拉普拉斯噪声
1. 概念
拉普拉斯噪声是一种连续概率分布生成的随机噪声,其核心特点是符合拉普拉斯分布。这种噪声被特意添加到数据(尤其是查询结果或统计量)中,以实现差分隐私这一严格的隐私保护框架。
-
核心目的: 在保护数据集中的个体隐私的同时,允许对数据集整体进行有价值的统计分析或机器学习。
-
关键特性:
-
对称性: 噪声值围绕0对称分布,正负值出现的概率相同。
-
重尾性: 虽然较小的噪声值更常见,但出现较大噪声值的概率比高斯分布(正态分布)更高。这意味着添加的噪声可能偶尔会比较大,但这是实现强隐私保证所必需的代价。
-
以0为中心: 期望值(均值)为0。这意味着如果对同一个查询多次添加拉普拉斯噪声并取平均,结果会趋近于真实的查询结果(满足“无偏性”)。
-
拉普拉斯分布的概率密度函数 :
在给定位置参数 μ和尺度参数 b的情况下,随机变量 X取值恰好为 x的可能性大小(更严格地说,是在 x附近一个极小区间内的概率与该区间长度的比值)。
-
x:这是随机变量 X可能取的值。是我们想要计算其概率密度的点。
-
μ (位置参数):
-
这是分布的中心位置。它决定了分布对称轴所在的位置。
-
在公式中体现为
。因为使用了绝对值,所以分布关于 μ 对称。也就是说,距离 μ相同距离的点(比如
和
),它们的概率密度是相等的。
-
μ也是分布的中位数和众数(出现概率最高的点)。
-
-
b (尺度参数):
-
这个参数 b>0,它控制着分布的离散程度(或“胖瘦”)。
-
b 越大:
-
分布越“胖”、越“平坦”。数据点更分散,偏离中心 μ的程度更大。
-
添加的噪声(在差分隐私中)幅度越大,隐私保护越强,但数据可用性越低。
-
-
b越小:
-
分布越“瘦”、越“尖锐”。数据点更集中在中心 μ 附近。
-
添加的噪声(在差分隐私中)幅度越小,数据可用性越高,但隐私保护越弱。
-
-
在公式中,b出现在分母
和指数部分的分母
中。它同时影响峰值高度和衰减速度。
-
-
-
这个系数确保了整个概率密度函数曲线下的总面积等于 1(这是所有概率分布的基本要求)。
-
当
时,指数项
,所以峰值密度就是
-
-
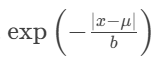 (指数衰减项):
(指数衰减项):-
这是公式的核心部分,它描述了概率密度如何随着点 x远离中心 μ而衰减。
-
-
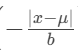 : 计算标准化的距离。距离 μ越远,这个值越负。
: 计算标准化的距离。距离 μ越远,这个值越负。 -
exp(...): 指数函数。输入值越负,输出值越小。
-
关键特性: 这个项导致概率密度随着
-
靠近中心 μ的点出现的概率密度相对较高。
-
远离中心的点出现的概率密度会迅速下降,但永远不会降到零(“重尾”特性)。
-
相比于同样方差的高斯分布(正态分布),拉普拉斯分布在中心更“尖”,在尾部更“厚”(有更大的概率产生远离均值的值)。这是它适合差分隐私的关键:偶尔添加较大的噪声能有效掩盖个体贡献。
-
-
2. 实现原理
拉普拉斯噪声在差分隐私中的实现原理紧密依赖于差分隐私的定义和全局敏感度的概念。
-
定义全局敏感度 (Δf):
-
这是拉普拉斯机制的核心输入参数。
-
对于一个查询函数
f(例如求和、平均值、计数、直方图等),其全局敏感度Δf定义为:对于任意两个相邻数据集D和D'(它们仅在一个个体的数据记录上不同),查询结果变化的最大绝对值。|
-
意义:
