Java开发经验——阿里巴巴编码规范实践解析8
摘要
本文主要介绍了阿里巴巴编码规范在Java开发中的实践解析,强调了在表查询中不使用“*”作为查询字段列表的重要性,指出其会增加查询分析成本、浪费网络传输资源、降低可维护性、不利于缓存且存在安全隐患。同时,还提出了正例推荐写法,包括明确指定查询字段、在不同框架中的体现以及最佳实践建议。此外,还涉及了POJO类布尔属性命名规范、resultMap的使用、sql.xml配置参数的规范、数据更新接口的规范、事务的合理使用、分层结构推荐、异常处理规约以及分层领域模型规约等内容,旨在帮助Java开发者更好地遵循编码规范,提高代码质量和可维护性。
1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:
- 增加查询分析器解析成本。
- 增减字段容易与 resultMap 配置不一致。
- 无用字段增加网络消耗,尤其是 text 类型的字段。
1.1. 为什么不能使用 SELECT *?
| 问题类别 | 详细说明 |
| ❌ 性能问题 | 解析 SQL 时会去查字段元数据,字段越多解析成本越大,尤其在复杂表连接中更明显。 |
| ❌ 网络传输浪费 | 加载了不需要的字段(如 TEXT、BLOB 等大字段),增加了数据库到应用间的网络 IO。 |
| ❌ 可维护性差 | 表结构变更(加字段、删字段)时容易造成 、DTO 等解析失败或字段映射错乱。 |
| ❌ 难以做缓存 | 无法根据字段内容判断缓存命中,增加缓存粒度模糊性。 |
| ❌ 安全隐患 | 返回了原本不该暴露给前端/日志的敏感字段,例如密码、身份证、手机号等。 |
1.2. ✅ 正例推荐写法
1.2.1. ✅ 推荐 SQL 写法(明确字段)
SELECT id, name, email FROM user WHERE status = 1;1.2.2. ❌ 错误写法(不可控)
SELECT * FROM user WHERE status = 1;1.3. ✅ 在不同框架中的体现
1.3.1. MyBatis
<!-- resultMap 需字段一一对应 -->
<select id="getUser" resultMap="BaseResultMap">SELECT id, name, email FROM user WHERE id = #{id}
</select>1.3.2. JPA / ORM
- 虽然有默认实体映射,但最好使用 JPQL 或 Projection 显式列出字段:
@Query("SELECT u.id, u.name FROM User u WHERE u.status = 1")
List<UserDTO> findActiveUsers();1.4. ✅ 最佳实践建议
| 场景 | 建议 |
| DTO/VO 场景 | 只查询所需字段,避免加载多余字段,提升效率 |
| 高并发接口 | 尤其注意排除 TEXT/BLOB 等大字段 |
| 日志与敏感数据 | 严格控制查询字段,避免敏感信息误打印到日志或返回 |
2. 【强制】POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行字段与属性之间的映射。
说明:参见定义 POJO 类以及数据库字段定义规定,在 sql.xml 增加映射,是必须的。
3. 【强制】不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义<resultMap>;反过来,每一个表也必然有一个<resultMap>与之对应。
说明:配置映射关系,使字段与 DO 类解耦,方便维护。
3.1. ✅ 规范要点总结
- 不要用
resultType或resultClass直接映射返回结果类。 - 即使 POJO 属性名和数据库字段名完全一致,也要定义
<resultMap>。 - 每张表对应至少一个
<resultMap>映射,保证灵活维护。 <resultMap>使数据库字段与对象字段的映射关系显式配置,实现解耦。
3.2. ❌ 为什么不推荐直接使用 resultType / resultClass
| 问题点 | 说明 |
| ❌ 隐藏映射规则 | 直接用类名,MyBatis 默认使用驼峰映射,字段名改变难定位映射问题。 |
| ❌ 难以维护 | 字段变动时,代码容易发生隐性错误,且调试难,错误不易发现。 |
| ❌ 无法灵活定制 |
|
| ❌ 代码耦合度高 | 类直接依赖数据库字段结构,耦合紧密,难以改动数据库或类结构。 |
3.3. ✅ 正确使用 <resultMap> 示例
<resultMap id="UserResultMap" type="com.example.domain.UserDO"><id property="id" column="user_id" /><result property="username" column="user_name" /><result property="email" column="email_address" /><result property="createdAt" column="created_at" />
