【深度学习】13. 图神经网络GCN,Spatial Approach, Spectral Approach
图神经网络
图结构 vs 网格结构
传统的深度学习(如 CNN 和 RNN)在处理网格结构数据(如图像、语音、文本)时表现良好,因为这些数据具有固定的空间结构。然而,真实世界中的很多数据并不遵循网格结构,而是以图的形式存在,例如:
- 社交网络
- 引文网络
- 通信网络
- 多智能体系统
- 分子结构
- 蛋白质相互作用网络
这些图结构数据的特点包括:
- 每个节点的邻居数量不固定
- 邻居之间没有隐含的顺序
- 卷积核大小不固定
- 权重无法按照固定顺序排列
因此,CNN 等传统架构无法直接应用于图结构数据中。
图卷积网络(GCN)简介
图卷积网络(GCN)旨在从图数据中提取特征。核心思想是:
- 将节点的邻居信息进行聚合
- 并通过权重参数进行变换
- 使得图中的节点能够学习到更好的表示
图的表示形式(Preliminaries)
基本图结构
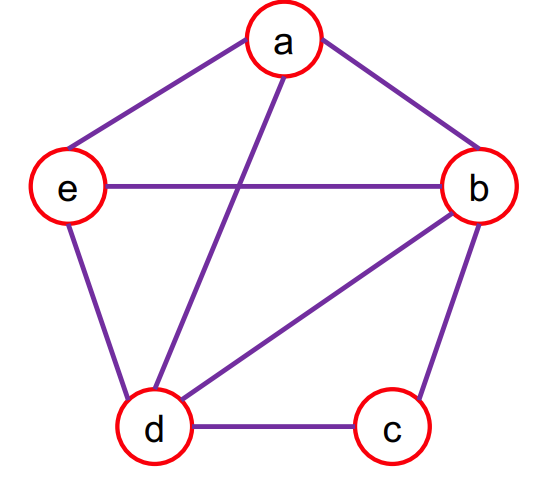
一个图通常记为 G = ( V , E ) G = (V, E) G=(V,E),其中:
- V = { v i ∣ i = 1 , … , N } V = \{v_i \mid i = 1, \dots, N\} V={vi∣i=1,…,N} 表示节点集合,共有 N N N 个节点
- E = { e i j ∣ v i 与 v j 相连 } E = \{e_{ij} \mid v_i \text{ 与 } v_j \text{ 相连} \} E={eij∣vi 与 vj 相连} 表示边集合
图的表示方式
- 边列表(Edge List):所有边组成的列表,如
( a , b ) , ( a , d ) , ( a , e ) , ( b , c ) , ( b , d ) , ( b , e ) , ( c , d ) , ( d , e ) (a,b), (a,d), (a,e), (b,c), (b,d), (b,e), (c,d), (d,e) (a,b),(a,d),(a,e),(b,c),(b,d),(b,e),(c,d),(d,e) - 邻接矩阵(Adjacency Matrix):一个 N × N N \times N N×N 的矩阵 A A A,其中 A i j = 1 A_{ij}=1 Aij=1 表示节点 v i v_i vi 与 v j v_j vj 有边连接,否则为 0。
- 具有自连接的邻接矩阵(Adjacency matrix with self connections):在2的基础上,对角线全为1,自己和自己都为1
- 带权邻接矩阵(Weighted Adjacency Matrix):矩阵中的每个元素是边的权重 w i j w_{ij} wij。
- 度矩阵(Degree Matrix):一个对角矩阵 D D D,其中 D i i D_{ii} Dii 表示节点 v i v_i vi 的度数(连接的边数)。
图的基本属性(Basic Properties)
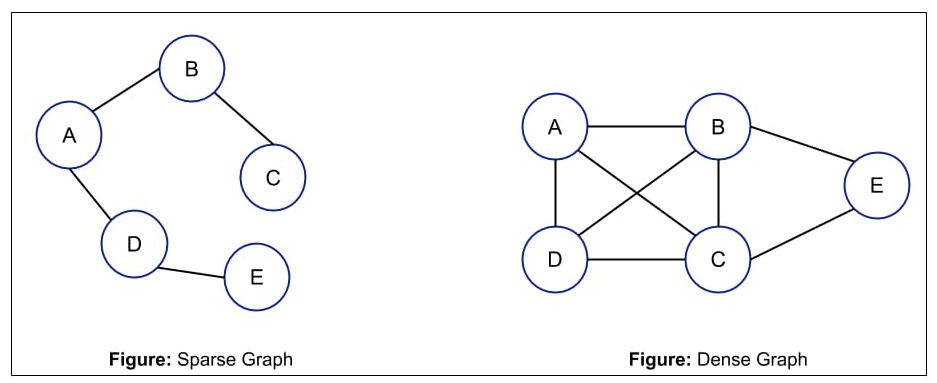
-
稠密图(Dense Graph):边的数量接近 O ( N 2 ) O(N^2) O(N2),例如社交网络中的名人图谱。
-
稀疏图(Sparse Graph):边的数量接近 O ( N ) O(N) O(N),大部分节点只有少量连接。
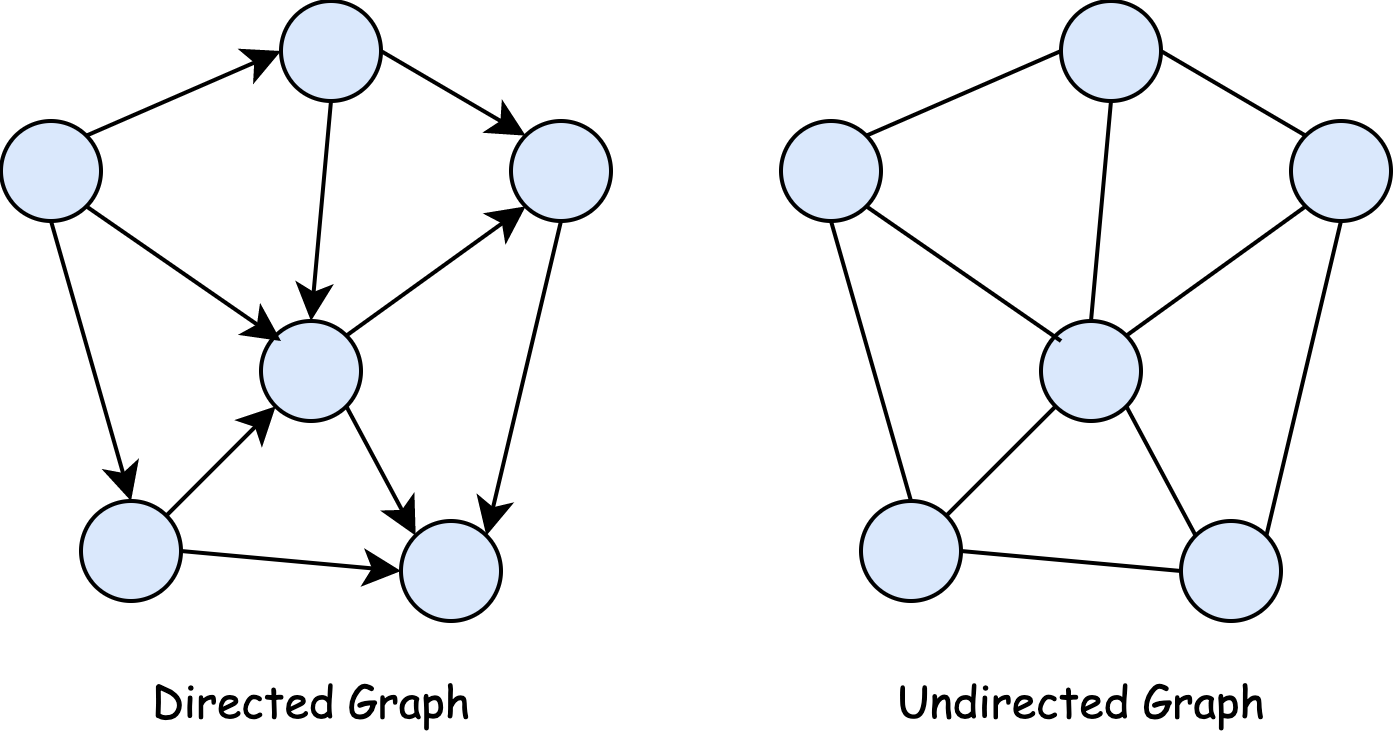
-
有向图 vs 无向图:
- 有向图中每条边有方向,邻接矩阵可能是不对称的。
- 无向图中边没有方向,邻接矩阵是对称的。
-
连通分量(Connected Components):
一个连通分量是一个子图,其中任意两个节点之间都有路径相连。
图神经网络中的常用表示
-
G = ( V , E ) G = (V, E) G=(V,E):图由节点集合 V V V 和边集合 E E E 构成。
-
V = { v i ∣ i = 1 , … , N } V = \{v_i \mid i = 1, \dots, N\} V={vi∣i=1,…,N}:节点集合,包含 ∣ V ∣ = N |V| = N ∣V∣=N 个节点。
