Vad-R1:通过从感知到认知的思维链进行视频异常推理
文章目录
- 速览
- 摘要
- 1 引言
- 2 相关工作
- 视频异常检测与数据集
- 视频多模态大语言模型
- 具备推理能力的多模态大语言模型
- 3 方法:Vad-R1
- 3.1 从感知到认知的思维链(Perception-to-Cognition Chain-of-Thought)
- 3.2 数据集:Vad-Reasoning
- 3.3 AVA-GRPO
- 3.4 训练流程(Training Pipeline)
- 4 实验
- 4.1 实验设置(Experimental Settings)
- 4.2 主要结果(Main Results)
- 4.3 消融实验(Ablation Studies)
- 4.4 质性分析(Qualitative Analyses)
- 5 结论
- A 附录概述(Summary of Appendix)
- B 所提出的 Vad-Reasoning 数据集
- B.1 标注流程(Annotation Pipeline)
- B.2 统计分析与对比(Statistical Analysis and Comparison)
- B.3 示例(Examples)
- C 实现细节(Implementation Details)
- C.1 提示设计(Prompt)
- C.2 AVA-GRPO 的训练过程(Training Process of AVA-GRPO)
- C.3 更多实验细节(More Experimental Details)
- C.4 在 VANE 基准上的评估(Evaluation on VANE Benchmark)
- D 更多实验结果(More Experimental Results)
- D.1 基于大语言模型的评估(LLM-Guided Evaluation)
- D.2 更多输入帧数量的实验(Experiments on More Input Tokens)
- D.3 更多消融实验(More Ablation Studies)
- D.4 训练曲线(Training Curves)
- D.5 更多定性结果(More Qualitative Results)
- E 影响与局限性(Impact and Limitation)
Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought
¹中山大学深圳校区;²哈尔滨工业大学(深圳);³香港理工大学
arxiv’25’05
速览
Vad-R1 提出“感知-认知”推理链、构建首个含 CoT 的 VAR 数据集,并以 AVA-GRPO 实现弱标签下的自验证强化学习,显著提升异常检测与深度推理能力。
动机
视频异常检测(VAD) 传统上仅回答“有没有异常”,而对 异常发生的原因、过程与后果 缺乏深度理解。
现有使用VLM/MLLM-辅助或直接执行异常检测与理解的方法总体仍停留在浅层描述,模型无法给出连贯、可解释的推理链。
挑战
数据层面:公开数据集中缺少结构化推理注释:大多数只有视频级标签或简短描述,导致模型难以学习“先感知再推理”的完整逻辑。
训练层面:如何在只拥有弱标签的大量视频上继续提升模型推理质量,而不过度依赖人工标注。
数据集
设计 Perception-to-Cognition 四步推理链(全局感知 → 局部感知 → 浅层认知 → 深层认知),构建Vad-Reasoning数据集,可同时用于监督微调与强化学习
- 8 k+ 视频
- 1755 条带高质 CoT (SFT 子集)
- 6 k+ 条仅弱标签 (RL 子集)
方法
在 GRPO 基础上加入 异常验证奖励(剪视频再判定)
- Case 1(正向奖励):如果模型预测为异常,剪掉异常片段后视频变正常,说明它准确定位了异常,给予正向奖励 +0.5;
- Case 2(负向惩罚):如果模型预测为正常,但仅剪掉视频开头或结尾后就变异常,说明它原本凭少量帧判断,给予惩罚 –0.2。
实验
主要围绕3个问题进行验证:
Q1:推理是否能够提升异常检测性能? 通过比较无推理、随机推理与结构化推理的性能
Q2:Vad-R1 在异常推理和检测方面的表现如何? 通过与开源模型、推理专家模型、VAD专家模型进行比较
Q3:如何获得推理能力? 通过消融实验,单独SFT、GRPO 不如 先SFT再GRPO
意义
首次在视频异常场景下验证了结构化 CoT + 自验证 RL的可行性,为 MLLM 在安全监控、无人驾驶等任务上的可解释应用奠定基础。
摘要
近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在推理能力方面取得了显著进展,展现出在处理复杂视觉任务中的有效性。然而,现有基于 MLLM 的视频异常检测(Video Anomaly Detection, VAD)方法仍局限于浅层的异常描述,缺乏深层次的推理能力。
本文提出了一项新任务,称为视频异常推理(Video Anomaly Reasoning, VAR),旨在通过要求 MLLM 在回答前显式思考,来实现对视频中异常事件的深入分析与理解。为此,我们提出了 Vad-R1,一个端到端的基于 MLLM 的 VAR 框架。
具体而言,我们设计了一个“从感知到认知的思维链”(Perception-to-Cognition Chain-of-Thought, P2C-CoT),模拟人类识别异常的过程,引导 MLLM 逐步进行异常推理。在结构化的 P2C-CoT 指导下,我们构建了一个专为 VAR 设计的数据集 Vad-Reasoning。
