使用 Unsloth 快速微调 LLMs 实用指南
大型语言模型(LLM)虽然具备强大的通用能力,但在实际生产部署中往往面临诸多挑战。要使它们真正满足企业级需求,必须确保模型能够:
-
动态适应领域知识 - 持续吸收最新的行业数据和专业信息
-
精准控制输出风格 - 保持符合品牌调性的表达方式
-
严格保障安全性 - 避免产生有害或误导性内容
-
消除信息幻觉 - 确保输出内容的真实性和可靠性
-
稳定聚焦任务目标 - 防止回答偏离核心业务需求
这就是 “微调”(Fine-tuning)的用武之地,即在特定数据集上进一步训练 LLM,使其内化有关领域、语气或预期任务目标的信息。
很多人会认为,RAG(检索增强生成)可以替代微调模型,但它并不能完全替代模型微调。二者本质上是互补关系:
RAG 的固有局限性
-
上下文整合效率低:检索到的外部知识难以深度融入模型推理过程
-
风格控制能力弱:无法系统性调整模型的表达方式和输出格式
-
延迟问题显著:额外的检索步骤会显著增加响应时间(通常增加300-500ms)
-
知识更新滞后:依赖外部知识库的更新周期,难以及时反映最新信息
微调的独特优势
-
深度知识内化:将专业知识直接编码到模型参数中
-
风格定制化:可精确控制语气、文风和输出结构
-
推理零延迟:无需外部检索,保持原始模型的响应速度
-
持续进化能力:支持增量学习,实现知识持续更新
但如何高效地进行微调?
微调一直是计算密集且耗时的工作,因为传统的微调需要通过在特定数据集上重新训练模型来更新所有模型权重。
对于拥有数十亿个参数的大型 LLM,传统的微调需要使用庞大而昂贵的 GPU,并经过数小时甚至数天的训练才能获得理想的结果。
微软在 2021 年发表的一篇研究论文彻底改变了这一观念,提出了一种参数高效的 LLM 微调方法。
与使用 175B 个参数对 GPT-3 进行传统微调相比,他们的方法 LoRA(Low-Rank Adaptation)将可训练参数的数量减少了 10,000 倍,GPU 内存需求减少了 3 倍!
它通过冻结预训练模型权重并将可训练秩分解矩阵注入变换器架构的每一层来实现这一目标。 因此,有了 LoRA,我们只需调整几百万个参数,而无需更新数十亿个参数,就能达到与传统微调接近的精度。
数学原理
在数学上,标准微调涉及更新一个更大的权重矩阵 W ,其维度为 d x k,其中 d 是输入维度,k 是模型的输出维度,如下所示:
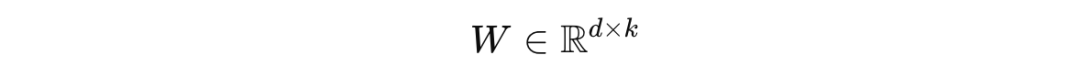
另一方面,LoRA 会将该矩阵的变化分解为两个小得多的矩阵的乘积(lower [rank](https://en.wikipedia.org/wiki/Rank_(linear_algebra "rank"))),如下所示:
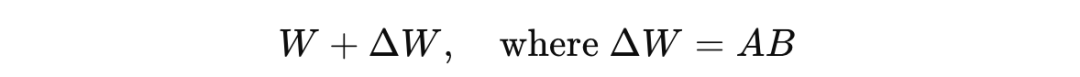
这些矩阵 A 和 B 被称为秩分解矩阵,其维度如下,其中 r 是矩阵的秩:
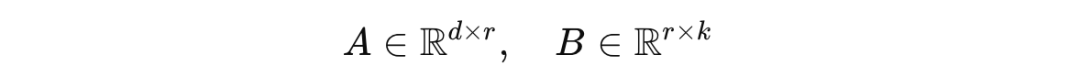
在微调过程中,只对这些矩阵进行训练,而原始权重矩阵 W 则保持不变。
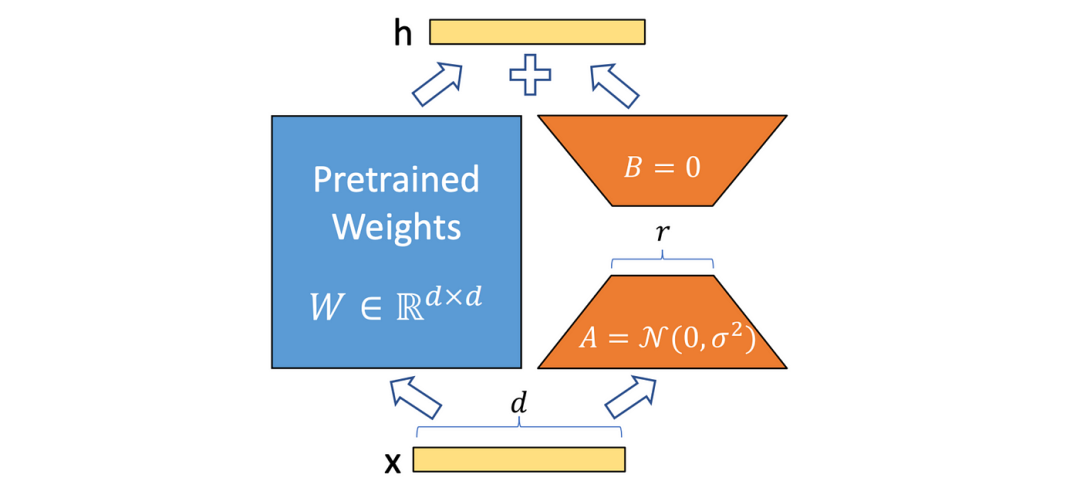
