堆与堆排序及 Top-K 问题解析:从原理到实践
一、堆的本质与核心特性
堆是一种基于完全二叉树的数据结构,其核心特性为父节点与子节点的数值关系,分为大堆和小堆两类:
- 大堆:每个父节点的值均大于或等于其子节点的值,堆顶元素为最大值。如:
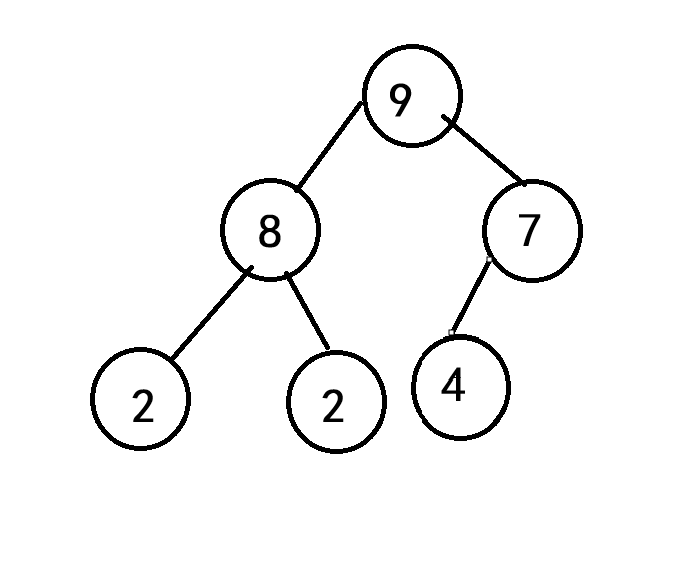
- 小堆:每个父节点的值均小于或等于其子节点的值,堆顶元素为最小值。
这种特性使得堆能够高效地支持插入、删除堆顶元素和获取极值等操作,时间复杂度均为 \(O(\log n)\),其中 n 为堆中元素个数。
二、堆排序:基于堆的经典排序算法
(一)算法思想
堆排序的核心是利用堆的特性实现排序,分为两个阶段:
- 建堆阶段:将初始序列构建成一个大堆(或小堆)。
- 排序阶段:依次将堆顶元素与末尾元素交换,调整剩余元素维持堆结构,直至排序完成。
(二)实现步骤(以小堆为例)
假设现有数组 data = { 4,2,8,1,5,6,9,7,2,7,9},如图
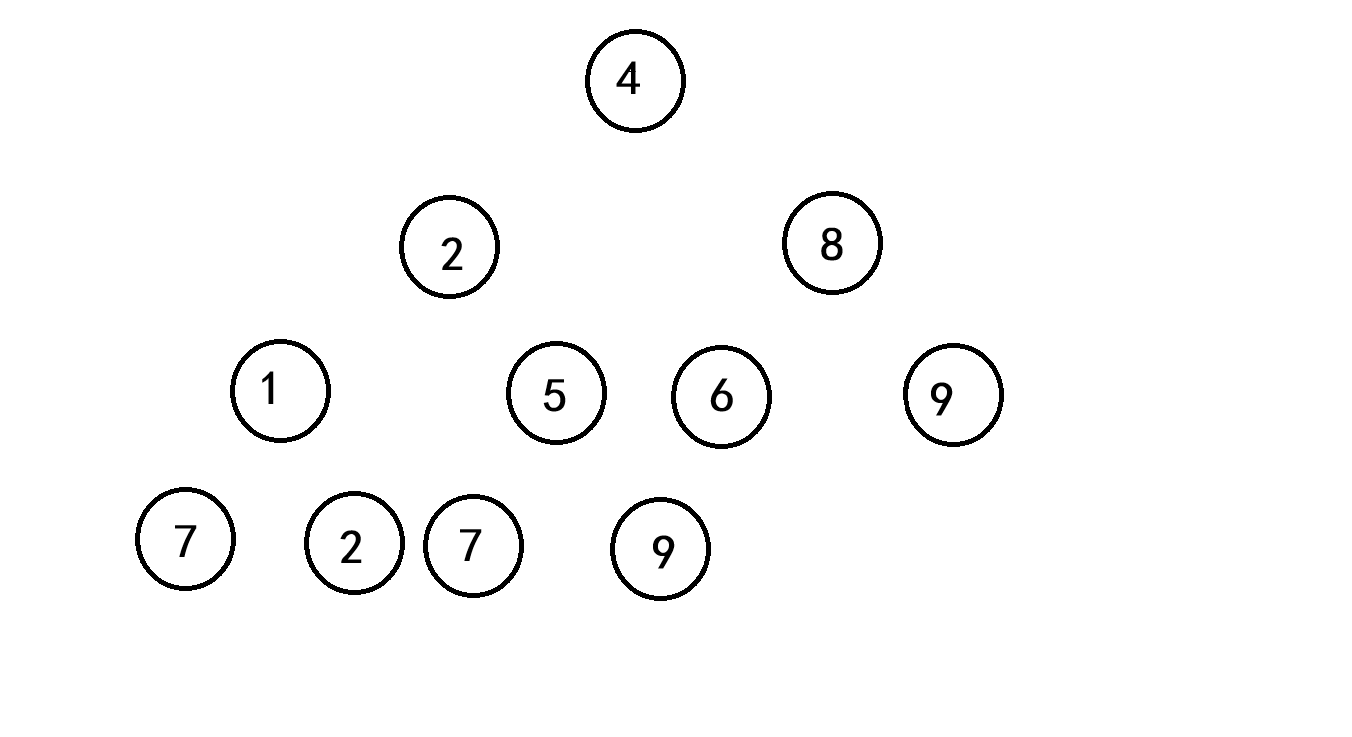
其排序过程如下:
- 构建小堆
- 从最后一个非叶子节点(索引为(n-1-1) / 2)开始调整。
- 运用向下调整算法进行处理。
//向下调整
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while(child < n)//找不到孩子{//找出小的孩子if(child + 1 < n && a[child + 1] < a[child]){child = child + 1;}//调整if(a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
- 排序过程
- 交换堆顶与末尾元素,此时末尾元素为最小值,固定。
- 对前 n - 1 个元素重新调整为小堆。
- 重复交换和调整操作,最终得到有序数组 {9 9 8 7 7 6 5 4 2 2 1}。
(三)代码实现(C)
//堆排序(O(N*logN))
void HeapSort(int* a, int n)
{//降序,建小堆//升序,建大堆// for(int i = 1; i < n; i++)// {// AdjustUp(a, i);//向上调整建堆(O(N*logN))// }for(int i = (n-1-1)/2; i >= 0; i--){AdjustDown(a, n, i);//向下调整建堆(O(N))}int end = n - 1;//(O(N*logN))while(end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}for(size_t i = 0; i < n; i++){printf("%d ",a[i]);}printf("\n");
}
三、Top-K 问题:基于堆的高效求解方案
(一)问题定义
在海量数据中快速找到最大的 K 个数(或最小的 K 个数),例如从 100 万个数中找出前 10 大的数。
(二)核心思路
- 求最大的 K 个数:使用小堆,堆中维护当前最大的 K 个数。遍历数据时,若当前数大于堆顶(堆中最小值),则替换堆顶并调整堆。
- 求最小的 K 个数:使用大堆,堆中维护当前最小的 K 个数。遍历数据时,若当前数小于堆顶(堆中最大值),则替换堆顶并调整堆。
