参数的原型模型了。 [Our World in Data] [Wikipedia]
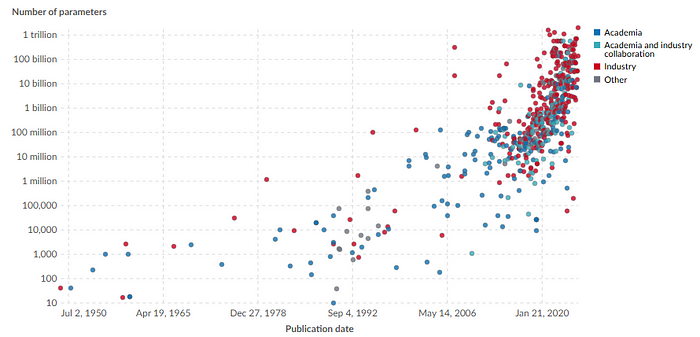
[**Our World in Data]
然而,消费级GPU的显存从大约8 GB只涨到了24/32 GB,这可和模型的增长速度完全不匹配呀。这就导致很多最先进的模型检查点大到连在单个笔记本或游戏显卡上做推理都装不下。
模型压缩研究就是来填补这个差距的,它能让同样的网络占用更少的字节,运行得还更快。主要有三大类方法:

在实际应用中,这些技术常常是组合使用的,比如一个4位量化、稀疏剪枝的学生模型。
不过,量化可是脱颖而出的第一选择呢,因为它能保持原来的架构不变,几乎不需要重新训练,还能立刻节省显存:一个70亿参数的模型从FP32的约28 GB一下子降到现代4位格式的约6 GB,小到能装进中端RTX笔记本GPU里啦。
接下来的指南先从能让模型变小的数值格式讲起,然后一步步从简单的8位线性量化讲到如今领先的4位方法,这些方法你只要几行代码就能试一试哦。
2. 数据类型和大小
不同的数值格式决定了每个权重或激活值要占多少位,也因此决定了模型需要多少内存,以及它的数学运算能跑多快。这一节咱们就来瞅瞅量化中最常遇到的两大类数值格式:整数和浮点数格式。
整数格式 [Wikipedia]
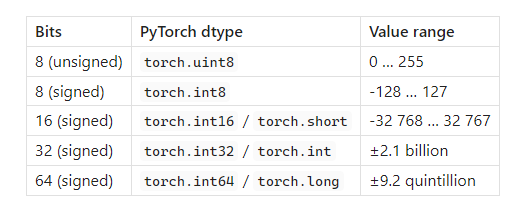
PyTorch的助手torch.iinfo(dtype)能打印出任何整数类型的最小值/最大值限制。 [PyTorch] 为啥整数很重要:把权重存成8位整数,内存就能减少到FP32的四分之一,还能减轻内存带宽的压力,这可是在推理工作负载里常常是真正的瓶颈呢。
浮点数家族
浮点数编码了三个字段:符号(1位)、指数(范围)和小数部分(精度)。把其中任何一个字段缩小,就能减少内存占用,还能解锁更快的GPU张量核心路径。 [Wikipedia]
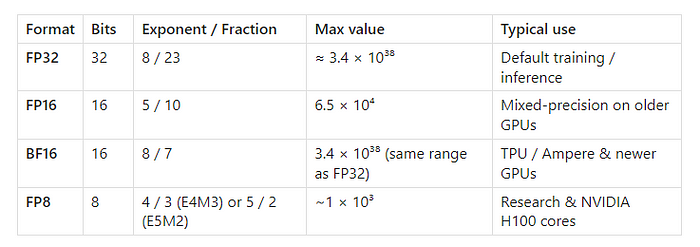
PyTorch通过torch.float16、torch.bfloat16等来暴露这些格式;用torch.finfo(dtype)就能查询精度和范围。 [PyTorch]
降低精度演示
把一个FP32张量转换成BF16,内存就能减半,不过会出现四舍五入的情况:
# 生成一个FP32类型的随机张量
x_fp32 = torch.rand(1000, dtype=torch.float32)
# 将其转换为BF16类型
x_bf16 = x_fp32.to(torch.bfloat16)# 打印前5个元素,看看转换后的值变粗略了
print(x_fp32[:5])
print(x_bf16[:5]) # fewer mantissa bits → coarse values
# 计算并打印两个张量的点积,看看精度损失
print(torch.dot(x_fp32, x_fp32))
print(torch.dot(x_bf16, x_bf16))
在大多数工作负载里,点积的误差都不到1%,这可就体现了典型的精度/准确率权衡啦。
3. 线性量化
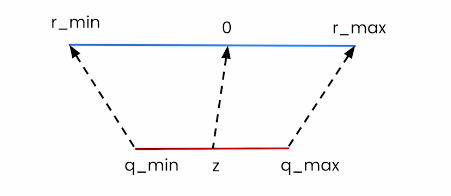
当你把一个张量从32位浮点数换成精度更低的类型时,你需要一条规则来告诉每个原始值它应该落在那个短得多的整数刻度的哪个位置。最常见的规则就是线性(均匀)量化啦:把满精度范围[rₘᵢₙ,rₘₐₓ]拉伸平移一下,让它正好能装进整数范围[qₘᵢₙ,qₘₐₓ]里。
两个小小的参数就能搞定:
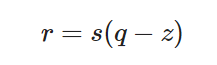
-
比例尺s决定了一个整数步有多宽
