SQL的查询优化
1. 查询优化器
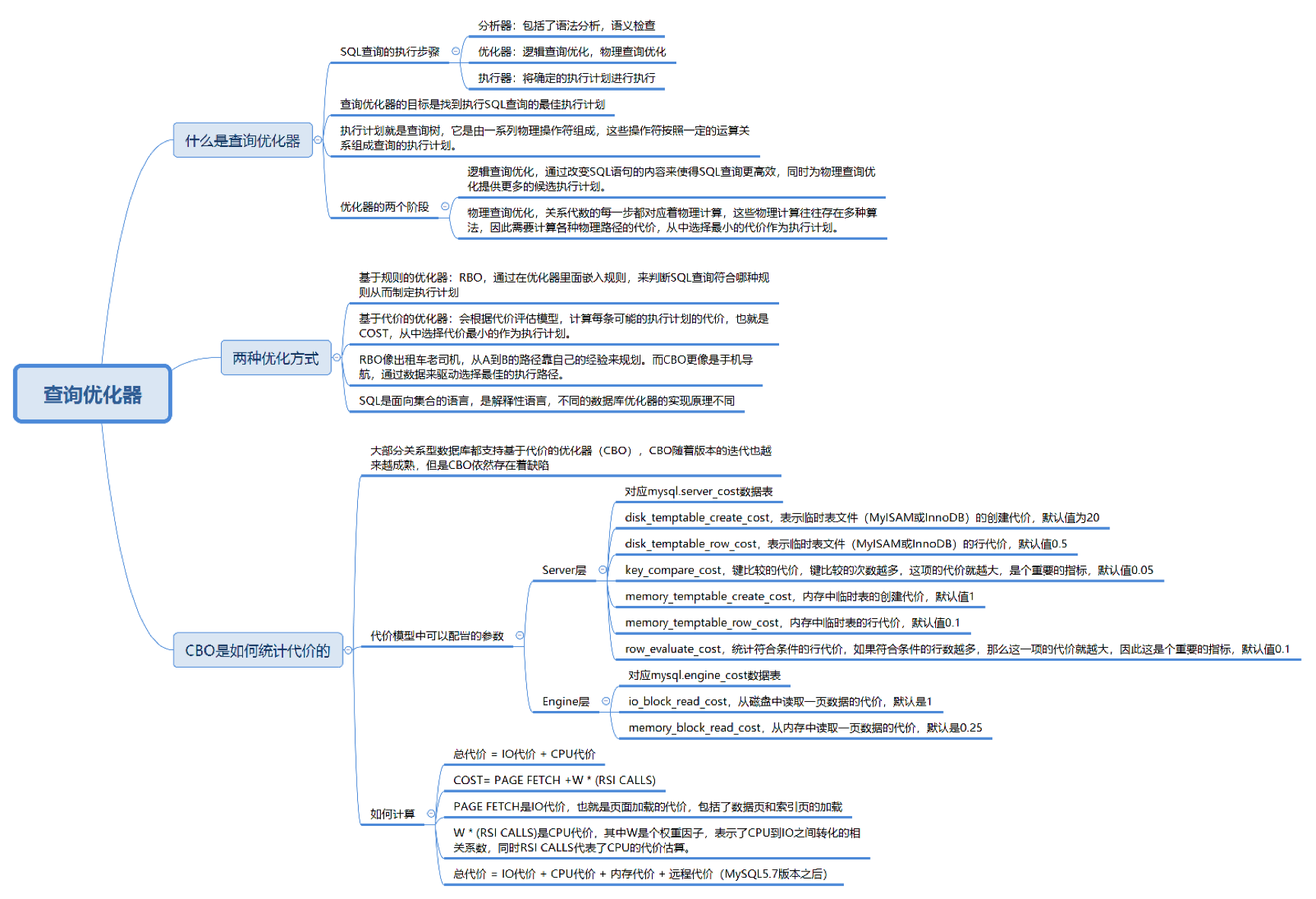
1.1. SQL语句执行需要经历的环节
- 解析阶段:语法分析和语义检查,确保语句正确;
- 优化阶段:通过优化器生成查询计划;
- 执行阶段:由执行器根据查询计划实际执行操作。

1.2. 查询优化器
查询优化器的概念:
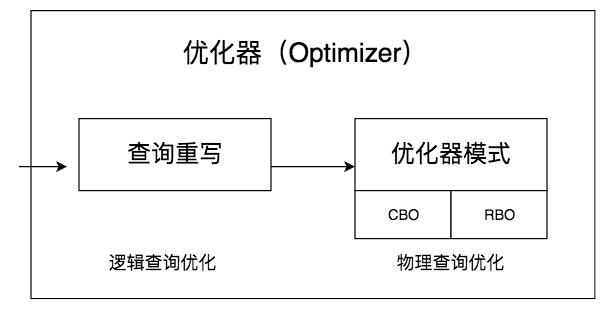
查询优化器的作用是为 SQL 查询生成最优的执行计划。其内部通常分为两个阶段:
1. 逻辑优化:
- 基于关系代数进行等价重写(如谓词下推、连接重写、视图展开);
- 目的是生成多个逻辑上等价但执行效率不同的候选计划。
2. 物理优化:
- 为逻辑计划选择具体的物理操作(如全表扫描 vs 索引扫描,嵌套循环连接 vs 哈希连接);
- 通过代价估算模型选出代价最小的执行路径。
查询优化器的两种优化方式:
- 第一种是基于规则的优化器(RBO,Rule-Based Optimizer),规则就是人们以往的经验,或者是采用已经被证明是有效的方式。通过在优化器里面嵌入规则,来判断 SQL 查询符合哪种规则,就按照相应的规则来制定执行计划,同时采用启发式规则去掉明显不好的存取路径。
- 第二种是基于代价的优化器(CBO,Cost-Based Optimizer),这里会根据代价评估模型,计算每条可能的执行计划的代价,也就是 COST,从中选择代价最小的作为执行计划。相比于 RBO 来说,CBO 对数据更敏感,因为它会利用数据表中的统计信息来做判断,针对不同的数据表,查询得到的执行计划可能是不同的,因此制定出来的执行计划也更符合数据表的实际情况。
