SpringCloud基础知识
学习视频链接:SpringCloud | 黑马程序员
文章目录
- Nacos
- Docker部署
- 1.拉取镜像
- 2.运行nacos
- 3.测试
- Nacos介绍
- 核心功能:
- 基本概念:
- 部署模式:
- 1.单机模式(Standalone)
- 2.集群模式(Cluster)
- 3.云原生部署模式(Kubernetes)
- 4、多集群部署模式(Multi-Cluster)
- Java-SDK
- 服务注册流程
- 小案例:
- 注册流程分析:
- **1. 客户端初始化**
- **2. 连接建立(gRPC)**
- **3. 服务注册请求**
- **4. 服务端处理与响应**
- **5. 注册后操作**
- RabbitMQ
- 部署
- 概述
- 关键组件
- 交换机
- 类型:
- 区别:
- Spring AMQP
- 生产者发送消息
- 消费者接收消息
- 配置Json转换器
- Elasticsearch
- 初识ES
- 介绍
- 原理
- 倒排索引
- 分词
- Docker部署
- 1.添加镜像源
- 2.启动docker
- 3.下载es
- 4.运行单节点es
- 5.访问测试
- 6.创建网络
- 7.下载kibana
- 8.运行kibana
- 9.测试访问
- 10.下载IK分词器插件(离线安装)
- 核心数据类型
- ES使用教程
- 索引库操作
- 创建索引库
- 查看索引库
- 删除索引库
- 修改索引库
- 文档操作
- 新增文档
- 查询文档
- 删除文档
- 修改文档
- 全量修改
- 增量修改
- DSL查询语法
- 全文查询
- 字段查询
- **单字段**:
- **多字段**:
- 查询所有
- 精准查询
- 范围查询
- 地理位置查询
- 矩形范围查询
- 圆形范围查询
- 复杂查询
- 相关性算分
- 控制相关性算分
- 布尔查询
- 搜索结果处理
- 排序
- 分页
- **1.基本分页:from/size 参数**
- **2.深度分页:Scroll API**
- **3.实时分页:search_after 参数**
- 高亮
- 数据聚合
- 聚合分类
- 桶聚合
- 指标聚合
- 管道聚合
- 矩阵聚合
- 自动补全
- 拼音分词器
- 自定义分词器
- RestHighLevelClient
- 索引操作:
- 初始化客户端
- 创建索引
- 查询索引
- 删除索引
- 新增字段
- 释放资源
- 文档操作
- 初始化客户端
- 添加文档
- 删除文档
- 修改文档
- 全量修改
- 增量修改
- 查询文档
- 释放资源
- 批量导入
- 查询操作
- 语法
- **1. 客户端初始化**
- **2. 文档查询操作**
- **3. 核心搜索 API**
- **4. 常用查询**
- **5. 聚合查询**
- 6. 高级查询功能
- 初始化客户端
- 查询所有数据
- 单字段查询
- 多字段查询
- 精确查询
- 范围查询
- 矩形范围查询
- 圆形范围查询
- 复杂查询
- 布尔查询
- 排序
- 分页
- 基础分页
- 深度分页
- 实时分页
- 高亮
- 桶聚合
- 自动补全
Nacos
官方文档:Nacos Docker 快速开始 | Nacos 官网
Docker部署
docker版本:Docker version 26.1.1【windows版本】
1.拉取镜像
docker pull nacos/nacos-server:v3.0.1
2.运行nacos
docker run --name nacos-new -e MODE=standalone -e PREFER_HOST_MODE=hostname -e NACOS_AUTH_ENABLE=true -e NACOS_AUTH_TOKEN="$( [Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes((New-Guid).ToString())) )" -e NACOS_AUTH_IDENTITY_KEY="nacos-key" -e NACOS_AUTH_IDENTITY_VALUE="nacos-value" -p 8080:8080 -p 8848:8848 -p 9848:9848 -d nacos/nacos-server:v3.0.1
格式化一下:
docker run --name nacos-new `-e MODE=standalone `-e PREFER_HOST_MODE=hostname `-e NACOS_AUTH_ENABLE=true `-e NACOS_AUTH_TOKEN="$( [Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes((New-Guid).ToString())) )" `-e NACOS_AUTH_IDENTITY_KEY="nacos-key" `-e NACOS_AUTH_IDENTITY_VALUE="nacos-value" `-p 8080:8080 -p 8848:8848 -p 9848:9848 `-d nacos/nacos-server:v3.0.1
--name nacos-new:指定容器名称为nacos-new-e MODE=standalone:设置 Nacos 以单机模式运行(非集群模式,适用于开发 / 测试)-e PREFER_HOST_MODE=hostname:服务注册时优先使用主机名而非 IP-e NACOS_AUTH_ENABLE=true:启用 JWT 认证机制(Nacos 3.0 + 默认强制启用)-e NACOS_AUTH_TOKEN=...:JWT 签名密钥(Base64 格式)-e NACOS_AUTH_IDENTITY_KEY="nacos-key":服务间认证的身份标识 Key-e NACOS_AUTH_IDENTITY_VALUE="nacos-value":服务间认证的身份标识 Value-p 8080:8080:Nacos 控制台访问端口(HTTP)-p 8848:8848:服务注册发现端口(兼容旧版客户端)-p 9848:9848:gRPC 通信端口(Nacos 2.0 + 长连接通信)
3.测试
访问:http://localhost:8080/index.html
Nacos介绍
核心功能:
- 服务注册与发现:提供基于 DNS 和 RPC 的服务发现机制,支持服务实例的自动注册与反注册,服务消费者可通过接口获取服务列表及健康实例,实现服务的动态发现与调用。
- 动态配置管理:支持分布式系统的配置集中管理,提供配置的动态更新、版本控制及灰度发布能力,通过推送机制实时同步配置到各服务实例,避免服务重启即可生效。
- 服务健康监测:持续检测服务实例的健康状态,自动剔除不健康实例,确保流量导向可用节点,同时支持自定义健康检查规则,适配不同场景的服务存活检测需求。
- 服务路由与流量管理:提供服务级别的路由规则、负载均衡策略(如权重、一致性哈希等),以及流量控制、熔断降级等能力,帮助优化服务调用链路,保障系统稳定性。
- 服务元数据管理:统一管理服务及其实例的元数据信息(如权重、标签、版本等),支持基于元数据的服务筛选与路由,为微服务架构中的服务治理提供数据支撑。
基本概念:
- 命名空间(Namespace)
- 作用:租户或环境隔离的逻辑单元,用于区分不同环境(如开发 / 测试 / 生产)或租户的配置与服务数据。
- 配置路径:左侧菜单 → 命名空间 → 新建或管理命名空间,每个命名空间生成唯一 ID(如
d4a3f92b-xxx),客户端需通过该 ID 关联对应环境。 - 典型场景:多租户隔离、跨环境配置(如数据库地址差异)。
- 配置分组(Group)
- 作用:对配置集进行逻辑分组,区分相同 Data ID 的不同用途(如
database组与mq组)。 - 配置路径:配置管理 → 配置列表 → 新建配置时指定 Group 名称(默认
DEFAULT_GROUP)。 - 注意:客户端需通过
spring.cloud.nacos.config.group指定 Group 名称以匹配配置5。
- 作用:对配置集进行逻辑分组,区分相同 Data ID 的不同用途(如
- Data ID
- 作用:配置集的唯一标识,通常对应配置文件名(如
application.properties),格式为${prefix}-${spring.profile.active}.${file-extension}。 - 配置路径:配置管理 → 配置列表 → 新建配置时填写 Data ID 及内容。
- 示例:
userservice-dev.yaml表示userservice服务在dev环境的 YAML 格式配置。
- 作用:配置集的唯一标识,通常对应配置文件名(如
部署模式:
1.单机模式(Standalone)
单节点,不采用集群,数据存储在本地文件或嵌入式数据库
2.集群模式(Cluster)
多个nacos节点,集群内数据保持同步
- 多节点组成集群,通过 Raft 算法保证数据一致性,支持高可用性和负载均衡。
- 数据可持久化到外部数据库(如 MySQL),避免单机数据丢失问题。
3.云原生部署模式(Kubernetes)
- 基于容器化技术(Docker)和 Kubernetes 集群部署,支持弹性扩缩容和服务发现。
- 利用 K8s 的 StatefulSet 保证节点顺序性和数据持久化,通过 Service 暴露服务。
4、多集群部署模式(Multi-Cluster)
- 在多个物理隔离的集群(如跨地域、跨云厂商)中部署 Nacos,通过网关或 DNS 实现跨集群服务调用。
- 支持 Namespace 隔离不同集群的服务与配置。
比较:
| 部署模式 | 可用性 | 数据持久化 | 适用场景 | 复杂度 |
|---|---|---|---|---|
| 单机模式 | 低(单点) | 否(H2 数据库) | 开发测试 | 简单 |
| 集群模式 | 高(多节点) | 是(外部数据库) | 生产环境、高并发业务 | 中等 |
| 云原生模式 | 高(K8s 调度) | 是(PVC + 数据库) | 云原生架构、弹性扩缩容 | 较高 |
| 多集群模式 | 极高(跨地域) | 按需同步 | 全球化业务、多地域容灾 | 高 |
Java-SDK
Nacos 的 Java SDK(或称Nacos-Java-Client),是一个针对 Nacos 配置中心、服务注册中心、分布式锁等场景的 Java SDK。旨在为Java的微服务或分布式应用提供稳定易用的配置中心、服务注册中心、分布式锁等功能,方便开发者访问Nacos进行配置、服务和分布式锁的操作。
Nacos 的 Java SDK需要 JDK 1.8 及以上版本的Java运行环境。
服务注册流程
小案例:
写个小demo来分析一下
application.yml配置文件:
server:port: 8081
spring:application:name: nacos-test # 服务名称cloud:nacos:discovery:server-addr: localhost:8848username: nacospassword: 123namespace: publiccluster-name: DEFAULTmetadata:version: 1.0.0nacos.access.key: nacos-key # 与Docker启动参数一致nacos.access.value: nacos-value # 与Docker启动参数一致
pom.xml配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.3</version><relativePath/></parent><groupId>com.xuan</groupId><artifactId>nacos-test</artifactId><version>1.0-SNAPSHOT</version><properties><java.version>17</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spring-cloud.version>2023.0.4</spring-cloud.version><spring-cloud-alibaba.version>2022.0.0.0-RC2</spring-cloud-alibaba.version></properties><dependencyManagement><dependencies><!-- Spring Cloud 依赖管理 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency><!-- Spring Cloud Alibaba 依赖管理 --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Nacos 服务发现依赖(已包含 nacos-client) --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>
在服务注册之前一定要记得启动nacos!!!
