知识图谱增强的大型语言模型编辑
https://arxiv.org/pdf/2402.13593
摘要
大型语言模型(LLM)是推进自然语言处理(NLP)任务的关键,但其效率受到不准确和过时知识的阻碍。模型编辑是解决这些挑战的一个有前途的解决方案。然而,现有的编辑方法很难跟踪和整合与编辑相关的知识变化,这限制了PostEdit LLM处理编辑知识的概括能力。为了解决这些问题,我们提出了一种新的模型编辑方法,利用知识图来增强LLM编辑,即GLAME。具体来说,我们首先利用知识图增强模块来发现由于编辑而发生变化的相关知识,并在LLM中获得其内部表示。这种方法允许LLM内的知识变更通过外部图形结构反映出来。随后,我们设计了一个基于图的知识编辑模块,将结构化知识集成到模型编辑中。这确保了更新的参数不仅反映了编辑的知识的修改,而且反映了编辑过程导致的其他相关知识的变化。在GPT-J和GPT-2 XL上进行的综合实验表明,GLAME显著提高了编辑后LLM在使用编辑后知识方面的泛化能力。
一、引言
大型语言模型(LLM)已经在各种自然语言处理(NLP)任务中取得了令人印象深刻的结果(Wan等人,2024年; Xia等人,2024; Zhang等人,2024 a),归因于他们的概括能力和广泛的世界知识(Zhao等人,2023年)的报告。然而,LLM中编码的知识往往是过时的或不准确的,这限制了它们在现实世界中的应用.为了解决这些局限性,模型编辑技术被引入作为更新嵌入在LLMs中的知识的更有效和更有针对性的方法,这是近年来吸引了大量研究关注的主题。
模型编辑主要包括两类方法:参数保留方法和参数修改方法。参数保留方法通常涉及在外部存储编辑的示例或知识参数以调整模型输出,如在SERAC(Mitchell等人,2022年)的报告。相比之下,参数修改方法直接改变LLM的内部参数,并可分为三种主要类型:基于微调的方法,如FT-L(Zhu等人,2020),基于元学习的方法,如KE(De Cao等人,2021)和MEND(Mitchell等人,2021)和定位然后编辑方法,包括罗马(Meng等人,2022 a)和MEMIT(Meng等人,第2022条b款)。
虽然这些方法在LLM的知识编辑中表现出了良好的效果,但它们仍然面临着捕获与编辑知识相关的相关知识变化的挑战。具体而言,现有的工作主要集中在目标知识的编辑上,例如将知识从(s,r,o)修改为(s,r,o)。然而,这种单一的知识修改往往会引发一系列的相关知识的相应变化。如图1所示,将知识从“LeBron James plays for the迈阿密Heat”改变为“LeBron James plays for the Los Angeles Lakers”的编辑将需要从“LeBron James works in迈阿密”到“LeBron James works in洛杉矶”的相应更新。现有的编辑方法没有考虑目标知识的修改对关联知识的影响,这限制了编辑后的LLM在处理此类编辑知识时的通用性。LLM的黑盒性质使得捕获模型中知识片段之间的关联变得非常复杂,这进一步挑战了在编辑期间检测这种关联知识变化的能力。
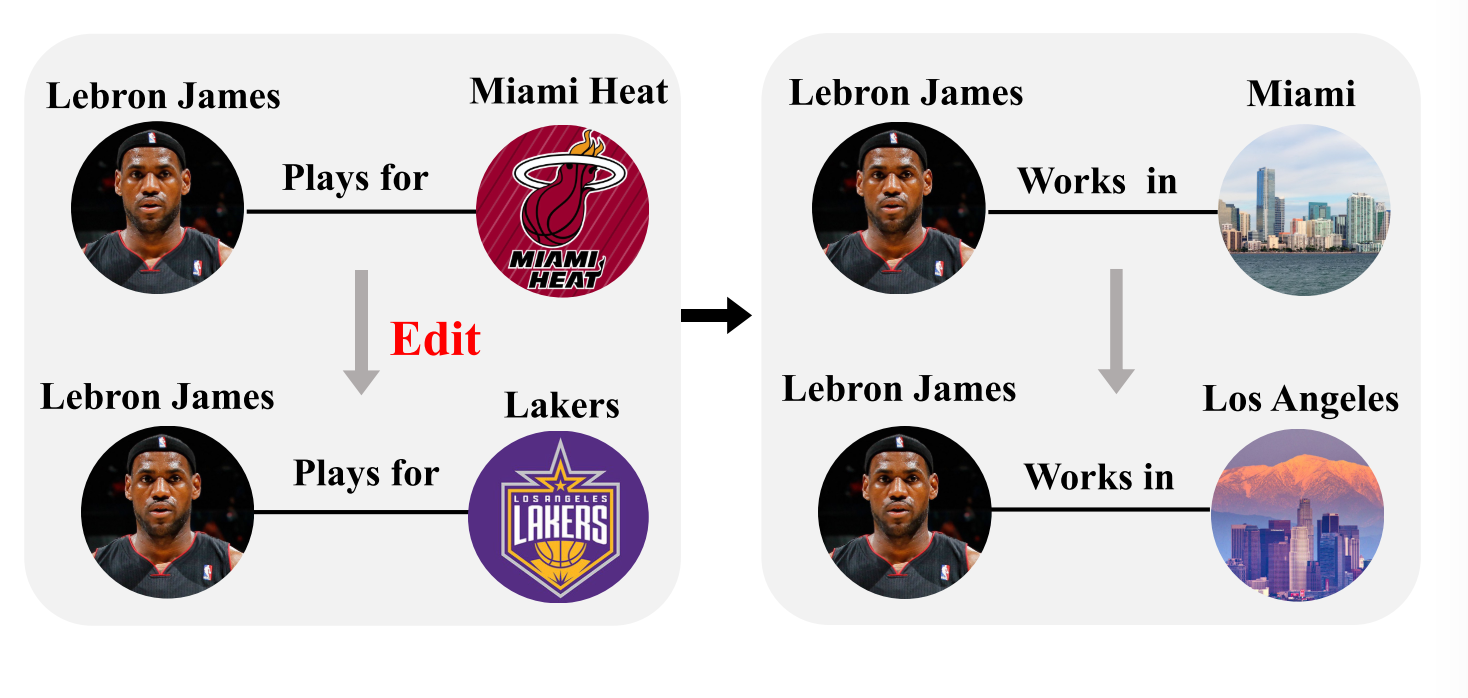
图1:LLM的模型编辑示例。编辑目标知识会导致相关知识的变化
为了应对上述挑战,我们提出了一种新的定位然后编辑方法增强知识图的大型语言模型编辑,即GLAME。具体来说,对于每个目标编辑知识,我们首先提出一个知识图增强(KGA)模块(§4.1)来构建一个子图,该子图捕获编辑产生的新关联。以简单的方式直接将子图中的高阶关系编辑为LLM需要对模型进行多次修改,并且可能会破坏目标编辑的知识,可能会产生显著的不利影响并降低编辑后的模型性能(§5.2)。因此,我们进一步开发了一个基于图的知识编辑(GKE)模块(§4.2),它将子图编码集成到一阶模型编辑框架中。只需进行一次编辑,它就能确保编辑的参数不仅能识别编辑的知识,还能识别受此类编辑影响的更广泛的知识范围。
我们将我们的贡献总结如下:
- 强调并研究了在模型编辑中捕捉编辑后知识引起的关联知识变化的必要性。
- 我们将知识图集成到模型编辑中,并提出了一种新颖有效的编辑方法来结构化编辑引起的知识变化,并将其纳入特定的参数。
- 我们在GPT-2 XL和GPT-J上的实验验证了上述模型的有效性。
二、相关工作
