(笔记+作业)第五期书生大模型实战营---L1G2000 OpenCompass 评测书生大模型实践
学员闯关手册:https://aicarrier.feishu.cn/wiki/QdhEwaIINietCak3Y1dcdbLJn3e
课程视频:https://www.bilibili.com/video/BV13U1VYmEUr/
课程文档:https://github.com/InternLM/Tutorial/tree/camp4/docs/L0/Python
关卡作业:https://github.com/InternLM/Tutorial/blob/camp4/docs/L0/Python/task.md
开发机平台:https://studio.intern-ai.org.cn/
开发机平台介绍:https://aicarrier.feishu.cn/wiki/GQ1Qwxb3UiQuewk8BVLcuyiEnHe
书生浦语官网:https://internlm.intern-ai.org.cn/
github网站:https://github.com/internLM/
InternThinker: https://internlm-chat.intern-ai.org.cn/internthinker
快速上手飞书文档:https://www.feishu.cn/hc/zh-CN/articles/945900971706-%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B%E6%96%87%E6%A1%A3
提交作业:https://aicarrier.feishu.cn/share/base/form/shrcnUqshYPt7MdtYRTRpkiOFJd;
作业批改结果:https://aicarrier.feishu.cn/share/base/query/shrcnkNtOS9gPPnC9skiBLlao2c
internLM-Chat 智能体:https://github.com/InternLM/InternLM/blob/main/agent/README_zh-CN.md
lagent:https://lagent.readthedocs.io/zh-cn/latest/tutorials/action.html#id2
1. OpenCompass 概述
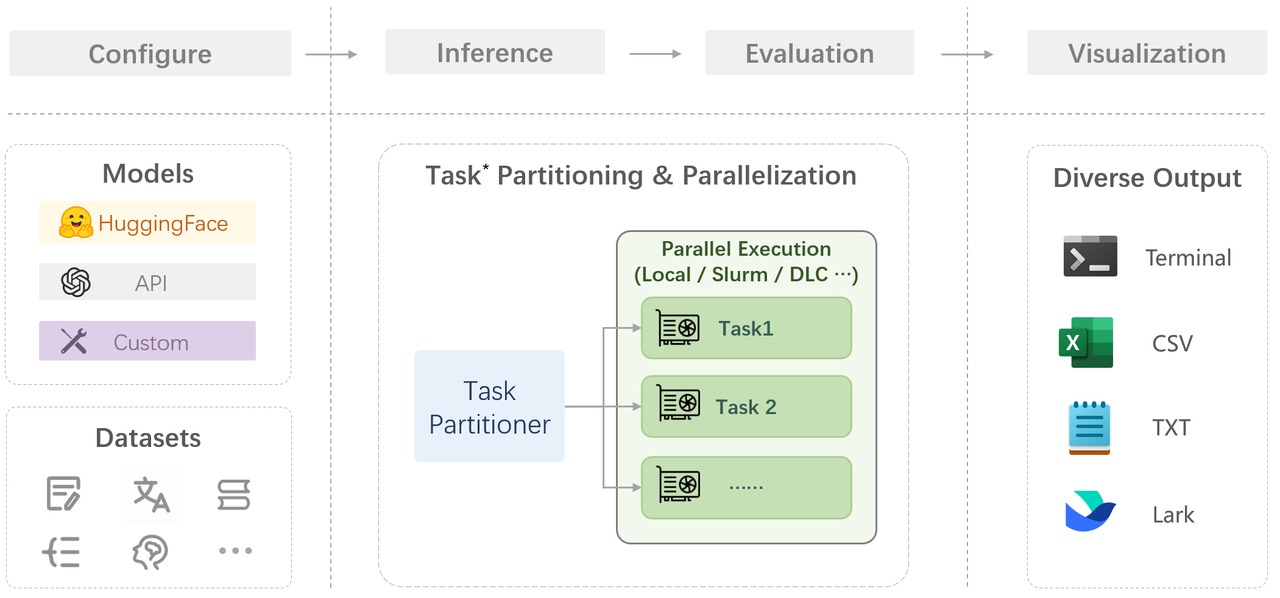
在 OpenCompass 中评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
配置:这是整个工作流的起点。您需要配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
推理与评估:在这个阶段,OpenCompass 将会开始对模型和数据集进行并行推理和评估。推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率,但请注意,如果计算资源有限,这种策略可能会使评测变得更慢。如果需要了解该问题及解决方案,可以参考 FAQ: 效率。
可视化:评估完成后,OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。你也可以激活飞书状态上报功能,此后可以在飞书客户端中及时获得评测状态报告。
对于其他模型,请参考 configs 目录 中提供的其他示例。
2. 3.1 评测C-Eval 选择题+math_gen计算题
开发机Cuda12.2-conda
#1、环境安装
conda create -n opencompass python=3.10
conda activate opencompass
# 注意:一定要先 cd /root
cd /root
git clone https://github.moeyy.xyz/https://github.com/open-compass/opencompass opencompas
cd opencompas
pip install -r requirements.txt
pip install -e .pip install sentencepiece
#升级datasets 避免不识别新的功能
pip install datasets==3.2.0
pip install modelscope#2、配置数据集、模型
export DATASET_SOURCE=ModelScope
#可用数据集来源:humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
cd /root/opencompass
wget https://ghfast.top/https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
#新建和编辑模型文件
touch opencompass/opencompass/configs/models/hf_internlm/hf_internlm3_8b_instruct.py#3、评测
#3.1直接评测
python run.py --datasets ceval_gen --models hf_internlm3_8b_instruct --debug
#3.2写配置脚本运行
cd /root/opencompass/opencompass/configs
touch eval_tutorial_demo.py
#编辑配置脚本文件
cd /root/opencompass
python run.py opencompass/configs/eval_tutorial_demo.py --debug
#3.3 评测math_gen计算题
python run.py --datasets math_gen --models hf_internlm3_8b_instruct --debug
#模型配置文件opencompass/opencompass/configs/models/hf_internlm/hf_internlm3_8b_instruct.py
from opencompass.models import HuggingFacewithChatTemplatemodels = [dict(type=HuggingFacewithChatTemplate,abbr='internlm3-8b-instruct-hf',path='/root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat',max_out_len=8192,batch_size=8,run_cfg=dict(num_gpus=1),)
]
#评测配置文件eval_tutorial_demo.py
from mmengine.config import read_basewith read_base():from .datasets.ceval.ceval_gen import ceval_datasetsfrom .models.hf_internlm.hf_internlm3_8b_instruct import models as hf_internlm3_8b_instructdatasets = ceval_datasets
models = hf_internlm3_8b_instruct