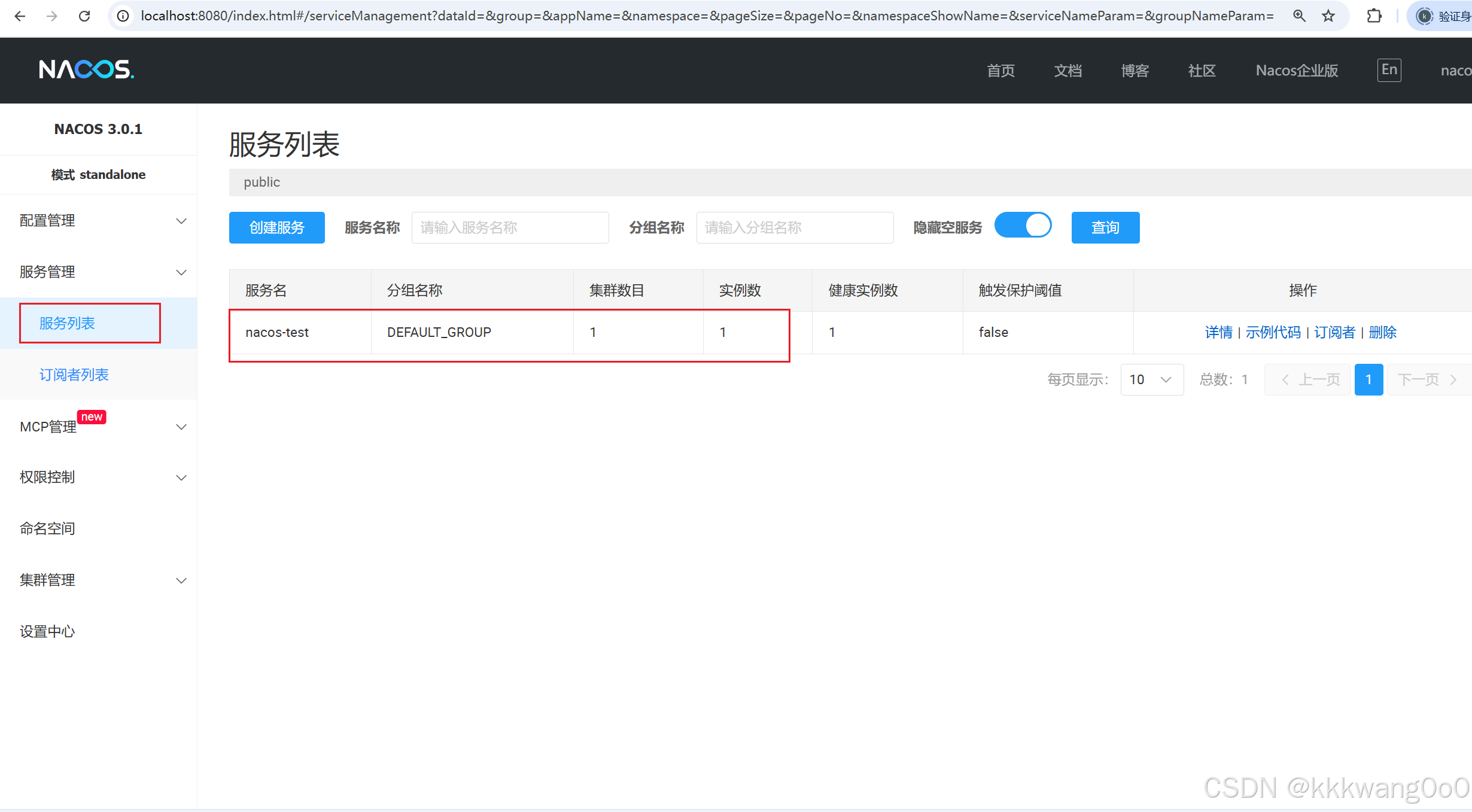
启动项目后,可以在nacos管理界面看到服务:
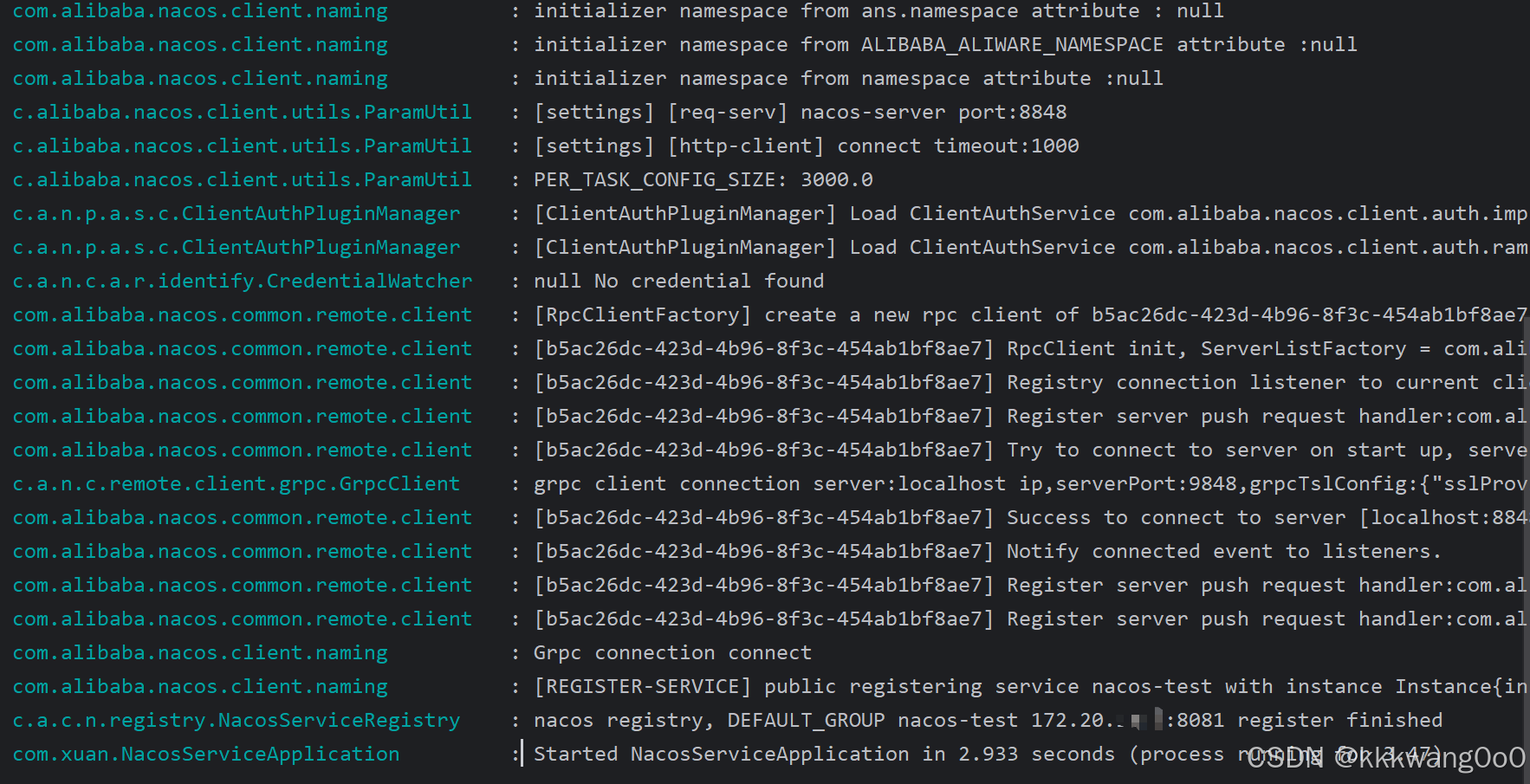
通过日志来分析一下这个服务注册流程:

注册流程分析:
1. 客户端初始化
- 参数配置:读取配置文件或环境变量,获取 Nacos 服务器地址(如
localhost:8848)、命名空间、超时时间等参数。 - 命名空间检查:尝试从多种来源获取命名空间(如
ans.namespace、ALIBABA_ALIWARE_NAMESPACE),若未配置则使用默认命名空间(public)。 - 认证插件加载:初始化认证机制(如 Nacos 原生认证、RAM 认证),若未配置凭证则使用匿名访问。
- Java sdk : 通过
NacosClientProperties读取配置文件里面的内容读取到
2. 连接建立(gRPC)
- 创建 RPC 客户端:初始化 gRPC 客户端,生成唯一 ID(如
b5ac26dc-423d-4b96-8f3c-454ab1bf8ae7)。 - 连接服务端:
- 通过 HTTP 端口(8848)进行初始通信。
- 建立 gRPC 长连接(默认端口 9848),用于双向通信。
- 注册请求处理器:客户端注册用于处理服务端推送的处理器(如连接重置、服务变更通知)。
- gRPC是一个RPC框架,主要用于远程过程调用。
3. 服务注册请求
- 构建服务实例信息:
- 服务名:如
nacos-test。 - 实例元数据:IP 地址(如
172.20.10.5)、端口(8081)、权重、健康状态、集群名称(DEFAULT)等。 - 自定义元数据:如版本号(
version=1.0.0)、认证信息(nacos.access.key)。
- 服务名:如
- 发送注册请求:通过 gRPC 将服务实例信息发送至 Nacos 服务端。
4. 服务端处理与响应
- 服务端接收请求:Nacos 服务端收到注册请求后,将实例信息存储在注册表中。
- 分配实例 ID:为临时实例(
ephemeral=true)生成唯一 ID(如172.20.*.*#8081#DEFAULT#public)。 - 返回注册结果:服务端返回成功响应,客户端记录注册完成。
5. 注册后操作
- 心跳机制:客户端定期向服务端发送心跳(默认 5 秒一次),维持服务实例的健康状态。
- 服务发现准备:
- 订阅服务:客户端可订阅其他服务的变更事件。
- 接收推送:服务端主动推送服务列表变更,客户端更新本地缓存。
RabbitMQ
部署
docker(Windows)部署RabbitMQ:
1.在线拉取:
docker pull rabbitmq:3-management
如果失败了,很大原因是因为加速器的原因。
可以先下载mq的镜像包,再使用下面这个指令:
docker load -i mq.tar
2.运行:
docker run -e RABBITMQ_DEFAULT_USER=itcast -e RABBITMQ_DEFAULT_PASS=202205567103 --name mq --hostname mq1 -p 15672:15672 -p 5672:5672 -d rabbitmq:3-management
我是在本地运行的,没有用虚拟机,所以我直接访问本地的http://127.0.0.1:15672/就可以访问到RabbitMQ的管理界面,如果用虚拟机部署,这里的ip地址就是你虚拟机的地址。
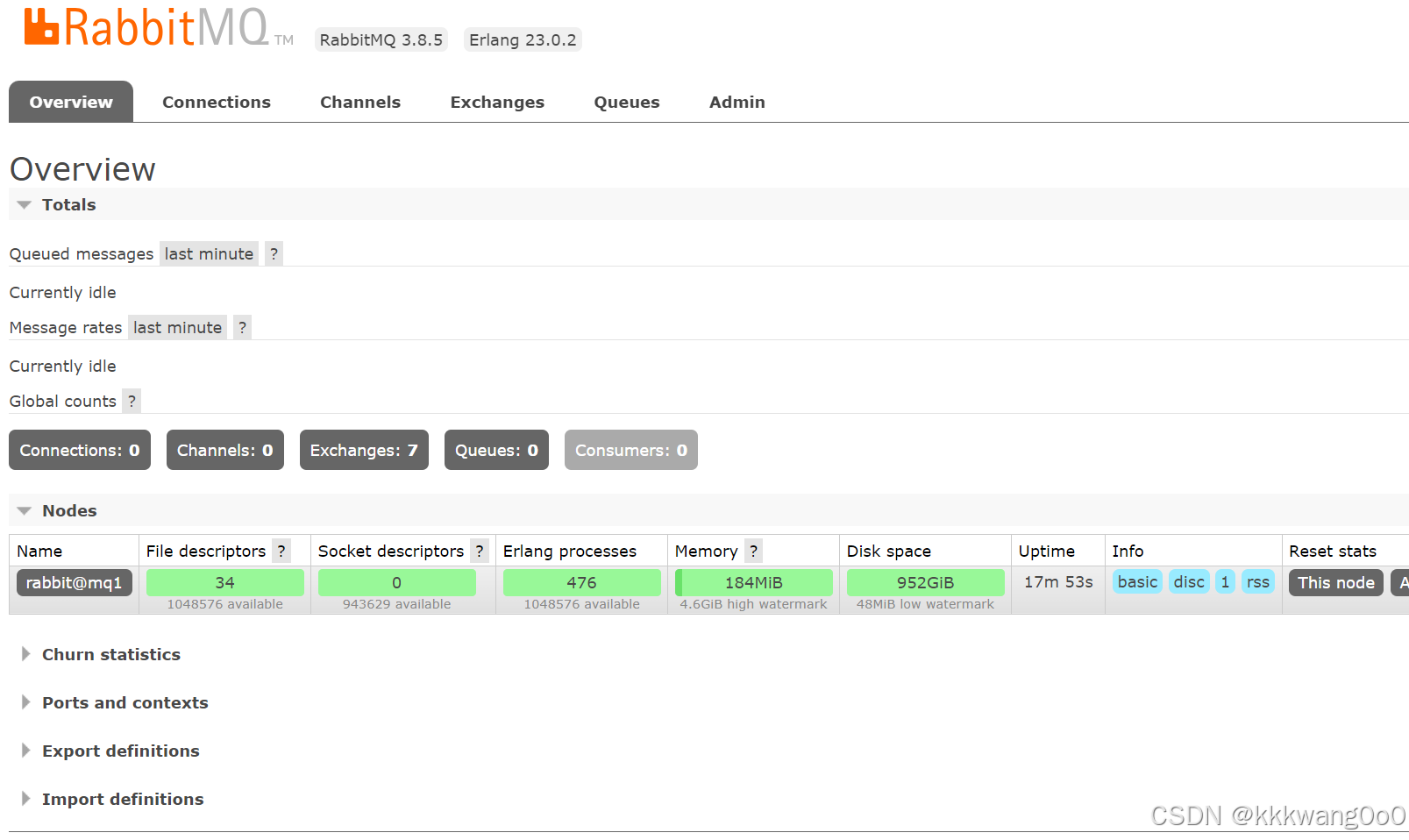
用户密码就是你在运行镜像的时候所配置的

RabbitMQ 默认使用两个主要的端口号:
- 5672:这是AMQP(Advanced Message Queuing Protocol)协议使用的端口,用于客户端应用程序与RabbitMQ服务器之间的通信。当您配置客户端连接到RabbitMQ时,通常会使用这个端口,除非被更改了默认设置。
- 15672:这是RabbitMQ管理插件所使用的端口,默认情况下提供了基于浏览器的用户界面来管理和监控RabbitMQ服务器。通过访问http://server-name:15672,您可以登录到管理控制台(需要先启用管理插件并配置正确的用户权限)。
概述
官方引导:RabbitMQ tutorial - “Hello World!” | RabbitMQ
- RabbitMQ 是一个开源的消息队列软件(消息代理),它实现了高级消息队列协议(AMQP)。它主要用于应用程序之间或者同一应用的不同组件之间的消息通信,提供可靠的消息传递服务。通过使用RabbitMQ,可以实现系统间的解耦、异步处理和负载均衡等。
- RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
关键组件
- publisher:生产者
- consumer:消费者
- exchange个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
!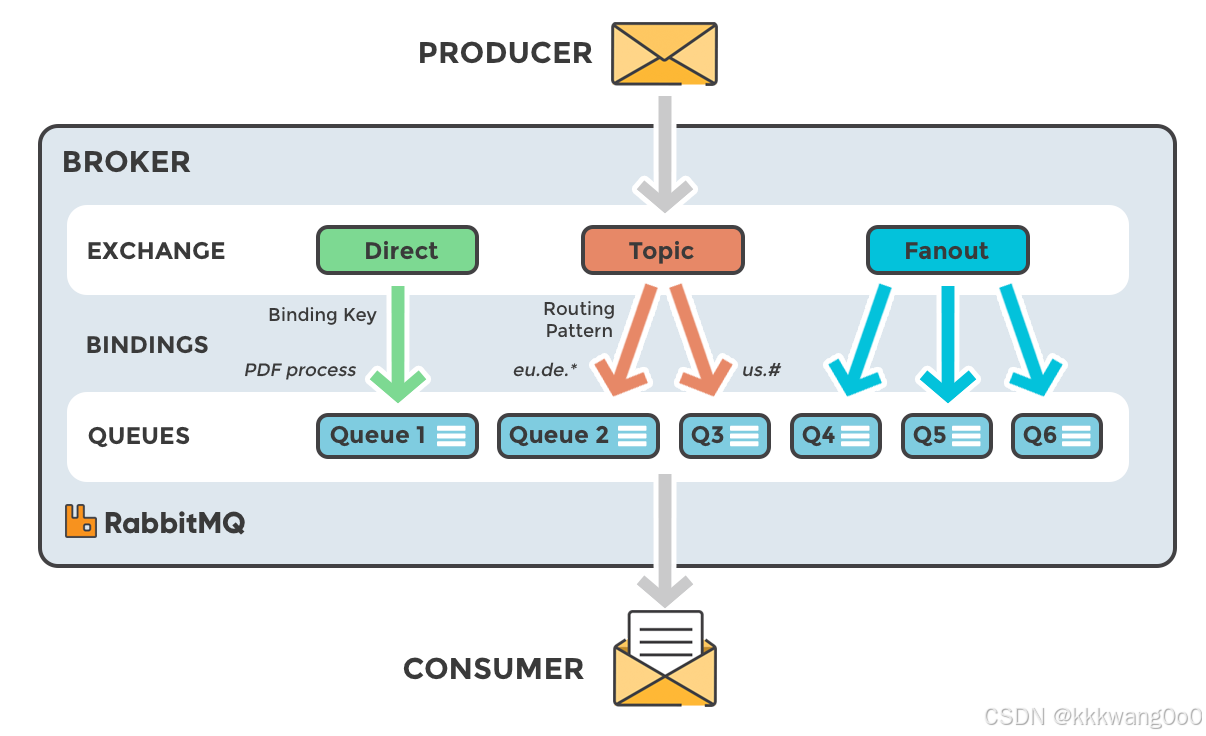
图源:https://www.cloudamqp.com/img/blog/exchanges-topic-fanout-direct.png
交换机
类型:
1. Direct Exchange(直接交换机)
- 路由规则:消息会根据其路由键(Routing Key)精确匹配绑定到交换机的队列的路由键。
- 使用场景:适用于需要基于特定值进行精确匹配的场景。例如,日志系统中可以根据严重程度(如 info, warning, error)来路由消息。
2. Fanout Exchange(扇出交换机)
- 路由规则:消息会被广播到所有绑定到该交换机的队列,忽略路由键。
- 使用场景:适用于广播消息的场景,例如通知所有订阅者更新状态。
3. Topic Exchange(主题交换机)
- 路由规则:消息会根据路由键和队列绑定键之间的模式匹配来路由。绑定键可以包含通配符:
* 匹配一个单词。
# 匹配零个或多个单词。
- 使用场景:适用于需要灵活路由的场景,例如日志系统中可以根据日志级别和来源来路由消息。
4. Headers Exchange(头部交换机)
- 路由规则:消息会根据消息头属性而不是路由键来进行路由。可以设置多个消息头,并且可以通过逻辑运算符(如 AND, OR)组合这些条件。
- 使用场景:适用于需要基于复杂条件进行路由的场景,例如根据消息头中的某些元数据来决定消息的去向。
5. Default Exchange(默认交换机)
- 路由规则:这是一个特殊的交换机,它没有名称(空字符串 “”),并且隐式地与每个队列绑定。路由键就是队列名称。
- 使用场景:通常用于简单的应用中,当不需要复杂的路由机制时。
区别:
| 类型 | 路由规则 | 应用场景 |
|---|---|---|
| Direct | 精确匹配路由键 | 需要精确匹配的消息路由 |
| Fanout | 广播消息到所有绑定的队列 | 需要广播消息的场景 |
| Topic | 模式匹配路由键 | 需要灵活路由的消息传递 |
| Headers | 根据消息头属性进行路由 | 需要基于复杂条件进行路由的场景 |
| Default | 隐式绑定到每个队列 ,路由键即队列名称 | 简单的应用场景 |
Spring AMQP
官方文档:Spring AMQP
在pom.xml中引入以下依赖:
<!--AMQP依赖,包含RabbitMQ-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
编写application.yml文件:
spring:rabbitmq:host: 127.0.0.1 port: 5672username:password: virtual-host: / # 虚拟机名称
创建队列和交换机的方法:
1.通过配置类
package cn.itcast.mq.config;import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class RabbitProducerConfig {// 声明队列@Beanpublic Queue myQueue() {return new Queue("my.queue", true); // 第二个参数表示是否持久化}// 声明直接交换机@Beanpublic DirectExchange myDirectExchange() {return new DirectExchange("itcast.exchange", true, false); // 是否持久化, 是否自动删除}// 声明绑定关系@Beanpublic Binding bindingRed(Queue myQueue, DirectExchange myDirectExchange) {return BindingBuilder.bind(myQueue).to(myDirectExchange).with("red");}@Beanpublic Binding bindingPink(Queue myQueue, DirectExchange myDirectExchange) {return BindingBuilder.bind(myQueue).to(myDirectExchange).with("pink");}
}
2.通过注解 (消费者端)
- @RabbitListener 注解允许你监听指定的队列,并且通过 bindings 属性可以定义队列、交换机及其绑定关系。这种方式非常适合在消费者端自动声明和管理这些资源。用于监听指定的队列。当有消息到达该队列时,会调用相应的处理方法。
- @QueueBinding:用于定义队列、交换机及其绑定关系。
value:定义队列。name 是队列名称,durable 表示是否持久化。
exchange:定义交换机。name 是交换机名称,type 是交换机类型(如 ExchangeTypes.DIRECT)。
key:定义路由键。这里指定了两个路由键 “red” 和 “pink”,意味着消息可以通过这两个路由键发送到该队列。
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue1"),exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),key = {"red", "pink"}))public void ListenDirectQueue1(String msg) {System.out.println("消费者1收到消息:" + msg);}
生产者发送消息
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class MessageProducer {private final RabbitTemplate rabbitTemplate;@Autowiredpublic MessageProducer(RabbitTemplate rabbitTemplate) {this.rabbitTemplate = rabbitTemplate;}/*** 发送消息到指定的交换机和路由键** @param message 要发送的消息内容* @param routingKey 路由键*/public void sendMessage(String message, String routingKey) {rabbitTemplate.convertAndSend("itcast.direct", routingKey, message);}
}
消费者接收消息
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Service;@Service
public class MessageConsumer {@RabbitListener(queues = "direct.queue1")public void listenDirectQueue1(String msg) {System.out.println("消费者1收到消息:" + msg);}
}
配置Json转换器
添加如下依赖:
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>2.9.10</version>
</dependency>
在启动类添加:
@Bean
public MessageConverter jsonMessageConverter(){return new Jackson2JsonMessageConverter();
}
Elasticsearch
初识ES
文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
Java Rest: https://elastic.ac.cn/guide/en/elasticsearch/client/java-api-client/current/introduction.html
介绍
Elasticsearch(简称 ES)是一个基于 Lucene 的分布式开源搜索引擎和数据分析引擎,具有实时搜索、全文检索、结构化数据处理和大规模数据聚合分析等能力
结合 Kibana 可实现数据可视化仪表盘,支持实时监控、趋势分析和异常检测(如服务器性能监控、业务指标告警)
原理
倒排索引
采用倒排索引的方式存储数据,倒排索引按 “关键词→包含该词的文档 ID 集合” 存储
三个重要概念:
- 索引:索引是 ES 中存储数据的逻辑容器,相当于数据库中的表结构
- 文档:文档是 ES 中可搜索的最小数据单元,相当于数据库每一行
- 词条:对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条,词条是对文本数据分词后的最小语义单元,是倒排索引的核心元素。
分词
输入文本按语言规则拆分为关键词(如英文按空格,中文需第三方分词器如 IK Analyzer),再构建倒排索引。
Docker部署
1.添加镜像源
进入 /etc/docker目录下创建daemon.json
文件内容如下:
{"registry-mirrors": ["https://***.mirror.aliyuncs.com", "https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn","https://cr.console.aliyun.com","https://mirror.ccs.tencentyun.com","https://docker.registry.cyou","https://docker-cf.registry.cyou","https://dockercf.jsdelivr.fyi","https://docker.jsdelivr.fyi","https://dockertest.jsdelivr.fyi","https://mirror.aliyuncs.com","https://dockerproxy.com","https://mirror.baidubce.com","https://docker.m.daocloud.io","https://docker.nju.edu.cn","https://docker.mirrors.sjtug.sjtu.edu.cn","https://docker.mirrors.ustc.edu.cn","https://mirror.iscas.ac.cn","https://docker.rainbond.cc"]
}
“https://***.mirror.aliyuncs.com” : 替换为自己的阿里云镜像源 https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
2.启动docker
sudo systemctl start docker
如果是已经启动的docker,可以使用以下命令:
