【TTS】基于GRPO的流匹配文本到语音改进:F5R-TTS

论文地址:https://arxiv.org/abs/2504.02407v3
摘要
我们提出了F5R-TTS,这是一种新颖的文本到语音(TTS)系统,它将群体相对策略优化(GRPO)集成到基于流匹配的架构中。 通过将流匹配TTS的确定性输出重新表述为概率高斯分布,我们的方法能够无缝集成强化学习算法。 在预训练期间,我们训练了一个基于概率重新表述的流匹配模型,该模型源自F5-TTS和一个开源数据集。 在随后的强化学习(RL)阶段,我们采用一个由GRPO驱动的增强阶段,该阶段利用双重奖励指标:通过自动语音识别计算的词错误率(WER)和通过验证模型评估的说话人相似度(SIM)。 零样本语音克隆的实验结果表明,与传统的基于流匹配的TTS系统相比,F5R-TTS在语音可懂度(WER相对降低29.5%)和说话人相似度(SIM得分相对提高4.6%)方面都取得了显著的改进。 音频样本可在https://frontierlabs.github.io/F5R访问。
评估是从两个关键角度进行的:说话人相似度(由SIM衡量)和语义准确性(由WER衡量)。
更高的SIM值和更低的WER值表示性能更优。
1、引言
近年来,文本到语音(TTS)系统的显著进步使得能够生成高保真、自然的声音和零样本语音克隆能力。这些发展涵盖了自回归(AR)[1, 2, 3, 4]和非自回归(NAR)[5, 6, 7]模型架构。 AR模型通常使用语音编解码器将音频编码成离散符元,然后采用基于语言模型(LM)的自回归模型来预测这些符元。 然而,这种方法存在推理延迟和暴露偏差的问题。 相反,基于去噪扩散或流匹配的NAR模型利用并行计算来加快推理速度,展现出强大的应用潜力。
此外,正如DeepSeek系列[8, 9, 10, 11]所示,强化学习(RL)已引发了大语言模型(LLM)研究的趋势。 直接偏好优化(DPO)[12]和组相对策略优化(GRPO)[8]等RL方法已被证明能够有效地使LLM输出与人类偏好保持一致,通过反馈优化来增强生成文本的安全性和实用性。 在图像生成领域,去噪扩散策略优化(DDPO)[13]等RL方法也已成功应用。 这种范式现已扩展到AR TTS系统:Seed-TTS[14]使用说话人相似度(SIM)和词错误率(WER)作为奖励,并结合近端策略优化(PPO)[15]、REINFORCE[16]和DPO实现了RL集成。 