AI炼丹日志-27 - Anubis 通过 PoW工作量证明的反爬虫组件 上手指南 原理解析
点一下关注吧!!!非常感谢!!持续更新!!!
Java篇:
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
大数据篇 300+:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)

基本介绍
官方地址
https://anubis.techaro.lol/docs/design/why-proof-of-work
核心理念
Anubis 采用类似于区块链挖矿的机制 —— Proof-of-Work(工作量证明),通过要求访问者在请求前完成一定的计算任务,来有效阻止自动化爬虫脚本对网站内容的抓取。
对人类用户几乎无感,但会显著增加爬虫成本和请求延迟。
官方介绍
Anubis 会“称量”你连接的“灵魂”,通过一道工作量证明(PoW)挑战,来保护上游资源不被爬虫程序滥用。
● PoW 机制:访问网页前必须完成一次 SHA256 Hash-based 运算(需要找到一个 nonce 使得哈希值满足某种前缀条件)
● 轻量无状态部署:可直接作为中间件接入 Web 项目,无需数据库
● 防御方式灵活:可配置访问频率限制、黑名单、白名单机制
● 兼容性强:可作为反向代理层组件使用,也可以集成进 Flask、Express、NGINX 等中间件架构
● 自定义难度:支持配置计算任务难度,适配不同的网络环境和安全需求
● 对正常用户影响小:支持 JS + WebAssembly 实现快速计算,首次验证后会缓存通行令牌,减少重复计算
应用场景
● 网站防爬(不依赖验证码)
● 对抗恶意扫描、暴力破解尝试
● 保护公开 API 接口免于被批量滥用
● 替代或增强 CAPTCHA 的轻量解决方案
工作流程
● 用户请求页面 → 被拦截
● 服务器返回 PoW 挑战(如:哈希前缀为 00000)
● 浏览器或客户端完成计算,返回答案(nonce)
● 验证通过后颁发访问令牌,后续访问直接放行
安装项目
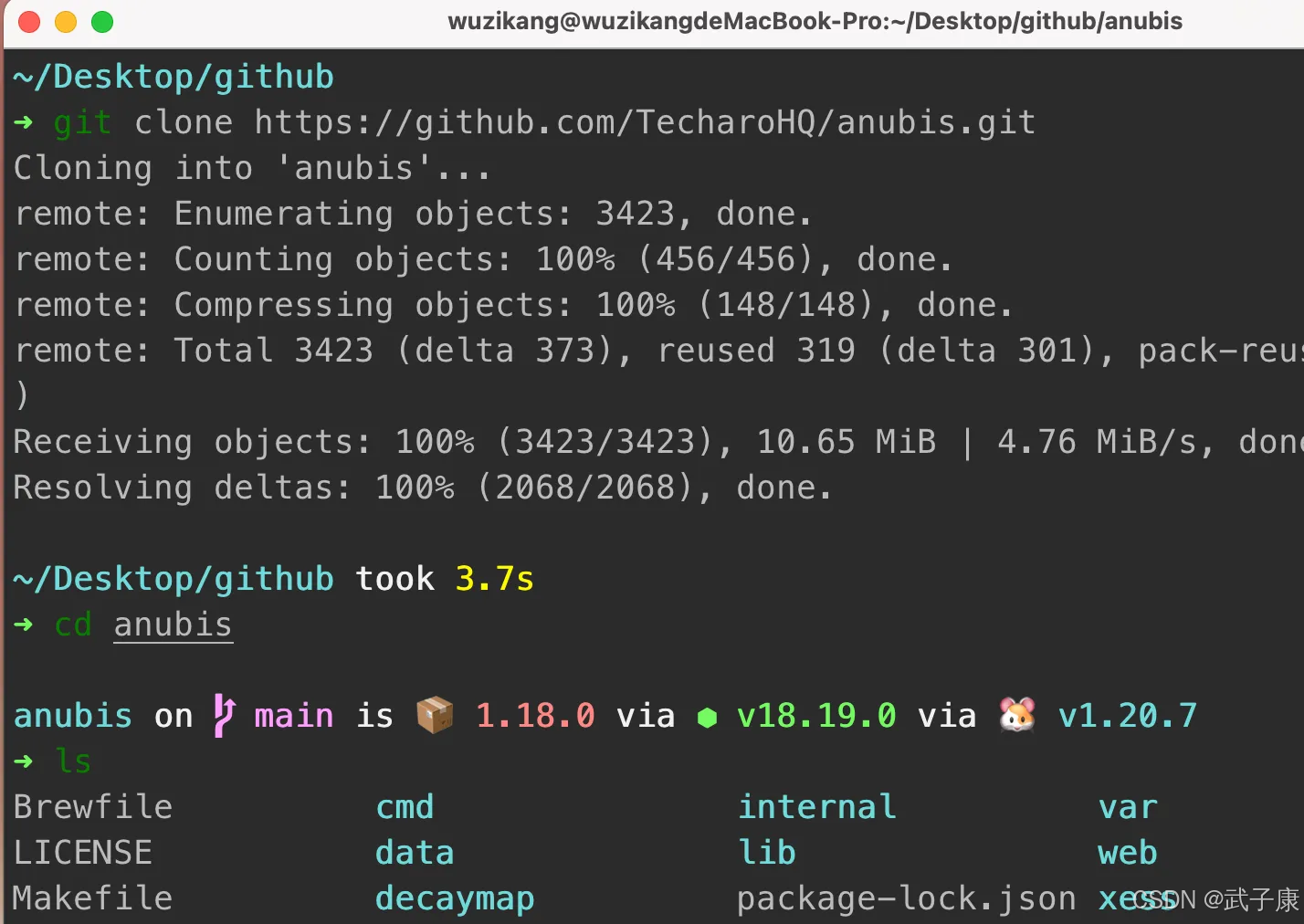
克隆项目
git clone https://github.com/TecharoHQ/anubis.git