sudo systemctl daemon-reloadsudo systemctl restart docker
3.下载es
docker pull elasticsearch:7.12.1
4.运行单节点es
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
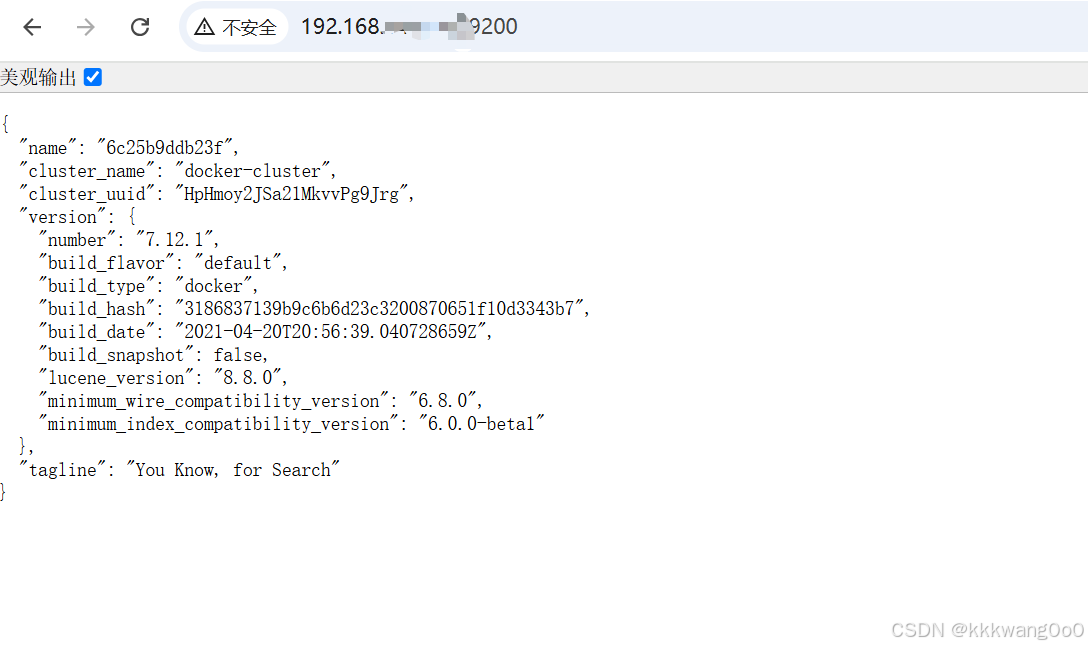
5.访问测试
在本地访问自己虚拟机ip地址的9200端口 可以看到如下输出
6.创建网络
docker network create es-net
7.下载kibana
(注意下载与es版本对应的)
docker pull kibana:7.12.1
8.运行kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1

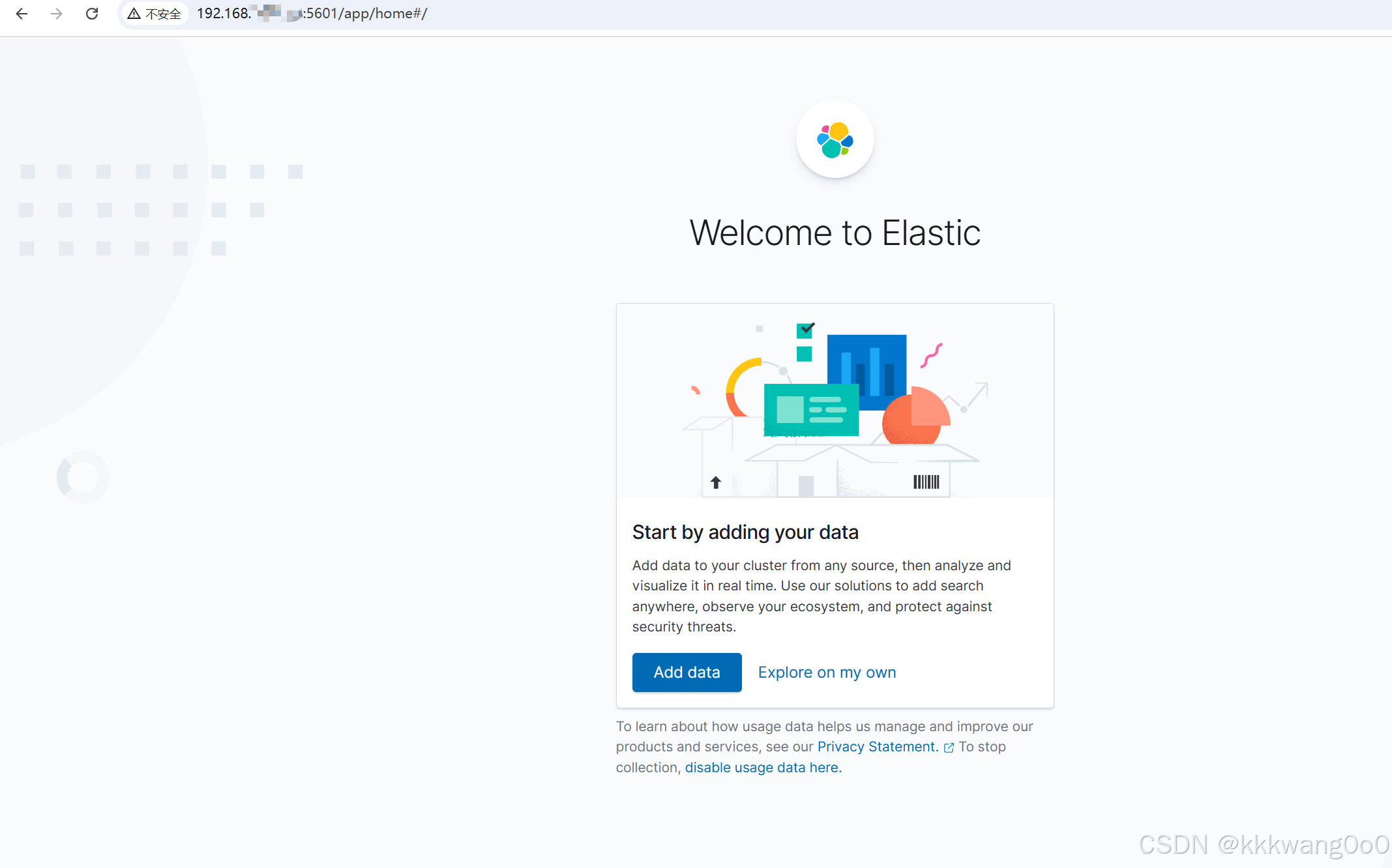
9.测试访问
访问虚拟机的5601端口
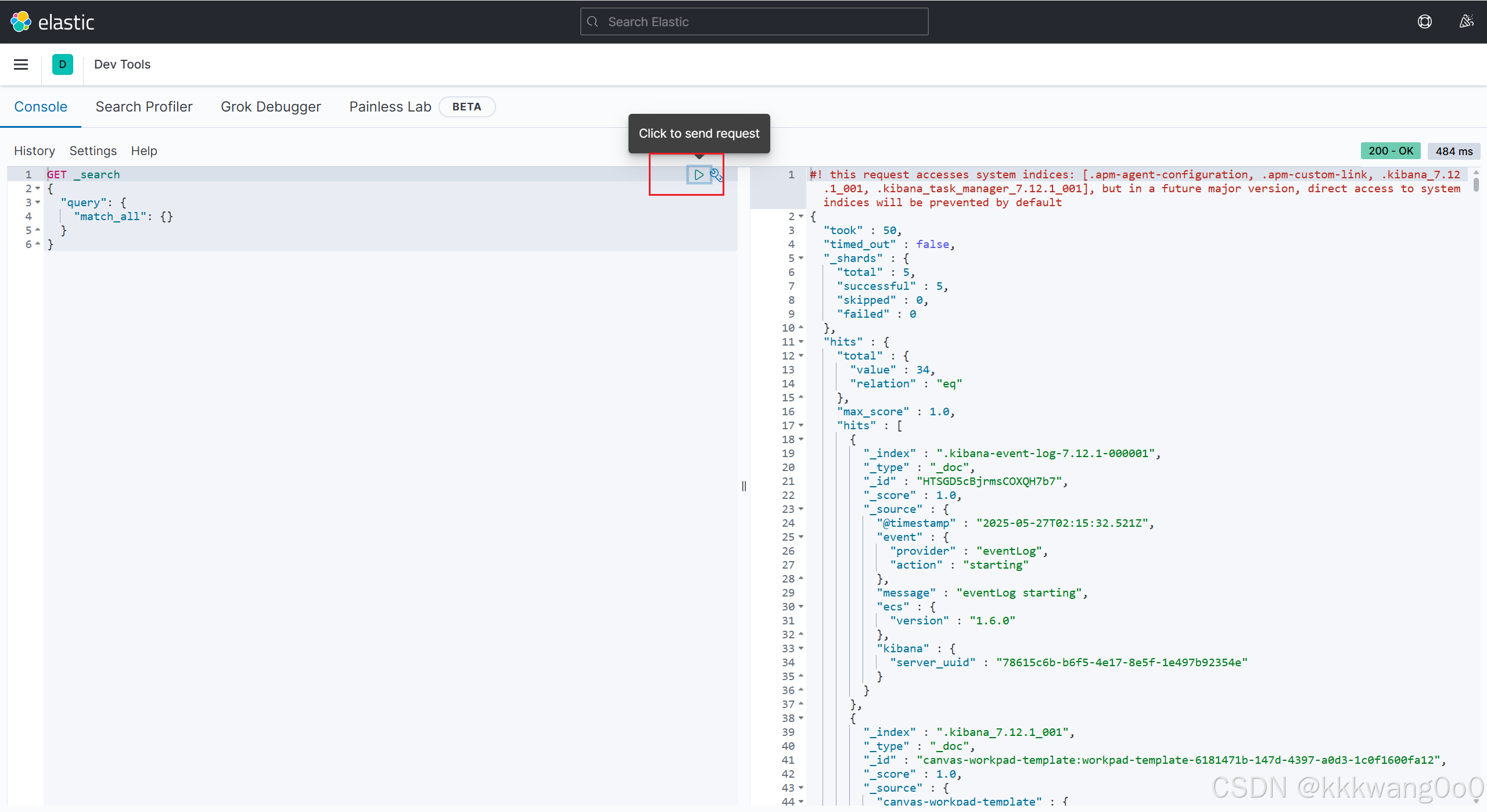
kibana中提供了一个DevTools界面:
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
10.下载IK分词器插件(离线安装)
10.1 下载ik安装包
https://github.com/infinilabs/analysis-ik/releases
(注意要下载对应es版本)
10.1 上传到虚拟机中es挂载的目录
[root@localhost plugins]# docker volume inspect es-plugins
[{"CreatedAt": "2025-05-26T20:04:02-07:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]进入 /var/lib/docker/volumes/es-plugins/_data
将文件上传

10.2 重启容器
docker restart es
10.3 使用kibana测试一下
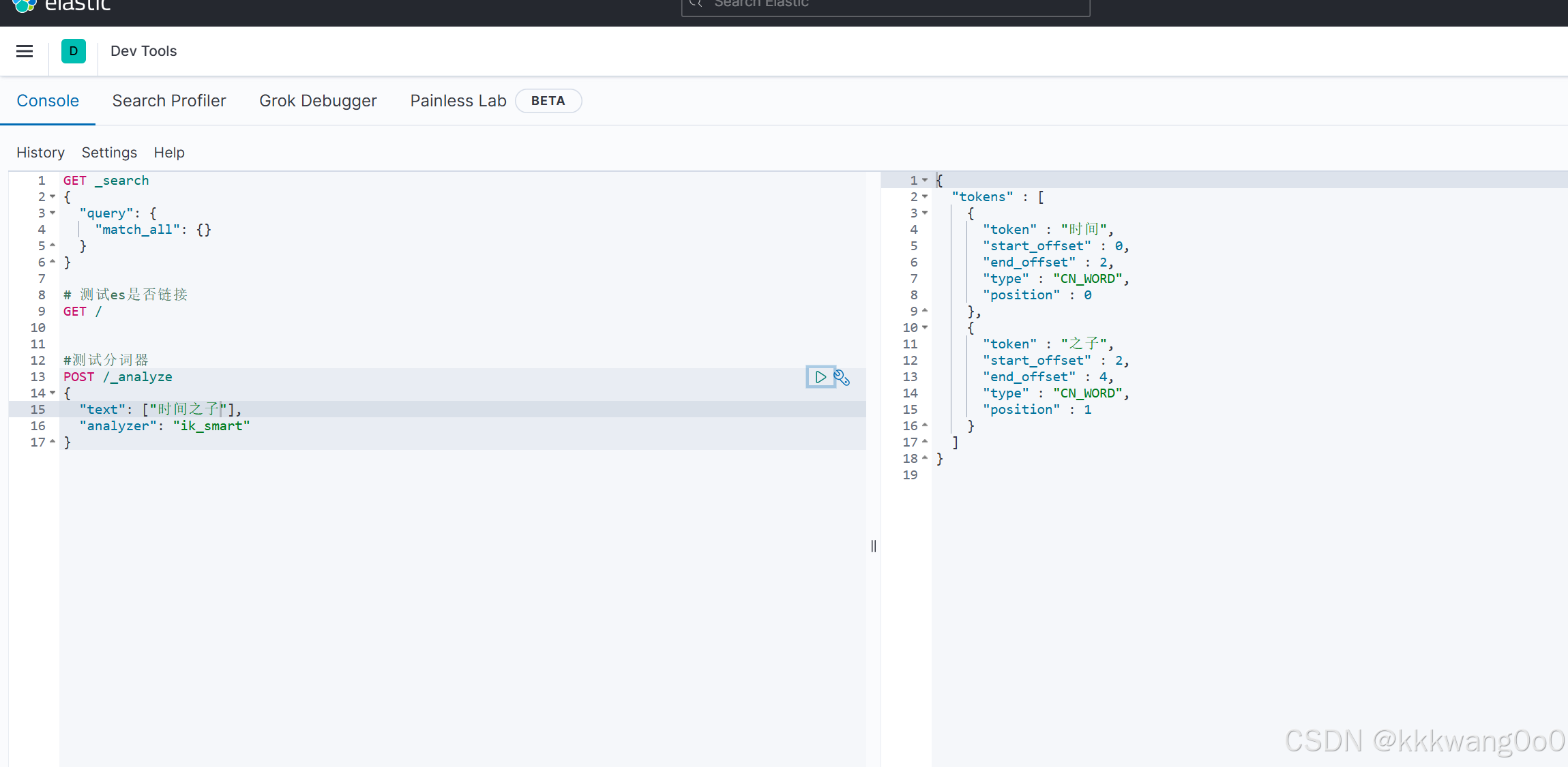
10.4 分词器配置
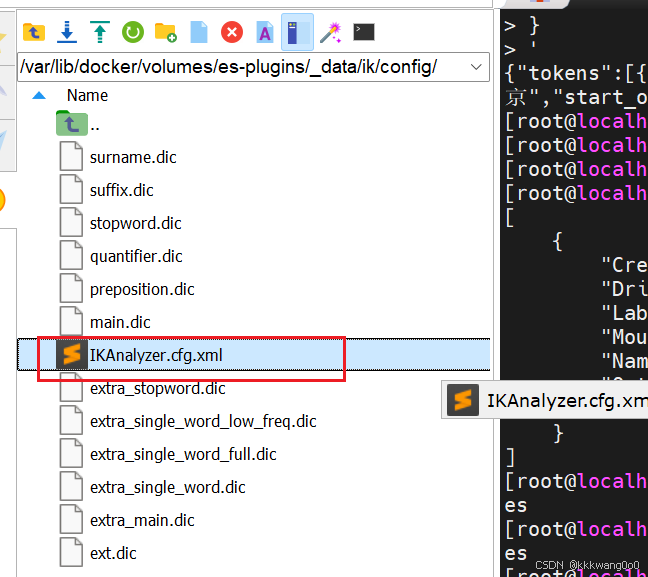
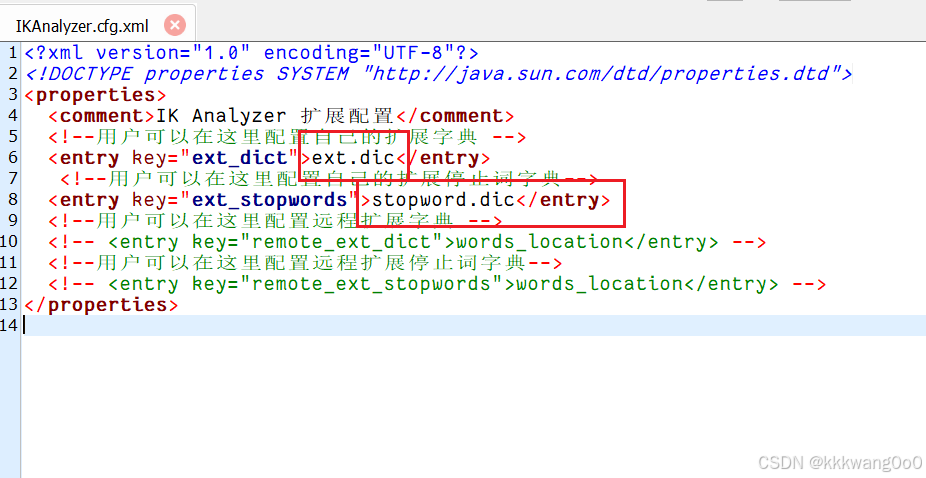
可以添加自己的扩展字典,但是这个文件的编码得是UTF-8
测试一下

核心数据类型
| 类别 | 数据类型 | 描述 |
|---|---|---|
| 字符串 | text | 全文搜索字段,会被分词处理 |
keyword | 精确匹配字段,不分词(如 ID、标签、枚举值) | |
| 数值 | long、integer、short、byte | 整数类型(范围不同) |
double、float、half_float | 浮点数类型(精度不同) | |
scaled_float | 缩放浮点数(适用于货币等需固定精度的值) | |
| 布尔 | boolean | 布尔值(true/false) |
| 日期 | date | 日期时间(支持多种格式,如2025-05-28) |
| 范围 | integer_range、float_range | 数值范围类型 |
date_range、ip_range | 日期范围、IP 范围类型 |
ES使用教程
索引库操作
创建索引库
语法:
PUT /索引名
{"mappings": {"properties": {"字段1":{},"字段2":{},...}}}
}
eg:
# 创建索引库
# demo为索引库名
PUT /demo
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": false},"name":{"type": "object","properties": {"firstName":{"type": "keyword"},"lastName":{"type": "keyword"}}}}}
}
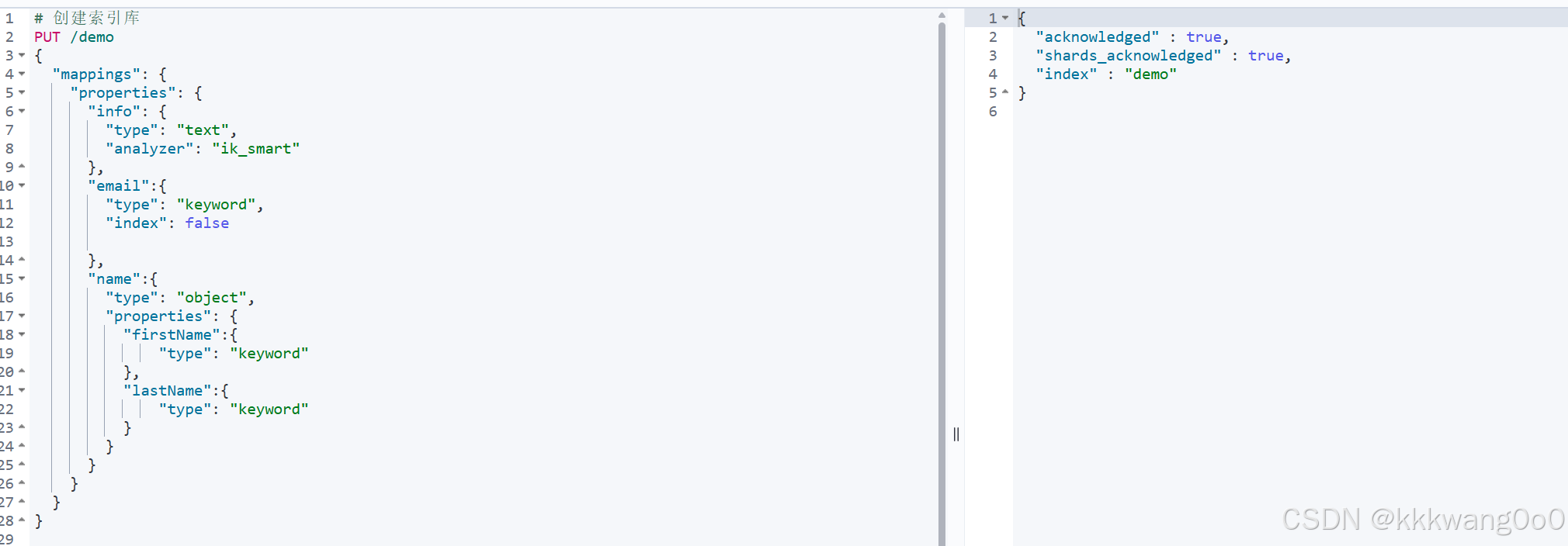
查看索引库
# 查看索引库
GET /demo
删除索引库
# 删除索引库
DELETE /demo
修改索引库
给索引库添加字段
语法:
PUT /索引名/_mapping
{"properties":{"添加的字段":{"添加的属性": "添加的值"}}
}
eg:
# 修改索引库
# 索引库和mapping一旦创建无法修改
# 但是可以添加新的字段
PUT /demo/_mapping
{"properties":{"age":{"type": "integer"}}
}

文档操作
新增文档
语法:
#新增文档DSL语法
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": "值3","字段4": {"子属性1": "值4","子属性2": "值5"}
}
eg:
POST /demo/_doc/1
{"info": "xkbb","email": "0921@karry.cn""name": {"firstName": "俊凯","lastName": "王"}
}
查询文档
语法:
GET /索引库名/_doc/文档id
eg:
# 查询文档
GET /demo/_doc/1
删除文档
语法:
DELETE /索引库名/_doc/文档id
eg:
# 删除文档
DELETE /demo/_doc/1
修改文档
全量修改
跟新增文档类似
语法:
PUT /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": "值3","字段4": {"子属性1": "值4","子属性2": "值5"}
}
eg:
# 修改文档--全量修改
PUT /demo/_doc/1
{"info" : "出生于1999年9月21日","email" : "0921@karry.cn","name" : {"firstName" : "俊凯","lastName" : "王"}
}
增量修改
修改指定字段值
语法:
POST /索引库名/_update/文档id
{"doc": {"字段": "新的字段值"}
}
eg:
# 修改文档--增量修改
POST /demo/_update/1
{"doc": {"info": "十九岁的时差"}
}
DSL查询语法
语法
GET /索引名/_search
{"query": {"查询方式": {}}
}
查询方式
match: 单字段查询multi_match: 多字段查询match_all: 查询所有数据term: 精确查询,查询不分词的字段,因此查询的条件也必须是不分词的词条range: 范围查询,一般对数值类型进行限制geo_bounding_box: 矩形范围查询,左上角到右下角的范围geo_distance:圆形范围查询,以一个点为圆形,一定距离为半径,这个圆范围内的数据
全文查询
- match: 单字段查询
- multi_match: 多字段查询
- match_all: 查询所有数据
字段查询
单字段:
GET /索引名/_search
{"query": {"match": {"字段": "字段值"}}
}
eg:
GET /hotel/_search
{"query": {"match": {"city": "上海"}}
}GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}
多字段:
GET /索引名/_search
{"query": {"multi_match": {"query": "搜索内容","fields": ["字段1","字段2","字段3",...]}}
}
eg:
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand","name","city"]}}
}
查询所有
GET /索引名/_search
{"query": {"match_all": {}}
}
精准查询
- term : 精确查询,查询不分词的字段,因此查询的条件也必须是不分词的词条
GET /索引名/_search
{"query": {"term": {"字段": {"value": "字段值"}}}
}
eg:
GET /hotel/_search
{"query": {"term": {"city": {"value": "上海"}}}
}
范围查询
- range : 范围查询,一般对数值类型进行限制
- 这里的gte代表大于等于,gt则代表大于
- lte代表小于等于,lt则代表小于
GET /索引名/_search
{"query": {"range": {"字段": {"gte": minv,"lte": maxv}}}
}
eg:
GET /hotel/_search
{"query": {"range": {"price": {"gte": 200,"lte": 1000}}}
}
地理位置查询
- geo_bounding_box : 矩形范围查询,左上角到右下角的范围
- geo_distance :圆形范围查询,以一个点为圆形,一定距离为半径,这个圆范围内的数据
矩形范围查询
GET /索引名/_search
{"query": {"geo_bounding_box": {"字段": {"top_left": {"lat": 40.73,"lon": 120.0},"bottom_right": {"lat": 30.01,"lon": 150.0}}}}
}
eg:
GET /hotel/_search
{"query": {"geo_bounding_box": {"location": {"top_left": {"lat": 40.73,"lon": 120.0},"bottom_right": {"lat": 30.01,"lon": 150.0}}}}
}
# 简化表示
GET /hotel/_search
{"query": {"geo_bounding_box": {"location": {"top_left": [ 120.0, 31.73 ],"bottom_right": [ 150.0, 30.01 ]}}}
}
圆形范围查询
GET /索引名/_search
{"query": {"geo_distance": {"distance": "200km","location": {"lat": 40,"lon": 200}}}
}
地理位置表示方式:
"location": "40, -70"
// 或者
"location": { "lat": 40, "lon": -70 }
// 又或者
"location": [ -70, 40 ] // 注意这里经度在前,纬度在后
eg:
GET /hotel/_search
{"query": {"geo_distance": {"distance": "200km","location": {"lat": 31.251433,"lon": 121.47522}}}
}
GET /hotel/_search
{"query": {"geo_distance": {"distance": "200km","location": "31.251433, 121.47522"}}
}
GET /hotel/_search
{"query": {"geo_distance": {"distance": "200km","location": [121.47522, 31.251433]}}
}
复杂查询
function_score:复杂查询,对查询结果进行算分控制
相关性算分
Elasticsearch(ES)的相关性算分是指查询结果与用户搜索词匹配程度的量化评估,分数越高表示文档越相关。ES 默认使用 BM25(Best Matching 25)算法,但也支持自定义评分模型
在Elasticsearch里,“算分” 其实就是给搜索结果 “打分”,判断每个结果和用户搜索的关键词有多匹配,分数越高就排得越靠前。通俗来说,就像老师改卷打分一样,分数高的 “答案”(文档)更符合用户的需求。
算法主要有BM25、TF-IDF、DFR、IB、平滑算法(LMDirichlet 和 LMJelinek-Mercer)、 自定义算法
控制相关性算分
ES通过function_score可以对结果的相关性算分进行控制,functions + boost_mode就是对结果进行控制算法(可以认为是一个函数,对过滤的文档进行控制算分)
-
filter: 过滤条件,决定哪些文档要进行控制 -
weight: 加分 -
boost_mode:在 Elasticsearch(ES)的function_score查询中,boost_mode参数控制着 原始查询分数(query score) 与 自定义函数分数(function score) 如何合并,从而影响最终的文档相关性评分模式有:
multiply:最终分数 = 原始查询分数 × 自定义函数分数
sum:最终分数 = 原始查询分数 + 自定义函数分数
min:最终分数 = min (原始查询分数,自定义函数分数)
max:最终分数 = max (原始查询分数,自定义函数分数)
replace:最终分数 = 自定义函数分数(完全忽略原始查询分数)
GET /索引名/_search
{"query": {"function_score": {"query": {"查询方式": {}},"functions": [{"filter": {},"weight": 10 }],"boost_mode": "sum"}}
}eg:
GET /hotel/_search
{"query": {"function_score": {"query": {"match_all": {}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10 }],"boost_mode": "sum"}}
}
布尔查询
复合查询Boolean Query
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
语法:
GET /索引/_search
{"query": {"bool": {"must": [],"should": [],"must_not": [],"filter": []}}
}
搜索结果处理
排序
- 基本语法:使用
sort参数,指定字段和排序方向。 - 多字段排序:按多个字段依次排序,确保结果唯一性。
- 特殊字段:
_score:按相关性分数排序。_geo_distance:按地理距离排序。_script:按自定义脚本计算结果排序。
语法:
GET /hotel/_search
{"query": {"请求方式": {}},"sort": [{"字段": {"order": "desc"}}]
}
eg:
# 121.479194,31.220115
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 31.220115,"lon": 121.479194},"order": "asc","unit": "km"}}]
}
分页
1.基本分页:from/size 参数
from:结果的起始位置,默认从 0 开始。size:每页返回的文档数量,默认值为 10。- 深度分页问题:当
from过大时(如from=10000),ES 需要先扫描前 10000 条数据,再返回结果,性能会显著下降。官方建议总页数不超过 10000(即from + size ≤ 10000)。
语法:
GET /索引名/_search
{"query": {"搜索方式": {}},"from": 10, "size": 10, "sort": []
}
eg:
GET /hotel/_search
{"query": {"match_all": {}},"from": 10, "size": 10, "sort": [{"price": {"order": "asc"}}]