在一些其他的AR架构工作中,也探讨了DPO及其变体[17, 18, 19, 20]。 然而,由于与LLM的根本结构差异,将RL集成到NAR架构中仍然具有挑战性。 当前的研究没有显示出在基于NAR的TTS系统中成功集成RL的案例,这表明这一挑战仍在等待可行的研究解决方案。
在本文中,我们介绍了F5R-TTS,这是一种新颖的TTS系统,它通过两项关键创新将GRPO应用于流匹配模型。 首先,我们将基于流匹配模型的确定性输出重新表述为概率序列,其中F5-TTS[7]被用作我们修改的骨干。 这种重新表述使得在后续阶段能够无缝集成RL算法。 其次,设计了一个由GRPO驱动的增强阶段,使用WER和SIM作为奖励指标,两者都与人类感知高度相关。 实验结果证明了该系统的有效性,与传统的NAR TTS基线相比,在语音清晰度(WER相对降低了29.5%)和说话人一致性(SIM得分相对提高了4.6%)方面都取得了显著改进。
本工作的关键贡献如下。
- 我们提出了一种方法,将基于流匹配的TTS模型的输出转换为概率表示,这使得各种强化学习算法能够方便地应用于流匹配模型。
- 我们成功地将GRPO方法应用于NAR-TTS模型,使用WER和SIM作为奖励信号。
- 我们已在零样本语音克隆应用场景中实现了 F5R-TTS 模型,并证明了其有效性。
本文的其余部分组织如下:第 2 节描述了所提出的方法。 然后,第 3 节介绍了实验设置和评估结果。 最后,第 4 节总结了本文。
2、提出的方法
所提出的方法将训练过程分为两个阶段。 我们首先使用流匹配损失对模型进行预训练,随后使用 GRPO 改进模型。 在本节中,我们将详细解释如何利用 GRPO 策略来改进基于流匹配的模型。
2.1、预备知识
我们的模型主要遵循 F5-TTS [7],这是一种具有零样本能力的新型基于流匹配的 TTS 模型。 该模型在文本引导的语音填充任务上进行训练。 根据流匹配的概念,目标是预测 以
作为输入,其中
数据分布 q(x) 和
。标准目标函数定义为
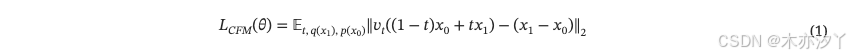
其中 θ 参数化神经网络 。