在本节中,我们介绍了模型编辑的相关工作,其目的是将新知识纳入LLM或修改其现有的内部知识,同时最大限度地减少对无关知识的影响。模型编辑方法可以大致分为两类(Yao等人,2023):参数保留和参数修改方法。
2.1参数保持方法
知识更新而不修改LLM的参数。例如,SERAC(Mitchell等人,2022)方法引入了一个门控网络,并结合了一个专门设计用于管理编辑过的知识的附加模型。然而,这些方法在可伸缩性方面都有一个基本的限制:外部模型的管理复杂性随着每一次额外的编辑而升级,这可能会阻碍其实用性。
2.2参数修改方法
参数修改方法直接改变LLM的内部参数,以纳入新的知识,包括元学习,基于微调和定位然后编辑方法。
元学习方法训练超网络以生成LLM的更新权重。KE(De Cao等人,2021)是最早的方法之一,利用双向LSTM来预测权重变化。然而,其可扩展性受到现代模型的大参数空间的限制。为了解决这个问题,MEND(Mitchell等人,2021)采用微调梯度的低秩分解,提供了一种有效的机制来更新LLM中的权重。
基于微调的方法通过监督微调来修改LLM的内部参数。最近的工作,如(Gangadhar和Stratos,2024),利用LoRA(Hu等人)。结合数据增强技术来微调LLM,有效地实现有针对性的知识编辑。定位然后编辑方法旨在通过针对与特定信息直接相关的参数来进行更可解释和更精确的知识编辑。早期的尝试包括KN(Dai等人,2022),提出了一种知识归属方法来识别知识神经元,但是在对模型的权重进行精确更改方面做得不够。随后,在理解Transformer的基本机制方面的进展(Vaswani等人,2017)模型已经引入了前馈网络(FFN)模块可能用作键值记忆的假设(Geva等人,2021年,2023年),从而为更精确的编辑策略奠定基础。罗马(Meng等人,2022 a)方法,建立在这一见解,采用因果跟踪,以查明知识相关的层,然后编辑其FFN模块,实现上级的结果。在此基础上,MEMIT(Meng等人,2022 b)处理批量编辑任务,实现大规模知识集成。
尽管取得了这些进步,但所有上述模型主要集中在编辑孤立的知识片段,忽略了模型知识库中潜在的涟漪反应(Cohen等人,2024; Zhang等人,第2024段b)。这种遗漏会削弱模型编辑后的泛化能力,并阻碍其利用新整合的知识进行进一步推理的能力(Zhong等人,2023年)的报告。
三、前言
在本节中,我们介绍了模型编辑和知识图的定义,以及我们研究中使用的一阶模型编辑框架。
定义1(LLM的模型编辑)
模型编辑(Yao等人,2023)旨在调整LLM F的行为,以将模型中编码的知识(s,r,o)修改为目标知识(s,r,o),其中知识表示为三元组,由主题s,关系r和对象o组成。每个编辑样本e可以表示为(s,r,o,o)。编辑后LLM定义为F′。
定义2(知识图谱)
知识图(KG)(Ji等人,2021)将结构化知识存储为三元组{(s,r,o)E ×R× E}的集合,其中E和R分别表示实体和关系的集合。
3.1一阶模型编辑框架
秩一模型编辑(罗马)(Meng等人,2022 a)是一种定位然后编辑的方法,该方法假设事实知识存储在前馈神经网络(FFN)中,概念化为键值存储器(Geva等人,2021年;小林等人,2023年)的报告。具体地,用于第i个令牌的第l层FFN的输出被公式化为:
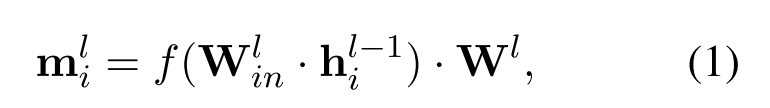
其中f(·)表示激活函数,hl−1 i是FFN的输入。为了便于表示,我们在后面的讨论中省略了上标l。
在该设置中,第一层的输出f(Win· hi)用作表示为ki的关键字。后续层的输出表示相应的值。基于该假设,该方法利用了偶然追踪(Pearl,2022; Vig等人,2020)以选择用于编辑的特定FFN层,从而通过求解约束最小二乘问题来更新第二层的权重W:
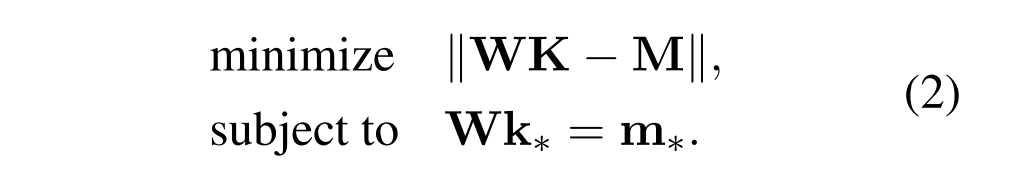
这里,目标函数的目的是在LLM内保持与编辑的样本无关的知识不变,其中K = [k1; k2;,.......kp]表示编码与所编辑事实无关的主题的键的集合, M =[m1; m2;,...、; mp]为相应的值。为相应的值。这个约束是为了确保编辑后的知识可以被合并到FFN层中,特别是通过使密钥k *(编码主体s)能够检索关于新对象o * 的值m *。
