网络协议的原理及应用层
网络协议
网络协议目的为了减少通信成本,所有的网络问题都是传输距离变长的问题。
协议的概念:用计算机语言来发出不同的信号,信号代表不同的含义,这就是通信双方的共识,便就是协议。
协议分层(语言层和通信设备层):
软件层优势:为了解耦,分层后,对任意一层做更改,不会影响其它层,一层出问题,不影响系统正常工作,为了更好的封装。
分层方式的优势:功能比较集中,耦合度比较高的模块放在同一层,高内聚。
分层依据:
每一层都要解决特定的问题
第一个问题:传递数据的能力
第二个问题:朝那个方向去传数据,就是路径选择能力
第三个问题:网络容错的纠错能力
第四个问题:解决数据应用方面的能力
OSI七层模型
上三层:应用能力,由用户去实现,去设置。
TCP/IP五层协议
物理层,数据链路层,网络层,传输层,应用层(负责建立和断开通信连接,网络传输格式,针对特定应用的协议)。
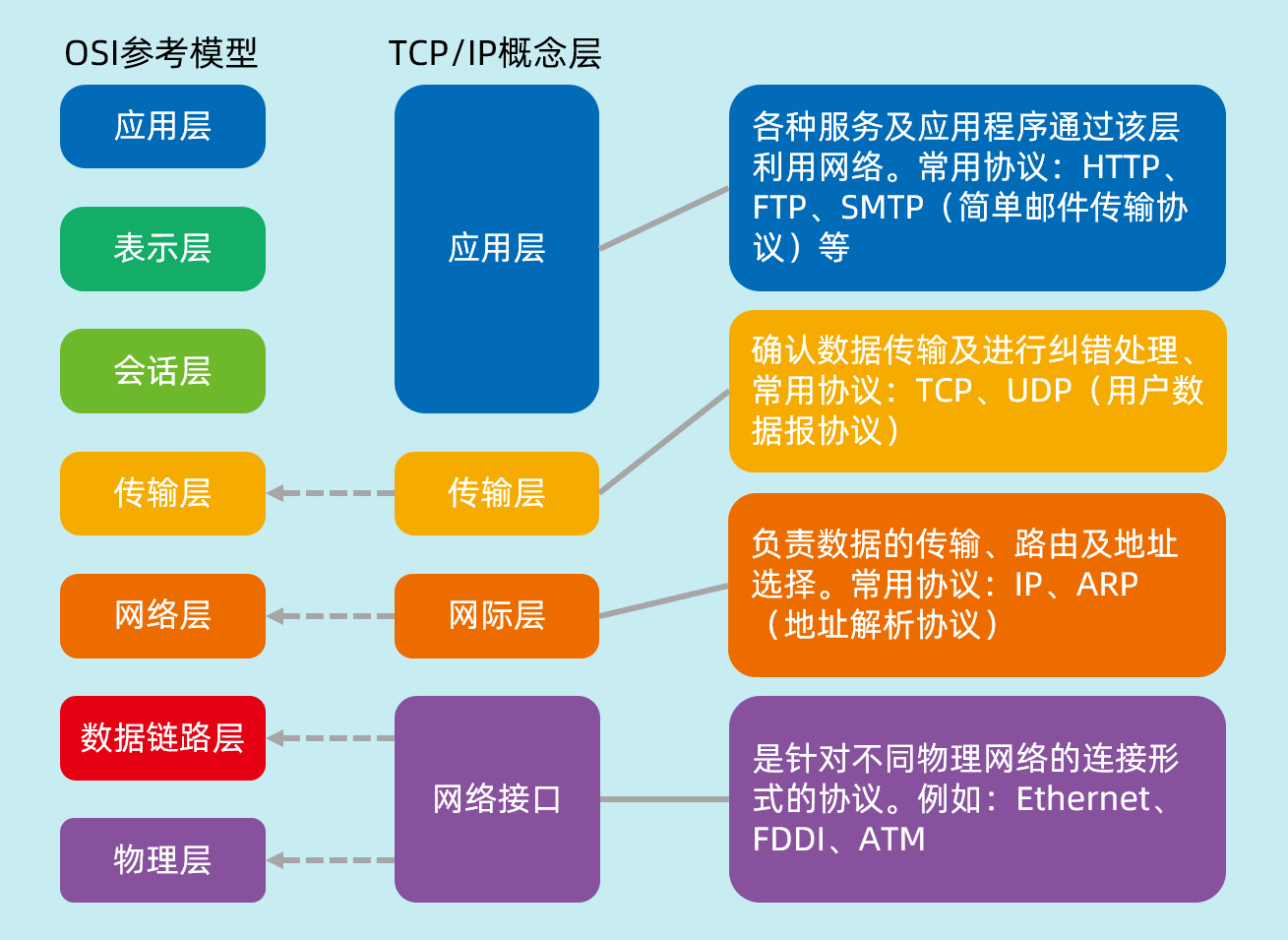
物理层(硬件):光/电信号的传递方式,主要是硬件电路。集线器(Hub)作用:当信息长距离传输时,信号衰弱时,可以进行信息放大,增大传播距离。调制解调器(modem)作用:负责信号的转换,把模拟信号和数字信号互相转换,用光纤连接到路由器,路由器构建成局域网。双绞线:水晶头作用:当作网线来使用。解决传输速率和距离,抗干扰能力。
数据链路层:网卡:连着网线,0/1信号的传输和识别 驱动程序实现
网络层:路径选择,地址和路由管理 os实现
传输层:纠错,确保两台主机之间通信数据可靠性 os实现
系统调用在两者之间
应用层:应用程序的实现
网络传输基本流程
局域网下:.协议报头:每层都有协议,而每一个协议最终表现就是协议都要有报头。而这个报头的作用就是包装数据的信息的容器,类似于快递单,而信息就是协议,类似于快递单的内容。协议通常时通过协议报头来表达的。每一份数据最终在被发送或者在不同的协议层中,都要有自己的报头。
IP地址(局域网和广域网)
规则:IPv4协议(点分十进制)
概念:IP地址是用来标识网络中不同主机的地址,用32位来表示。用来表示从起始位置到终点,IP地址提供方向,位置不会发生变化,它决定了途径点,方便进行路径选择。类似于:从哪里来,到哪里去。
MAC地址(局域网)
概念:地址会变化,位置变化,mac就会变化,阶段目的地。类似于:上一站来自哪里,下一站去哪里。
应用层
网络套接字
套接字有:网络套接字,域间套接字等
端口号(port)
概念:1.2个字节 2.端口号告诉os,网络通信的数据要给那个进程 3.IP地址和端口号能够标识网络上的某台主机的某一个进程。4.一个端口号只能被一个进程占用
需知两台主机通信目的:
把数据从A从到B的过程只是传输手段,不是目的。目的是:两台机器上面的软件通信。
数据有公网IP来标识一台唯一的主机。而端口号标识主机上的服务器进程,客户端进程的唯一性,让os将数据给哪一个进程。
网络通信的本质是进程间间通信通过IP地址+端口号进行唯一标识,然后客户端进程和服务器进程的通信。而网络通信的操作就是IO(发出数据,让别人看到数据)
规则:
IP全网唯一,端口号主机内部唯一。一个端口号一个进程,多个端口号一个进程。
端口使用的原因:
系统是系统,网络是网络,这一原理决定了,需要一个不同于pid的数字来标识网络中的进程,强耦合。其次,存在单机的进程,它有pid而没有端口号,因此这种进程需要用有无端口号来辨别它是否单机。pid会轻易发生改变,而端口号不能随意发生改变,因为需要客户端每次都能找到服务器进程。
端口号的用法:
IP地址+端口号进行唯一标识一个主机中唯一个进程,os通过哈希表的方法用端口号映射文件描述表,找到文件,拷贝到缓冲区,这个就是网络通信需要的进程。而进程的pid也是为了通过哈希表映射,完成一定目的。发送数据需要知道自己的端口(源端口)和传递位置的端口(目的端口),这样才能通过端口号找到进程。
TCP协议(SOCK_STREAM)
面向连接,服务端做好后,还需要与客户端建立三次握手后,才能进行交流,这三次交流就是客户端申请链接,服务端同意链接回复客户端,客户端再进行发消息。服务端需要用listen进行监听状态,然后获取新连接accept(不能使用udp的recvfrom,sendto,因为必须被连接)
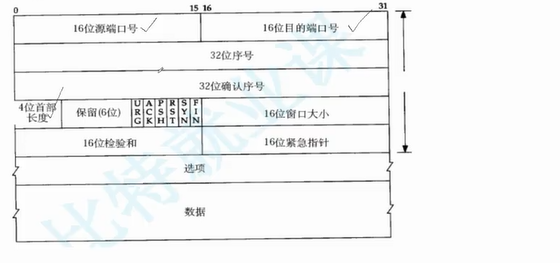
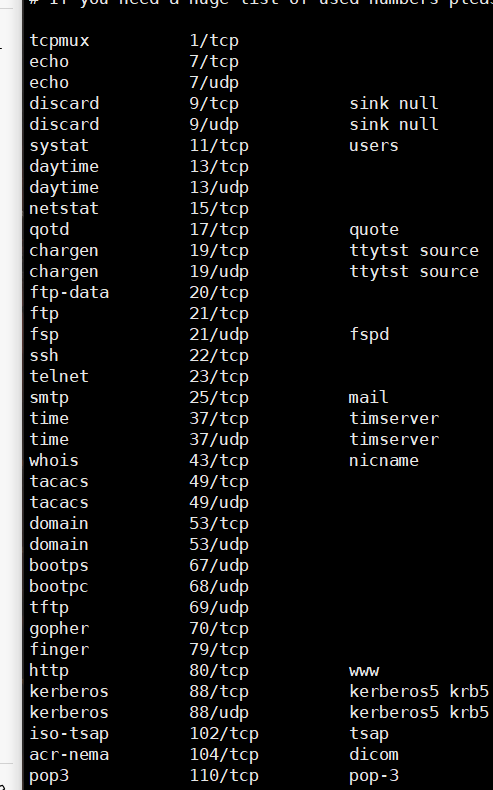
1.认识TCP协议的报头
2.如何封装解包,分用
解包tcp协议有标准长度20,先取20字节,这个20字节一定可以转换为结构化数据,立马提取标准报头中4位首部长度(tcp报头的总长度0000-1111,取值范围[0~15]),tcp报文的总长度=4位首部长度*4字节 报头总长度[0,60],[20,60]字节
分用:报头有目的端口号,就可以找到应用层的进程,数据就可以交付给进程。系统有很多进程,os会以端口号来维护哈希表找到进程PCB。
3.理解TCP的报头
一个结构体包含 源端口号,目的端口号,序号,确认序号,首部长度
结构体的对象添加数据,然后转到缓冲区就是添加报头
4.可靠性
不可靠的原因就是距离边长了,不可靠的场景丢包,乱序,校验错误,重复
1、只有收到应答,才知道对方收到了,历史消息保证可靠性
2、双方通信,一定存在新数据,没有应答,最新消息无法保证可靠性
3、不存在绝对可靠性,相对可靠性是基于确认应答
UDP协议(SOCK_DGRAM)
无连接,服务端做好,客户端就可以直接对服务端发消息
问题1:传输过程
相同点:
服务器的启动方式是相同的,都是用本地ip+端口号
区别:

网络字节序列
内存中的多字节数据相对于内存地址有大小端之分。
网络传输中的数据以先发的数据是低地址的,后发为高地址的,都是以大端传输的,而发送主句通常将数据按内存地址从低到高的顺序发出。接收主机从网络上接到的字节依次保持在接收缓冲区中,也是按内存地址从低到高的顺序保存。
大端:高权值位放低地址
小端:高权值位位放高地址
而网络是按照大端的方式存储的,而主机取决于程序员。
这是网络字节序按相应的方式与主机字节序转换的接口。
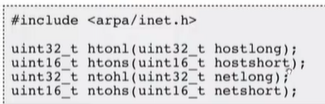
其中h代表主机,to是前一个转后一个,n是网络,l表示32为长整型,s表示16位短整型。
socket网络编程接口
socket常用的一些接口(类似于文件操作)
底层:创建一个文件,打开网卡
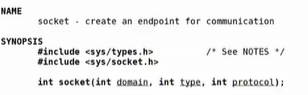
domain(AF_INET/AF_UNIX):决定通信方式:本地、网络等
type(服务能力类型(数据包,流):决定使用网络协议种类,传输什么样的格式
SOCK_STRAM/SOCK_DGRAM),protocol(选择前两者,默认选择协议):决定以udp还是tcp通信,而服务能力类型决定了协议种类,因此直接写0。STRAM是TCP,DGRAM是UDP.