此外,我们提出了一种改进的强化学习算法 AVA-GRPO,该算法通过有限标注下的自验证机制,显式激励 MLLM 的异常推理能力。实验结果表明,Vad-R1 在多个 VAD 和 VAR 任务上均实现了卓越性能,显著超越了开源和专有模型。
代码与数据集将发布于:https://github.com/wbfwonderful/Vad-R1。
1 引言
视频异常检测(Video Anomaly Detection, VAD)旨在识别视频中的异常事件,已广泛应用于监控系统 [49] 和自动驾驶 [37, 75] 等多个领域。传统的 VAD 方法主要分为两类:半监督方法和弱监督方法。半监督方法 [75, 32, 20, 34, 19, 17] 致力于建模正常事件的特征,而弱监督方法 [66, 49, 18, 17, 24, 90, 21] 仅提供视频级标签。随着视觉-语言模型的发展,一些研究开始引入语义信息以增强 VAD [60, 68, 67, 76, 7]。然而,传统方法仅停留在检测层面,缺乏对异常的理解与解释。
近年来,大语言模型在推理能力方面的进展引发了广泛关注 [41, 9, 54]。与日常对话不同,推理要求模型在回答前进行思考,从而实现因果分析和深入理解。特别地,DeepSeek-R1 证明了强化学习(Reinforcement Learning, RL)在激发模型推理能力方面的有效性 [9]。与此同时,一些研究也开始尝试将推理能力扩展到多模态领域 [53, 56]。
尽管对推理能力的兴趣日益增长,但现有基于多模态大语言模型(Multimodal Large Language Models, MLLMs)的 VAD 方法在推理方面仍表现不足。这些方法可根据 MLLM 的角色分为两类:一类将 MLLM 作为辅助模块 [36, 84, 85, 11],用于在分类器预测异常置信度之后提供补充解释。在此框架下,异常理解是检测之后的一个步骤,MLLM 的输出不会直接促进异常检测。另一类方法虽然尝试让 MLLM 直接执行异常检测与理解 [50, 38, 73, 80, 13, 12],但 MLLM 通常只生成异常描述或基于视频内容进行简单问答,缺乏思考与分析能力。因此,在 VAD 任务中,推理仍然是一个尚未充分探索的问题。
为弥补这一差距,我们提出了一项新任务:视频异常推理(Video Anomaly Reasoning, VAR),旨在赋予 MLLM 结构化、逐步推理视频中异常事件的能力。与现有的视频异常检测或理解任务相比,VAR 更加关注深层次分析,模拟人类的认知过程,从而实现上下文理解、行为解释和规范违背分析。为此,我们提出了 Vad-R1,这是首个端到端的基于 MLLM 的 VAR 框架,其在生成答案之前显式地进行推理。
然而,在视频异常任务中实现推理面临两个主要挑战。首先,现有 VAD 数据集缺乏结构化推理标注,无法满足训练与评估推理模型的需求。其次,如何有效训练模型以获得推理能力仍是一个开放性难题。不同于具有明确目标的任务,开放式 VAR 要求模型执行多步推理,这使得难以定义清晰的训练目标或直接指导推理过程。
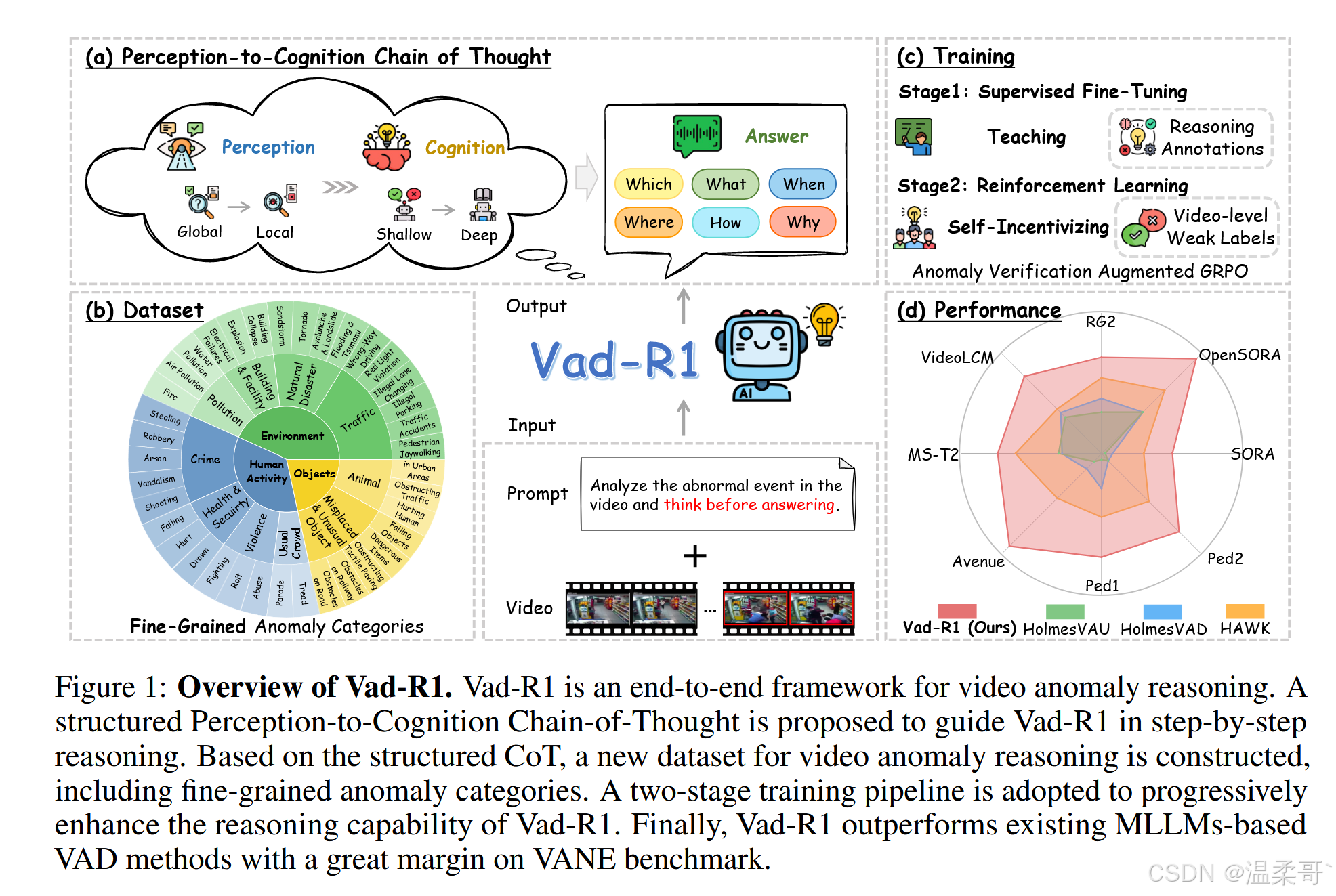
为了解决第一个挑战,我们设计了一个结构化的“从感知到认知的思维链”(Perception-to-Cognition Chain-of-Thought, P2C-CoT)用于视频异常推理,如图 1(a) 所示。该结构借鉴了人类理解视频异常的过程,首先引导模型从视频的整体环境感知,逐步聚焦至可疑片段。在感知完成后,模型将基于视觉线索从浅层到深层逐级认知。最终,模型将输出分析结果作为答案,包括异常类别、异常描述、异常发生的时间范围、空间位置等。
基于上述思维链,我们构建了 Vad-Reasoning,这是一个专为 VAR 任务设计的数据集,涵盖了细粒度的异常类别,如图 1(b) 所示。Vad-Reasoning 包含两个互补子集:一个子集包含由专有模型逐步生成的 P2C-CoT 注释视频,另一个子集包含数量更多但仅提供视频级弱标注的视频,目的是降低标注成本。
为了解决第二个挑战,受 DeepSeek-R1 成功经验的启发,我们提出了一个如图 1(c) 所示的两阶段训练流程。在第一阶段,通过监督微调(Supervised Fine-Tuning, SFT)使基础 MLLM 具备基本的异常推理能力;在第二阶段,使用我们提出的 AVA-GRPO(Anomaly Verification Augmented Group Relative Policy Optimization)强化学习算法进一步激励模型的推理能力。
该算法是 GRPO [47] 的扩展版本,专为 VAR 任务设计。在强化学习过程中,模型首先生成一组推理结果。基于这些推理结果,对原始视频进行时间裁剪,裁剪后的视频再次输入模型以生成新的推理输出。随后,比较两组推理结果,若满足预设条件,则给予额外的异常验证奖励。AVA-GRPO 通过这种自验证机制,在仅有有限标注的情况下,有效提升 MLLM 的视频异常推理能力。
总结而言,本文的主要贡献如下:
-
我们提出了 Vad-R1,一个新颖的端到端 MLLM 框架,旨在对视频异常事件进行深入分析与理解。
-
我们设计了结构化的 P2C-CoT,并据此构建了包含两个子集的专用视频异常推理数据集 Vad-Reasoning。同时,提出改进的强化学习算法 AVA-GRPO,通过自验证机制激励 MLLM 的推理能力。
-
实验结果表明,Vad-R1 在多个评估场景中均表现出卓越性能,在异常检测和推理任务中全面超越现有的开源及专有模型。
2 相关工作
视频异常检测与数据集
