【存储基础】NUMA架构
文章目录
- 1. 前置知识:物理CPU和CPU核心
- 物理CPU
- CPU核心
- 关系
- 2. NUMA架构
- 2.1 NUMA架构是什么?
- 2.2 NUMA架构详解
- 2.3 查看NUMA信息
- 2.4 NUMA架构在分布式存储中的应用
- 数据本地化 Data Locality
- 计算与存储协同调度
- NUMA感知的网络通信
- 内存池优化与跨节点均衡
- 3 补充:线程绑核
1. 前置知识:物理CPU和CPU核心
物理CPU
物理CPU是指独立的物理处理器芯片,通过插槽安装在主板上。一个物理CPU可能包含多个CPU核心、缓存、内存控制器等组件。服务器主板可支持多个物理CPU,比如双路就表明支持两个物理CPU。
CPU核心
CPU核心是物理CPU内部的独立计算单元,每个核心具备完整的执行能力,有自己的ALU、寄存器、L1/L2缓存等。CPU核心是物理CPU内部的子单元,不可物理拆分,每个核心可独立运行一个线程(单线程核心)或通过超线程支持多线程
关系
可以把物理CPU理解成一个容器,一个物理CPU可以包含多个CPU核心;核心是执行单元,实际执行指令的最小物理单位。
多个核心可同时处理不同任务;同一个物理CPU内的核心共享L3缓存、内存控制器、PCIe通道。
| 特性 | 物理CPU | CPU核心 |
|---|---|---|
| 本质 | 物理硬件设备(芯片) | 物理CPU内部的子计算单元 |
| 数量层级 | 服务器常见1-8个 | 每个物理CPU含4-128个核心 |
| 功能 | 集成核心、缓存、I/O控制器 | 执行指令和运算 |
| 超线程影响 | 不直接受影响 | 1个物理核心可虚拟为2个逻辑核心 |
| 资源隔离 | 不同物理CPU之间资源完全隔离(如缓存) | 同物理CPU的核心共享L3缓存和内存通道 |
2. NUMA架构
2.1 NUMA架构是什么?
NUMA(Non-Uniform Memory Access非统一内存访问)是一种多处理器计算机系统设计架构,旨在解决传统对称多处理器(SMP)架构中内存访问延迟和带宽瓶颈的问题。
NUMA的核心思想是将多个CPU和内存资源划分为多个节点 Node,每个结点内的CPU可以直接访问本地内存(延迟低、带宽高),而访问其他节点的内存(远端内存)则需要经过互联总线(延迟高、带宽低)。
2.2 NUMA架构详解
numa架构的组成:
- 节点Node:每个节点包括
- 一组CPU核心,称为Socket或NUMA Node;
- 本地内存;
- 互联总线
- 内存访问模式:
- 访问本地内存:CPU直接访问本节点内存,速度快;
- 远端内存访问:CPU跨节点访问其他节点的内存