返回值(sockfd):网络的文件描述符,因此可以根据返回值用操作文件的方法,处理网络通信。

addr:绑定的套接字结构体类型。sockaddr_in(ipv 4 网络套接字结构体)
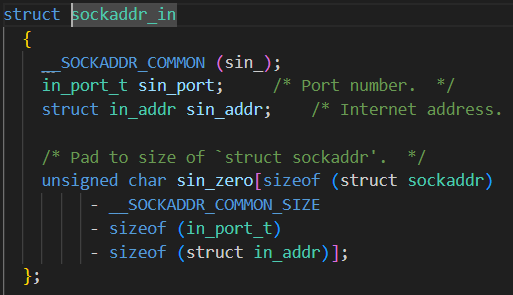
第一行:协议家族(将参数和协议家族结合成一个字符串),拼接通信方式的字符串,来决定结构体的通信方式

第二行:端口号 16位整型 因为在网络上给对方发消息,对方需要知道我的ip和端口,因此需要将端口号由本地转网络类型,而且需要进行大小端转换(htons),端口号不能随便bind,因为不同的端口号表示不同的服务
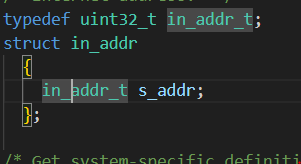
第三行:IP地址,其中in_addr是一个包含 32位的整型,因此传IP时要调用结构体成员。inet_addr
将点分十进制的字符串转换位32位整数,将这个整数转换为网络序列
注意:云服务器是应该虚拟化的服务器,不能直接bind公网ip,虚拟机可以bind自己的ip,可以进行bind内网IP,但只能在局域网中通信,因此只有绑定全0就可以都用。

小点:127.0.0.1 -》点分十进制风格的ip,特点:字符串类型,可读性好。 uin32_t ip -》整数风格ip-网络通信使用 特点:便于计算机内部使用


设计UDP:
server端的创建
void initServer(){ // 1.创建套接字 socket// 2.创建网络套接字的结构体 struct sockaddr_in ,然后对结构体初始化(bzero),填充// 3.将套接字绑定上ip和端口号 bind_sockfd = socket(AF_INET, SOCK_DGRAM, 0);if (_sockfd == -1)//判断创建成功与否{cerr << "socket error:" << errno << " : " << strerror(errno) << endl;exit(SOCKET_ERR);}cout << "socket success: " << " : " << _sockfd << endl;struct sockaddr_in local;//文件描述符绑定它的ip和端口,只定义了变量,在栈上面,属于用户,还不能进行网络通信bzero(&local, sizeof(local)); // 初始化local,全部变为0local.sin_family = AF_INET; // 设置首两个字节决定它的套接字类型local.sin_port = htons(_port); // 端口号的转入local.sin_addr.s_addr = inet_addr(_ip.c_str()); // 将点分十进制转化为整型,以及本地转网络,这个ip用0.0.0.0是为了便于用于各种对这个服务器并且对应port发更加方便。int n = bind(_sockfd, (struct sockaddr *)&local, sizeof(local)); // 将网络套接字与网络文件的结构体绑定,这样就从用户转网络了if (n == -1){cerr << "bind error:" << errno << ":" << strerror(errno) << endl;exit(BIND_ERR);}}
recvfrom这类调用接口用于接收信息,其中的src_addr 输出型参数,用于了解谁发的消息的结构体
client端:
不需要知道的ip和端口,但是需要服务器的端口和ip,这样才知道发送请求给谁,需要知道服务器的公网ip。服务端需要显示bind的原因:需要显示bind端口,服务端需要明确的端口号,不能随意改变且众所周知的。客户端需要进行bind,但是不需要显示的bind,os会自动形成端口进行bind,原因:服务端是一家公司的,客户端是无数家公司。
TCP的实现
1.服务器创建文件描述符2.服务器绑定自己的IP和端口3.创建监听描述符4.客户端发起建立连接请求5.服务端接收连接6.服务端返回已经接收连接的回答7.客户端进行发送数据8.服务端接收数据9.开始通信
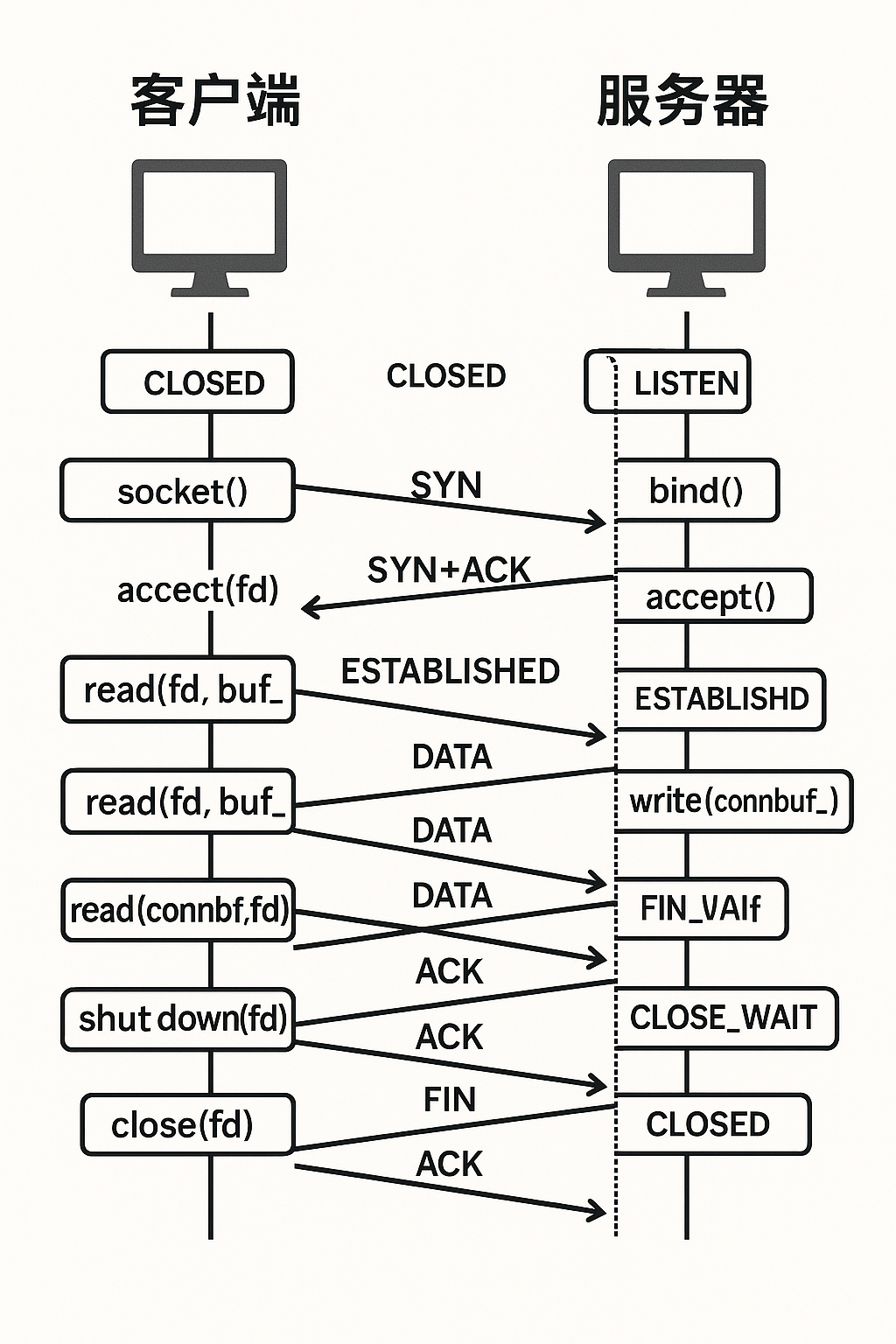
三次握手(建立连接)是os完成的申请连接,同意连接,回复接收到同意链接的回应,四次挥手(断开连接,双方都要提出)也是os完成的:1申请2单方面断联,2回复收到消息,2申请1单方面断联,1回复收到消息
accept:
参数sockfd:(用于监听) 获取新连接
返回值:用于与客户端通信,每次接收后,返回值都不一样,一个返回值对一个客户端,用于与客户端通信的套接字。提供玩服务后,需要关闭返回到套接字。
传输信息(面向字节流,类似于文件操作)
read(accept返回的套接字,字符串,大小):从文件中读取
客户端
先创建套接字,os自动bind。
connect(客户端套接字,服务端结构体,服务端结构体大小):对服务端发起连接,成功后返回值为0.