}
2.深度分页:Scroll API
- Scroll 会创建一个临时的搜索上下文,适合批量处理数据,但不适合实时交互场景。
- 每次请求都会返回新的
_scroll_id,需使用最新的_scroll_id。 - 数据快照:Scroll 基于查询开始时的索引状态,期间的文档更新不会反映在结果中。
语法:
scroll=1m :scroll参数指定上下文保持时间
GET /索引/_search?scroll=1m
{"size": 10,"query": {"match_all": {}}
}
响应中会返回一个 _scroll_id,用于获取下一页
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlY4R0RUTjVvVGhhc2hWYTQyakx4LXcAAAAAAAAULRZWSjV5VExtRlJNZTg5ekxoU2RuMHh3",
GET /_search/scroll
{"scroll": "1m", "scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlY4R0RUTjVvVGhhc2hWYTQyakx4LXcAAAAAAAAULRZWSjV5VExtRlJNZTg5ekxoU2RuMHh3"
}
3.实时分页:search_after 参数
- 必须指定
sort参数,且search_after的值要与sort字段顺序一致。 - 只支持 “下一页” 操作,不支持回退到上一页(需自行维护历史状态)。
- 实时性好,适合实时滚动加载场景(如社交媒体动态)
GET /hotel/_search
{"size": 2,"query": {"match": {"all": "如家"}},"sort": [{"price": "asc"},{"score": "desc"}]
}
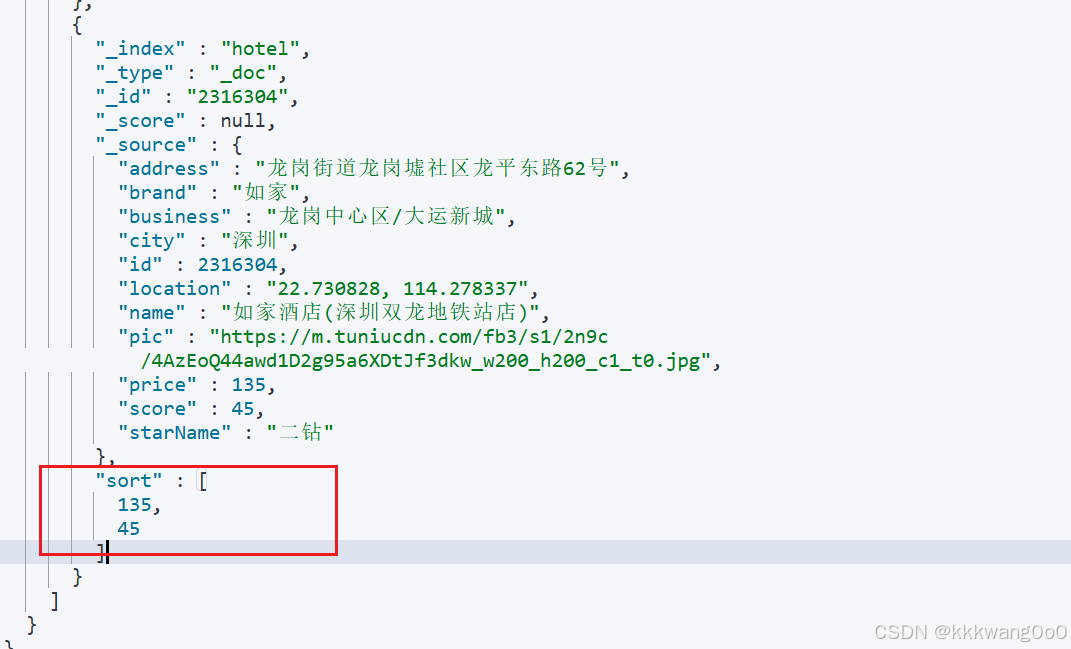
# 根据上一次查询的返回的sort结果为起点
GET /hotel/_search
{"size": 2,"query": {"match": {"all": "如家"}},"sort": [{"price": "asc"},{"score": "desc"}],"search_after": [135,45]
}高亮
在 Elasticsearch(ES)中,高亮是指将搜索结果中与查询匹配的关键词用特殊标签标记出来,以便用户快速识别。
对搜索结果进行高亮展示
语法:
GET /索引名/_search
{"query": {"match": {"字段": "查询字段值" // 查询字段}},"highlight": {"fields": {"字段": {} // 指定要高亮的字段}}
}
高亮参数:
| 参数名 | 作用 |
|---|---|
type | 高亮算法,可选 unified(默认)、plain 或 fvh。 |
fragment_size | 每个高亮片段的最大字符数(默认 100)。 |
number_of_fragments | 返回的高亮片段数量(默认 5)。如果设为 0,返回整个字段内容。 |
no_match_size | 当字段未匹配时,返回的字符数(用于显示上下文)。 |
require_field_match | 仅高亮匹配的字段(默认 true)。如果设为 false,所有字段都会尝试高亮。 |
eg:
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"all": {"pre_tags": "<em>","post_tags": "</em>","require_field_match": "false"}}}
}
数据聚合
聚合分类
| 聚合类型 | 描述 | 常见示例 |
|---|---|---|
| 桶聚合(Bucket) | 将文档分组到不同的 “桶” 中,每个桶满足特定条件,用于数据分组统计。 | terms(按字段值分组)、range(数值范围分组)、date_range(日期范围分组)、 histogram(数值直方图)、date_histogram(日期直方图)、filters(多条件过滤分组) |
| 指标聚合(Metrics) | 对数值型字段进行统计计算,生成数值指标。 | avg(平均值)、sum(总和)、max(最大值)、min(最小值)、 count(计数)、cardinality(去重计数)、percentiles(百分位数)、stats(综合统计) |
| 管道聚合(Pipeline) | 基于其他聚合的结果进行二次计算(依赖父聚合的输出)。 | avg_bucket(桶的平均值)、sum_bucket(桶的总和)、max_bucket(桶的最大值)、 min_bucket(桶的最小值)、percentiles_bucket(桶的百分位数)、derivative(聚合结果的变化率) |
| 矩阵聚合(Matrix) | 计算多个数值字段之间的相关性或统计关系。 | matrix_stats(矩阵统计,如协方差、相关系数) |
桶聚合
相当于数据库里面的group by
语法:
GET /hotel/_search
{"aggs": {"聚合名称": {"桶聚合类型": {"参数": 值,...},"aggs": { // 嵌套聚合(可多层)"子聚合名称": { ... }}}}
}
常用参数:
field:指定聚合的字段(需为分词字段时加.keyword后缀)。size:限制桶的数量(如terms聚合中返回前 N 个高频值)。order:桶的排序方式(如按_count或自定义字段排序)。missing:指定字段缺失时的处理方式(如归入某个桶)。
| 聚合类型 | 描述 |
|---|---|
| terms | 按字段值分组,常用于分类数据聚合(如按标签、状态分组) |
| range | 按数值范围分组(如价格区间、年龄分段) |
| date_range | 按日期范围分组(如按年月、季度、自定义时间区间) |
| histogram | 按数值间隔分组(自动生成等宽区间,适用于连续数值数据) |
| date_histogram | 按时间间隔分组(如按天、小时、分钟生成时间桶) |
| filters | 按多个过滤条件分组(每个桶对应一个过滤条件) |
| missing | 按字段是否存在分组(筛选出缺少指定字段的文档) |
| nested | 对嵌套对象(nested 类型字段)进行聚合(需指定嵌套路径) |
| reverse_nested | 从嵌套文档反向关联到父文档进行聚合(需配合 nested 使用) |
| sampler | 对文档抽样后再聚合(减少数据量,提升性能) |
eg:
GET /索引名/_search
{"size": 0,"query": {"range": {"price": {"gte": 100,"lte": 300}}}, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 5,"order": { "scoreAgg.avg": "desc" }},"aggs": {"scoreAgg": {"stats": {"field": "score"}}}}}
}
指标聚合
语法:
GET /索引名/_search
{"aggs": {"聚合名称": {"指标聚合类型": {"field": "字段名", // 或其他参数...}}}
}
常用参数:
field:指定要计算的字段(必须为数值、日期或地理类型)。script:使用脚本自定义计算逻辑(如"script": "doc['price'].value * 1.1")。missing:指定字段缺失时的默认值(如"missing": 0)。precision_threshold:cardinality专用参数,控制去重精度(值越高越精确,但内存消耗越大)。
| 聚合类型 | 描述 |
|---|---|
| stats | 计算数值字段的多个指标,包括avg、sum、min、max、count |
| avg | 计算数值字段的平均值 |
| sum | 计算数值字段的总和 |
| min | 计算数值字段的最小值 |
| max | 计算数值字段的最大值 |
| value_count | 统计字段值的数量(无论是否唯一) |
| cardinality | 计算字段的唯一值数量(去重计数,近似算法) |
| stats | 一次性返回多个统计指标(count、min、max、avg、sum) |
| extended_stats | 扩展统计指标(包含方差、标准差、平方和等) |
| percentiles | 计算数值字段的百分位数(如中位数、95% 分位数) |
| percentile_ranks | 计算指定值对应的百分位排名(与 percentiles 相反) |
| geo_bounds | 计算地理坐标的边界范围(最小 / 最大经纬度) |
| geo_centroid | 计算地理坐标的质心(中心点) |
| scripted_metric | 使用自定义脚本计算复杂指标(需编写 Painless 脚本) |
eg:
根据brand进行分组,计算每一组的指标
# 通过brand进行分组
GET /hotel/_search
{"size": 0,"aggs": {"brand_agg": {"terms": {"field": "brand","size": 2}, "aggs": {"price_stats": {"stats": {"field": "price"}},"sum_price": {"sum": {"field": "price"}},"min_price": {"min": {"field": "price"}},"max_price":{"max": {"field": "price"}}}}}
}
响应结果:
"aggregations" : {"brand_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 141,"buckets" : [{"key" : "7天酒店","doc_count" : 30,"max_price" : {"value" : 781.0},"min_price" : {"value" : 143.0},"price_stats" : {"count" : 30,"min" : 143.0,"max" : 781.0,"avg" : 446.46666666666664,"sum" : 13394.0},"sum_price" : {"value" : 13394.0}},{"key" : "如家","doc_count" : 30,"max_price" : {"value" : 459.0},"min_price" : {"value" : 127.0},"price_stats" : {"count" : 30,"min" : 127.0,"max" : 459.0,"avg" : 253.2,"sum" : 7596.0},"sum_price" : {"value" : 7596.0}}]}}
管道聚合
语法:
GET /索引名/_search
{"aggs": {"聚合名称": {"管道聚合类型": {"buckets_path": "源聚合路径", // 必选参数,引用上游聚合结果"参数1": "值","参数2": "值",...}}}
}
常用参数:
buckets_path:引用上游聚合的路径(必选)。gap_policy:处理缺失值的策略(如skip、insert_zeros)。format:结果格式化(如"format": "0.00%")。script:自定义计算逻辑。
| 聚合类型 | 描述 |
|---|---|
| avg_bucket | 计算父聚合中多个桶的平均值 |
| sum_bucket | 计算父聚合中多个桶的总和 |
| min_bucket | 计算父聚合中多个桶的最小值 |
| max_bucket | 计算父聚合中多个桶的最大值 |
| stats_bucket | 一次性计算父聚合中多个桶的统计指标(count、min、max、avg、sum) |
| extended_stats_bucket | 计算父聚合中多个桶的扩展统计指标(含方差、标准差等) |
| percentiles_bucket | 计算父聚合中多个桶的百分位数 |
| derivative | 计算相邻桶之间的变化率(如增长率、减少率) |
| cumulative_sum | 计算累积和(如销售额的累计值) |
| moving_avg | 计算滑动平均值(如 7 天移动平均) |
| bucket_sort | 对父聚合的桶进行排序和分页 |
| bucket_selector | 基于条件过滤父聚合的桶(类似 SQL 的 HAVING 子句) |
矩阵聚合
语法:
GET /索引名/_search
{"aggs": {"行维度聚合": {"terms": {"field": "row_field","size": 10},"aggs": {"列维度聚合": {"terms": {"field": "column_field","size": 10},"aggs": {"矩阵指标": { "sum": { "field": "value_field" } }}}}}}
}
| 聚合类型 | 描述 | 核心参数 |
|---|---|---|
| matrix_stats | 计算多个数值字段间的统计关系(协方差、相关性等) | fields(待分析的多字段列表)、missing(缺失值处理) |
| nested | 对嵌套对象(nested 类型字段)进行聚合,生成嵌套矩阵结构 | path(嵌套路径)、子聚合(如terms、stats) |
| reverse_nested | 从嵌套文档反向关联回父文档,补全矩阵维度 | path(反向路径)、子聚合(如terms、stats) |
自动补全
拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。
拼音分词插件地址:https://github.com/medcl/elasticsearch-analysis-pinyin
eg:
GET /_analyze
{"text": ["我的小名是安安"],"analyzer": "pinyin"
}
拼音分词器会将每个字分出拼音
如下:
{"tokens" : [{"token" : "wo","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 0},{"token" : "wdxmsaa","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 0},{"token" : "de","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 1},{"token" : "xiao","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 2},{"token" : "ming","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 3},{"token" : "shi","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 4},{"token" : "an","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 5},{"token" : "an","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 6}]
}自定义分词器
在 Elasticsearch 中,自定义分词器(Analyzer)由三个主要组件构成:字符过滤器(Character Filters)、分词器(Tokenizer)和词元过滤器(Token Filters).