-
E = { e i j ∣ v i 与 v j 有边相连 } E = \{e_{ij} \mid v_i \text{ 与 } v_j \text{ 有边相连} \} E={eij∣vi 与 vj 有边相连}:边集合,记录节点之间的连接关系。
-
X ∈ R N × d X \in \mathbb{R}^{N \times d} X∈RN×d:节点属性矩阵, d d d 为每个节点的特征维度。
-
邻接矩阵 A ∈ R N × N A \in \mathbb{R}^{N \times N} A∈RN×N,其中 A i j ∈ { 0 , 1 } A_{ij} \in \{0, 1\} Aij∈{0,1} 表示边 e i j e_{ij} eij 是否存在。
-
单位矩阵 I N I_N IN: N × N N \times N N×N 的单位矩阵,用于表示节点的自连接(self-connection)。
-
带自环的邻接矩阵 A ^ = A + I N \hat{A} = A + I_N A^=A+IN:在原始邻接矩阵基础上加入自环。
-
节点的度数(Degree):某个节点连接的边的数量。
-
度矩阵 D ∈ R N × N D \in \mathbb{R}^{N \times N} D∈RN×N:从邻接矩阵 A A A 计算得出,是对角矩阵,其对角线元素表示每个节点的度。
-
自环度矩阵 D ^ ∈ R N × N \hat{D} \in \mathbb{R}^{N \times N} D^∈RN×N:从带自环的邻接矩阵 A ^ \hat{A} A^ 计算得到。
CNN 中的卷积 vs GCN 中的卷积
CNN 中的像素更新(标准卷积)
对于一张图片的像素,使用 3 × 3 3 \times 3 3×3 卷积核:
h i ( l + 1 ) = σ ( W 1 ( l ) h 1 ( l ) + W 2 ( l ) h 2 ( l ) + ⋯ + W 9 ( l ) h 9 ( l ) ) h_i^{(l+1)} = \sigma(W_1^{(l)} h_1^{(l)} + W_2^{(l)} h_2^{(l)} + \cdots + W_9^{(l)} h_9^{(l)}) hi(l+1)=σ(W1(l)h1(l)+W2(l)h2(l)+⋯+W9(l)h9(l))
GCN 中的节点更新(图卷积)
使用公式:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中:
- A ~ \tilde{A} A~ 是加入自环的邻接矩阵
- D ~ \tilde{D} D~ 是其对应的度矩阵
- H ( l ) H^{(l)} H(l) 是第 l l l 层的节点表示
- W ( l ) W^{(l)} W(l) 是可训练参数矩阵
- σ \sigma σ 是非线性激活函数
该形式实现了特征归一化的图卷积操作。
图卷积操作的标准形式(Spatial Approach)
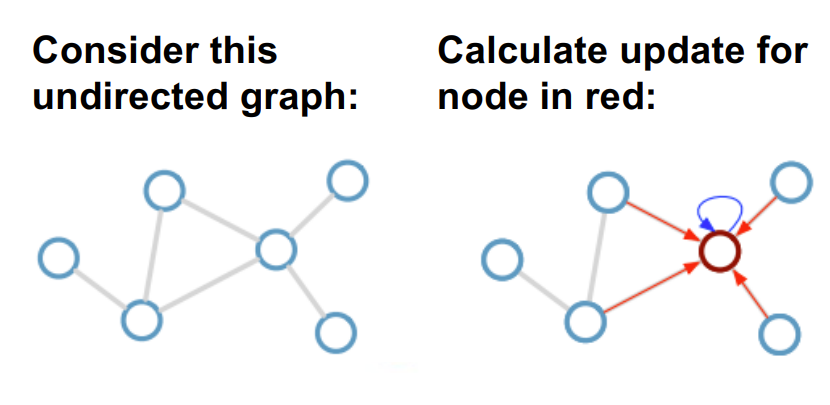
在空间方法(Spatial-based GCN)中,图卷积的更新规则如下:
h i ( l + 1 ) = σ ( h i ( l ) W 0 ( l ) + ∑ j ∈ N i 1 c i j h j ( l ) W 1 ( l ) ) h_i^{(l+1)} = \sigma \left( h_i^{(l)} W_0^{(l)} + \sum_{j \in \mathcal{N}_i} \frac{1}{c_{ij}} h_j^{(l)} W_1^{(l)} \right) hi(l+1)=σ hi(l)W0(l)+j∈Ni∑cij1hj(l)W1(l)
其中:
- N i \mathcal{N}_i Ni 表示节点 i i i 的邻居集合
- W 0 ( l ) W_0^{(l)} W0(l) 和 W 1 ( l ) W_1^{(l)} W1(l) 为权重矩阵
- c i j c_{ij} cij 是归一化常数(可设为固定值或可训练)
- σ \sigma σ 是非线性激活函数(如 ReLU)
优点:
- 权重共享,空间结构不变
- 排列的不变性