write(客户端套接字,字符串,大小):往文件里写入,通信手段,
须知:从输入流获取字符串getline(cin,字符串名称),读取整行文本,包含空格。cin>>读取无空格的单词,高效但忽略空格后的内容。fprintf(流,字符串):向流里面输入字符串,无缓冲,输出会立即显示,fflush(流)刷新流,保持流有新的输入,在多线程或复杂程序中显式刷新可以避免输出顺序混乱。fgets(字符串,字符串大小,流):从流中按行读取到字符串中,遇到\n就截止,但是如果从流输入换行符,字符串结尾会有一个换行符。
守护进程化(孤儿进程的一种)
xshell会给用户创建一个会话(其中右bash)属于前台任务(有且只有一个),任务由进程组完成的,sid属于这个会话的进程,这些进程可以前后台转换,jobs查编号,fg 编号切前台,ctrl+z切后台。这些进程,会受到用户的登陆和注销的影响,只有通过守护进程化自成会话,不受影响。
进程组:组长为第一个
守护进程化的接口:
setsid:创建一个新的会话,调用这个接口的进程不能是组长
步骤:
1.让调用进程忽略异常的信号:忽略管道退出命令
2.如何让自己不成为组长:通过子进程的方式,将父进程杀掉,然后调用setsid
3.守护进程脱离终端:/dev/null(文件黑洞),默认的操作所有进入的数据都丢弃,也读不到任何东西,打开dev,重定向dup2将0/1/2都重定向dev dup2(新,老)
4.进程执行路径发生更改 小点:进程存在一个cwd默认的指名在当前路径
套接字
分类:网络套接字(网络通信)、原始套接字(抓包) 、unix域套接字(本地通信)
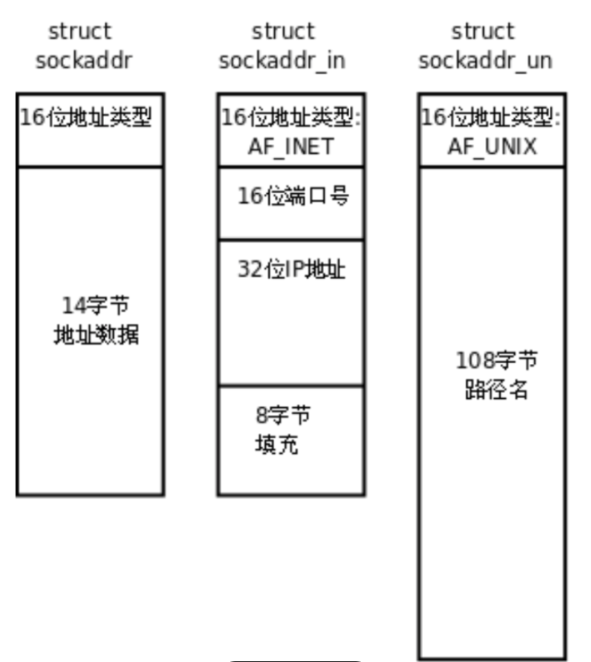
套接字的结构体:第一个是模仿两者,设配后两者,第二个是网络套接字的结构体,第三个是域套接字的结果体,用前两个字节判断类型。
127.0.0.1:本地环回,本地的ip地址
云服务器是虚拟化的服务器,不能直接进行bind云服务器的公网ip,但可以绑定内网ip
如果将服务器的ip设置为0.0.0.0 就表明,接收所有想发个这个进程和端口号的客户端所发的报文(任意地址绑定),因为服务器中的进程可以绑定私有IP、公网IP等等,因此设为这个IP,就说明任意IP+端口号都可以发给它了,不在乎IP是多少。
netstat -nuap :查看网络进程的详细属性
mkfifo 文件名:创建命名管道,运用于文件与文件。
可以客户端输入的数据传到网络中,输出的数据重定向给管道。然后就会构成,客户端的收到的数据在管道中,可以对管道进行打印,而客户端发出的数据在网络中。
本地套接字的结构体创建和绑定,port和ip需要主机转网络,而收发不需要主机转网络,因为底层已经做好了。
协议定制
多个字符串组成的结构体类似于:头像,时间,昵称,消息 序列化 形成一个报文(字符串)。网络拿到报文,对报文进行结构化处理。
进行报文转换为头像,时间,昵称,消息叫做反序列化。
反序列化和序列化就是定制的协议
实现方法
先描述再组织,序列化通过结构体的方式,将这几点放入,然后转成字符串。反序列化是将字符串变成结构体。这个结构体的名称就是业务协议。
1.序列化过程的实现
2.反序列化过程的实现
3.业务协议的实现
4.保证报文的完整性
为什么需要序列化,因为容易出现问题,比如:内存对齐的问题。
tcp传输控制协议(需要序列化和反序列化,UDP收到的是完整的所以不需要):
应用层缓冲区的数据拷贝到tcp发送方的发送缓冲区,tcp接收方通过网络,将对方的数据拷贝到接受缓冲区。
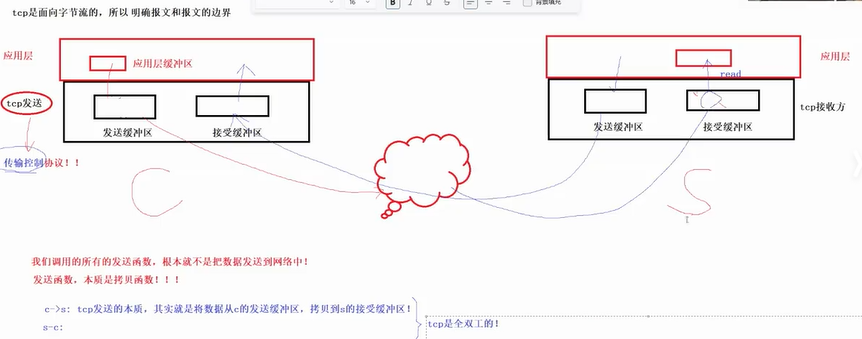
序列化和反序列化的目的是因为在网络通信时,传一个长字符串很方便,便以理解,而其他的类型不方便传输。
接收缓冲区:根据定长,特殊符号
问题1:如何能保证收到的数据是完整的?
通过前缀,来获得具体信息的长度,引申出来的子问题(怎么知道前缀读完了)。
方法:因为收到的时候是用特殊的分隔符来隔开,将前缀转整型就是内容的长度。
我的问题为什么不直接通过分隔符来找到信息,而不要前缀?