如在(Meng等人,2022a),可以导出上述优化问题的封闭形式解:
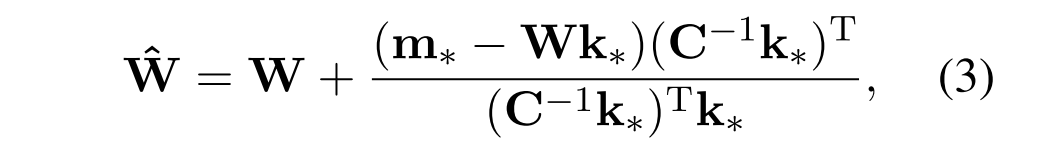 其中C = KKT表示一个常数矩阵,通过基于维基百科文本样本估计k的非中心协方差来预计算(附录E)。因此,求解最优参数θ W转化为计算k θ和m θ。
其中C = KKT表示一个常数矩阵,通过基于维基百科文本样本估计k的非中心协方差来预计算(附录E)。因此,求解最优参数θ W转化为计算k θ和m θ。
扩展这一框架,我们的研究描绘了一种方法来整合图形结构的知识,新的和内在的编辑知识,到编辑的模型参数。我们将在下面的章节中详细描述我们的方法。
四、方法
在本节中,我们将介绍所提出的GLAME,其架构如图2所示。该框架包括两个主要组成部分(1)知识图增强(KGA),其通过利用外部知识图来关联LLM中的内部变化的知识,以及(2)基于图的知识编辑(GKE),其将编辑和编辑引起的变化的知识注入到LLM的特定参数中。
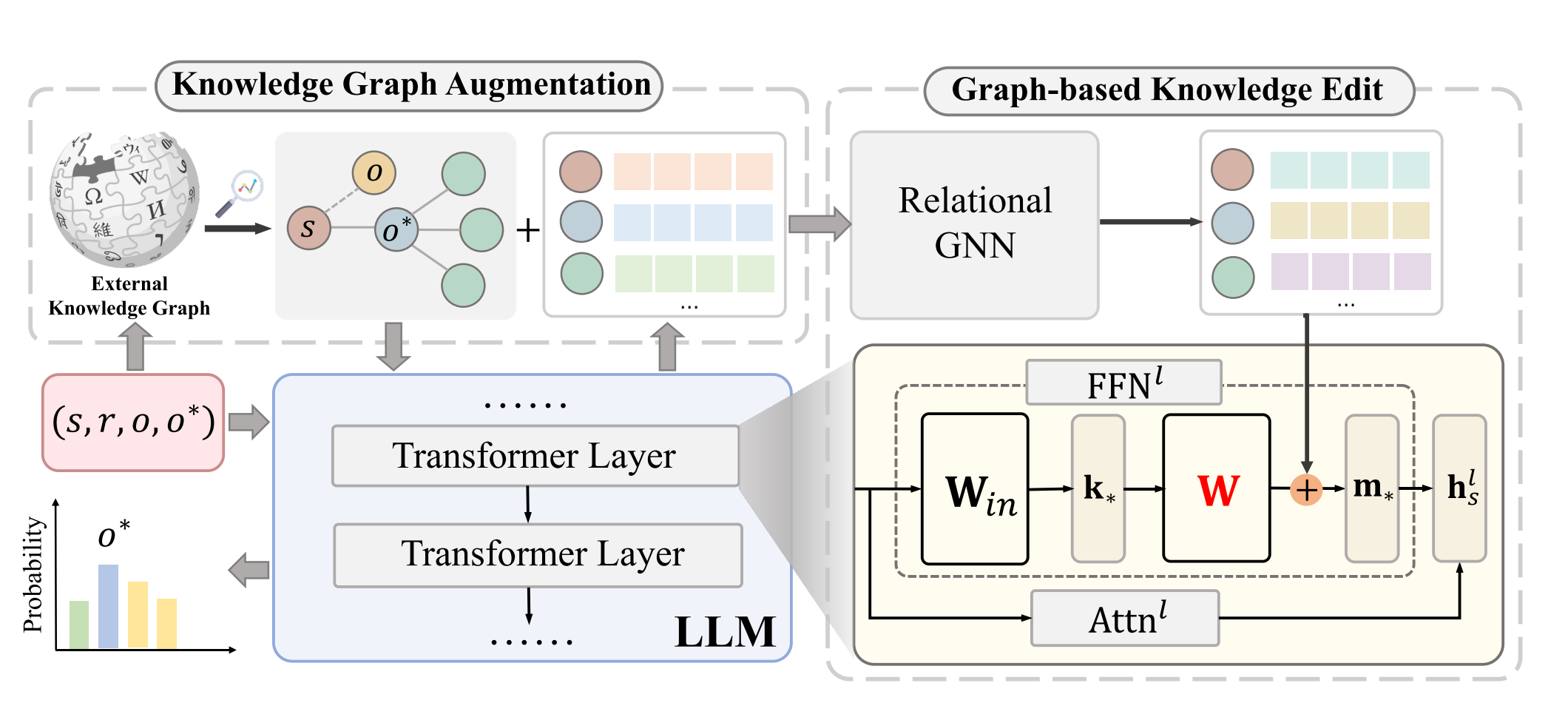
图2:GLAME架构的说明。我们首先利用知识图增强模块对高阶子图进行采样,记录由编辑(s,r,o,o)引起的更改的相关知识。随后,使用LLM对子图内的实体和关系进行编码,从中从早期层提取隐藏向量作为子图中的实体和关系的初始表示。然后,精心设计的基于图的知识编辑模块利用关系图神经网络将来自子图的新知识关联纳入参数编辑过程。
4.1知识图谱增强
为了准确地捕捉在LLM编辑引起的相关知识的变化,我们建议使用外部知识图。这种方法分为两个操作部分:首先,它利用外部知识图来构建子图,捕获改变的知识。然后,LLM被用来提取该子图中的实体和关系的相应表示,作为初始表示。
4.1.1子图构造
我们首先介绍如何利用外部知识图来构造一个子图,该子图封装了由于编辑而新形成的关联。
具体来说,对于给定的目标编辑样本e =(s,r,o,o),我们最初使用o来匹配外部知识图中最相关的实体,例如Wikipedia1。该步骤之后是对以该实体为中心的相邻实体及其关系进行采样,记作(o n,r1,o1),(o n,r2,o2),· · ·,(o n,rn,om)。它们被用来构建新的二阶关系:(s,r,o 1,r1,o1),(s,r,o 2,r2,o2),· · ·,(s,r,o n,rn,om),从而产生新的相关知识作为编辑的结果。这里m表示每个实体的最大样本数。按照这种方法,我们可以顺序地对o1,o2,· · ·,om的相邻实体进行采样,从而为s构建更高阶的新知识关联。我们定义新构建的关系的最大阶为n。目标编辑知识(s,r,o)与这些新的高阶关系沿着形成一个子图Gmn(e),它可以记录编辑知识部分引起的关联知识的变化。n也是子图的最大阶数,并且与m一起充当控制图的大小的超参数。
4.1.2子图初始化
为了进一步明确地关联受编辑影响的LLM内的知识,我们从LLM的早期层提取实体和关系的隐藏向量(Geva等人,2023)作为所构造的子图中的实体和关系的初始表示。
具体地说,我们将实体和关系文本分别输入到LLM中,然后选择第k层实体和关系文本的最后一个标记的隐藏状态向量作为它们的在子图中的初始表示:
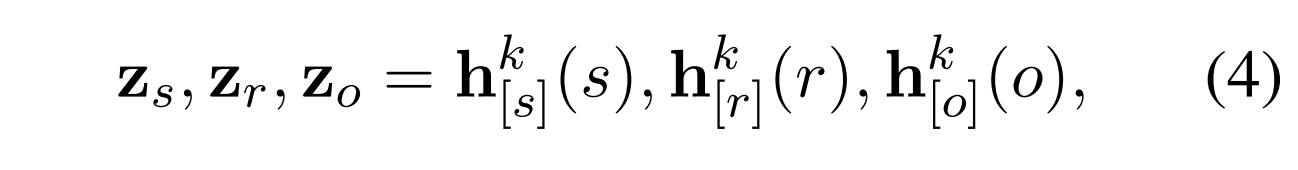
其中hk [x](x)是LLM的第k层处的文本x的最后一个令牌的隐藏状态向量。
4.2基于图的知识编辑
在得到知识增强子图后,设计了一个基于图的知识编辑模块,将子图中包含的新的关联知识整合到LLM的修改参数中。
4.2.1子图编码
为了利用由目标知识的编辑产生的新构造的关联知识来增强主题,我们通过关系图卷积网络(RGCN)(Schlichtkrull等人,(2018年版)。
形式上,我们将子图编码如下:
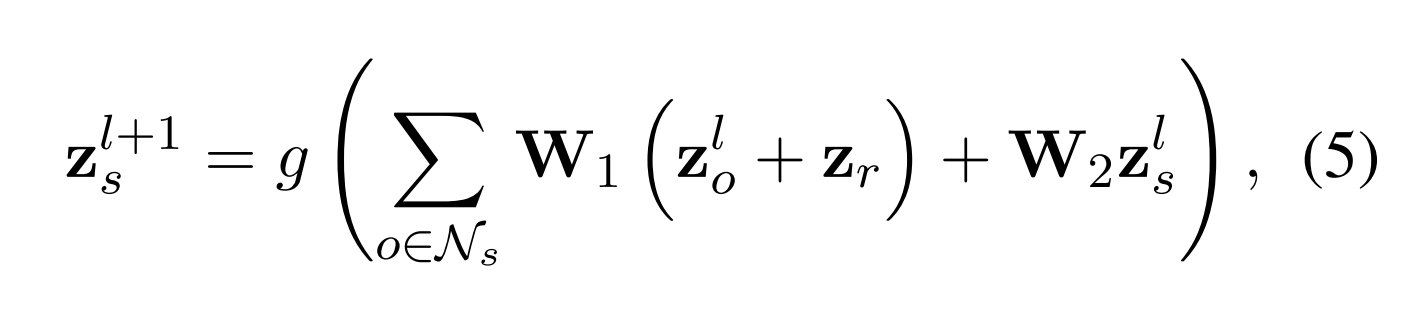
其中Ns是Gm n(e)中s的邻居集,g(·)是ReLU函数,W1和W2 ∈ Rd×d是每层中的可训练权重参数矩阵,z0 s,z0 o和zr是从§4.1.2中获得的相应实体和关系表示。为了全面地捕捉子图中节点之间的语义依赖关系,RGCN的层数被设置为子图的最大阶数n,在n层操作之后产生实体表示zn s。
4.2.2知识编辑
遵循罗马框架(Meng等人,2022 a),在该子部分中,我们针对特定层l来计算m和k。随后,我们使用等式(3)来更新FNN的第二层的参数,从而完成知识的编辑。