(三)代码实现(C,求最大的 K 个数)
假设文件 data.txt 中存储了大量整数,可通过以下步骤进行Top-K 求解:
- 输入数据:将数据输入进data.txt中
- Top-K 查询:调用
topK函数获取前 K 大或前 K 小的元素。
void CreateNData()
{//造数据int n = 100000;srand((unsigned int)time(NULL));const char* file = "data.txt";FILE* fin = fopen(file, "w");if(fin == NULL){perror("fopen fail!");return;}for(int i = 0; i < n; i++){int x = (rand()+i) % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}void Test03()
{/* A *///读前k个数据system("chcp 65001");int k = 0;printf("请输出k>:");scanf("%d",&k);int* kminheap = (int*)malloc(k*sizeof(int));if(kminheap == NULL){perror("malloc fail!");return;}const char* file = "data.txt";FILE* fout = fopen(file, "r");if(fout == NULL){perror("fopen fail!");exit(1);}for(int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);}//建小堆for(int i = (k-1-1)/2; i >= 0; i--){AdjustDown(kminheap, k, i);}//读取剩下N-K个数int x = 0;while(fscanf(fout, "%d", &x) > 0){if(x > kminheap[0]){kminheap[0] = x;AdjustDown(kminheap, k, 0);}}//打印topkprintf("最大前%d个数",k);for(int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");
}四、性能分析与应用场景
(一)时间复杂度
- 堆排序:建堆时间为 ,每次调整时间为 (O(log n)),总时间复杂度为 (O(nlog n)),属于不稳定排序。
- Top-K 问题:遍历数据时间为 (O(n)),每次堆操作时间为 (O(\log K)),总时间复杂度为 (O(nlog K)),适用于 (K 远小于 n) 的场景。
(二)应用场景
- 堆排序:适用于内存中数据排序,尤其适合不需要额外空间的原地排序(空间复杂度 (O(1)))。
- Top-K 问题:
- 海量日志分析:提取热门访问记录。
- 数据挖掘:找出频繁出现的元素。
- 实时系统:实时监控数据中的极值点。
五、总结
堆作为一种高效的数据结构,通过巧妙的完全二叉树性质实现了快速的极值操作。堆排序和 Top-K 问题是其典型应用,前者利用建堆和交换实现排序,后者通过维护固定大小的堆解决海量数据中的极值查询。理解堆的核心原理与应用,能有效提升数据处理的效率,尤其在面对大规模数据时优势显著。