视频异常检测(Video Anomaly Detection)旨在定位视频中的异常事件。根据训练数据的不同,传统的 VAD 方法通常可分为两大类:半监督方法 [75, 32, 20, 34, 19, 17, 45, 72, 79] 和弱监督方法 [66, 49, 18, 17, 24, 90, 21, 91]。此外,一些研究尝试引入文本描述以增强检测性能 [60, 68, 67, 76, 7, 8]。近年来,越来越多的研究开始将多模态大语言模型(MLLMs)引入 VAD 以提升理解与解释能力 [36, 50, 38, 73, 80, 84, 85, 11, 13, 12]。然而,目前的研究仍停留在浅层理解,缺乏对推理能力的深入探索。本文提出一个端到端的框架,旨在增强视频异常任务中的推理能力。
此外,现有的 VAD 数据集主要提供粗粒度的类别标签 [49, 66, 37, 1] 或异常事件描述 [13, 12, 50, 78],缺乏对推理过程的标注。为弥补这一空白,我们提出了结构化的“从感知到认知的思维链”(Perception-to-Cognition Chain-of-Thought),并构建了一个专门用于视频异常推理的数据集,提供逐步的 CoT 标注。
视频多模态大语言模型
视频多模态大语言模型提供了一种交互式的方式来理解视频内容。早期的工作通过映射网络对视觉与文本 token 进行对齐,将视觉编码器集成进大型语言模型中 [25, 30, 39, 83, 87]。与静态图像相比,视频包含更多冗余信息,因此部分研究探索了 token 压缩机制以获取更长上下文 [29, 71, 86, 23]。此外,近期也有研究探索了在线流式视频的理解 [6, 10, 74, 69]。尽管如此,这些方法仍局限于视频理解层面,缺乏对推理能力的探索。
具备推理能力的多模态大语言模型
提升多模态大语言模型(MLLMs)推理能力已成为一个主要研究方向。一些研究提出多阶段推理框架与大规模 CoT 数据集来增强 MLLMs 的推理能力 [70, 59, 33]。近期,DeepSeek-R1 [9] 展示了强化学习在提升推理能力方面的潜力,激发了后续在多模态领域的相关工作 [22, 81]。在视频领域,一些研究也使用 RL 来提升空间推理 [28]、时间推理 [64] 和一般因果推理能力 [14, 88]。本文则聚焦于视频异常推理任务。
3 方法:Vad-R1
概述
本节中我们介绍 Vad-R1,这是一个新颖的端到端基于多模态大语言模型(MLLM)的框架,用于视频异常推理(VAR)任务。Vad-R1 的推理能力源于一个两阶段的训练策略:首先在带有高质量 CoT(Chain-of-Thought)注释的视频上进行监督微调(SFT),然后使用 AVA-GRPO 算法进行强化学习(RL)。
我们首先在第 3.1 节中介绍所提出的 P2C-CoT(Perception-to-Cognition Chain-of-Thought);随后在第 3.2 节中基于该思维链构建新数据集 Vad-Reasoning;接着在第 3.3 节中介绍改进后的 RL 算法 AVA-GRPO;最后在第 3.4 节中介绍 Vad-R1 的整体训练流程。
3.1 从感知到认知的思维链(Perception-to-Cognition Chain-of-Thought)
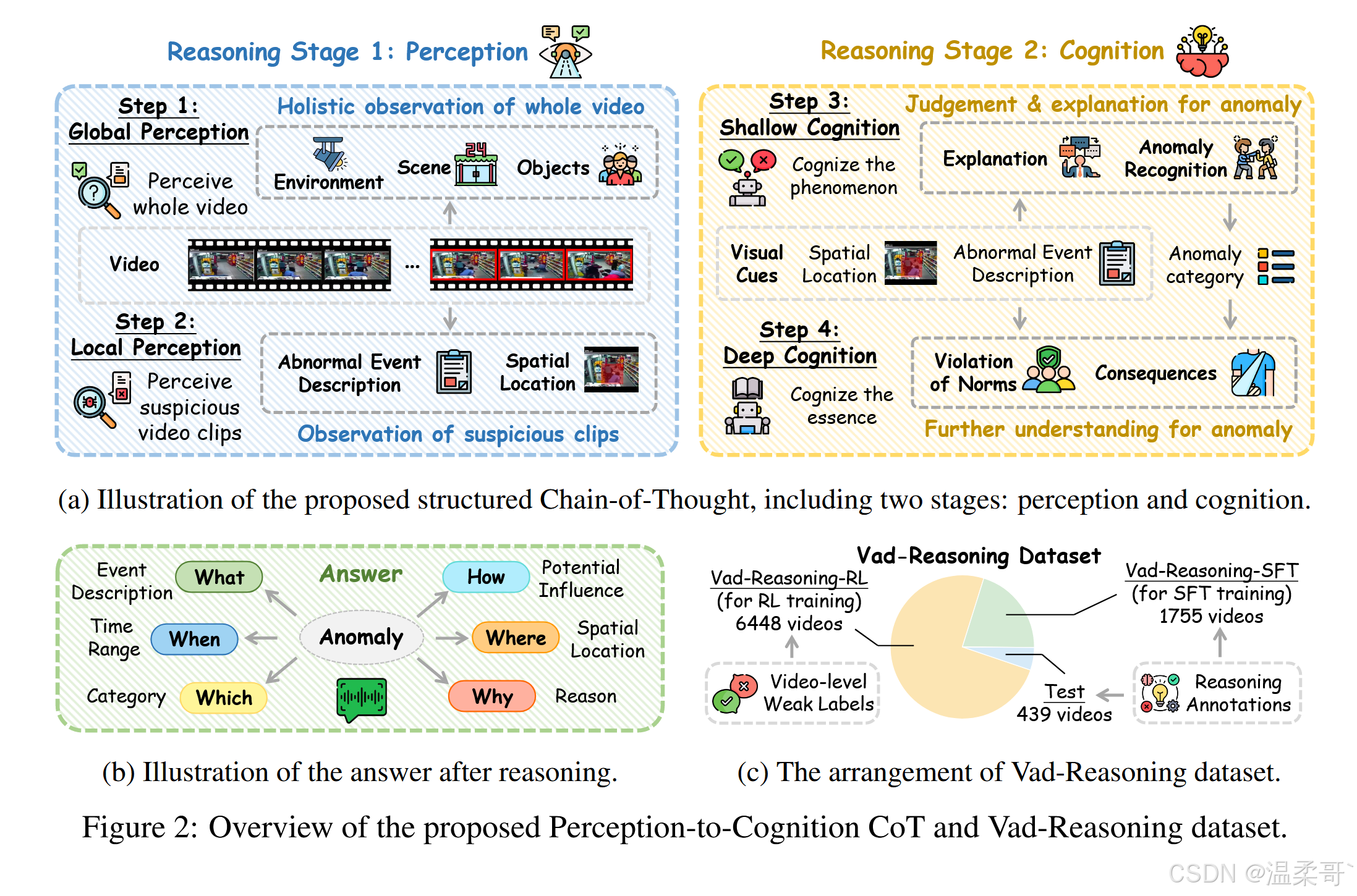
当人类理解一段视频时,通常会首先观察其中发生的事件,然后再基于视觉观察发展出更深层次的理解。受此启发,我们为视频异常推理任务设计了一个结构化的“从感知到认知的思维链”(Perception-to-Cognition Chain-of-Thought, P2C-CoT)。该思维链从感知(Perception)逐步过渡到认知(Cognition),共包含两个阶段、四个步骤,如图 2(a) 所示,最终形成如图 2(b) 中的简洁回答。
感知(Perception)
在观看视频时,人类通常先对整体场景与环境进行全局观察,然后再将注意力转向具体的物体或异常事件。与此一致,P2C-CoT 的感知阶段体现了从全局观察到局部聚焦的转变。模型起初需关注整个环境,描述场景并识别视频中的对象,该步骤要求模型具备对视频中“正常性”的全面理解。在此基础上,模型再聚焦于偏离正常性的事件,识别“发生了什么、何时发生、在哪里发生”。
认知(Cognition)
在观察视频内容之后,人类通常会基于视觉线索识别异常事件,并进一步推理其可能的后果。类似地,P2C-CoT 的认知阶段从浅层认知逐步深入到深层认知。模型首先判断事件是否异常,并结合视觉证据解释其异常性;随后模型需进行更高层次的推理,分析异常事件的成因、违背的社会预期,以及可能导致的后果。
回答(Answer)
如图 2(b) 所示,在完成上述推理过程后,模型需对视频中的判断结果做出简洁总结。最终回答应包含与异常相关的关键要素,包括异常类别(Which)、事件描述(What)、时空定位信息(When & Where)、异常原因(Why)及其潜在影响(How)。
值得注意的是,对于正常视频,P2C-CoT 将被简化为两个步骤。详见附录 B。
3.2 数据集:Vad-Reasoning
视频采集(Video Collection)
现有的 VAD 数据集普遍缺乏对推理过程的标注。为构建一个更适用于 VAR 的数据集,我们从以下两个方面进行考量。
一方面,我们希望该数据集能够涵盖广泛的真实生活场景。类似 HAWK [50],我们从已有 VAD 数据集中采集视频,涵盖的场景包括:监控下的犯罪行为(UCF-Crime [49])、镜头下的暴力事件(XD-Violence [66])、交通场景(TAD [37])、校园环境(ShanghaiTech [32])以及城市街景(UBnormal [1])。此外,我们还从 ECVA [12],一个多场景基准数据集中收集视频。