elasticsearch中分词器(analyzer)的组成包含三部分:
字符过滤器(Character Filters)
它的作用是在分词之前对原始文本进行预处理。
分词器(Tokenizer)
分词器的任务是将经过预处理的文本切割成一个个独立的词元(Token),可以把它看作是文本的 “切割机”,处理粒度为词语级。
词元过滤器(Token Filters)
词元过滤器是对分词器输出的词元进行进一步的加工处理,可将其视为词元的 “加工厂”,处理粒度同样是词语级。它可以执行多种操作,例如将词元转换为小写、移除停用词(像 “的”“是” 这类常见但无实际意义的词)、提取词干(例如把 “running” 处理成 “run”)、添加同义词,以及在你使用的配置中,将中文转换为拼音等。
语法:
{"settings": {"analysis": {"analyzer": {"自定义分词器名称": {"type": "custom", // 声明为自定义类型"char_filter": ["字符过滤器1", "字符过滤器2"], // 可选,可多个"tokenizer": "分词器名称", // 必选,只能一个"filter": ["词元过滤器1", "词元过滤器2"] // 可选,可多个}},"char_filter": { ... }, // 字符过滤器定义"tokenizer": { ... }, // 分词器定义"filter": { ... } // 词元过滤器定义}}
}
字符过滤器:
| 过滤器类型 | 描述 |
|---|---|
html_strip | 移除 HTML 标签,保留文本内容 |
mapping | 基于映射规则替换字符(如将 “&” 替换为 “and”) |
pattern_replace | 使用正则表达式替换文本 |
icu_normalizer | Unicode 文本标准化(基于 ICU 库) |
分词器类型:
| 分词器类型 | 描述 |
|---|---|
standard | 默认分词器,按词切分,处理大多数语言,支持停用词 |
simple | 按非字母字符切分,将文本转为小写 |
whitespace | 按空白字符(空格、制表符等)切分,不转换大小写 |
stop | 类似 simple,但支持停用词过滤 |
keyword | 不分词,将整个文本作为单个词元 |
pattern | 使用正则表达式切分文本 |
language | 特定语言分词器(如英语、中文等),针对特定语言优化 |
ngram | 生成 N-gram 词元(连续字符组合) |
edge_ngram | 生成边缘 N-gram 词元(从开头开始的连续字符组合) |
ik_max_word | IK 中文分词器,细粒度切分(你示例中使用的分词器) |
ik_smart | IK 中文分词器,粗粒度切分 |
词元过滤器:
| 过滤器类型 | 描述 |
|---|---|
lowercase | 将词元转为小写 |
uppercase | 将词元转为大写 |
stop | 移除停用词(如 “the”, “and” 等) |
stemmer | 词干提取(如将 “running” 转为 “run”) |
snowball | 基于 Snowball 算法的词干提取器 |
ngram | 生成词元的 N-gram 变体 |
edge_ngram | 生成词元的边缘 N-gram 变体 |
synonym | 同义词替换 |
pinyin | 拼音转换过滤器(你示例中使用的过滤器) |
trim | 去除词元前后的空白字符 |
unique | 移除重复词元 |
length | 过滤指定长度范围外的词元 |
asciifolding | 将非 ASCII 字符转换为等效的 ASCII 字符(如将 “é” 转为 “e”) |
eg:
定义了一个名为 my_analyzer 的自定义分词器,它使用 ik_max_word 分词器对中文进行细粒度分词,并通过 pinyin 词元过滤器将中文转换为拼音。这个配置允许你通过拼音搜索中文内容。
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word", // 使用 IK 分词器进行中文分词"filter": "py" // 使用自定义的拼音过滤器}},"filter": {"py": { "type": "pinyin", // 指定为拼音过滤器"keep_full_pinyin": false, // 不保留全拼"keep_joined_full_pinyin": true, // 保留连接的全拼"keep_original": true, // 保留原始词元"limit_first_letter_length": 16, // 限制首字母缩写长度"remove_duplicated_term": true, // 移除重复词元"none_chinese_pinyin_tokenize": false // 非中文不进行拼音转换}}}}
}
RestHighLevelClient
通过JavaRestClient操作索引库,就像RedisTemplate操作Redis一样,是Java提供的可以与索引库交互的一系列接口
引入依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
指定对应的版本号(与之前下载的es版本保持一致):
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
创建表便于测试:
DROP TABLE IF EXISTS `tb_hotel`;
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店名称',`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店地址',`price` int(10) NOT NULL COMMENT '酒店价格',`score` int(2) NOT NULL COMMENT '酒店评分',`brand` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店品牌',`city` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '所在城市',`star_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店星级,1星到5星,1钻到5钻',`business` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '商圈',`latitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '纬度',`longitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '经度',`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店图片',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Compact;(数据来源—黑马程序员)
索引操作:
| 操作类型 | 功能描述 | 核心类与方法 |
|---|---|---|
| 创建索引 | 创建新索引 | IndicesClient.create(CreateIndexRequest) |
| 删除索引 | 删除现有索引 | IndicesClient.delete(DeleteIndexRequest) |
| 检查索引存在 | 判断索引是否存在 | IndicesClient.exists(GetIndexRequest) |
| 获取索引设置 | 获取索引配置信息 | IndicesClient.getSettings(GetSettingsRequest) |
| 更新索引设置 | 修改索引配置 | IndicesClient.putSettings(PutSettingsRequest) |
| 获取索引映射 | 获取索引字段映射 | IndicesClient.getMapping(GetMappingsRequest) |
| 更新索引映射 | 修改索引字段映射 | IndicesClient.putMapping(PutMappingRequest) |
| 刷新索引 | 使最近的更改可搜索 | IndicesClient.refresh(RefreshRequest) |
| 关闭索引 | 关闭索引(释放资源) | IndicesClient.close(CloseIndexRequest) |
| 打开索引 | 重新打开已关闭的索引 | IndicesClient.open(OpenIndexRequest) |
| 索引别名管理 | 添加 / 删除索引别名 | IndicesClient.updateAliases(UpdateAliasesRequest) |
| 查看索引健康状态 | 获取索引健康统计信息 | ClusterClient.health(ClusterHealthRequest) |
文档操作:
| 操作类型 | 功能描述 | 核心类与方法 |
|---|---|---|
| 添加文档 | 插入新文档(自动生成 ID) | DocumentClient.index(IndexRequest) |
| 添加 / 更新文档 | 插入或替换文档(指定 ID) | DocumentClient.index(IndexRequest) |
| 获取文档 | 根据 ID 获取文档 | DocumentClient.get(GetRequest) |
| 更新文档 | 部分更新文档字段 | DocumentClient.update(UpdateRequest) |
| 删除文档 | 根据 ID 删除文档 | DocumentClient.delete(DeleteRequest) |
| 检查文档存在 | 判断文档是否存在 | DocumentClient.exists(GetRequest) |
| 批量操作 | 批量执行增删改操作 | BulkClient.bulk(BulkRequest) |
| 批量导入 | 从源索引复制文档 | ReindexClient.reindex(ReindexRequest) |
| 文档计数 | 统计匹配条件的文档数量 | DocumentClient.count(CountRequest) |
查询操作:
| 操作类型 | 功能描述 | 核心类与方法 |
|---|---|---|
| 基本查询 | 执行标准搜索 | SearchClient.search(SearchRequest) |
| 布尔查询 | 组合多个查询条件 | BoolQueryBuilder.must()/should()/must_not() |
| 全文查询 | 文本搜索(分词匹配) | QueryBuilders.matchQuery() |
| 精确查询 | 精确匹配单个值 | QueryBuilders.termQuery() |
| 范围查询 | 数值 / 日期范围过滤 | QueryBuilders.rangeQuery() |
| 多字段查询 | 多字段同时搜索 | QueryBuilders.multiMatchQuery() |
| 前缀查询 | 按前缀匹配 | QueryBuilders.prefixQuery() |
| 通配符查询 | 使用通配符匹配 | QueryBuilders.wildcardQuery() |
| 正则查询 | 使用正则表达式匹配 | QueryBuilders.regexpQuery() |
| 地理查询 | 基于地理位置的查询 | QueryBuilders.geoDistanceQuery() |
| 排序 | 对查询结果排序 | SearchSourceBuilder.sort(FieldSortBuilder) |
| 分页 | 实现结果分页 | SearchSourceBuilder.from()/size() 或 searchAfter() |
| 聚合查询 | 分组统计与计算 | AggregationBuilders.terms()/avg()/sum()/histogram() |
| 高亮显示 | 搜索结果关键词高亮 | SearchSourceBuilder.highlighter(HighlightBuilder) |
| 滚动查询 | 大数据量分页(Scroll API) | ScrollRequest + ClearScrollRequest |
| 异步查询 | 非阻塞方式执行查询 | SearchClient.searchAsync() |
索引操作:
使用Java RestClient实现如下操作:
PUT /hotel
{"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address": {"type": "text"},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword","copy_to": "all"},"starName":{"type": "keyword"},"business":{"type": "text","analyzer": "ik_max_word"},"location":{"type": "geo_point","index": false},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}GET /hotel DELETE /hotelPUT /hotel/_mapping
{"properties":{"age":{"type": "integer"}}
}初始化客户端
- 功能:初始化 Elasticsearch 客户端
- 关键 API:
RestHighLevelClient构造函数RestClient.builder()
- 流程:
- 创建
RestHighLevelClient实例 - 通过
RestClient.builder()设置连接地址
- 创建
/*** 创建客户端*/
@BeforeEach
public void setUp() {this.client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.***.***", 9200)));
}
创建索引
- 功能:创建名为 “hotel” 的索引并设置映射
- 关键 API:
CreateIndexRequestclient.indices().create()request.source()
- 流程:
- 创建索引创建请求
CreateIndexRequest - 设置索引映射 JSON 作为请求体
- 调用
indices().create()发送请求创建索引
- 创建索引创建请求
/*** 创建索引* 相当于发送* PUT /hotel* {** }* @throws IOException*/
@Test
public void testCreateHotelIndex() throws IOException {// 1.创建请求 相当于 PUT /hotelCreateIndexRequest request = new CreateIndexRequest("hotel");// 2.指定请求体request.source(CreateHotelIndex, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
查询索引
- 功能:查询 “hotel” 索引的映射信息
- 关键 API:
GetIndexRequestindices().exists()indices().get()
- 流程:
- 创建索引查询请求
GetIndexRequest - 先检查索引是否存在
indices().exists() - 若存在,调用
