Linux --OS和PCB
目录
认识冯诺依曼系统
操作系统概念与定位
1.概念
2.设计OS的目的
3.OS的核心功能
4.系统调⽤和库函数概念
深⼊理解进程概念,了解PCB
1.基本概念与基本操作
2.描述进程-PCB
基本概念
task_ struct 的内容分类
认识冯诺依曼系统
在计算机中小到个人的笔记本,大到企业的服务器,大多都遵从冯诺依曼体系结构。
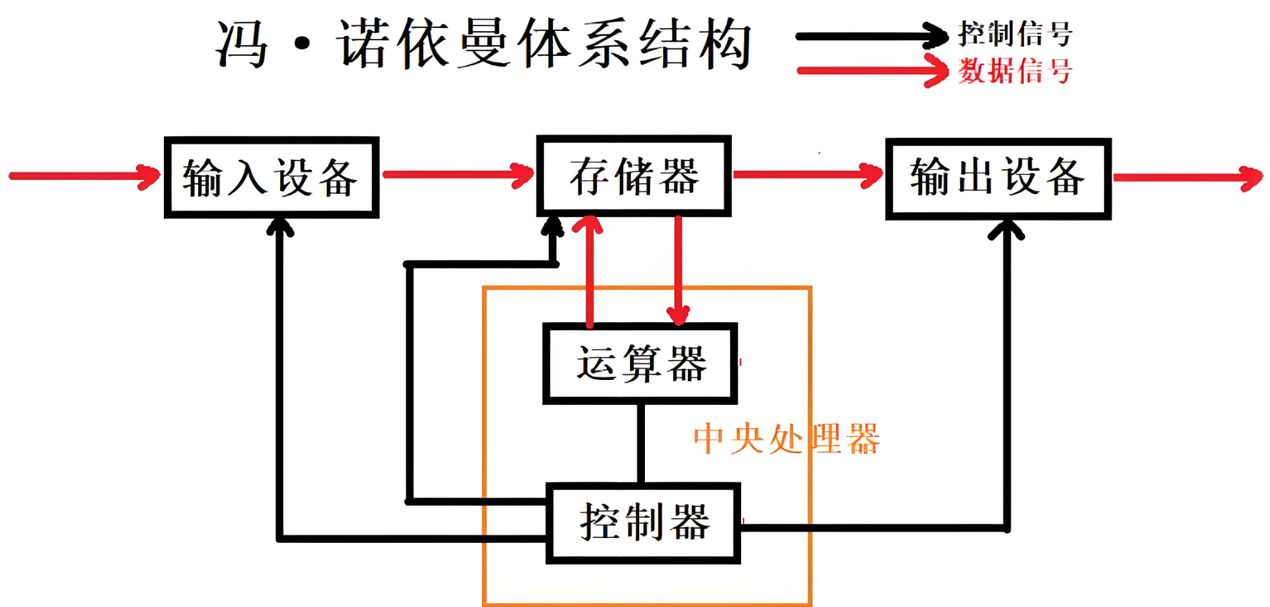
为什么大多数的计算机都要遵从这套体系呢,这是因为cpu在数据层面,不会和外设直接打交道,而是通过这里的储存器也就是内存,进行交换。当程序运行时首先会加载到内存中,由内存和cpu进行交互。那么为什么要有内存,内存其实是cpu和外设间的一个巨大缓存,外设如果和cpu直接进行交互,cpu的传输速率很快,但是外设的传输速率很慢,那么这个计算机的传输速率就会很慢,就像木桶定律一样,一只水桶能装多少水取决于它最短的那块木板,所以内存就诞生了,能够使程序提前加载到内存中,在需要运行程序时会直接与cpu交互,且速率并不会太慢,这是一个伟大的发明,使一般计算机能够拥有不错的效率,促进了计算机的发展。
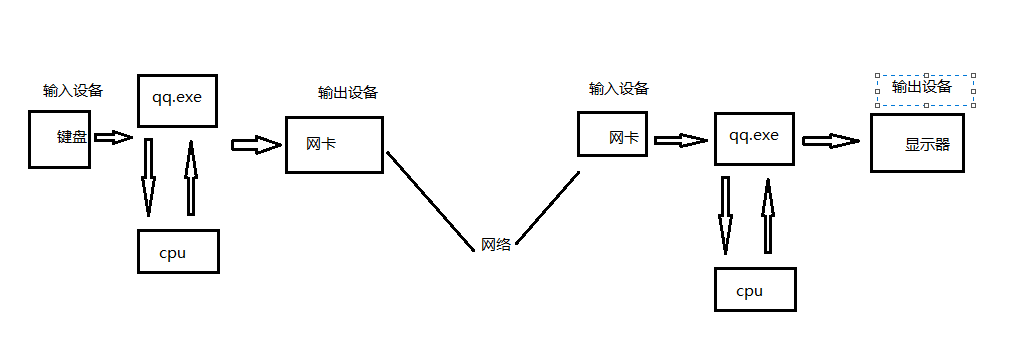
下面利用qq收发数据时来理解冯诺依曼
操作系统概念与定位
1.概念
2.设计OS的目的
3.OS的核心功能
4.系统调⽤和库函数概念
在计算机中用户并不能直接去和硬件交互,而是需要通过系统调用来交互,因为不是每个用户都深入了解底层硬件的,使用系统调用的方法能够极大保证安全的运行环境。
深⼊理解进程概念,了解PCB
1.基本概念与基本操作
2.描述进程-PCB
基本概念
task_ struct 的内容分类
进程属性
1.查看进程
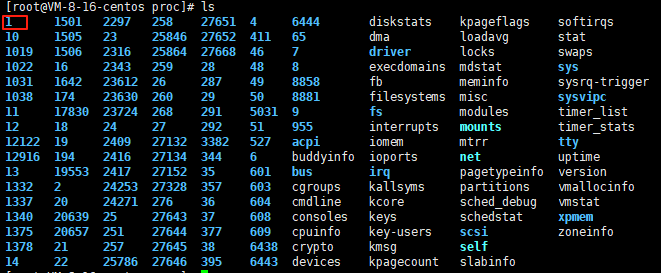
2.通过系统调用来获取进程标识符
在进程信息中我们可以看到每个进程都有自己的Pid和ppid,ps是通过一些系统调用遍历/proc文件夹来获取的,那么这两个标识符我们自己也可以通过系统调用来获取。
进程pid我们可以使用getpid()来获取,父进程id可以用getppid()来获取,这两个函数存在于sys/types.h头文件中。
#include<iostream>
#include<unistd.h>
#include<sys/types.h>using namespace std;int main()
{while(1){cout<<"pid :"<<getpid()<<endl;cout<<"ppid :"<<getppid()<<endl;sleep(1);}return 0;
}
这是一个进程id获取的代码,运行起来可以发现获取的的id和pid确实一致
![]()
我们在/proc文件夹找到对应进程信息能够看到exe和cwd
![]()
那么这两个属性是什么呢,cwd为current work dir即当前工作目录,exe为当前可执行程序所在的路径。创建一个可执行程序或者是在当前路径下创建的吗?其实是在当前的工作目录下创建的,我们可以用chdir来改变这个路径,这里用创建一个txt文件来展示
int main()
