c++学习值---模版
目录
一、函数模板:
1、基本定义格式:
2、模版函数的优先匹配原则:
二、类模板:
1、基本定义格式:
2、类模版的优先匹配原则(有坑哦):
3、缺省值的设置:
4、typename关键字(参数名称的迷惑性):
5类模版里的函数模版:
三、非类型模板参数:
1、基本定义格式:
2、c++里的array:
3、缺省值规则的猫腻:
四、模版的特化:
1、函数模板的特化:
2、类模板的特化:
全特化:
偏特化:
进一步对指针和引用的偏特化:
五、模版的声明定义分离---危!!!
1、显式声明:
2、都挤在头文件算了:
3、模板无法直接声明和定义分离的原理:
六、一点边角料:
1,类模版的按需实例化:
2,头文件之间交叉引用所要注意的小细节:
模版,物如其名 。 就是个类似于设计图纸似的东西,有了图纸,我们就可以在此基础上添枝加叶后较为轻松的做出成品;
c++里的模板也是相同的道理,有了模板,在此基础上就可以衍生出各种不同的成品(函数和类)。
一、函数模板:
1、基本定义格式:
定义一个函数模版需要用到的关键字是 template , 然后结合class 或 typename就可以达到定义模版参数的效果。如下:
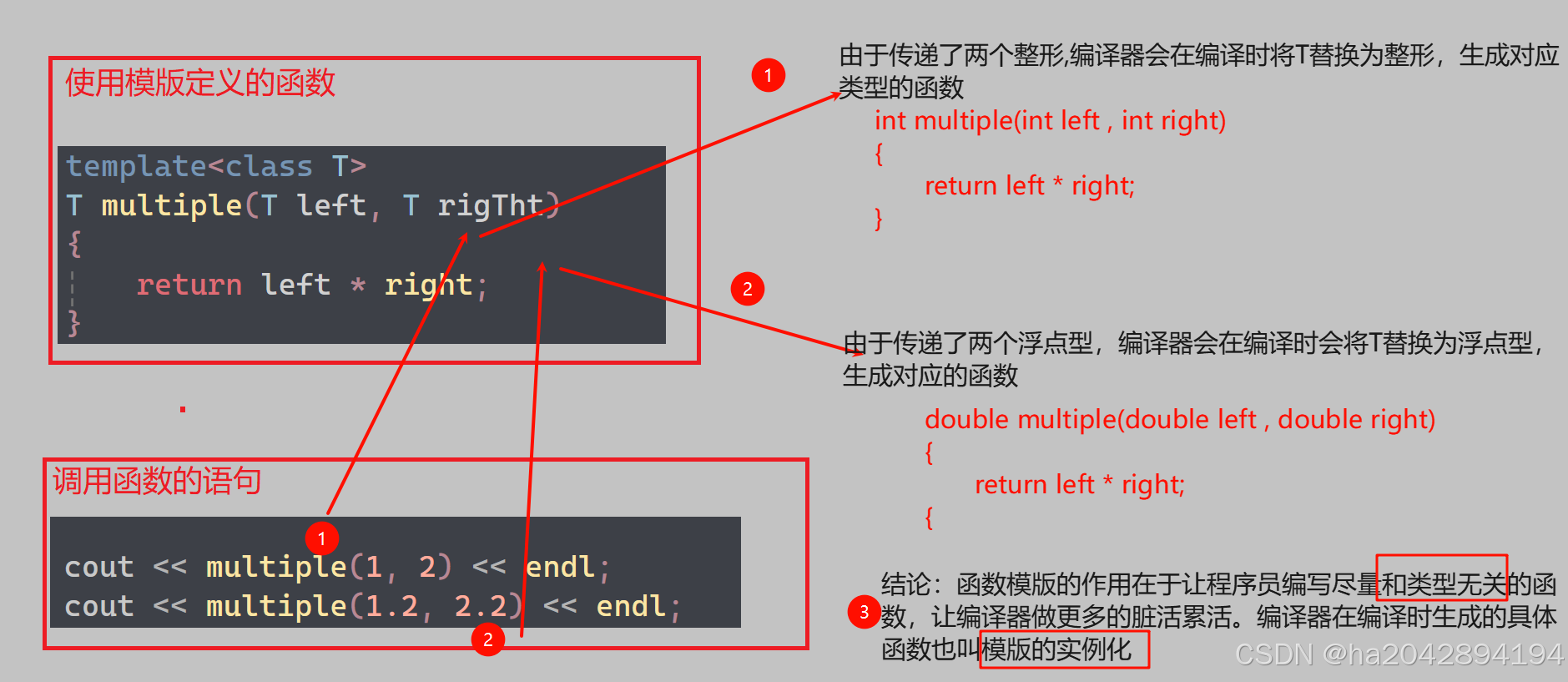
template<class T> //定义格式:template开头,用尖括号包围,里面用class搭配上形参名(比如此处的T)
// template<typename T> //typename 和class在此时没有区别//这里函数中涉及相关类型的地方用模版参数T替代了T multiple(T left, T rigTht)
{return left * right;
}
2、模版函数的优先匹配原则:
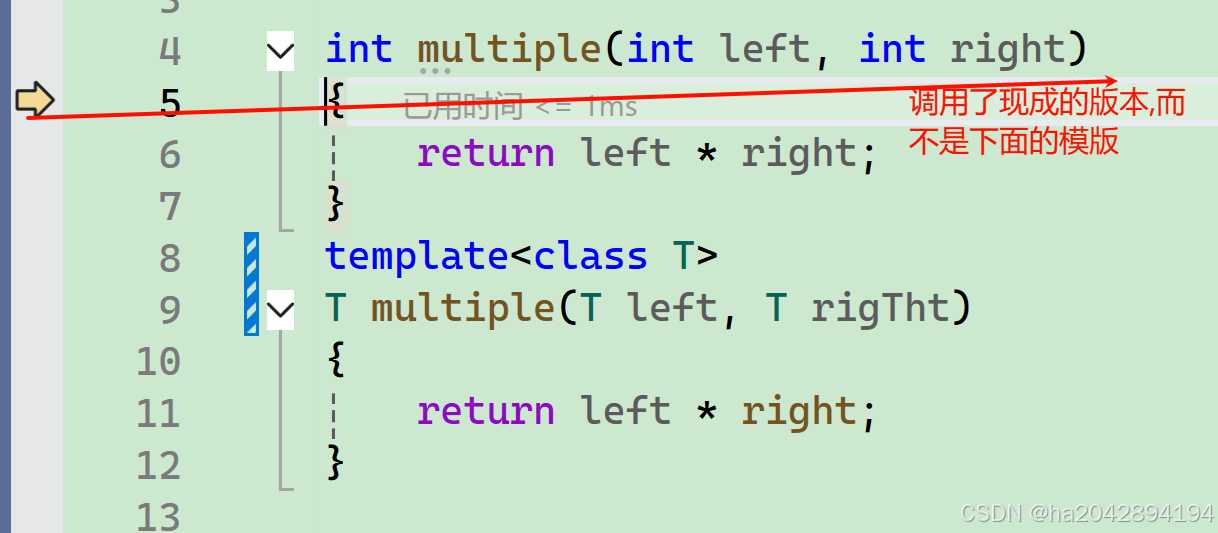
虽然上面我们提到模版的一大本质在于让编译器根据函数传参的具体类型在编译阶段生成带有具体类型的函数,但编译器只是勤快,而不是傻!!!如果已经有了现成的函数,他就直接调用这个函数,而非吭哧吭哧的埋头苦干....
当调用一个函数时,如果已经存在现成的函数版本,编译器则会直接调用它,而不是自己另外生成.