计算m
考虑到zn s聚合了新关联关系下邻居的信息,我们利用zn s来增强LLM的第l个FFN层中s的最后一个令牌处的表示:
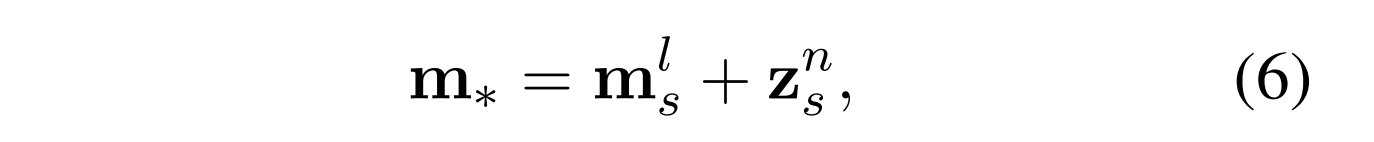
其中ml_s表示在LLM中的s的最后令牌处来自第l个FFN的输出。FFN的进一步细节在等式(1)中描绘。
对于每个编辑样本(s,r,o,o),我们的目标是细化RGCN以产生增强的表示m,m,使得LLM能够准确地预测目标对象o。因此,主损失函数定义为:
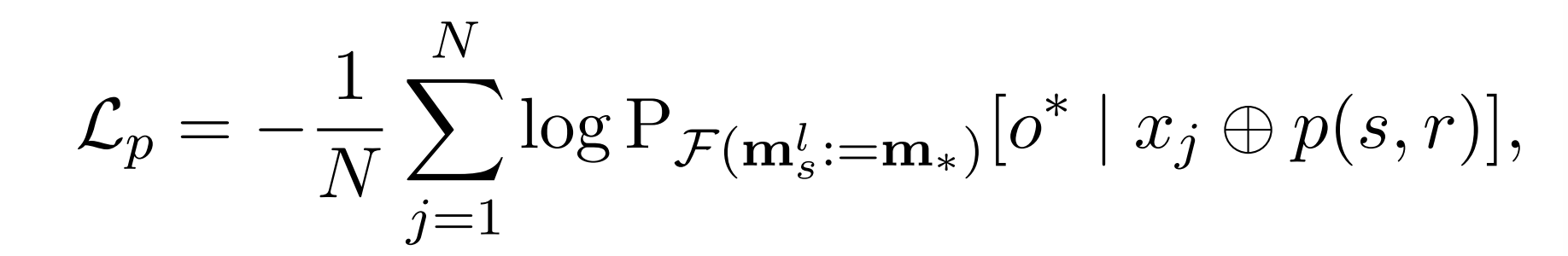
其中Xj是由LLM生成的随机前缀,以促进优化鲁棒性。F(ml s:= m)表示通过隐藏状态ml s修改为m的LLM的推理变更
为了减轻增强s对其在LLM内的固有性质的影响,我们的目标是在没有任何干预的情况下最小化F(ml s:= m λ)与原始模型F之间的KL发散(Meng等人,2022年a):
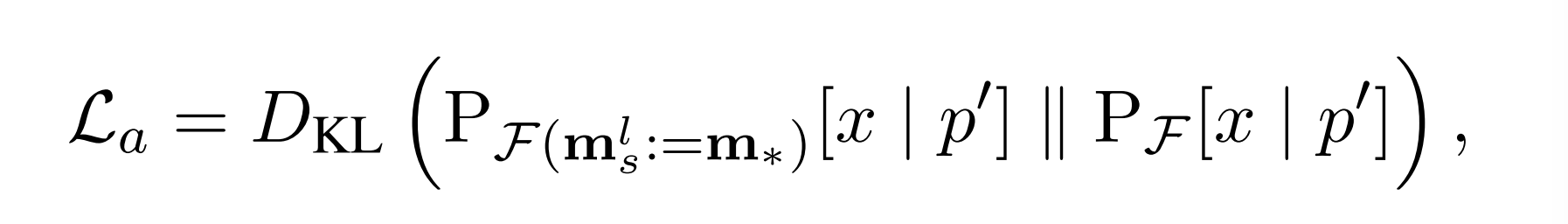
其中p′表示“主体是a”形式的提示。这一项用作正则化损失。
最终,通过最小化以下目标函数来优化RGCN的参数:
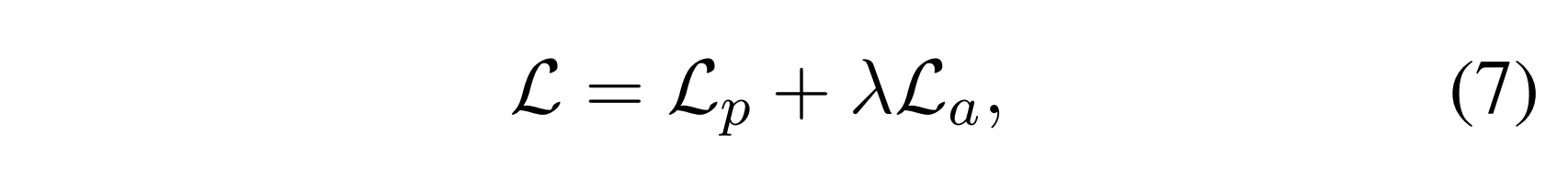
其中λ调整正则化强度。重要的是要注意,在整个优化过程中,LLM的参数保持不变。修改反而集中在优化RGCN的参数,这反过来又影响LLM的推理。
计算k
对于每个编辑样本(s,r,o,o),k通过以下公式计算:
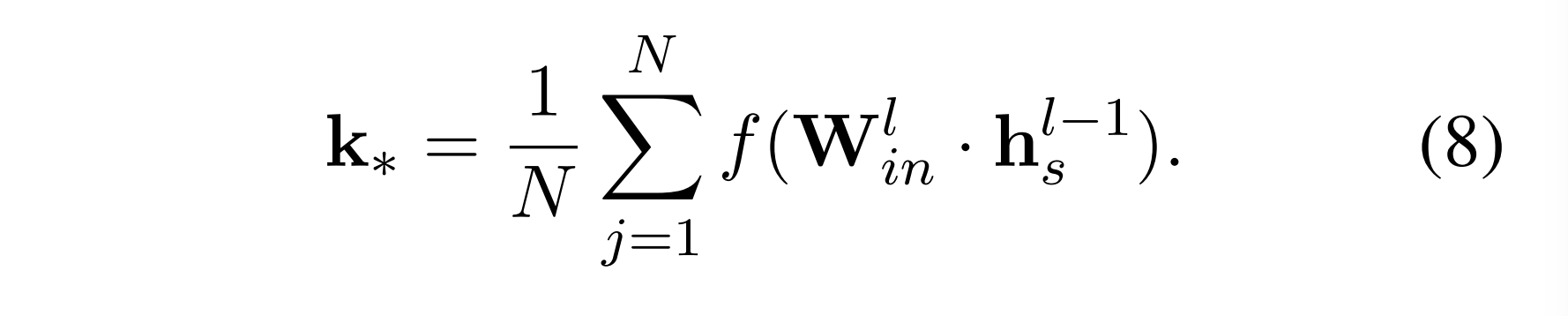
这里,我们还利用了以与计算m * 相同的方式生成的N个随机前缀(Meng等人,第2022条a款)。
在获得优化的m和k之后,我们将它们带入等式(3),然后获得编辑参数W。算法1提供了整个框架的伪代码。
五、实验
在本节中,我们将评估用于大型语言模型编辑(GLAME)的编辑方法图。通过将其应用于三个数据集并评估其在两个自回归LLM上的性能。我们的目标是通过实验回答以下问题。
- Q1:与最先进的模型编辑方法相比,GLAME在编辑知识方面的表现如何?
- Q2:不同的组件如何影响GLAME的性能?
- Q3:GLAME在不同超参数设置下的灵敏度如何?
5.1实验设置
5.1.1数据集和评估
在我们的实验中,我们在三个代表性的数据集上评估我们的GLAME:COUNTERFACT(Meng等人,2022a)、COUNTERFACTPLUS(Yao等人,2023)和MQUAKE(Zhong等人,2023年)的报告。
COUNTERFACT
是一个专注于将反事实知识插入模型的数据集。我们在这个数据集上使用了三个指标:功效分数,直接测量编辑的成功率;释义分数,表明模型准确回忆释义形式的编辑知识的能力,从而测试其泛化能力;和邻域分数,评估LLM中不相关的知识是否受到干扰。
COUNTERFACTPLUS
是COUNTERFACT的一个扩展,它提出了更具挑战性的测试问题,旨在评估编辑后模型准确响应需要使用编辑过的知识进行推理的查询的能力。与COUNTERFACT相比,该评估对泛化能力有更高的要求。以下(Yao等人,2023),我们采用可移植性评分来评估所有方法在该数据集上的性能。与其他指标相比,该指标更好地反映了LLM利用编辑后的知识及其相关信息的能力的上级反映。
MQUAKE
是一个更具挑战性的数据集,它也专注于评估模型使用新编辑的知识进行进一步推理的能力。此数据集中的每个条目可能涉及多个编辑,并包含多跳推理问题,需要从2到4跳进行推理才能正确回答,这对后模型的泛化能力提出了更严格的要求。
有关COUNTERFACT、COUNTERFACTPLUS和MQUAKE以及评价指标的更多详细信息,请参见附录B和C。
5.1.2基线
我们的实验是在GPT-2XL(1.5B)上进行的(拉德福等人,2019年)和GPT-J(6 B)(Wang和Komatsuzaki,2021年),我们将GLAME与以下最先进的编辑方法进行了比较:约束微调(FT-L)(Zhu等人,2020)、MEND(Mitchell等人,2021)、罗马(Meng等人,2022 a)和MEMIT(Meng等人,第2022条b款)。为了进一步验证基于图的编辑方法的优越性,我们还将基于图的编辑方法与两个变体模型ROME-KG和MEMIT-KG进行了比较。这些模型分别利用罗马和MEMIT,直接将新的高阶关系(s,r,o *,r,o 1),· · ·,(s,r,o *,r,on)(如4.1.1节所述)编辑到LLM中,这些新的高阶关系是由编辑后的知识(s,r,o,o *)产生的。我们在附录D中提供了基线和GLAME的实施细节。