RBO 的方式更像是一个出租车老司机,凭借自己的经验来选择从 A 到 B 的路径。而 CBO 更像是手机导航,通过数据驱动,来选择最佳的执行路径。
1.3. CBO 的代价估算机制
1. 代价模型
能调整的代价模型的参数:
MySQL 中的COST Model就是优化器用来统计各种步骤的代价模型,MySQL 会引入两张数据表,里面规定了各种步骤预估的代价(Cost Value) ,我们可以从mysql.server_cost和mysql.engine_cost这两张表中获得这些步骤的代价:
SQL > SELECT * FROM mysql.server_cost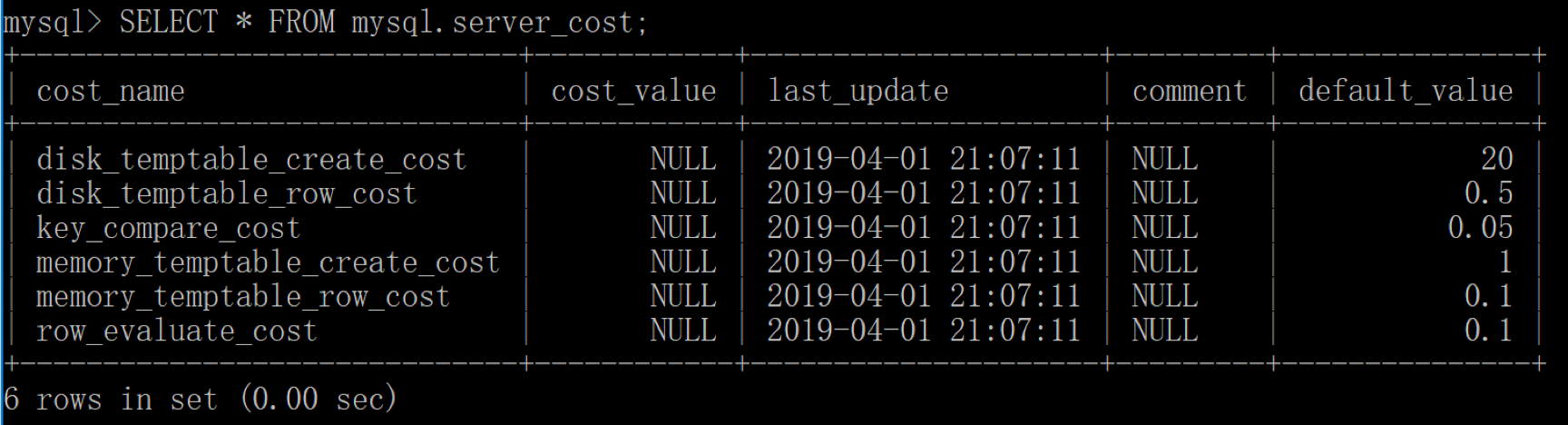
server_cost 数据表是在 server 层统计的代价,具体的参数含义如下:
disk_temptable_create_cost,表示临时表文件(MyISAM 或 InnoDB)的创建代价,默认值为 20。disk_temptable_row_cost,表示临时表文件(MyISAM 或 InnoDB)的行代价,默认值 0.5。key_compare_cost,表示键比较的代价。键比较的次数越多,这项的代价就越大,这是一个重要的指标,默认值 0.05。memory_temptable_create_cost,表示内存中临时表的创建代价,默认值 1。memory_temptable_row_cost,表示内存中临时表的行代价,默认值 0.1。row_evaluate_cost,统计符合条件的行代价,如果符合条件的行数越多,那么这一项的代价就越大,因此这是个重要的指标,默认值 0.1。