在消息末尾添加特定分隔符(如 \r\n\r\n),接收方按分隔符切分消息。
缺点:数据内容若包含分隔符会导致误判;需遍历数据查找分隔符,效率较低。
在协议定制的头文件中要有,接收的类,发送的类,获取带报头字符串的函数,去报头获取正文的函数(用于接收的结果),对正文加报头的函数(用于接收结果后,处理完,进行回显的结果)。
问题2:如何将从命令行输入的内容,从客户端转换为带报头的字符串。
方法:设计函数,构建简易版本的状态机。原理:从命令行输入,用字符串接收,字符串提取,然后转整型
以上的可扩展性比较差,怎么提高
系统自带的序列化和反序列化的用法:Json
JSON::Value 接收后各种类型
value是一个pair
序列化 json::fastwriter/styledwriter
write返回值就是序列化后的值
反序列化json::Reader
parse提字符串的值
如何在一套代码中定制多种协议,以及如何让系统知道用哪一个协议
字符串长度/分隔符/协议编号/分隔符/内容
会话层连接管理,表示层数据转换序列化和反序列化,应用层约定协议定制
HTTP:应用场景:web
概念:通过HTTP可以将服务器的网络资源拿给客户端
URL:俗称网址,获取网络资源
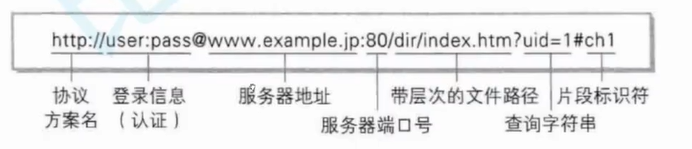
端口号:会被统一做管理,指定的用途
utlencode和urldecode
作用:前者将客户端的符号进行转化为url中的特定格式(编码),后者将url格式转换为符号(解码),目的:不干扰对url的解析,影响获取资源的操作。
编码规则:
-
非保留字符保留原样。
-
保留字符若在非保留位置出现(如查询参数中的
/),需编码。 -
其他字符按指定编码(如UTF-8)转为字节序列,每个字节转为
%XX(十六进制)。
encode实现:
#include <string>
#include <iomanip>
#include <sstream>// 判断字符是否需要保留原样(非保留字符)
bool is_unreserved_char(char c) {return (std::isalnum(c) || c == '-' || c == '_' || c == '.' || c == '~');
}std::string url_encode(const std::string &value) {std::ostringstream escaped;escaped.fill('0');escaped << std::hex;for (auto c : value) {if (is_unreserved_char(c)) {escaped << c;} else {escaped << '%' << std::setw(2) << int(static_cast<unsigned char>(c));}}return escaped.str();
}
decode实现:
#include <cctype>std::string url_decode(const std::string &value) {std::string result;result.reserve(value.size());for (size_t i = 0; i < value.size(); ++i) {if (value[i] == '%') {if (i + 2 < value.size()) {// 提取十六进制字符并转换为字节std::string hex = value.substr(i + 1, 2);char decoded = static_cast<char>(std::stoi(hex, nullptr, 16));result += decoded;i += 2;} else {// 无效的 % 格式,跳过result += value[i];}} else if (value[i] == '+') {// 查询参数中的 '+' 转为空格result += ' ';} else {result += value[i];}}return result;
}
http的请求格式:
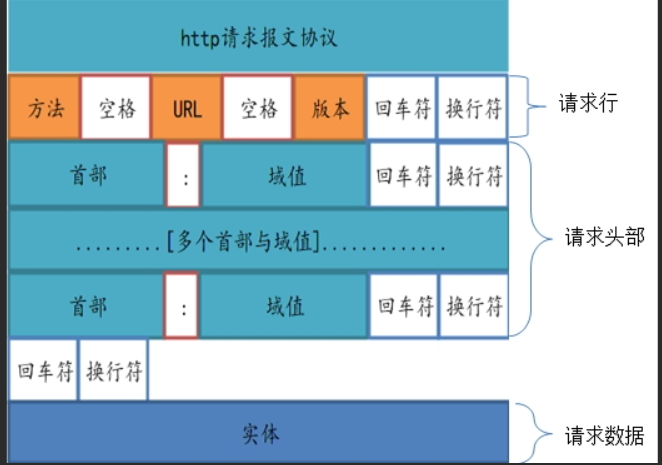
申请版本:目的是申请到对应版本的服务器,根据版本给相应的服务
http的回复格式:
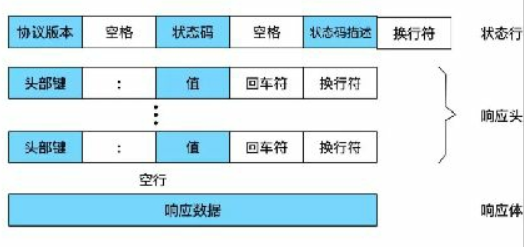
协议版本:http 1.0 1.1 2.0这种作为第一行的内容
状态码:判断请求的状态,例如:404
状态码描述:对状态码进行解释意义
http是在应用层对数据做到结构化处理后的协议规则,规定了传输的格式,而tcp和udp在传输层是做传递具有这些协议规则的数据。
http应用层读取完整请求和响应的方法
1.因为换行符存在的原因,就可以读取完整的一行
2.循环读每一行,直到空行
3.报头可以全部被读完,报头有正文长度,因此根据报头可以读取完整的正文。
4.正文数据通过读取文件内容来获取
http请求和响应的序列化和反序列化
按照\r\n进行字符串转换为多行内容
HTTP
http设计步骤:
先写出了服务端对数据处理的每个操作,然后根据每个操作去设置函数和类,第一步是接收数据,第二部反序列化(请求类),第三步回调函数(执行任务函数),第四步序列化(回复类),第五步回复。
客户端不用实现,因为计算机自带的浏览器就已经是一个已经做好的客户端。
客户端发送给服务端的请求:
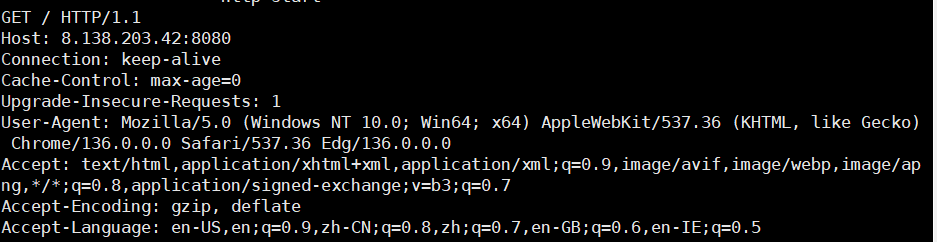
服务端对请求的分割处理:
要点:需要与HTML结合进行回复,前提是分割得到响应的HTTP的请求格式,根据请求格式回应相应的网站给客户端。
小点:telnent 127.0.0.1 端口号 可以在linux中查看服务器的状态。浏览器现在已经很成熟,可以不对回复进行反序列化,就可以处理回复消息了。
就是web服务器中有根目录,服务器所在根目录下
web服务器中可以进行配置路径,index.html(默认首页)
可以设置从哪个文件夹/文件下面找指定的资源
根据资源不同,就需要标定不同的响应报头。然后用资源的后缀去映射响应报头,客户端请求资源会有路径,根据路径分离后,找到后缀,然后找到资源。
手动设置路径的目的:
-
统一访问入口:用户输入域名即可直达首页(如
http://example.com自动访问index.html),无需输入完整文件名。 -
安全防护:避免服务器暴露目录结构(如访问
/images/时不返回文件列表),提升安全性。 -
灵活适配:不同子目录可定制独立默认页(如
/blog默认显示博客列表),适配复杂结构。 -
环境一致性:开发、生产环境可统一配置默认文档,避免因服务器默认规则差异导致问题。
http请求方法
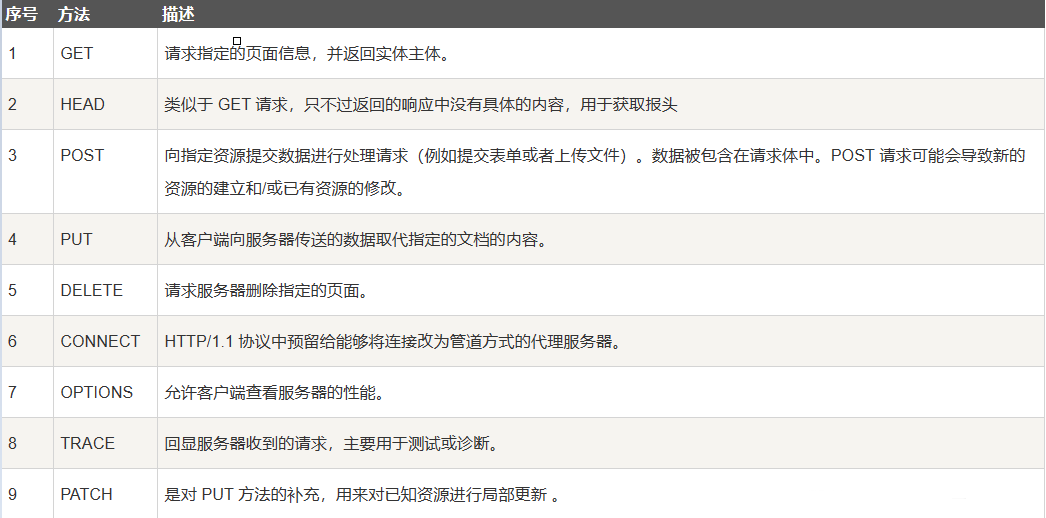
需知:表单,目的是客户端向服务端提交数据,例如:账号登陆。前端在网页上提交表单,后端就会收到内容,进行处理,解析为GET或者POST。
请求方法:GET.