5.2性能比较(RQ1)
5.2.1关于COUNTERFACT和COUNTERFACTPLUS的结果
所有编辑器在COUNTERFACT和COUNTERFACTPLUS上的性能如表1所示。根据结果,我们有以下观察结果:
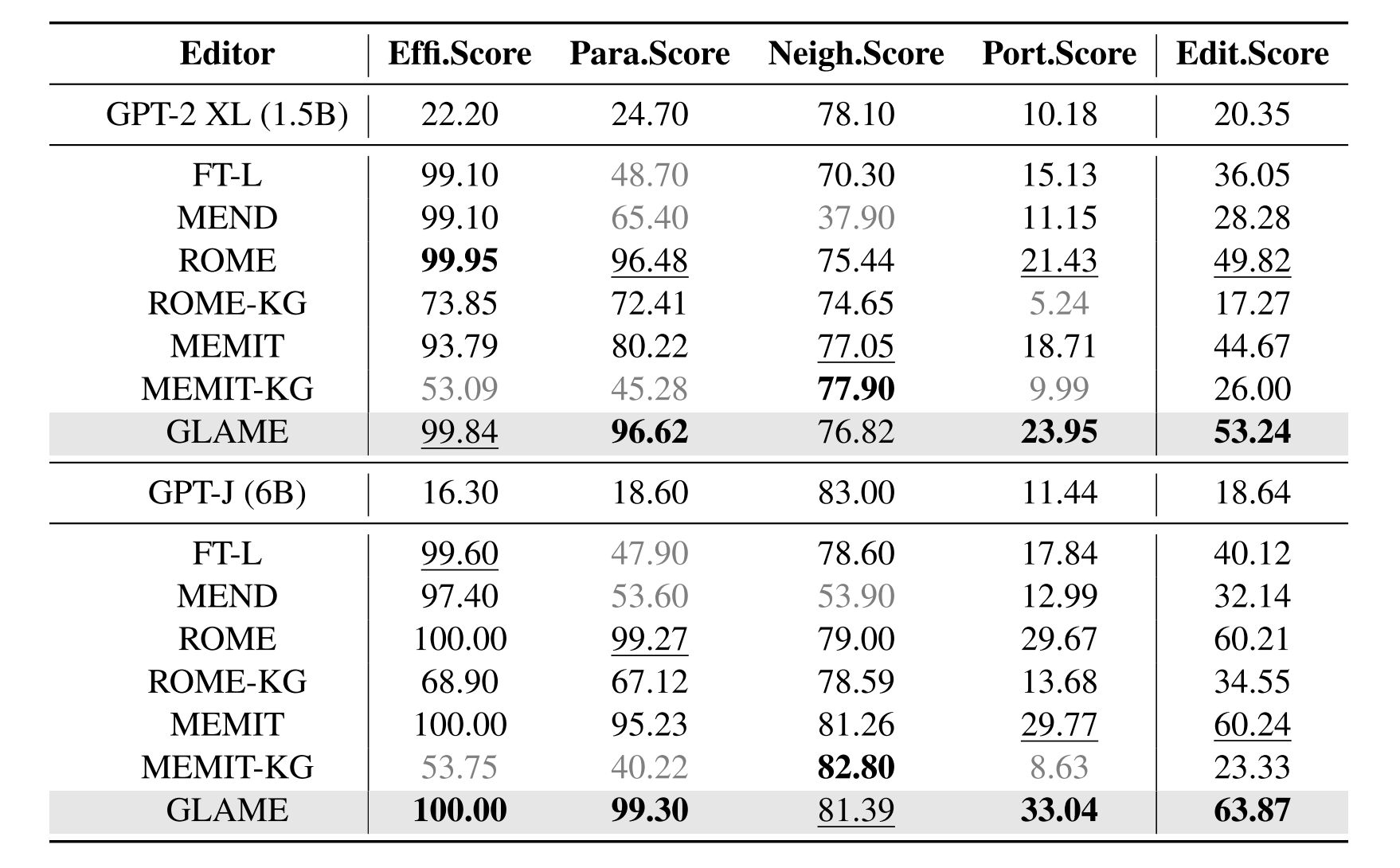
表一:在有效性评分(%)、释义评分(%)和邻域评分(%)方面对COUNTERFACT进行的性能比较,以及在可移植性评分(%)方面对COUNTERFACTPLUS进行的性能比较。编辑评分(%)是四个评估指标的调和平均值。最好的表现用粗体突出显示,第二好的表现用下划线突出显示。灰色数字表示相应指标明显失败。
我们的模型GLAME在综合评估指标上获得了最高的性能,即编辑分数,在大多数评估指标上超过了其他编辑器。具体而言,GLAME在GPT-2 XL和GPT-J的最佳基线模型上的可移植性评分分别提高了11.76%和10.98%。这表明,我们的方法可以有效地提高泛化能力的编辑后LLM利用编辑的知识,特别是在多跳推理,通过有效地引入外部知识图。GLAME、罗马和MEMIT在释义和邻域得分方面明显优于其他方法。其原因可能是这些方法对编辑知识的回忆和编辑无关知识的保留施加了明确的限制。尽管MEND和FT-L可以准确地回忆编辑过的知识并在功效评分上取得值得称赞的结果,但与其他编辑器相比,它们在编辑过程中缺乏精确度导致释义、邻里和可移植性评分表现不佳。
与罗马和MEMIT相比,ROME-KG和MEMIT-KG表现出明显的性能下降。这表明简单地仅仅添加额外的外部信息进行编辑并不能保证性能得到改善。具体来说,ROME-KG需要对模型参数进行多次调整,以编辑高阶关系,这可能会损害原始参数。MEMIT-KG将大量信息无限制地合并到LLM中可能会危及目标知识的编辑。相反,GLAME通过开发针对图结构定制的编辑方法,将由于编辑而改变的多条关联知识仅通过一次编辑合并到模型中。该方法不仅保持了编辑的精确性,而且大大提高了利用外部知识图的效率.
5.2.2关于MQUAKE的结果
为了进一步证明GLAME在捕获由于编辑引起的相关知识变化方面的能力,我们将我们的GLAME与两个竞争性基线模型罗马和MEMIT在更具挑战性的MQUAKE上进行了比较(Zhong等人,2023年)数据集。结果示于表2中。从结果中,我们发现,我们的GLAME实现了显着的改善,罗马和MEMIT在不同的跳数的问题。随着跳数的增加,这需要更大的编辑知识利用率,各种编辑方法的性能开始下降。然而,GLAME在4跳问题上比SOTA方法表现出最高的相对改进,这可能归因于我们的模型有效地捕获了关联知识,使其能够构建更坚实的知识表示。这种优势在4hop问题的背景下变得很重要,其中推理的复杂性明显更高。这着重验证了该模型在提高后编辑模型处理编辑后知识的泛化能力方面的有效性。

表2:编辑器在MQUAKE数据集的多跳问题上的性能比较,以功效评分(%)表示。
5.3消融研究(RQ 2)
为了研究我们方法的每个组件的优越性,我们将GLAME与不同的变体进行比较:GLAME w/ GCN,它省略了RGCN的关系信息,并在GKE模块中采用GCN(Kipf和Welling,2017)进行子图编码; GLAME w/ RGAT,它利用关系图注意力机制(Lv等人,GLAME w/ MLP,它忽略了图的结构信息,仅依赖于MLP来编码GKE模块中的实体表示; GLAME w/o GKE,它删除了GKE模块并且退化到进入罗马。结果如表3所示,我们有以下观察结果:
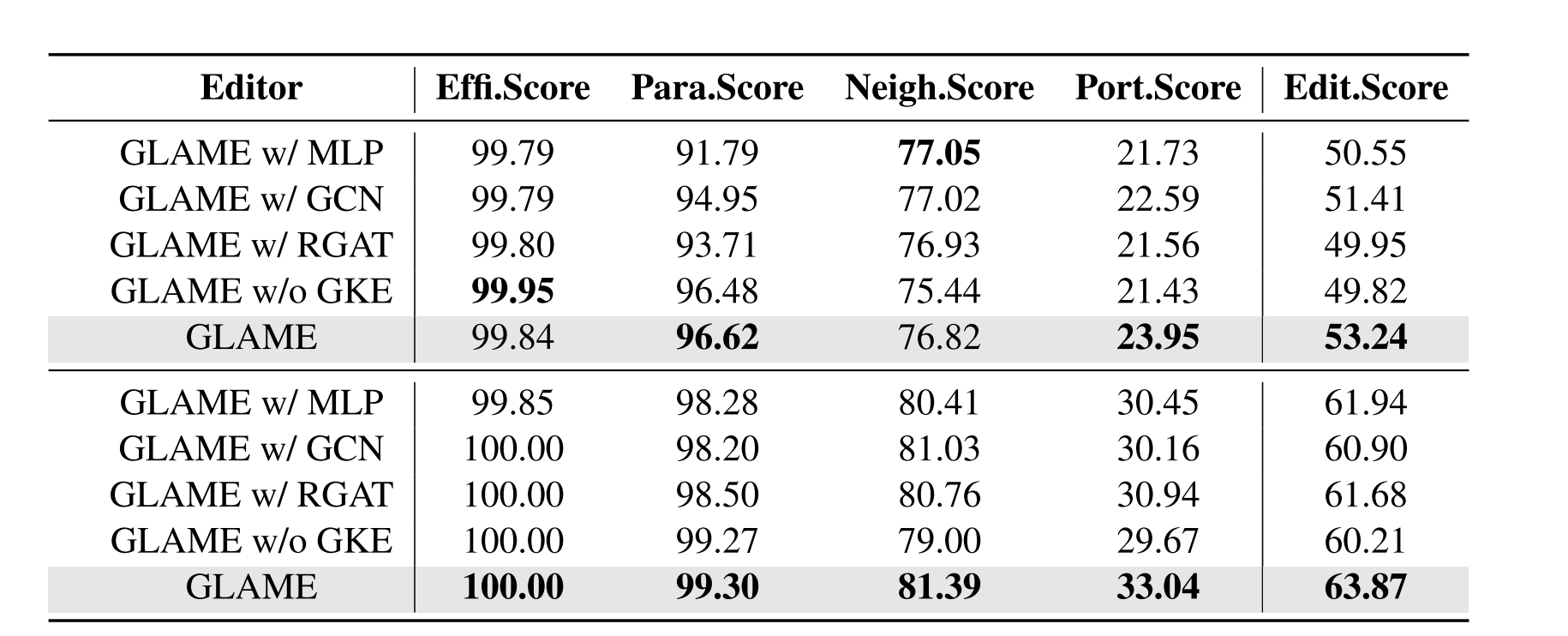
表三:关于COUNTERFACT的消融研究(有效性评分(%)、释义评分(%)和邻域评分(%))以及关于COUNTERFACTPLUS的消融研究(便携性评分(%))。