//具体类型的函数定义
int multiple(int left, int right)
{return left * right;
}
//模版函数定义
template<class T>
T multiple(T left, T rigTht)
{return left * right;
}//调用语句里传入了两个整形值
cout << multiple(1, 2) << endl;下面是通过调试观察到了程序运行时的情况
二、类模板:
1、基本定义格式:
类模版的定义方式和函数模版类似,同样关键字template、<>、class或typename的组合,只不过作用的范围是紧随其后的整个类,整个类里的变量和函数里凡是涉及到类型的地方都可以使用一开始定义的模版参数
template<class T>
class myclass
{
public:T add(T val) //成员函数的返回值和形参使用模版参数类型{T tmp = 0; //函数内部也可以使用模版参数类型return _val1 + _val2 + val;}
private:T _val1; //成员变量使用模版参数类型T _val2;
};2、类模版的优先匹配原则(有坑哦):
模版的匹配原则起始挺傻瓜的,毕竟在真正实例化出具体的类型之前,编译器能看到有几个参数,以及是否相同和顺序如何(从左往右匹配)。
下面用一个模拟实现vector成员函数的例子来阐释:
// 用n 个 val初始化的构造函数
vector(int num, const T& val):_start(new T[num])
{for (int i = 0; i < num; i++){*(_start + i) = val;}_finish = _end_of_storage = _start + num;
}
// 用迭代器区间初始化的构造函数
template<class inputIterator>
vector(inputIterator begin, inputIterator end)
{while (begin != end){push_back(*begin);begin++;}
}如果只存在以上两种vector的构造函数,那么当使用这样的语句来实例化一个对象时,就会报错 :vector<int> v(5,7)。也就是传递两个整形值,下面是分析:

最简单的解决方法是自己另外写一个更加明显的版本:把int改为size_t ,这样一来,参数6会被隐式类型转换为size_t,参数9仍然是正常的int ,但正因如此,就变成了参数类型不同的函数,也就能和第二个函数完美的区分开来。
3、缺省值的设置:
类似于函数重载,类模版也可以设置缺省值。比较常用的情景就是在为容器适配器设置默认的底层容器,比如stack和queue底层的deque :
这样即使在创建stack或者queue的对象时,没有特殊情况的话就只是显式实例化一个模版参数,比如myStack<int>就可以 , 并不需要繁琐的myStack<int,deueue<T>>。
template<class T , class Container = deque<T>>
class myStack()
{//stack类的相关实现.............
}template<class T , class Container = deque<T>>
class myQueue()
{//queue类的相关实现
..................
}4、typename关键字(参数名称的迷惑性):
都学习过函数的我们知道,函数的形参的名称真的就只是一个普通的名称,仅仅是为了方便内部的使用,甚至不写形参的名字在语法上也是对的。
c++在运算符重载里区分前置和后置的++和--时就利用了这一点,如下图就是一个日期类的后置++的成员函数:
Date operator++(int) // int参数仅用于区分前置/后置++,因此压根就不用写形参名
{ Date temp = *this; *this = *this + 1; return temp;
}下面通过一个printf_container,也就是通用的容器打印函数,来说明形参名称的迷惑性(模版参数的形参也是形参,只不过不向函数的形参那样可以省略罢了)。
template<class Container>
void PrintContainer(const Container& obj)
{Container::iterator it = obj.begin(); //这条语句又隐藏的风险while(it != obj.end()){cout << *it <<" ";it++;}
}
这里的问题的根源在于程序员和编译器视角的不同:
- 在我们心中,这里的Container代表各种容器,因此函数里的 Container::Iterator it 的写法是顺理成章的.
- 可是在编译器眼里, 这里的Container仅仅只是一个类型名,虽然可能是容器类型(自定义类型) , 但同样也可能是int、double等内置类型。
- 编译器的做法很严谨,为了避免函数在被调用时,参数实例化为了int等内置类型,就在编译阶段进行拦截了 。毕竟,int::iterator it 这样的语句怎么看怎么逆天...
