【Doris基础】Apache Doris业务场景全解析:从实时数仓到OLAP分析的完美选择
目录
1 Doris核心能力概述
2 实时数据分析场景
2.1 实时数据仓库
2.2 实时监控与告警
3 交互式OLAP分析场景
3.1 自助式BI分析
3.2 用户行为分析
4 大数据分析场景
4.1 日志分析系统
4.2 时序数据处理
5 Doris技术架构适配性分析
5.1 适合Doris的场景特征
5.2 不适合Doris的场景
6 Doris在技术栈中的定位
7 总结与选型建议
7.1 Doris核心价值总结
7.2 选型决策checklist
Apache Doris作为一款开源的MPP分析型数据库,凭借其卓越的性能和灵活的架构,已在众多行业和业务场景中得到广泛应用。
1 Doris核心能力概述
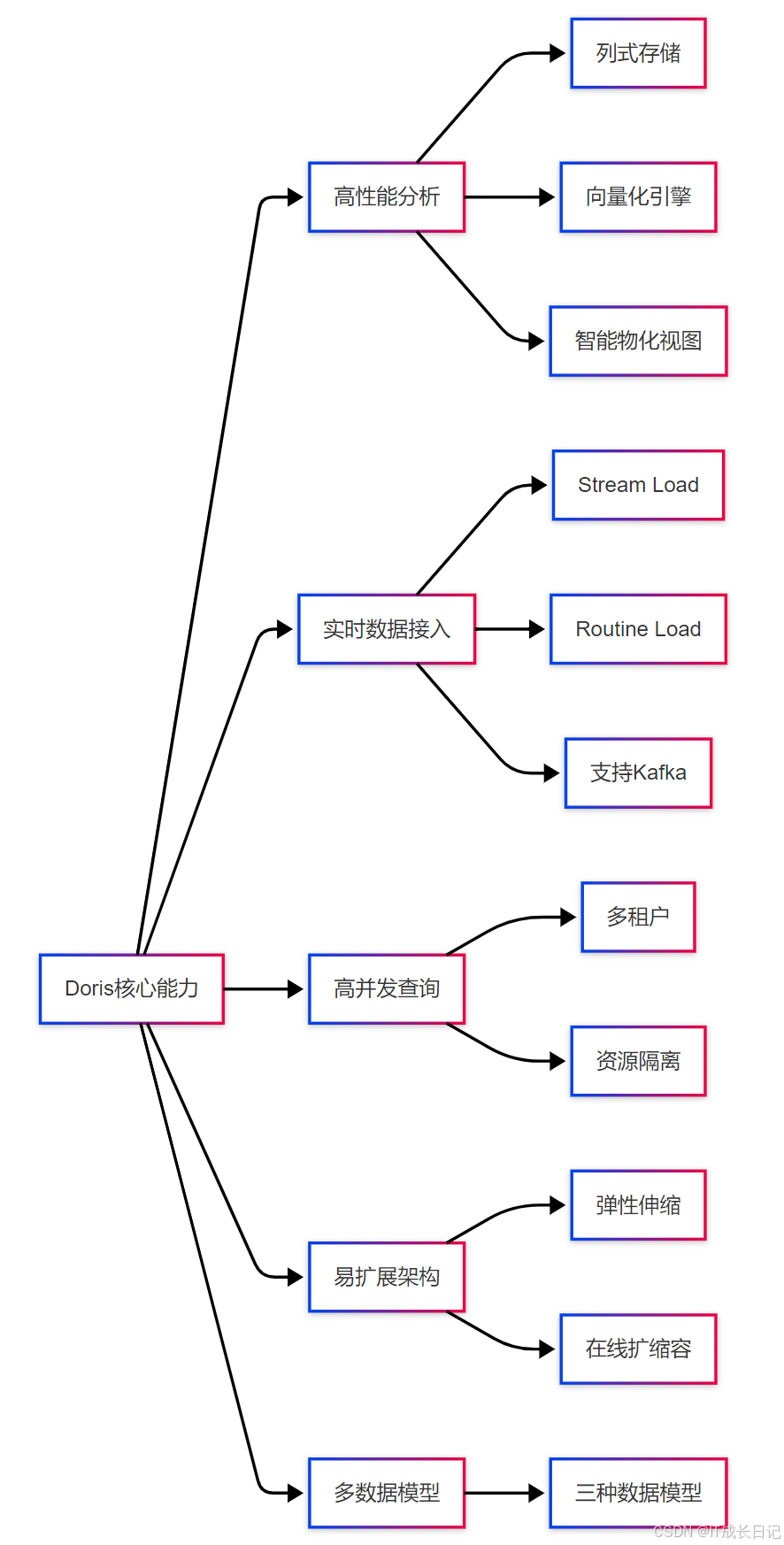
关键技术特性解释:
- 列式存储:数据按列而非按行存储,极大提高分析查询效率,减少I/O
- 向量化引擎:利用现代CPU的SIMD指令并行处理数据,提升计算效率
- MPP架构:大规模并行处理,分布式执行查询计划
- 实时数据接入:支持秒级数据可见性,多种数据摄入方式
- 成本优化:高效的压缩算法和智能索引减少存储需求