输入和输出大小'd'相似的模型的秩分解图,其中预训练权重的维度为 d x d,但得到的矩阵 A 和 B 的维度分别为'd x r'和'r x d'。(图片来自 ArXiv 上发表的题为“LoRA:Low-Rank Adaptation of Large Language Models[1] ”的研究论文)
假设我们的 LLM 有以下值:
-
输入大小或
d=512 -
输出大小或
k=2048
这样,可学习的权重参数总数为 1,048,576 (512 x 2048)。
在使用 r = 8 进行秩分解时,可学习的权重参数总数为 (d × r) + (r × k) = r × (d + k) ,即只有 20k 个参数,而不是 1M+ 。
这减少了约 98% 的参数!
怎样让 LoRA 运行得更快吗?
可以!这正是 Unsloth[2] 所要做的。
Unsloth 是一个将 LoRA 与 4 位量化相结合的框架,称为 QLoRA(Quantized Low-Rank Adaptation)[3]。
如果你对“量化[4]”这个术语感到陌生,那么它的含义如下。
在深度学习中,计算和模型参数的默认精度是 32 位浮点(FP32)[5]。
这意味着每个参数占用 32 位内存。
在4 位量化[6]中, 这些参数被降低到 4 位精度,从而大大降低了内存需求和训练时间。
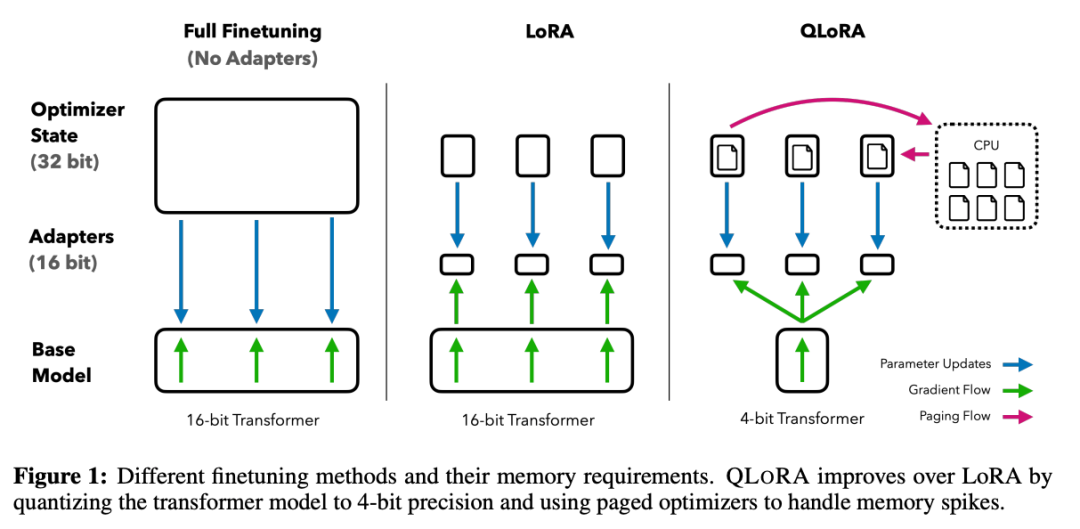
完全微调与 LoRA 与 QLoRA 的对比(图片来自 Arxiv 题为“QLoRA: Efficient Finetuning of Quantized LLMs[7] ”的研究论文)
Unsloth 则更进一步,通过手动推导反向传播步骤和使用**Triton**[8]将 PyTorch 模块重写为高效的 GPU 内核,优化了 QLoRA 的默认实现。
与传统方法相比,这使其微调速度提高了2.7倍,内存使用量减少了**74%,同时不影响精度。
现在我们了解了 Unsloth 的基本原理,让我们用它来微调 LLM。
微调 LLM 以正确回答医学问题
本文主要目的是微调Llama-3.2-1B-Instruct[9] 模型,以正确回答医学问题。
该模型已通过监督微调(SFT)和人类反馈强化学习(RLHF)进行了微调,以符合人类对有用性和安全性的偏好。
我们将使用MedQA-USMLE[10]数据集对其进行进一步训练,该数据集可作为关于拥抱脸的开源数据集[11]使用。
安装 Unsloth
Unsloth 只能在使用英伟达™(NVIDIA®)GPU 的情况下运行。
我们将使用带有 T4 GPU 运行时的 Google Colab 来解决这个问题。
我们按如下步骤安装 unsloth 软件包:
!pip install unsloth
下载基本模型和标记符
下面下载 4 位量化的 Llama-3.2-1B-Instruct[12]及其标记符。
from unsloth import FastLanguageModelmodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/Llama-3.2-1B-Instruct",max_seq_length = 2048,load_in_4bit = True,
