代谢组数据分析(二十六):LC-MS/MS代谢组学和脂质组学数据的分析流程
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者!
文章目录
- 介绍
- 加载R包
- 依赖包
- 安装包
- 加载需要的R包
- 数据下载以及转换mzML
- 数据预处理
- 代谢物注释
- LipidFinder过滤
- MultiABLER数据预处理
- 过滤
- 补缺失值
- 对数变换
- 数据标准化
- 下游数据分析
- 总结
- 系统信息
- 参考
介绍
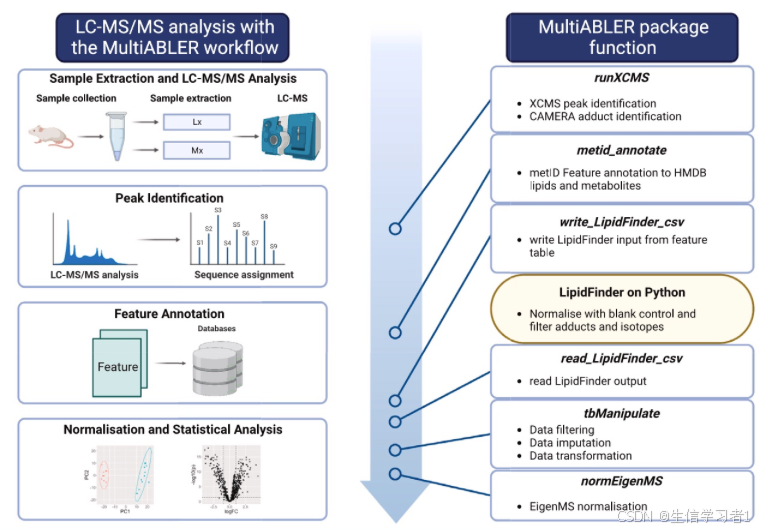
LC-MS/MS(液相色谱-串联质谱)分析在代谢组学和脂质组学中扮演着至关重要的角色。整个分析流程从样本的采集和提取开始。首先,需要从生物样本中提取代谢物或脂质,这一步骤通常涉及使用特定的溶剂和方法来分离目标化合物。接下来,提取的样本通过液相色谱系统进行分离,该系统能够根据化合物的化学性质(如极性和分子大小)对其进行分离。分离后的化合物随后进入质谱仪进行检测,质谱仪通过测量离子化后的化合物的质量/电荷比(m/z)来识别和定量这些化合物。
在质谱分析过程中,峰识别是一个关键步骤,它涉及到从质谱数据中识别出特定的峰,这些峰对应于特定的化合物。通过序列分配,可以将这些峰与已知的化合物或数据库中的条目进行匹配,从而实现化合物的鉴定。随后,特征注释步骤将这些识别出的化合物与数据库中的信息进行关联,以获取更多关于这些化合物的详细信息,如其生物功能或参与的代谢途径。
最后,为了确保数据的可靠性和可比性&