另一方面,我们致力于扩大异常类别的覆盖范围。为此,我们定义了三类主要异常类型的分类体系:人类行为异常(Human Activity Anomaly)、环境异常(Environments Anomaly) 和 物体异常(Objects Anomaly)。每类被进一步细分为若干子类。随后,我们基于已有数据集从互联网补充采集视频以扩充异常种类。
最终,Vad-Reasoning 数据集共包含 8203 个训练视频和 438 个测试视频。如图 2(c) 所示,训练集被划分为两个子集:
- Vad-Reasoning-SFT:包含 1755 个带有高质量推理过程标注的视频;
- Vad-Reasoning-RL:包含 6448 个仅具有视频级弱标签的视频。
标注过程(Annotation)
为构建 Vad-Reasoning 数据集,我们设计了一个多阶段的标注流程,使用了两个专有模型:Qwen-Max [55] 与 Qwen-VL-Max [57]。为了确保 P2C-CoT 标注涵盖视频中的所有关键信息,我们遵循高帧信息密度原则 [77]。
具体地,我们首先通过 Qwen-VL-Max 生成视频帧的密集描述。然后将这些帧级描述输入至 Qwen-Max,以不同提示词逐步生成思维链(CoT)的各个阶段内容。更多细节请见附录 B。
250530:高帧信息密度强调的是 “进入推理过程中的帧必须有效、浓缩且富含关键线索”,它并不要求所有帧都携带异常,而是确保被用来推理的帧(尤其是异常片段)是最具语义价值的。
3.3 AVA-GRPO
原始的 GRPO 在文本推理任务中展现出了良好的效果。然而如前所述,多模态任务(如 VAR)本质上更加复杂。此外,由于标注成本较高,强化学习阶段仅能获取视频级的弱标签,这使得仅基于准确性和格式奖励评估输出质量变得困难。
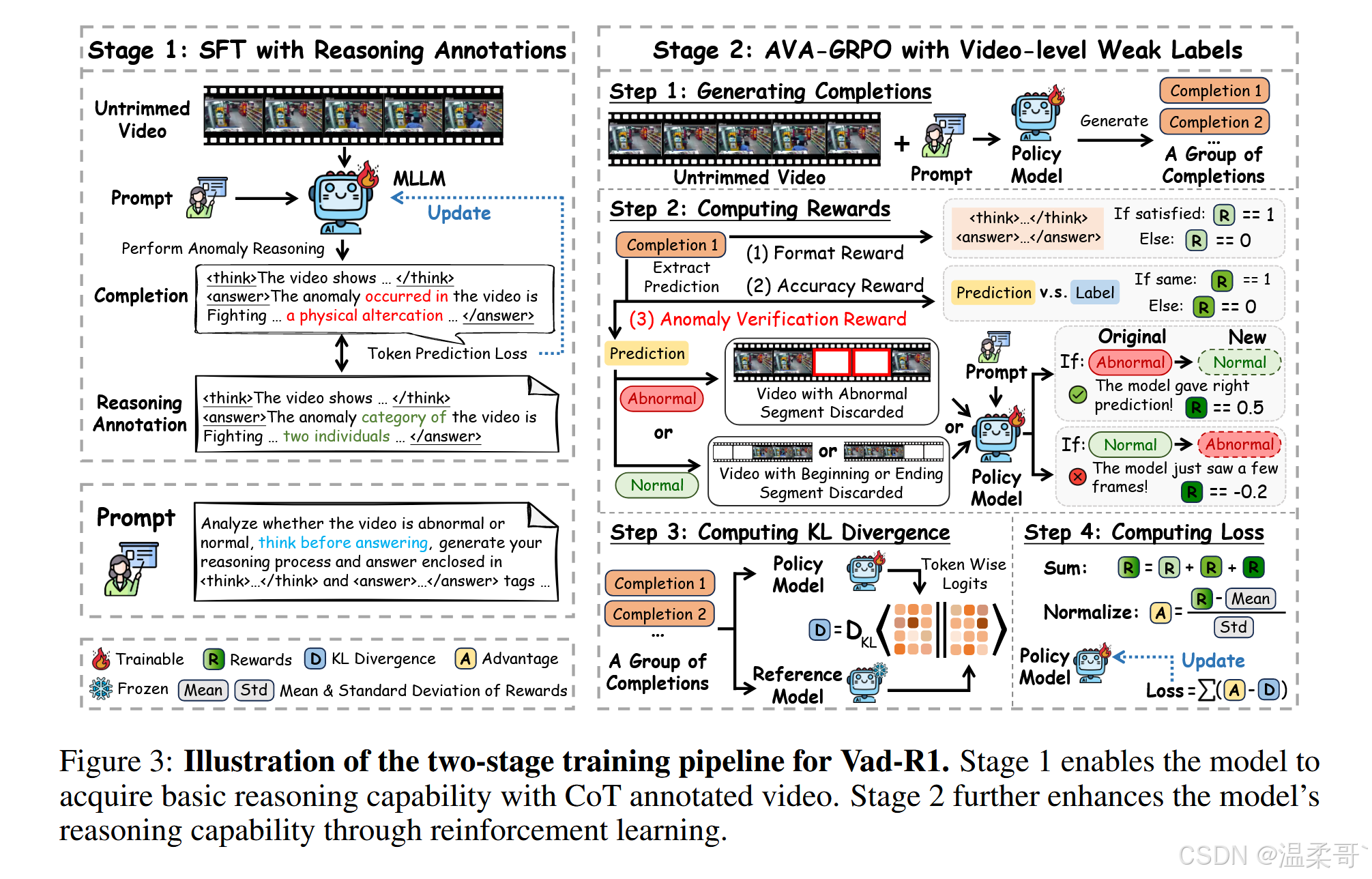
为应对这一挑战,我们提出了 AVA-GRPO(Anomaly Verification Augmented GRPO),该方法通过自验证机制引入了额外的奖励,如图 3 右侧所示。
GRPO 概述
我们首先回顾原始 GRPO [47]。GRPO 去除了值函数模型,旨在最大化答案的相对优势(relative advantages)。对于一个问题 q q q,模型首先生成一组回答 O = { o i } i = 0 G O = \{ o_i \}_{i=0}^{G} O={oi}i=0G,随后计算对应奖励 R = { r i } i = 0 G R = \{ r_i \}_{i=0}^{G} R={ri}i=0G,并根据预设的奖励函数对其进行归一化,计算相对优势:
A i = r i − mean ( R ) std ( R ) (1) A_i = \frac{r_i - \text{mean}(R)}{\text{std}(R)} \tag{1} Ai=std(R)ri−mean(R)(1)
其中, A i A_i Ai 表示回答 o i o_i oi 的相对优势得分,能够更有效地评估单个回答的质量以及组内的相对比较。此外,为防止当前策略 π θ \pi_\theta πθ 与参考策略 π ref \pi_\text{ref} πref 差异过大,GRPO 引入了 KL 散度正则项。最终目标函数如下:
L GRPO ( θ ) = E { q , O } [ 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ϵ , 1 + ϵ ) A i ) − β D K L ( π θ ∥ π ref ) ) ] (2) \mathcal{L}_{\text{GRPO}}(\theta) = \mathbb{E}_{\{q, O\}} \left[ \frac{1}{G} \sum_{i=1}^{G} \left( \min\left( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_\text{old}}(o_i \mid q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_\text{old}}(o_i \mid q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) - \beta \, \mathrm{D}_{\mathrm{KL}}(\pi_\theta \,\|\, \pi_\text{ref}) \right) \right] \tag{2} LGRPO(θ)=E{q,O}[G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref))](2)
其中, π θ ( o i ∣ q ) π θ old ( o i ∣ q ) \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_\text{old}}(o_i \mid q)} πθold(oi∣q)πθ(oi∣q) 表示当前策略与旧策略之间的相对变化, clip ( ⋅ , 1 − ϵ , 1 + ϵ ) \text{clip}(\cdot, 1 - \epsilon, 1 + \epsilon) clip(⋅,1−ϵ,1+ϵ) 用于限制变化范围。
异常验证奖励(Anomaly Verification Reward)