GLAME在大多数评估指标上都优于GLAME w/ MLP和GLAME w/o GKE,尤其是在可移植性评分和编辑评分方面。这证实了通过GKE模块对结构化知识进行整合,有效地增强了编辑后模型的泛化能力。此外,与GLAME w/o GKE相比,GLAME w/ MLP、GLAME w/ RGAT和GLAME w/ GCN在编辑评分方面也实现了更好的性能。这些改进验证了外部信息的有效结合:LLM早期层的主体实体及其邻居的隐藏状态向量有助于编辑的性能。此外,相比GLAME w/ GCN,GLAME的性能进一步提高,突出了关系在LLM识别复杂图结构知识关联中的重要性。然而,与GLAME相比,GLAME w/ RGAT的性能下降。这种下降可能是由于RGAT的结构和参数的复杂性,这对其优化过程提出了挑战。
5.4敏感性分析(RQ3)
为了进一步探讨GLAME对重要超参数的敏感性,我们研究了关键超参数,子图的最大阶数n和最大采样邻居数m对GLAME性能的影响。更多结果见附录F。
5.4.1最大子图阶数n的影响
子图构造是知识图增强模块的重要操作(第4.1.1节)。子图的最大阶数决定了编辑后的知识所影响的关联知识的范围。在这一部分中,我们在GPT-2 XL和GPT-J上的GKE模块中进行了不同子图阶数n的GLAME,以编辑和可移植性得分为标准。我们将n设置在{0,1,2,3}的范围内。结果如图3所示。主要意见如下:
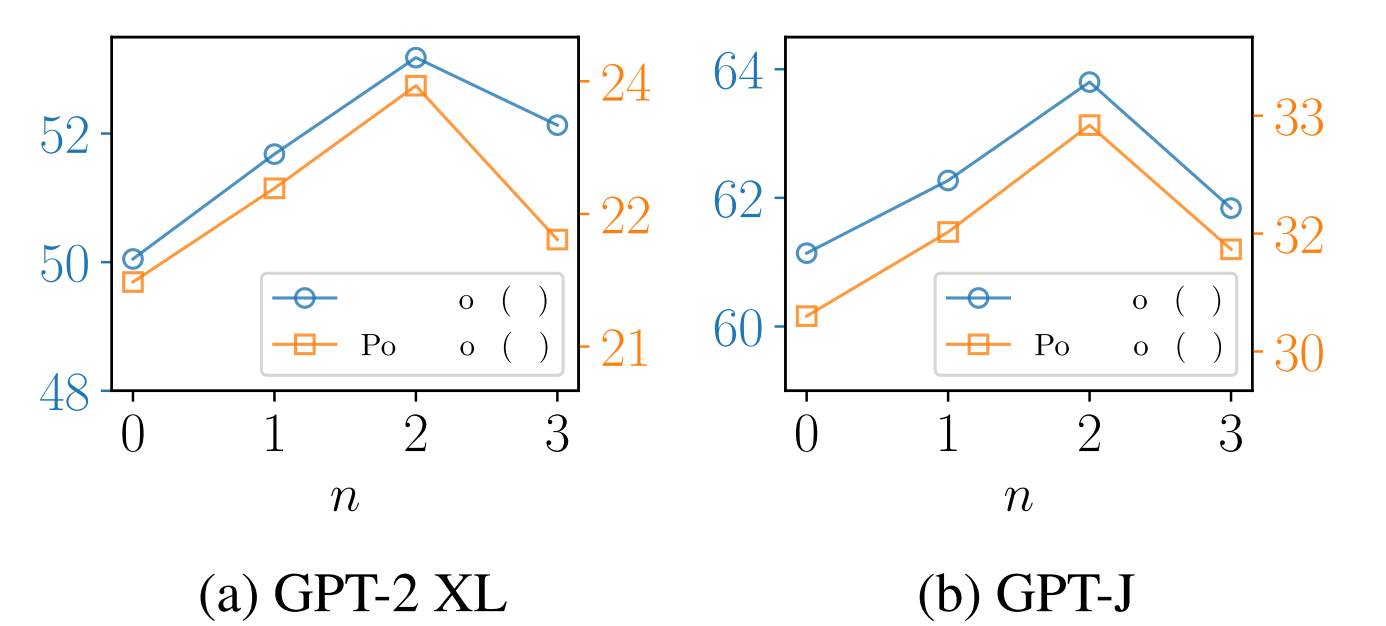
图3:不同子图阶数n的GLAME在Edit.Score和Prot.Scores方面的性能。
增加最大子图阶数n显著提高了编辑后模型的性能,对于两个LLM,在n = 2时达到峰值。n > 0的GLAME始终优于n = 0的GLAME。我们将改进归因于由于编辑而改变的相关知识的合并。然而,当最大阶数超过2(n > 2)时,后模型的性能开始下降,这可能是因为高阶信息的使用容易给编辑过程引入噪声
5.4.2最大相邻数m的影响
为了进一步研究子图的大小如何影响编辑性能,我们在GPT-2 XL和GPT-J上用GLAME进行实验,改变KAG模块中每个节点的最大邻居数m,和可移植性得分。结果如图4所示。具体来说,我们观察到一致的改进,在编辑性能的邻居的数量从5增加到20 GPT-2 XL,并高达25 GPT-J。这表明,纳入更多的邻居可以增强中央实体的表示,使图形结构可以更好地反映编辑的知识所造成的变化。然而,随着m的不断增大,模型的性能开始下降。这种下降可能是由于过多的相邻节点引入了噪声,并且增加的子图大小可能会升级RGCN的优化难度。

图4:在Edit.Score和Prot.Score方面,具有不同最大邻居数m的GLAME的性能。
六、结论
本文首次提出了一种新的大规模语言模型编辑方法GLAME。GLAME利用知识图扩充模块,通过构造外部图来捕获关联知识中的变化。在此基础上,我们引入了一个基于图的知识编辑模块,该模块利用关系图神经网络将新的知识关联从构建的子图无缝地集成到LLM的参数编辑框架中。在两个LLM上的实验结果和广泛的分析表明了GLAME在模型编辑任务中的有效性和优越性。
不足
在本节中,我们将讨论GLAME的局限性。第一个限制是,我们的框架对知识图的依赖可能会受到相关知识的可用性和质量的限制。在相关知识稀缺或知识图质量较低的情况下,模型的性能可能会受到影响。尽管采用了一个简单而直接的子图采样策略,我们已经取得了可喜的成果。未来,我们计划开发更复杂的子图采样策略,以提高子图质量并更准确地捕获编辑引起的知识变化。此外,这些策略旨在提高采样速度和减少子图大小
第二个限制是,我们的框架可能会限制在一些非结构化的编辑场景中,例如基于事件的知识编辑或与知识图没有显式关联的场景。在这些场景中,提取关键实体是具有挑战性的,需要额外的实体提取算法或工具来从用于子图构造的编辑样本中提取有效的关键实体。尽管这些算法和工具已经开发得很好,但它们在效率或灵活性方面可能存在局限性。在未来,我们将设计更灵活的策略来识别编辑样本中的关键实体并构建相关的子图,将我们的方法扩展到更一般的编辑场景。
伦理考虑
我们认识到,发展生成型LLM存在着风险,因此有必要关注LLM的伦理问题。我们使用公开提供的经过预训练的LLM,即:GPT-2 XL(1.5B)和GPT-J(6B)。这些数据集是公开的,反证、反证加和地震。所有的模型和数据集都由其出版商仔细处理,以确保不存在道德问题。
A 伪代码
算法1提供了编辑方法GLAME的伪代码.
