【google 论文】Titans: Learning to Memorize at Test Time
核心思想与贡献:
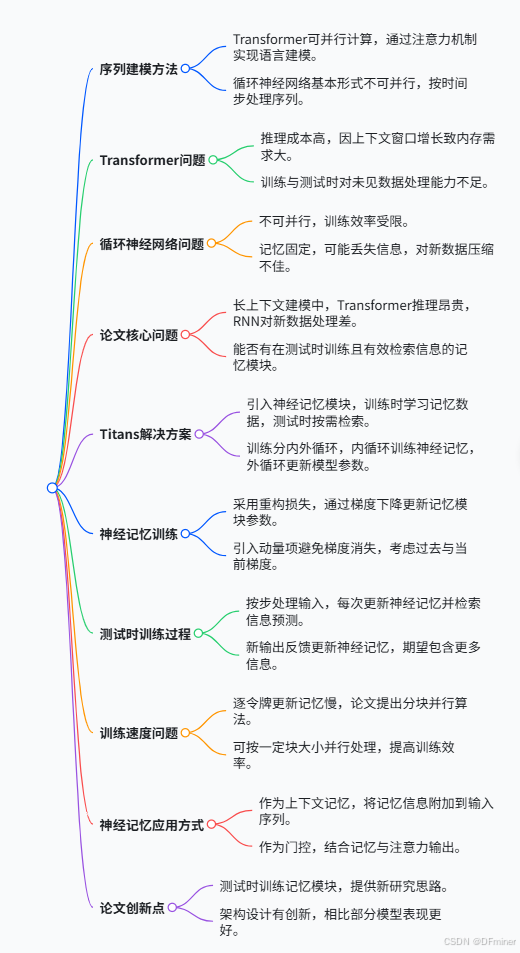
这篇论文的核心贡献在于提出了一种新的神经网络长期记忆模块 (neural long-term memory module),并基于此构建了一个名为 Titans 的新型系列架构。这个架构旨在克服现有模型(如Transformers)在处理超长序列和长期依赖方面的局限性。
关键特性在于,Titans 能够在测试阶段(test time / inference time,即模型实际应用时)动态地学习去记忆和遗忘信息。这与传统模型在训练后参数固定的做法有显著不同。
类比人类记忆系统:
研究者从人脑拥有短期记忆和长期记忆的不同系统获得启发。在Titans架构中:
- 短期记忆 (Short-Term Memory): 类似于标准模型中的注意力机制 (attention mechanisms)。注意力机制能让模型关注当前上下文中最相关的部分,但其计算复杂度通常随上下文长度二次方增长,限制了处理序列的长度。
- 长期记忆 (Long-Term Memory): 由Titans提出的新型神经模块实现。这个模块被设计用来持久存储历史上下文信息,并能动态学习哪些信息需要被“储存”起来,哪些信息可以被“遗忘”。
Titans架构的关键点:
- 测试时学习与记忆: 这是最核心的特性。模型在遇到新数据时,不仅仅是预测,还会根据一定的机制(例如,基于输入的“惊奇程度”——即输入数据与模型已有知识的差异程度,通常用梯度大小来衡量)来更新其长期记忆模块。
- 处理超长上下文: 实验结果表明,Titans架构能够有效扩展到处理超过200万个token的超长上下文,并在“大海捞针”(needle-in-haystack,即在大量无关信息中找到关键信息)这类任务中展现出更高的准确性。
- 平衡短期精度与长期持久性: Titans试图结合注意力机制的短期精确性与神经长期记忆模块的持久性。
- 多种集成方式: 论文提出了Titans架构的三种变体,探讨了如何有效地将长期记忆模块整合到整体架构中,例如:
- Memory as Context (MAC): 将记忆模块的输出作为额外上下文供注意力机制使用。
- Memory as Gate (MAG): 通过门控机制结合记忆模块和注意力模块的输出。
- Memory as Layer (MAL): 将记忆层和注意力层串行堆叠。
- 遗忘机制: Titans包含复杂的遗忘机制(例如,通过权重衰减),逐渐降低不那么“令人惊讶”或不那么重要的信息的权重,以防止记忆过载,同时确保关键信息的保留。
- 应用广泛: 实验表明,Titans在多种任务上均优于传统的Transformer模型和一些现代的线性循环模型 (linear recurrent models),这些任务包括语言建模、常识推理、基因组学序列分析和时间序列预测等。