- 这个问题的解法,是typename关键字,显式的告诉编译器这是一个类。或者更省心一点,直接用关键字auto来让编译器自己推导正确的类型。
//正确的写法
template<class Container>
void PrintContainer(const Container& obj)
{//关键代码
//------------------------------------------------------------------------------------typename Container::const_iterator it = obj.begin(); //在前面加上typename关键字//auto iterator it = obj.begin(); //当然auto就更省心啦
//---------------------------------------------------------------------------------------while (it != obj.end()){cout << *it << " ";it++;}
}5类模版里的函数模版:
一个类的内部并非只能使用在类之前定义的那些模版参数,也就是说:一个类的成员函数还可以定义自己的模版参数。
template<class T>
class myclass
{
public://特立独行的成员函数add,定义了自己的模版参数
//--------------------------------------------------------------template<class Y>Y add(Y val){return _val1 + _val2 + val;}
//-----------------------------------------------------------------
private:T _val1;T _val2;
};三、非类型模板参数:
1、基本定义格式:
定义模版类型时,我们既可以用关键字class和typename来定义一个通用的类型,反过来,我们也可以直接写死所期望的类型,比如下面这个例子里:一个成员变量为array类型的类,在模版参数里固定了整形变量,甚至是他的缺省值。
template<class T , int size = 10> //此处的int size就是非类型模版参数,10是他的缺省值
class Array
{
public:Array(){double tmp = 1.2;for (auto& au : obj){au = (tmp += 3.9);}}void PrintSelf(){for (auto au : obj){cout << au << " ";}cout << endl;}
private:array<T, size> obj; //size也就充当了array类型对象的元素个数
};
2、c++里的array:
在上面对于非类型模版参数的例子中,我使用到了c++里的一个不太起眼的容器——array。看名字咱就很眼熟,谁在初学c语言数组的时候不是这样定义的数组名称??? int arr[10] ={0} 。
其实array的底层就是一个静态数组,只不过还夹带了一点私货,让他比普通的静态数组更加安全和好用。
| 普通的静态数组 | 封装了静态数组的容器array | |
| 安全性 | 仅仅在空间的边界处设有标志位 | 一旦越界访问,断言报错 |
| 便捷性 | 需要自己写for循环遍历 | 支持迭代器遍历 |
| 可读性 | int arr [10]中 int [10]才是类型名 | array<int,10> obj 中 obj之前的就是类型名 |
顺带补充一点:普通静态数组的越界检查比较简陋,主要就是在底层封装了一层逻辑来判断内存边界前后的元素是否被修改,这也代表如果只是访问元素,几遍非法,也不会报错。看下面的情况:

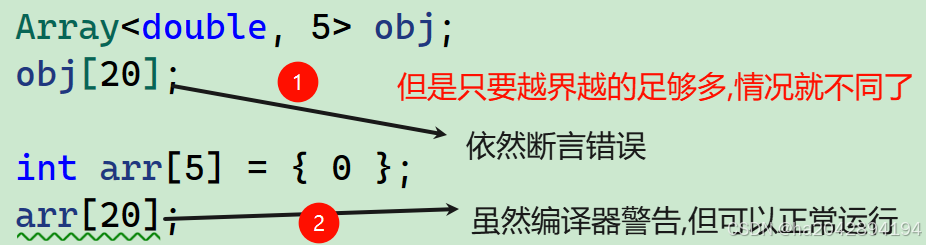

3、缺省值规则的猫腻:
非类型模版的规则随着c++标准的迭代经历了巨多巨多的变更,如下图所示。看看就好,不用太在意,需要用的时候查资料就好啦。
| 标准版本 | 整型/枚举 | 指针/引用 | 浮点类型 | 类类型 | 其他特性 |
|---|---|---|---|---|---|
| C++98/03 | ✔️ | ✔️ | ❌ | ❌ | - |
| C++11/14 | ✔️ | ✔️ | ❌ | ❌ | nullptr 支持 |
| C++17 | ✔️ | ✔️ | ❌ | ❌ | auto 推导 |
| C++20 | ✔️ | ✔️ | ✔️ | ✔️(字面量类) | 字符串字面量间接支持 |
| C++23 | ✔️ | ✔️ | ✔️ | ✔️ | 结构化绑定 |
四、模版的特化:
模版的特化,无论是函数模版还是类模版,都是在原有模版的基础上进行的更加具象化的定义,因此特化后的模版参数起码在参数个数上要和原模版相匹配!!!
1、函数模板的特化:
特化就是对全部的模版参数特殊处理化。
//函数模版的基础版本
template<class T , class Y>
Y add(T left, Y right)
{return left + right;
}
//函数模版的全特化版本
template<> //由于是全特化,所以不再使用原来的模版参数,这里可以空着
double add<int,double>(int left, double right) //写法的关键在于函数名之后、括号之前显示实例化 模版参数(类似于定义模版类对象时的写法);以及,替换模版参数为具体的类型。
{return left + right;
}2、类模板的特化:
全特化:
//基础的类模板
template<class T ,class Y>
class Myclass
{
public:
private:T _val1;Y _val2;
};
//全特化的类模板
template<> //全特化就可以把这里空着,因为全部要自己显式写
class Myclass<int, double> //显式实例化(注意模板参数个数要和原模板一致)
{
public:
private:int _val1;double _val2;
};偏特化:
//基础的类模板
template<class T ,class Y>
class Myclass
{
public:
private:T _val1;Y _val2;
};
//偏特化的类模板
template<class T> //这里偏特化模板参数Y,所以原来的参数T还得写
class Myclass<T,double> //显式实例化时仅仅将偏特化的模板参数确定即可
{
public:
private:T _val1;double _val2;
};进一步对指针和引用的偏特化:
偏特化除了可以理解为“对一部分模板参数特殊处理化”之外,也有“对已有的模板参数进一步处理”的功能。
//原模板
template<class T ,class Y>
class Myclass
{
public:
private:T _val1;Y _val2;
};
//偏特化出指针类型
template<class T, class Y>
class Myclass<T*, Y* >
{
public:
private:T _val1;Y _val2;
};
//偏特化出引用类型
template<class T, class Y>
class Myclass<T& ,Y& >
{
public:
private:T _val1;Y _val2;
};
五、模版的声明定义分离---危!!!