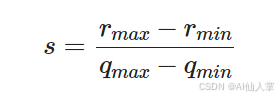
-
零点z告诉哪个整数应该代表现实世界里的零
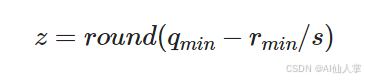
用这种技术把32位浮点数换成8位整数,我们通常能在语言模型基准测试里把准确率损失控制在不到一个百分点以内哦。 [NVIDIA Developer] 虽然这技术看起来挺基础的,但它其实超有效,还是2025年目前大多数最先进的量化技术(比如SmoothQuant、GPTQ、QLoRA的NF4块、AWQ的激活感知变体)的基础呢。
4. 动手实践小实验
在咱们聊现代的INT8和4位方案到底是咋回事之前,先让咱们用自己的GPU看看量化到底有多厉害吧。下面这个短短的脚本会用三种不同的方式加载同一个TinyLlama-1.1 B检查点:全精度FP16、8位INT8和4位NF4,然后:
- 记录每种版本占用了多少显存
- 对短文本生成操作计时几次
- 打印出一行总结,让你能直观比较速度和内存的差别。
导入模块和选择模型
# 导入必要的模块
from transformers import (AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig)
import torch, time, GPUtil, gc
- transformers模块给我们提供了模型加载器和
BitsAndBytes包装器。 - GPUtil能读取实时的GPU内存。
ID设置为TinyLlama/TinyLlama-1.1B-Chat-v1.0(在FP16下约2GB)。如果你的显存有12GB或更多,可以取消注释Mistral那行哦。
# ID = 'mistralai/Mistral-7B-Instruct-v0.3'ID = 'TinyLlama/TinyLlama-1.1B-Chat-v1.0'
tok = AutoTokenizer.from_pretrained(ID, use_fast=True)
辅助函数:加载并基准测试
# 定义一个函数来加载模型并测试显存占用
def load_and_benchmark(label, kwargs):torch.cuda.empty_cache(); gc.collect()start_vram = GPUtil.getGPUs()[0].memoryUsedmodel = AutoModelForCausalLM.from_pretrained(ID, **kwargs)used = GPUtil.getGPUs()[0].memoryUsed - start_vramreturn model, used
- 清空缓存,让每次加载都从同一个基准线开始。
- 返回模型对象以及它给显存增加了多少GB。
辅助函数:运行几个提示词
# 定义一个函数来运行几次推理并记录时间
def run_inference(model, model_mem, tag, prompt="Tell me one fact about volcanoes.", n=3):times = []for _ in range(n):t0 = time.time()_ = model.generate(**tok(prompt, return_tensors="pt").to(model.device),max_new_tokens=100, do_sample=False,pad_token_id=tok.eos_token_id)times.append(time.time() - t0)avg = sum(times) / ntotal_vram = GPUtil.getGPUs()[0].memoryUsedprint(f"{tag:>6}: {avg:>5.2f}s avg | {model_mem:>4.1f} GB model | {total_vram:>4.1f} GB total")return avg, model_mem
