【深度学习】15. Segment Anything Model (SAM) :基于提示的分割新时代
Segment Anything Model (SAM) :基于提示的分割新时代
基本介绍
The first foundation model for promptable segmentation.
Segment Anything Model(简称 SAM)是 Meta AI 于 2023 年提出的一种通用型图像分割基础模型。与以往分割模型不同,SAM 是首个支持多种交互提示(prompt)方式进行分割的模型,可以在不训练的前提下实现多种图像分割任务,是典型的 zero-shot promptable segmentation 模型。
模型能力概览
- 只需简单点击图像、框选区域、画掩码或提供文字提示,即可自动生成目标分割结果;
- 可对不确定区域生成多个有效掩码;
- 可对整张图像进行全目标检测和分割;
- 在对图像嵌入进行预计算后,SAM可以即时为任何提示提供分割掩码,实现与模型的实时交互。
- 分割速度极快,预计算 embedding 后能实时响应提示。
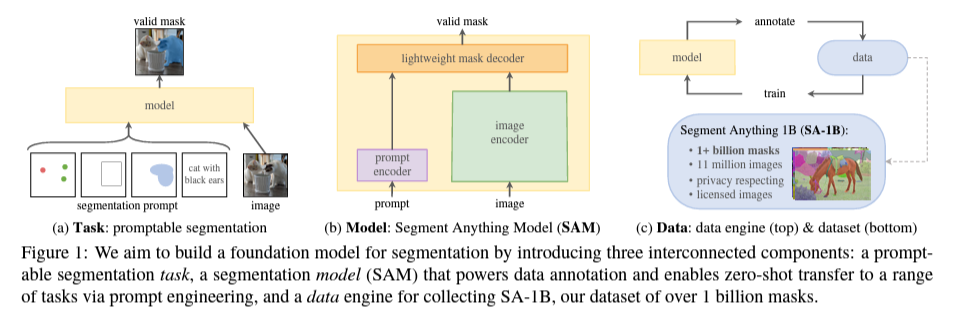
SAM由三个相互连接的组件构建:任务、模型和数据引擎
-
Task: Promptable Segmentation
- 在这种情况下,提示符是分割任务,可以是前景/背景点、粗框或蒙版、点击、文本,或者一般情况下,指示图像中要分割的内容的任何信息。该任务也被用作模型的预训练目标。
-
模型: Segment Anything Model (SAM)
- 重量级图像编码器输出图像嵌入。
- 一个轻量级的提示编码器有效地查询图像嵌入。
- 轻量级掩码解码器生成对象掩码和置信度分数。
SAM 的结构组成
SAM 的结构由三个核心模块构成:
| 模块名称 | 作用说明 |
|---|---|
| 图像编码器 | 使用 ViT 结构对整张图像生成 embedding(图像特征向量) |
| 提示编码器 | 编码前景点、背景点、框、掩码等用户提示信息 |
| 掩码解码器 | 综合图像和提示信息,生成分割掩码及其置信度评分 |
整体流程是:图像 → ViT → 图像 embedding + 提示 embedding → 解码 → 分割掩码
支持的提示类型(Prompt Types)
| 提示类型 | 示例 | 说明 |
|---|---|---|
| 点提示 | 单点/多点点击 | 指定前景或背景区域 |
| 框提示 | 粗略框定区域 | 生成与框中物体一致的掩码 |
| 掩码提示 | 传入已有掩码,进一步优化 | 支持迭代式修正 |
| 多模态提示(实验) | 如文本:“segment the dog” | 未来可能支持文本指令(暂不稳定) |
示例:通过点击分割一只猫
假设你上传了一张猫的照片并点击了猫的头部,SAM 的工作如下:
- 将整张图像通过 ViT 编码为高维 embedding;
- 对点击坐标编码为提示 embedding;
- 解码器融合两种信息,生成多个候选掩码;
- 输出包含:
- 最可能的掩码;
- 多个备选掩码(适用于歧义区域);
- 每个掩码的置信度(IoU score 估计);
支持多掩码、多粒度分割
SAM 特别支持 ambiguity-aware segmentation,即:
-
输出多个粒度层级的掩码,如 “整只狗”、“狗的头”、“狗的耳朵”;
SAM旨在为单个提示预测多个掩码(即3个掩码:整体、部分、子部分)。
-
对每个掩码预测一个 置信度分数(IoU 估计);
为了对掩码进行排名,该模型预测每个掩码的置信度分数(即估计的IoU(交集/联合))
-
训练时仅对损失最小的掩码反向传播,提升鲁棒性。
数据引擎:SA-1B 数据集
为了训练 SAM,Meta 构建了迄今为止最大的分割数据集:
- 名称:SA-1B(Segment Anything 1 Billion)
- 数据量:包含 1100 万张图像,11 亿个分割掩码,比任何先前的分割数据集多400倍的掩码
- 用途:用于训练、评估通用分割模型
- 开放性:仅限研究使用,开源访问:https://segment-anything.com/dataset
分割任何10亿掩码(SA-1B)数据集是迄今为止最大的标记分割数据集。它是专门为开发和评估高级分割模型而设计的。
数据集将是训练和微调未来通用模型的重要组成部分
实验表现与优势
- SAM的结果具有开创性的原因之一是,与其他技术(如ViTDet)相比,分割掩码的效果非常好。
- 在 23 个数据集上进行评测,尤其在 单点 zero-shot 分割 上表现优异;
- 使用 1 个点提示时,性能已超越传统模型(RITM,SIMPLECLICK,FOCALCLICK)使用多个提示点的效果;
- 分割边缘细腻、结构自然,是当前最强的基础模型之一。
局限性
虽然 SAM 很强大,但仍存在一些限制:
- 对复杂结构或细小物体容易漏检或产生错误边界;
- 在多点交互下可能不如专门的交互式分割模型(如 SimpleClick);
- SAM在文本到掩码任务上的表现并不完全稳健。
- SAM的性能预计会被特定于领域的工具超越(例如,ilastik)。
- SAM是用自监督技术初始化的(即,MAE),它的绝大部分能力来自大规模的监督训练。
总结
SAM 引领了 promptable segmentation 的新范式,具备以下特征:
- 可迁移性强:一次训练,支持多任务、多场景;
- 交互式强:支持实时反馈和多种交互方式;
- 数据基础强大:配合 SA-1B 具备强泛化能力;
- 未来可拓展至多模态分割、3D 分割、视频分割等更广泛应用。
你现在就可以通过官方 demo 在线体验:
Segment Anything Demo