)
用医学问题进行测试
向基础模型提出一个测试问题。
# Test using a medical question
import torchdevice = "cuda"if torch.cuda.is_available() else"cpu"tokenizer.pad_token = tokenizer.eos_tokenmodel.eval()prompt = """
Q. A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus.
Which of the following is the best treatment for this patient?Options:
A: Ampicillin
B: Ceftriaxone
C: Ciprofloxacin
D: Doxycycline
E: NitrofurantoinPlease choose the correct answer.
"""inputs = tokenizer(prompt, return_tensors="pt").to(device)
input_len = inputs["input_ids"].shape[-1]output = model.generate(**inputs, max_new_tokens=128)response = tokenizer.decode(output[0][input_len:], skip_special_tokens=True)print("Test Prompt:\n", prompt.strip())
print("\nTest Response:\n", response.strip())
The following is the response that we get.
Test Prompt:Q. A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus.
Which of the following is the best treatment for this patient?Options:
A: Ampicillin
B: Ceftriaxone
C: Ciprofloxacin
D: Doxycycline
E: NitrofurantoinTest Response:F: Levofloxacin
G: Doxycycline
H: Metronidazole
I: Trimethoprim/sulfamethoxazole
J: Azithromycin
A. Ceftriaxone
B. Ceftriaxone
C. Ciprofloxacin
D. Doxycycline
E. Nitrofurantoin
F. Levofloxacin
G. Doxycycline
H. Metronidazole
I. Trimethoprim/sulfamethoxazole
J. Azithromycin
The best
模型回答的是幻觉中的新选项,并没有回答我们的问题。*哎呀,这需要修复!