</resultMap><select id="selectUser" resultMap="UserResultMap">SELECT user_id, user_name, email_address, created_at FROM user WHERE user_id = #{id}
</select>3.4. ✅ 四、优点
- 解耦:数据库字段名改变,不影响 Java 类,只改
<resultMap>映射即可。 - 灵活:支持字段重命名、复杂类型转换、嵌套关联映射。
- 可维护:映射关系集中管理,方便排查和修改。
- 规范化:符合大型项目的代码标准和规范,便于多人协作。
总结:无论字段名是否一一对应,都要定义 <resultMap>,杜绝直接使用 resultType/resultClass,保证映射的灵活性与系统的可维护性。
4. 【强制】sql.xml 配置参数使用:#{},#param# 不要使用 ${} 此种方式容易出现 SQL 注入。
5. 【强制】iBATIS 自带的 queryForList(String statementName,int start,int size) 不推荐使用。
说明:其实现方式是在数据库取到 statementName 对应的 SQL 语句的所有记录,再通过 subList 取 start,size
的子集合,线上因为这个原因曾经出现过 OOM。
正例:
Map<String,Object> map = new HashMap<>(16);
map.put("start", start);
map.put("size", size);6. 【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。
反例:某同学为避免写一个<resultMap>xxx</resultMap>,直接使用 Hashtable 来接收数据库返回结果,结果出现日常是把 bigint 转成 Long 值,而线上由于数据库版本不一样,解析成 BigInteger,导致线上问题。
6.1. ✅ 规范核心说明
- 禁止用
HashMap、Hashtable直接作为查询结果类型。 - 即使临时方便,也会导致类型转换不确定,增加线上问题风险。
- 需通过明确的实体类(DO/DTO)+
<resultMap>来规范映射。
6.2. 为什么禁止用 HashMap/Hashtable?
| 风险点 | 说明 |
| 类型不确定 | 数据库数值类型(如 bigint)在不同数据库版本或 JDBC 驱动下映射不同,可能是 |
| 缺乏编译期检查 |
|
| 可维护性差 | 难以追踪和管理字段,后期变更数据库结构或字段时异常隐蔽。 |
| 严重线上隐患 | 不同环境中类型映射不一致,可能导致应用崩溃或数据处理错误。 |
6.3. ✅ 推荐做法
使用实体类 + <resultMap>
<resultMap id="UserResultMap" type="com.example.domain.UserDO"><id property="id" column="user_id"/><result property="name" column="user_name"/><result property="age" column="user_age"/>
</resultMap>对应 Java 实体类:
public class UserDO {private Long id;private String name;private Integer age;// getter/setter
}如果必须使用动态字段,可考虑使用专门的 VO 或 DTO 类,而非原生 Map。
总结:禁止使用 HashMap 和 Hashtable 作为查询结果,统一使用实体类映射,避免数据类型不一致和难以维护的问题。
7. 【强制】更新数据表记录时,必须同时更新记录对应的 update_time 字段值为当前时间。
8. 【推荐】不要写一个大而全的数据更新接口。 传入为 POJO 类,不管是不是自己的目标更新字段,都进行update table set c1 = value1 , c2 = value2 , c3 = value3;这是不对的。执行 SQL 时,不要更新无改动的字段,一是易出错;二是效率低;三是增加 binlog 存储。
“更新操作只更新实际变动的字段,避免大而全、无差别地全字段更新。”
8.1. ✅ 规范核心含义
不推荐:
update user set name = #{name}, email = #{email}, age = #{age} where id = #{id};即使这些字段值根本没有变化,也全部更新。
推荐:
<set><if test="name != null"> name = #{name}, </if><if test="email != null"> email = #{email}, </if><if test="age != null"> age = #{age} </if>
</set>仅更新真正需要改动的字段。
8.2. 为什么不能“无差别更新”?