indices().get()获取索引映射 - 解析并打印映射信息
- 创建索引查询请求
/*** 查询索引* GET /hotel*/
@Test
public void testGetHotelIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("hotel");IndicesClient http = client.indices();if (!http.exists(request, RequestOptions.DEFAULT)) {System.out.println("索引不存在");return;}GetIndexResponse response = http.get(request, RequestOptions.DEFAULT);Map<String, MappingMetadata> mappings = response.getMappings();for (MappingMetadata mapping : mappings.values()) {System.out.println(mapping.getSourceAsMap());}
}
删除索引
- 功能:删除 “hotel” 索引
- 关键 API:
DeleteIndexRequestclient.indices().delete()
- 流程:
- 创建索引删除请求
DeleteIndexRequest - 调用
indices().delete()发送删除请求 - 根据响应
isAcknowledged()判断是否删除成功
- 创建索引删除请求
/*** 查询索引* GET /hotel*/
@Test
public void testGetHotelIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("hotel");IndicesClient http = client.indices();if (!http.exists(request, RequestOptions.DEFAULT)) {System.out.println("索引不存在");return;}GetIndexResponse response = http.get(request, RequestOptions.DEFAULT);Map<String, MappingMetadata> mappings = response.getMappings();for (MappingMetadata mapping : mappings.values()) {System.out.println(mapping.getSourceAsMap());}
}
新增字段
- 功能:更新 “hotel” 索引的映射(添加字段)
- 关键 API:
PutMappingRequestclient.indices().putMapping()
- 流程:
- 创建映射更新请求
PutMappingRequest - 设置新增字段的 JSON 作为请求体
- 调用
indices().putMapping()发送请求更新映射
- 创建映射更新请求
/*** 修改索引(其实是添加字段)* PUT /hotel/_mapping* {* "properties":{* "age":{* "type": "integer"* }* }* }*/
@Test
public void updateHotelIndex() throws IOException {// 1.创建请求PutMappingRequest request = new PutMappingRequest("hotel");// 2.设置参数request.source("{\n" +" \"properties\": {\n" +" \"age\": {\n" +" \"type\": \"integer\"\n" +" }\n" +" }\n" +"}", XContentType.JSON);// 3. 发送请求更新 mappingclient.indices().putMapping(request, RequestOptions.DEFAULT);
}
释放资源
/*** 释放资源* @throws IOException*/
@AfterEach
void tearDown() throws IOException {this.client.close();
}
文档操作
IndexRequest:增 / 全量更新DeleteRequest:删除UpdateRequest:增量更新GetRequest:查询BulkRequest:批量操作
初始化客户端
@BeforeEach
public void setUp() {this.client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.140.138", 9200)));
}
添加文档
- 功能:向 ES 添加单个文档
- 关键 API:
IndexRequest:创建索引请求client.index():执行文档添加
- 流程:
- 从数据库获取酒店数据
- 转换为 ES 文档对象(HotelDoc)
- 转 JSON 字符串
- 创建
IndexRequest并指定 ID - 设置 JSON 源并发送请求
/*** 添加文档* POST /索引库名/_doc/文档id* {* "字段1": "值1",* "字段2": "值2",* "字段3": "值3",* "字段4": {* "子属性1": "值4",* "子属性2": "值5"* }* }*/
@Test
public void testAddDocument() throws IOException {// 1. 获得数据Hotel hotel = hotelService.getById(45870);// 2.封装成文档对象HotelDoc hotelDoc = new HotelDoc(hotel);// 3.转换成json对象String json = JSON.toJSONString(hotelDoc);// 1. 创建索引请求 相当于 /索引库名/_doc/文档idIndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 2. 指定文档内容request.source(json, XContentType.JSON);// 3. 发送请求client.index(request, RequestOptions.DEFAULT);
}
删除文档
- 功能:删除 ES 中的文档
- 关键 API:
DeleteRequest:创建删除请求client.delete():执行文档删除
- 流程:
- 创建
DeleteRequest并指定索引和 ID - 发送删除请求
- 打印操作结果(Result)
- 创建
/*** 删除文档* DELETE /索引库名/_doc/文档id*/
@Test
public void testDeleteDocument() throws IOException {DeleteRequest request = new DeleteRequest("hotel", "45870");DeleteResponse deleted = client.delete(request, RequestOptions.DEFAULT);System.out.println(deleted.getResult());
}
修改文档
全量修改
- 功能:全量更新文档(覆盖方式)
- 关键 API:
IndexRequest:本质是重新索引文档client.index():通过索引请求实现全量更新
- 流程:
- 修改酒店数据(如名称)
- 转换为文档对象并转 JSON
- 创建
IndexRequest(同添加文档) - 发送请求(ES 会覆盖原有文档)
/*** 全量修改* PUT /索引库名/_doc/文档id* {* "字段1": "值1",* "字段2": "值2",* "字段3": "值3",* "字段4": {* "子属性1": "值4",* "子属性2": "值5"* }* }*/
@Test
public void testUpdateDocumentByAll() throws IOException {// 1. 获得数据Hotel hotel = hotelService.getById(45870);hotel.setName("测试数据");// 2.封装成文档对象HotelDoc hotelDoc = new HotelDoc(hotel);// 3.转换成json对象String json = JSON.toJSONString(hotelDoc);// 1. 创建索引请求 相当于 /索引库名/_doc/文档idIndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 2. 指定文档内容request.source(json, XContentType.JSON);// 3. 发送请求client.index(request, RequestOptions.DEFAULT);
}
增量修改
- 功能:增量更新文档字段
- 关键 API:
UpdateRequest:创建更新请求client.update():执行字段级更新
- 流程:
- 创建
UpdateRequest并指定索引和 ID - 通过
doc()方法设置需要更新的字段 - 发送请求实现增量更新
- 创建
/*** 增量修改* POST /索引库名/_update/文档id* {* "doc": {* "字段": "新的字段值"* }* }*/
@Test
public void testUpdateDocumentByField() throws IOException {UpdateRequest request = new UpdateRequest("hotel", "45870");request.doc("name","测试数据2");client.update(request, RequestOptions.DEFAULT);
}
查询文档
- 功能:根据 ID 查询文档
- 关键 API:
GetRequest:创建查询请求client.get():获取文档内容
- 流程:
- 创建
GetRequest并指定索引和 ID - 先检查文档是否存在(
client.exists()) - 若存在则获取文档并打印源数据
- 创建
/*** 查询文档* GET /索引库名/_doc/文档id*/
@Test
public void testGetDocument() throws IOException {GetRequest request = new GetRequest("hotel", "45870");if (!client.exists(request, RequestOptions.DEFAULT)) {System.out.println("文档不存在!");return;}GetResponse response = client.get(request, RequestOptions.DEFAULT);System.out.println(response.getSourceAsString());
}
释放资源
/*** 释放资源* @throws IOException*/
@AfterEach
public void tearDown() throws IOException {client.close();
}
批量导入
BulkRequest将数据库中的数据批量导入ES中
- 功能:批量导入大量文档
- 关键 API:
BulkRequest:批量操作请求client.bulk():执行批量操作
- 流程:
- 从数据库获取所有酒店数据
- 创建
BulkRequest - 循环添加
IndexRequest(每个文档一个请求) - 发送批量请求一次性导入
/*** 运用BulkRequest批量导入数据*/
@Test
public void testBulkAddDocument() throws IOException {List<Hotel> hotelList = hotelService.list();BulkRequest request = new BulkRequest();for (Hotel hotel : hotelList) {HotelDoc hotelDoc = new HotelDoc(hotel);request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}client.bulk(request, RequestOptions.DEFAULT);
}
查询操作
语法
1. 客户端初始化
| 方法名 | 功能描述 | 参数 | 返回类型 |
|---|---|---|---|
RestHighLevelClient | 创建高级 REST 客户端 | RestClient.builder() | 客户端实例 |
close() | 关闭客户端 | 无 | void |
2. 文档查询操作
| 方法名 | 功能描述 | 参数 | 返回类型 |
|---|---|---|---|
get() | 根据 ID 查询单个文档 | GetRequest(index, id) | GetResponse |
search() | 搜索文档(核心查询方法) | SearchRequest(index) | SearchResponse |
mget() | 批量查询多个文档 | MultiGetRequest | MultiGetResponse |
3. 核心搜索 API
(SearchRequest)
| 方法名 | 功能描述 | 参数示例 | 返回类型 |
|---|---|---|---|
source() | 设置查询字段 | source("field1", "field2") | SearchRequest |
query() | 设置查询条件 | QueryBuilders.matchQuery("field", "value") | SearchRequest |
from()/size() | 设置分页 | from(0), size(10) | SearchRequest |
sort() | 设置排序 | SortBuilders.fieldSort("field").order(SortOrder.DESC) | SearchRequest |
aggregation() | 设置聚合查询 | AggregationBuilders.terms("term_agg").field("field") | SearchRequest |
execute() | 执行搜索 | RequestOptions.DEFAULT | SearchResponse |
4. 常用查询
(QueryBuilders)
| 方法名 | 功能描述 | 参数示例 | 返回类型 |
|---|---|---|---|
matchQuery() | 全文匹配查询 | field, text, operator | QueryBuilder |
termQuery() | 精确词项查询 | field, value | QueryBuilder |
rangeQuery() | 范围查询 | field, from, to | QueryBuilder |
boolQuery() | 布尔组合查询 | must(), should(), mustNot() | QueryBuilder |
wildcardQuery() | 通配符查询 | field, wildcardPattern | QueryBuilder |
prefixQuery() | 前缀查询 | field, prefix | QueryBuilder |
5. 聚合查询
(AggregationBuilders)
| 方法名 | 功能描述 | 参数示例 | 返回类型 |