加载和准备医疗质量保证数据集
MedQA-USMLE](https://huggingface.co/datasets/Neelectric/MedQA-USMLE/viewer/default/train?row=57)数据集包含来自United States Medical Licensing Examination(USMLE)[13]的 10,178 道训练题。
我们的加载过程如下:
# Load dataset
from datasets import load_datasetdataset = load_dataset("Neelectric/MedQA-USMLE", split="train")
该数据集有以下列。
Dataset({features: ['question', 'answer', 'options', 'meta_info', 'answer_idx'],num_rows: 10178
})
这就是其中一个训练示例的样子。
print("Question:\n", dataset[0]["question"])
print("\nOptions:\n", dataset[0]["options"])
print("\nAnswer:\n", dataset[0]["answer"])
Question:A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus. Which of the following is the best treatment for this patient?Options:{'A': 'Ampicillin', 'B': 'Ceftriaxone', 'C': 'Ciprofloxacin', 'D': 'Doxycycline', 'E': 'Nitrofurantoin'}Answer:Nitrofurantoin
我们需要将该数据集转换为聊天式的提示和回复结构,并将其格式化为我们的模型内部预期[14],以便进行微调。
具体步骤如下。
def format_prompts(examples):questions = examples["question"]options_list = examples["options"]answers = examples["answer"]conversations = []for q, opts, ans in zip(questions, options_list, answers):options_text = "\n".join([f"{key}. {val}"for key, val in opts.items()])prompt = f"{q}\n\nOptions:\n{options_text}\n\nPlease choose the correct answer."response = f"The correct answer is {ans}."conversations.append([{"role": "user", "content": prompt},{"role": "assistant", "content": response},])texts = [tokenizer.apply_chat_template(convo, tokenize=False, add_generation_prompt=False) for convo in conversations]return {"text": texts}dataset = dataset.map(format_prompts, batched=True)
This is how our dataset now looks with a new ‘text’ column.
Dataset({features: ['question', 'answer', 'options', 'meta_info', 'answer_idx', 'text'],num_rows: 10178
})
该数据集的一个示例如下。
print("Question:\n", dataset[0]["question"])
print("\nOptions:\n", dataset[0]["options"])
print("\nAnswer:\n", dataset[0]["answer"])
print("\nFormatted Text:\n", dataset[0]["text"])
Question:A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus. Which of the following is the best treatment for this patient?Options:{'A': 'Ampicillin', 'B': 'Ceftriaxone', 'C': 'Ciprofloxacin', 'D': 'Doxycycline', 'E': 'Nitrofurantoin'}Answer:NitrofurantoinFormatted Text:<|begin_of_text|><|start_header_id|>system<|end_header_id|>Cutting Knowledge Date: December 2023
Today Date: 10 Apr 2025<|eot_id|><|start_header_id|>user<|end_header_id|>A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus. Which of the following is the best treatment for this patient?Options:
A. Ampicillin
B. Ceftriaxone
C. Ciprofloxacin
D. Doxycycline
E. NitrofurantoinPlease choose the correct answer.<|eot_id|><|start_header_id|>assistant<|end_header_id|>The correct answer is Nitrofurantoin.<|eot_id|>
配置模型以进行参数高效微调 (PEFT)/ LoRA
为微调模型做好准备。
model = FastLanguageModel.get_peft_model(model,r=16,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],lora_alpha=16,lora_dropout=0,bias="none",use_gradient_checkpointing="unsloth",random_state=42,use_rslora=False,loftq_config=None,