2 实时数据分析场景
2.1 实时数据仓库
Doris非常适合构建企业级实时数据仓库,能够满足从数据接入到分析展示的全流程需求。
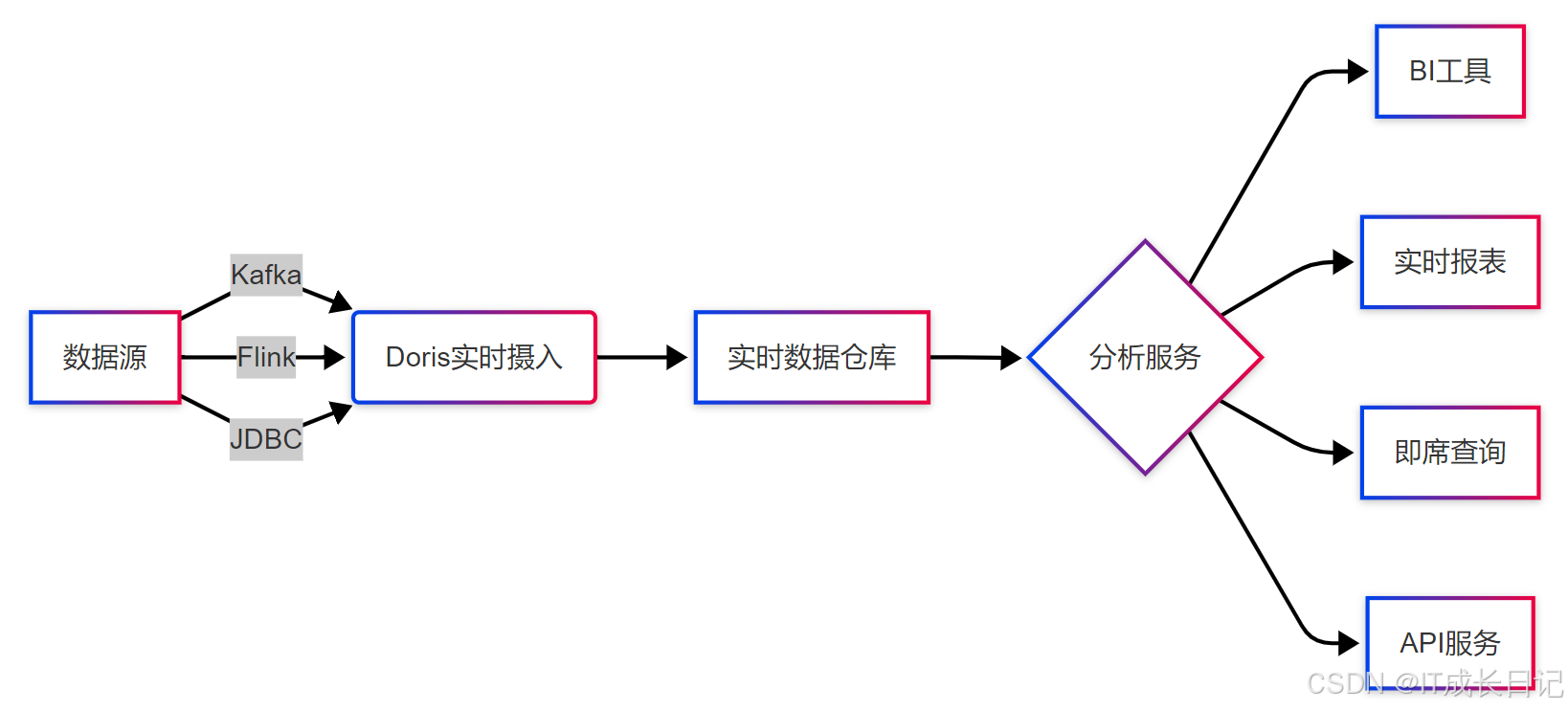
典型实现方案:
- 使用Routine Load从Kafka持续摄入数据
- 建立适当的数据模型(通常Aggregate模型为主)
- 通过物化视图预计算关键指标
- 对接Superset、Tableau等BI工具
优势体现:
- 数据时效性:从产生到可查询仅需秒级延迟
- 查询性能:复杂分析查询亚秒级响应
- 简化架构:替代传统的Lambda架构,一套系统满足实时和离线需求
2.2 实时监控与告警
Doris的高效查询能力使其成为实时监控系统的理想存储引擎。适用场景:
- IT基础设施监控
- 应用性能监控(APM)
- 业务指标监控
- 物联网设备状态监控
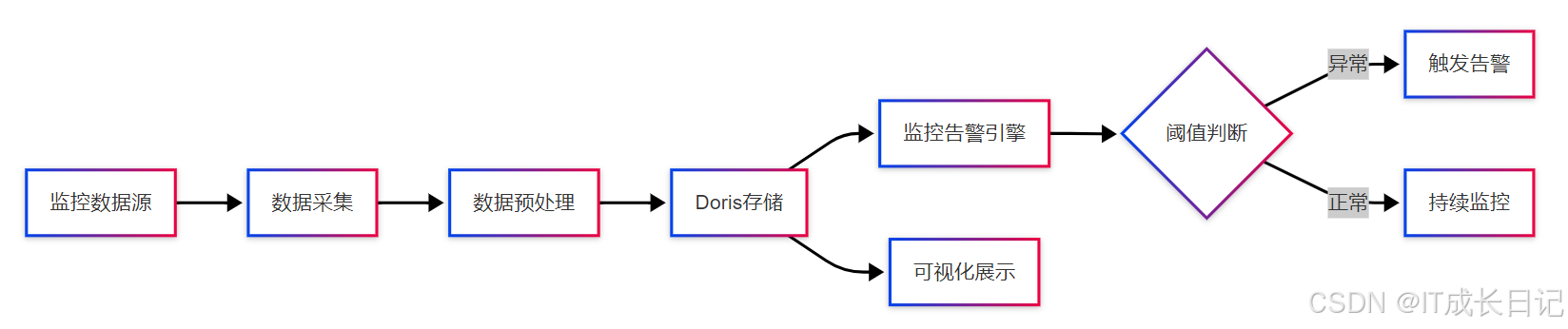
实现要点:
- 使用Duplicate模型存储原始指标数据
- 按时间分区分桶优化查询性能
- 建立Rollup表加速常见查询模式
- 通过定时查询或连接Flink实现复杂告警规则
3 交互式OLAP分析场景
3.1 自助式BI分析