并且我们旨在使用GRPO进一步增强模型的性能,GRPO是PPO的简化变体,它消除了价值模型,并通过基于规则或基于模型的方法计算奖励。 惩罚项KL散度 之间
和
的估计如公式所示。
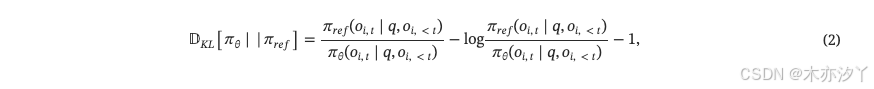
对于每个问题 q ,它根据输出的相对奖励计算优势 o 在每个组内,然后通过最大化以下目标来优化策略模型 。
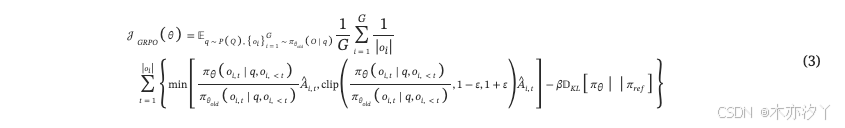
其中 ε 和 β 是超参数,优势 。
2.2、输出概率化和预训练
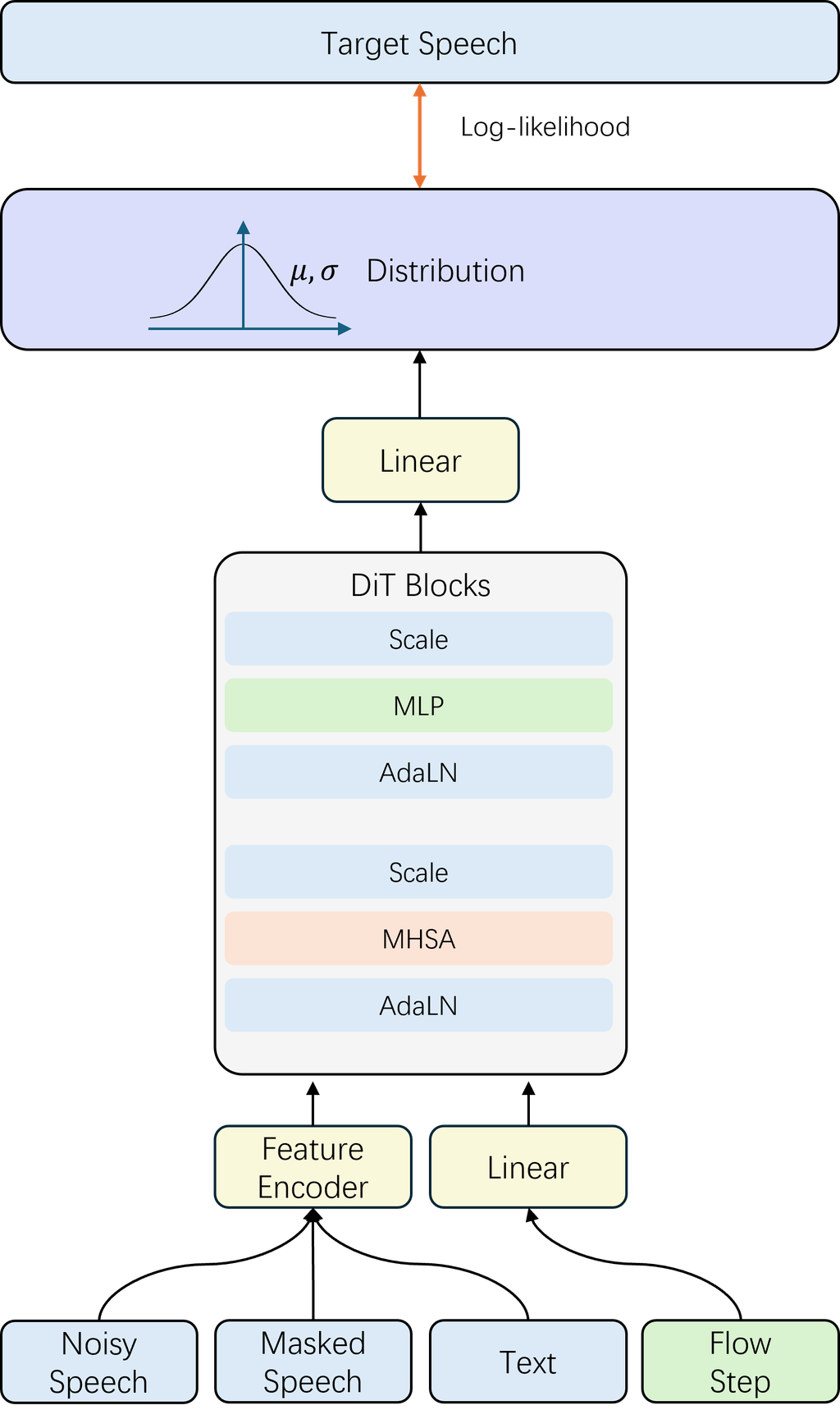
我们模型中最重要的区别在于修改了最终的线性层,以便准确预测每个流步骤的概率分布。
我们将模型的输出重新表述为概率术语,以增强与GRPO的兼容性,从而能够预测……的分布概率 。 图2显示了模型的整体结构。 在第一阶段,我们保留了流匹配目标函数。 流匹配目标是将标准正态分布中的概率路径与近似于数据分布的分布匹配。
所提出的模型也在填充任务上进行了训练。 在训练过程中,模型接收流步骤 t、噪声声学特征 、掩蔽声学特征
以及完整语音的文本转录
作为输入。 我们使用提取的梅尔谱图特征作为训练的声学特征,并将文本特征填充到与声学特征相同的长度。
所提出的模型并不直接预测……的精确值 。我们让模型预测均值 μ(x) 以及方差 σ(x) 最后一层高斯分布和参数 θ 被优化以最大化以下对数似然
。
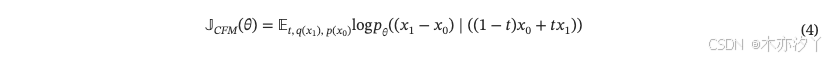
简化公式后 4,我们可以得到以下改进的目标函数
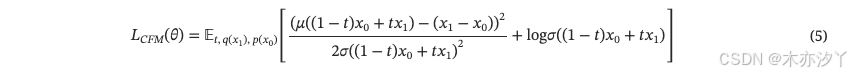
在预训练阶段,我们使用公式 5来优化模型。
2.3、使用GRPO增强模型
在预训练阶段之后,我们继续使用GRPO来提高模型的性能。 GRPO阶段的流程如图3所示:
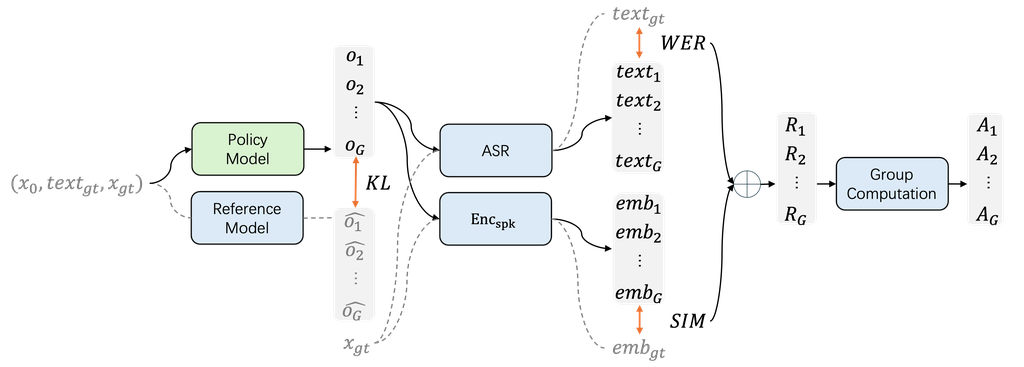
KL散度被纳入作为惩罚项,以增强GRPO阶段的训练稳定性。
在第二阶段,我们进一步训练预训练模型作为策略模型 同时初始化参考模型
使用预训练参数。 在整个 GRPO 阶段,参考模型保持冻结状态。 在 GRPO 训练期间,我们的 TTS 模型的前向操作与预训练阶段不同。 存在一个类似于推理的采样操作。 策略模型