- 确定地生成文本(
do_sample=False),这样时间才好比较。 - 打印三个数字:平均延迟、模型的增量大小以及总显存占用。
定义三种加载配置
configs = [("FP16", {"torch_dtype": torch.float16, "device_map": "auto"}),("INT8", {"quantization_config":BitsAndBytesConfig(load_in_8bit=True),"device_map": "auto"}),("NF4", {"quantization_config":BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True),"device_map": "auto"})
]
运行实验
# 打印实验的标题和分隔线
print("Quantization Effectiveness Comparison")
print("="*50)
print(f"{'Type':>6}: {'Time':>8} | {'Model':>11} | {'Total':>11}")
print("-"*50)results = []
for name, kwargs in configs:model, mem = load_and_benchmark(name, kwargs)avg, _ = run_inference(model, mem, name)results.append((name, avg, mem))del model; torch.cuda.empty_cache(); gc.collect()
打印一行总结
# 提取FP16的基准时间和内存占用
fp_time, fp_mem = results[0][1], results[0][2]
print("\nSummary")
print("-"*30)
for name, t, m in results:print(f"{name}: {fp_time/t:>4.2f}× speed | {fp_mem/m:>4.2f}× memory")
我得到的结果是:
Quantization Effectiveness Comparison:
==================================================Type: Time | Model | Total
--------------------------------------------------FP16: 0.16s avg | 2346.0 GB model | 3321.0 GB totalINT8: 0.07s avg | 1288.0 GB model | 2387.0 GB totalNF4: 0.07s avg | 1072.0 GB model | 2171.0 GB totalSummary:
------------------------------
FP16: 1.00x speed, 1.00x memory efficiency
INT8: 2.24x speed, 1.82x memory efficiency
NF4: 2.34x speed, 2.19x memory efficiency
5. 大型语言模型的量化
在刚才的小实验里,咱们看到8位和4位格式能把TinyLlama的内存占用减少2-4倍呢。要是想在大型语言模型(LLM)上玩同样的把戏,可就难多了,因为Transformer架构有些古怪的地方,会把简单的线性量化给搞砸。