在存储引擎层都包括了哪些代价:
SQL > SELECT * FROM mysql.engine_cost
engine_cost主要统计了页加载的代价,一个页的加载根据页所在位置的不同,读取的位置也不同,可以从磁盘 I/O 中获取,也可以从内存中读取。因此在engine_cost数据表中对这两个读取的代价进行了定义:
io_block_read_cost,从磁盘中读取一页数据的代价,默认是 1。memory_block_read_cost,从内存中读取一页数据的代价,默认是 0.25。
通过SQL语句调整以上参数:
MySQL 将这些代价参数以数据表的形式呈现给了我们,我们就可以根据实际情况去修改这些参数。因为随着硬件的提升,各种硬件的性能对比也可能发生变化,比如针对普通硬盘的情况,可以考虑适当增加io_block_read_cost的数值,这样就代表从磁盘上读取一页数据的成本变高了。当我们执行全表扫描的时候,相比于范围查询,成本也会增加很多。
将io_block_read_cost参数设置为 2.0,使用下面这条命令:
UPDATE mysql.engine_costSET cost_value = 2.0WHERE cost_name = 'io_block_read_cost';
FLUSH OPTIMIZER_COSTS;
我们对mysql.engine_cost中的io_block_read_cost参数进行了修改,然后使用FLUSH OPTIMIZER_COSTS更新内存,然后再查看engine_cost数据表,发现io_block_read_cost参数中的cost_value已经调整为 2.0。