c、c++是典型的编译型语言,中途会把每个源文件独立编译,最后和头文件一起链接起来生成可执行文件。因此但凡是写过小项目的人,一定会用到声明和定义分离的项目组织模式。
但是 ,当编写的函数或者类使用到了模板,却仍然像效仿c语言那样直接将声明和定义分离的话必定会看到扑朔离奇的报错,下面给出常用的解决方案以及背后所蕴含的原理。
1、显式声明:
- 实在是要声明和定义分离,就必须在源文件里显式特化,也就是给出具体的类型。
- 这样的做法不实用 :传入的参数的类型可能有很多,一旦是没有显示特化的类型,依然会报错,但是程序员难免会有疏忽导致没有提前谋划好此函数可能接受的所有参数类型,从而出现问题。
- 建议在源文件里依然不辞劳苦的写一份原模板函数,这时c++标准的一项规定。有趣的是:如果在源文件里不写源模板函数,仅仅是显示特化的版本,编译器会警告,但仍然会正常运行......。
- 第三点中的现象的原因在于:编译器对模板的处理分两部分,一是在编译阶段检查基本的语法,此时发现一个声明后面没有定义,但由于每个文件都是单独编译,编译器不能排除定义放在其他文件的可能性,所以没有拦截我们;二是在链接时编译器找到了其他源文件里显示特化后直接可用的函数版本,所以就一路长虹的执行下去喽,最后造成了有警告但没报错的奇异现象。
//.h 文件的声明
template<class T>
void testFunc(T a);//.c文件的显式特化//保留初始版本的函数模版
template<class T>
void testFunc(T a)
{ cout << a << endl;
}
//特化版本
template<>
void testFunc<int>(int a)
{cout << a << endl;
}2、都挤在头文件算了:
既然声明和定义分离有陷阱,那干脆放弃挣扎,直接都放在头文件里算了
类里的成员函数在声明时就顺便定义:类里的代码量较小成员函数默认会作为内联函数,代码量较大的函数则会和普通函数一样进入符号表后参与编译的过程。
3、模板无法直接声明和定义分离的原理:
这个就要从c、c++这种编译型语言的可执行文件生成阶段说起了,分别是:预处理、编译、汇编、链接。
- 预处理:展开头文件、去掉注释、进行宏替换、执行条件编译。
- 编译 : 分别对每个源文件单独进行词法语法分析、生成汇编代码。此阶段中,头文件里的模板函数或类的声明不会被编译器是做毒瘤,因为有可能具体实现在其他文件里,要等到链接的时候才能下定论;源文件里的模板函数或类由于尚未被调用,没有实例化出具体的代码,也就没有进入符号表,无法被找到。
- 汇编:将汇编代码转换为CPU可以直接执行的二进制代码。
- 链接:将所有源文件和头文件连接,生成可执行程序。此时编译器发现模板类和模板函数不存在于符号表,也无法确定调用的地址,所以报错。
六、一点边角料:
1,类模版的按需实例化:
模版仅仅是一个模具、一份设计图纸,就像各种武器还仅仅是一份概念图而尚未被制造出来时不会别别的国家所忌惮,当然,更多的时候压根就没人知道。
因此编译器就好像是一个不知道邻国正在研发秘密武器的懵懵懂懂的总统,在邻国的武器制造出来之前,即模版实例化具体的类或者函数之前,都不太会引起总统/编译器的注意。
说人话就是:只要不调用某个类的成员函数,即便这个成员函数内部存在一些荒唐的逻辑错误(比如使用了不存在的函数),也不会报错!!!