Doris支持高并发查询的特性,使其成为自助BI分析的理想后端。关键能力匹配:
- 支持标准SQL,兼容主流BI工具
- 高并发能力(可达数千QPS)
- 快速响应复杂查询
- 支持多租户和资源隔离
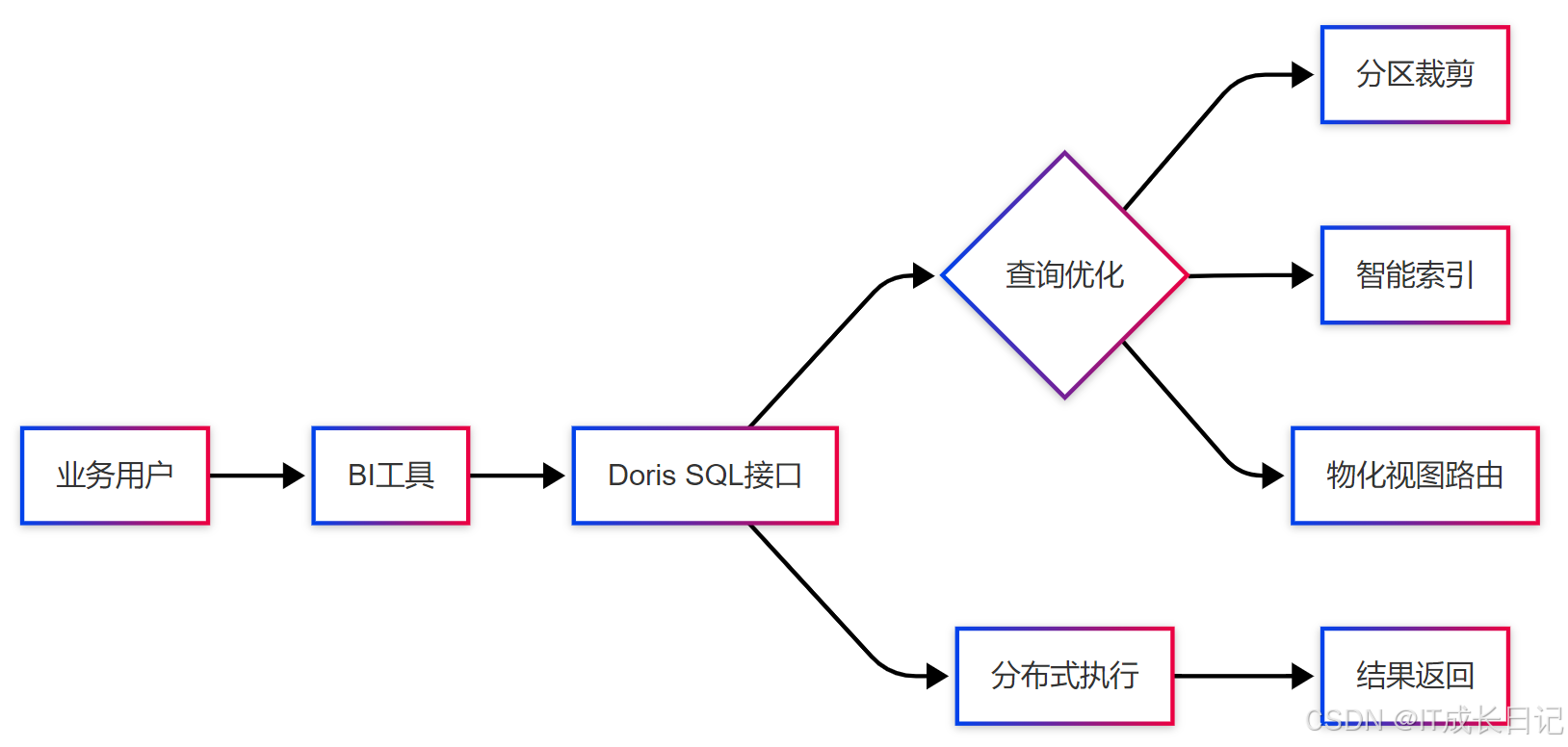
实施建议:
- 根据常用查询模式设计Rollup表
- 设置合理的资源组限制查询资源
- 对重要表建立适当的索引
- 定期收集和分析查询统计优化schema
3.2 用户行为分析
用户行为分析是Doris的典型应用场景,特别适合处理大规模的用户事件数据。常见分析需求:
- 漏斗分析
- 留存分析
- 路径分析
- 用户分群
- 事件分析
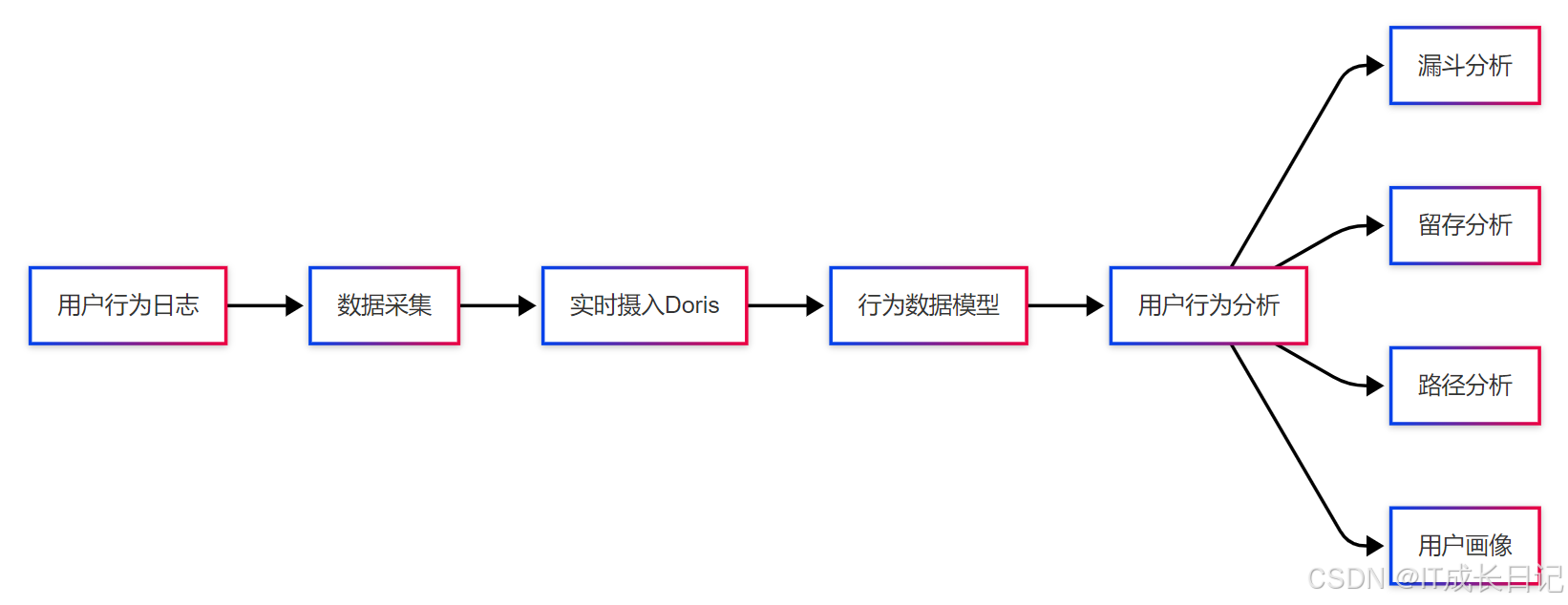
- 数据模型设计示例:
CREATE TABLE user_events (`event_date` DATE NOT NULL COMMENT "事件日期",`user_id` VARCHAR(64) NOT NULL COMMENT "用户ID",`event_type` VARCHAR(32) NOT NULL COMMENT "事件类型",`event_time` DATETIME NOT NULL COMMENT "事件时间",`device_id` VARCHAR(64) COMMENT "设备ID",`session_id` VARCHAR(64) COMMENT "会话ID",`page_url` VARCHAR(256) COMMENT "页面URL",`referrer` VARCHAR(256) COMMENT "来源",`province` VARCHAR(32) COMMENT "省份",`city` VARCHAR(32) COMMENT "城市",-- 其他事件属性...INDEX idx_user_id (user_id) USING BITMAP COMMENT "用户ID索引",INDEX idx_event_type (event_type) USING BITMAP COMMENT "事件类型索引"
)
DUPLICATE KEY(event_date, user_id, event_type)
PARTITION BY RANGE(event_date) (PARTITION p202501 VALUES LESS THAN ('2025-04-01'),PARTITION p202502 VALUES LESS THAN ('2025-05-01'),-- 其他分区...