GRPO 使用组相对评分替代值函数模型,从而减少了内存消耗与训练时间。然而,仅依赖准确性和格式奖励不足以评估视频异常推理任务中答案的质量。为此,我们提出了 AVA-GRPO,这是 GRPO 的扩展版本,包含一种新的异常验证奖励机制。具体而言,如图 3 右侧所示,对于每个生成的答案 o i o_i oi,首先提取模型预测的视频异常类别,然后根据该预测对原视频进行时间裁剪,并将裁剪后的视频再次输入模型以生成新的答案。通过比较原始与再生成的答案,决定是否给予额外的异常验证奖励。
一方面,若视频最初被判定为异常,则提取异常事件的预测时间范围,并从原视频中裁剪对应片段,生成一个仅包含正常片段的新视频。该裁剪后的视频被重新输入模型进行推理。如果该新视频被模型判断为“正常”,说明被裁剪的片段确实是异常的,且模型最初的判断是正确的。在这种情况下,将给予正奖励,以增强模型的原始判断。
另一方面,受 Video-UTR [77] 启发,我们考虑到视频多模态语言模型中的“时间黑客(temporal hacking)”现象——模型倾向于仅凭开头或结尾的少量帧做出预测,而不处理整个视频序列,这不利于异常事件的识别。因此,若模型最初将视频判断为正常,我们将随机丢弃视频的起始或末尾片段,并将裁剪后的视频重新输入模型。如果此时模型判断其为异常,则表明模型先前的预测仅基于不足的视觉证据,属于非期望行为。在这种情况下,将给予负奖励。
250530:Case 1(正向奖励):如果模型预测为异常,剪掉异常片段后视频变正常,说明它准确定位了异常,给予正向奖励 +0.5;Case 2(负向惩罚):如果模型预测为正常,但仅剪掉视频开头或结尾后就变异常,说明它原本凭少量帧判断,给予惩罚 –0.2。
3.4 训练流程(Training Pipeline)
我们采用 Qwen-2.5-VL-7B [57] 作为基础 MLLM。Vad-R1 的训练流程由两个阶段组成,如图 3 所示。
第一阶段,在 Vad-Reasoning-SFT 数据集上进行监督微调(Supervised Fine-Tuning),该数据集中的视频带有高质量的思维链(Chain-of-Thought, CoT)标注。
在此阶段,模型的能力将从通用的多模态理解逐步转向视频异常理解,使其具备基本的异常推理能力。
第二阶段,在 Vad-Reasoning-RL 数据集上继续训练,并使用我们提出的 AVA-GRPO 强化学习算法。在该阶段,由于仅提供视频级的弱标签,AVA-GRPO 通过自验证机制评估模型响应的质量。这一阶段旨在使模型摆脱 SFT 阶段的模式匹配倾向,从而学习到更具灵活性与可迁移性的异常推理能力。
更多细节可参考附录 C。
4 实验
4.1 实验设置(Experimental Settings)
实现细节(Implementation Details)
Vad-R1 基于 Qwen-2.5-VL-7B [57],采用两阶段训练流程。在第一阶段,使用 Vad-Reasoning-SFT 数据集进行 4 个 epoch 的监督微调(SFT)。第二阶段使用 AVA-GRPO 算法在 Vad-Reasoning-RL 数据集上进行 1 个 epoch 的强化学习训练,该阶段仅提供视频级的弱标签。所有实验在 4 块 NVIDIA A100(80GB)GPU 上进行。更多细节见附录 C。
评估指标与对比方法(Evaluation Metrics and Baselines)
我们在 VA-Reasoning 的测试集上评估 Vad-R1 的性能,重点关注两个方面:异常推理与异常检测。
- 对于异常推理,我们使用 BLEU [43]、METEOR [3] 和 ROUGE [31] 等指标评估推理过程文本的质量。
- 对于异常检测,我们报告分类的准确率(accuracy)、精确率(precision)、召回率(recall)和 F1 分数,同时评估异常时间定位性能,包括 mIoU 和 R@K。
250530:
🧠 异常推理指标
BLEU:看模型写的句子里,有多少词组跟标准答案完全一样,匹配得多就得分高。
METEOR:不光看词是不是一样,还考虑同义词和词形变化,判断更聪明、更宽容。
ROUGE:看模型有没有覆盖参考答案里的关键信息,越全面得分越高。🚨 异常检测指标
Accuracy(准确率):模型判断对的次数除以总次数,越高说明整体判断越可靠。
Precision(精确率):模型说“异常”的视频中,实际真异常的比例,高说明误报少。
Recall(召回率):所有真异常的视频中,被模型成功识别出来的比例,高说明漏报少。
F1 分数:精确率和召回率的综合得分,衡量模型是否又准又不漏。🕒 异常定位指标
mIoU(平均交并比):模型画的异常时间段和真实异常段重合得有多好,越重合得分越高。
R@K(Recall at K):看模型前 K 个预测的异常片段中,有没有命中真正的异常;比如 R@0.5 就是看有没有画对至少一半重合的异常片段。这里的“前 K 个”好像指的是模型对一个输入视频的预测可能会有多个异常片段,所以前 K 个是他最自信的 K 个。
此外,为进一步探索 Vad-R1 的能力,我们在 VANE [15] 数据集上进行实验,该数据集是针对 MLLM 的视频异常基准集,任务形式为单选题。我们报告各类别的预测准确率。
我们将 Vad-R1 与以下方法进行对比:
- 通用视频 MLLMs:[25, 30, 39, 83, 87]
- 推理型视频 MLLMs:[28, 64, 14, 88]
- 专有模型:[56, 40, 52, 51]
- 基于 MLLM 的 VAD 方法:[50, 85, 84]
接下来的章节将围绕以下问题展开实验结果分析:
- Q1:推理是否能提升异常检测性能?
- Q2:Vad-R1 在异常推理和检测任务中的表现如何?
- Q3:如何获得推理能力?
4.2 主要结果(Main Results)
Q1:推理是否能够提升异常检测性能?
表 1 展示了异常推理的有效性。一方面,我们评估了 Qwen2.5-VL [57] 和 Qwen3 [58] 的性能。如表 1 前两行所示,与直接回答相比,提示模型按照所提出的“从感知到认知的思维链(P2C-CoT)”进行推理可以显著提升性能。与此同时,我们还评估了随机推理的效果。在该设置下,性能提升非常有限,甚至低于直接回答。
250530:随机推理指的是不依照 P2C-CoT(感知到认知的推理链条)结构去组织推理过程,而是生成一些没有逻辑结构或顺序混乱的推理内容。
值得注意的是,Qwen3 是一个同时支持推理模式与非推理模式的混合模型,在相同任务下的一致性能差异进一步验证了所提出的 P2C-CoT 在异常推理与检测中的有效性。
另一方面,我们比较了使用完整 P2C-CoT 与仅使用最终答案部分训练的 Vad-R1 的性能。如表 1 第三行所示,当仅使用最终答案进行训练时,模型性能出现下降。

Q2:Vad-R1 在异常推理和检测方面的表现如何?
表 2 展示了 Vad-R1 在 Vad-Reasoning 测试集上的异常推理与检测任务的性能对比结果。Vad-R1 在推理文本质量与异常检测准确性两个方面均取得了优异表现。
特别地,Vad-R1 在异常推理能力方面显著超越了现有的专有 MLLM 推理模型,如 Gemini2.5-Pro、QVQ-Max 和 o4-mini,在 BLEU 分数上分别提升了 0.088、0.091 和 0.127。

此外,与现有的基于 MLLM 的 VAD 方法相比,Vad-R1 在异常推理与检测方面也表现出更大优势。表 3 展示了其在 VANE 基准上的结果,Vad-R1 超越了所有基线模型,包括通用视频 MLLMs 与基于 MLLM 的 VAD 方法。

250530:Gani H, Bharadwaj R, Naseer M, et al. VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs[C]//Findings of the Association for Computational Linguistics: NAACL 2025. 2025: 3123-3140.
4.3 消融实验(Ablation Studies)
Q3:如何获得推理能力?
表 4 展示了不同训练策略的效果。当直接对基础模型进行强化学习(RL)而没有预先进行 SFT(监督微调)时,性能提升是有限的。这表明在缺乏基本推理能力的前提下,模型难以从仅有视频级弱标签的 RL 训练中获益。
相比之下,引入 SFT 可显著提升性能,说明结构化的 CoT(Chain-of-Thought)标注能够有效地赋予模型基础的异常推理能力。值得注意的是,SFT 与 RL 的组合实现了最佳性能。这一结果与 DeepSeek-R1 [9] 的结论一致,即 SFT 阶段为模型提供了基础的推理能力,而 RL 阶段则进一步强化该能力。

4.4 质性分析(Qualitative Analyses)
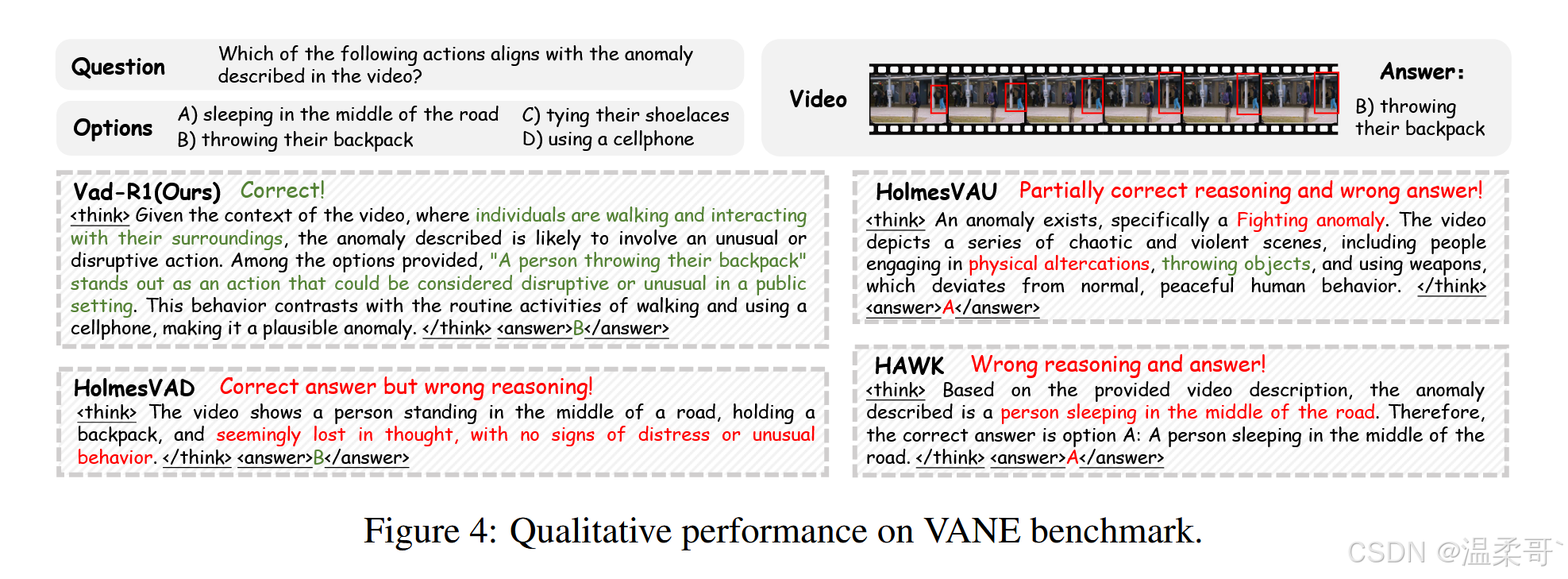
如图 4 所示,Vad-R1 在复杂环境中展现了强大的推理能力,并能够正确识别视频中的异常事件。相比之下,HolmesVAU 的推理过程部分正确,导致判断错误,而 HolmesVAD 的判断虽然正确,但推理过程不准确。更多质性结果请见附录 D。
5 结论
本文提出了 Vad-R1,一个新颖的端到端基于 MLLM 的视频异常推理框架,旨在实现对视频异常事件的深入分析与理解。Vad-R1 通过结构化的思维链(Chain-of-Thought)实现异常推理,该过程从感知逐步过渡到认知。
Vad-R1 的推理能力来源于两阶段训练策略:在具有 CoT 注释的视频上进行的监督微调(SFT),以及结合异常验证机制的强化学习(RL)。实验结果表明,Vad-R1 在异常检测与推理任务中表现出卓越性能。
A 附录概述(Summary of Appendix)
本附录为正文提供补充信息。首先,我们详细介绍了所提出的 Vad-Reasoning 数据集,包括其构建过程、统计分析及示例。随后,我们进一步提供了更多实验细节,包括提示词设计、参数设置及计算资源配置。此外,附录还包含了更多实验结果及可视化内容。最后,我们讨论了本工作的潜在影响与局限性。
B 所提出的 Vad-Reasoning 数据集
B.1 标注流程(Annotation Pipeline)
Vad-Reasoning 的训练集包含两个子集:Vad-Reasoning-SFT 与 Vad-Reasoning-RL。
对于 Vad-Reasoning-RL,我们保留原始数据集的标注,并将其压缩为视频级别的弱标签(异常或正常)。
对于 Vad-Reasoning-SFT,我们设计了一个基于所提出的 P2C-CoT 的多阶段标注流程,如图 5 所示。
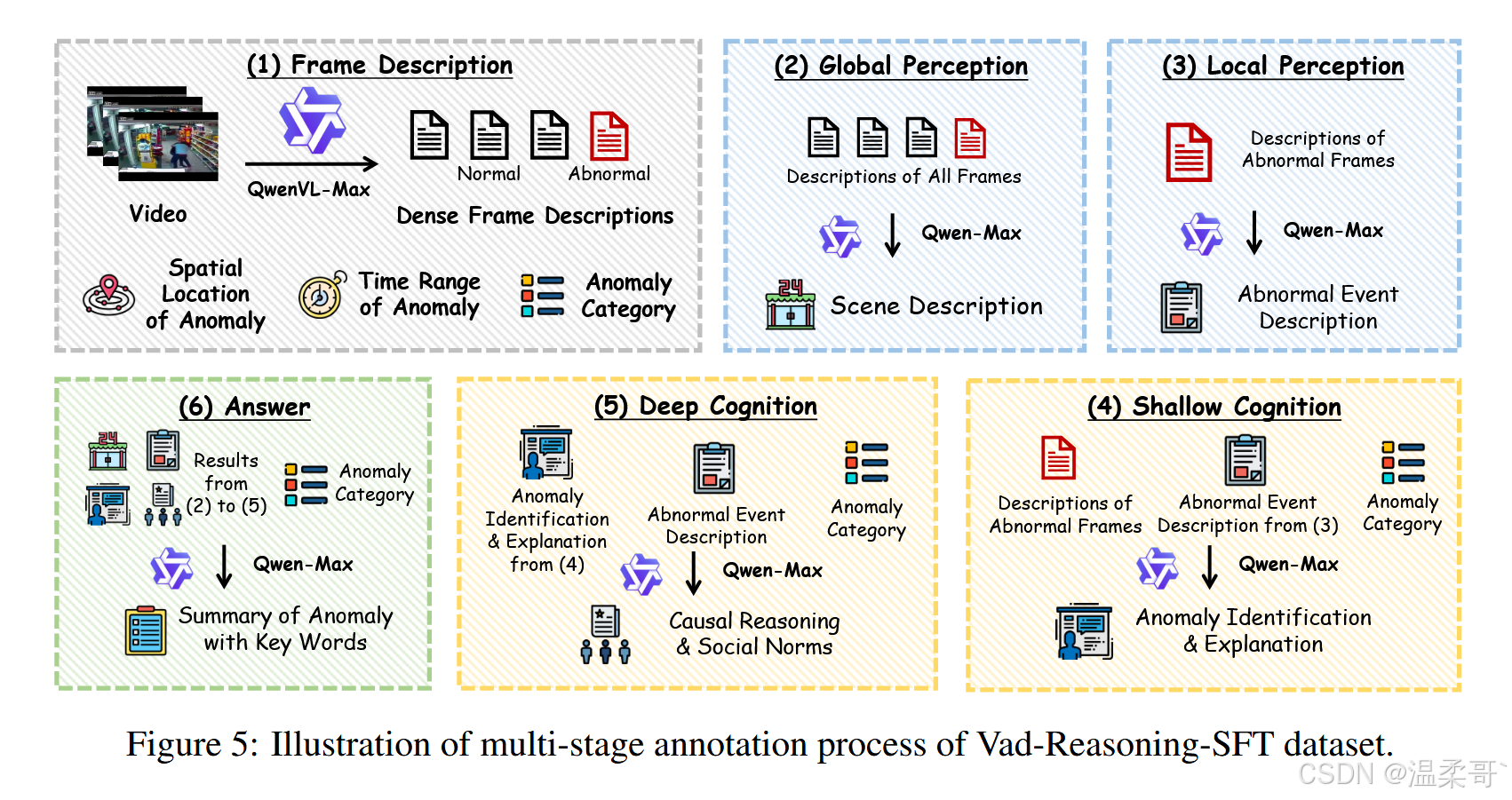
Frame Description(帧描述)
每段视频首先被标注:(1) 异常的大致空间位置,(2) 异常的时间跨度,(3) 细粒度的异常类别。随后,视频按帧间隔 16 被分解为若干帧,并输入 Qwen-VL-Max 生成详细描述。
250530:这些标注到底是人标的还是模型标的,如果是模型标的,是先让VL输出大致空间位置、事件跨度、异常类别,然后再让VL基于这个信息输出帧描述吗?