专门针对某个存储引擎,比如 InnoDB 存储引擎设置io_block_read_cost,设置为 2:
INSERT INTO mysql.engine_cost(engine_name, device_type, cost_name, cost_value, last_update, comment)VALUES ('InnoDB', 0, 'io_block_read_cost', 2,CURRENT_TIMESTAMP, 'Using a slower disk for InnoDB');
FLUSH OPTIMIZER_COSTS;再查看一下mysql.engine_cost数据表:

2. 总代价计算方式
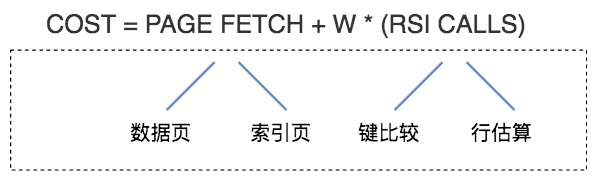
可以简单地认为,总的执行代价等于 I/O 代价 +CPU 代价。在这里 PAGE FETCH 就是 I/O 代价,也就是页面加载的代价,包括数据页和索引页加载的代价。W*(RSI CALLS) 就是 CPU 代价。W 在这里是个权重因子,表示了 CPU 到 I/O 之间转化的相关系数,RSI CALLS 代表了 CPU 的代价估算,包括了键比较(compare key)以及行估算(row evaluating)的代价。
总代价 = I/O 代价 + CPU 代价 [+ 内存代价 + 远程访问代价]- I/O 成本:页的加载,如索引页和数据页;