操作:将网页形成的参数,以url的方式直接拼接到当前ip和端口号后面,提交给服务端。
缺点:不私密,不安全,不能接收大的参数,因为url。
请求方法:POST
操作:将网页形成的参数,通过http请求的正文提交参数。
优点:私密性好,传递参数可以很大,因为在正文。 缺点:不安全
通过方法可以进行分离客户端提交的数据,按照访问路径,进行绑定服务,进行执行其它任务,跳转网页等。

状态码:
4开头为客户端的错误,访问的资源一般,服务端提供不了这类资源
5服务器一般是创建空间和创建线程出错
3重定向(301,307,308)进入网站会跳转到其它网页
307/302临时重定向:类似于跳转到广告商
301永久重定向:网站升级后,访问原始网站每次进入就会跳到新网站,更新本地书签。
HTTP常见的一些报头
Content-Type:数据类型
Content-Length:body的长度
Host:客户端告知服务器,所请求的资源是哪一个主机的那个一个端口上。
user-Agent:客户端的设备信息,服务端可以根据设备信息,去回复客户端,这就是pc和手机端的网站不同的原因。
Accept:客户端告诉服务端,客户端可以接受什么格式。
location:搭配3开头的状态码。告诉客户端接下来要去哪里访问。
HTTP的一些关于网站的知识点
长链接
作用是获取一大份资源,通过一条链接就可以完成,因为http是基于tcp的,然后面向链接会频繁的创建链接,所以长连接可以解决建立链接的成本。
会话保持
保持用户始终在线,切换页面不影响之前的操作和登陆
身份认证:凡是对于网页有权限要求的网页,在被获取之前,全部都要做判断。
如何实现会话保持
浏览器存用户登陆的信息是用cookie文件存的,因此每次关闭还有用户信息,如果关闭浏览器进程需要重新输入,说明是cookie文件内存存的
木马是:获取用户信息,对计算机没有影响,盗取cookie文件,泄露账号密码
解决方法:通过登陆方法将用户的认证信息和浏览痕迹不保存在浏览器端,而是保存在服务器端,用session id来唯一标识,然后返回session id 给浏览器,浏览器只保存seesion id(本地cookie文件),浏览器拿seesion id 就可以拿用户的数据。
如果黑客拿到session id 进行访问,如何进行避免
用一定策略,让session id失效即可,比如(ip地址的网络号突然改变)
实操问题:服务器如何写入cookie信息,如何进行验证
响应报头设置cookie后,以后每次客户端http请求,会自动携带曾经设置的cookie报头,帮服务器进行鉴权,会话保持
基本工具
postman:模拟客户端--浏览器的行为,
fidder:抓包工具--主要抓http的工具,抓本地请求的http,主要用于调试,相当于中介
HTTPS
根据端口可以区分两者,http80,https443,就是在http协议的基础上引入了一个加密层.目的是结局传输安全的问题(数据篡改,数据被窃取)。
原理: 底层用密钥对数据加密,接收方拿到密钥进行解密
常见的加密方式
哈希摘要
session id 就是经过哈希摘要形成的,哈希摘要的搜索作用:对文件进行哈希形成摘要,保存在服务端,如果不同的客户端要对相同的文件进行存服务端,服务端会对这个文件进行哈希摘要,得到的字符串,直接在服务器中寻找,如果有直接在服务器中形成软连接,这样两个在不同的本地文件,在服务器里就变成了一个。
http的加密方法选择
对称加密(密钥相同):黑客拿到数据,不知道密钥是什么也没用,但是服务器和客户端需要看到同一份密钥,这之间也需要传递,所以黑客也会拿到未加密的密钥。因此密钥也需要被安全传递,所以密钥也要有密钥的密钥,因此这个对称加密操作并不安全,解决不了http的安全需求。
服务器非对称加密(密钥不同):公钥(客户端都有,公开的)加密,私钥解密,私钥加密,公钥解密,服务器形成私钥和公钥,客户端第一次握手,服务端第二次发起握手推送公钥,客户端用公钥加密数据,第三次握手发送加密的数据,服务端拿到数据后,用私钥解密,但是服务器恢复数据,用私钥加密就不安全了。
双方非对称加密:原理用各自发来的公钥加密,自身用私钥解密。缺点:慢,有安全问题()
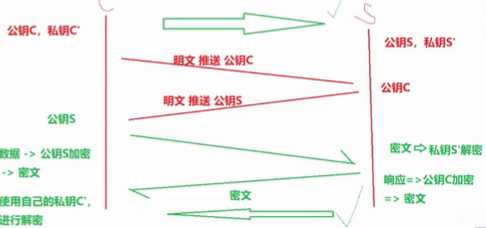
非对称+对称加密:客户端发起请求,服务端应答以及接收链接请求并且传递公钥给客户端,客户端生成对称密钥,用公钥加密密钥,传给服务端,之后用对称密钥通信,与双方非对称密钥类似,只是要快一点。
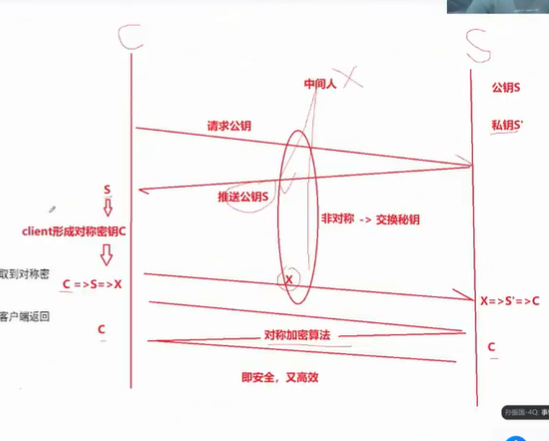
以上的方法都会遇到一个问题:
中间人攻击:在最开始协商,三次握手时,它就进入传输路径上,获取各种信息包括密钥,然后中间人此时就相当于一个客户端了,每次信息都要经过中间人,再到客户端,中间人就可以有自己的公钥和私钥,将在自己的密钥给客户端,将服务端的密钥给自己,自己来做信息转发。
如何防止中间人对传递公钥处理
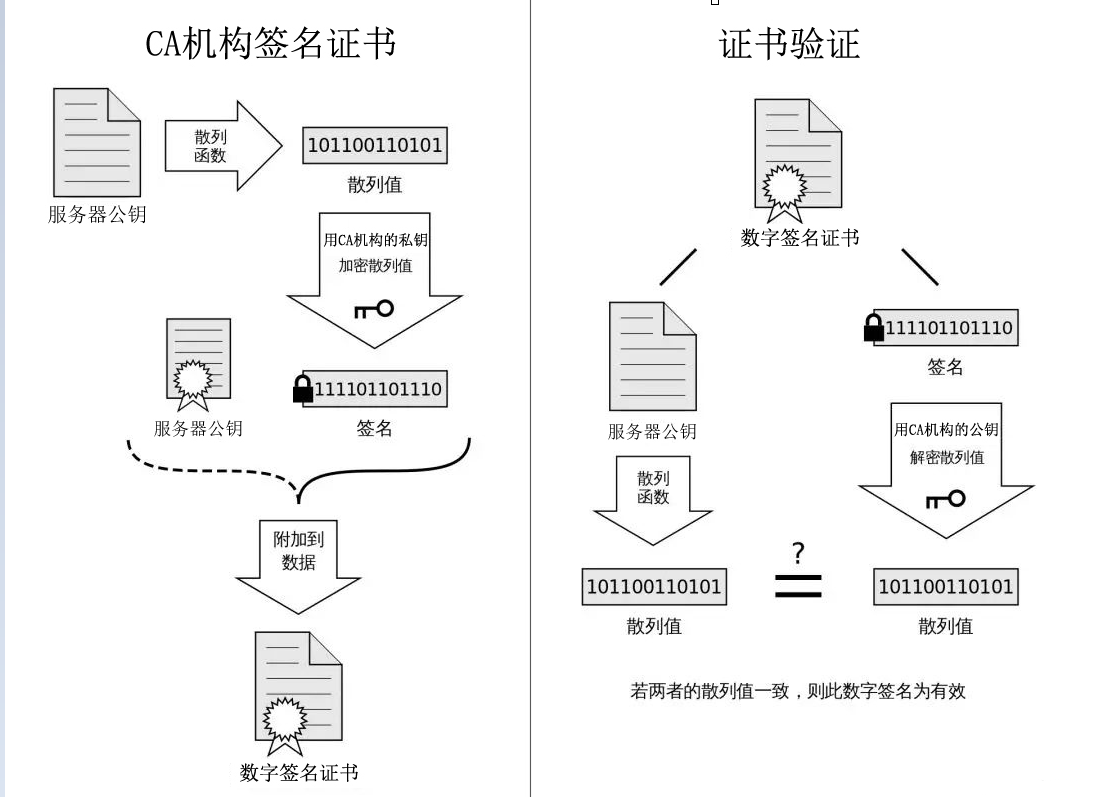
证书:数据签名(非对称加密算法),生成哈希散列值,防止数据篡改
数据签名:对数据通过哈希摘要形成散列值。
CA证书,非对称,对称相结合。
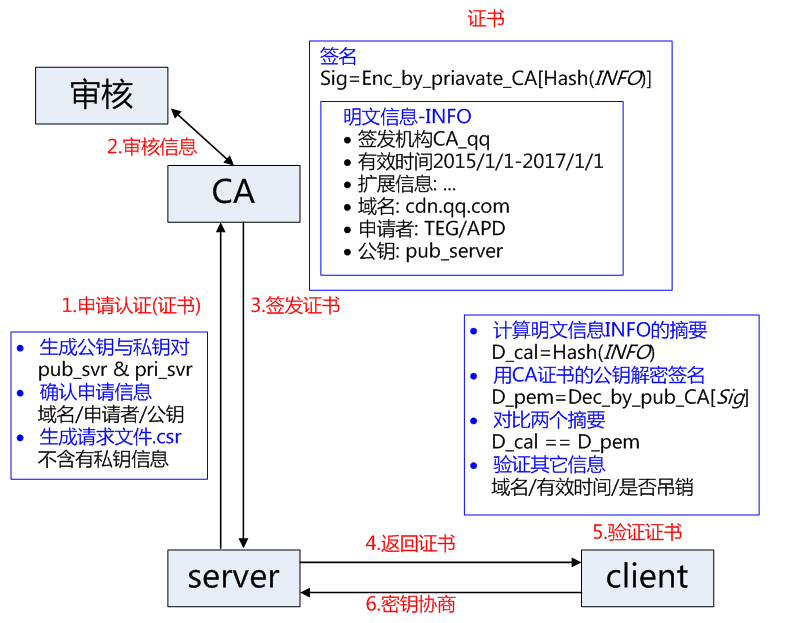
CA机构有自己的公钥和私钥,CA公钥内置在浏览器中。
第一步:CA对服务端提交来的数据(服务端形成的公钥,服务端信息)进行哈希摘要得到哈希散列值。
第二步:CA用自己的私钥(CA独有)加密散列值(数据签名),CA将数据与加密的散列值合起来,形成CA证书。