克隆后进入项目:
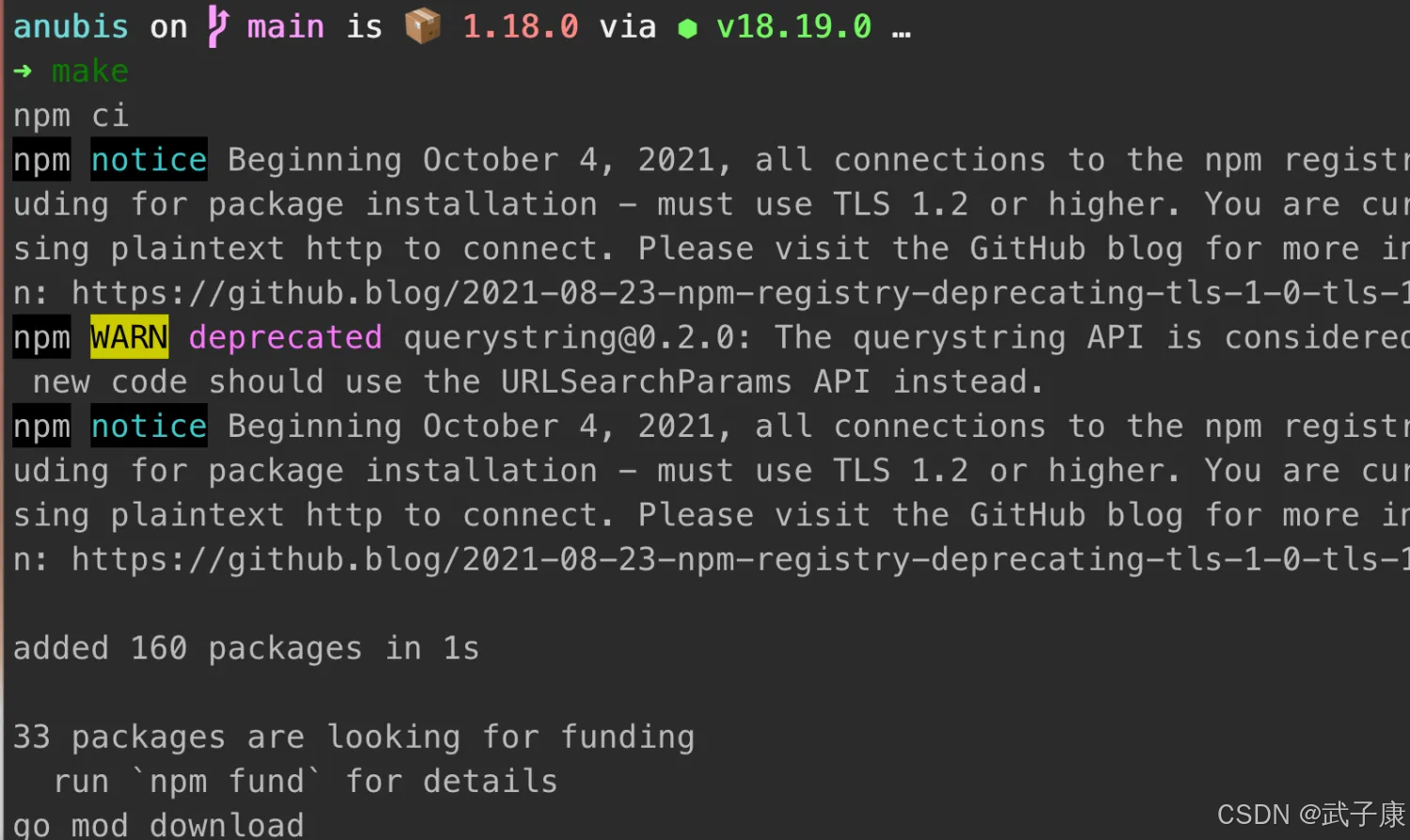
构建项目
我们使用 make 编译:
make
需要耐心等待:
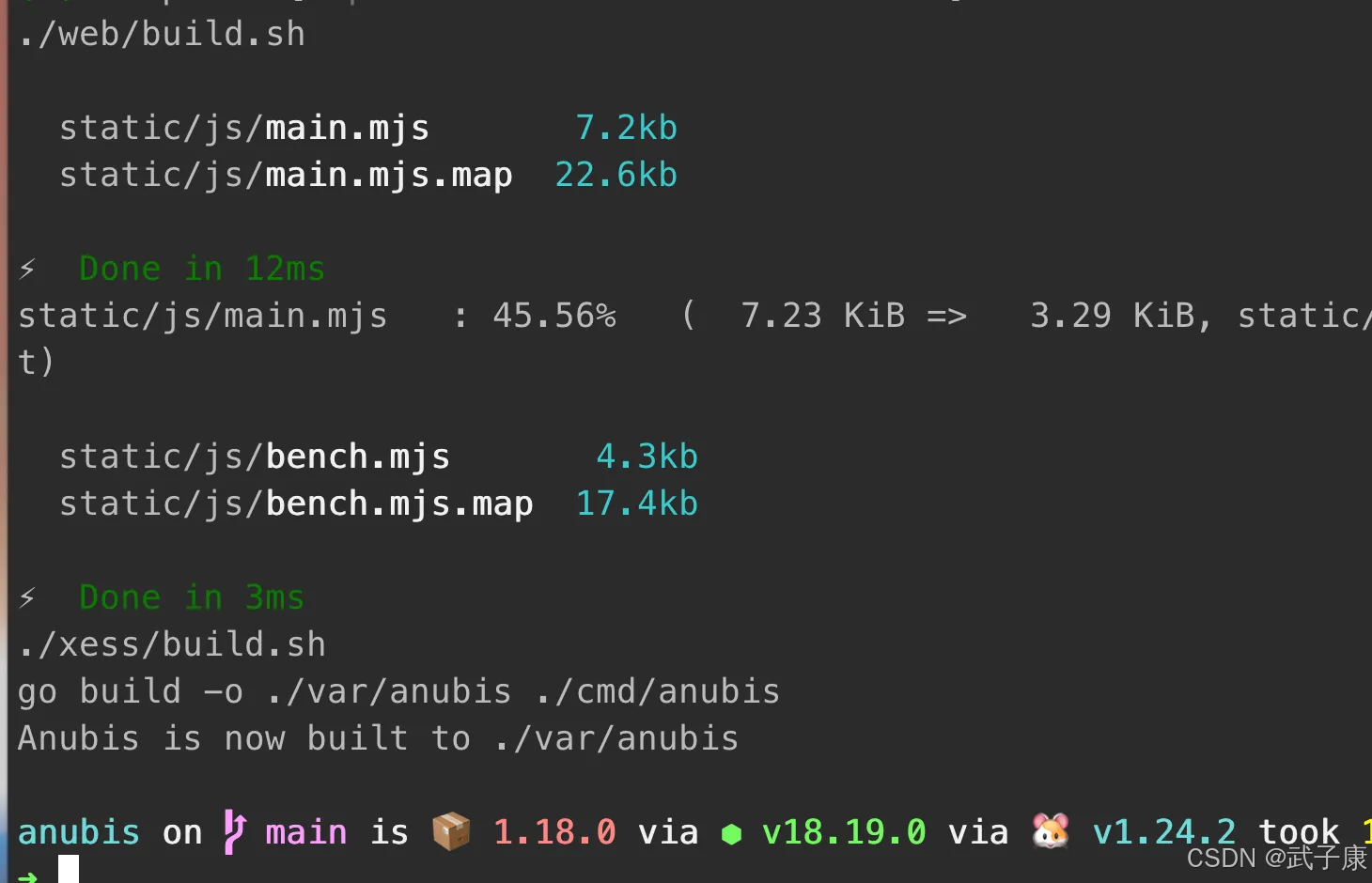
如果顺利编译结束可以看到:
测试项目
编译完成之后,我们可以通过配置参数来进行配置:
./var/anubis -target http://localhost:8888 -use-remote-address
需要解释一下:
● -target 就是做完 PoW 校验之后,要转发到的地址
● -use-remote-address 如果你不配置该参数,你需要通过 NGINX->Anubis->你的服务,需要转发才可以。这种适合本地测试,如果上线的话,则去掉。
运行之后,可以看到正常输出了日志:
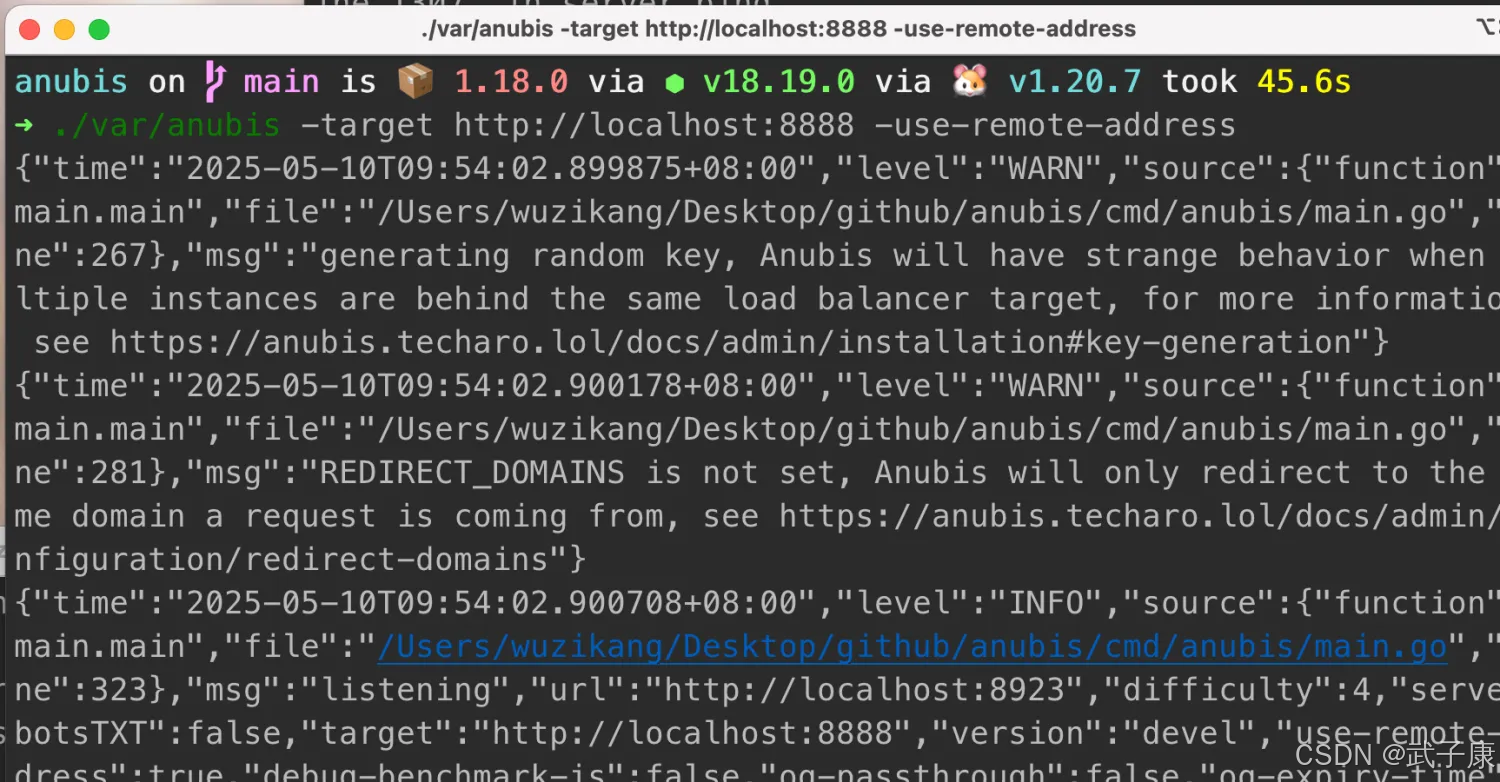
当中比较重要的内容,主要是服务的地址、目标服务的地址、计算难度等内容:
{"time": "2025-05-10T09:54:46.832563+08:00","level": "INFO","source": {"function": "main.main","file": "/Users/wuzikang/Desktop/github/anubis/cmd/anubis/main.go","line": 323},"msg": "listening","url": "http://localhost:8923","difficulty": 4,"serveRobotsTXT": false,"target": "http://localhost:8888","version": "devel","use-remote-address": true,"debug-benchmark-js": false,"og-passthrough": false,"og-expiry-time": 86400000000000,"base-prefix": "","cookie-expiration-time": 604800000000000,"rule-error-ids": {"ai-robots-txt": "8e399aa8f9f5d95a8cd0ad01284ea904784a854e9c6ab17ac9994f479d18aaed","cloudflare-workers": "559e7f01707b78efda8b0ed791e13d0e0079fbf0e3c81c8dfaf2299537f8b666","deny-aggressive-brazilian-scrapers": "c6664788c65ba3a1fbc2df151564b216b65a05a6828f94c63e1226c4d971cfca","headless-chrome": "b2dd0d54fa37a160ed04d152bcdde5df296a5861e0a6ef6a4fe845ef51d93be0","headless-chromium": "900a0b88e9bcd4ae0772b55c198f6fb9e0e352da8af4ed61f7f72df1391f85a2","lightpanda": "8c4f381bde0fabcd361c88ec7f015d981fd7f80f3edcb16e670ed0bc772eb62d","us-artificial-intelligence-scraper": "5f0cb91e78d0499d22892c79e1520ccb378e98d3836effbd1ad675721bd46ac1"}
}
访问项目:
http://localhost:8923
我们访问之后,可以看到需要先进行一个 PoW 的计算,计算通过后才会转发到对应的地址上:
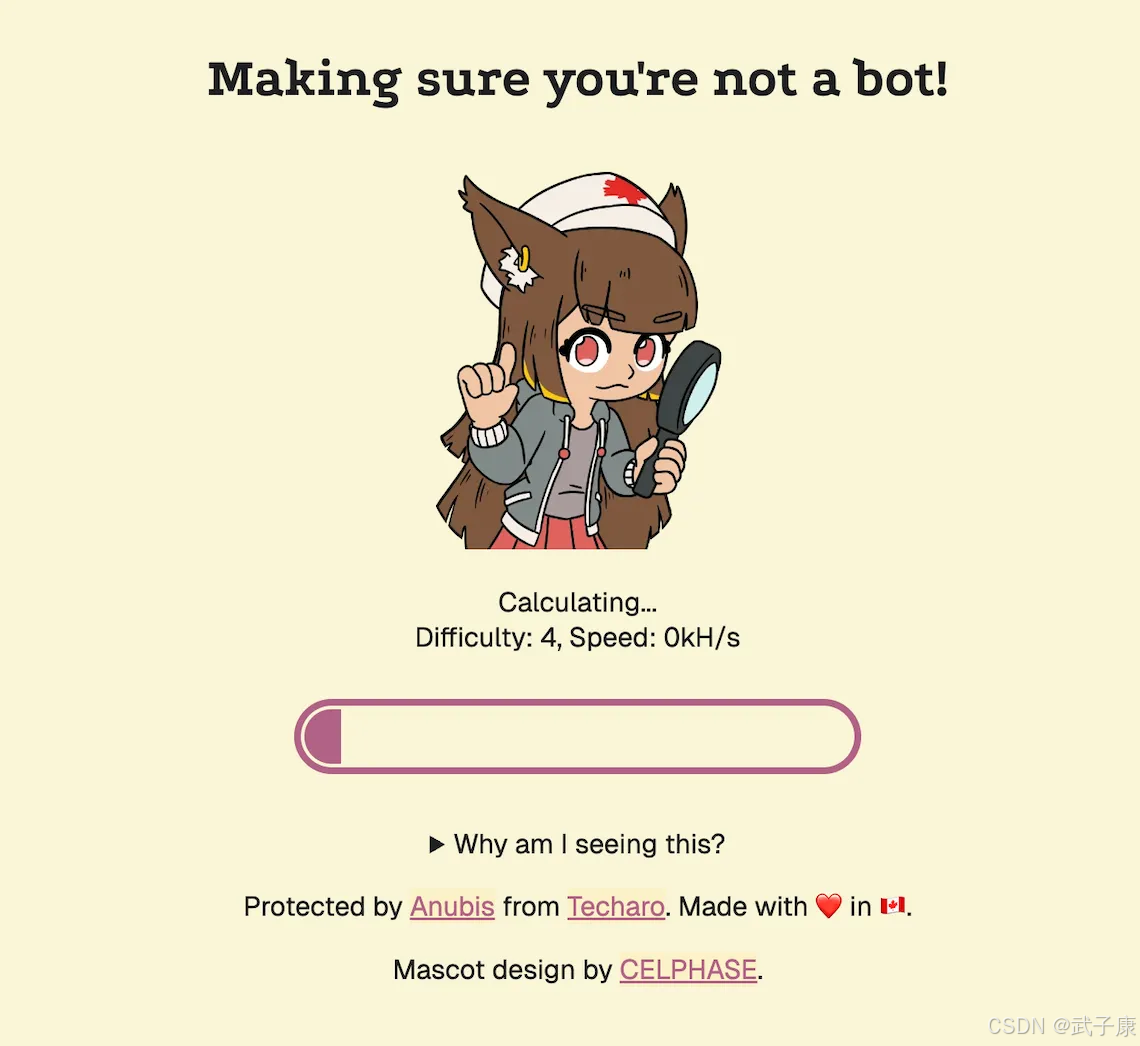
简易分析
工作原理
如下图所示:
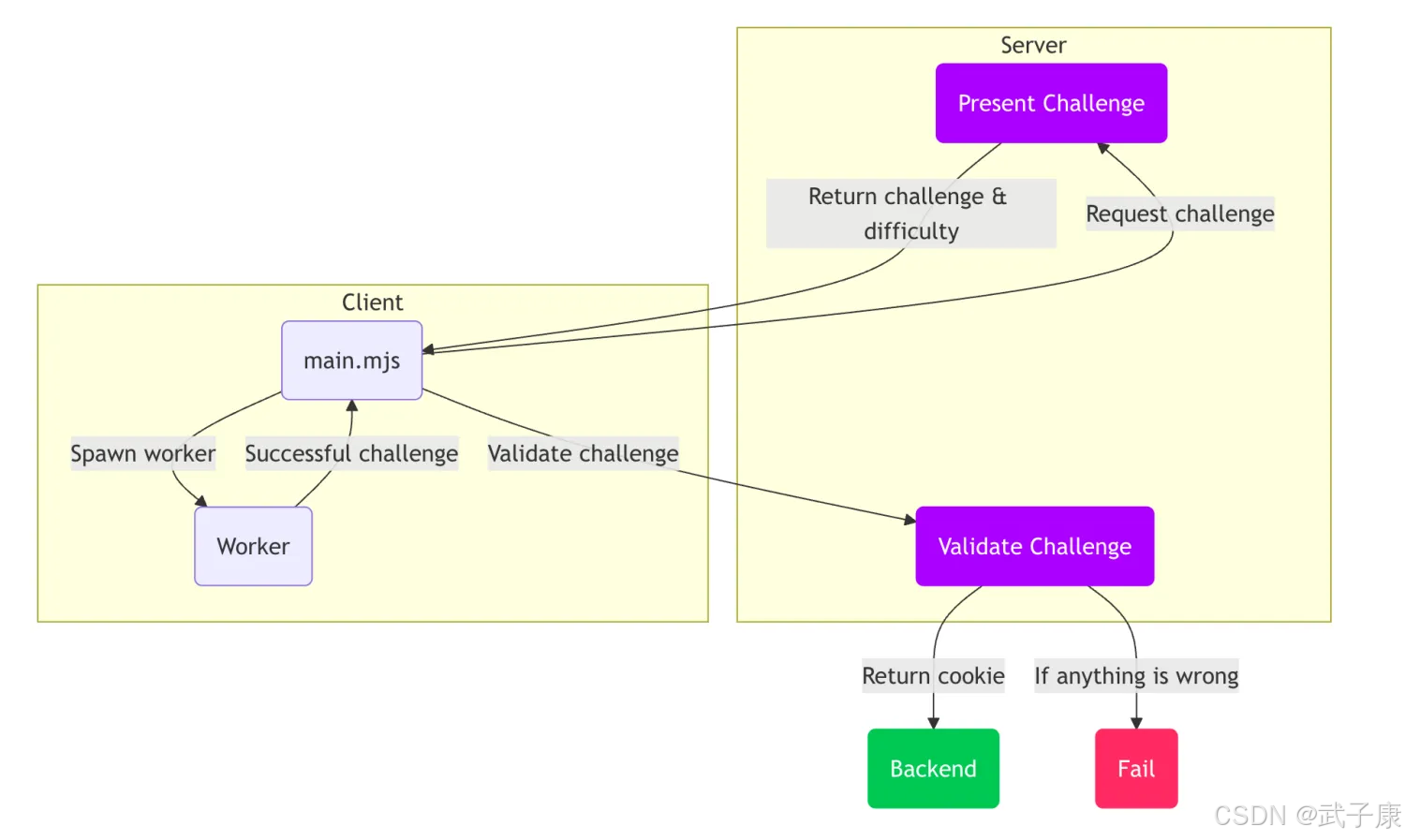
主要是进行一个 SHA-256 的计算,比如要求客户端算出一个开头是 “0000” 的值才可以,那客户端会进行 SHA-256 的多次计算,直到结果的开头是:“0000” 则结束。
当然,这个计算并不会每次都进行,不然如果一个页面反复计算的话,也会给用户带来很不好的体验。
所以当客户端通过计算之后,会在 HTTP 的 Cookie 中加一个: “within.website-x-cmd-anubis-auth”,当中的内容用的是 JWT实现的,当中含有的内容有:
● challenge:根据用户请求的元数据生成的挑战字符串
● nonce:用于生成通过验证结果的 nonce 值(即迭代次数)
● response:通过 Anubis 校验的哈希值(计算结果)
● iat(Issued At):令牌的签发时间
● nbf(Not Before):令牌的生效时间,通常是签发时间的前一分钟
● exp(Expiration):令牌的过期时间,通常是签发后一周
为什么用SHA-256
PS:来自官方的解释
Anubis 使用工作量证明(Proof of Work)机制来验证客户端是否为真实用户。
其灵感来源于 Hashcash,这是 2000 年代初提出的一种方案,旨在通过扩展电子邮件协议来防止垃圾邮件。
这个想法的核心是:
真实用户在发送邮件前需要完成一个小型的数学问题,比如 对一个字符串进行哈希运算,使结果具有指定数量的前导零。
这种计算 对个人用户来说开销很小(一周发几封邮件几乎无影响),
但对于那些 大规模发送广告邮件的公司来说,这样的计算代价会变得非常高昂,起到抑制作用。
这种机制的原理,实际上也是 比特币共识算法(挖矿) 的基础。