mysql核心知识点
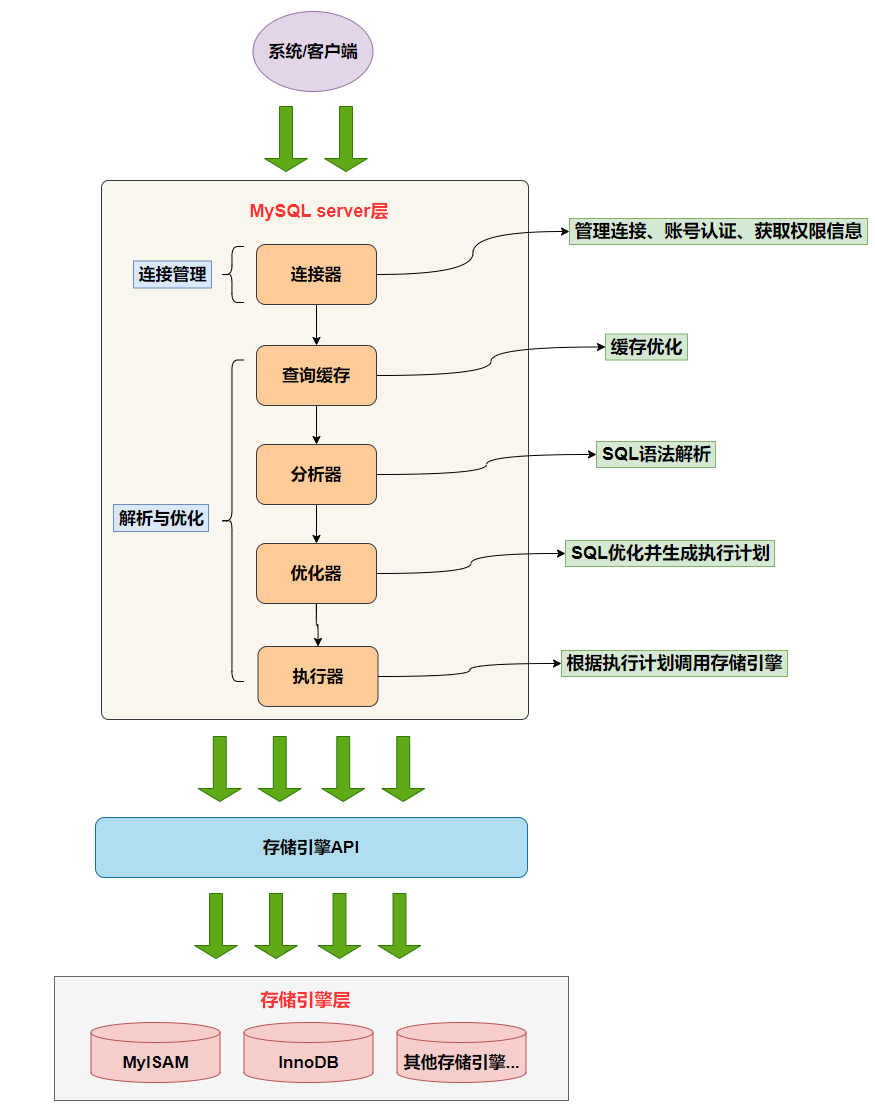
Server 层负责建立连接、分析和执行 SQL。MySQL 大多数的核心功能模块都在这实现,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。另外,所有的内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等。)都在 Server 层实现。
存储引擎层负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。现在最常用的存储引擎是 InnoDB,从 MySQL 5.5 版本开始, InnoDB 成为了 MySQL 的默认存储引擎。我们常说的索引数据结构,就是由存储引擎层实现的,不同的存储引擎支持的索引类型也不相同,比如 InnoDB 支持索引类型是 B+树 ,且是默认使用,也就是说在数据表中创建的主键索引和二级索引默认使用的是 B+ 树索引。
第一步:连接器
连接的过程需要先经过 TCP 三次握手,因为 MySQL 是基于 TCP 协议进行传输的
如果用户密码都没有问题,连接器就会获取该用户的权限,然后保存起来,后续该用户在此连接里的任何操作,都会基于连接开始时读到的权限进行权限逻辑的判断。所以,如果一个用户已经建立了连接,即使管理员中途修改了该用户的权限,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
MySQL 的连接也跟 HTTP 一样,有短连接和长连接的概念
第一种,定期断开长连接。既然断开连接后就会释放连接占用的内存资源,那么我们可以定期断开长连接。第二种,客户端主动重置连接。MySQL 5.7 版本实现了 mysql_reset_connection() 函数的接口,注意这是接口函数不是命令,那么当客户端执行了一个很大的操作后,在代码里调用 mysql_reset_connection 函数来重置连接,达到释放内存的效果。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
与客户端进行 TCP 三次握手建立连接;
• 校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
• 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限;
第二步:查询缓存
对于更新比较频繁的表,查询缓存的命中率很低的,MySQL 8.0 版本直接将查询缓存删掉了,也就是说 MySQL 8.0 开始,执行一条 SQL 查询语句,不会再走到查询缓存这个阶段了。
第三步:解析 SQL
词法分析、语法分析
第四步:执行 SQL
每条SELECT 查询语句流程主要可以分为下面这三个阶段:• prepare 阶段,也就是预处理阶段;• optimize 阶段,也就是优化阶段;• execute 阶段,也就是执行阶段;
预处理:检查 SQL 查询语句中的表或者字段是否存在;• 将 select * 中的 * 符号,扩展为表上的所有列;
优化器:优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。当然,我们本次的查询语句(select * from product where id = 1)很简单,就是选择使用主键索引。要想知道优化器选择了哪个索引,我们可以在查询语句最前面加个 explain 命令,这样就会输出这条 SQL 语句的执行计划,然后执行计划中的 key 就表示执行过程中使用了哪个索引,比如下图的 key 为 PRIMARY 就是使用了主键索引。
执行器:
- 主键索引查询
使用主键索引查询一条记录,那么执行器与存储引擎的执行流程是这样的:
• 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为 InnoDB 引擎索引查询的接口,把条件 id = 1 交给存储引擎,让存储引擎定位符合条件的第一条记录。
• 存储引擎通过主键索引的 B+ 树结构定位到 id = 1的第一条记录,如果记录是不存在的,就会向执行器上报记录找不到的错误,然后查询结束。如果记录是存在的,就会将记录返回给执行器;
• 执行器从存储引擎读到记录后,接着判断记录是否符合查询条件,如果符合则发送给客户端,如果不符合则跳过该记录。
• 执行器查询的过程是一个 while 循环,所以还会再查一次,但是这次因为不是第一次查询了,所以会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为一个永远返回 - 1 的函数,所以当调用该函数的时候,执行器就退出循环,也就是结束查询了。
const 是 MySQL 优化器判定的一种访问类型(Access Type),表示查询结果最多只有一行数据,且这一行数据在查询执行阶段可以被视为 “常量”。