接收
作为输入,然后计算每个流程步骤的输出概率。 策略模型的采样结果 o 用于计算奖励以及与参考模型结果相比的 KL 损失
.
就奖励指标而言,我们选择 WER 和 SIM 作为改进语义一致性和说话人相似性的主要标准,因为它们代表了语音克隆任务中最关键的两个方面。 我们使用一个 ASR 模型来转录合成的语音,获得转录文本 ,然后将转录文本与真实语音的
真实文本进行比较以计算 WER。 此外,我们利用说话人编码器
来提取合成的说话人嵌入
和真实说话人嵌入
分别来自生成的语音 o 和真实语音样本
。 通过计算这些嵌入之间的余弦相似度来评估说话人相似度。
因此,GRPO奖励被分为语义相关奖励和说话人相关奖励,定义如下。
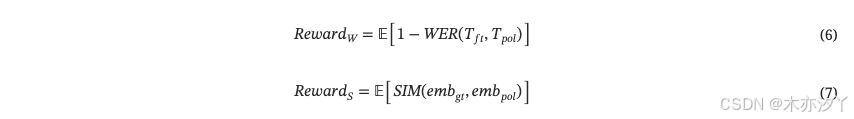
总奖励定义为:
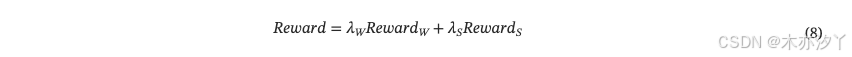
其中 和
是各自奖励的权重项。
计算奖励后,我们可以通过组相对优势估计[8]得到优势。
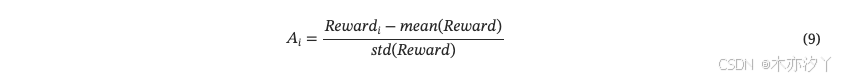
为了保持模型输出的稳定性,GRPO还需要使用参考模型 来提供约束。 最后,我们定义公式。 10作为第二阶段的目标函数。
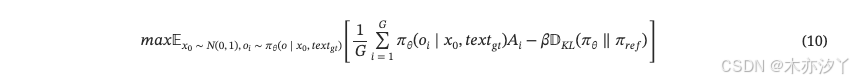
3、实验
在本节中,我们的实验重点在于验证所提出方法在增强零样本语音克隆任务性能方面的有效性。
3.1、数据集和实验设置
在预训练阶段,我们使用了WenetSpeech4TTS Basic [21],这是一个包含7226小时多说话人语料的普通话开源数据集,作为训练集。 在GRPO阶段,我们从同一数据集中随机选择了100小时的语音数据进行训练。 在评估中,遵循Seed-TTS的测试设置,我们使用Seed-TTS-eval测试集(cn集)1中的参考语音合成了2020个通用样本和400个困难样本。 通用样本使用纯文本,而困难样本使用难以处理的文本,例如绕口令或包含高频重复词语和短语的文本。 为了测试噪声鲁棒性,我们使用同一测试集中的70个含噪语音生成了140个样本。