)
每个参数都有以下含义:
-
model:我们打算微调的 LLM -
r: Low-Rank Adaptation (LoRA) 更新矩阵的等级 -
target_modules: 我们使用 LoRA 针对的模型层。 在我们的例子中,我们使用的是 LLM 变换器模型中与注意力和前馈机制相关的层。 -
lora_alpha: 微调期间 LoRA 更新的缩放因子 -
lora_dropout: LoRA 的丢失率 -
bias: 设置微调时是否更新偏置项 -
use_gradient_checkpointing: 使用 Gradient checkpointing[15],以减少 VRAM 的使用。 我们使用的是 Unsloth 设计的自定义实现。 -
random_state: 使用 LoRA 的 randonmess 种子 -
use_rslora: 设置微调期间是否使用Rank-Stabilized LoRA (RS-LoRA)[16] -
loftq_config: 如果使用LoftQ(LoRA-Fine-Tuning-aware Quantization)[17],则设置其参数
设置训练器
在这一步中,我们将设置 Huggingface TRL[18]的 “SFTTrainer ”如下:
from trl import SFTTrainertrainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,dataset_text_field = "text",max_seq_length = 2048,dataset_num_proc = 2,packing = False,args=TrainingArguments(per_device_train_batch_size = 2,gradient_accumulation_steps = 4,warmup_steps = 5,max_steps = 200,learning_rate = 2e-4,logging_steps = 10,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 700,output_dir = "outputs",report_to = "none",),
)
在这个类中,有一些参数是我们以前没有见过的。这些参数的含义如下:
-
train_dataset`: 用于训练的数据集
-
dataset_text_field: 数据集中包含用于训练的文本的字段 -
max_seq_length: 输入数据的最大序列长度。超过此长度的序列将被截断。 -
dataset_num_proc: 用于数据预处理的进程数 -
packing=False: 防止将多个示例串联成一个序列 -
args=TrainingArguments(...): 训练参数配置如下所示 -
per_device_train_batch_size: 每个设备每批训练样本的数量。 -
gradient_accumulation_steps: 执行优化步骤前积累梯度的步数 -
warmup_steps: 训练开始时学习率线性预热的步数 -
max_steps: 训练的总步数 -
learning_rate: 优化器的学习率。 -
logging_steps: 记录训练步数的频率 -
optim: 指定要使用的优化器 -
weight_decay: 正则化的权重衰减系数,以防止过度拟合 -
lr_scheduler_type: 学习率调度器类型。在我们的例子中,linear在训练期内线性降低学习率。 -
output_dir: 保存模型检查点和训练输出的目录。 -
report_to: 指定报告平台(例如 Tensorboard[19])
接下来,我们要确保在微调过程中,损耗是根据assistant的回应而不是对话的 system 和 user 部分来计算的。
from unsloth.chat_templates import train_on_responses_onlytrainer = train_on_responses_only(trainer,instruction_part="<|start_header_id|>user<|end_header_id|>\n\n",response_part="<|start_header_id|>assistant<|end_header_id|>\n\n",
)
检查内存统计数据
在开始微调之前,让我们先了解一下 GPU 的一些细节。
import torchgpu_stats = torch.cuda.get_device_properties(0)start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
GPU = Tesla T4. Max memory = 14.741 GB.
4.252 GB of memory reserved.
开始训练
最后,我们开始如下训练。
trainer_stats = trainer.train()
完成后,我们可以保存模型和标记符,如下所示。
# Save LoRA fine tuned model and tokenizeroutput_dir = "medqa_finetuned_model"model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
检查内存和时间统计数据
下面的代码将为我们提供所有内存和训练时间统计信息,我们可以利用这些信息进行进一步的微调实验。
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory / max_memory * 100, 3)
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training."
)
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
259.3875 seconds used for training.
4.32 minutes used for training.
Peak reserved memory = 4.252 GB.
Peak reserved memory for training = 0.0 GB.
Peak reserved memory % of max memory = 28.845 %.
Peak reserved memory for training % of max memory = 0.0 %.
注意,微调这个庞大的模型只用了几分钟!