NUMA架构的特点:
- 非对称延迟:本地内存访问快,远端内存访问慢;
- 扩展性优势:支持更多CPU和内存,避免SMP架构的总线争用问题;
- 本地化优化:操作系统和应用程序需尽量使用本地内存,减少跨节点访问;
- 硬件透明性:对应用程序透明
2.3 查看NUMA信息
numactl --hardware # 查看numa节点拓扑
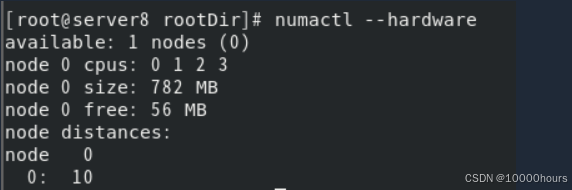
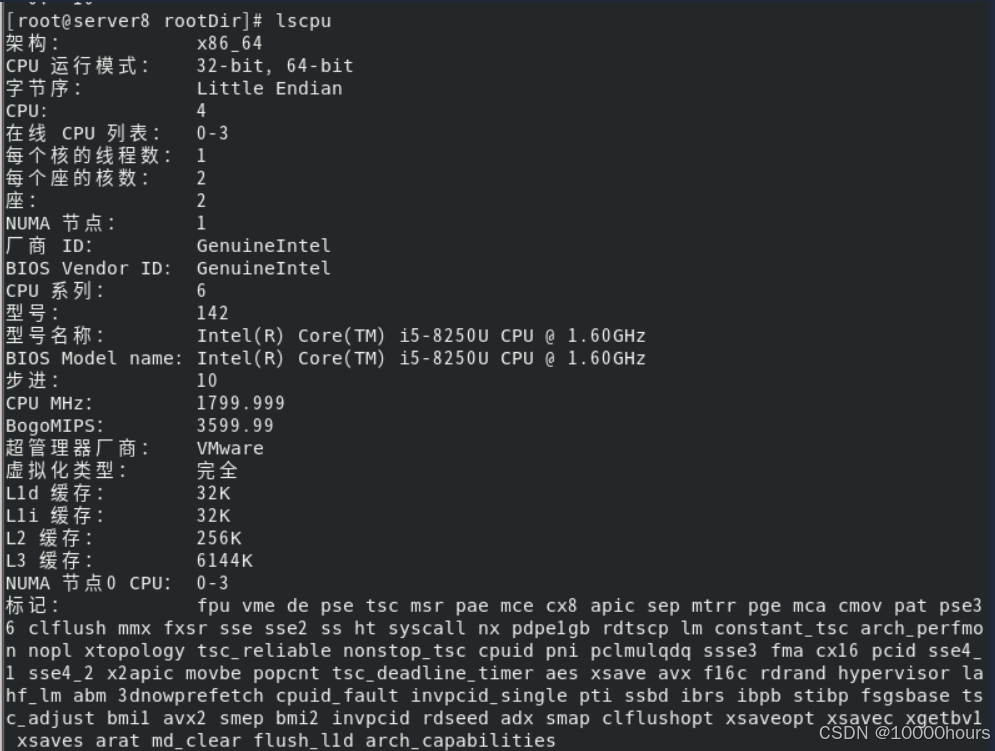
lscpu
2.4 NUMA架构在分布式存储中的应用
数据本地化 Data Locality
将数据存储在处理它的NUMA节点的本地内存中,减少跨节点访问。
实现方式:
- 存储分片策略:将数据分片(shard)绑定到特定NUMA节点,例如numa_0处理shard_0的数据,numa_1处理shard_1的数据;
- 元数据管理:记录数据分片与NUMA节点的映射关系,确保读写请求优先路由到本地结点
计算与存储协同调度
将计算任务调度到数据所在的NUMA节点,实现“存算一体”。
实现方式:
- 任务绑定:将存储服务的进程/线程绑定到特定NUMA节点的CPU核心;
- 内存分配策略:强制进程从本地NUMA节点分配内存。
NUMA感知的网络通信
减少网络数据包处理中的跨节点内存复制。
实现方式:
- 网卡绑定到NUMA节点:将网卡与NUMA节点关联,确保网卡的中断和DMA内存区域位于同一节点;
- 零拷贝技术:避免数据在用户态和内核态间的多次复制
例如高性能存储网络(如IB, InfiniBand)通过RDMA直接访问远端NUMA节点的内存,绕过操作系统和CPU干预。
内存池优化与跨节点均衡
在NUMA节点间动态平衡内存使用,避免热点和资源耗尽。
实现方式:
- 内存交错:将内存分配均匀分散到多个NUMA节点(牺牲局部性换取均衡);
- 动态迁移:监控NUMA节点的内存压力,将冷数据迁移到空闲节点
3 补充:线程绑核
线程绑核是将特定线程/进程绑定到指定CPU核心上运行的机制,目的是减少上下文切换、提升缓存命中率、避免跨核心/跨NUMA节点的性能损失。
线程绑核的优势:
- 减少上下文切换:操作系统默认动态调度线程到不同的核心,频繁切换可能导致缓存失效和延迟;
- 提升缓存利用率:线程固定在某个核心之后,其缓存(L1/L2/L3)中的数据可长期保留;
- 避免NUMA延迟:绑核可强制线程在本地NUMA结点运行;
- 实时性需求:某些应用场景下要求严格的任务响应时间。
可使用Linux的taskset工具将线程绑定到核心;或numactl工具将线程绑定到NUMA节点。