- 对节点顺序不敏感(Permutation invariant)
- 线性复杂度O(E),适用于大规模稀疏图
缺点:
- 仅间接支持边缘特征
- 多层堆叠需要残差结构以避免过平滑(over-smoothing)
- 需要闸门机制/深度残余连接(如果nodes太多,一半需要去掉一些信息)
Kipf & Welling 的 GCN 模型(2017)
Kipf & Welling 提出的图卷积网络是一种半监督学习方法,其更新公式为:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma \left( \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)} \right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中:
- A ~ = A + I \tilde{A} = A + I A~=A+I:加入自环的邻接矩阵
- D ~ \tilde{D} D~ 是 A ~ \tilde{A} A~ 的度矩阵
- W ( l ) W^{(l)} W(l) 是第 l l l 层的权重矩阵
- σ \sigma σ 是非线性激活函数
网络结构如下:
- 输入:节点特征矩阵 X X X
- 第一层图卷积: H ( 1 ) = ReLU ( A ^ X W ( 0 ) ) H^{(1)} = \text{ReLU}(\hat{A} X W^{(0)}) H(1)=ReLU(A^XW(0))
- 第二层输出: Z = softmax ( A ^ H ( 1 ) W ( 1 ) ) Z = \text{softmax}(\hat{A} H^{(1)} W^{(1)}) Z=softmax(A^H(1)W(1))
该模型被广泛用于半监督节点分类任务。
图卷积更新公式的空间方法详解
图卷积的一般更新形式如下:
h i ( l + 1 ) = σ ( h i ( l ) W 0 + ∑ j ∈ N i 1 c i j h j ( l ) W 1 ) h_i^{(l+1)} = \sigma\left(h_i^{(l)} W_0 + \sum_{j \in \mathcal{N}_i} \frac{1}{c_{ij}} h_j^{(l)} W_1\right) hi(l+1)=σ hi(l)W0+j∈Ni∑cij1hj(l)W1
其中:
- N i \mathcal{N}_i Ni 表示节点 i i i 的邻居集合;
- W 0 W_0 W0 是自身的权重矩阵;
- W 1 W_1 W1 是所有邻居共享的权重矩阵;
- c i j c_{ij} cij 是归一化因子(如邻居数、可学习权重);
- σ \sigma σ 是非线性激活函数(如 ReLU)。
该空间方法强调局部邻居信息聚合,具有如下性质:
- 权重共享,适应不同图结构;
- 对邻居节点的顺序不敏感(Permutation Invariant);
- 时间复杂度为 O ( E ) O(E) O(E),适用于大规模图。
- Applicable both in transductive(access to test set) and inductive(sperate test set)
GCN 计算示例
假设节点为 a , b , c , d , e a, b, c, d, e a,b,c,d,e,图的邻接矩阵 A A A 为:
A = [ 0 1 0 1 1 1 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 1 0 1 0 ] A = \begin{bmatrix} 0 & 1 & 0 & 1 & 1 \\ 1 & 0 & 1 & 1 & 1 \\ 0 & 1 & 0 & 1 & 0 \\ 1 & 1 & 1 & 0 & 1 \\ 1 & 1 & 0 & 1 & 0 \end{bmatrix} A= 0101110111010101110111010
加入自环后得到:
A ~ = A + I = [ 1 1 0 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 1 1 1 0 1 1 ] \tilde{A} = A + I = \begin{bmatrix} 1 & 1 & 0 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 \\ 0 & 1 & 1 & 1 & 0 \\ 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 0 & 1 & 1 \end{bmatrix} A~=A+I= 1101111111011101111111011
该过程表示:每个节点与其邻居(含自身)对应特征值相加,未做归一化。
H ( l + 1 ) = σ ( A ~ H l W l ) H^{(l+1)} = \sigma(\tilde{A}H^lW^l) H(l+1)=σ(A~HlWl)
GCN 的特征归一化
为避免特征总量随度数增长,需对 A ~ \tilde{A} A~ 进行对称归一化:
A ^ = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} A^=D~−1/2A~D~−1/2
H ( l + 1 ) = σ ( D ~ − 1 A ~ H l W l ) H^{(l+1)} = \sigma( \tilde{D}^{-1}\tilde{A}H^lW^l) H(l+1)=σ(D~−1A~HlWl)
其中,度矩阵 D ~ \tilde{D} D~ 为:
D ~ = [ 4 0 0 0 0 0 5 0 0 0 0 0 3 0 0 0 0 0 5 0 0 0 0 0 4 ] \tilde{D} = \begin{bmatrix} 4 & 0 & 0 & 0 & 0 \\ 0 & 5 & 0 & 0 & 0 \\ 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 5 & 0 \\ 0 & 0 & 0 & 0 & 4 \end{bmatrix} D~= 4000005000003000005000004
D − 1 A ^ = [ 1 4 1 4 0 1 4 1 4 1 5 1 5 1 5 1 5 1 5 0 1 3 1 3 1 3 0 1 5 1 5 1 5 1 5 1 5 1 4 1 4 0 1 4 1 4 ] D^{-1} \hat{A} = \begin{bmatrix} \frac{1}{4} & \frac{1}{4} & 0 & \frac{1}{4} & \frac{1}{4} \\ \frac{1}{5} & \frac{1}{5} & \frac{1}{5} & \frac{1}{5} & \frac{1}{5} \\ 0 & \frac{1}{3} & \frac{1}{3} & \frac{1}{3} & 0 \\ \frac{1}{5} & \frac{1}{5} & \frac{1}{5} & \frac{1}{5} & \frac{1}{5} \\ \frac{1}{4} & \frac{1}{4} & 0 & \frac{1}{4} & \frac{1}{4} \\ \end{bmatrix} D−1A^= 4151051414151315141051315104151315141415105141
这样更新会有个问题,ab ≠ ba,不是对称矩阵,所以将D分成2个。
GCN 标准更新公式
标准 GCN 更新层表示如下:
H ( l + 1 ) = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma\left( \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} W^{(l)} \right) H(l+1)=σ(D~−1/2A~D~−1/2H(l)W(l))
该式通过对邻接矩阵的对称归一化:
- 保持了特征值分布的稳定;
- 实现了特征传播不随度数膨胀;
- 简洁且高效,成为主流 GCN 实现方式。
该矩阵乘法等价于三步:
- H ( l ) H^{(l)} H(l) 通过权重矩阵 W ( l ) W^{(l)} W(l) 投影;
- 使用归一化矩阵 A ^ \hat{A} A^ 聚合邻居;
- 应用非线性激活函数 σ \sigma σ。
GCN 中对称归一化公式的逐步推导与解释