{chdir("./mydir");FILE* fp=fopen("log.txt","w");if(fp == NULL){}while(1){cout<<"pid :"<<getpid()<<endl;cout<<"ppid :"<<getppid()<<endl;sleep(1);}return 0;
}
可以看到目前的cwd更改了,而且log.txt也创建在更改的cwd目录下了
![]()

3.通过系统调用创建进程--fork
如果我们想要在代码中创建一个进程,那么就需要使用fork系统调用,fork的有分流的意思,即本来是一个进程,fork后就变成了一个父进程和子进程,通过man可以得知fork的返回值有两个,父进程返回子进程的Pid,子进程返回0,这是因为父进程和子进程是一比n的关系,因为一个父进程可以用于多个子进程,但是子进程的父进程是唯一的。
int main()
{pid_t id = fork();if(id > 0){while(1){cout<<"我是父进程 pid :"<<getpid()<<" ppid :"<<getppid()<<" id :"<<id<<endl;sleep(1);}}else if(id == 0){while(1){cout<<"我是子进程 pid :"<<getpid()<<" ppid :"<<getppid()<<" id :"<<id<<endl;sleep(1);}}return 0;
}
![]()
可以看出父进程对应的id确实就是子进程的Pid,而子进程的id为0,他的父进程正是16918,这两个循环其实是在同时运行的,fork以后进程一分为二,这两个进程共享代码(采⽤写时拷⻉),但是数据是独立的,所以各自拥有各自的id值,也就能够同时进入这两个循环,而不是一会id大于0一会id等于0。所以进程之间有很强的独立性,多个进程直接运行时互不影响,这里可以用一个例子来说明他们的数据独立且互不影响。
int globl=0;int main()
{pid_t id = fork();if(id > 0){while(1){cout<<"我是父进程 pid :"<<getpid()<<" ppid :"<<getppid()<<" globl :"<<globl<<endl;sleep(1);}}else if(id == 0){globl++;while(1){cout<<"我是子进程 pid :"<<getpid()<<" ppid :"<<getppid()<<" globl :"<<globl<<endl;sleep(1);}}return 0;
}
这里增加了一个全局变量来说明,如果父子进程确实数据独立,那么他们的globl的值应该就是不一样的,运行代码可以看出确实如此。
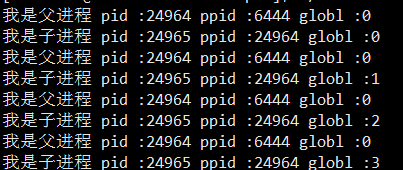
这里结合系统调用再说明一下为什么fork以后会出现两个id返回值,这是为了数据的独立性,在fork的过程中,先会将父进程的PCB拷贝给子进程,然后子进程再调整新的属性,将新的PCB连接到进程列表中,此时子进程就已经创建了而不是返回id以后才会创建,所以此时父子进程数据已经独立了,返回的时候根据PCB的属性返回不同的id。