我们的模型架构主要遵循F5-TTS论文中描述的配置,仅对最后一层输出层进行了修改。 在预训练阶段,模型在8个A100 40GB GPU上进行了100万次更新训练,批量大小为160,000帧。 在GRPO训练阶段,模型在8个A100 40GB GPU上进行了1100次更新训练,批量大小为6400帧。 对于GRPO训练,我们使用SenseVoice [22]作为自动语音识别(ASR)系统来计算 RewardW ,并使用WeSpeaker [23]作为说话人编码器进行 RewardS 计算。
我们选择原始F5-TTS作为我们实验的基线。 为了证明GRPO在改进TTS模型方面的有效性,我们比较了原始F5-TTS、输出概率化F5-TTS和所提出的方法的性能。 我们分别将它们命名为F5、F5-P和F5-R。 F5严格保留了原始架构和参数设置。 F5-P也是GRPO阶段的预训练模型。 我们在相同的预训练数据集上训练所有模型。
3.2、评估
3.2.1、可视化分析
我们尝试可视化不同模型在零样本语音克隆任务中的性能差异。

图表中的每个小数字代表一个话语样本。 不同的数字或颜色对应不同的目标说话人。
带星号的数字表示目标说话人的参考话语(数字代表的目标说话人)。 不带星号的数字指的是合成的语音。 并用红箭头标出了一些错误案例。
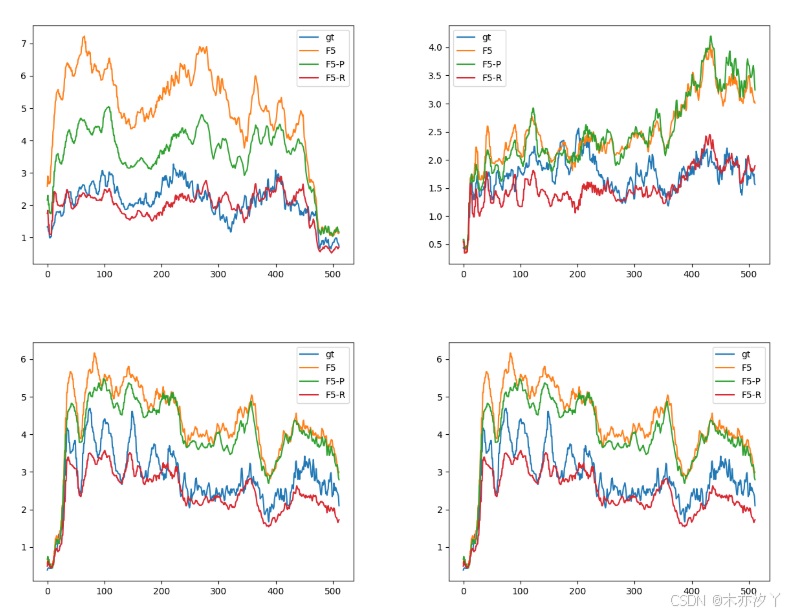
在每个子图中,横轴表示梅尔频谱系数数量,纵轴表示方差。 每个子图中都有4条GV曲线,对应不同的来源。
曲线的对应关系如图例所示,其中gt表示ground truth(真实值)。
我们首先使用t-SNE[24]将说话人相似度可视化到二维空间。 T-SNE可以以无监督的方式对数据(例如说话人嵌入)进行聚类。 对于此分析,我们从Seed-TTS-eval test-cn集中随机选择了10个未见过的说话人作为目标说话人,然后模型分别为每个说话人合成了10个话语。 我们使用WeSpeaker获取话语的说话人嵌入,然后通过t-SNE进行可视化。 我们可以直观地看到合成结果与真实样本之间的相似性。 我们还可以观察到目标说话人之间的分布差异。 如图4所示,F5-R的结果根据目标说话人进行了很好的聚类。 同时,F5和F5-P的子图显示,对应于某些目标说话人的合成结果并未完全聚在一起。 这意味着F5-R的合成结果具有更好的说话人相似性。