| 问题点 | 说明 |
| ❌ 易误更新 | POJO 被错误填充默认值(如 0/null/""),可能导致非目标字段被误更新 |
| ❌ 性能浪费 | 无差别 UPDATE 会修改整行数据,增加锁竞争,降低写入效率 |
| ❌ binlog 膨胀 | MySQL 会记录每次更新的全部字段,即使值没变,也会产生完整 binlog |
| ❌ 主从同步压力 | Binlog 体积大,导致主从同步延迟增加 |
| ❌ 容易丢数据 | 特别是在更新对象未做字段控制时,容易清空其他字段原始值(比如某些字段传 null) |
8.3. ✅ 正确写法(以 MyBatis 为例)
<update id="updateUser" parameterType="com.example.User">update user<set><if test="name != null"> name = #{name}, </if><if test="email != null"> email = #{email}, </if><if test="age != null"> age = #{age} </if></set>where id = #{id}
</update>8.4. ✅ 最佳实践建议
| 场景 | 建议 |
| DTO 层 | 拆分多个“更新专用 DTO”,不要直接用全量 POJO |
| 接口层 | 拆分为:修改基本信息、修改密码、修改头像等小接口 |
| MyBatis 层 | 用 |
| JPA 层 | 尽量用 |
9. 【参考】@Transactional 事务不要滥用。 事务会影响数据库的 QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
不要滥用 @Transactional,事务不是免费使用的,代价高、责任重。
9.1. ✅ 为什么要谨慎使用事务?
| 问题 | 说明 |
| 📉 性能损耗 | 事务开启后,MySQL/InnoDB 要维护 undo/redo log、加锁、限制并发,导致 QPS 降低。 |
| 🔒 资源占用 | 长事务会持有数据库连接、锁资源,造成阻塞甚至死锁。 |
| ❗ 不完整的回滚 | 大多数情况下, 只保证数据库回滚,缓存、消息队列、搜索引擎等都不会自动回滚。 |
| 💥 全局异常吞噬 | 某些异常(如 住、或非 RuntimeException)不会触发事务回滚,易留坑。 |
| 🧩 分布式事务困难 | 一旦涉及多个系统或数据库表,事务控制难度和成本大增,可能需要引入消息补偿或 TCC 模式。 |
9.2. ✅ 常见滥用场景举例
| 场景 | 说明 |
| ❌ 在读操作上加事务 | 没必要浪费事务开销 |
| ❌ Controller 层加 | 会造成事务粒度过大,不清晰 |
| ❌ 包含远程调用的业务中加事务 | 事务回滚了但远程服务没法一起回滚,造成数据不一致 |
| ❌ 操作缓存、ES、MQ 等非数据库资源但未配套补偿机制 | 回滚不完整,业务数据不一致 |
9.3. ✅ 最佳实践建议
9.3.1. 控制事务范围最小化(即最小事务单元)
@Transactional
public void updateUserInfo(UserDTO userDTO) {
// 只更新 DB,缓存单独处理
userMapper.update(...);
}9.3.2. 不跨 RPC、MQ、Redis 等资源使用事务,使用补偿机制替代
- ✅ 分布式事务 → 使用本地消息表 + 消息确认机制
- ✅ Redis 缓存 → 明确使用 try-catch 后补偿、双写延迟队列
- ✅ MQ 消息 → 使用幂等机制 + 状态标记
9.3.3. @Transactional应只出现在Service 层,不出现在Controller和DAO层。
9.3.4. 明确哪些操作需要事务,哪些不需要
- ✅ 批量 insert/update/delete → 可考虑事务。
- ✅ 单条读操作、缓存更新、状态轮询等 → 不需要事务。
9.4. ✅ 额外提醒:Spring 的事务默认规则坑点
| 事务规则 | 说明 |
| 默认只回滚 RuntimeException |
|
| 事务方法调用自身内部方法无效 | 事务必须通过 Spring AOP 调用才能生效 |
| 多线程场景下事务无效 | 子线程不会共享事务上下文 |
| 超时/嵌套事务不当容易造成锁未释放 | 配置不当会引发隐藏问题 |
总结:事务是业务保障的手段,不是默认配置。用事务前,请问自己:是否真的需要?事务能保护的全部资源是否都可回滚?