|---|---|---|---|
terms() | 术语聚合(分组统计) | name, field | TermsAggregationBuilder |
avg() | 平均值聚合 | name, field | AvgAggregationBuilder |
sum() | 求和聚合 | name, field | SumAggregationBuilder |
dateHistogram() | 日期直方图聚合 | name, field, interval | DateHistogramAggregationBuilder |
nested() | 嵌套字段聚合 | name, path, sub-aggregation | NestedAggregationBuilder |
6. 高级查询功能
| 方法名 | 功能描述 | 参数示例 | 返回类型 |
|---|---|---|---|
scroll() | 滚动查询(处理大数据量) | SearchRequest, TimeValue | SearchResponse |
msearch() | 批量搜索 | MultiSearchRequest | MultiSearchResponse |
suggest() | 自动补全 / 建议查询 | SuggestRequest, SuggestBuilder | SuggestResponse |
初始化客户端
private RestHighLevelClient client;@BeforeEach
public void setUp() {this.client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.***.***", 9200)));
}
@AfterEach
public void tearDown() throws IOException {this.client.close();
}
查询所有数据
- 功能:查询索引中所有文档
- 关键 API:
SearchRequest("hotel")QueryBuilders.matchAllQuery()client.search()
- 流程:
- 创建搜索请求,指定索引名
- 设置查询类型为
match_all - 执行搜索并遍历结果
/*** 查询所有* GET /索引名/_search* {* "query": {* "match_all": {}* }* }*/
@Testpublic void testSearchAll() throws IOException {// 1.创建请求 相当于 /索引名/_searchSearchRequest request = new SearchRequest("hotel");// 2.指定查询方式 相当于 { "query": { "match_all": {} } }request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求 相当于 发送 get 请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
单字段查询
- 功能:单字段全文搜索
- 关键 API:
QueryBuilders.matchQuery("name", "上海")
- 流程:
- 指定字段名
name和搜索词上海 - 执行全文搜索(分词匹配)
- 指定字段名
/*** GET /索引/_search* {* "query": {* "match": {* "字段": "字段值"* }* }* }*/
@Test
public void testSearchBySingleField() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.matchQuery("name", "上海"));SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
多字段查询
- 功能:多字段全文搜索
- 关键 API:
QueryBuilders.multiMatchQuery("上海", "name", "city")
- 流程:
- 在
name和city字段中同时搜索上海 - 合并匹配结果
- 在
/*** 多字段查询* GET /索引名/_search* {* "query": {* "multi_match": {* "query": "搜索内容",* "fields": ["字段1","字段2","字段3",...]* }* }* }*/@Test
public void testSearchByMultiField() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.multiMatchQuery("上海", "name", "city"));SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));}
精确查询
- 功能:精确查询(不分词)
- 关键 API:
QueryBuilders.termQuery("city", "上海")
- 流程:
- 对
city字段进行精确匹配 - 仅返回值为
上海的文档
- 对
/*** 精准查询* GET /索引名/_search* {* "query": {* "term": {* "字段": {* "value": "字段值"* }* }* }* }*/
@Test
public void testTermSearch() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.termQuery("city", "上海"));SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
范围查询
- 功能:范围查询
- 关键 API:
QueryBuilders.rangeQuery("price").gte(100).lte(200)
- 流程:
- 筛选
price字段在 100-200 之间的文档
- 筛选
/*** 范围查询* GET /索引名/_search* {* "query": {* "range": {* "字段": {* "gte": minv,* "lte": maxv* }* }* }* }*/
@Test
public void testRangeSearch() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(200));SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
矩形范围查询
- 功能:矩形范围地理位置查询
- 关键 API:
QueryBuilders.geoBoundingBoxQuery("location")
- 流程:
- 指定矩形区域(左上角和右下角坐标)
- 返回
location字段落在区域内的文档
/*** 矩形范围查询* GET /索引名/_search* {* "query": {* "geo_bounding_box": {* "字段": {* "top_left": {* "lat": 40.73,* "lon": 120.0* },* "bottom_right": {* "lat": 30.01,* "lon": 150.0* }* }* }* }* }*/
@Test
public void testGeoBoxSearch() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.geoBoundingBoxQuery("location").setCorners(40.73, 120.0, 30.01, 150.0));SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
圆形范围查询
- 功能:圆形范围地理位置查询
- 关键 API:
QueryBuilders.geoDistanceQuery("location")
- 流程:
- 指定中心点坐标和距离半径(200km)
- 返回距离中心点 200km 内的文档
/*** 圆形范围查询* GET /索引名/_search* {* "query": {* "geo_distance": {* "distance": "200km",* "location": {* "lat": 40,* "lon": 200* }* }* }* }*/
@Test
public void testGeoDistanceSearch() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.geoDistanceQuery("location").point(40, 200).distance(200, DistanceUnit.KILOMETERS));SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
复杂查询
- 功能:算分控制查询
- 关键 API:
QueryBuilders.functionScoreQuery()
- 流程:
- 基础查询:品牌为
如家 - 过滤条件:城市为
上海 - 权重调整:符合过滤条件的文档得分 +10
- 算分模式:SUM(叠加权重)
- 基础查询:品牌为
/*** 复杂查询 --- 算分控制* GET /索引名/_search* {* "query": {* "function_score": {* "query": {* "查询方式": {** }* },* "functions": [* {* "filter": {},* "weight": 10* }* ],* "boost_mode": "sum"* }* }* }*/
@Test
public void testComplexSearch() throws IOException {// 1.构建请求 /索引名/_searchSearchRequest request = new SearchRequest("hotel");// 2.构建请求体// 2.1 基础查询 query{}MatchQueryBuilder query = QueryBuilders.matchQuery("brand", "如家");// 2.2 构建functions ScoreFunctionBuilders// 构建过滤器 filter{}MatchQueryBuilder filter = QueryBuilders.matchQuery("city", "上海");// 权重函数 weight{}WeightBuilder weight = ScoreFunctionBuilders.weightFactorFunction(10);// 结合生成 functions{}FunctionScoreQueryBuilder.FilterFunctionBuilder functions = new FunctionScoreQueryBuilder.FilterFunctionBuilder(filter, weight);// 2.3 指定boost_modeFunctionScoreQueryBuilder scoreQuery = QueryBuilders.functionScoreQuery(query,new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{functions}).boostMode(CombineFunction.SUM);// 2.4 构建请求 /索引名/_search {}request.source().query(scoreQuery);// 3. 发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit-> System.out.println(hit.getSourceAsMap()));
}
布尔查询
- 功能:布尔组合查询
- 关键 API:
BoolQueryBuilder.must()BoolQueryBuilder.should()BoolQueryBuilder.mustNot()BoolQueryBuilder.filter()
- 流程:
must:城市必须为上海should:品牌为如家或汉庭(提高匹配度)mustNot:价格不得 >= 500filter:星级必须为二钻(不参与算分
/*** 布尔查询* GET /索引/_search* {* "query": {* "bool": {* "must": [],* "should": [],* "must_not": [],* "filter": []* }* }* }*/
@Test
public void testBooleanQuery() throws IOException {// 1. 创建请求SearchRequest request = new SearchRequest("hotel");BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 2. 添加查询条件// 2.1 添加must条件boolQuery.must(QueryBuilders.termQuery("city", "上海"));// 2.2 添加should条件boolQuery.should(QueryBuilders.multiMatchQuery("brand", "如家"));boolQuery.should(QueryBuilders.multiMatchQuery("brand", "汉庭"));// 2.3 添加must_not条件boolQuery.mustNot(QueryBuilders.rangeQuery("price").gte(500));// 2.4 添加filter条件boolQuery.filter(QueryBuilders.termQuery("starName", "二钻"));// 3. 设置请求request.source().query(boolQuery);// 4. 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
排序
- 功能:结果排序
- 关键 API:
SearchSourceBuilder.sort()
- 流程:
- 先按
price升序排序 - 价格相同的按
score降序排序 - 返回前 20 条结果
- 先按
/*** 对搜索结果进行排序* GET /hotel/_search* {* "query": {* "match_all": {}* },* "sort": [* {"字段": {"order": "desc"}}* ]* }*/
@Test
public void testSortResult() throws IOException {// 1.构建请求SearchRequest request = new SearchRequest("hotel");// 2.创建请求体SearchSourceBuilder sortQuery = new SearchSourceBuilder();// 相当于 query{"match_all":{}}sortQuery.query(QueryBuilders.matchAllQuery());sortQuery.sort(new FieldSortBuilder("price").order(SortOrder.ASC));sortQuery.sort(new FieldSortBuilder("score").order(SortOrder.DESC));sortQuery.size(20); // 设置结果数量request.source(sortQuery);// 3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
分页
基础分页
- 功能:基础分页(from/size)