Global Perception(全局感知)
将所有帧的描述按时间顺序拼接,并送入 Qwen-Max,生成涵盖环境、物体和动作的整体场景描述。需要注意,此阶段仅描述正常模式。
Local Perception(局部感知)
将对应于异常帧的描述提取出来,再次输入 Qwen-Max,生成对异常事件的描述。但该阶段仍停留在“感知”层面,不涉及对异常性的判断。
Shallow Cognition(浅层认知)
基于异常帧的描述与对应异常类别,Qwen-Max 在此阶段需完成异常的初步识别与简要解释。
Deep Cognition(深层认知)
在浅层认知的基础上,Qwen-Max 对视频中的异常进行更深入的推理,输出更详尽的异常事件描述及其对应类别。
Answer(答案)
最后,Qwen-Max 将以上各阶段输出整合生成简洁摘要,并用定义好的标签包裹关键词,例如使用 <which></which> 表示预测的异常类型,<what></what> 表示异常事件的描述等。
标注规范
为确保 Qwen-VL-Max 与 Qwen-Max 生成的标注具有高质量和伦理合规性,我们在整个标注流程中遵循以下准则:
- Relevance(相关性):所有回答必须直接关联视频的可视内容,严禁出现无关假设或幻觉内容。
- Objectivity(客观性):所有回答必须基于可观察的视觉证据,避免主观推测。
- Neutrality(中立性):不得包含地理位置、种族、性别、政治观点或宗教信仰等偏向性内容。
- Non-discrimination(反歧视):严禁使用任何带有偏见、歧视或冒犯性的语言。
- Style(风格):语言应简洁、中性、通用,确保普遍可读性与可用性。
- Conciseness(简明性):每条回答应控制在 4 至 6 句之间,以保持表达清晰聚焦。
B.2 统计分析与对比(Statistical Analysis and Comparison)
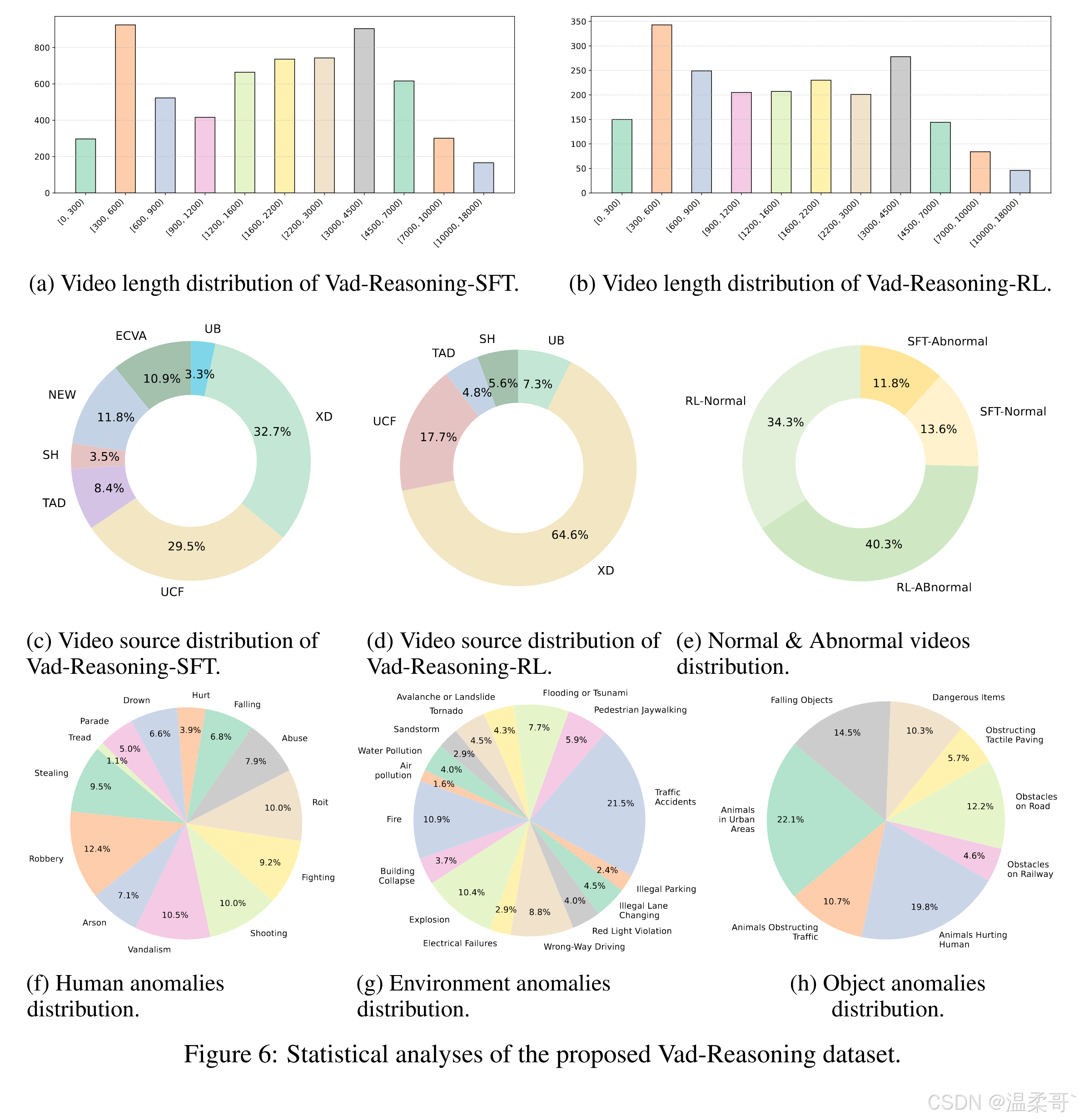
我们将 Vad-Reasoning 与现有的视频异常检测与理解数据集进行了对比,如表 5 和表 6 所示。Vad-Reasoning 总共包含 8641 个视频,涵盖 3400 万帧和超过 360 小时的视频时长,是当前最大规模的视频异常理解基准之一。

此外,Vad-Reasoning-SFT 提供了细粒度的思维链(CoT)标注,显式模拟人类在异常事件上的推理过程,平均每段标注长度为 260 个词。相比之下,近期的视频异常理解数据集如 CUVA [13] 和 ECVA [12] 虽然也描述了异常的成因与影响,但它们的标注往往是零散、割裂的,缺乏系统结构与逻辑衔接。而 Vad-Reasoning-SFT 提供的是结构清晰、逻辑连贯的异常推理标注。
图 6 对 Vad-Reasoning 数据集进行了全面的统计分析。图 6(a) 与 6(b) 展示了视频时长的整体分布,整体分布较为均匀。图 6(c) 与 6(d) 显示,大部分视频来自 UCF-Crime [49] 与 XD-Violence [66],另有约 10% 的视频来源于互联网。
图 6(e) 展示了正常与异常视频在两个子集中的分布比例,整体较为平衡。图 6(f)-(h) 则呈现了细粒度异常类别的分布情况。
B.3 示例(Examples)
我们在图 7 和图 8 中提供了两个 Vad-Reasoning 数据集的示例。需要注意的是,对于正常视频,其 CoT(思维链)被简化为两个步骤,即感知与认知两个阶段。

C 实现细节(Implementation Details)
C.1 提示设计(Prompt)
用于执行视频异常推理的提示如图 9 所示。该提示由三部分组成:任务定义(Task Definition)、输出规范(Output Specification) 和 格式要求(Format Requirements)。
首先,任务定义描述了视频异常推理的整体目标,并明确要求模型在回答前进行思考。
其次,输出规范提供了推理过程与期望回答的详细指导说明。
最后,格式要求展示了包含明确标签的输出示例(例如,使用 <think></think> 表示思维链内容,使用 <answer></answer> 表示最终答案)。

C.2 AVA-GRPO 的训练过程(Training Process of AVA-GRPO)
所提出的 AVA-GRPO 的核心在于引入了额外的异常验证奖励(详见算法 1)。

此外,我们还引入了长度奖励(Length Reward)。我们首先分别计算 Vad-Reasoning-SFT 中异常视频与正常视频的推理文本长度。在强化学习过程中,若模型输出的文本长度符合对应范围,即可获得长度奖励。
值得注意的是,对于每次生成的回答,模型只更新一次参数。
因此,AVA-GRPO 的目标函数被简化为:
L AVA-GRPO ( θ ) = E { q , O } [ 1 G ∑ i = 1 G ( π θ ( o i ∣ q ) π θ no grad ( o i ∣ q ) A i − β D K L ( π θ ∥ π ref ) ) ] (3) \mathcal{L}_{\text{AVA-GRPO}}(\theta) = \mathbb{E}_{\{q, O\}} \left[ \frac{1}{G} \sum_{i=1}^{G} \left( \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{no grad}}}(o_i \mid q)} A_i - \beta \, \mathrm{D}_{\mathrm{KL}}(\pi_\theta \,\|\, \pi_{\text{ref}}) \right) \right] \tag{3} LAVA-GRPO(θ)=E{q,O}[G1i=1∑G(πθno grad(oi∣q)πθ(oi∣q)Ai−βDKL(πθ∥πref))](3)
其中 π θ no grad \pi_{\theta_{\text{no grad}}} πθno grad 与 π θ \pi_\theta πθ 等价,仅用于梯度停止。最终,AVA-GRPO 的训练过程详见算法 2。

250530: π θ no grad π_{θ_{\text{no grad}}} πθno grad 不回传梯度,是为了在策略优化中起到“对比基准”的作用,确保只有当前策略被更新,旧策略保持固定,从而稳定策略学习过程。这是 PPO/GRPO 等方法的标准做法。
C.3 更多实验细节(More Experimental Details)
所有实验均在 4 块 NVIDIA A100(80GB)GPU 上进行。
- 监督微调阶段:在 Vad-Reasoning-SFT 数据集上训练基础 MLLM 共 4 个 epoch,耗时约 6 小时。
- 强化学习阶段:在 Vad-Reasoning-RL 数据集上继续训练 1 个 epoch,耗时约 26 小时。
为提升训练效率,我们将所有视频统一归一化为 16 帧,且每帧的最大像素尺寸限制为 128 × 28 × 28 128 \times 28 \times 28 128×28×28。