大型语言模型量化面临的挑战
和计算机视觉模型里表现良好的激活值不同,LLM有好些特性让简单的量化变得困难:
- 异常激活值:有些通道的激活值能比其他通道高出100倍。要是你硬要把所有值都塞进一个整数网格里,大部分编码就浪费在空白区域啦 [arXiv]。
- 每个通道都不一样:注意力头和MLP行都有自己的尺度,要是“一刀切”地用同一个尺度,准确率可就遭殃了 [OpenReview]。
- 小错误会滚雪球:在自回归模型里,一个错的标记会改变后面所有的标记,所以即使是小的权重误差也很重要。
为了解决这些挑战,出现了三种流行的后训练量化工具包:
- GPTQ(Frantar 22)
- AWQ(Lin 23)
- SmoothQuant(Xiao 22)
这三种方法都是在训练之后运行的,最多只需要几百个样本提示词,而且压根不碰梯度。
GPTQ:生成式预训练Transformer的量化
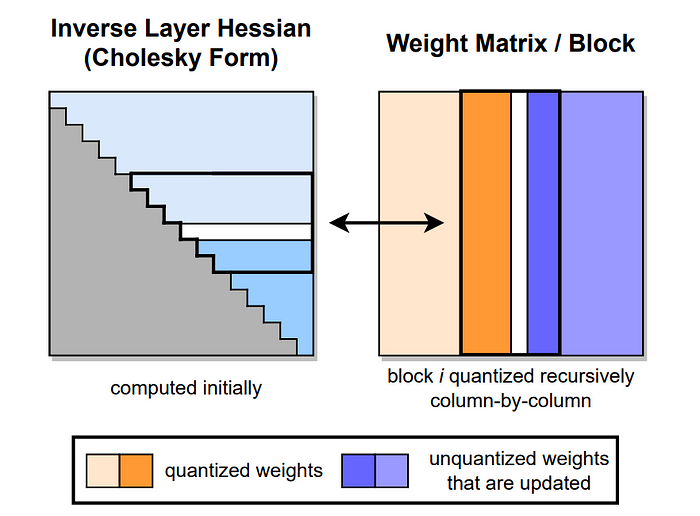
GPTQ [Frantar et al. 2023] 是把经典的最优大脑量化算法改编给Transformer架构用的。关键的洞见是逐层量化权重,同时通过调整剩下的未量化权重来补偿量化误差。
算法如下:
- 校准:把一个小数据集(通常是128个样本)通过模型,收集激活值的统计信息。
- 逐层量化:对于每个Transformer层:
- 量化一组权重
- 测量量化误差
- 更新剩下的权重,以最小化误差对层输出的影响。
- 4位效率:把多个4位权重打包到一个内存字里,方便GPU快速访问。
优点:准确率保留得非常好(通常小于1%的退化),能和任何4位格式搭配,不需要重新训练。
AWQ:激活感知权重量化
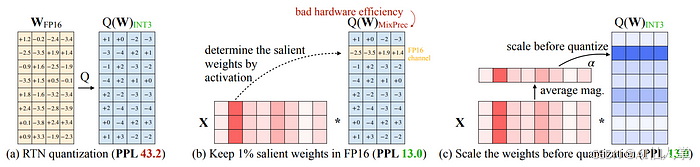
AWQ [Lin et al. 2023] 采用了一种不同的方法:与其事后修正量化误差,不如一开始就防止它们出现。这个方法会识别出“关键”权重(那些对重要激活值贡献最大的权重),然后给它们应用通道级的缩放,减少它们的量化误差。不太重要的权重就可以更激进地量化啦。
关键创新:AWQ发现大约1%的权重就能撑起模型的大部分能力。通过用更高精度(或者更好的缩放)保留这些权重,整个模型就能保持性能啦。
SmoothQuant:激活值和权重量化
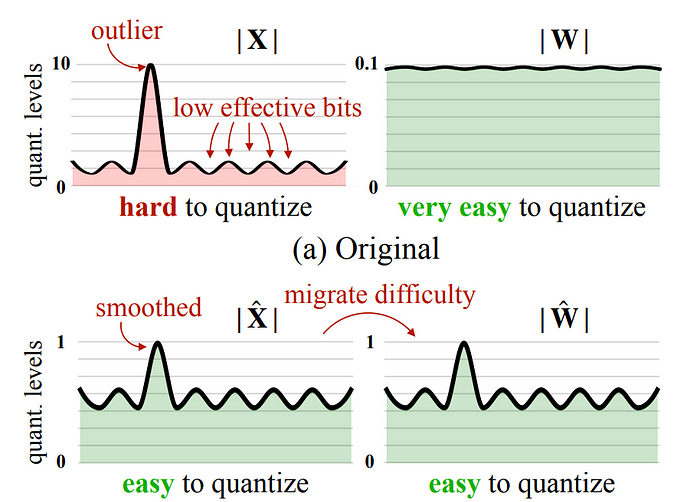
标准的方法是把权重量化到INT8,但激活值还保留在FP16,这就造成了一个混合精度的瓶颈。SmoothQuant [Xiao et al. 2023] 通过用不同的方式处理异常值,实现了全INT8推理。
它不是保留异常值,而是通过把难度从激活值转移到权重上来“平滑”异常值:
- 给激活值应用通道级的缩放(减少异常值)
- 给权重应用反向缩放(权重更能扛得住这个调整)
- 这样一来,激活值和权重都能量化到INT8,而且不会损失准确率
这种方法特别适合部署场景,因为全INT8推理能带来显著的速度提升。
结语
量化已经成为在消费级硬件上运行大型语言模型最实用的解决方案啦,它能立刻把内存减少4-8倍,同时还能保持模型的质量。从咱们动手做的实验里,咱们也看到了INT8和4位技术能把需要昂贵服务器GPU的模型变成能在笔记本上舒舒服服运行的模型。
从基础的线性量化发展到像GPTQ、AWQ和SmoothQuant这样复杂的方法,反映了这个领域的成熟。这些可不是学术上的奇思妙想,而是能直接用在生产环境里的工具,它们能在大大减少计算需求的同时保留模型的智能。最吸引人的是它们的易用性,现代的量化方法只要几行代码就能作为即插即用的替代品。
模型越来越大,但多亏了量化,它们也越来越容易接触到了。这种组合有望加速整个领域的创新呢。