10. 【参考】<isEqual>中的 compareValue 是与属性值对比的常量,一般是数字,表示相等时带上此条件;<isNotEmpty>表示不为空且不为 null 时执行;<isNotNull>表示不为 null 值时执行。
11. 【推荐】根据业务架构实践,结合业界分层规范与流行技术框架分析,推荐分层结构如图所示,默认上层依赖于下层,箭头关系表示可直接依赖,如:开放 API 层可以依赖于 Web 层(Controller 层),也可以直接依赖于 Service 层,依此类推:
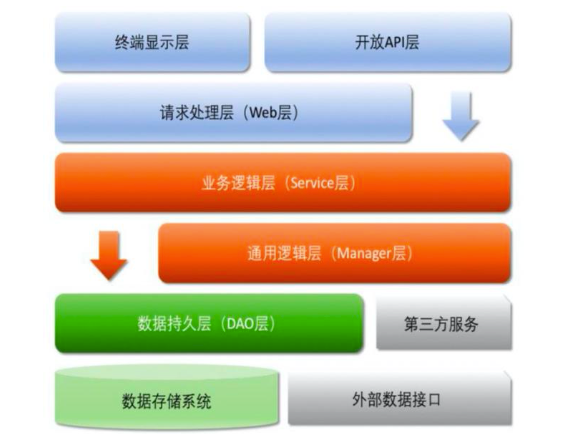
- 开放 API 层:可直接封装 Service 接口暴露成 RPC 接口;通过 Web 封装成 http 接口;网关控制层等。
- 终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染,JSP 渲染,移动端展示等。
- Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
- Service 层:相对具体的业务逻辑服务层。
- Manager 层:通用业务处理层,它有如下特征
-
- 对第三方平台封装的层,预处理返回结果及转化异常信息,适配上层接口。
- 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理。
- 与 DAO 层交互,对多个 DAO 的组合复用。
- DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase、OceanBase 等进行数据交互。
- 第三方服务:包括其它部门 RPC 服务接口,基础平台,其它公司的 HTTP 接口,如淘宝开放平台、支付宝付款服务、高德地图服务等。
- 外部数据接口:外部(应用)数据存储服务提供的接口,多见于数据迁移场景中。
12. 【参考】(分层异常处理规约)在 DAO 层,产生的异常类型有很多,无法用细粒度的异常进行 catch,使用 catch(Exception e) 方式,并 throw new DAOException(e),不需要打印日志,
因为日志在Manager 或 Service 层一定需要捕获并打印到日志文件中去,如果同台服务器再打日志,浪费性能和存储。在 Service 层出现异常时,必须记录出错日志到磁盘,尽可能带上参数和上下文信息,相当于保护案发现场。Manager 层与 Service 同机部署,日志方式与 DAO 层处理一致,如果是单独部署,则采用与Service 一致的处理方式。Web 层绝不应该继续往上抛异常,因为已经处于顶层,如果意识到这个异常将导致页面无法正常渲染,那么就应该直接跳转到友好错误页面,尽量加上友好的错误提示信息。开放接口层要将异常处理成错误码和错误信息方式返回。
这是一个非常重要且成熟的分层异常处理规约,目标是在系统中做到:“异常分层抛出、按职责处理、按场景记录、避免重复打日志”。
12.1. ✅ 各层的职责与处理方式概览
| 层级 | 异常处理策略 | 是否打日志 | 抛出异常类型 |
| DAO 层 |
后包装为 抛出 | ❌ 不打日志 |
|
| Manager 层 | 可选择记录日志(若和 Service 层不同机),否则继续抛出 | ✅ 或 ❌ | 抛出封装后的业务异常 |
| Service 层 | 捕获并记录完整日志(包含参数、上下文),保证案发现场完整 | ✅ 必须打日志 | 抛出业务异常或处理异常 |
| Web 层 | 绝不继续向上抛出,处理为友好页面/响应码/提示消息 | ✅ 打用户友好日志 | 页面跳转或 JSON 响应 |
| 开放接口层 | 捕获所有异常,转为标准错误码和提示信息响应 | ✅ 日志 + 错误码 | 统一响应格式 |
12.2. ✅ DAO 层示例(不打日志,只包装异常)
不使用 try-catch,而是让异常自然抛出(即直接向上抛出),由 Service 层统一 catch 包装为 BizException 并打印日志。为什么 DAO 层通常不写 try-catch?
| 原因 | 说明 |
| ✅ 避免重复封装异常 | MyBatis、JPA 已经会抛出具体的数据库异常(如 |
| ✅ 统一异常处理职责 | DAO 只做数据访问,不处理业务,异常的封装和日志由上层(Service)负责 |
| ✅ 便于排查问题 | Service 打日志时可以带上业务上下文(userId, 操作参数),DAO 很难拿到这些信息 |
| ✅ 保持代码简洁 | 大量 try-catch 会让 DAO 代码变得冗余 |
12.3. ✅ 推荐写法(更常见的做法)
// ✅ 不做 try-catch,异常自然抛出
public UserDO getUserById(Long id) {return sqlSession.selectOne("UserMapper.selectById", id);
}然后在 Service 层封装日志与业务异常:
public UserDTO queryUser(Long userId) {try {UserDO user = userDAO.getUserById(userId);return convert(user);} catch (Exception e) {log.error("查询用户失败 userId={}", userId, e);throw new BizException("用户查询失败");}
}阿里规约 vs 实战最佳实践
| 规范来源 | 是否建议 DAO try-catch | 是否建议封装为 DAOException |
| 阿里 Java 开发手册(规范型项目) | ✅ 建议 catch 后包装 DAOException(但不打日志) | 是 |
| 实战项目(Spring Boot + MyBatis) | ❌ 通常不 catch,让异常抛给 Service | 否(让 Service 层统一包装) |
12.4. 什么时候写 try,什么时候不写?