推理
最后,是时候测试基础模型和微调模型在医学问题上的表现了。
我们首先建立这些模型,并将它们放入评估模型中。
base_model_name = "unsloth/Llama-3.2-1B-Instruct"
lora_path = "medqa_finetuned_model"
max_seq_length = 2048# Load Base Model
base_model, tokenizer = FastLanguageModel.from_pretrained(model_name = base_model_name,max_seq_length = max_seq_length,dtype = torch.float16,load_in_4bit = True,
)tokenizer.pad_token = tokenizer.eos_token
tokenizer = get_chat_template(tokenizer, chat_template="llama-3.2")base_model.eval()# Load LoRA Fine-Tuned Model
lora_model, _ = FastLanguageModel.from_pretrained(model_name = base_model_name,max_seq_length = max_seq_length,dtype = torch.float16,load_in_4bit = True,
)lora_model.load_adapter(lora_path)
lora_model.eval()
接下来,我们编写并使用一个函数来检查和比较这些模型的响应。
在下面的例子中,我们将使用训练数据集中的一个示例,但要很好地评估微调模型,您最好使用不同的定量(指标,如BLEU[20]、Perplexity[21]等)和定性(人类专家审查/LLM-as-a-judge[22])方法。
def compare_model_outputs(base_model, lora_model, tokenizer, prompt, max_new_tokens=128):def generate_response(model, prompt):formatted_prompt = tokenizer.apply_chat_template([{"role": "user", "content": prompt.strip()}],tokenize=False,add_generation_prompt=True,)inputs = tokenizer(formatted_prompt, return_tensors="pt").to(device)input_len = inputs["input_ids"].shape[-1]output = model.generate(**inputs, max_new_tokens=max_new_tokens)response = tokenizer.decode(output[0][input_len:], skip_special_tokens=True)return response.strip()print("Prompt:\n")print(prompt.strip())print("\nBase Model Response:\n")print(generate_response(base_model, prompt))print("\nFine-Tuned Model Response:\n")print(generate_response(lora_model, prompt))
prompt = """
Q. A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus.
Which of the following is the best treatment for this patient?Options:
A: Ampicillin
B: Ceftriaxone
C: Ciprofloxacin
D: Doxycycline
E: NitrofurantoinPlease choose the correct answer.
"""
compare_model_outputs(base_model, lora_model, tokenizer, prompt)
将返回以下答复。
Prompt:Q. A 23-year-old pregnant woman at 22 weeks gestation presents with burning upon urination. She states it started 1 day ago and has been worsening despite drinking more water and taking cranberry extract. She otherwise feels well and is followed by a doctor for her pregnancy. Her temperature is 97.7°F (36.5°C), blood pressure is 122/77 mmHg, pulse is 80/min, respirations are 19/min, and oxygen saturation is 98% on room air. Physical exam is notable for an absence of costovertebral angle tenderness and a gravid uterus.
Which of the following is the best treatment for this patient?Options:
A: Ampicillin
B: Ceftriaxone
C: Ciprofloxacin
D: Doxycycline
E: NitrofurantoinPlease choose the correct answer.Base Model Response:To determine the best treatment for this patient, let's analyze the information provided:1. **Symptoms**: The patient is experiencing burning upon urination, which started 1 day ago and worsened despite drinking more water and taking cranberry extract. This suggests a urinary tract infection (UTI).2. **Age and Pregnancy**: The patient is 23 years old at 22 weeks gestation. While there's no direct contraindication for antibiotics in pregnancy, the use of cranberry extract is not recommended during pregnancy due to potential risks.3. **Vital Signs**: The patient's temperature is normal, blood pressure isFine-Tuned Model Response:The correct answer is Nitrofurantoin.
这个答案是正确的,而且不像基础模型的回答那样啰嗦。
恭喜!我们已经成功地对 LLM 进行了微调,使其立足于相关的医学信息,并在回答时采用对话风格。
如何对LLMs进行最佳微调?