算法1:编辑过程

B 数据集详细信息
B.1 COUNTERFACT数据集详情
表4显示了COUNTERFACT数据集的一个示例。每个条目都包含一个编辑请求、几个释义提示和邻域提示。在该示例条目中,编辑请求旨在将LLM的知识从Danielle Darrieux的母语是法语改变为Danielle Darrieux的母语是英语,其中Danielle Darrieux对应于s,的母语对应于r,法语对应于o,并且英语对应于编辑样本(s,r,o,o)中的o。释义提示语是目标提示语Danielle Darrieux母语的语义变体,而邻近提示语是与编辑请求具有相同关系但具有不同主题的提示语,其知识应保持不变。

表4:COUNTERFACT数据集示例
我们的训练/测试数据集拆分与(Meng等人,第2022条a款)。同样,我们使用GPT-2 XL上的前7500条记录和GPT-J上的前2000条记录来评估我们的方法。注意,对于不采用超网络的方法,包括我们的GLAME中,不需要使用来自训练集的数据进行训练。
B.2 COUNTERFACTPLUS数据集详情
COUNTERFACTPLUS数据集作为原始CounterFact数据集的补充扩展,选择1031个条目作为原始数据的子集,并根据原始内容使用新的测试问题丰富它们。每个条目都包含与COUNTERFACT中相同的编辑请求,以及需要LLM根据编辑的知识进行进一步推理的其他问题和答案。
表5展示了数据集中的一个示例条目。在该示例条目中,编辑请求需要将LLM的知识从Spike Hughes originates from伦敦修改为Spike Hughes originates from Philadelphia。这个编辑引入了新的知识关联,例如(Spike Hughes,起源于费城,以奶酪牛排闻名),导致多跳问题“什么著名的食物与Spike Hughes起源的城市有关?”。编辑后的LLM应使用此多跳问题的正确答案Cheesesteaks进行响应,而不是与问题关联的原始答案。用于构造多跳问题的相关知识关联(Philadelphia,以Cheesesteaks而闻名)在数据集中被标记为“召回关系”。在我们的工作中,我们主要集中在多跳推理方面,旨在评估GLAME的能力,以捕捉相关的知识变化。

表5:COUNTERFACTPLUS数据集示例
B.3 MQUAKE数据集详情
与COUNTERFACTPLUS类似,MQUAKE是一个更具挑战性的数据集,也专注于评估模型使用新编辑的知识执行进一步推理的能力。此数据集中的每个条目可能涉及多个编辑,并包含多跳推理问题,这些问题需要从2到4跳进行推理才能正确回答,显示出对后模型的泛化能力要求更高。
表6展示了来自MQUAKE数据集的示例。示例条目需要对LLM进行两次编辑,插入新知识(贝蒂卡特,戏剧,器乐摇滚)和(美国,国家元首,诺罗敦·西哈莫尼)。因此,一个3跳的问题“谁是国家元首的音乐流派与贝蒂卡特起源?”的构建,以评估编辑后LLM的能力,采用编辑的知识及其相关的知识。继(Zhong等人,2023),我们的评估还集中在3000个条目的子集上,均匀分布在{2,3,4}跳问题上,每个类别包括1000个条目。

表6:MQUAKE数据集示例
C评估
我们采用三个广泛使用的指标(Meng et al.,2022 a,B)、功效评分、释义评分和邻域评分来评估COUNTERFACT数据集上的所有编辑器,并使用可移植性评分(Yao等人,2023年)在COUNTERFACTPLUS数据集上。我们利用调和平均值的四个指标,编辑分数,以评估每个编辑的整体能力。每个度量计算如下:
功效分数
是为了测试当给定编辑提示p(s,r)时,编辑后LLM是否可以正确地回忆新的目标实体。计算方法为
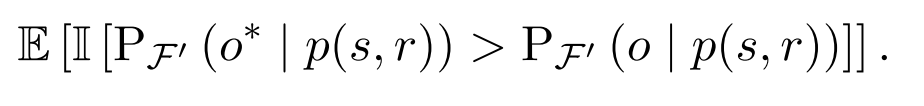
释义分数
测量编辑后LLM对编辑提示p(s,r)的重排提示集PP的性能。计算方法类似于功效评分:
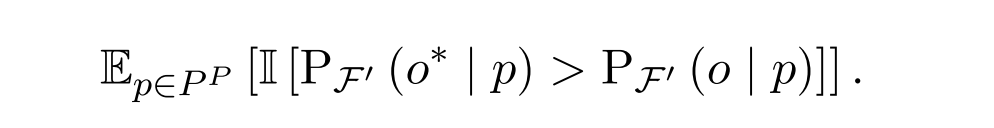
邻域得分
测量编辑后LLM是否将较高概率分配给提示集PN上的正确事实,提示集PN由不同但语义相似的提示p(s,r)组成。计算定义为: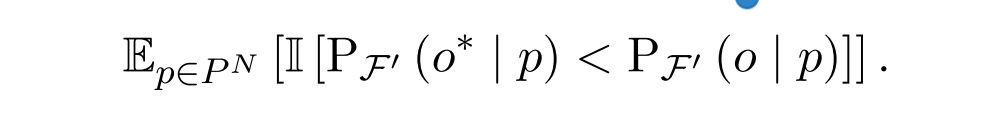
此度量可以评估编辑对不相关知识的影响程度
可移植性分数
测量编辑后模型对关于编辑样本的多跳问题集P的准确性:
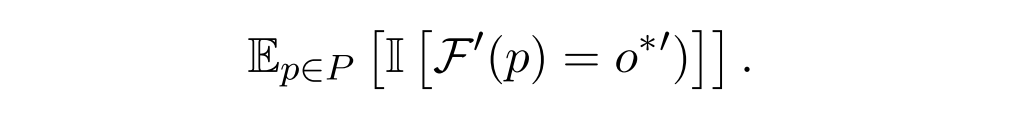
考虑到与评估数据相关的挑战,与其他指标相比,可移植性分数提供了模型泛化能力的更准确反映。
D 基线
我们的实验是在GPT-2 XL(1.5B)上进行的(拉德福等人,2019)和GPT-J(6 B)(Wang和Komatsuzaki,2021),我们将GLAME与以下最先进的编辑方法进行了比较:
约束微调(FT-L)
(Zhu等人,2020)涉及直接使用梯度下降来微调LLM参数的特定层,同时对权重变化施加范数约束以防止灾难性遗忘。
MEND
(Mitchell等人,2021)基于梯度的低秩分解来构造超网络以执行编辑。
ROMA
( Meng等人,2022 a)基于LLM中的知识存储在FFN模块中的假设,并且使用优化来更新FFN层以插入知识。
MEMIT
( Meng等人,2022 b)建立在罗马方法的基础上,通过在一系列FFN层上执行编辑来专门进行批量编辑任务。
为了进一步验证我们的基于图形的编辑方法的优越性,我们还将我们的方法与两个变体模型ROME-KG和MEMITKG进行了比较。这两个基线旨在评估在不使用GKE模块的情况下直接将相同数量的外部信息添加到LLM的性能。对于测试数据集中的每条记录,我们构造包含知识图中高阶关系的编辑请求。例如,给定原始编辑内容“Spike Hughes originates from伦敦→华盛顿”和相关的知识图三元组(华盛顿,美国首都),我们然后创建新的编辑请求以将该知识插入到LLM中:“Spike Hughes originates from华盛顿,美国首都”,使用罗马或者MEMIT.