- 两阶段的学习率均设为 1 × 10 − 6 1 \times 10^{-6} 1×10−6。
- 每组生成的候选回答数量为 4。
- 异常验证奖励函数中公式 (3) 的超参数 β \beta β 设为 0.04。
- AVA-GRPO 共包含五种奖励类型,具体值与含义详见表 7。
推理过程长度约束如下:
- 对于正常视频,设定范围为 [ 140 , 261 ] [140, 261] [140,261];
- 对于异常视频,设定范围为 [ 233 , 456 ] [233, 456] [233,456]。
250530:128*28*28 大概就是 448*224

C.4 在 VANE 基准上的评估(Evaluation on VANE Benchmark)
VANE [15] 是一个专为评估视频多模态大语言模型(video-MLLMs)检测视频异常能力而设计的基准数据集。该数据集包含 325 段视频剪辑与 559 个问答对,涵盖现实监控场景与 AI 生成视频,异常类型被划分为 9 类。
对于现实世界异常,VANE 从现有的视频异常检测数据集中收集了 128 段视频(例如:CUHK Avenue [35]、UCSD-Ped1/Ped2 [26]、UCF-Crime [49])。
对于 AI 生成的异常,VANE 包含 197 段由以下系统生成的视频:
- SORA [4]
- OpenSora [16]
- Runway Gen2 [46]
- ModelScopeT2V [61]
- VideoLCM [62]
我们报告了 Vad-R1 及其他基于 MLLM 的 VAD 方法在不同类别上的性能表现。
需要注意的是,由于 Vad-R1 使用了包含 UCF-Crime 视频的 Vad-Reasoning 数据集进行训练,我们在 VANE 基准中排除了 UCF-Crime 对应子集以避免数据泄漏。
250530:数据泄露是指测试集中的数据在训练过程中已经以某种方式被模型见过或用过了,导致评估结果虚高、不公平、不可信。
D 更多实验结果(More Experimental Results)
D.1 基于大语言模型的评估(LLM-Guided Evaluation)
传统的评估指标,如 BLEU 和 METEOR,主要关注生成答案与参考答案在 token 级别的重合度。然而,这些指标在捕捉生成答案的语义质量方面存在天然局限,尤其在涉及因果推理与上下文判断的任务中更为明显。
为弥补这一不足,我们借助专有的大语言模型(LLM)对生成回答的质量进行辅助评估。参考 HAWK [50],我们从以下几个方面进行评估:
-
Reasonability(合理性):评估生成的回答是否呈现出连贯且逻辑有效的异常因果推理。
-
Detail(细节性):评估模型输出中信息的具体性与内容的丰富性。高质量回答应覆盖关键的上下文要素。
-
Consistency(一致性):关注生成回答与参考元数据之间的事实对齐程度,包括事件描述、潜在后果等内容。
每一维度的评分范围为 [ 0 , 1 ] [0, 1] [0,1],其中 1 表示语义对齐与推理质量最高。
表 8 展示了在 Vad-Reasoning 测试集上的评估结果对比。结果表明:
- Vad-R1 在所有开源方法中表现最佳;
- 与专有 MLLM 相比,Vad-R1 尤其在 Reasonability 与 Consistency 两项指标上展现出更优性能,甚至超过了 GPT-4o。

D.2 更多输入帧数量的实验(Experiments on More Input Tokens)
在训练与推理阶段,原始视频统一采样为 16 帧输入,每帧像素上限为 128 × 28 × 28 128 \times 28 \times 28 128×28×28。在本节中,我们将每个视频的帧数增加到 32 与 64,并将每帧的最大像素数提高至 256 × 28 × 28 256 \times 28 \times 28 256×28×28。实验结果见表 9。
一方面,我们观察到帧数从 16 增加至 64 可在异常推理与检测两个任务上均带来性能提升,说明更多帧提供了更有用的视觉信息。
另一方面,分辨率的提升是否有益则取决于帧数。当在 16 帧设置下将像素上限提升到 256 × 28 × 28 256 \times 28 \times 28 256×28×28 时,模型性能虽提升幅度较小,但提升稳定,表明高分辨率细节可在帧数较少时带来补偿效果。
相反,当帧数增加到 32 时,若进一步提升像素上限,性能反而下降,这可能是由于 token 冗余导致。因此,相较于分辨率,增加帧数更有效;而提升分辨率则可能引起信息过载。

D.3 更多消融实验(More Ablation Studies)
在本节中,我们评估所提出的 AVA-GRPO 的有效性。
与原始 GRPO 相比,AVA-GRPO 额外引入了异常验证奖励,用于在仅有视频级弱标签的情况下激励 MLLM 提升异常推理能力。同时,我们还加入了一个长度奖励,以控制生成文本的长度。
这两个附加奖励项的有效性如表 10 所示:
- 在 16 帧和 32 帧两种设置下,AVA-GRPO 在异常推理与检测任务中均优于原始 GRPO。
- 相比之下,若仅使用其中一个奖励项,模型性能提升有限且不稳定。
这些结果表明:结合异常奖励与长度奖励是提升整体推理与检测性能的关键。

D.4 训练曲线(Training Curves)
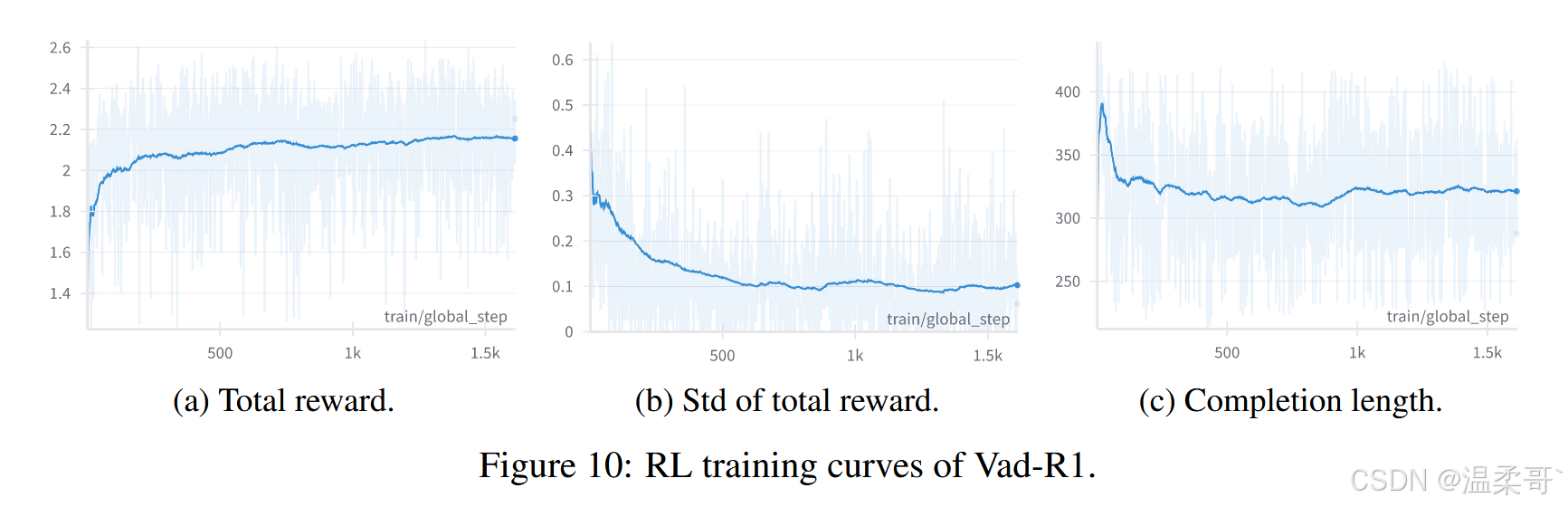
图 10 展示了 Vad-R1 在强化学习阶段的关键训练曲线。
- 图 10(a) 显示了 AVA-GRPO 的总奖励随训练步骤的变化,总体趋势为稳定上升,并在约 1000 步后收敛,说明 Vad-R1 的输出策略与奖励函数的匹配程度持续提升。
- 图 10(b) 显示了总奖励的标准差,在训练初期迅速下降,并稳定在 0.1 以下,表明输出质量随训练的进行而逐渐稳定。
- 图 10(c) 报告了生成回答的平均长度,在训练初期有所上升,随后趋于平稳,暗示模型逐步生成更加精炼而高效的回答,同时保持较高奖励水平。
D.5 更多定性结果(More Qualitative Results)
我们在图 11 和图 12 中展示了两个定性结果。与一些专有模型相比,Vad-R1 展示出稳健的异常推理与检测能力。
例如,在图 11 中,Vad-R1 成功识别了“白色塑料袋”为异常对象,并进行了合理的推理。
相比之下,Claude 虽然也检测到了塑料袋,但将其异常原因解释为“塑料袋在移动”,而非“塑料袋阻挡路径”这一更合理的因果逻辑。
此外,QVQ-Max 与 o4-mini 虽然也注意到了白色塑料袋,但并未将其判断为异常。

E 影响与局限性(Impact and Limitation)
本文提出了一个新任务:视频异常推理(Video Anomaly Reasoning),旨在使 MLLM 能够对视频中的异常事件进行深入分析与理解。我们希望本工作能为视频异常研究领域作出贡献。
然而,Vad-R1 的一个局限性在于推理速度较慢。由于其采用多阶段推理机制,这带来了额外的计算开销。