)
DISTRIBUTED BY HASH(user_id) BUCKETS 32
PROPERTIES ("replication_num" = "3","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "MONTH","dynamic_partition.start" = "-12","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "32"
);4 大数据分析场景
4.1 日志分析系统
Doris能够高效处理PB级别的日志数据,是ELK等传统日志系统的有力替代方案。对比优势:
- 更高的查询性能
- 更强的分析能力
- 更低的存储成本
- 更简单的架构维护
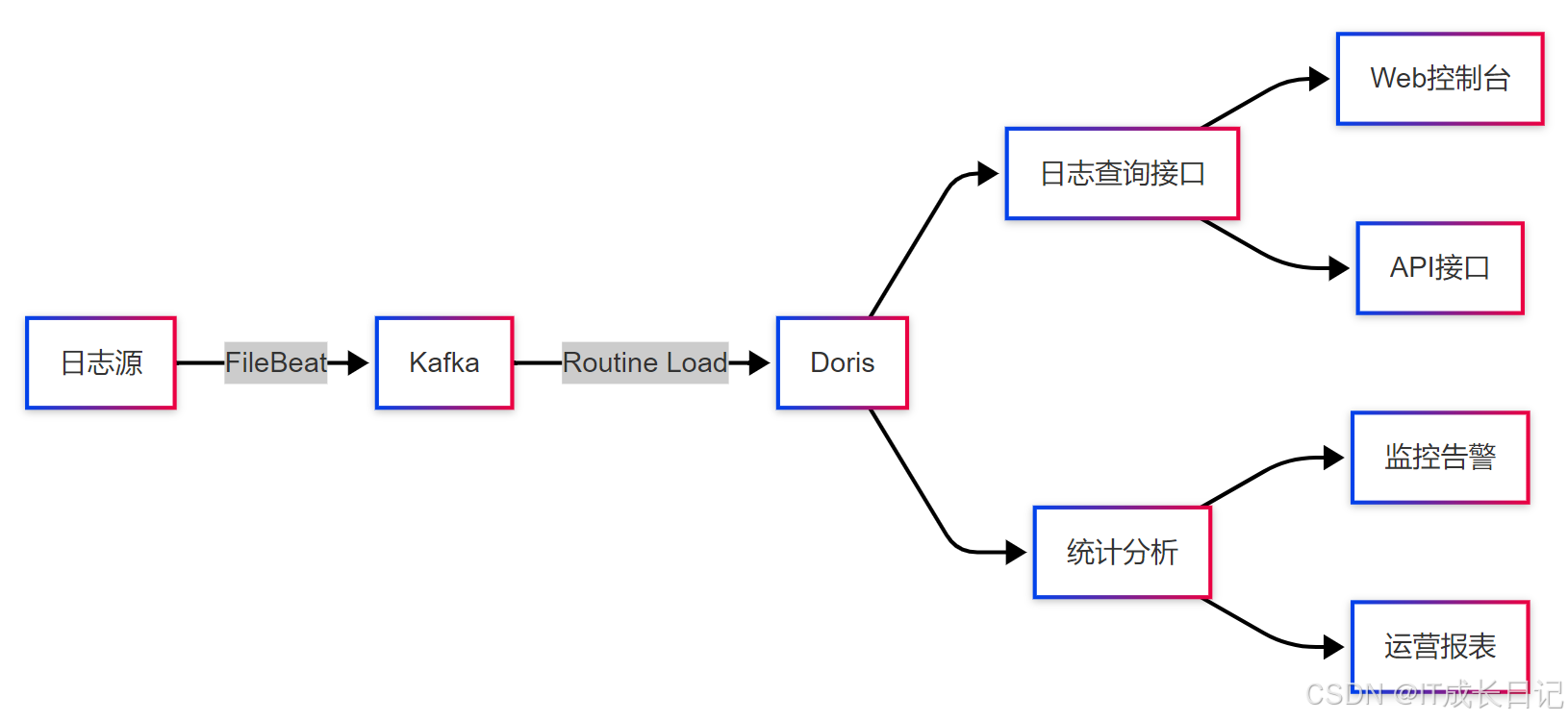
实施要点:
- 使用Duplicate模型保留原始日志
- 按日志时间分区管理
- 对常用过滤条件建立索引
- 对高频分析维度建立物化视图
- 设置合理的TTL自动清理旧日志
4.2 时序数据处理
虽然Doris不是专门的时序数据库,但其优秀的聚合性能使其能有效处理许多时序场景。适用时序场景:
- 物联网传感器数据
- 应用性能指标
- 业务时间序列数据
- 金融行情数据
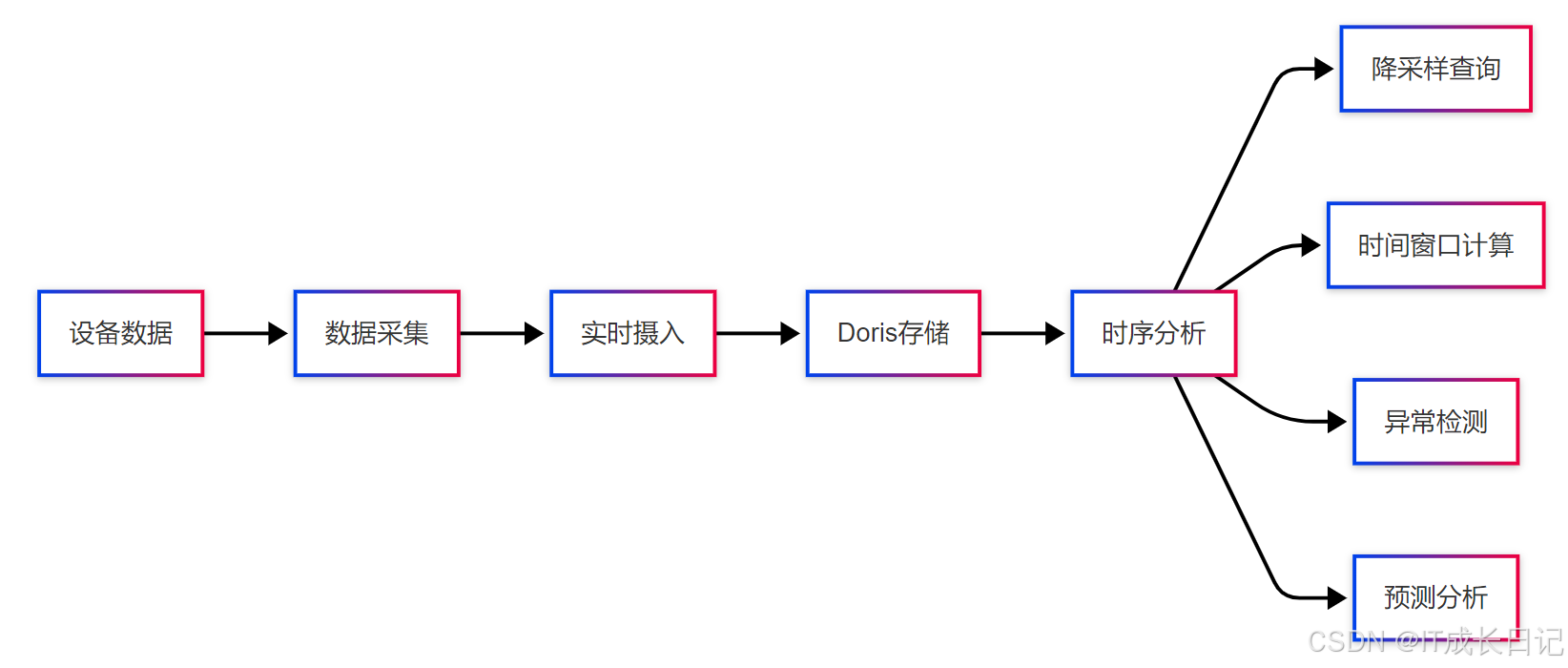
优化建议:
- 按时间分区分桶
- 使用Aggregate模型预聚合
- 对设备ID建立Bitmap索引
- 使用Rollup表加速常见时间范围查询
- 示例查询:
SELECT device_id,DATE_TRUNC('MINUTE', event_time, 5) AS five_min,AVG(temperature) AS avg_temp