- CPU 成本:如行过滤、键比较等操作;
- W × RSI Calls:W 是 CPU/I/O 的权重因子,RSI Calls 是逻辑计算量。
2. 使用性能分析工具定位SQL执行慢的原因
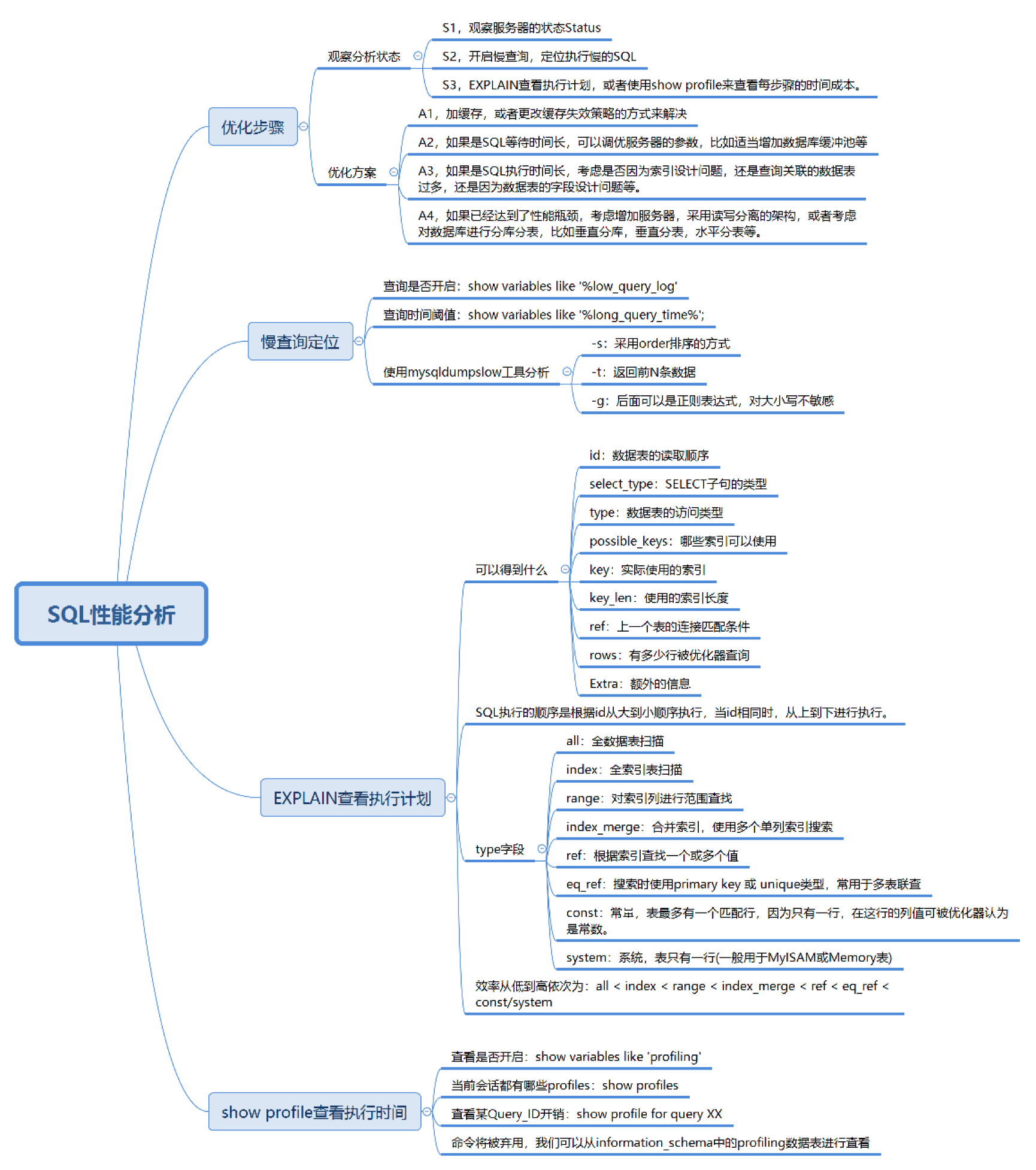
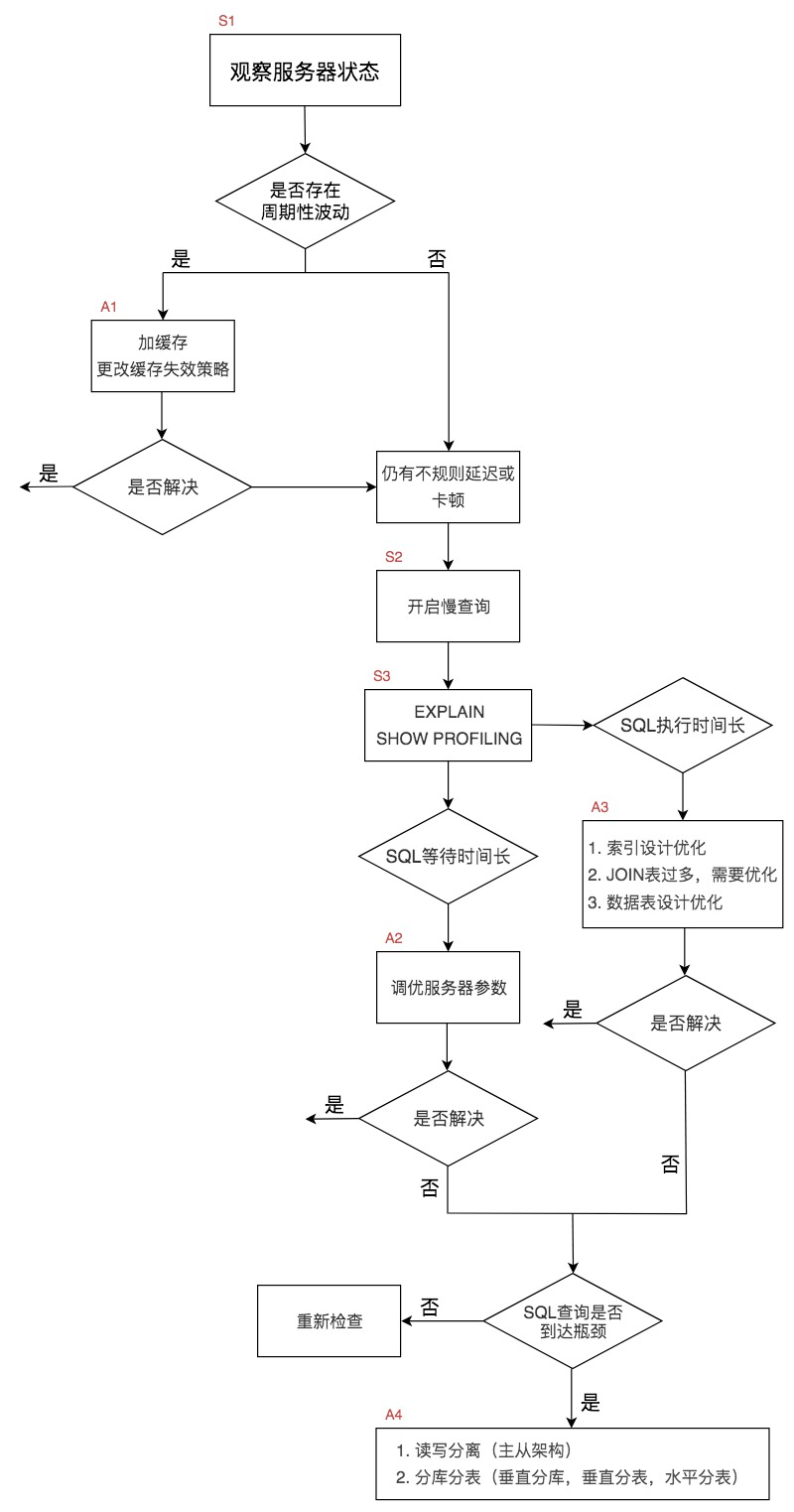
2.1. 数据库服务器的优化步骤
整个流程划分成了观察(Show status)和行动(Action)两个部分。字母 S 的部分代表观察(会使用相应的分析工具),字母 A 代表的部分是行动(对应分析可以采取的行动)。
2.2. 三种性能分析工具
| 工具 | 功能 |
| 慢查询日志 | 定位慢 SQL 语句 |
| EXPLAIN | 分析执行计划与索引使用情况 |
| SHOW PROFILE | 分析执行过程中各步骤的时间开销 |
1. 慢查询日志分析(Slow Query Log)
1. 查看是否启用慢查询日志:
SHOW VARIABLES LIKE '%slow_query_log%';2. 启用慢查询日志:
SET GLOBAL slow_query_log = 'ON';- 查看/设置慢查询时间阈值:
SHOW VARIABLES LIKE '%long_query_time%';
SET GLOBAL long_query_time = 3; -- 单位为秒3. 使用 mysqldumpslow 工具分析慢查询日志:
perl mysqldumpslow.pl -s t -t 2 /路径/slow.log| 参数 | 含义 |
|