我们从标准的图卷积操作出发:
H ( l + 1 ) = D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) H^{(l+1)} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} H(l+1)=D~−1/2A~D~−1/2H(l)
关注第 i i i 个节点的输出 H i ( l + 1 ) H_i^{(l+1)} Hi(l+1),即第 i i i 行的表示:
H i ( l + 1 ) = ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) ) i H_i^{(l+1)} = \left( \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} \right)_i Hi(l+1)=(D~−1/2A~D~−1/2H(l))i
将矩阵乘法拆解成向量形式:
- 首先将左侧乘法与右侧拆分:
= ( D ~ − 1 / 2 A ~ ) i ⋅ D ~ − 1 / 2 H = \left( \tilde{D}^{-1/2} \tilde{A} \right)_i \cdot \tilde{D}^{-1/2} H =(D~−1/2A~)i⋅D~−1/2H
- 用求和展开:
= ( ∑ k D ~ i k − 1 / 2 A ~ k j ) D ~ − 1 / 2 H = \left( \sum_k \tilde{D}_{ik}^{-1/2} \tilde{A}_{kj} \right) \tilde{D}^{-1/2} H =(k∑D~ik−1/2A~kj)D~−1/2H
- 注意 D ~ \tilde{D} D~ 是对角矩阵,仅对角线非零,即 D ~ i k − 1 / 2 = 0 \tilde{D}_{ik}^{-1/2} = 0 D~ik−1/2=0 当 i ≠ k i \ne k i=k:
= D ~ i i − 1 / 2 ∑ j A ~ i j D ~ j j − 1 / 2 H j = \tilde{D}_{ii}^{-1/2} \sum_j \tilde{A}_{ij} \tilde{D}_{jj}^{-1/2} H_j =D~ii−1/2j∑A~ijD~jj−1/2Hj
将所有常数合并成一项,得到最终形式:
H i ( l + 1 ) = ∑ j 1 D ~ i i D ~ j j A ~ i j H j H_i^{(l+1)} = \sum_j \frac{1}{\sqrt{\tilde{D}_{ii} \tilde{D}_{jj}}} \tilde{A}_{ij} H_j Hi(l+1)=j∑D~iiD~jj1A~ijHj
每个邻居 j j j 对 H i ( l + 1 ) H_i^{(l+1)} Hi(l+1) 的影响
该公式表示:
节点 i i i 的新表示 H i ( l + 1 ) H_i^{(l+1)} Hi(l+1) 是其所有邻居 j j j 的表示 H j H_j Hj 的加权平均。
权重部分为:
w i j = 1 D ~ i i D ~ j j w_{ij} = \frac{1}{\sqrt{\tilde{D}_{ii} \tilde{D}_{jj}}} wij=D~iiD~jj1
- A ~ i j = 1 \tilde{A}_{ij} = 1 A~ij=1 表示 j j j 是 i i i 的邻居(包括自环)
- H j H_j Hj 是邻居 j j j 的特征表示
- D ~ i i \tilde{D}_{ii} D~ii 和 D ~ j j \tilde{D}_{jj} D~jj 是节点 i i i 和 j j j 的度(含自环)
j j j 如何对 i i i 有更大的影响?
邻居 j j j 对节点 i i i 的影响取决于 这个分母:
D ~ i i D ~ j j \sqrt{\tilde{D}_{ii} \tilde{D}_{jj}} D~iiD~jj
因此:
- 若 j j j 的度数 D ~ j j \tilde{D}_{jj} D~jj 越小,即 j j j 越“稀疏”或不太活跃,它的特征 H j H_j Hj 在这个加权和中占比越大;