微调更多的是试错,而不是遵循精确的指导原则,但以下几条一般原则将帮助您实现更好的微调性能。
数据质量的关键作用
训练数据的质量直接影响微调效果。理想情况下,数据集应当经过严格清洗,确保样本准确无误。数据需要覆盖目标场景的各种边界情况,数量通常在500-5000个优质样本之间。值得注意的是,人工标注数据通常比合成数据效果提升30-50%,这是值得投入的方向。
微调策略的权衡选择
在资源充足且追求极致性能的场景下,全参数微调是首选方案,通常能达到最佳效果,性能提升可达5-15%。但需要准备高端GPU集群,并接受长达数天的训练时间。对于资源有限或需要快速迭代的情况,参数高效微调(如LoRA)更为合适,它能将GPU内存需求降低3倍,训练速度提升5-10倍,同时保持全参数微调90-95%的性能水平。
关键参数的优化技巧
学习率的选择需要区分微调方式:全参数微调建议使用3e-5到5e-5,而LoRA微调建议1e-4到5e-4。训练过程应当采用早停策略(patience=3),每100步验证一次效果,通常需要3-10个epoch。特别需要注意的是灾难性遗忘问题,可以通过保留10%原始预训练数据,采用弹性权重固化(EWC)技术,并持续监控原始任务性能来预防。
多维度的评估体系
建立完善的评估体系至关重要。自动评估可以使用LLM-as-a-judge(如GPT-4评估),重点关注相关性、准确性和流畅度等指标。人工评估则需要设计细粒度评分卡(1-5分制),安排至少3人交叉评审,特别关注边缘案例的表现。线上A/B测试建议采用渐进式放开策略(5%→20%→50%→100%),密切监控业务核心指标的变化。
持续优化的实施路径
模型微调不是一次性的工作,建议每月用新数据进行增量学习刷新模型。可以考虑组合多个微调版本的集成学习方法。建立用户反馈闭环机制,持续收集使用数据。最重要的是详细记录每次实验参数,保持完整的文档追踪。
实践建议:从LoRA开始建立基线,再尝试全参数微调。每次变更只调整一个变量,确保实验结果的可追溯性。这种循序渐进的方法能够帮助团队在可控的成本下获得最佳的微调效果。
参考资料
[1]
LoRA:Low-Rank Adaptation of Large Language Models: https://arxiv.org/abs/2106.09685
[2]
Unsloth: https://unsloth.ai/
[3]
QLoRA(Quantized Low-Rank Adaptation): https://arxiv.org/abs/2305.14314
[4]
量化: https://huggingface.co/docs/optimum/en/concept_guides/quantization
[5]
32 位浮点(FP32): https://en.wikipedia.org/wiki/Single-precision_floating-point_format
[6]
4 位量化: https://huggingface.co/blog/4bit-transformers-bitsandbytes
[7]
QLoRA: Efficient Finetuning of Quantized LLMs: https://arxiv.org/abs/2305.14314
[8]
Triton: https://triton-lang.org/main/index.html
[9]
Llama-3.2-1B-Instruct: https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
[10]
MedQA-USMLE: https://huggingface.co/datasets/Neelectric/MedQA-USMLE/viewer/default/train?row=57
[11]
关于拥抱脸的开源数据集: https://huggingface.co/docs/datasets/en/index
[12]
Llama-3.2-1B-Instruct: https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
[13]
United States Medical Licensing Examination(USMLE): https://www.usmle.org/
[14]
内部预期: https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_2/
[15]
Gradient checkpointing: https://aman.ai/primers/ai/grad-accum-checkpoint/
[16]
Rank-Stabilized LoRA (RS-LoRA): https://arxiv.org/abs/2312.03732
[17]
LoftQ(LoRA-Fine-Tuning-aware Quantization): https://arxiv.org/abs/2310.08659
[18]
Huggingface TRL: https://huggingface.co/docs/trl/en/index
[19]
Tensorboard: https://www.tensorflow.org/tensorboard
[20]
BLEU: https://en.wikipedia.org/wiki/BLEU
[21]
Perplexity: https://huggingface.co/docs/transformers/en/perplexity
[22]
LLM-as-a-judge: https://github.com/tatsu-lab/alpaca_eval