第三步:证书返回给服务端,服务端将证书和应答推给客户端。
第四步:客户端收到证书,客户端用浏览器中CA的公钥将数据签名解开,然后分离数据签名和明文数据。
第五步:将数据(服务端形成的公钥,服务端信息) 进行哈希摘要,得到对应的散列值,然后与数据签名对比,如果一样说明公钥没有被篡改,不一样说明公钥被篡改了。
第六步:客户端再进行生成对称密钥,然后用服务端的公钥对对称密钥加密,传给服务端,服务端用私钥进行解密拿到对称密钥。
第七步:双方用对称密钥通信。
注意:期间中间人只能拿到服务端的公钥,但是公钥只能加密,无法解密,因此无法查看信息。如果中间人对CA证书进行更改,将CA中服务端的公钥改了,就无法与数字签名匹配,如果两个都更改了,用自己的私钥对数字签名加密了,但是浏览器中内置的CA公钥是打不开这个数字签名的,因此也无法更改成功。注意的要点CA的公钥只能解密,服务端的公钥只能加密。
因为加密哈希散列值是为了浏览器用固定的公钥解密,相当于匹配一样,如果不进行加密,浏览器就无法判断这个数据签名是是不是CA形成的,这样中间人就可以篡改公钥和数据签名了。也就是,不进行加密,中间人就可以自己形成一个证书了,客户端浏览器还不能验证是否是安全的。
传输层
再谈端口号(linux内核下是16位)
端口标识应用层中不同的应用程序,例如0-1023应用于知名协议,HTTP-80
进程与端口号的关系:一对多,一对一
指令:
pidof :得到进程的pid, pidof 进程 | xargs(从管道得到pid,放在命令行后面)
netstat :
语法 -选项 :-l 处于监听状态 -n 协议数字化显示 -t tcp -p 进程信息 -u udp
UDP协议

报头:固定8字节,用于定制数据的大小。本质是一个结构化数据对象。操作:先进行开空间,将结构体和有效载荷结合,然后强转成结构体,填入数据,传字符串数据到别的os上,然后进行强转为结构体数据,就可以拿到报头的信息了。
源端口:发送数据报的应用程序所使用的端口。
目的端口号:匹配上层的应用的端口号,用于交付给上层的应用,进行分用。
UDP长度:整个UDP长度(报头和数据),最大64KB,超过了需要进行打包分开发。
校验值:检验数据再传输过程中是否损坏
基于UDP协议的应用层协议:NFS TFTP DHCP BOOTP DNS
特点:
无连接:知道对方的ip和端口号,可以直接传输
不可靠:没有确认机制,没有重传机制,不用管数据是否发给对方,发了之后就不管了
面向数据报:直接能读完一个完整的数据报,·不用考虑读不完一个数据报。
缓冲区:接收接口要经过接收缓冲区,只有接收缓冲区,因为,可以实现类似于消费者和生产者模型,让进程执行其它任务,而因为不需要可靠性,所以发送直接调用接口经过网络直达对方接收缓冲区
TCP协议
两种工作模式 c->s:
一端发送一条,一端应答一条
一端并发发送多条,一端并发回复多条
报头
不加选项标准20个字节的大小,结构化数据
源端口:发送数据报的应用程序所使用的端口。
目的端口号:匹配上层的应用的端口号,用于交付给上层的应用,bind就是添加到哈希表中,通过haxi的方式找到进程的PCB,进行分用。
4位首部长度:加上选项的报头长度[0,15],报头总长度=首部长度*4字节
序号:标识发出数据的顺序序号,类似于数组下标。
确认序号:用于应答的报文中,对应发来的报文的序号,让对方下一次开始的序号是多少,
对发来的报文序号+1。
小点:两个序号存在的条件是因为,两端都有发送和接收所以要有自己的标识序号
窗口大小:告诉对方自己接收缓冲区剩余大小,对方可以根据这个进行流量控制。
标志位(1/0控制)【标识报文的类型】
URG:tcp的数据是按序到达,如果有数据的紧急指针标志位1,有效载荷中包含了需要被特殊尽快的数据(用16位紧急指针作为偏移量去有效载荷找这块数据,这个数据是一个字节),就可以进行插队,优先处理,用于发带外数据。将紧急数据跳过接收缓冲区队列,直接提交给上层应用进程处理,而普通数据仍按正常流程缓存或处理。
ACK:确认收到1,用于这个报文是否为确认的报文
PSH:定期催促接收方上层取走接收缓冲区的资源1,让read和write的读取条件满足
RST:复位标志位1,单方面认为连接不存在时,用这个标志位告诉对方,进行连接重置,通常用于连接建立后,某一端出问题断开了连接,然后另一端一直发报文。
SYN:建立连接1
FIN:断开连接 1
特点
1.全双工,一个接收区,一个发送区
2.可靠性传输:发消息之后,对方对收到正确的旧消息有应答
3.字节流
4.面向连接
超时重传机制(TCP策略,超时(根据网络情况决定的))
作用:用于处理丢包问题(数据丢了,应答丢了),设置一定时间,如果超过一定时间没有收到对方应答就会重传数据,而这个数据会保存在发送缓冲区里一段时间,之后会被新数据覆盖。如果接收方收到重复的数据,tcp会根据序号自动丢弃收到的重复的数据。
超时时间:根据网络的质量进行浮动变化的。一般以500ms为单位,时间是它的整数倍。
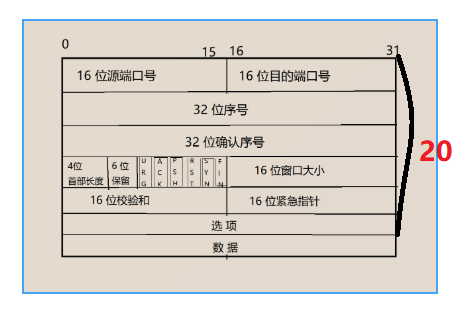
连接管理机制
一次握手的缺点:多个客户端发起建立连接,就会单方面对服务端形成洪水攻击,而客户端没有资源损失,服务器缺一直有连接请求,消耗它的资源。
两次握手的缺点:跟一次握手一样,因为服务端的连接建立成功的回复会丢失,然后客户端还是会洪水般的发起请求,因为他不知道连接建立成功没有。
三次握手是建立连接机制,不保证三次握手成功.(握手期间可能会出现SYN的消息丢失)