- 若 j j j 是一个“中心节点”连接了很多邻居(度很大),则 D ~ j j \tilde{D}_{jj} D~jj 大,导致它对 i i i 的影响反而被 弱化。
示例:
- 若 i i i 和 j j j 都只有 2 个连接(含自环),则权重为 1 2 ⋅ 2 = 0.5 \frac{1}{\sqrt{2 \cdot 2}} = 0.5 2⋅21=0.5
- 若 j j j 是高阶节点, D ~ j j = 10 \tilde{D}_{jj} = 10 D~jj=10,则权重是 1 2 ⋅ 10 ≈ 0.22 \frac{1}{\sqrt{2 \cdot 10}} \approx 0.22 2⋅101≈0.22
- 说明:低度的邻居在信息传播中影响力更大,高度节点被稀释
GCN 模型结构与任务
Kipf & Welling 的 GCN 被广泛用于半监督分类任务,模型结构如下:
-
输入:特征矩阵 X ∈ R N × d X \in \mathbb{R}^{N \times d} X∈RN×d
-
第一层:
H ( 1 ) = ReLU ( A ^ X W ( 0 ) ) H^{(1)} = \text{ReLU}(\hat{A} X W^{(0)}) H(1)=ReLU(A^XW(0)) -
输出层:
Z = softmax ( A ^ H ( 1 ) W ( 1 ) ) Z = \text{softmax}(\hat{A} H^{(1)} W^{(1)}) Z=softmax(A^H(1)W(1))
常见任务包括:
-
节点分类(Node Classification):
y ^ i = softmax ( z i ) \hat{y}_i = \text{softmax}(z_i) y^i=softmax(zi) -
边预测(Link Prediction):
p ( A i j ) = σ ( z i T z j ) p(A_{ij}) = \sigma(z_i^T z_j) p(Aij)=σ(ziTzj) -
图级分类(Graph Classification):
使用聚合操作如全局平均池化后接多层感知机(MLP)。
y ^ i = softmax ( ∑ n z n ) \hat{y}_i = \text{softmax}(\sum_nz_n) y^i=softmax(n∑zn)
GCN 模型仅需少量标注节点即可训练整图,是图神经网络的基础模型之一。
谱方法(Spectral Approach)下的图卷积网络
谱方法通过图拉普拉斯矩阵对图信号进行傅里叶变换,并在频域上实现卷积操作。该方法理论上完整严谨,是最早期图卷积的基础。
图拉普拉斯矩阵的定义
-
非归一化图拉普拉斯矩阵:
L = D − A L = D - A L=D−A
-
归一化图拉普拉斯矩阵:
L ′ = I − D − 1 2 A D − 1 2 L' = I - D^{-\frac{1}{2}} A D^{-\frac{1}{2}} L′=I−D−21AD−21
其中 A A A 是邻接矩阵, D D D 是度矩阵, I I I 是单位矩阵。
卷积定理与频域操作
在经典信号处理中,有如下结论:
在合适条件下,两个信号卷积的傅里叶(或拉普拉斯)变换等于它们各自傅里叶变换的逐点乘积。
对于图信号 f f f 和滤波器 h h h,有:
f ∗ h = F − 1 [ F ( f ) ⋅ F ( h ) ] f * h = \mathcal{F}^{-1} \left[ \mathcal{F}(f) \cdot \mathcal{F}(h) \right] f∗h=F−1[F(f)⋅F(h)]
一维傅里叶变换的本质
经典傅里叶变换是将信号 f f f 展开在复指数函数基底 e i ω x e^{i\omega x} eiωx 上。这些复指数正是一维拉普拉斯算子的特征函数,满足:
L u = λ u L u = \lambda u Lu=λu
一维拉普拉斯算子与经典傅里叶变换的关系
经典傅里叶变换定义为:
f ^ ( ξ ) = ⟨ f , e 2 π i ξ t ⟩ = ∫ R f ( t ) e 2 π i ξ t d t \hat{f}(\xi) = \langle f, e^{2\pi i \xi t} \rangle = \int_{\mathbb{R}} f(t) e^{2\pi i \xi t} \, dt f^(ξ)=⟨f,e2πiξt⟩=∫Rf(t)e2πiξtdt