FROM device_metrics
WHERE event_time >= NOW() - INTERVAL 1 DAY
GROUP BY device_id, five_min
ORDER BY device_id, five_min;5 Doris技术架构适配性分析
5.1 适合Doris的场景特征
根据Doris的技术特性,以下特征的业务场景特别适合采用Doris:
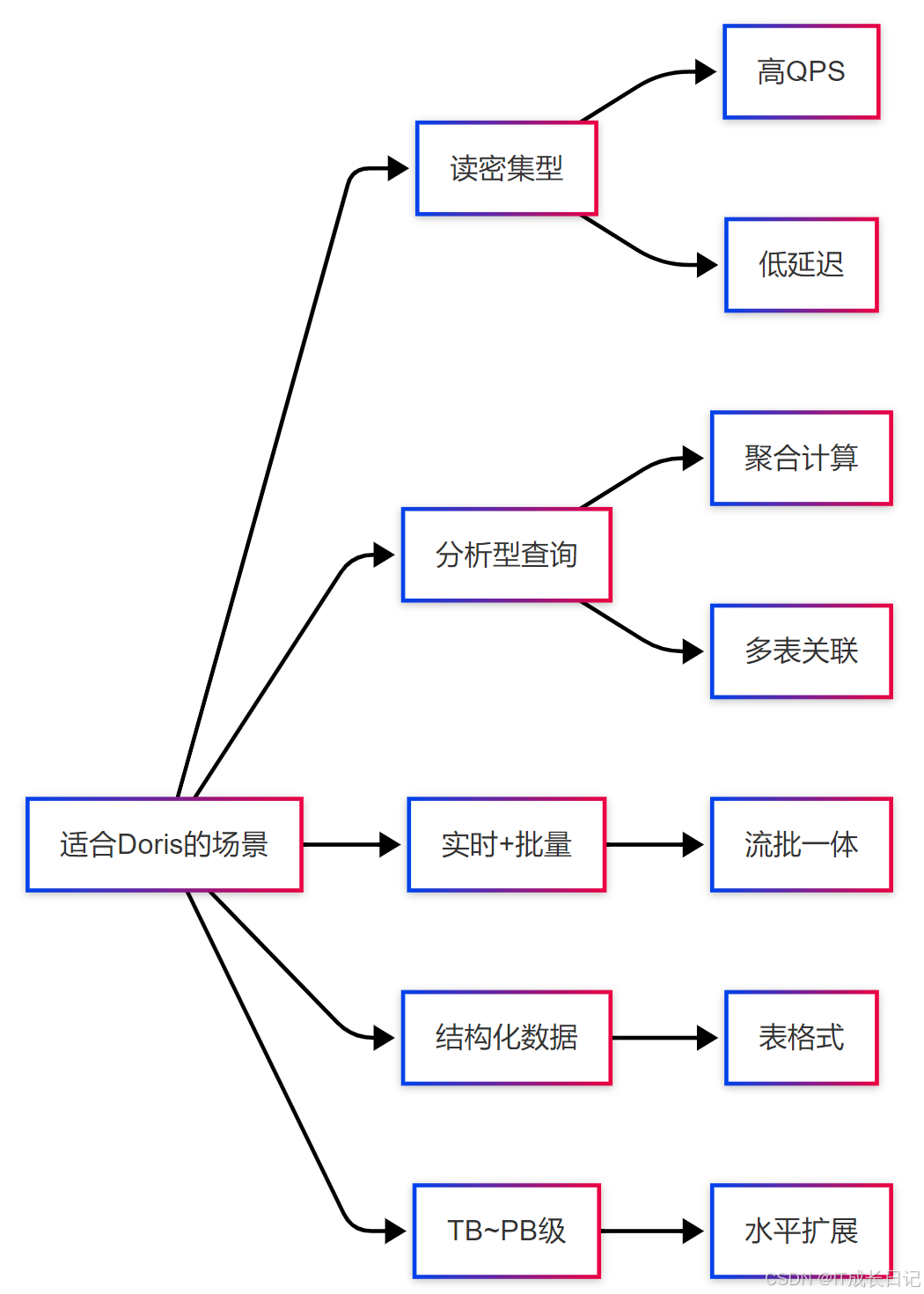
5.2 不适合Doris的场景
虽然Doris功能强大,但以下场景可能不适合:
- 高频小事务的OLTP系统
- 非结构化数据存储
- 简单的键值查询
- 超大规模图计算
- 复杂事务处理
6 Doris在技术栈中的定位
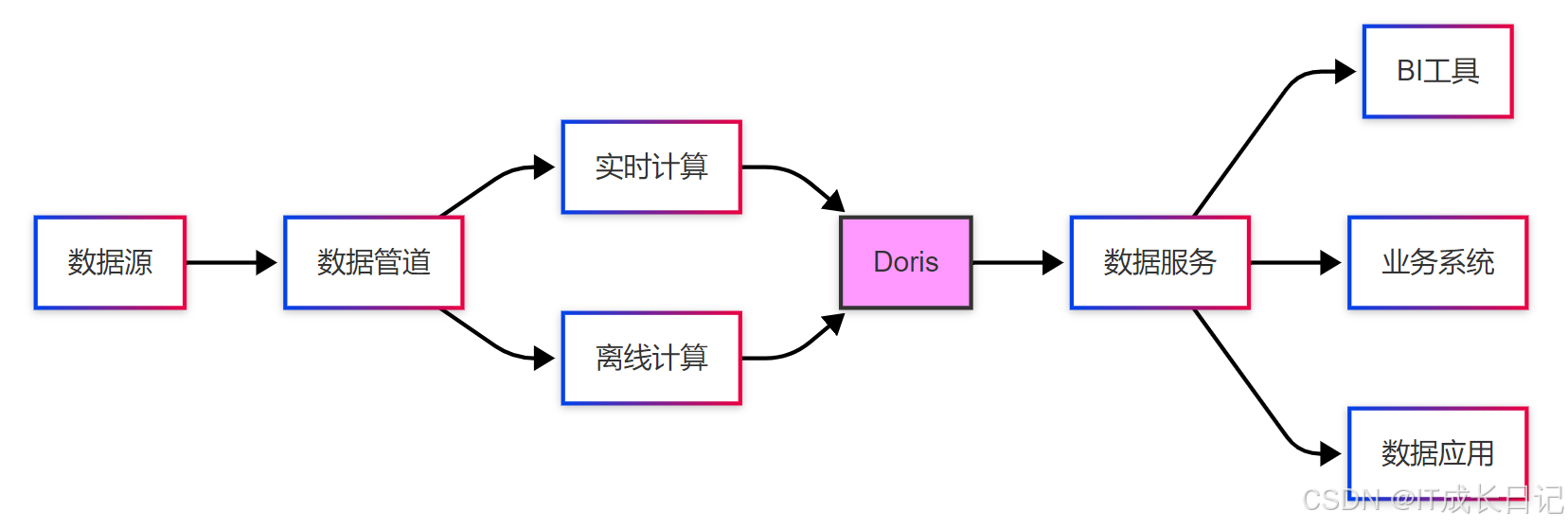