三次握手优点:
1.用最小成本验证全双工通信时通常的。验证方法:全双工的功能是能发能收,两次握手能够知道客户端能发能收,服务端则只知道能收,能发需通过要第三次握手的客户端应答证明。
2。可以有效防止单机进行对服务器进行攻击。防御的核心思路是:减少服务器在握手完成前需要消耗的资源,或者更早地识别并丢弃恶意SYN包。
三次握手的目的:
第一次:请求连接,发送带有syn标志位的报头。
第二次:同意连接,采用带有syn和ack的报头回复,此时请求方先建立成功。
第三次 :收到请求方连接建立成功的ack应答报头,这时接收方再建立成功连接。
这三次握手:实现了以最少次数使双方都完成连接,间接保证了可靠性,因为报文内部有一些数据,两端根据握手的报文内部数据,进行用户数据的传递,建立器连接结构体。
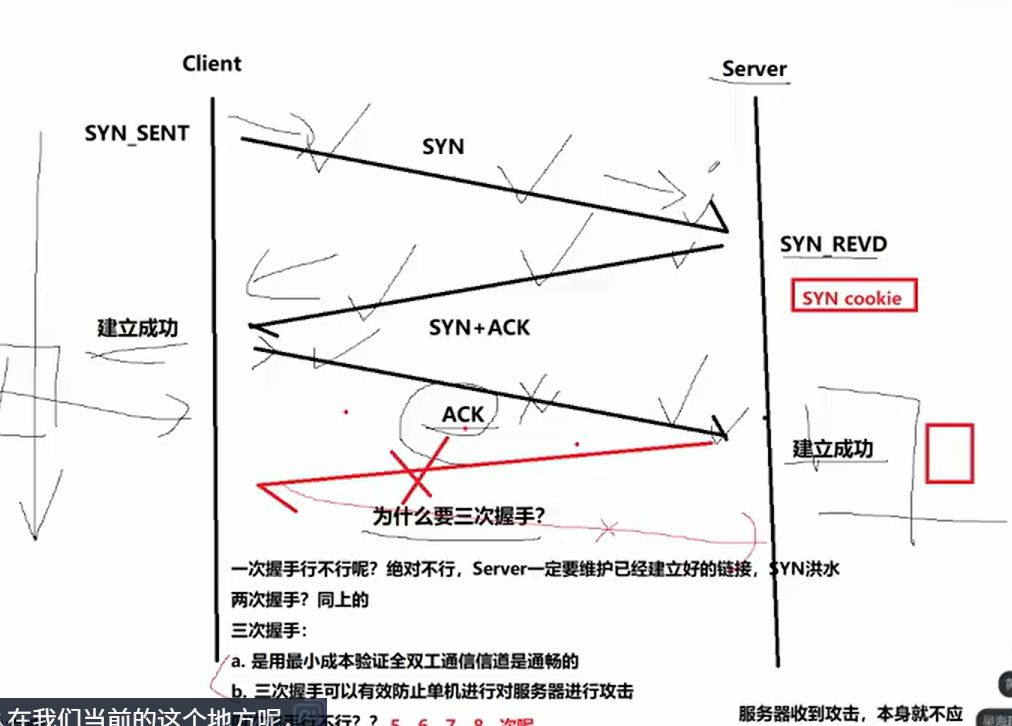
四次挥手
第一次挥手:客户端发送单方面FIN(断开连接),之后不给服务端发用户数据了,但是还有底层报文数据。
第二次挥手:服务端对客户端单反面断连应答
第三次挥手:服务端对客户端也进行单方面断连
第四次挥手:客户端对服务端单方面断联进行应答,这是底层报文数据,不属于用户数据。
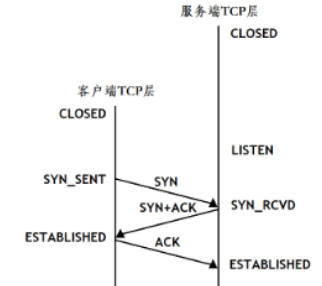
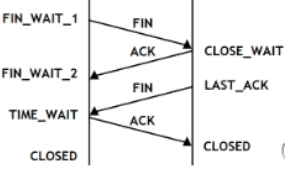
四次挥手两端的状态:
1.断开连接是双方都能发起
2.第一个发送断连的状态是FIN_WAIT_1,而回复端进入CLOSE_WAIT
3.第二个发送断连的进入LAST_ACK,而回复端为TIME_WAIT
4.服务端调用close关闭文件描述符后,会发出FIN给客户端,客户端就会发ACK进行应答,如果服务端没有收到客户端的ACK回复,它就不会断开,会进行补发FIN,因此客户端会处于一段时间(2*MSL)的TIME_WAIT。
TIME_WAIT(2倍MSL:两次收发所花的时间,报文生成时间) :是为了防止最后一次服务器没收到ACK,为了让对方去补发FIN,所以会等待一段时间,保证ACK被对方收到,防止滞留报文
立即重启服务端
服务崩掉之后,短时间无法重新bind套接字。
int setsockopt(SOCKET s, int level, int optname, const char FAR *optval, int optlen);
流量控制
报头中的窗口大小就是为了流量控制,通过连接发报文时,在报头中携带自己的窗口大小,让对方根据窗口大小,用相应的速度来传递相应大小的数据。
滑动窗口
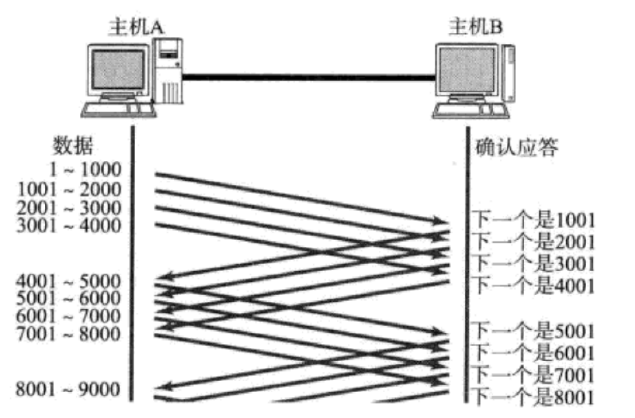
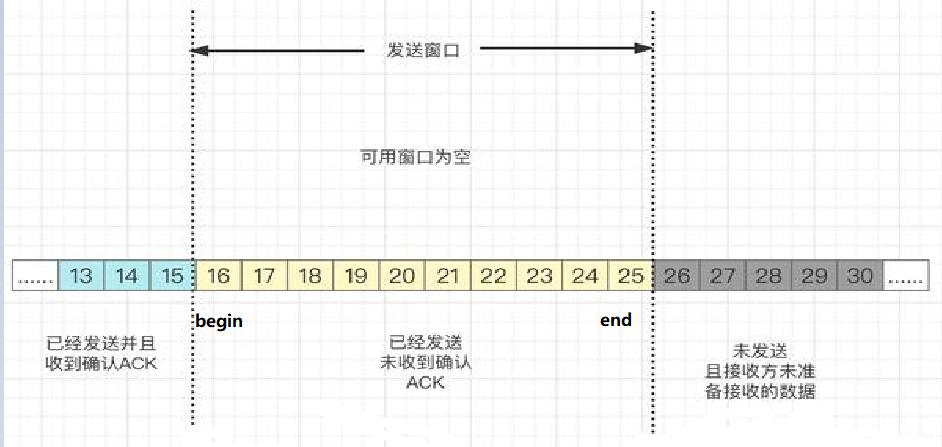
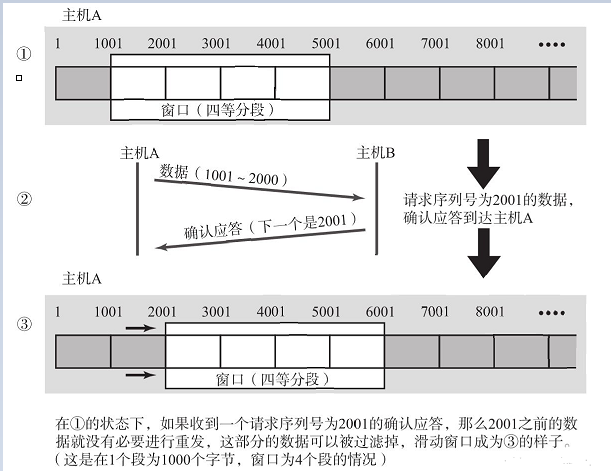
本质:基于可靠性,为了提高发送效率,可以并发
发送方的发送缓冲区存在滑动窗口,滑动窗口根据接收方接收缓冲区大小而定的。滑动窗口的前方为已经发送的数据并且收到对方应答,而滑动窗口是发给对方了,还没收到应答。
滑动窗口的原理
1.它是按序号进行发送给对方,类似于数组下标。
2.当发给对方后,并且收到应答,begin会向后移动,begin=确认序号。
3.当发给对方后,收到应答,并且应答中包含对方取走缓存区数据后的新的窗口大小时,end会向后移动,end的位置为begin+对方剩余窗口大小。
4.对方每次的应答是接收到数据的序号+1,告诉发送方下一次发的数据序号应该从这个数字开始。
5.如果对方接收到的数据序号不能连接起来,说明中间发送的数据有丢失情况,因此连续收到的数据都会应答相同的序号,这个序号是丢失数据的前一项没有丢失数据下标+1。
6.如果发送端接收到三次次相同序号,这是发送端就会按这个序号开始,进行重发。
7.发送缓存区的数据满了,数据会重开头进行覆盖已经发送并且收到应答的数据,类似于环形结构。
8.如果应答丢失了,不会受到影响,因为下一次应答的序号还是会按照本来的规则进行,不会进行重发。
拥塞控制
大背景就是网络问题,停止重发
拥塞窗口
恢复网络过程中,采用指数级的慢启动,其中会引入阈值,来规定达到这个阈值后,开始加法增长,拥塞窗口根据阈值变化。
滑动窗口大小=min[拥塞窗口,对方窗口]
延迟应答:因为有确认序号,所以可以对多个报文一起确认应答,这样可以先收多个数据,再一起应答,这样可以提高效率。
捎带应答
面向字节流:
字节流是什么?
-
面向字节流(TCP):像用水管传输水,水流连续不断,你无法区分哪滴水是哪个杯子倒进去的。
-
面向数据报(UDP):像用快递寄包裹,每个包裹独立打包,贴上地址,彼此之间毫无关联。
| 维度 | 面向字节流 | 面向数据报 |
|---|---|---|
| 数据组织 | 连续字节流,无边界。 | 独立数据包,有明确边界。 |
| 传输控制 | 可靠、有序、流量控制。 | 不可靠、无序、无流量控制。 |
| 适用场景 | 大数据量、高可靠性需求。 | 低延迟、容忍丢包、简单请求-响应。 |
| 协议代表 | TCP、SCTP(支持多流)。 | UDP、ICMP。 |
粘包问题
概念:
解决方法:
listen第二个参数
网络层
IP:将数据从主机a跨网路到主机b的能力
功能:路径选择:什么最重要,功能是选择数据传递的路线。
IP的组成: 网络地址+主机地址 举例:
IP协议的协议报头结构:
4位版本:Ipv4或ipv6,IP的长度
4位首部长度:单位4字节,是报头长度 类似于TCP,要对长度*4.