其次,我们使用了全局方差(GV)[25]。 GV是一种可视化话语频谱方差分布的方法。 我们分别为Seed-TTS-eval test-cn集中的4个未见过的说话人(2个女性和2个男性)生成了20个话语。 然后,我们计算了参考话语和合成话语的GV。 合成曲线和参考曲线越接近,表明性能越好。 如图5所示,F5-R的红色曲线比其他曲线与参考话语的蓝色曲线更好地吻合,这也表明F5-R的合成结果与参考话语更相似。
3.2.2、指标分析
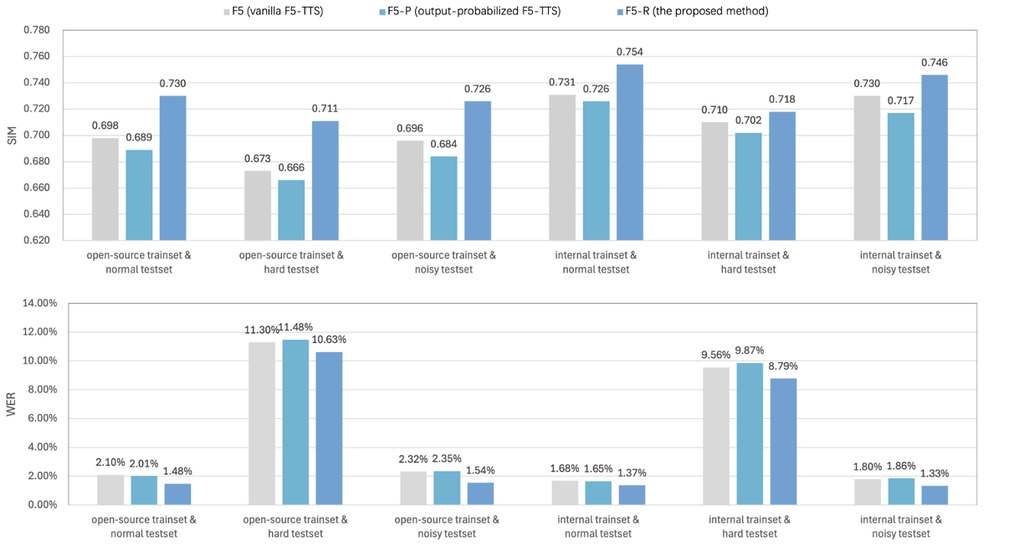
为评估模型性能,我们基于seed-tts-eval test-cn采用了WER和SIM作为客观指标。 对于指标计算,我们利用了seed-tts-eval提供的官方评估工具包。 对于WER,我们使用了Paraformer-zh[26]进行转录。 对于SIM,我们利用了基于WavLM-large的说话人识别模型[27]提取说话人嵌入。 这些指标分别量化了语义准确性(较低的WER更佳)和说话人相似度(较高的SIM更佳)。 表1展示了这三个模型的比较评估结果。
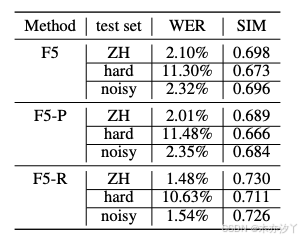
就SIM而言,可以观察到F5和F5-P在两个不同的测试集上表现出相当的性能,F5略优于后者。 我们提出的模型在这两个集合上都取得了优越的性能,确立了其顶级性能的地位。 值得注意的是,在通用测试集上,我们的模型以至少0.03 SIM点的优势优于其他模型。 与F5相比,F5-R在通用测试集和困难测试集上分别取得了4.6%和5.6%的相对增长。 这表明GRPO对提高说话人相似度有积极贡献。
就词错误率 (WER) 而言,F5 和 F5-P 在两个不同的测试集上保持高度一致。 然而,我们的模型在这两个数据集上都取得了显著更好的结果。 在通用测试集上,与基线相比,它实现了 29.5% 的 WER 相对降低,在困难测试集上进一步降低了 5.9%。 这些结果最终证实了 GRPO 在提高语义准确性方面的有效性。
对于噪声鲁棒性测试,我们使用噪声话语作为参考音频。 噪声对所有模型的 SIM 影响微乎其微,同时导致 F5 和 F5-P 的 WER 增加。 同时,F5-R 显示出显著改进的噪声鲁棒性。 我们发现 F5-R 在噪声条件下也保持了优越的节奏性能。 噪声鲁棒性测试的音频样本可在 https://frontierlabs.github.io/F5R 获取。