即将信号 f f f 展开为复指数函数 e 2 π i ξ t e^{2\pi i \xi t} e2πiξt 的线性组合。
这些复指数函数 e 2 π i ξ t e^{2\pi i \xi t} e2πiξt 是一维拉普拉斯算子 Δ \Delta Δ 的特征函数。
我们来看具体推导:
− Δ ( e 2 π i ξ t ) = − ∂ 2 ∂ t 2 e 2 π i ξ t = ( 2 π ξ ) 2 e 2 π i ξ t -\Delta\left(e^{2\pi i \xi t}\right) = -\frac{\partial^2}{\partial t^2} e^{2\pi i \xi t} = (2\pi \xi)^2 e^{2\pi i \xi t} −Δ(e2πiξt)=−∂t2∂2e2πiξt=(2πξ)2e2πiξt
说明 e 2 π i ξ t e^{2\pi i \xi t} e2πiξt 是 Δ \Delta Δ 的特征函数,特征值为 ( 2 π ξ ) 2 (2\pi \xi)^2 (2πξ)2。
这一结论可抽象表达为:
L u = λ u Lu = \lambda u Lu=λu
其中:
- L L L 是拉普拉斯算子(在图上也记为 L L L)
- u u u 是特征函数(在傅里叶中为 e 2 π i ξ t e^{2\pi i \xi t} e2πiξt)
- λ \lambda λ 是对应特征值
这为图谱方法中“频域展开”提供了数学基础:傅里叶基底是拉普拉斯算子的本征函数。
图傅里叶变换与拉普拉斯特征分解
令 L = U Λ U T L = U \Lambda U^T L=UΛUT 为图拉普拉斯矩阵的特征值分解( U U U 为特征向量矩阵, Λ \Lambda Λ 为对角特征值矩阵),则有:
-
图傅里叶变换:
f ^ = U T f \hat{f} = U^T f f^=UTf
h ^ = U T h \hat{h} = U^T h h^=UTh
-
图傅里叶逆变换:
f = U f ^ f = U \hat{f} f=Uf^
图上的卷积操作
图信号与滤波器的卷积在频域中表示为:
f ∗ h = U ( f ^ ⊙ h ^ ) = U ( U T f ⊙ U T h ) f * h = U ( \hat{f} \odot \hat{h} ) = U ( U^T f \odot U^T h ) f∗h=U(f^⊙h^)=U(UTf⊙UTh)
其中 ⊙ \odot ⊙ 表示逐元素乘积。
第一版谱图卷积(Spectral Network)
Bruna 等人提出的谱卷积形式为:
y = σ ( U g θ ( Λ ) U T x ) y = \sigma( U g_\theta(\Lambda) U^T x ) y=σ(Ugθ(Λ)UTx)
其中 g θ ( Λ ) g_\theta(\Lambda) gθ(Λ) 是学习到的频域滤波器:
g θ ( Λ ) = [ θ 0 0 ⋯ 0 0 ⋱ ⋮ ⋮ ⋱ 0 0 ⋯ 0 θ n ] g_\theta(\Lambda) = \begin{bmatrix} \theta_0 & 0 & \cdots & 0 \\ 0 & \ddots & & \vdots \\ \vdots & & \ddots & 0 \\ 0 & \cdots & 0 & \theta_n \end{bmatrix} gθ(Λ)= θ00⋮00⋱⋯⋯⋱00⋮0θn
该方法缺点:
- 无空间局部性;
- 参数数量与节点数相同;
- 每次前向传播需特征分解,开销大。
第二版谱图卷积:局部化滤波器
为了缓解参数过多的问题,提出使用多项式表示滤波器:
g α ( Λ ) = ∑ k = 0 K α k Λ k g_\alpha(\Lambda) = \sum_{k=0}^{K} \alpha_k \Lambda^k gα(Λ)=k=0∑KαkΛk
对应卷积变为:
y = σ ( U g α ( Λ ) U T x ) = σ ( ∑ k = 0 K α k L k x ) y = \sigma( U g_\alpha(\Lambda) U^T x ) = \sigma\left( \sum_{k=0}^K \alpha_k L^k x \right) y=σ(Ugα(Λ)UTx)=σ(k=0∑KαkLkx)
优点:
- 不需特征分解;
- 有空间局部性( k k k 阶表示 k k k 距离内邻居);
- 参数数为 K K K,小于 n n n。
第三版谱图卷积:Chebyshev 多项式展开
用 Chebyshev 多项式对谱滤波器逼近,定义为:
T 0 ( x ) = 1 , T 1 ( x ) = x , T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) T_0(x) = 1,\quad T_1(x) = x,\quad T_k(x) = 2x T_{k-1}(x) - T_{k-2}(x) T0(x)=1,T1(x)=x,Tk(x)=2xTk−1(x)−Tk−2(x)
令:
Λ ~ = 2 Λ λ max − I \tilde{\Lambda} = \frac{2\Lambda}{\lambda_{\max}} - I Λ~=λmax2Λ−I
则滤波器近似为:
g θ ( Λ ~ ) ≈ ∑ k = 0 K θ k T k ( Λ ~ ) g_\theta(\tilde{\Lambda}) \approx \sum_{k=0}^K \theta_k T_k(\tilde{\Lambda}) gθ(Λ~)≈k=0∑KθkTk(Λ~)
因此卷积可写为:
y = σ ( ∑ k = 0 K θ k T k ( L ~ ) x ) y = \sigma\left( \sum_{k=0}^K \theta_k T_k(\tilde{L}) x \right) y=σ(k=0∑KθkTk(L~)x)
其中 L ~ = 2 L λ max − I \tilde{L} = \frac{2L}{\lambda_{\max}} - I L~=λmax2L−I
该方法是 Defferrard 等人提出,具有良好的数值稳定性与本地性。
GCN 的最终简化形式(Kipf & Welling)
Kipf 和 Welling 在 2017 年提出了图卷积网络(GCN)的简化谱方法,通过对 Chebyshev 多项式滤波器进行一阶近似,得到了一种高效的图卷积实现。
首先,从 Chebyshev 展开退化为一阶近似,即取 K = 1 K = 1 K=1,并使用如下形式:
g θ ∗ x ≈ θ ( I + D − 1 2 A D − 1 2 ) x g_\theta * x \approx \theta \left( I + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \right) x gθ∗x≈θ(I+D−21AD−21)x
为了提升模型表达能力并确保节点信息自保留,加入自环:
A ~ = A + I \tilde{A} = A + I A~=A+I
计算新的度矩阵:
D ~ i i = ∑ j A ~ i j \tilde{D}_{ii} = \sum_j \tilde{A}_{ij} D~ii=j∑A~ij
最终得到了标准的 GCN 卷积层表达形式:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma\left( \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)} \right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中:
- A ~ \tilde{A} A~ 是加入自环的邻接矩阵;
- D ~ \tilde{D} D~ 是 A ~ \tilde{A} A~ 对应的度矩阵;
- H ( l ) H^{(l)} H(l) 是第 l l l 层节点特征矩阵;
- W ( l ) W^{(l)} W(l) 是第 l l l 层可学习权重;
- σ \sigma σ 是非线性激活函数,如 ReLU。
这一形式不再依赖拉普拉斯的特征分解,计算效率高,可在整个图上批处理所有节点,是现代 GCN 应用中的标准实现。