16位总长度:报头+有效载荷的长度 作用:得出有效载荷长度
8位协议:用于给上层,给到传输层的具体协议
16位首部校验和:检验数据是否损坏
8位生存时间:传递的步长,需要经过多少ip,到达目的ip的主机。如果没有在指定步长完成,就会销毁重发 产生的原因:防止循环转发,导致一直没发送到指定位置。
32位源IP地址:发送端的网络层分配的主机IP
32位目的IP地址:接收端的IP
传输过程经过的结构和过程:例子(归还钱包)
主机:发送端和接收端
子网:发送端和接收端所在的区域,可以通过区域找到各自主机。
主机与子网的关系:子网里面包含主机,由多个主机进行构成,而这些主机是消息互通的。
路由器:每个子网都有一个路由器,而路由器就是对子网的数据进行管理。然后每个子网的路由器又在更大的子网中进行消息互通。
子网划分
子网划分方法:通过网络号进行划分,每个子网网络号不同,子网内部主机号不同,而主机号对于子网外部的其他子网的来说可以相同。
子网划分目的:解决IPV4的32位地址不够用的问题。
划分的类型:
ABCDE子网划分:缺点是有些网络不需要太多主机,但是却分配了大量的主机ip就会引起一些ip没被使用。
动态地址分配:在子网内部,一些设备下线之后,可以把这个ip给其他主机。
公网和私网:通过子网掩码的方式进行分配私网ip。
NAT:私有IP可以重复,出公网IP进行通信时,转化为公网IP。
IPV6:采用128位IP地址。
公网和私网:内外网协同
公网:ICANN分配—运营商获取—用户使用
特殊地址:
127.0.0.1:本机环回(自己寄信给自己)
169.254.x.x:DHCP失败时自动分配(无家可归的临时地址)
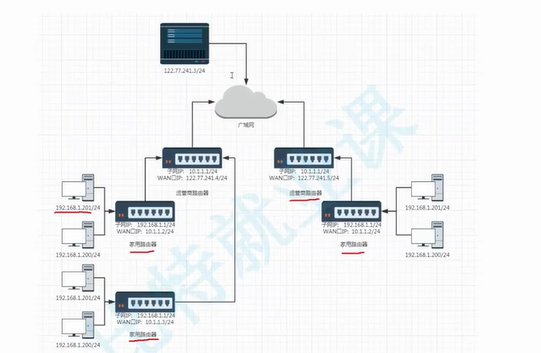
策略:主机采用内网ip,路由器采用内网加公网ip,内网用于内部,公网用于路由器所属的更大的网络中,一层套一层。
子网IP:
WAN口IP:
私网
私有IP:
传输过程:主机的在局域网中对比路由表,进行跟子网掩码的与运算,寻找指定的目的ip,如果没有就跳出这一层局域网,往更上一层,用同样的方法寻找。
路由表:涵盖连接路由器下,所有的IP地址。
路由转发:主机构造IP数据包,通过路由表寻找,如果有在局域网下,所有主机进行解封至IP层,对比目的IP,找到确定的主机,没有满足的就通过发送给网关。

网络层对数据的处理

这三个的作用
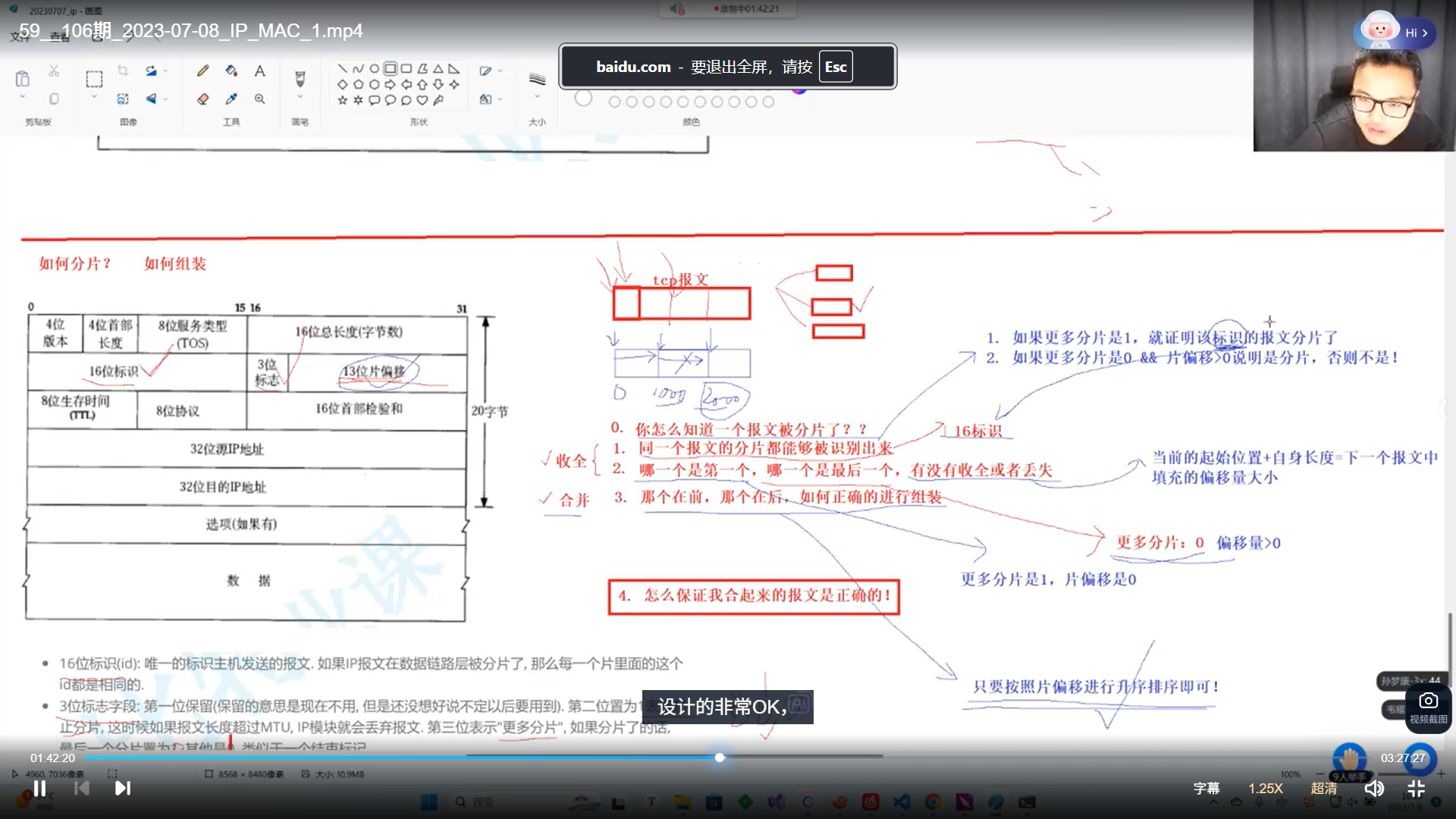
16位标识:用于将数据匹配数据链路层大小进行分片,这个是分片之后,所属同一报文的身份证号。
3位标志:第一位1表示还有分片,0表示最后一片
13位片偏移:每个分片距离第一个分片的地址的距离。
数据链路层:协议:以太 功能:与传输层相关,规定数据一次传输的大小
IP的分片和组装:
目的:分片为了满足数据链路层的要求。
组装的方法:
1.识别是否为分片:通过13位偏移和3位标志位
2.识别同一个分片:16位标识符
3.检测分片的完整和第一个以及最后一个:通过组合之后,13位偏移能够组合起来,连接上就是一个整体,第一个是偏移量0,最后一个有偏移量且标志位为0
4.正确顺序组装分片:根据偏移量来排序
5.保证报文内部数据是否正确:IP和TCP都有校验码。
分片好吗?
对tcp和udp ip的影响
分片方法
通过加报头,然后填写标识符,标志位,偏移量,然后满足链路层的数据要求。
数据链路层
局域网下转发原理:
以太(ether)网协议:MAC指针做报头
MAC的分离
目的地址:目标主机的MAC地址(全球唯一网卡标识)
源地址:当前主机的地址
类型:
CRC:差错检测
MAC的分用
基于以太网的局域网转发:
同一个路由器下,消息互通,发消息给局域网内部任意一个主机,所有主机都会拿到,然后进行检测,不符合就丢弃。
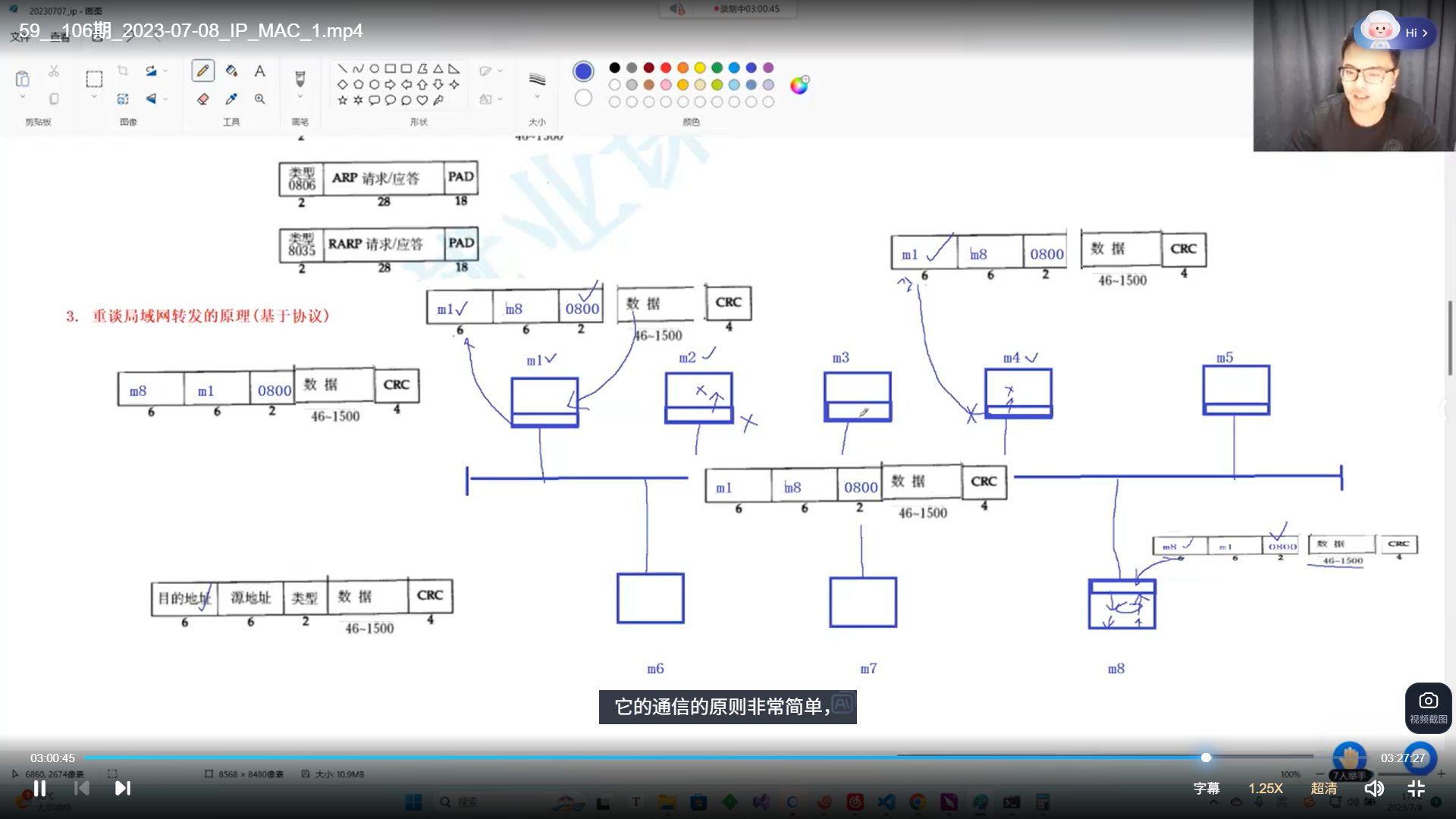
局域网的通信规则
规则对应的策略(局域网类似于临界资源)
局域网内部通信只能一个一个发,类似于管道,有一个主机拿到令牌才能发,其余等待,如果等待时间相同,会发生碰撞,此时可以用交换机来隔离碰撞域,定向转发,如果遇到碰撞,都停止,然后不处于碰撞域的进行发送。
交换机