-
核心特点:
-
通过主键索引或唯一索引的等值条件(如
WHERE id = 123)直接定位到唯一记录。 -
优化器在执行查询前即可确定具体的行,无需逐行扫描或二次查找。
-
访问类型的优先级极高,属于最优等级的查询方式之一。
-
-
全表扫描
执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 all,这个函数指针被指向为 InnoDB 引擎全扫描的接口,让存储引擎读取表中的第一条记录;
• 执行器会判断读到的这条记录的 name 是不是 iphone,如果不是则跳过;如果是则将记录发给客户的(是的没错,Server 层每从存储引擎读到一条记录就会发送给客户端,之所以客户端显示的时候是直接显示所有记录的,是因为客户端是等查询语句查询完成后,才会显示出所有的记录)。
• 执行器查询的过程是一个 while 循环,所以还会再查一次,会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 all,read_record 函数指针指向的还是 InnoDB 引擎全扫描的接口,所以接着向存储引擎层要求继续读刚才那条记录的下一条记录,存储引擎把下一条记录取出后就将其返回给执行器(Server层),执行器继续判断条件,不符合查询条件即跳过该记录,否则发送到客户端;
• 一直重复上述过程,直到存储引擎把表中的所有记录读完,然后向执行器(Server层) 返回了读取完毕的信息;
• 执行器收到存储引擎报告的查询完毕的信息,退出循环,停止查询。
- 索引下推
索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。对 age 和 reward 字段建立了联合索引
现在有下面这条查询语句:select * from t_user where age > 20 and reward = 100000;
联合索引当遇到范围查询 (>、<) 就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。那么,不使用索引下推(MySQL 5.6 之前的版本)时,执行器与存储引擎的执行流程是这样的:
• Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
• 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
• Server 层在判断该记录的 reward 是否等于 100000,如果成立则将其发送给客户端;否则跳过该记录;
• 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
• 如此往复,直到存储引擎把表中的所有记录读完。可以看到,没有索引下推的时候,每查询到一条二级索引记录,都要进行回表操作,然后将记录返回给 Server,接着 Server 再判断该记录的 reward 是否等于 100000。而使用索引下推后,判断记录的 reward 是否等于 100000 的工作交给了存储引擎层,过程如下 :
• Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
• 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(reward列)的条件(reward 是否等于 100000)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
• Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
如此往复,直到存储引擎把表中的所有记录读完。可以看到,使用了索引下推后,虽然 reward 列无法使用到联合索引,但是因为它包含在联合索引(age,reward)里,所以直接在存储引擎过滤出满足 reward = 100000 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
总结:
连接器:建立连接,管理连接、校验用户身份;• 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;• 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;• 执行 SQL:执行 SQL 共有三个阶段:◦ 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。◦ 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;◦ 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