E 实施细节
我们用PyTorch 2和DGL 3实现了我们的GLAME方法。在知识图增强(KGA)模块中,我们将GPT-2 XL和GPT-J的最大子图阶数n设置为2,将GPT-2 XL的最大采样邻居数m设置为20,GPT-J的最大采样邻居数m设置为40。分别从GPT-2 XL的第5层(k = 5)和GPT-J的第2层(k = 2)提取实体和关系的隐藏向量,以初始化子图表示。对于GKE模块,我们根据罗马的定位结果在GPT-2 XL的第9层(l = 9)和GPT-J的第5层(l = 5)上执行编辑操作。对于RGCN优化,使用AdamW(Loshchilov and Hutter,2018)优化器,学习率为5 × 10−1,COUNTERFACT的最佳正则化因子λ为6.25 × 10−2,COUNTERFACTPLUS和MQUAKE的最佳正则化因子λ为7.5 × 10−2。为了防止过度拟合,我们在损失低于1 × 10−2时执行早期止损。由于我们的方法不需要额外的训练集进行训练,因此我们在训练集上选择重要的超参数。对于表示层中的预先计算的键的协方差矩阵估计C,我们直接使用由罗马计算的结果(Meng等人,2022a),这是使用100,000个维基文本样本收集的。为计算m和k而生成的随机前缀的数量N为50,用作原始编辑的数据扩充方法。对于其他基线,我们使用罗马实现的代码进行实验(Meng et al.,2022 a),并且我们比较的基线的所有设置,包括超参数,都与(Meng et al.,2022 a,B)。所有实验均在NVIDIA Tesla A100(80G)和AMD EPYC 7742 CPU上进行。
E.1维基数据采样细节
在知识图增强(KGA)模块中,我们利用Wikidata 4作为外部知识图,为每个编辑样本(s,r,o,o)构建子图。具体来说,我们使用2 https:pytorch.org/ 3 https:www.dgl.ai/ 4 https:www.wikidata.org/ Wikidata的API 5来执行SPARQL查询,检索实体的所有传出边。在检索到这些边之后,我们通过对它们进行排序来优先考虑三元组,以突出最有潜在价值的信息。这种优先级排序基于每个关系在数据集中出现的频率。出现频率较低的关系被认为更有价值,因为它们可能包含更高特异性或稀有性的信息,类似于信息熵的原理,其中出现频率较低的关系传达更多信息。
由于数据集COUNTERFACT、COUNTERFACTPLUS和MQUAKE是直接使用维基数据构建的,因此这些数据集中的每个编辑实体都与其对应的维基数据项ID相关联,从而允许精确采样。请注意,在我们的实验中,构造的子图被过滤以排除多跳问题的标准答案。这种操作确保了模型性能的提高归因于泛化能力的增强,而不是简单地受到子图中特定答案模式的影响。
E.2评估详情
在我们的实验中,我们按照(Meng等人,第2022条a款)。我们使用特定的提示作为LLM的输入,并检查了模型对原始实体o和编辑实体o * 的预测概率。对于COUNTERFACTPLUS数据集,我们对可移植性分数的评估涉及使用多跳问题提示LLM,然后验证生成的输出是否包括正确的答案。为了适应模型输出和标准答案之间的措辞或同义词的变化,采用了模糊匹配。在实践中,我们使用了Fuzzywuzzy6库中的部分比率算法,该算法基于Levenshtein距离计算相似性。对于MQUAKE数据集,我们采用功效评分来评估不同编辑方法的有效性。
F 敏感性分析
子图的最大阶数n和最大采样邻数mGLAME中的2个关键超参数。图5和图6描绘了GLAME在各种n和m值上的性能,如通过释义和邻域得分所测量的。从图5中,我们观察到增加子图的阶数可以增强编辑后模型在释义得分方面的性能。这表明,在编辑过程中引入更多的新知识,可以提高编辑后模型在处理编辑知识时的泛化能力。相比之下,邻域分数相对于n的值表现出更大的稳定性,这表明我们的编辑方法对模型的原始能力造成的损害最小。
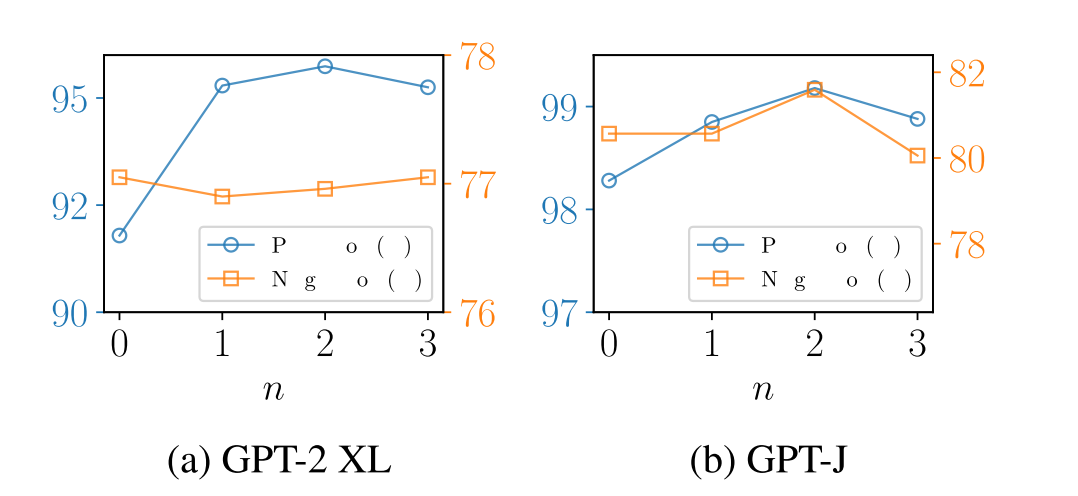
图5:不同子图阶数n的GLAME在释义和邻域得分方面的性能
在图6中,我们可以发现释义和邻域得分比图4中的编辑和可移植性得分更稳定。这种稳定性可以归因于损失函数的设计和在优化期间添加的那些随机前缀,其对与这两个度量相关的场景施加某些约束,从而导致随着子图的变化而更稳定的行为。
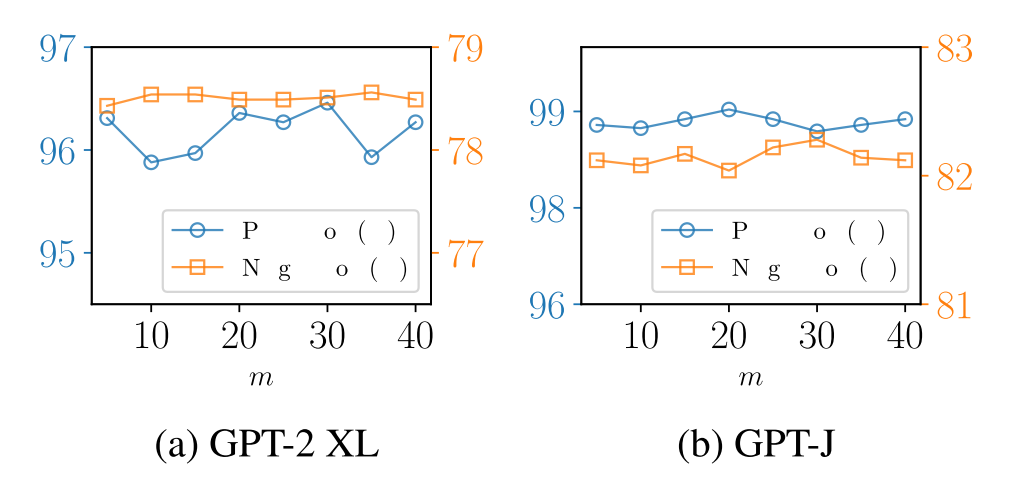
图6:在释义和邻域得分方面,具有不同最大邻居数量m的GLAME的性能。
值得注意的是,当n = 1时,所构造的子图将只包括主体实体、关系和新的对象实体(记为s-r-o)。在这种情况下,与罗马和MEMIT相比,GLAME表现出相对更好的编辑性能,在GPT 2-XL上实现了51.68的编辑得分,在GPT-J上实现了62.27的编辑得分。这意味着即使在最坏的情况下,通过子图采样在外部KG中找不到关于要编辑的实体的相关信息,我们的GLAME仍然可以执行基本编辑并实现更好的性能。
G 效率分析
我们提出的GLAME引入的时间开销主要包括子图采样和知识的编辑。第一部分涉及从外部知识图(如维基数据)中抽取子图。在我们的工作中,我们使用Wikidata的API进行采样操作。在实践中,每次编辑只需要向维基数据服务器发送一个简单的HTTP请求,这并不会带来很大的开销。尽管所需时间取决于网络条件,但在我们的实验中,获得每个编辑的子图所需时间始终不到1秒。
为了进一步检验我们的GLAME的效率,我们测量了GPT-J中GLAME在不同大小的子图上的编辑时间。其结果如表7所示。从结果中我们可以看出,GLAME的时间开销确实随着子图节点的数量而增加,然而,在模型表现出最佳性能的子图大小范围内(约20-40个节点),GLAME的额外时间要求并不显著高于罗马的额外时间要求(5.25s)。我们认为,考虑到编辑后LLM的泛化能力和编辑性能的提高,这种编辑时间是可以承受的。

表7:不同子图大小下GPT-J中GLAME的编辑时间(秒)。
H 案例研究
在本节中,我们将介绍几个GPT-J上的生成示例,其中使用了三种知识编辑模型:GLAME、罗马和MEND,以证明COUNTERFACTPLUS中通过多跳问题进行知识编辑的有效性。我们专注于编辑模型的利用新插入的知识的能力,用于响应给定提示进行推理,同时保持上下文连贯性。生成示例如图7所示。

图7:GLAME、罗马和MEND的GPT-J生成示例。生成输出中的斜体和绿色部分与多跳应答相关。输出中的红色突出显示表示模型生成的内容与插入的知识或上下文之间明显的不一致。
示例A [COUNTERFACTPLUS中的案例1662]。
在这个例子中,插入了反事实知识“遗产范围在非洲”。要正确回答多跳问题,编辑后的模型必须首先调用新插入的知识(Heritage Range,位于,Africa),然后调用(Africa,最高峰,基利曼哈罗山)。值得注意的是,GLAME提供了正确的答案,而罗马和MEND在推理过程中似乎无法回忆起插入的知识,提供了基于美国相关知识的答案,如“大平原”和“麦金利山”,表明概括性较弱。
示例B [COUNTERFACTPLUS中的病例5431]。
在这个例子中,一段新知识“足球起源于瑞典”被插入。要回答多跳问题,需要进一步推理,以确定瑞典著名运动员Zlatan Zahimovic。GLAME与上下文保持一致,并正确地回忆了答案。尽管罗马成功回忆起与“瑞典”相关的信息,但其回答与提示不符,只提到“瑞典”,并错误地声称“瑞典”是除中国外世界上人口最多的国家,出现了幻觉的迹象。MEND再次未能回忆起新插入的知识,提供了一个与巴西足球运动员贝利无关的答案。