- 关键 API:
SearchSourceBuilder.from(0).size(15)
- 流程:
- 从第 0 条记录开始
- 返回 15 条结果
- 适合浅分页(from 值较小)
/*** 基础分页查询 --- from/size 参数* GET /索引名/_search* {* "query": {* "搜索方式": {}* },* "from": 10,* "size": 10,* "sort": []* }*/
@Test
public void testBasePage() throws IOException {// 1.创建请求SearchRequest request = new SearchRequest("hotel");// 2.创建请求体SearchSourceBuilder query = new SearchSourceBuilder();query.query(QueryBuilders.matchAllQuery());query.from(0).size(15);query.sort(new FieldSortBuilder("price").order(SortOrder.ASC));request.source(query);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> System.out.println(hit.getSourceAsMap()));
}
深度分页
- 功能:深度分页(Scroll API)
- 关键 API:
request.scroll(TimeValue.timeValueMinutes(1))SearchScrollRequest
- 流程:
- 初始化滚动会话,设置超时时间
- 通过 scroll_id 持续获取下一页
- 适合大数据量导出(不适合实时交互)
/*** 深度分页* GET /_search/scroll* {* "scroll": "1m",* "scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlY4R0RUTjVvVGhhc2hWYTQyakx4LXcAAAAAAAAULRZWSjV5VExtRlJNZTg5ekxoU2RuMHh3"* }*/
@Test
public void testScrollPage() throws IOException {// 1. 创建第一次查询请求SearchRequest request = new SearchRequest("hotel");// 2. 创建SearchSourceBuilder对象,用于构建查询源SearchSourceBuilder query = new SearchSourceBuilder();query.query(QueryBuilders.matchAllQuery());query.size(2);request.scroll(TimeValue.timeValueMinutes(1));request.source(query);// 3.执行搜索请求并获取响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 获取滚动查询的IDString scrollId = response.getScrollId();// 获取查询结果中的文档数组SearchHit[] hits = response.getHits().getHits();// 初始化页码为1int pageNum = 1;// 打印第一页的数据System.out.println("第" + pageNum + "页:");for (SearchHit hit : hits) {System.out.println(hit.getSourceAsMap());}System.out.println();// 4.循环滚动查询,直到没有更多结果while (hits != null && hits.length > 0) {// 4.1 创建滚动查询请求对象SearchScrollRequest scrollRequest = new SearchScrollRequest("hotel");scrollRequest.scrollId(scrollId);scrollRequest.scroll(TimeValue.timeValueMinutes(1));// 4.2 执行滚动查询并获取响应response = client.scroll(scrollRequest, RequestOptions.DEFAULT);hits = response.getHits().getHits();// 页码递增pageNum++;// 打印当前页的数据System.out.println("第" + pageNum + "页:");for (SearchHit hit : hits) {System.out.println(hit.getSourceAsMap());}// 更新滚动查询的IDscrollId = response.getScrollId();System.out.println();}
}
实时分页
- 功能:实时分页(search_after)
- 关键 API:
SearchSourceBuilder.searchAfter()hit.getSortValues()
- 流程:
- 基于排序值(价格、评分、ID)实现无偏移分页
- 每页使用上一页最后文档的排序值作为起点
- 适合实时用户交互场景
/*** 实时分页查询 --- search_after 参数* GET /hotel/_search* {* "size": 2,* "query": {* "match": {* "all": "如家"* }* },* "sort": [* {"price": "asc"},* {"score": "desc"}* ],* "search_after": [135,45]* }*/
@Test
public void testTimePage() throws IOException {// 创建搜索请求并指定索引SearchRequest request = new SearchRequest("hotel");SearchSourceBuilder query = new SearchSourceBuilder();// 设置查询条件:搜索所有字段中包含"如家"的文档query.query(QueryBuilders.matchQuery("all", "如家"));// 设置排序规则(必须包含至少一个唯一字段以确保结果稳定)// 1. 按价格升序排序query.sort(new FieldSortBuilder("price").order(SortOrder.ASC));// 2. 价格相同的情况下按评分降序排序query.sort(new FieldSortBuilder("score").order(SortOrder.DESC));// 3. 最终按文档ID升序排序(确保唯一性)query.sort(new FieldSortBuilder("_id").order(SortOrder.ASC));// 设置每页大小(每次查询返回的文档数量)query.size(2);// 用于存储上一页最后一个文档的排序值,作为下一页的起始点Object[] searchAfter = null;// 页码计数器int pageNum = 1;// 循环分页查询,直到没有更多结果do {// 非第一页需要设置 search_after 参数if (searchAfter != null) {// 设置 search_after 为上一页最后一个文档的排序值query.searchAfter(searchAfter);}// 将查询配置应用到请求中request.source(query);// 执行搜索请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 获取搜索结果文档数组SearchHit[] hits = response.getHits().getHits();// 如果没有结果,退出循环if (hits.length == 0) {break;}// 更新 search_after 为当前页最后一个文档的排序值,用于下一页查询searchAfter = hits[hits.length - 1].getSortValues();// 增加页码计数pageNum++;// 打印当前页的所有文档for (SearchHit hit : hits) {System.out.println(hit.getSourceAsMap());}// 分页间隔空行System.out.println();} while (true); // 持续循环直到没有更多结果
}
高亮
- 功能:搜索结果高亮
- 关键 API:
HighlightBuilder()
- 流程:
- 对
name字段中匹配的如家进行高亮 - 使用
<em>标签包裹高亮内容 - 从结果中提取高亮片段并打印
- 对
/*** 对搜索结果高亮处理* GET /索引名/_search* {* "query": {* "match": {* "字段": "查询字段值" // 查询字段* }* },* "highlight": {* "fields": {* "字段": {} // 指定要高亮的字段* }* }* }* @throws IOException*/
@Test
public void testHighlight() throws IOException {SearchRequest request = new SearchRequest("hotel");SearchSourceBuilder query = new SearchSourceBuilder();query.query(QueryBuilders.matchQuery("name", "如家"));query.highlighter(new HighlightBuilder().field("name").requireFieldMatch(false).preTags("<em>").postTags("</em>"));request.source(query);SearchResponse response = client.search(request, RequestOptions.DEFAULT);response.getHits().forEach(hit -> {Map<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField name = highlightFields.get("name");System.out.println(name.getFragments()[0].string());});
}
桶聚合
- 作用:将文档 “分组” 到不同的桶中,每个桶满足特定条件(如字段值、范围等)。
- 核心逻辑:类似 SQL 的
GROUP BY,但更灵活。 - 常用类型:
terms:按字段值分组(如按城市、标签分组)。range:按数值范围分组(如价格区间 [0-100]、[100-200])。date_range:按时间范围分组(如按月份、季度分组)。filters:按多个过滤条件分组。
- 应用场景:统计不同城市的酒店数量、按价格区间划分商品销量等。
/*** 桶聚合* GET /hotel/_search* {* "aggs": {* "聚合名称": {* "桶聚合类型": {* "参数": 值,* ...* },* "aggs": { // 嵌套聚合(可多层)* "子聚合名称": { ... }* }* }* }* }*/
@Test
public void testBucketAggregation() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().size(0);request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(5));request.source().sort("price", SortOrder.DESC);SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 正确获取并类型转换为 Terms 聚合Aggregations aggregations = response.getAggregations();Terms brandAgg = aggregations.get("brandAgg"); // 直接返回 Terms 类型if (brandAgg != null) {brandAgg.getBuckets().forEach(bucket -> {System.out.println("桶名称:" + bucket.getKey() + " | 文档数:" + bucket.getDocCount());});if (brandAgg.getMetadata() != null) {brandAgg.getMetadata().forEach((k, v) -> System.out.println(k + ":" + v));}} else {System.out.println("brandAgg 为空,请确认索引和字段是否正确");}
}
自动补全
/*** 根据前缀关键词获取酒店自动补全建议* * @param key 搜索关键词前缀* @return 包含自动补全建议的字符串列表* @throws RuntimeException 当搜索请求执行失败时抛出* * 工作流程:* 1. 创建针对hotel索引的搜索请求* 2. 配置Completion Suggester:* - 使用字段suggestion的完成建议器* - 设置搜索前缀为用户输入的关键词* - 启用重复项过滤* - 限制返回结果数量为10条* 3. 执行搜索请求并解析返回结果* 4. 提取建议文本并返回列表*/
@Override
public List<String> suggestions(String key){SearchRequest request = new SearchRequest("hotel");request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(key).skipDuplicates(true).size(10)));List<String> list = new ArrayList<>();try {SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);Suggest suggest = response.getSuggest();CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}System.out.println(list);} catch (IOException e) {throw new RuntimeException(e);}return list;
}/*** 从聚合结果中提取指定名称的聚合桶键列表* * @param aggregations 聚合结果对象* @param aggName 目标聚合名称* @return 包含聚合桶键的字符串列表* * 工作流程:* 1. 根据聚合名称从聚合结果中获取Terms聚合* 2. 提取聚合中的所有桶(buckets)* 3. 遍历每个桶并提取键值* 4. 将所有键值收集到列表中返回*/
private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历List<String> list = new ArrayList<>();for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();list.add(key);}return list;
}
如有错误,欢迎指正!!!