为了证明所提出方法的泛化能力,我们在其他数据集上进行了并行实验。 对于预训练阶段,我们使用了一个包含 10,000 小时语料库的内部普通话数据集,主要来自广播和有声读物。 我们对数据集进行了预备的基于质量的过滤。 此外,随机选择了一个 100 小时的子集用于 GRPO 训练。 使用内部数据集的客观指标比较如表 2 所示。 与F5相比,F5-R在通用测试集上的字错误率(WER)相对降低了18.4%,语音相似度(SIM)相对提高了3.1%。 在困难测试集上,F5-R的WER相对降低了8.1%,SIM相对提高了1.1%。 在噪声测试集上,F5-R的WER相对降低了26.1%,SIM相对提高了2.2%。 总体结果与在WenetSpeech4TTS Basic上获得的结果一致,表明GRPO持续提高了不同数据集上的模型性能。
总体而言,F5和F5-P的性能大体相当。 正如预期,以WER和SIM作为奖励的GRPO使模型在语义准确性和说话人相似度方面均取得了提升。 在说话人相关奖励组件的指导下,该模型通过上下文学习展示了增强的克隆目标说话人特征的能力。 在困难测试集上,所提出的模型在WER性能方面表现出更明显的相对优势。 我们假设这种改进源于WER相关的奖励组件,该组件有效地增强了模型的语义保持能力。 然而,所有三个模型在困难测试集上都表现出性能下降,这表明文本复杂性的增加通常会降低模型的稳定性。 这一观察结果可以作为未来优化工作的重点。
4、结论
在本文中,我们提出了F5R-TTS,它将GRPO方法引入基于流匹配的NAR TTS系统。 通过将基于流匹配模型的输出转换为概率表示,GRPO可以集成到训练流程中。 实验结果表明,与基线系统相比,所提出的方法实现了更高的SIM和更低的WER,这表明具有适当奖励函数的GRPO对语义准确性和说话人相似性都有积极的贡献。
我们下一步将投资于以下方向的研究。
- 强化学习方法研究: 我们计划探索将额外的强化学习方法(例如,PPO,DDPO)集成到NAR TTS系统中。
- 奖励函数优化: 为了进一步增强模型在挑战性场景中的稳定性,我们将继续研究优化的奖励函数设计。
- 数据探索: 为了更好地理解模型在大数据集上的性能,我们将利用更多训练数据进行进一步的实验。
参考文献
参见原文