| 场景 | 建议 |
| ✅ DAO 层复杂通用封装(如 BaseDAO) | 可使用 try-catch,统一转为 DAOException |
| ✅ DAO 层用 JDBC 原生写法(抛 SQLException) | 应封装为 DAOException |
| ✅ 规范驱动团队(如银行/金融) | 遵循阿里手册,catch Exception + 包装DAOException |
| ✅ 敏捷开发团队或项目较轻量 | 直接抛出异常,在 Service 层统一处理更简洁 |
12.5. ✅ Service 层示例(打日志 + 上抛)
public UserDTO getUserById(Long id) {try {return userManager.getUserById(id);} catch (DAOException e) {log.error("查询用户失败,userId={},异常:{}", id, e.getMessage(), e);throw new BizException("用户查询异常", e);}
}12.6. ✅ Controller 全局异常处理
Controller 层将异常转为响应码或错误页面的最佳实践方式就是使用 全局异常处理(Global Exception Handler),通过 Spring 提供的 @ControllerAdvice 和 @ExceptionHandler 实现。
12.6.1. ✅ 为什么使用全局异常处理?
| 目的 | 说明 |
| 📦 统一异常格式 | 避免每个 Controller 手动 try-catch,减少重复代码 |
| 🎯 集中管理错误码 | 可以统一输出错误码、错误信息、traceId 等 |
| 😇 提升用户体验 | 前端展示统一风格的错误提示页或 JSON 格式 |
| 📄 方便监控审计 | 日志记录位置统一,便于日志采集、异常告警 |
12.6.2. ✅ 示例:全局异常处理类(针对 Web 和 API)
@RestControllerAdvice // 如果是页面应用,可用 @ControllerAdvice
public class GlobalExceptionHandler {// 处理自定义业务异常@ExceptionHandler(BizException.class)public ApiResponse<?> handleBizException(BizException ex) {log.warn("业务异常:{}", ex.getMessage(), ex);return ApiResponse.failure("BIZ_ERROR", ex.getMessage());}// 处理数据库异常@ExceptionHandler(DAOException.class)public ApiResponse<?> handleDaoException(DAOException ex) {log.error("DAO异常:{}", ex.getMessage(), ex);return ApiResponse.failure("DB_ERROR", "数据库操作失败");}// 处理参数校验失败@ExceptionHandler(MethodArgumentNotValidException.class)public ApiResponse<?> handleValidation(MethodArgumentNotValidException ex) {String msg = ex.getBindingResult().getAllErrors().get(0).getDefaultMessage();return ApiResponse.failure("VALIDATION_ERROR", msg);}// 兜底处理未知异常@ExceptionHandler(Exception.class)public ApiResponse<?> handleException(Exception ex) {log.error("系统异常", ex);return ApiResponse.failure("SYSTEM_ERROR", "系统繁忙,请稍后再试");}
}12.6.3. ✅ 页面异常处理(跳转错误页)
@ControllerAdvice
public class PageExceptionHandler {@ExceptionHandler(Exception.class)public String handlePageError(Exception ex, Model model) {model.addAttribute("errorMsg", "页面加载失败:" + ex.getMessage());return "errorPage";}
}12.6.4. ✅ 示例响应体类:ApiResponse
public class ApiResponse<T> {private String code;private String message;private T data;public static <T> ApiResponse<T> success(T data) {ApiResponse<T> res = new ApiResponse<>();res.code = "SUCCESS";res.message = "操作成功";res.data = data;return res;}public static <T> ApiResponse<T> failure(String code, String message) {ApiResponse<T> res = new ApiResponse<>();res.code = code;res.message = message;return res;}// getter/setter 略
}12.6.5. ✅ 总结
- ✅ Controller 层异常不应使用 try-catch,而应通过 全局异常处理集中解决。
- ✅
@RestControllerAdvice适用于前后端分离的接口(JSON 返回)。 - ✅
@ControllerAdvice适用于传统页面应用(返回ModelAndView或跳转页)。 - ✅ 每种异常可细分处理,记录日志 + 统一响应结构 是最佳实践。