Δf衡量了单个个体的数据所能引起的最大影响。它是数据本身和查询函数的属性,与数据集的具体内容无关。
-
-
确定隐私预算 (ε):
-
ε是差分隐私的核心参数,称为隐私预算或隐私损失参数。 -
ε的值由数据发布者设定,代表了愿意承受的隐私风险级别。ε越小(例如 0.1, 1),提供的隐私保护越强(噪声越大);ε越大(例如 10),提供的隐私保护越弱(噪声越小),数据越准确。
-
-
计算噪声尺度 (b):
-
噪声的尺度参数
b由全局敏感度Δf和隐私预算ε共同决定:
b=Δf/ε -
原理: 为了满足 ε-差分隐私,需要确保添加的噪声强度足以“掩盖”单个个体数据可能带来的最大影响 (
Δf)。ε控制了这个掩盖的程度。ε越小,要求掩盖得越好,需要的噪声 (b) 就越大(b =Δf/ε变大)。
-
-
生成并添加噪声:
-
从以
μ=0和b=Δf/ε为参数的拉普拉斯分布中独立地抽取一个随机样本L。 -
将这个噪声样本
L加到真实的查询结果f(D)上:
M(D) = f(D) + L -
M(D)就是满足 ε-差分隐私的、带有噪声的发布结果。
-
3. 能解决什么问题?
拉普拉斯噪声是解决如何在公开发布数据或数据分析结果时,严格保护其中个体隐私这一核心问题的关键技术。具体来说:
-
防止成员推断攻击: 攻击者无法根据发布的(带噪)结果,可靠地推断出某个特定个体是否存在于原始数据集中。
-
防止属性推断攻击: 攻击者无法根据发布的(带噪)结果,可靠地推断出某个特定个体在数据集中的敏感属性值(即使知道该个体在数据集中)。
-
提供可量化的隐私保证: 差分隐私(通过拉普拉斯机制实现)提供了严格的、可证明的数学隐私保证(ε-差分隐私)。隐私预算
ε的大小直接量化了隐私泄露的风险上限。 -
在隐私和效用之间实现可控的权衡: 通过调整
ε,数据发布者可以明确地在个体隐私保护强度 (ε小) 和发布结果的统计准确性/可用性 (ε大) 之间进行权衡。
4. 应用场景
-
人口普查和官方统计机构:
-
发布人口统计数据(如不同地区、年龄段、职业的收入分布、教育水平等),保护公民个人隐私。
-
发布经济指标。
-
-
医疗健康研究:
-
共享匿名的医疗数据集或聚合统计结果(如某种疾病的患病率、不同治疗方案的有效性比较),用于公共健康研究或药物研发,同时保护患者隐私。
-
医院间共享去识别化的统计数据。
-
-
互联网公司和服务提供商:
-
用户行为分析: 收集聚合信息了解用户如何使用产品(如某个功能的点击率、不同用户群的停留时长),用于改进产品,而不追踪个体行为。例如,Google 的 RAPPOR 项目。
-
A/B 测试: 比较不同产品版本的效果(如转化率)时保护个体用户隐私。
-
个性化推荐/广告的隐私保护: 在训练推荐模型或计算用户画像相关统计量时加入噪声。
-
-
位置数据服务:
-
发布热门地点、人流密度地图(如交通流量、商场人流量),保护单个用户的行踪轨迹隐私。
-
-
金融行业:
-
在满足隐私法规的前提下,金融机构之间或向监管机构共享聚合的金融风险统计数据。
-
-
机器学习:
-
隐私保护机器学习: 在训练过程中(如目标函数、梯度)添加拉普拉斯噪声,使得最终发布的模型不会泄露训练数据中个体的敏感信息。例如,差分隐私随机梯度下降。
-
发布训练好的模型参数(尤其是基于敏感数据训练的模型)。
-
-
数据库查询:
-
对包含敏感信息的数据库提供对外查询接口,对每个查询结果添加拉普拉斯噪声以满足差分隐私,防止通过多次查询进行隐私推断攻击。
-