| 排序方式(t:时间,c:次数,r:返回行数) |
|
| 显示前几条 |
|
| 正则匹配(不区分大小写) |
4. 使用 EXPLAIN 分析 SQL 执行计划
示例:
EXPLAIN SELECT ... FROM table JOIN table2 ON ...常见字段说明:
| 字段 | 含义 |
|
| 查询执行顺序,越大越早执行 |
|
| 查询类型(SIMPLE、PRIMARY、SUBQUERY) |
|
| 正在访问的表 |
|
| 访问方式(越靠前越好) |
|
| 实际使用的索引 |
|
| 预估扫描行数 |
|
| 额外信息,如是否使用索引覆盖、临时表、排序等 |
数据表的访问类型:

- 效率从低到高依次为 all < index < range < index_merge < ref < eq_ref < const/system。
2. 使用 SHOW PROFILE 分析查询时间
1. 开启 profiling:
SET profiling = 1;2. 执行要分析的 SQL:
SELECT * FROM ...;3. 查看分析结果:
SHOW PROFILES;
SHOW PROFILE FOR QUERY [query_id];| 步骤 | 说明 |
| SHOW PROFILES | 显示最近查询的耗时 |
| SHOW PROFILE FOR QUERY N | 显示第 N 条查询的各阶段耗时 |
解决MySQL中长连接内存占用太大的问题:
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。