典型数据架构中的角色:
- 实时层:直接对接Kafka等消息队列,提供实时分析能力
- 服务层:作为统一的数据服务层,支撑各类应用
- 集市层:存储面向业务主题的数据集市
- 接口层:通过MySQL协议提供标准访问接口
7 总结与选型建议
7.1 Doris核心价值总结
Apache Doris在以下场景中表现尤为出色:
- 需要实时分析的场景:替代传统的Lambda架构
- 高并发查询的需求:支撑自助BI和运营分析
- 简化数据栈的目标:一个系统满足多种分析需求
- 快速迭代的业务:灵活的schema变更和快速上线
7.2 选型决策checklist
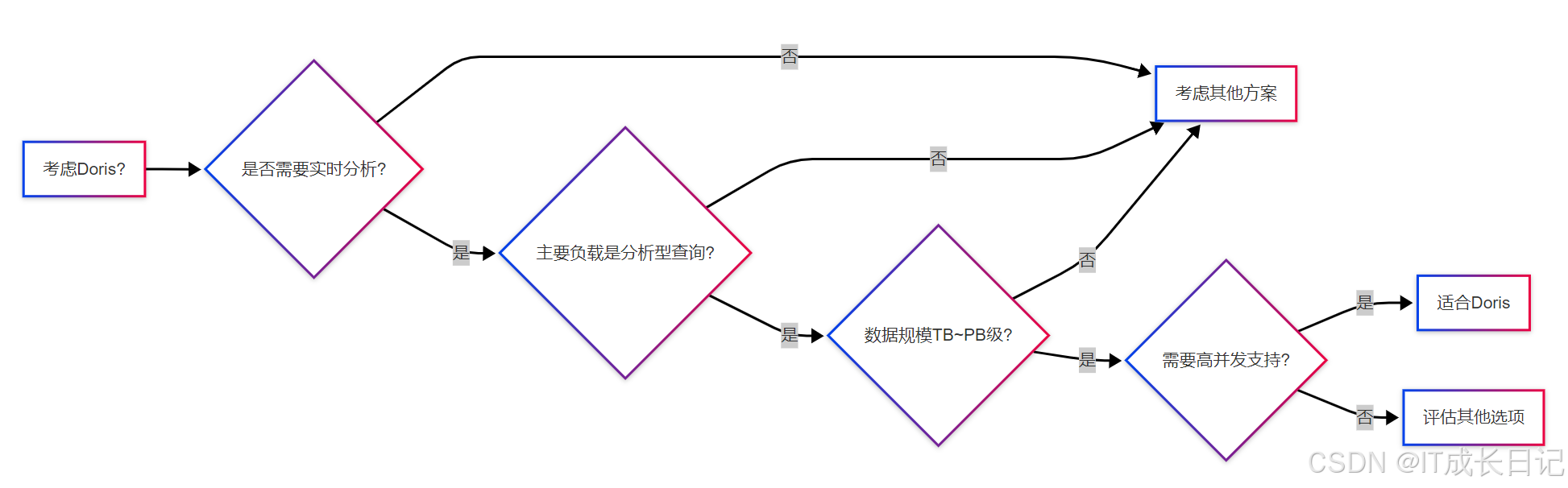
随着Doris社区的快速发展和功能的不断完善,其适用场景还在持续扩展。正确理解和应用Doris,能够为您的数据分析架构带来显著的性能提升和成本优化。