12.7. ✅ 重点总结
| 内容 | |
| ❌ 不重复打日志 | 异常只在 Service/Web 层 打日志,避免 DAO 打日志浪费资源 |
| ✅ 上层处理上下文 | Service 层必须记录:入参、上下文、堆栈,便于排查 |
| ✅ 分层包装异常 | DAO → |
| ✅ 接口返回友好 | 页面 → 跳转友好错误页,接口 → 错误码 + 提示 |
13. DAO层是否需要使用try 捕获异常? 什么需要使用,什么时候不需要?
13.1. DAO是否捕获异常结论总结
| 是否使用 try-catch | 使用场景 | 原因说明 |
| ❌ 不使用(推荐方式) | 80% 场景都不需要,如使用 MyBatis、JPA、Spring Data | 异常由框架抛出(如 |
| ✅ 使用 | 需要封装为自定义异常(如 | 原生 JDBC 抛 SQLException,需要封装;某些规范要求分层异常 |
| ✅ 使用 | 编写框架/中间件/公共组件中的 BaseDAO | 可捕获异常统一转换(如抛 DAOException),提高通用性和一致性 |
| ✅ 使用 | 捕获数据库某些特定错误(如主键冲突)并做业务分支处理 | 需要判断 SQLState 或 errorCode 执行特定逻辑 |
13.2. ❌ 不使用 try-catch(常见写法)
public UserDO getUserById(Long id) {return sqlSession.selectOne("UserMapper.selectById", id);
}- 简洁清晰,异常直接抛出
- 由 Service 层统一记录日志、抛业务异常
- 实际项目中更常见 ✅
13.3. ✅ 使用 try-catch 的场景一:需要包装为自定义异常
如果你遵循的是分层异常体系(DAO 层抛 DAOException,Service 层抛 BizException),可以这样写:
public UserDO getUserById(Long id) {
try {return sqlSession.selectOne("UserMapper.selectById", id);
} catch (Exception e) {// 不打日志,向上抛 DAO 异常throw new DAOException("查询用户失败,id=" + id, e);
}
}- 使用自定义异常
DAOException,方便统一识别来源 - 常见于 大型公司、强规范金融类项目
- 缺点是代码冗余,Service 层还需再包装一次
13.4. ✅ 使用 try-catch 的场景二:原生 JDBC 时必须使用
public UserDO getUserById(Long id) {Connection conn = null;PreparedStatement stmt = null;ResultSet rs = null;try {conn = dataSource.getConnection();stmt = conn.prepareStatement("SELECT * FROM user WHERE id = ?");stmt.setLong(1, id);rs = stmt.executeQuery();if (rs.next()) {// 封装成 UserDOreturn mapToUserDO(rs);}return null;} catch (SQLException e) {throw new DAOException("JDBC 查询失败", e);} finally {closeQuietly(rs, stmt, conn);}
}- 原生 JDBC 一定需要 try-catch
- 注意释放连接资源
- 推荐封装为工具类
13.5. ✅ 使用 try-catch 的场景三:针对 SQL 错误码做逻辑判断
try {sqlSession.insert("UserMapper.insertUser", user);
} catch (DuplicateKeyException e) {log.warn("插入用户失败,主键冲突 userId={}", user.getId());throw new BizException("用户已存在");
}- 某些业务逻辑上需要识别特定异常类型做降级或提示
- 通常在 Service 层做即可
13.6. 📌 总结建议:你的项目应该怎么做?
| 项目类型 | DAO 是否 try-catch | 异常处理建议 |
| 中小型项目、Spring Boot+MyBatis | ❌ 不用,异常直接抛 | Service 统一日志和封装 BizException |
| 传统企业规范项目(如金融、电信) | ✅ 使用,包装为 DAOException | 不打日志,由 Service 记录 |
| 原生 JDBC 使用较多的场景 | ✅ 必须使用 | 封装成工具类或 BaseDAO |
14. 【参考】分层领域模型规约:
- DO(Data Object):此对象与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service 或 Manager 向外传输的对象。
- BO(Business Object):业务对象,可以由 Service 层输出的封装业务逻辑的对象。
- Query:数据查询对象,各层接收上层的查询请求。注意超过 2 个参数的查询封装,禁止使用 Map 类来传输。
- VO(View Object):显示层对象,通常是 Web 向模板渲染引擎层传输的对象。
博文参考
《阿里java规范设计》