//类模版
template<class T , int size = 10>
class Array
{
public:void SecretWeapon(){obj.push_back(666); //成员变量obj是array<T,size>类型,容器array显然没有push_back接口}
private:array<T, size> obj;
}; 
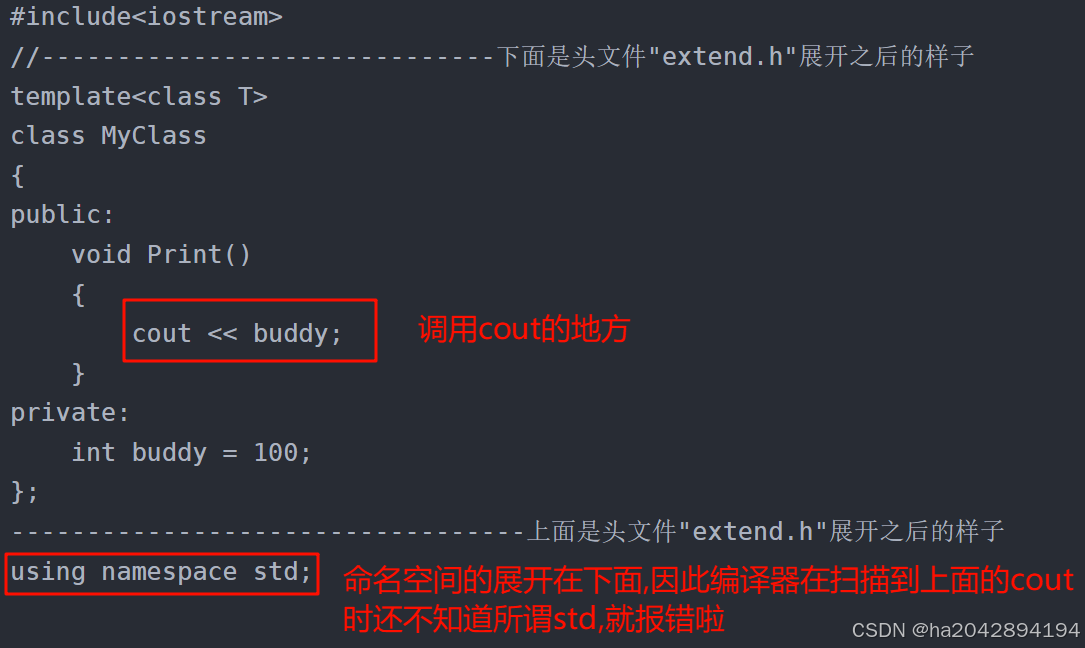
2,头文件之间交叉引用所要注意的小细节:
在一个源文件里包含其他头文件是十分常见的操作,但是在c++里也会有一些和命名空间有关的坑,如下是一个头文件和一个源文件以及程序运行的报错结果:
//头文件 extend.htemplate<class T>
class MyClass
{
public:void Print(){cout << buddy; //这里用到了<iostream>库,std命名空间里的cout函数!!!}
private:int buddy = 100;
};//源文件 Main.c#include<iostream>
#include"extend.h" //包含了我们自己的头文件"extend.h",其中有用的官方库的cout函数
using namespace std;int main()
{cout << "good morning , my dear boY !!!" << endl;return 0;
}
这样就很奇怪,毕竟我们既包含了官方库(#include<iostream>) , 也展开了命名空间(using namespace std) , 可编译器还是无法找到我们头文件里的cout函数 . 其实问题就出现在源文件里那几条语句的声明顺序!!!
对于在源文件里包含一个头文件,不要感到恐慌.当程序在运行之前,首先要进行预处理,这里就是出现问题的关键,下面就是我程序们的预处理之后大致的模样 : 可以看到原先的#include"extend.h"这一句指令被替换成了头文件里的代码
#include<iostream>
//------------------------------下面是头文件"extend.h"展开之后的样子
template<class T>
class MyClass
{
public:void Print(){cout << buddy;}
private:int buddy = 100;
};
----------------------------------上面是头文件"extend.h"展开之后的样子
using namespace std;int main()
{cout << "good morning , my dear boY !!!" << endl;return 0;
}